Misalignment Detection for Web-Scraped Corpora: A Supervised Regression Approach

Abstract
:1. Introduction
2. Materials and Methods
2.1. Labeled Dataset
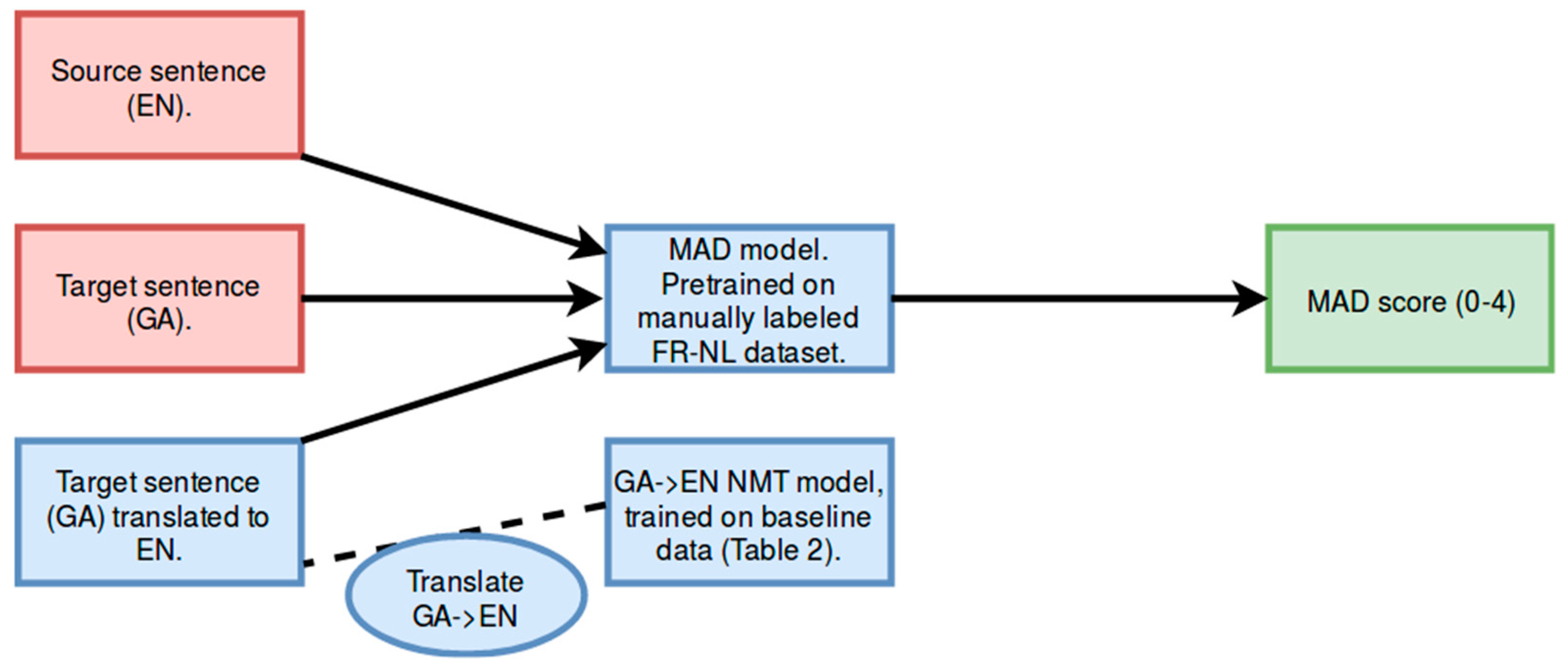
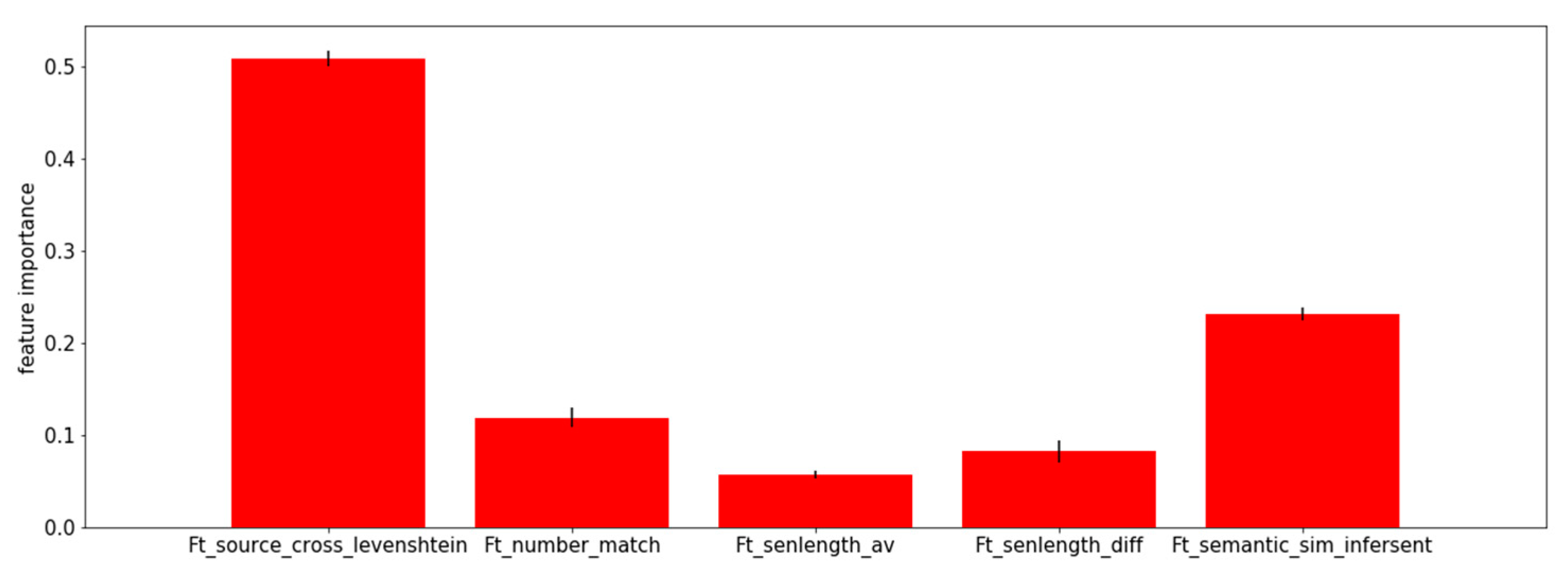
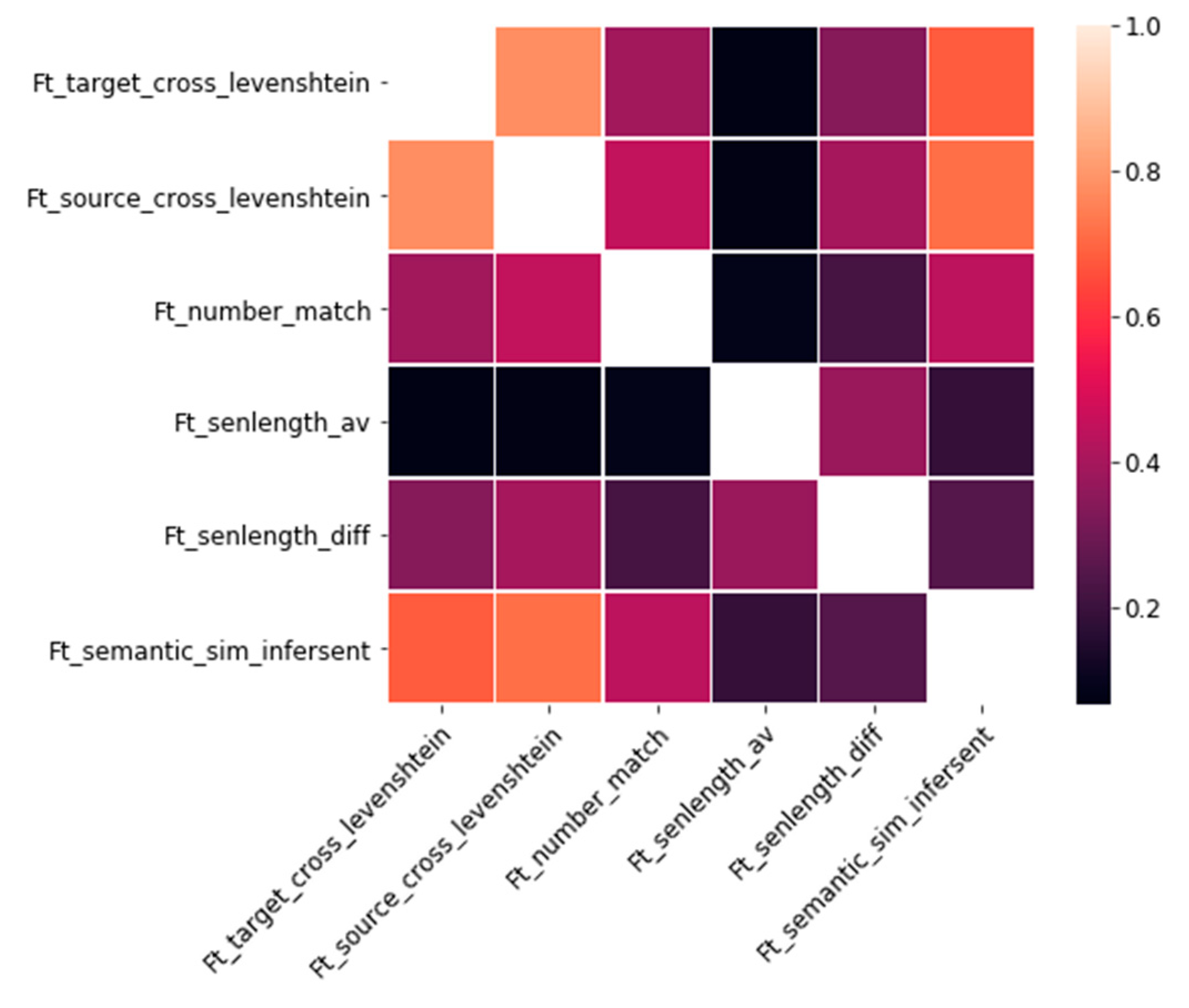
2.2. Features
- Ft_senlength_av: Average sentence length (in characters) of the S-T sentence pair.
- Ft_senlength_diff: Absolute difference among sentence length of S and T (in characters).
- Ft_number_match: Hand-crafted hard rule score between −1 and 1. Equal to 0 if S and T do not contain numbers; and closer to −1 or 1 if there is a big mismatch, respectively match among the detected numbers in S and T. For more details we refer to Appendix A.
- Ft_source_cross_levenshtein: Levenshtein distance between the target sentence T and the translation of the source sentence S in the target language.
- Ft_semantic_sim_infersent: Cosine similarity between the sentence embedding of the source and target sentences translated into English. Sentence embeddings are calculated using a pre-trained sentence encoder, InferSent (https://github.com/facebookresearch/InferSent), trained with fastText (https://github.com/facebookresearch/fastText). InferSent is a sentence embeddings method that provides semantic representations for English sentences. For more information about the sentence encoder we refer to Conneau et al. [21].
2.3. Supervised Regression
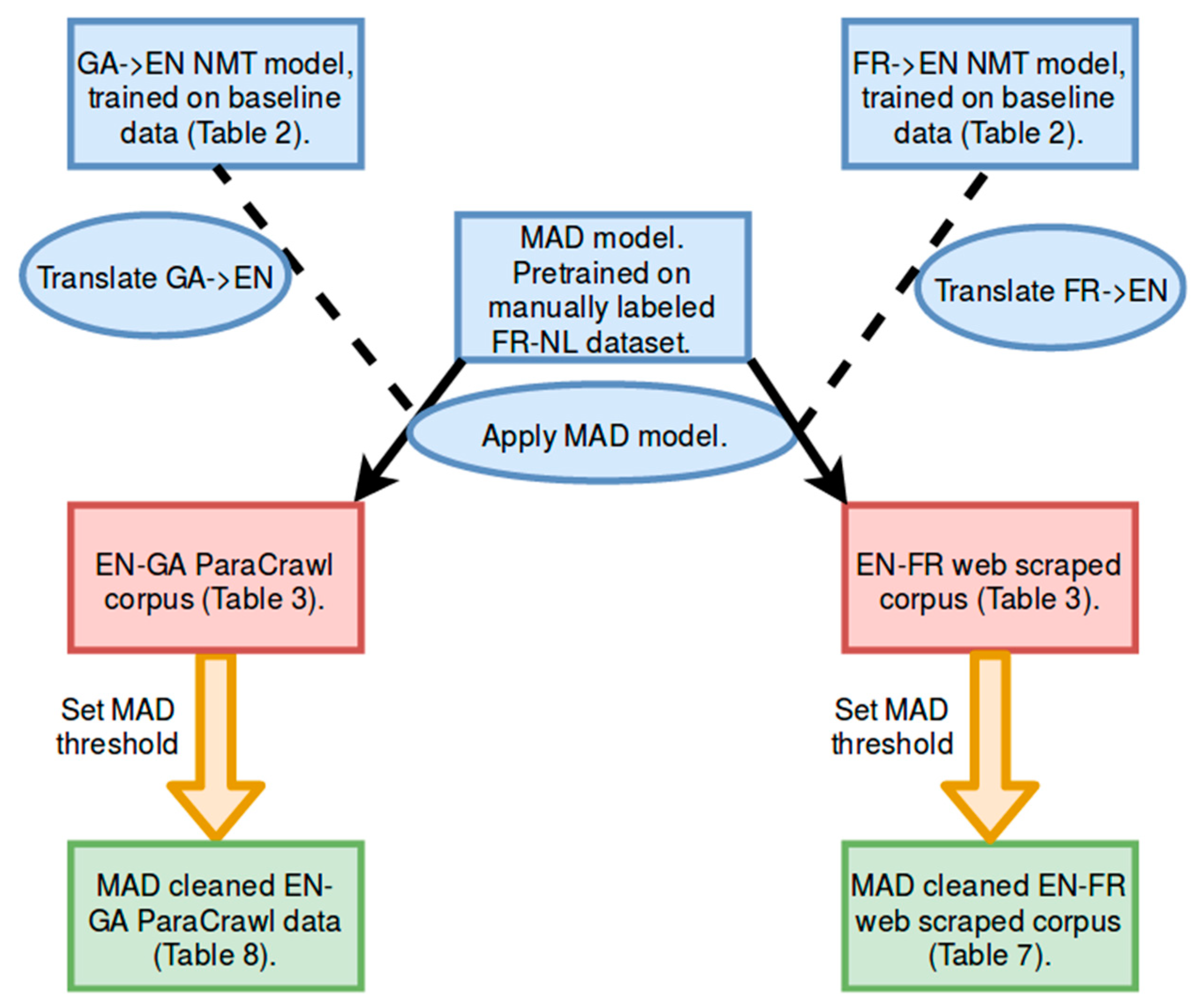
2.4. Data for Machine Translation
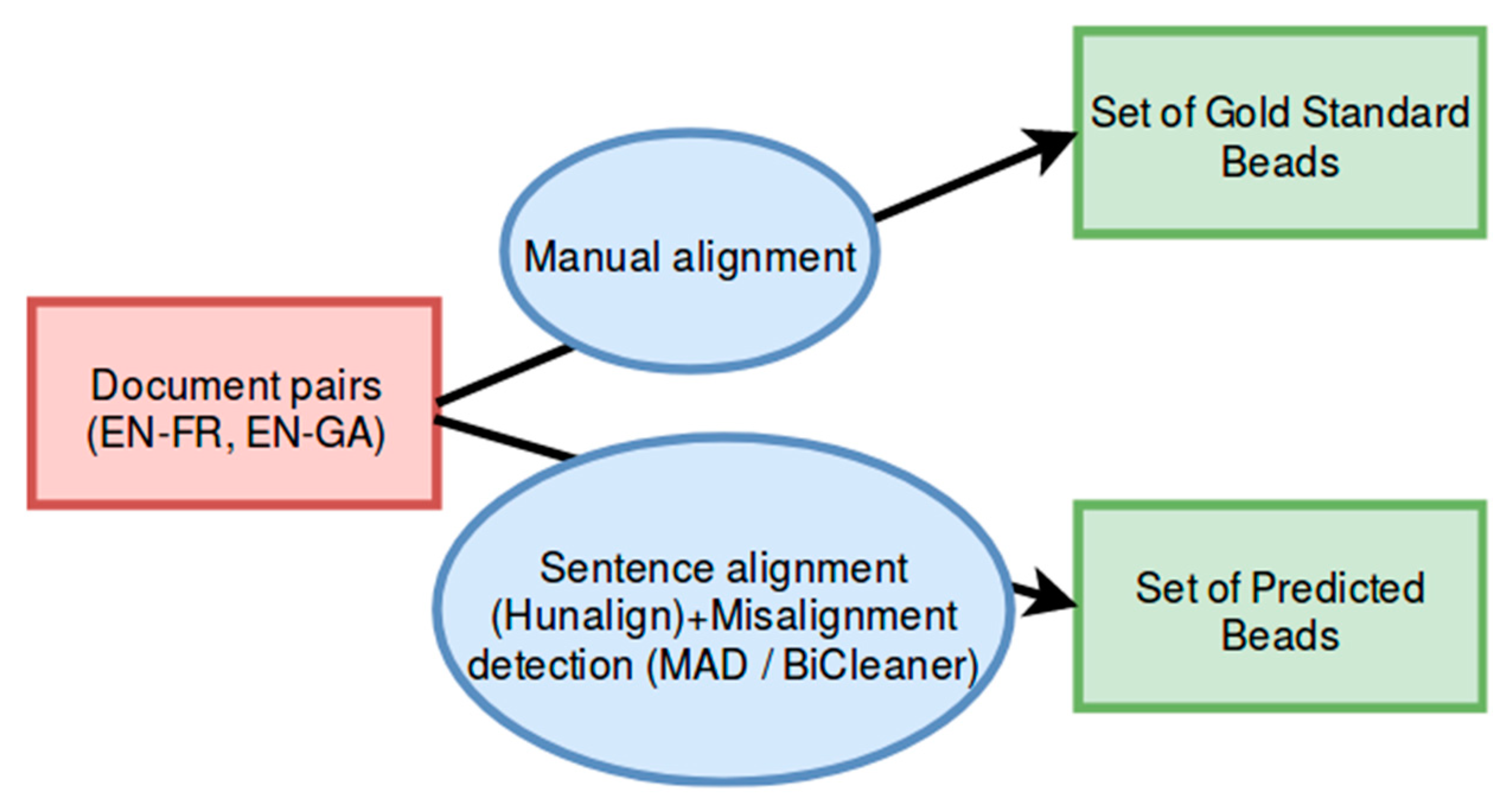
2.5. Gold Standard for Sentence Alignment
- Source: Payment can be made in person. However, the office should be contacted beforehand.
- Target: Le versement peut être effectué en personne, mais le bureau doit être contacté en avance.
- Source: Payment can be made in person.
- Target: Le versement peut être effectué en personne.
- Source: However, the office should be contacted beforehand.
- Target: Toutefois, le bureau doit être contacté en avance.
2.6. BiCleaner
3. Results
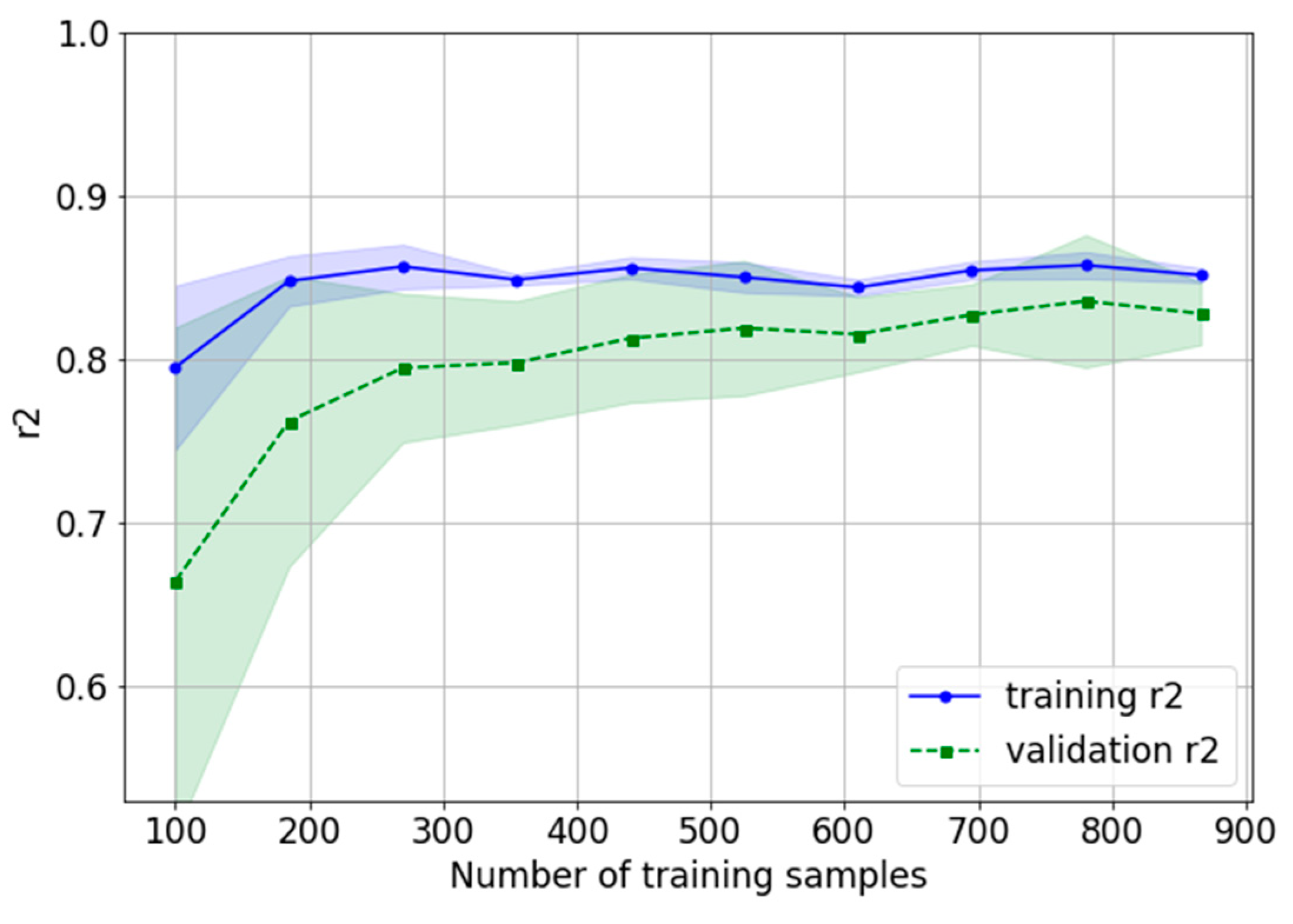
3.1. Machine Learning Pipeline
3.2. Intrinsic Evaluation
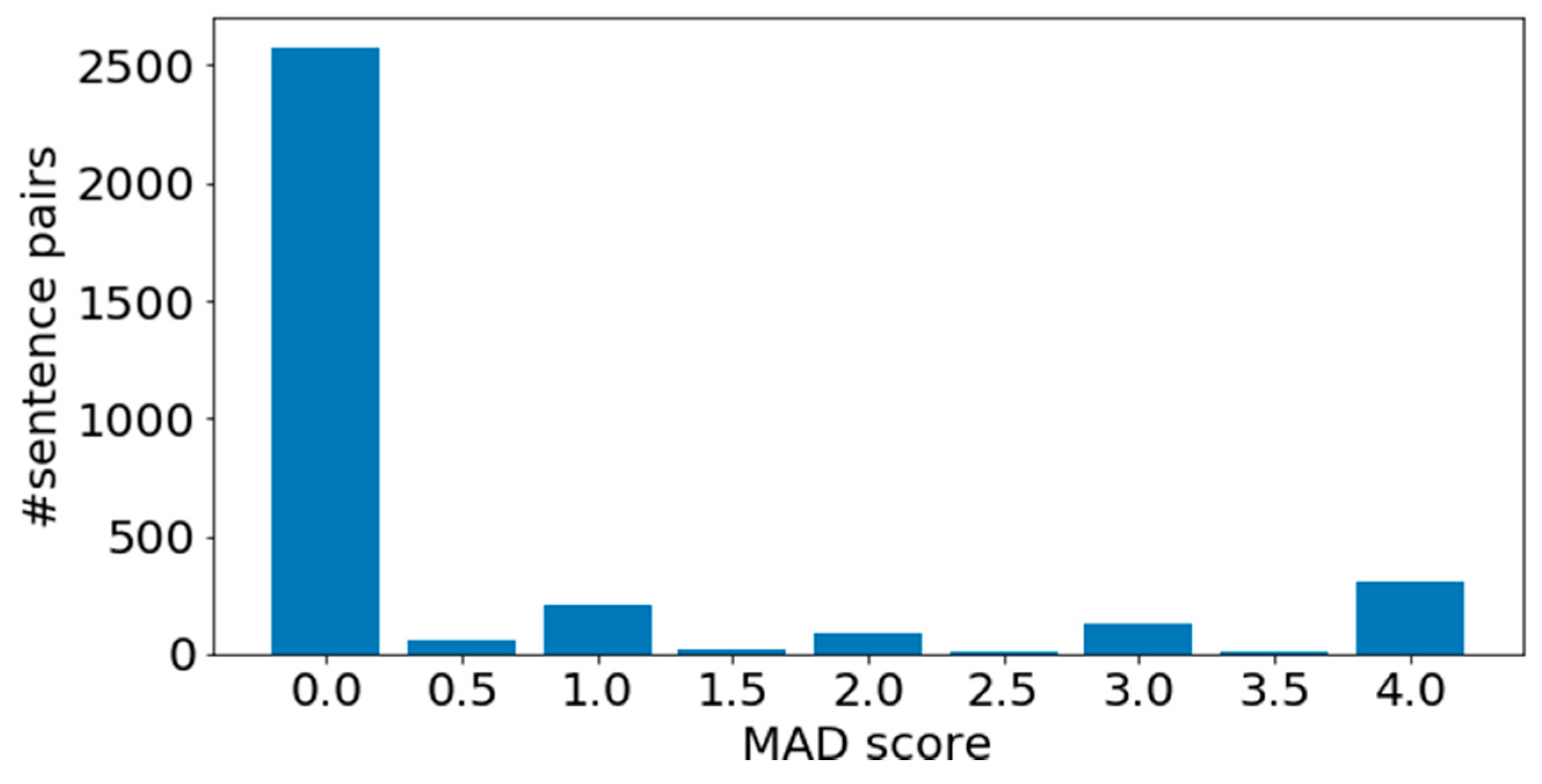
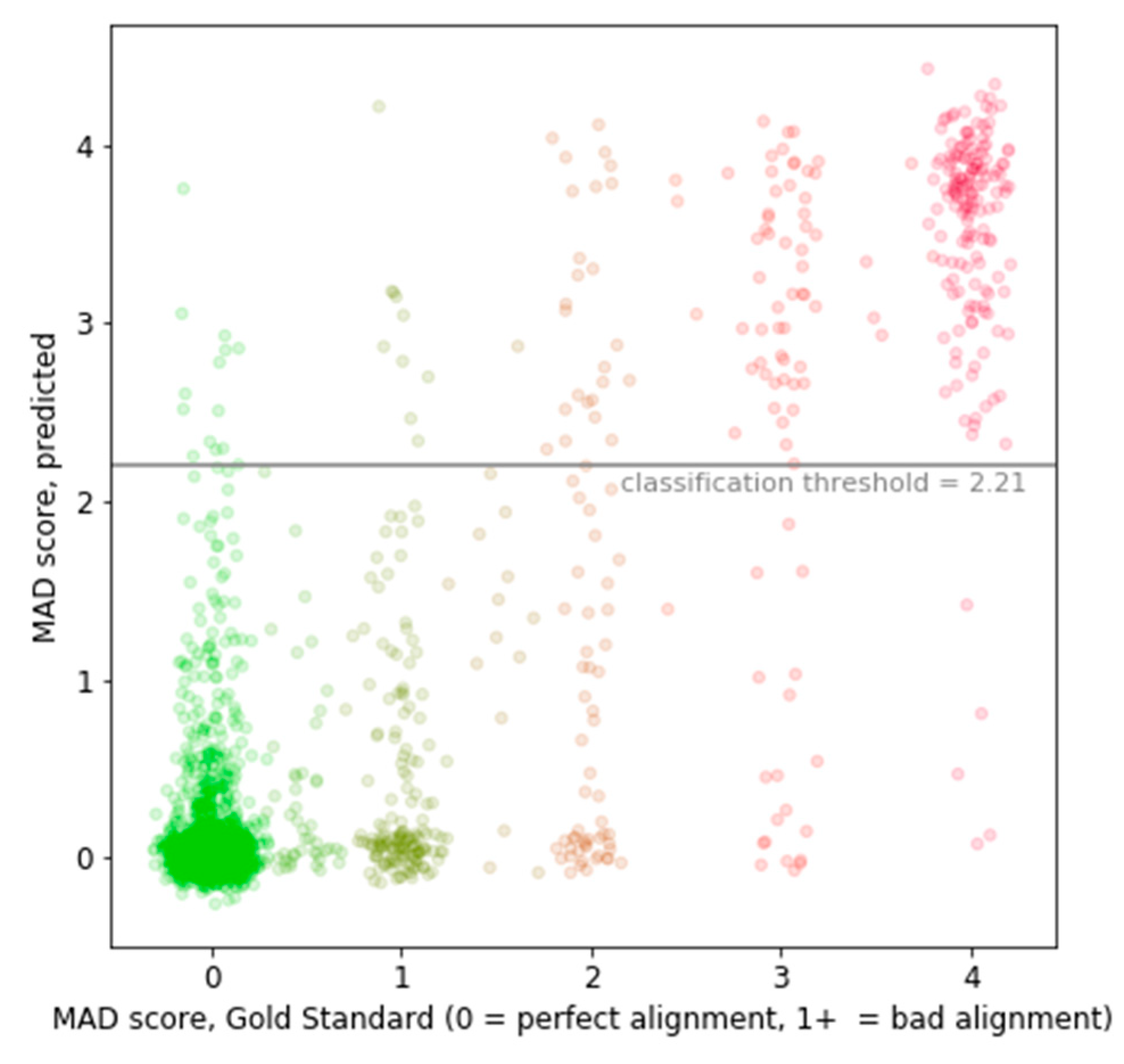
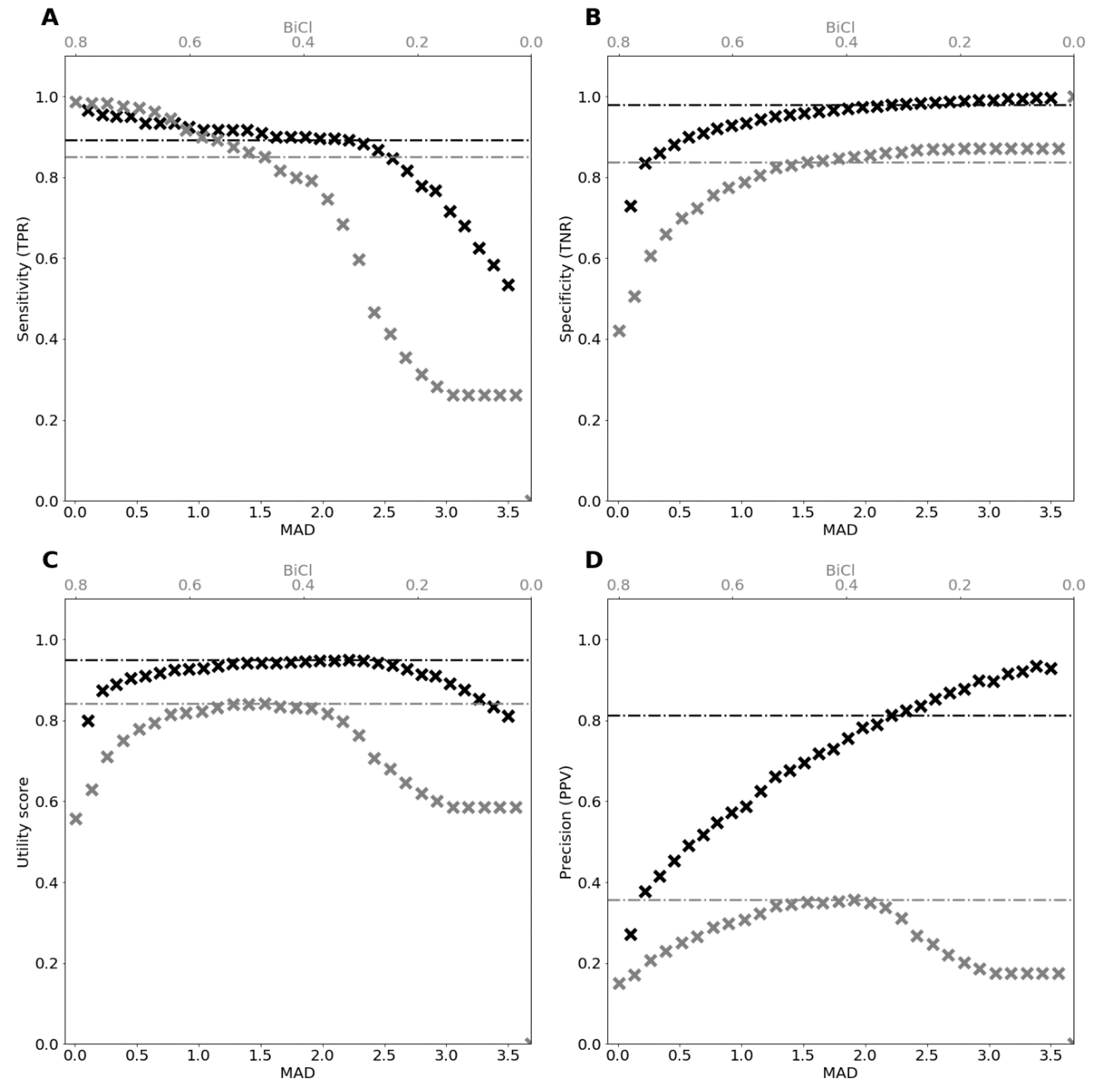
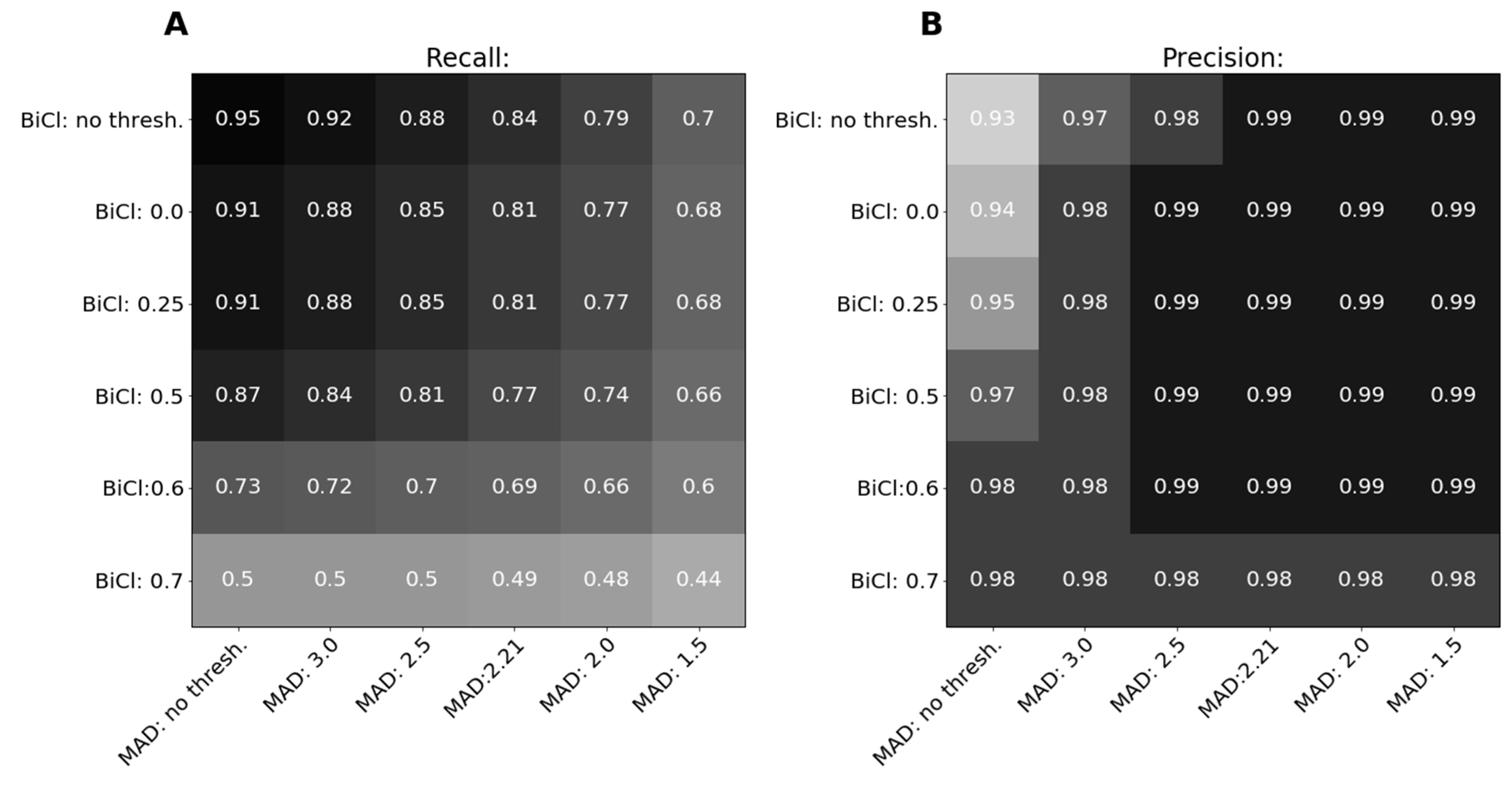
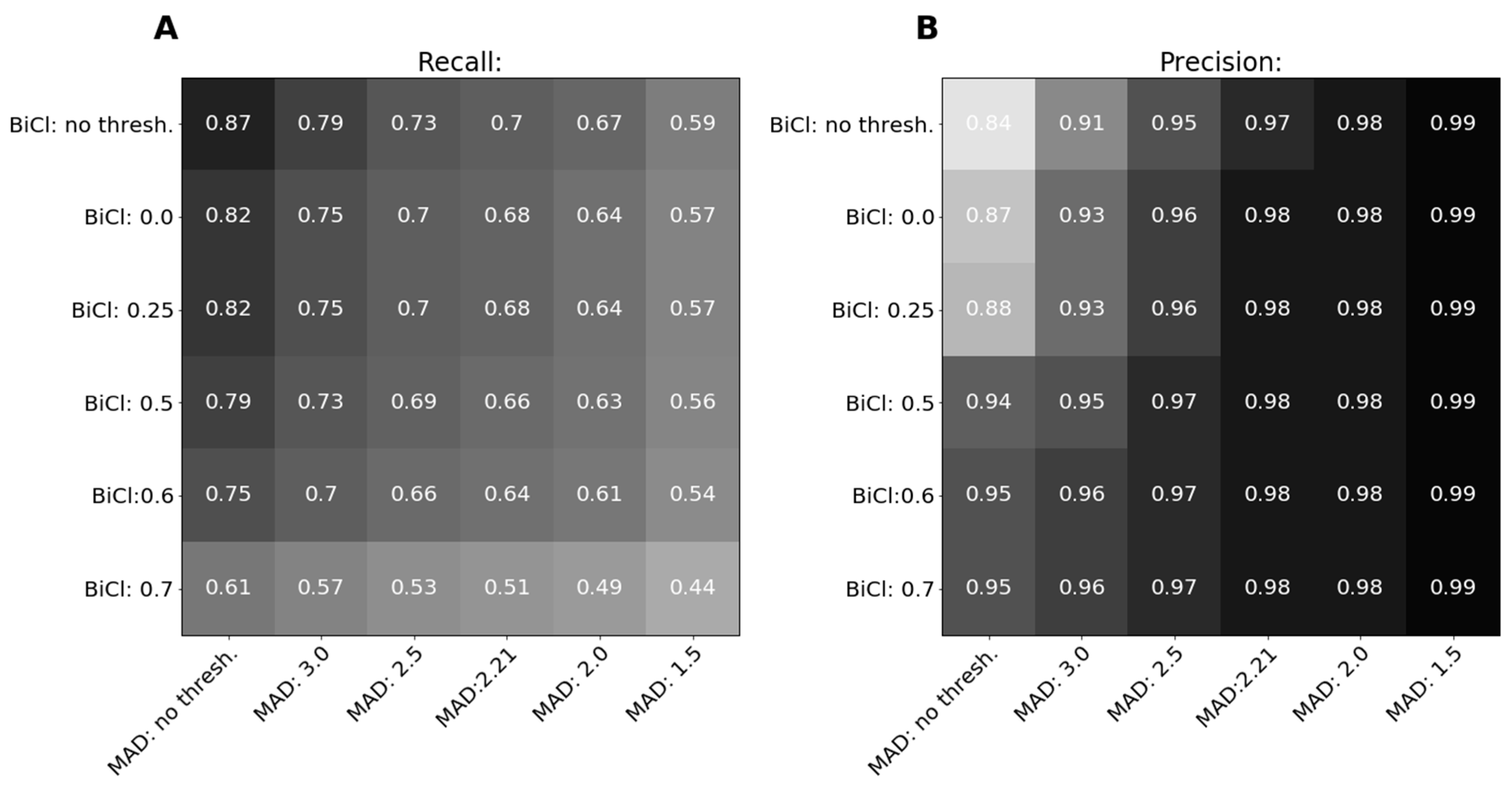
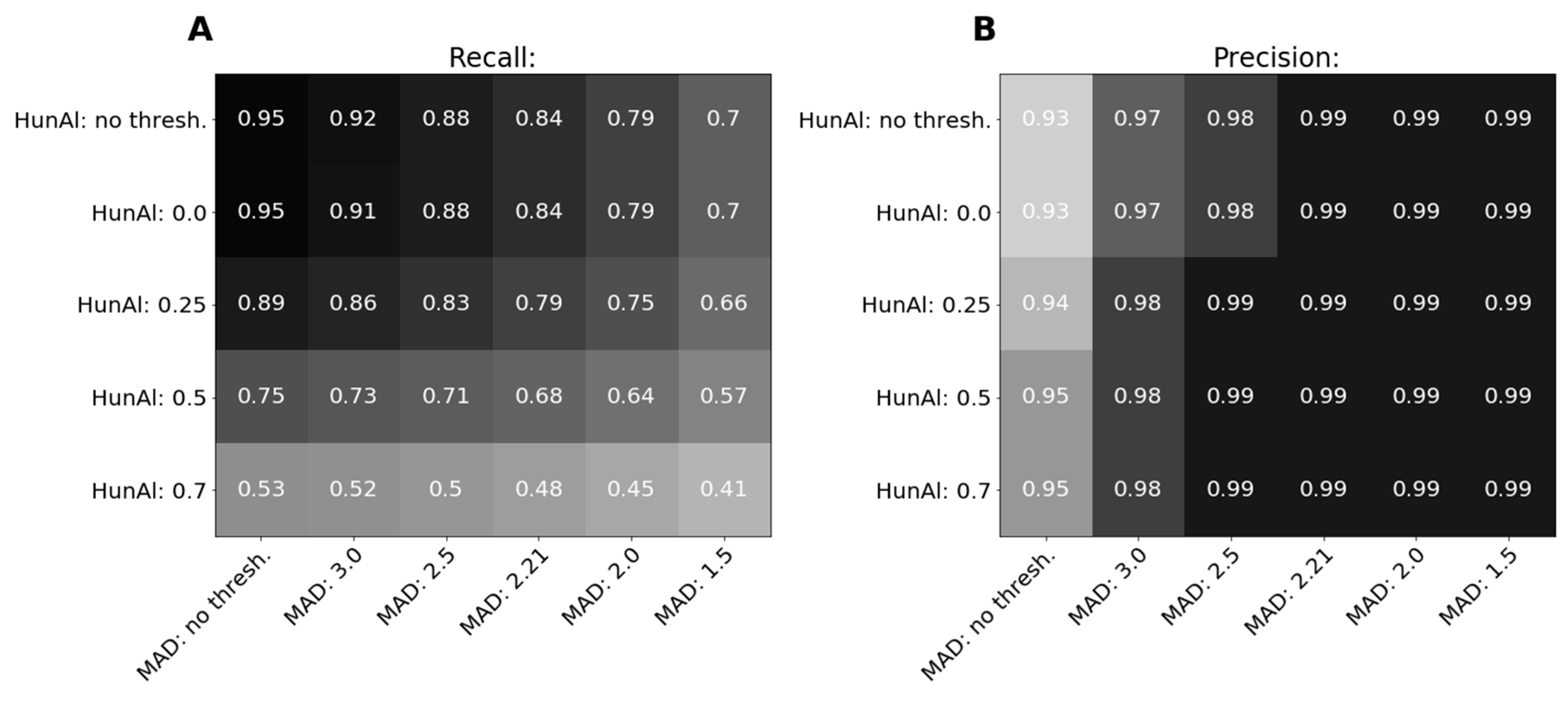
3.2.1. Intrinsic Evaluation on the Gold Standard for Misalignment Detection
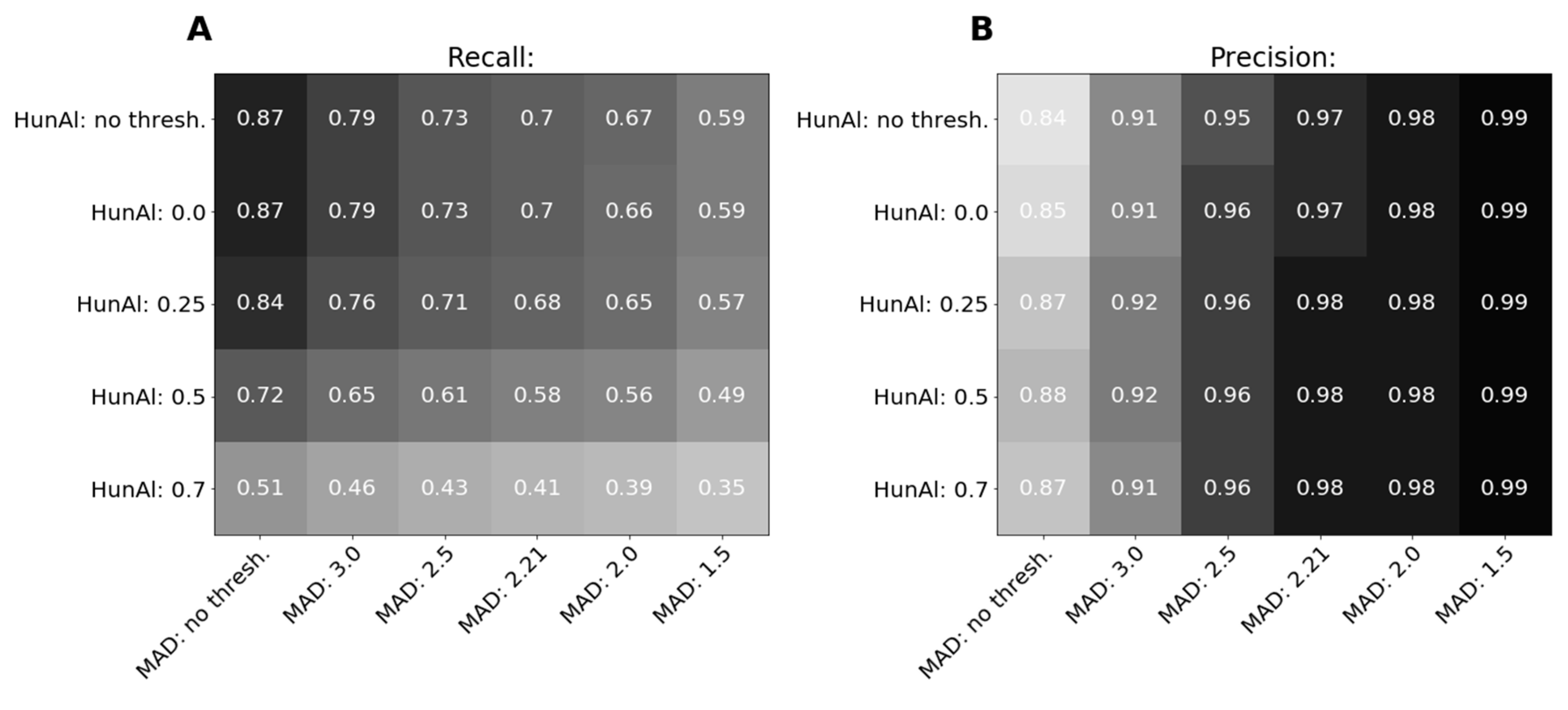
3.2.2. Intrinsic Evaluation on Gold Standards for Alignment
3.3. Extrinsic Evaluation
4. Discussion
Author Contributions
Funding
Conflicts of Interest
Appendix A
| Algorithm A1. Pseudo-code to calculate the feature Ft_number_match. |
| def get_numbers(sentence): |
| ‘Function that returns a set containing all the unique numbers in a given sentence.’ |
| return set_numbers |
| def get_size(set): |
| ‘Function that returns the amount of numbers in a given set.’ |
| return size |
| def calculate_ft_number_match(source_sentence, target_sentence) |
| ‘Function that calculates Ft_number_match given a source and target sentence.’ |
| set_numbers_source=get_numbers(source_sentence) |
| set_numbers_target=get_numbers(target_sentence) |
| ‘Calculate total amount of numbers in source and target sentence.’ |
| total_number=size(set_numbers_source)+size(set_numbers_target) |
| ‘Calculate size of symmetric difference, union and intersection of the set of numbers in source and target sentence:’ |
| num_symdiff=size(symmetric_difference(set_numbers_source, set_numbers_target)) |
| num_union=size(union(set_numbers_source, set_numbers_target)) |
| num_intersect=size(intersection(set_numbers_source, set_numbers_target)) |
| ‘Calculate the number match score:’ |
| if total_numbers==0: |
| score=0.0 |
| else if total_numbers!=0 and num_symdiff==0: |
| score=round(1.0-(1.0+num_union)**(-0.3333),2) |
| else if total_numbers >1 and num_symdiff >=1: |
| score=-(num_symdiff - num_intersect)/num_union |
| return score |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source Sentence | Target Sentence | Ft_Number_Match |
|---|---|---|
| I was born on the 4th of May. | I was born on the 5th of May. | −1.00 |
| I was born on the 4th of May. | I was born on the 4th of May. | 0.21 |
| I was born on the 4th of May. I have 2 sisters. | I was born on the 4th of May. I have 2 sisters. | 0.31 |
| I was born on the 4th of May. I have 5 sisters. | I was born on the 4th of May. I have 2 sisters. | −0.33 |
Appendix B
| Domain/Url EN–FR | Description | # Unique Sentence Pairs | # Tokens (EN) |
|---|---|---|---|
| https://e-justice.europa.eu | European e-justice portal | 50,884 | 1,376,827 |
| laws-lois.justice.gc.ca | Consolidated Acts and regulations | 66,346 | 2,300,404 |
| http://justice.gc.ca | Department of Justice | 142,458 | 3,571,748 |
| www.noscommunes.ca | House of commons | 1,042,797 | 23,074,752 |
| https://sencanada.ca | Senate | 123,570 | 2,802,562 |
| www.legifrance.gouv.fr | Government entity responsible for publishing legal texts online | 25,321 | 827,434 |
| www.oecd.org | Org. for Economic Co-operation and Development. | 21,511 | 571,287 |
| Total (deduplicated) | 1,472,511 | 34,520,231 |
Appendix C

Appendix D


References
- Goutte, C.; Carpaut, M.; Foster, G. The impact of Sentence Alignment Errors on Phrase-Based Machine Translation Performance. In Proceedings of the Tenth Biennial Conference of the Association for Machine Translation in the Americas, San Diego, CA, USA, 28 October–1 November 2012. [Google Scholar]
- Chen, B.; Kuhn, R.; Foster, G.; Cherry, C.; Huang, F. Bilingual Methods for Adaptive Training Data Selection for Machine Translation. In Proceedings of the 12th Conference of the Association for Machine Translation in the Americas (AMTA), Austin, TX, USA, 29 October–2 November 2016; p. 93. [Google Scholar]
- Belinkov, Y.; Bisk, Y. Synthetic and Natural Noise Both Break Neural Machine Translation. CoRR 2016, arXiv:abs/1711.02173. [Google Scholar]
- Khayrallah, H.; Koehn, P. On the Impact of Various Types of Noise on Neural Machine Translation. arXiv 2018, arXiv:1805.12282. [Google Scholar]
- Lamraoui, F.; Langlais, P. Yet Another Fast and Open Source Sentence Aligner. Time to Reconsider Sentence Alignment? In Proceedings of the Machine Translation Summit XIV, Nice, France, 2–6 September 2013; pp. 77–84. [Google Scholar]
- Munteanu, D.S.; Marcu, D. Improving Machine Translation Performance by Exploiting Non-Parallel Corpora. Comput. Linguist. 2005, 31, 477–504. [Google Scholar] [CrossRef]
- Etchegoyhen, T.; Azpeitia, A. Set-Theoretic Alignment for Comparable Corpora. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12, August 2016; pp. 2009–2018. [Google Scholar]
- Abdul-Rauf, S.; Schwenk, H. On the Use of Comparable Corpora to Improve SMT performance. In Proceedings of the 12th Conference of the European Chapter of the ACL (EACL 2009), Athens, Greece, 30 March–3 April 2009; pp. 16–23. [Google Scholar]
- España-Bonet, C.; Csaba Varga, A.; Barrón-Cedeño, A.; van Genabith, J. An Empirical Analysis of NMT-Derived Interlingual Embeddings and their Use in Parallel Sentence Identification. IEEE J. Sel. Top. Signal Process. 2017, 11, 1340–1350. [Google Scholar] [CrossRef]
- Grégoire, F.; Langlais, P. A First Attempt Toward a Deep Learning Framework for Identifying Parallel Sentences in Comparable Corpora. In Proceedings of the 10th Workshop on Building and Using Comparable Corpora, Vancouver, Canada, 3 August 2017; pp. 46–50. [Google Scholar]
- Carpuat, M.; Vyas, Y.; Niu, X. Detecting Cross-lingual Semantic Divergence for Neural Machine Translation. In Proceedings of the First Workshop on Neural Machine Translation, Vancouver, Canada, 30 July–4 August 2017; pp. 69–79. [Google Scholar]
- Grégoire, F.; Langlais, P. Extracting Parallel Sentences with Bidirectional Recurrent Neural Networks to Improve Machine Translation. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 21–25 August 2018; pp. 1442–1453. [Google Scholar]
- Schwenk, H. Filtering and Mining Parallel Data in a Joint Multilingual Space. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Volume 2, pp. 228–234. [Google Scholar]
- Vyas, Y.; Niu, X.; Carpuat, M. Identifying Semantic Divergences in Parallel Text without Annotations. In Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies ACL, New Orleans, LA, USA, 1–6 June 2018; Volume 1, pp. 1503–1515. [Google Scholar]
- Bouamor, H.; Sajjad, H. Parallel Sentence Extraction from Comparable Corpora using Multilingual Sentence Embeddings. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Hassan, H.; Aue, A.; Chen, C.; Chowdhary, V.; Clark, J.; Federmann, C.; Huang, X.; Junczys-Dowmunt, M.; Lewis, W.; Li, M.; et al. Achieving Human Parity on Automatic Chinese to English Translation. arXiv 2018, arXiv:1803.05567. [Google Scholar]
- Pham, M.; Crego, J.; Senellart, J.; Yvon, F. Fixing Translation Divergences in Parallel Corpora for Neural MT. In Proceedings of the 2018 Conference on Emperical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2967–2973. [Google Scholar]
- Artetxe, M.; Schwenk, H. Margin-Based Parallel Corpus Mining with Multilingual Sentence Embeddings. arXiv 2018, arXiv:1811.01136. [Google Scholar]
- Guo, M.; Shen, Q.; Yang, Y.; Ge, H.; Cer, D.; Hernandez Abrego, G.; Stevens, K.; Constant, N.; Sung, Y.; Strope, B.; et al. Effective Parallel Corpus Mining using Bilingual Sentence Embeddings. In Proceedings of the Third Conference on Machine Translation (WMT), Brussels, Belgium, 31 October–1 November 2018; Volume 1, pp. 165–176. [Google Scholar]
- Sánchez-Cartagena, V.M.; Bañón, M.; Sergio Ortiz-Rojas, S.; Ramírez-Sánchez, G. Prompsit’s Submission to WMT 2018 Parallel Corpus Filtering Shared Task. In Proceedings of the Third Conference on Machine Translation (WMT), Brussels, Belgium, 31 October–1 November 2018; Volume 2, pp. 955–962. [Google Scholar]
- Conneau, A.; Kiela, D.; Schwenk, H.; Barrault, L.; Bordes, A. Supervised Learning of Universal Sentence Representations from Natural Language Inference Data. In Proceedings of the 2017 Conference on Emperical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 670–980. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, O.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Klein, G.; Kim, Y.; Deng, Y.; Senellart, J.; Rush, A.M. OpenNMT: Open-Source Toolkit for Neural Machine Translation. arXiv 2017, arXiv:1701.02810. [Google Scholar] [Green Version]
- Varga, D.; Németh, L.; Halácsy, P.; Kornai, A.; Trón, V.; Nagy, V. Parallel Corpora for Medium Density Languages. In Proceedings of the RANLP, Borovets, Bulgaria, 21–23 September 2005; pp. 590–596. [Google Scholar]
- Defauw, A.; Vanallemeersch, T.; Szoc, S.; Everaert, F.; Van Winckel, K.; Scholte, K.; Brabers, J.; Van den Bogaert, J. Collecting Domain Specific Data for MT: An Evaluation of the ParaCrawl Pipeline. In Proceedings of the Machine Translation Summit, Dublin, Ireland, 19–23 August 2019. [Google Scholar]
- Brown, P.F.; Lai, J.C.; Mercer, R.L. Aligning Sentences in Parallel Corpora. In Proceedings of the 29th Annual Meeting of the ACL, Berkeley, CA, USA, 18–21 June 1991; pp. 169–176. [Google Scholar]
- Barbu, E.; Parra Escartín, C.; Bentivogli, L.; Negri, M.; Turchi, M.; Orasan, M.F. The First Automatic Translation Memory Cleaning Shared Task. Comput. Transl. 2016, 30, 145–166. [Google Scholar] [CrossRef]
- Koehn, P.; Khayrallah, H.; Heafield, K.; Forcada, M.L. Findings of the WMT 2018 Shared Task on Parallel Corpus Filtering. In Proceedings of the Third Conference on Machine Translation (WMT), Brussels, Belgium, 31 October–1 November 2018; Volume 2, pp. 726–739. [Google Scholar]
- Zweigenbaum, P.; Sharoff, S.; Rapp, R. Overview of the Second BUCC Shared Task: Spotting Parallel Sentences in Comparable Corpora. In Proceedings of the 10th Workshop on Building and Using Comparable Corpora, Vancouver, Canada, 3 August 2017; pp. 60–67. [Google Scholar]










| MAD Score | Criteria | Example (S) | Example (T) |
|---|---|---|---|
| 0 |
| Vous avez un permis de conduire valide. (You have a valid driving license.) | U hebt een geldig rijbewijs. (You have a valid driving license.) |
| 1 |
| Vous avez un permis de conduire valide. (You have a valid driving license.) | U hebt een geldig rijbewijs. (You have a valide driving license.) |
| 2 |
| Vous avez un permis de conduire valide du FNI. (You have a valid driving license from the FNI.) | U hebt een geldig rijbewijs van de DVLA in Swansea. (You have a valid driving license from the DVLA in Swansea.) |
| 3 |
| Vous avez un permis de conduire valide ou vous êtes en train de demander une licence provisoire. (You have a valid driving license or you are applying for a temporary license.) | U hebt een geldig rijbewijs. (You have a valid driving license.) |
| 4 |
| Vous avez un permis de conduire valide. (You have a valid driving license.) | Formulier C-63 moet ingediend worden drie weken op voorhand. (Form C-63 must be submitted three weeks in advance.) |
| Corpus | EN–FR | EN–GA |
|---|---|---|
| DCEP (https://wt-public.emm4u.eu/Resources/DCEP-2013/DCEP-Download-Page.html) | 3,728,978 | 46,418 |
| DGT (http://opus.nlpl.eu/DGT.php) | 3,071,997 | 44,309 |
| ECDC (https://ec.europa.eu/jrc/en/language-technologies/ecdc-translation-memory) | 2499 | - |
| EAC (https://ec.europa.eu/jrc/en/language-technologies/eac-translation-memory) | 4476 | - |
| Eubookshop (http://opus.nlpl.eu/EUbookshop-v2.php) | - | 133,363 |
| Total (deduplicated) | 4,258,861 | 139,404 |
| Language Pair | Corpus | #Sentence Pairs |
|---|---|---|
| EN–FR | web-scraped corpus | 1,472,511 |
| EN–GA | Raw ParaCrawl corpus v4.0 | 156,189,807 |
| Type | #Sentence Pairs |
|---|---|
| EN–FR: | |
| English sentences | 723 |
| French sentences | 716 |
| 1-to-1 beads | 629 |
| Many-to-1 beads | 16 |
| 1-to-many beads | 18 |
| Many-to-many beads | 1 |
| Total number of beads used for evaluation | 664 |
| 1-to-0 beads | 35 |
| 0-to-1 beads | 32 |
| English sentences in partial links | 5 |
| French sentences in partial links | 5 |
| Total number of beads | 731 |
| EN–GA: | |
| English sentences | 746 |
| Irish sentences | 778 |
| 1-to-1 beads | 631 |
| Many-to-1 beads | 18 |
| 1-to-many beads | 19 |
| Many-to-many beads | 3 |
| Total number of beads used for evaluation | 671 |
| 1-to-0 beads | 38 |
| 0-to-1 beads | 67 |
| English sentences in partial links | 13 |
| Irish sentences in partial links | 15 |
| Total number of beads | 776 |
| Feature | F-Score | MI |
|---|---|---|
| Ft_source_cross_levenshtein | 1.00 | 1.00 |
| Ft_semantic_sim_infersent | 0.49 | 0.76 |
| Ft_number_match | 0.21 | 0.51 |
| Ft_senlength_diff | 0.10 | 0.16 |
| Ft_senlength_av | 0.01 | 0.03 |
| Type of Data (EN–FR) | BiCl Threshold | MAD Threshold | Unique Sentence Pairs | Unique Sentence Pairs Added to the Baseline | BLEU |
|---|---|---|---|---|---|
| baseline sample training data | - | - | 1000k | 0k | 40.5 |
| +web-scraped corpus (MAD) | - | 2.21 | 2118k | 1118k | 41.2 |
| +web-scraped corpus (BiCl) | 0.7 | - | 1787k | 787k | 41.0 |
| +web-scraped corpus | - | - | 2472k | 1472k | 41.5 |
| Exp nr | Type of Data (EN–GA) | BiCl Thresh. | MAD Thresh. | Unique Sentence Pairs, Total | Unique Sentence Pairs Added to the Baseline | BLEU |
|---|---|---|---|---|---|---|
| 1 | baseline training data | - | - | 133k | 0k | 25.0 |
| 2 | +ParaCrawl data (top500k MAD) | 0.0 | 2.27 | 633k | 500k | 42.9 |
| 3 | +ParaCrawl data (top 500k BiCl) | 0.76 | - | 633k | 500k | 43.2 |
| 4 | +ParaCrawl data (random 500k) | 0.0 | - | 633k | 500k | 41.8 |
| 5 | +ParaCrawl data (top 500k misaligned MAD) | 0.0 | - | 633k | 500k | 38.0 |
| 6 | +ParaCrawl data (top 600k MAD) | 0.0 | 2.80 | 733k | 600k | 43.5 |
| 7 | +ParaCrawl data (top 600k BiCl) | 0.7 | - | 733k | 600k | 43.5 |
| 8 | +ParaCrawl data (random 600k) | 0.0 | - | 733k | 600k | 42.3 |
| 9 | +ParaCrawl data (random noise) | - | - | 1367k | 1234k | 35.6 |
| 10 | +ParaCrawl data (all, BiCl score > 0.0) | 0.0 | - | 1367k | 1234k | 43.4 |
| 11 | +ParaCrawl data (top 600k MAD)+ParaCrawl data (random noise) | 0.0, - | 2.80 - | 1967k | 600k + 1234k | 41.7 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Defauw, A.; Szoc, S.; Bardadym, A.; Brabers, J.; Everaert, F.; Mijic, R.; Scholte, K.; Vanallemeersch, T.; Van Winckel, K.; Van den Bogaert, J. Misalignment Detection for Web-Scraped Corpora: A Supervised Regression Approach. Informatics 2019, 6, 35. https://doi.org/10.3390/informatics6030035
Defauw A, Szoc S, Bardadym A, Brabers J, Everaert F, Mijic R, Scholte K, Vanallemeersch T, Van Winckel K, Van den Bogaert J. Misalignment Detection for Web-Scraped Corpora: A Supervised Regression Approach. Informatics. 2019; 6(3):35. https://doi.org/10.3390/informatics6030035
Chicago/Turabian StyleDefauw, Arne, Sara Szoc, Anna Bardadym, Joris Brabers, Frederic Everaert, Roko Mijic, Kim Scholte, Tom Vanallemeersch, Koen Van Winckel, and Joachim Van den Bogaert. 2019. "Misalignment Detection for Web-Scraped Corpora: A Supervised Regression Approach" Informatics 6, no. 3: 35. https://doi.org/10.3390/informatics6030035
APA StyleDefauw, A., Szoc, S., Bardadym, A., Brabers, J., Everaert, F., Mijic, R., Scholte, K., Vanallemeersch, T., Van Winckel, K., & Van den Bogaert, J. (2019). Misalignment Detection for Web-Scraped Corpora: A Supervised Regression Approach. Informatics, 6(3), 35. https://doi.org/10.3390/informatics6030035