Domain-Specific Aspect-Sentiment Pair Extraction Using Rules and Compound Noun Lexicon for Customer Reviews


Abstract
:1. Introduction
- To determine the optimized number of review sentences to train the aspect-sentiment pair extraction model; and
- To improve the aspect-sentiment pairs extraction via enhancement of rules and compound noun lexicon.
2. Aspect-Sentiment Opinion Mining
3. Related Work
4. Aspect Sentiment Pair Extraction using Rules and the Compound Noun Lexicon Model
4.1. Phase I: Compound Noun Lexicon Generation
4.1.1. Step I: Compound Nouns’ Pattern Identification
4.1.2. Step II: Compound Nouns Compilation
4.1.3. Step III: Compound Nouns Verification
4.1.4. Step 4: Compound Nouns’ Pruning
4.2. Phase II: Aspect-sentiment Pair Rules Generation
4.2.1. Step I: Preprocessing
4.2.2. Step II: POS Tagging
4.2.3. Step III: Special Compound Noun Pattern Detection

4.2.4. Step IV: POS Tag Grouping
4.2.5. Step V: Rules’ Generation
4.3. Phase III: Aspect-sentiment Pair Extraction
4.3.1. Step I: Preprocessing
4.3.2. Step II: POS Tagging
4.3.3. Step III: Compound Noun Pattern Detection

4.3.4. Step IV: POS Tag Grouping
4.3.5. Step V: Rule and Grouped POS Tagged Sentence Matching




5. Results and Discussion
5.1. Dataset
5.1.1. Data Collection
5.1.2. Benchmarked Dataset
5.2. Performance Metric
5.2.1. Precision
- Relevant aspect sentiment pair indicates the correct aspect-sentiment pair that is extracted by the approach as in the gold standard aspect-sentiment pair; and
- retrieved aspect sentiment pair indicates the aspect-sentiment pair in the gold standard that is supposed to be retrieved by the approach, but it is not retrieved. Also, added with the aspect-sentiment pair that is retrieved by the approach, but not present in the gold standard.
5.2.2. Recall
5.3. Experimental Result
5.3.1. Evaluation on Optimized Number of Review Sentences to Train the Aspect-sentiment Pair Extraction Model
5.3.2. Evaluation on Precision and Recall of Aspect-sentiment Pair Extraction on Testing Review Sentences
- The baseline [8] has nine rules for extraction of aspect-sentiment pairs. The rules consist of a POS tag sequence to extract aspect-sentiment pairs where a noun is extracted as an aspect and an adjective as a sentiment. The position of the aspect and sentiment is denoted by the arrangement of the noun and adjective in rules;
- this approach considers extraction of aspect-sentiment pairs with occurrence of aspect-sentiment pairs, such as one aspect with one sentiment, one aspect with many sentiments, many aspects with one aspect, one sentiment with one aspect, one sentiment with many aspects, and many sentiments with one aspect; and
- for the multi-word, the aspect is only considered a noun-noun compound noun. Special compound noun aspects and parent-child aspects are not identified.
- This model consists of 63 rules and a template for extraction of aspect-sentiment pairs. The position of aspects and sentiments is denoted with respect to the arrangement of nouns and adjectives in the rules and in the template;
- the model considers extraction of aspect-sentiment pairs with the occurrence of aspect-sentiment pairs, such as one aspect with one sentiment, one aspect with many sentiments, many aspects with one aspect, one sentiment with one aspect, one sentiment with many aspects, and many sentiments with one aspect; and
- it is also able to identify multi-word aspects, such as a noun-noun compound noun, special compound noun aspect, and parent-child aspect.
- This model is the variant of ASPERC where the usage of a compound noun is excluded;
- it can identify a multi-word aspect, such as a noun-noun compound noun and parent-child aspect. A special compound noun aspect is not identified; and
- the model is used to test the rules applicability across various domains.
5.4. Result Analysis
5.4.1. Optimized Number of Review Sentences to Train the Aspect-sentiment Pair Extraction Model
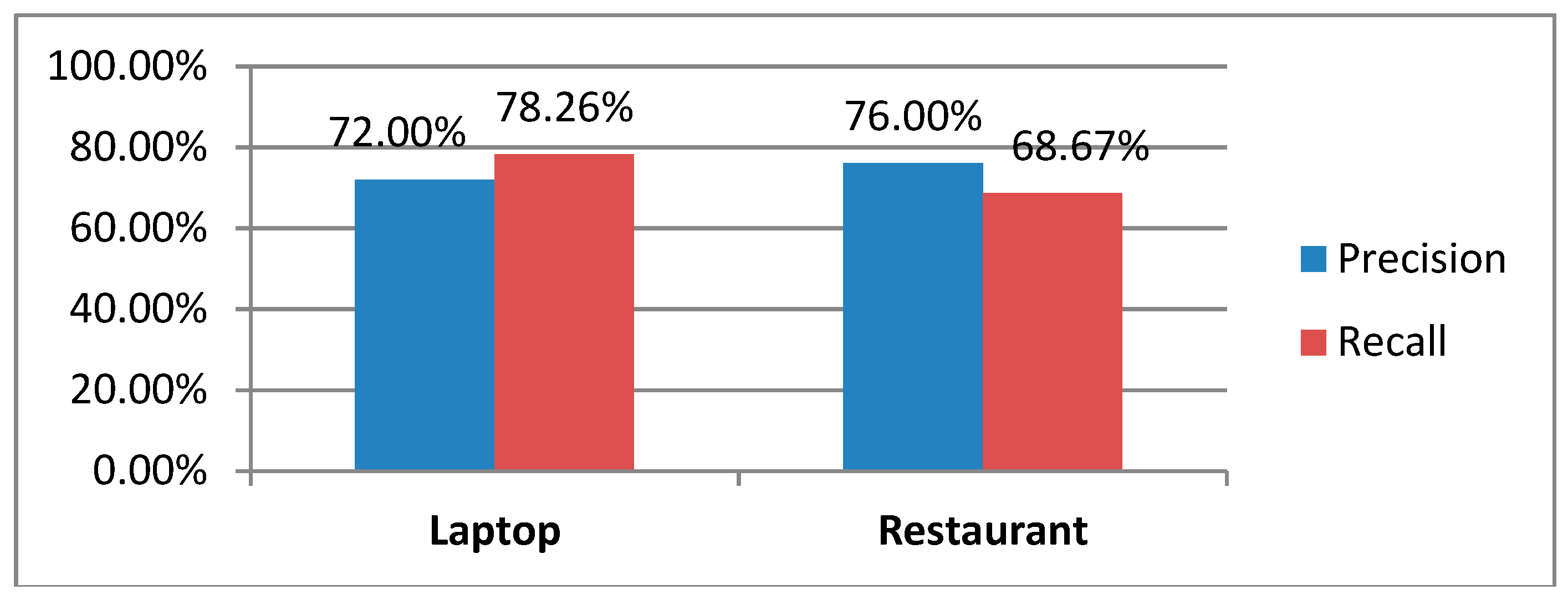
5.4.2. Precision of Aspect-sentiment Pair Extraction on Testing Review Sentences
5.4.3. Recall of Aspect-sentiment Pair Extraction on Testing Review Sentences
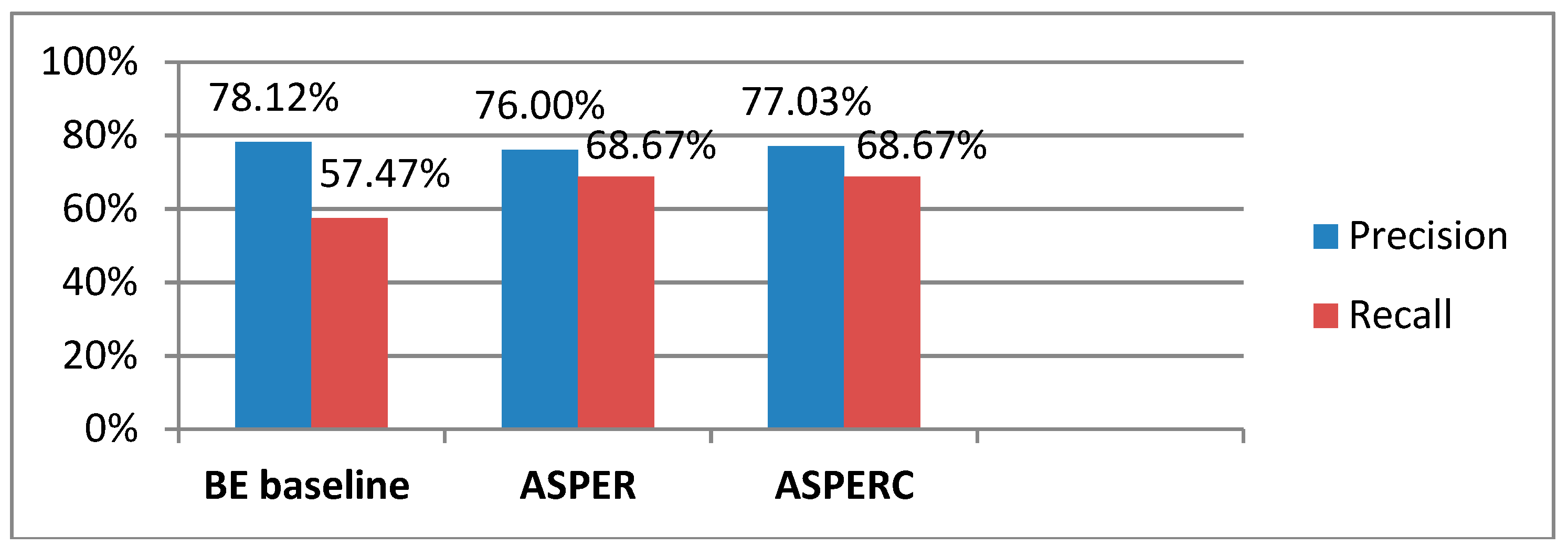
5.5. Comparison of Aspect-sentiment Pair Extraction ASPER Model, ASPERC Model, and BE Baseline
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Liu, B. Sentiment analysis and opinion mining. In Synthesis Lectures on Human Language Technologies; Morgan & Claypool Publishers: San Rafael, CA, USA, 2012; Volume 5, pp. 1–167. [Google Scholar]
- Perikos, I.; Hatzilygeroudis, I. Aspect based sentiment analysis in social media with classifier ensembles. In Proceedings of the IEEE/ACIS 16th International Conference on Computer and Information Science (ICIS), Wuhan, China, 24–26 May 2017; pp. 273–278. [Google Scholar]
- Hu, M.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–24 August 2004; pp. 168–177. [Google Scholar]
- Popescu, A.M.; Etzioni, O. Extracting product features and opinions from reviews. In Natural Language Processing and Text Mining; Springer: London, UK, 2007; pp. 9–28. [Google Scholar]
- Moghaddam, S.; Ester, M. On the Design of LDA Models for Aspect-based Opinion Mining. In Proceedings of the 12th ACM International Conference on Information & Knowledge Management, Maui, HI, USA, 29 October–2 November 2012; pp. 803–812. [Google Scholar]
- Ravi, K.; Raghuveer, K. Web User Opinion Analysis for Product Features Extraction and Opinion Summarization. Int. J. Web Semant. Technol. 2012, 3, 69–82. [Google Scholar] [CrossRef]
- Chinsha, T.C.; Shibily, J. A Syntactic Approach for Aspect Based Opinion Mining. In Proceedings of the 9th International Workshop on Semantic Evaluation, Denver, CO, USA, 4–5 June 2015; pp. 730–735. [Google Scholar]
- Bancken, W.; Alfarone, D.; Davis, J. Automatically Detecting and Rating Product Aspects from Textual Customer Reviews. In Proceedings of the DMNLP, Workshop at ECML/PKDD, Nancy, France, 15 September 2014. [Google Scholar]
- Bross, J.; Ehrig, H. Automatic construction of domain and aspect specific sentiment lexicons for customer review mining. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 1077–1086. [Google Scholar]
- Veselovská, K.; Tamchyna, A. UFAL: Using Hand-crafted Rules in Aspect Based Sentiment Analysis on Parsed Data. In Proceedings of the 8th International Workshop on Semantic Evaluation, Dublin, Ireland, 23–24 August 2014; pp. 694–698. [Google Scholar]
- Poria, S.; Cambria, E.; Gelbukh, A.; Gui, C. A Rule-Based Approach to Aspect Extraction from Product Reviews. In Proceedings of the Second Workshop on Natural Language Processing for Social Media, Dublin, Ireland, 24 August 2014; pp. 28–37. [Google Scholar]
- Zhao, Q.; Wang, H.; Lv, P.; Zhang, C. A Bootstrapping Based Refinement Framework for Mining Opinion Words and Targets. In Proceedings of the 23rd ACM International Conference On Conference On Information and Knowledge Management, Shanghai, China, 3–7 November 2014; pp. 1995–1998. [Google Scholar]
- Carpenter, T.; Golab, L.; Syed, S. Is the Grass Greener? Mining Electric Vehicle Opinions. In Proceedings of the 5th International Conference on Future Energy Systems, Cambridge, UK, 11–13 June 2014; pp. 241–252. [Google Scholar]
- Li, Y.; Wang, H.; Qin, Z.; Xu, W.; Guo, J. Confidence Estimation and Reputation Analysis in Aspect Extraction. In Proceedings of the 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 3612–3617. [Google Scholar]
- Kim, H.; Ganesan, K.; Parikshit, S.; ChengXiang, Z. Comprehensive review of opinion summarization. 2011; in press. [Google Scholar]
- Schouten, K.; Frasincar, F. Survey on Aspect-Level Sentiment Analysis. IEEE T Knowl. Data En. 2016, 28, 813–830. [Google Scholar] [CrossRef]
- Hurford, J.R. Grammar: A. Student’s Guide; Cambridge University Press: Cambridge, UK, 1994. [Google Scholar]
- Kim, S.; Zhang, J.; Chen, Z.; Oh, A.; Liu, S. A Hierarchical Aspect-Sentiment Model for Online Reviews. In Proceedings of the 27th AAAI Conference on Artifical Intelligence, Bellevue, WA, USA, 14–18 July 2013; pp. 526–533. [Google Scholar]
- Xu, P.; Kang, J.; Ringgaard, M.; Och, F. Using a Dependency Parser to Improve SMT for Subject-Object-Verb Languages. In Proceedings of the Annual Conference of the North American Chapter of ACL, Boulder, CO, USA, 31 May–5 June 2009; pp. 245–253. [Google Scholar]
- Wang, W.; Pan, S.J.; Dahlmeier, D.; Xiao, X. Coupled Multi-Layer Attentions for Co-Extraction of Aspect and Opinion Terms. In Proceedings of the AAAI, San Francisco, CA, USA, 4–9 February 2017; pp. 3316–3322. [Google Scholar]
- Luhn, H.P. Key word-in-context index for technical literature (KWIC index). Am. Doc. 1960, 11, 288–295. [Google Scholar] [CrossRef]
- Anthony, L. AntConc: Design and Development of a Freeware Corpus Analysis Toolkit for the Technical Writing Classroom. In Proceedings of the 2005 International Professional Communication Conference, Limerick, Ireland, 10–13 July 2005; pp. 729–737. [Google Scholar]
- Barri’ere, C.; Ménard, P. Multiword noun compound bracketing using Wikipedia. In Proceedings of the First Workshop on Computational Approaches to Compound Analysis, Dublin, Ireland, 24 August 2014; pp. 72–80. [Google Scholar]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, And Speech Recognition, 2nd ed.; Prentice Hall PTR: Upper Saddle River, NJ, USA, 2014. [Google Scholar]
- Pontiki, M.; Galanis, D.; Pavlopoulos, J.; Papageorgiou, H.; Androutsopoulos, I.; Manandhar, S. Semeval-2014 Task 4: Aspect Based Sentiment Analysis. In Proceedings of the 8th International Workshop on Semantic Evaluation, Dublin, Ireland, 23–24 August 2014; pp. 27–35. [Google Scholar]
- Ganu, G.; Elhadad, N.; Marian, A. Beyond the Stars: Improving Rating Predictions using Review Text Content. In Proceedings of the 12th International Workshop on the Web and Databases, Providence, RI, USA, 28 June 2009; pp. 1–6. [Google Scholar]
- Kiremire, A.R. The Application of The Pareto Principle in Software Engineering; Louisiana Tech University: Ruston, LA, USA, 2011. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | Laptop Review Sentences |
|---|---|
| 1 | Keyboard is great |
| 2 | Mac OS is so simple and easy |
| 3 | Nice appearance |
| 4 | Simple yet stylish design |
| 5 | Design of this laptop is fantastic |
| 6 | The Photo Booth is a great program |
| No | Aspect | Sentiment |
|---|---|---|
| 1 | Keyboard | Great |
| 2 | Mac OS | Simple |
| Mac OS | Easy | |
| 3 | Appearance | Nice |
| 4 | Design | Simple |
| Design | Stylish | |
| 5 | Design of laptop | Fantastic |
| 6 | Photo Booth program | Great |
| Compound Noun Patterns | Example |
|---|---|
| JJ+ NN+ | Hard/JJ disk/NN |
| NN+ CD | Windows/NN 7/CD |
| VB+ NN+ | Operating/VBG system/NN |
| VB+ RP | Boot/VB up/RP |
| Laptop | Restaurant |
|---|---|
| black_jj model_nn | corned_jj beef_nn |
| blue_jj screen_nn | fried_jj rice_nn |
| casual_jj games_nns | black_jj vinegar_nn |
| chat_jj services_nns | chinese_jj desserts_nns |
| cooling_jj system_nn | creme_jj brulee_nn |
| windows_nnp 7_cd | sweet_jj lassi_nns |
| boot_vb up_rp | smoked_jj salmon_nn |
| shut_vbd down_rp | green_jj curry_nn |
| sound_jj card_nn | condensed_jj milk_nn |
| operating_vbg system_nn | mashed_jj potatoes_nns |
| Example No. | Grouped POS Tagged Sentence | Generic Rules |
|---|---|---|
| 4.5 | This/DT speed/nn1 is/VBZ fine/JJ. /. | nnxa VB JJa |
| 4.6 | Good/JJ price/nn1. /. | JJa nnxa |
| 4.7 | It/PRP’s/VBZ wonderful/JJ for/IN computer gaming/nn2 ./. | JJa IN nnxa |
| Rank | Generic Rules | Frequency of Occurrence |
|---|---|---|
| 1 | nnxa VB JJa | 107 |
| 2 | JJa nnxa | 103 |
| 3 | JJa IN nnxa | 22 |
| 4 | nnxa IN JJa nnxb | 14 |
| 5 | nnxa WD VB JJa | 11 |
| 6 | JJa JJb nnxa | 11 |
| 7 | nnxa IN nnxb JJa | 9 |
| 8 | nnxa JJa | 6 |
| 9 | JJa CC JJa nnxa | 3 |
| 10 | JJa TO nnxa | 2 |
| Iteration | Number of Aspect-sentiment Rules |
|---|---|
| 1 | 21 |
| 2 | 14 |
| 3 | 19 |
| 4 | 5 |
| 5 | 4 |
| 6 | 1 |
| Rule Id | Generic Rule Rank | Generic Rule | Aspect-sentiment Pair Rule (R) |
|---|---|---|---|
| R1 | 1 | nnxa VB JJa | nnxa VB JJa |
| R2 | 1 | nnxa VB JJa | nnxa VB rbxa JJa |
| R3 | 1 | nnxa VB JJa | nnxa VB JJa CC JJb |
| Rule Id | Generic Rule Rank | Generic Rule | Aspect-sentiment Pair Rule Rank | Aspect-sentiment Pair Rule (R) |
|---|---|---|---|---|
| R1 | 1 | nnxa VB JJa | 1 | nnxa VB JJa |
| R2 | 1 | nnxa VB JJa | 2 | nnxa VB rbxa JJa |
| R3 | 1 | nnxa VB JJa | 3 | nnxa VB JJa CC JJb |
| Rule Id | Generic Rule Rank | Generic Rule | Aspect Sentiment Pair Rule Rank | Aspect Sentiment Pair Rule | Aspect Sentiment Pair Template (Aspect; Intensity; Sentiment) |
|---|---|---|---|---|---|
| R1 | 1 | nnxa VB JJa | 1 | nnxa VB JJa | (nnxa ; ; JJa) |
| R2 | 1 | nnxa VB JJa | 2 | nnxa VB rbxa JJa | (nnxa ; rbxa ; JJa) |
| R3 | 1 | nnxa VB JJa | 3 | nnxa VB JJa CC JJb | (nnxa ; ; JJa), (nnxa ; ; JJb), |
| R4 | 1 | nnxa VB JJa | 4 | nnxa VB DT JJa nnxb | (nnxa nnxb; ; JJa) |
| R5 | 1 | nnxa VB JJa | 5 | nnxa VB rbxa JJa CC JJb | (nnxa ; rbxa ; JJa), (nnxa ; ; JJb) |
| R6 | 1 | nnxa VB JJa | 6 | nnxa VB JJa nnxb | (nnxa nnxb; ; JJa) |
| R7 | 1 | nnxa VB JJa | 7 | nnxa VB DT rbxa JJa | (nnxa ; rbxa ; JJa) |
| R8 | 1 | nnxa VB JJa | 8 | nnxa VB JJa TO nnxb | (nnxa nnxb; ; JJa) |
| R9 | 1 | nnxa VB JJa | 9 | nnxa VB DT JJa | (nnxa ; ; JJa) |
| R10 | 1 | nnxa VB JJa | 10 | nnxa VB rbxa JJa CC rb JJb | (nnxa ; rbxa ; JJa), (nnxa ; rbxb; JJb) |
| R11 | 1 | nnxa VB JJa | 11 | nnxa CC DT nnxb VB JJa | (nnxa ; ; JJa) , (nnxb ; ; JJa) |
| R12 | 1 | nnxa VB JJa | 12 | nnxa CC nnxb VB DT JJa | (nnxa ; ; JJa) , (nnxb ; ; JJa) |
| R13 | 1 | nnxa VB JJa | 13 | nnxa CC nnxb VB rbxa JJa | (nnxa ; rbxa ; JJa) , (nnxb ; rbxa ; JJa) |
| R14 | 1 | nnxa VB JJa | 14 | nnxa VB DT JJa CC JJb | (nnxa ; ; JJa), (nnxa ; ; JJb) |
| R15 | 1 | nnxa VB JJa | 15 | nnxa VB rbxa JJa TO nnxb | (nnxa nnxb; rbxa; JJa) |
| R16 | 1 | nnxa VB JJa | 16 | nnxa VB rbxa DT JJa | (nnxa ; rbxa ; JJa) |
| R17 | 1 | nnxa VB JJa | 17 | nnxa VB rbxa JJa nnxb | (nnxa nnxb; rbxa; JJa) |
| R18 | 2 | JJa nnxa | 1 | JJa nnxa | (nnxa; ; JJa) |
| R19 | 2 | JJa nnxa | 2 | rbxa JJa nnxa | (nnxa; rbxa ; JJa) |
| R20 | 2 | JJa nnxa | 3 | JJa nnxa IN nnxb | (nnxa IN nnxb; ; JJa) |
| R21 | 2 | JJa nnxa | 4 | JJa nnxa IN DT nnxb | (nnxa IN nnxb; ; JJa) |
| R22 | 2 | JJa nnxa | 5 | JJa nnxa IN PR nnxb | (nnxa IN nnxb; ; JJa) |
| R23 | 2 | JJa nnxa | 6 | JJa nnxa CC nnxb | (nnxa; ; JJa), (nnxb; ; JJa) |
| R24 | 2 | JJa nnxa | 7 | JJa nnxa CC nnxb CC nnxc | (nnxa; ; JJa), (nnxb; ; JJa) ,(nnxc; ; JJa) |
| R25 | 2 | JJa nnxa | 8 | JJa nnxa IN nnxb CC nnxc rbxa DT JJa nnxa | (nnxa IN nnxb; ; JJa), (nnxa IN nnxc; ; JJa) |
| R26 | 2 | JJa nnxa | 9 | nnxa VB JJa IN DT nnxb | (nnxa; rbxa ; JJa) |
| R27 | 3 | JJa IN nnxa | 1 | JJa IN nnxa | (nnxa IN nnxb; ; JJa) |
| R28 | 3 | JJa IN nnxa | 2 | nnxa JJa IN nnxb | (nnxa; ; JJa ) |
| R29 | 3 | JJa IN nnxb | 3 | rbxa JJa IN nnxa | (nnxa IN nnxb; ; JJa) |
| R30 | 3 | JJa IN nnxb | 4 | nnxa VB rbxa JJa IN nnxb CC nnxc | (nnxa; rbxa; JJa) |
| R31 | 3 | JJa IN nnxb | 5 | nnxa VB rbxa JJa IN DT nnxb | (nnxa IN nnxb; rbxa; JJa), (nnxa IN nnxc; rbxa; JJa) |
| R32 | 3 | JJa IN nnxb | 6 | nnxa VB rbxa JJa IN DT nnxb | (nnxa IN nnxb; rbxa; JJa) |
| R33 | 3 | JJa IN nnxb | 7 | nnxa rbxa JJa IN DT nnxb | (nnxa IN nnxb; rbxa; JJa) |
| R34 | 3 | JJa IN nnxb | 8 | nnxa VB rbxa JJa IN nnxb | (nnxa IN nnxb; rbxa; JJa) |
| R35 | 3 | JJa IN nnxb | 9 | nnxa rbxa JJa IN nnxb | (nnxa IN nnxb; rbxa; JJa) |
| R36 | 3 | JJa IN nnxb | 10 | nnxa VB JJa IN nnxb | (nnxa IN nnxb; ; JJa) |
| R37 | 3 | JJa IN nnxa | 11 | rbxa JJa IN DT nnxa | (nnxa; rbxa; JJa ) |
| R38 | 3 | JJa IN nnxa | 12 | rbxa JJa IN PR nnxa | (nnxa; rbxa; JJa ) |
| R39 | 3 | JJa IN nnxa | 13 | rbxa JJa nnxa IN nnxb | (nnxa IN nnxb; rbxa; JJa) |
| R40 | 3 | JJa IN nnxb | 14 | JJa IN DT nnxa | (nnxa; ; JJa ) |
| R41 | 4 | nnxa IN JJa nnxb | 1 | nnxa IN JJa nnxb | (nnxa IN nnxb; ; JJa) |
| R42 | 4 | nnxa IN JJa nnxb | 2 | nnxa IN DT JJa nnxb | (nnxa IN nnxb; ; JJa) |
| R43 | 4 | nnxa IN JJa nnxb | 3 | nnxa IN rbxa JJa nnxb | (nnxa IN nnxb; rbxa ; JJa) |
| R44 | 5 | nnxa WD VB JJa | 1 | nnxa WD VB DT JJa nnxb | (nnxa nnxb; ; JJa) |
| R45 | 5 | nnxa WD VB JJa | 2 | nnxa WD VB rbxa JJa | (nnxa ; rbxa ; JJa) |
| R46 | 5 | nnxa WD VB JJa | 3 | nnxa WD VB JJa | (nnxa ; ; JJa) |
| R47 | 5 | nnxa WD VB JJa | 4 | nnxa WD VB IN DT nnxb VB rbxa JJa | (nnxa IN nnxb; rbxa; JJa) |
| R48 | 5 | nnxa WD VB JJa | 5 | nnxa WD VB IN DT JJa | (nnxa ; ; JJa) |
| R49 | 5 | nnxa WD VB JJa | 6 | nnxa WD VB IN JJa nnxb | (nnxa IN nnxb; ; JJa) |
| R50 | 5 | nnxa WD VB JJa | 7 | nnxa WDT VB JJa JJb nnxb | (nnxa nnxb; ; JJa), (nnxa nnxb; ; JJb) |
| R51 | 5 | nnxa WD VB JJa | 8 | nnxa WD VB IN JJa | (nnxa ; ; JJa) |
| R52 | 6 | JJa JJb nnxa | 1 | JJa JJb nnxa | nnxa; ; JJa), (nnxa; ; JJb) |
| R53 | 6 | JJa JJb nnxa | 2 | rbxa DT JJa JJb nnxa | (nnxa; rbxa; JJa), (nnxa; ; JJb) |
| R54 | 7 | nnxa IN nnxb JJa | 1 | nnxa IN DT nnxb VB rbxa JJa | (nnxa IN nnxb; rbxa; JJa) |
| R55 | 7 | nnxa IN nnxb JJa | 2 | nnxa IN DT nnxb VB JJa | (nnxa IN nnxb; ; JJa) |
| R56 | 7 | nnxa IN nnxb JJa | 3 | nnxa IN nnxb VB rbxa DT JJa | (nnxa IN nnxb; rbxa; JJa) |
| R57 | 7 | nnxa IN nnxb JJa | 4 | nnxa IN nnxb rbxa VB JJa | (nnxa IN nnxb; rbxa; JJa) |
| R58 | 8 | nnxa JJa | 1 | nnxa rbxa JJa | (nnxa; rbxa ; JJa) |
| R59 | 8 | nnxa JJa | 2 | nnxa JJa | (nnxa; ; JJa) |
| R60 | 9 | JJa CC JJb nnxa | 1 | JJa CC JJb nnxa | (nnxa; ; JJa), (nnxa; ; JJb) |
| R61 | 9 | JJa CC JJb nnxa | 2 | rbxa JJ a CC JJb nnxa | (nnxa; rbxa; JJa), (nnxa; ; JJb) |
| R62 | 10 | JJ a TO nnxa | 1 | rbxa JJa TO nnxa | (nnxa; rbxa ; JJa) |
| R63 | 10 | JJ a TO nnxa | 2 | JJa TO nnxa | (nnxa; ; JJa) |
| Grouped POS Tagged Sentence | Generic Rule Rank | Generic Rule | Matching |
|---|---|---|---|
| DT nn2 VBD rb1 JJ IN rb1 | 1 | nnxa VB JJa | Match |
| DT nn2 VBD rb1 JJ IN rb1 | 2 | JJa nnxa | No match |
| DT nn2 VBD rb1 JJ IN rb1 | 3 | JJa IN nnxa | No match |
| DT nn2 VBD rb1 JJ IN rb1 | 4 | nnxa IN JJa nnxb | No match |
| DT nn2 VBD rb1 JJ IN rb1 | 5 | nnxa WD VB JJa | No match |
| DT nn2 VBD rb1 JJ IN rb1 | 6 | JJa JJb nnxa | No match |
| DT nn2 VBD rb1 JJ IN rb1 | 7 | nnxa IN nnxb JJa | No match |
| DT nn2 VBD rb1 JJ IN rb1 | 8 | nnxa JJa | Match |
| DT nn2 VBD rb1 JJ IN rb1 | 9 | JJa CC JJb nnxa | No match |
| DT nn2 VBD rb1 JJ IN rb1 | 10 | JJa TO nnxa | No match |
| Domain | Training Dataset | Training Dataset Used | Testing Dataset | Testing Dataset Used |
|---|---|---|---|---|
| Laptop | 3041 | 250 | 800 | 63 |
| Restaurant | 3045 | - | 800 | 63 |
| Total | 6086 | 250 | 1600 | 126 |
| No. | Example of Testing Sentence | Approach | ||
|---|---|---|---|---|
| BE Baseline | ASPER | ASPERC | ||
| 1 | Set up was easy | No | No | Yes |
| 2 | MS Office 2011 for Mac is wonderful | No | Yes | Yes |
| 3 | But the Mountain lion is just too slow | No | Yes | Yes |
| 4 | I was extremely happy with the OS itself | No | Yes | Yes |
| 5 | The specs are pretty good too | Yes | Yes | Yes |
| 6 | The technical support was not helpful as well. | No | No | Yes |
| 7 | Greatproduct | Yes | Yes | Yes |
| 8 | Customization on Mac is impossible | No | Yes | Yes |
| 9 | Excellentdurability of battery | No | Yes | Yes |
| 10 | GreatAsian salad | Yes | Yes | Yes |
| 11 | Great and attentive staff | Yes | Yes | Yes |
| 12 | Their twist on a pizza is healthy | No | Yes | Yes |
| 13 | Definitely try the taglierini with truffles it was incredible | No | Yes | Yes |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahamed Kabeer, N.R.; Gan, K.H.; Haris, E. Domain-Specific Aspect-Sentiment Pair Extraction Using Rules and Compound Noun Lexicon for Customer Reviews. Informatics 2018, 5, 45. https://doi.org/10.3390/informatics5040045
Ahamed Kabeer NR, Gan KH, Haris E. Domain-Specific Aspect-Sentiment Pair Extraction Using Rules and Compound Noun Lexicon for Customer Reviews. Informatics. 2018; 5(4):45. https://doi.org/10.3390/informatics5040045
Chicago/Turabian StyleAhamed Kabeer, Noor Rizvana, Keng Hoon Gan, and Erum Haris. 2018. "Domain-Specific Aspect-Sentiment Pair Extraction Using Rules and Compound Noun Lexicon for Customer Reviews" Informatics 5, no. 4: 45. https://doi.org/10.3390/informatics5040045
APA StyleAhamed Kabeer, N. R., Gan, K. H., & Haris, E. (2018). Domain-Specific Aspect-Sentiment Pair Extraction Using Rules and Compound Noun Lexicon for Customer Reviews. Informatics, 5(4), 45. https://doi.org/10.3390/informatics5040045