1. Introduction
In recent years, the emergence of Zika and Ebola viruses have attracted much attention from the scientific community after reports of their aggressive effects, respectively, microcephaly in newborns [
1] and high mortality rate [
2,
3,
4]. Despite their intrinsic differences concerning transmission mechanisms and pathogen-host interaction, both viruses spread in a population starting from a few infected individuals, based on their geographic location and network of contacts. Contact tracing and proper clinical care planning are critical parts of the WHO strategic plan [
5] to mitigate ongoing transmissions and incidence cases, requiring the correct spatiotemporal dissemination of the disease. This assertion has renewed the interest in agent-based epidemic models (ABEM).
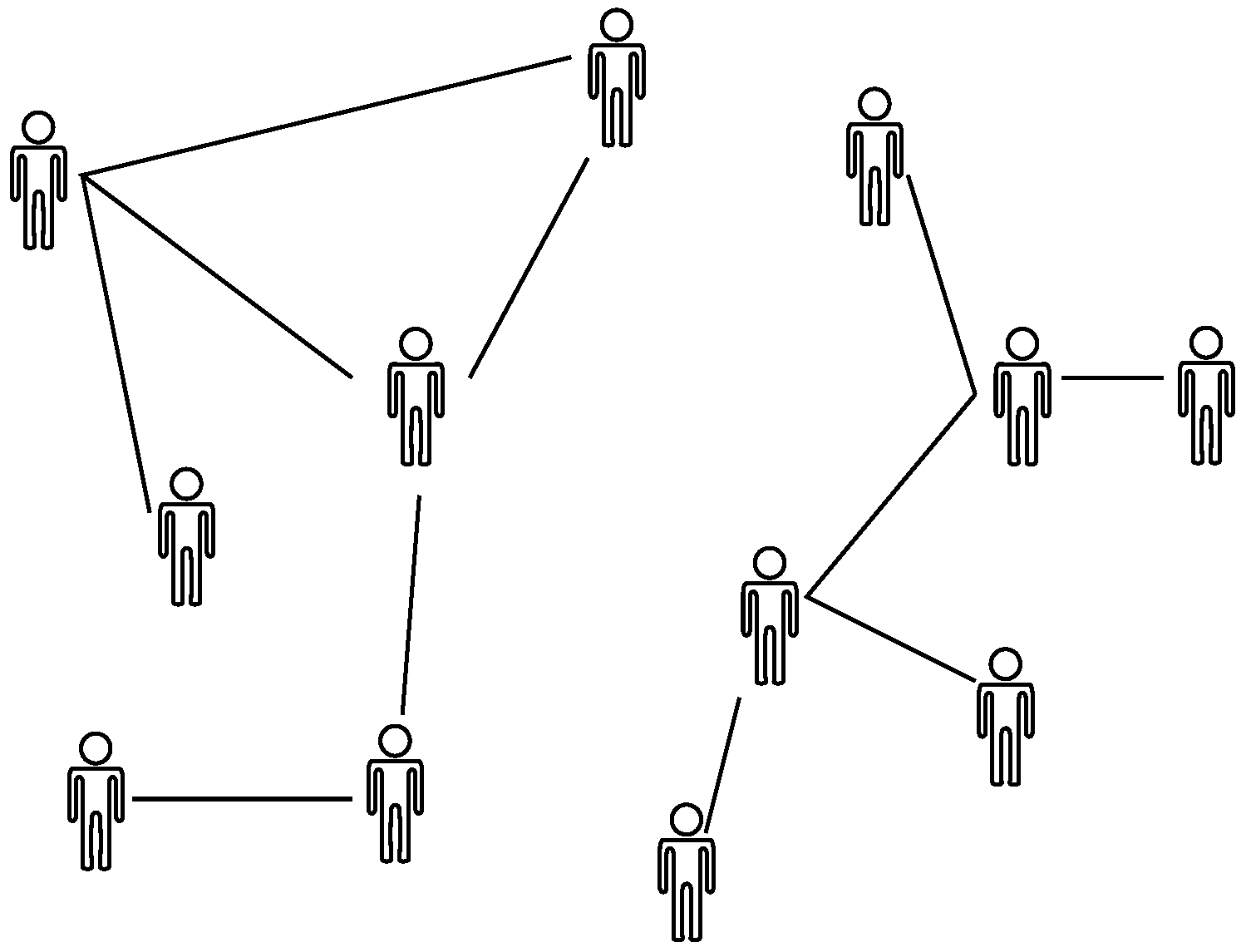
ABEM are mathematical models that describe the evolution of infectious diseases among a finite number
N of agents over time (see Reference [
6] for an extensive review). For that purpose, agents are labeled using integer numbers
, whereas contacts between agents are mapped via an adjacency matrix
A. The matrix elements are
if the
j-th agent connects to the
i-th agent and otherwise vanishes. Accordingly, the set formed by agents and their interconnection is expressed as a graph, as depicted in
Figure 1. In this way, heterogeneity arises naturally since the individuality of agents is taken into account, distinguishing ABEM from compartmental epidemic models [
7,
8,
9].
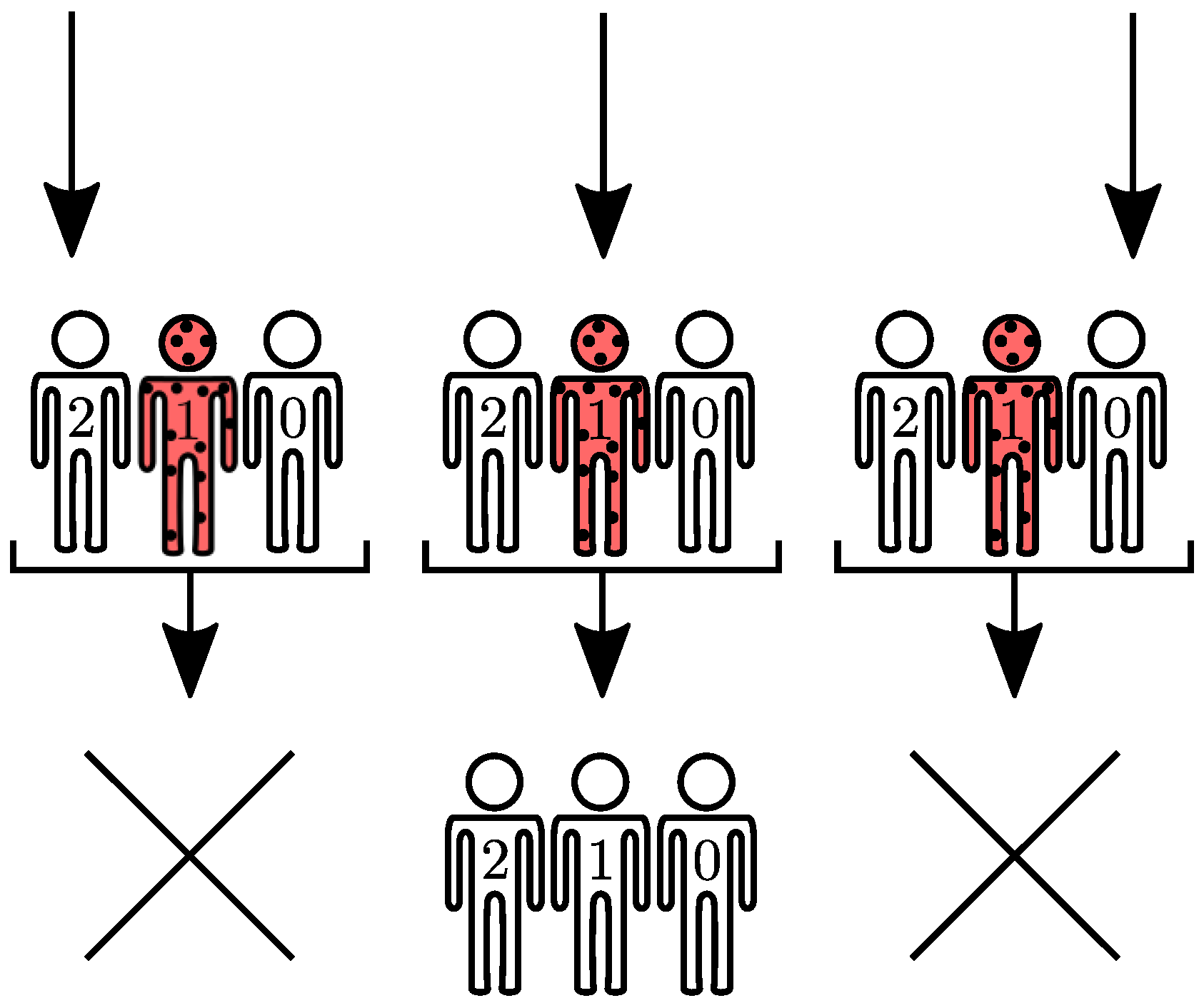
The susceptible-infected-susceptible model (SIS) is the simplest ABEM. It considers only two health states for agents, infected
or susceptible
, and the occurrence of the following events during a time interval
[
10,
11]. An infected agent may undergo a recovery event and return to susceptible state with probability
; an infected agent may infect a susceptible agent with transmission probability
if and only if both agents are connected; or remains unchanged, as
Figure 2 illustrates. Therefore, the SIS ABEM is inherently a Markov process in discrete time. The time interval
is often chosen so that sequential recovery-recovery or transmission-recovery events are unlikely within the available time window. This is the so-called Poissonian hypothesis [
12,
13,
14,
15].
Following Reference [
16], any configuration of
N agents is obtained by direct composition of individual agent states. Let
be an integer that labels the
-th configuration so that:
with
and
. A simple example for
is
, which represents the configuration where only the agent
is infected. From this scheme, it is already clear that there exist
configurations in total since there are two available states for each agent. In what follows, we employ the notation: Latin indices enumerate agents
, while Greek indices enumerate configuration states
.
Let
be the probability vector and
the probability of observing the configuration
at time
t [
17,
18]. The master equation for the general Markov process reads:
is the step operator, whereas
stands for the transition matrix [
19]. The transition matrix
encodes all transitions available between any two configuration vectors. Its matrix elements
are constructed from much simpler rules. These rules are model dependent and fully characterize the stochastic model, as we shall see in details later. If a representation of
is known, the solution of the master equation provides the instantaneous values of the probabilities
, i.e., the entire probability distribution function. Therefore, it becomes possible to calculate any relevant statistics of the problem at any instant of time, including those that may not be easily accessible or accurate by other numerical methods, such as the instantaneous Shannon entropy or the characteristic function.
Luckily, for time independent
, the solution is well known:
Despite the existence of this exact solution, the applicability of Equation (
3) at this stage is limited to small population sizes
. The reason is the exponential growth of the underlying vector space with
N. Here, we present algorithms to generate the operators
and
using finite symmetries or, equivalently, permutation symmetries via Cayley’s theorem [
20]. These algorithms are usually applied to condensate matter physics [
21,
22], but they may also be employed in epidemiology studies, due to recent developments in the disease spreading dynamics [
16]. For pedagogical reasons, we first show how to build the complete
vector space and the corresponding transition matrix. Next, we explore cyclic permutations to construct the cyclic vector space, in which
is broken down into
N smaller blocks. Lastly, we consider the most symmetric cases, which reduce the problem to O(
N). These instances correspond to the mean field or averaged networks. The iteration of sparse
over
produces the desired disease evolution among agents. Relevant steps are shown in Algorithm A1.
2. Transition Matrix
The transition matrix
for an SIS model considering
N two-state agents is [
16]:
where
,
is the Kronecker delta,
, is the local number operator (
), and
,
are the Pauli raising and lowering local operators, respectively. Local algebraic relationships are
and
. Inspection of Equation (
4) readily shows
is not Hermitian. This means left- and right-eigenvectors are not related by Hermitian conjugation. In this scenario, the correct time evolution of
using Equation (
3) requires the complete eigendecomposition, i.e.,
eigenvalues accompanied by
right-eigenvectors and
left-eigenvectors. This is often the main criticism against ABEM [
12].
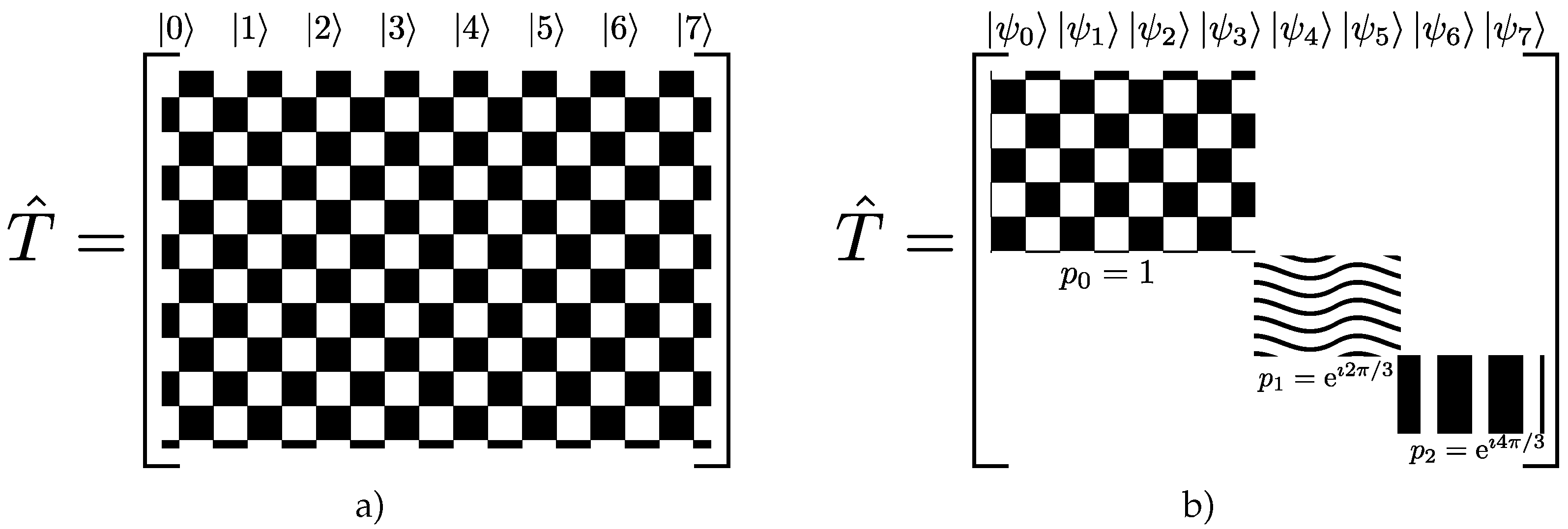
However, the scenario described above is not entirely correct. The rationale behind it assumes all eigenstates are equally relevant, which is incorrect whenever
A exhibits invariance upon the action of a particular group (sets of transformations). Symmetries allow the matrix representation of
to be in block diagonal form, as depicted in
Figure 3. Eigenvectors related to each block share the same eigenvalue (degeneracy), as usual in quantum mechanics [
23]. Therefore, the trick to simplify problems involving the transition matrix lies in the selection of the appropriate basis in respect to a given symmetry, creating matrix representations with smaller blocks. The computational performance using this methodology surpasses that of working with the full matrix because each block can be treated separately, reducing memory storage and access. In particular, if only a few blocks are relevant to the analysis, the remaining blocks can be neglected. This property often produces massive reductions in the typical dimensions of the problem, enhancing computation times.
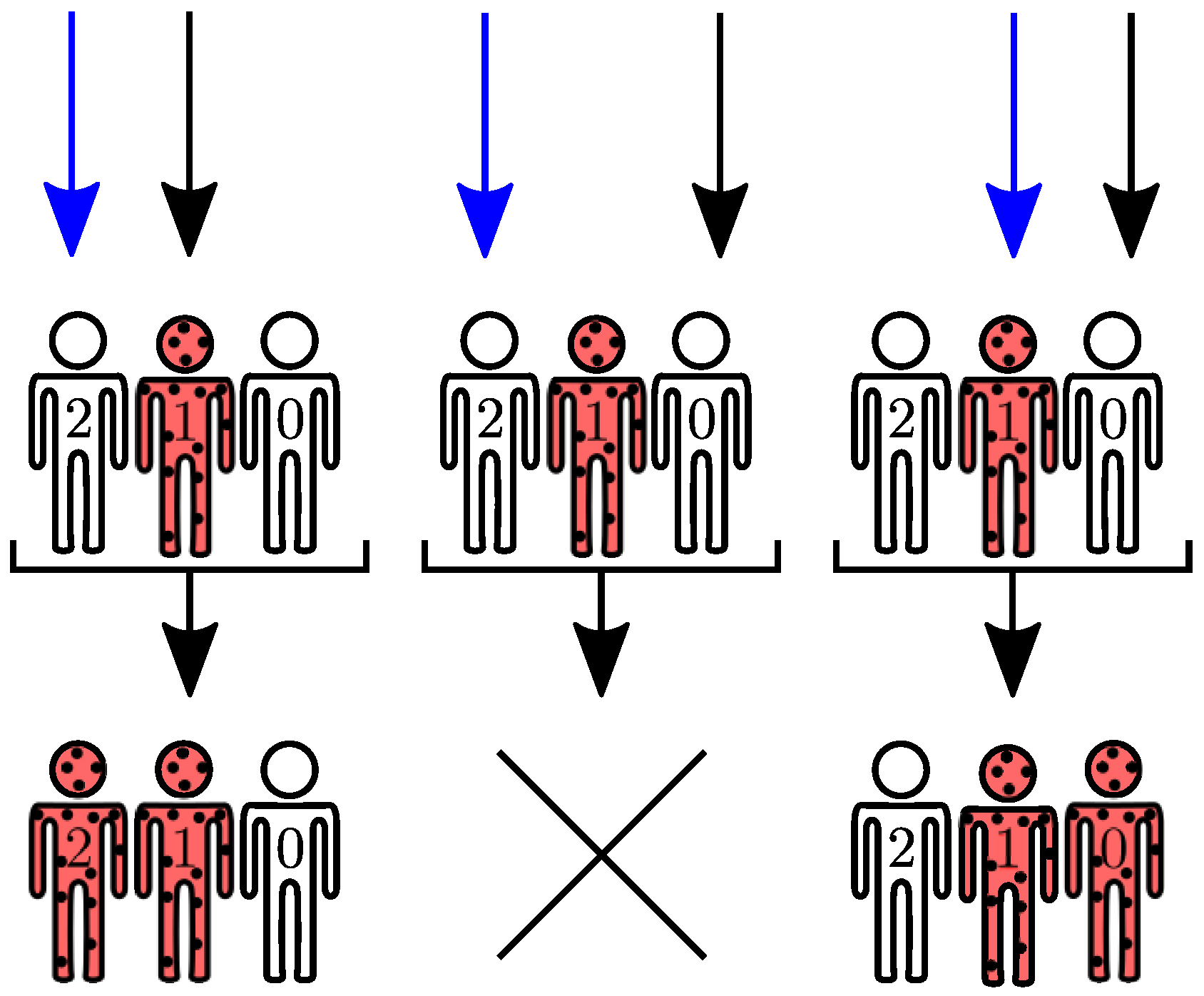
In the SIS model, recovery events result from actions of one-body operators, , on configuration vectors. Infection events are two-body operators: one infected agent may transmit the communicable disease to a susceptible agent after interaction between them, in the time interval . Interestingly, the resulting interaction also depends on symmetries available to the adjacency matrix A. The symmetries available to A may be further explored to assemble the initial vector space, reducing to its block diagonal form.
Group operations over
A are always finite transformations. One may explore the isomorphism between finite groups and the permutation group via Cayley theorem [
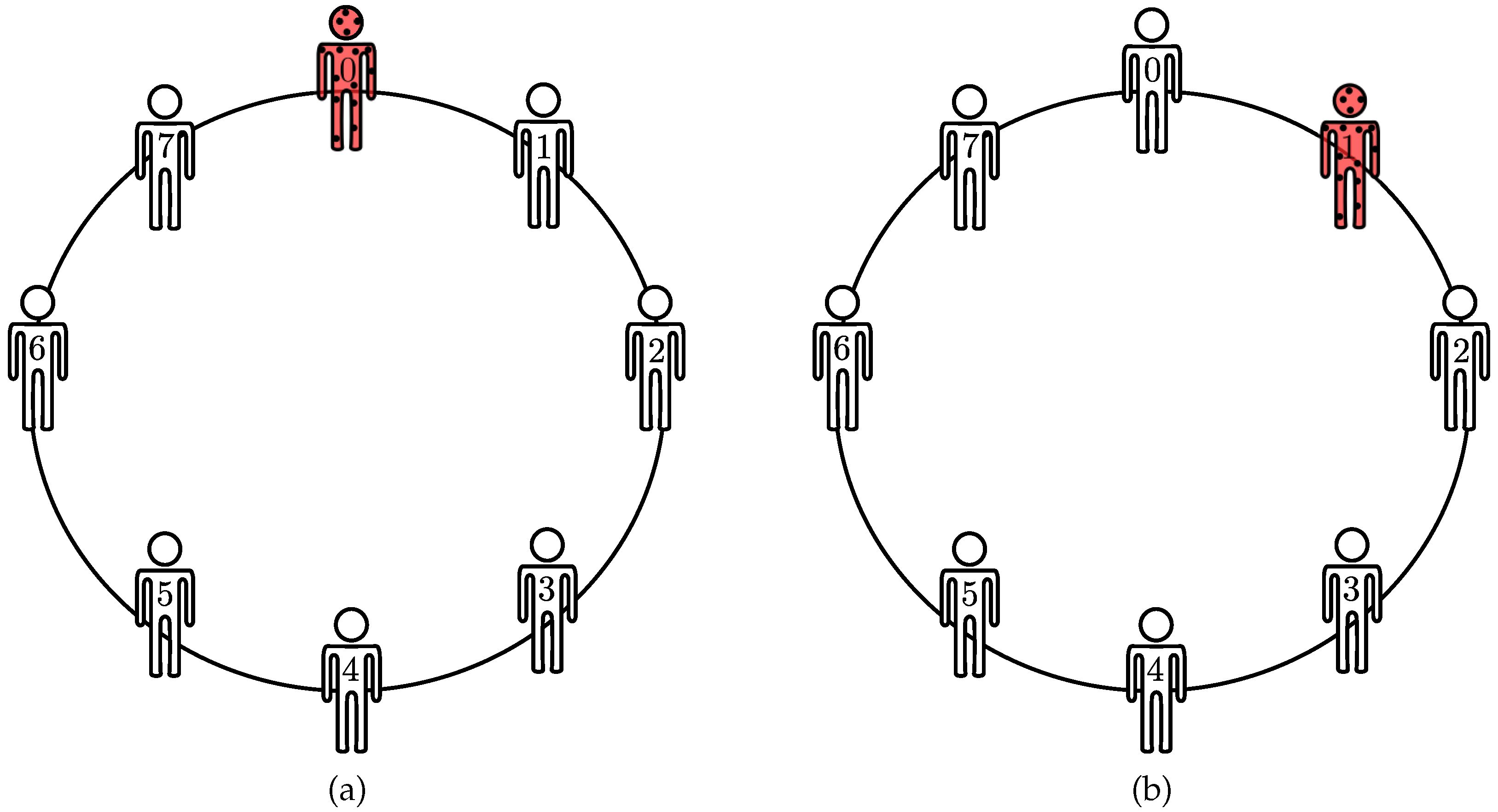
20] to build permutation invariant subspaces. To that end, one must select the finite group and the corresponding symmetry. For graphs, the circular representation provides a convenient context to explore the existing symmetries, as
Figure 4a depicts. From
Figure 4b, connections among agents remain unchanged after cyclic permutation of agents, hence,
A exhibits invariance under cyclic permutations. Cyclic permutations form a subset of permutation group and often represent geometric transformations, such as rotations and translations.
Vectors with
N agents and invariant by cyclic permutations are built as follows. Consider the
representative vector:
where
is the normalization and
is the single step cyclic permutation with
. The eigenvalues
are derived from
. Eigenvalues can be associated with invariant subspaces, or sectors, spanned by their corresponding eigenvectors. For the sake of convenience, the integer
p labels the eigenvalue sector. The representative vector
describes the linear combination of
N-agent configurations related to
by cyclic permutations. For instance,
corresponds to the representative vector for
, with
in the
sector. By construction, the vectors
satisfy the eigenvalue equation
. They are also useful to identify symmetries, as they never change link distributions, only node labels. If
is symmetric under cyclic permutations,
and
commute with each other
, meaning they share a common set of eigenvectors. Thus,
can be written using
and, more importantly, transitions between eigenvectors with distinct eigenvalues are prohibited. This feature leads to a block diagonal form to the matrix representation of
.
3. Cyclic Vector Space
The complete picture of infection dynamics generated by the SIS model requires the utilization of
configuration vectors. For completeness sake, we discuss the algorithm to obtain the vector space using both string and numeric representations. Matrix elements of
in Equation (
4) are calculated from an adjacency matrix and user input dictionary (lookup table) based on off-diagonal transition rules.
According to Equation (
1), the configuration vector
is obtained from the binary representations of the labels
, as exemplified in
Figure 5. There are two common equivalent routes to implement the configuration in computer codes. The first method employs string objects whereas the second method makes use of discrete mathematics. The second approach tends to be more efficient for two-state problems as optimized and native libraries for binary operations are widely available. For pedagogical purposes and generalization for more than two-states, we avoid exclusive binary operations in favor of usual discrete integer division and modulo operations.
In Python programming language, classes provide a convenient mechanism to enable both formalisms for each instanced object (vector). Here, the custom class SymConf is used to encapsulate two instance variables:
label stores the string representation of
N agents, while
label_int stores the corresponding integer number. In addition, the custom class also encapsulates three global class variables,
base,
dimension, and
basemax, whose default values are 2,
N, and
. Base corresponds to the number of available states per agent. The class main method generates the eigenvectors
with eigenvalue
, relative to the cyclic permutation operator
using Equation (
5).
In what follows, we address four relevant points regarding the permutation eigenvectors , namely, the criteria used to label eigenvectors; normalization; number of infected agents; and the permutation operation.
Labels. Equation (
5) claims permutation eigenvectors are a linear combination of all configuration vectors related by cyclic permutations. Here, we set the convention to adopt the smallest value
present in the linear combination to label the representative vector. As examples, consider the following representatives of
,
, and
:
The order convention is necessary to calculate the relative phase between configurations related by permutations in non-trivial linear combinations. For instance, consider the vector
. Since
and
are related by a single cyclic permutation, they differ by a phase factor:
. Note that the linear combination
vanishes for
. Despite the simplicity of the previous example, it already illustrates the relevance of phase difference among cyclic vectors.
Normalization. According to Equation (
5), the squared norm of representative vectors is:
The evaluation of the scalar product
follows directly from Equation (
5). One notices the configuration
may appear only once for several linear combinations
, so that
. For instance, this is the case of
. However, a given configuration
may contribute more than once if there exists an integer
such that
, i.e., after
r cyclic permutations the configuration repeats itself. Since
, it follows
is the number of times the configuration
appears in
. Each contribution adds
in Equation (
7). This result is conveniently summarized using the repetition number:
where the primed sum indicates
in the upper limit is an integer number. Therefore,
and one obtains
from Equation (
7).
We now show two examples to consolidate the discussion around
and
, for
and two infected agents. The configuration state
requires
N cyclic permutations to repeat itself, so that
for any
p and the corresponding normalization for
is simply
, as expected. The first non-trivial case arises for
because the base configuration
satisfies
. According to Equation (
8),
and assume only values:
and
. Thus, depending on
p, certain linear combinations are
forbidden because they produce vectors with null norm, ensuring the correct dimension of vector space. The remaining non-null states for
are shown in
Table 1 for further reference.
Number of Infected Agents. The number of infected agents using representative vectors is calculated as:
In the string representation, native string methods, such as
count(’x’), count the number agents with health state
. If native methods are unavailable, one may always perform a comparative loop over the string. Algorithm A2 explains the standard procedure to count bits in the integer representation. It is worth mentioning that the operator
commutes with
.
Permutation. Cyclic permutations are the core transformations here. In the string representation, cyclic permutations consist of one copy and one concatenation call, as exemplified in
Figure 6a.
Meanwhile, in the integer representation, cyclic permutations are obtained using modulo and integer division:
%
, the new configuration
is obtained from configuration
taking the modulo of
by
in addition to the result of the integer division
by
. Multiplication by the number of available states translates bit fields to the left. The modulo operation crops contributions larger than those available to
N-bit fields. Integer division
selects the bit associated to largest binary position and shifts it to the lowest binary position (see
Figure 6b).
Next, we focus our attention on the sector with
, which plays an important role in epidemic models (see
Section 5 for further discussion). This invariant subspace holds only symmetric linear combinations of configuration vectors. Incidentally, that also means that configurations with short cycles—or large repetition numbers—can only have representative vectors with non-vanishing norms iff
. The most important cases are: a) the all-infected configuration
, and b) disease-free configuration
. This occurs because these two configurations are invariant by every cyclic permutation available, including a single cyclic permutation (short cycle). As a direct consequence, the probability of disease eradication,
, and the probability that the disease has infected each element of the population,
, can only be evaluated at
. Moreover, this sector holds the largest dimension being the worst scenario for numerical computations.
To construct the vectors for this particular sector, consider each integer
in
as a potential candidate to assemble the symmetric vector spaces for fixed
p. By performing
cyclic permutations over
, one determines the representative state
in Equation (
5), as well as the number of repetitions
, hence the norm
. Algorithm A3 calculates the representative vector
associated with configuration
. Due to the order convention adopted here, the string representation must be converted to the integer representation at the
if-clause test. The representative configurations are then stored either in a list or dictionary. As an additional benefit, since vector spaces are independent of the problem at hand, the set of representatives may also be stored in a database for further use in different problems, as long as they are subjected to the same symmetry.
4. Matrix Elements
The next step is the evaluation of the transition matrix in the sector
. Infection and recovery dynamics are the main actors in this context, as they inform the way representative vectors
interact with each other,
. The prime indicates the sum runs over all eigenvectors in the
sector, while cyclic permutation invariance implies:
Equation (
10) tells us the action of
on the linear combination
is calculated from the simpler operation
. The resulting vectors are then permuted, producing the corresponding matrix elements. The practical advantages of this method come from the order of the operations: By doing the transitions first and then finding the respective representatives, one divides the workload by a factor
N. If the normal ordering were used instead, one would evaluate the transitions for each element of the linear combination and then find the corresponding representative, hence
N times the number of operations required with transition first. For instance, consider
for
:
The relevant data structure for
are the off-diagonal transitions, which are further subdivided into two categories: one or two-body contributions. This is illustrated in
Figure 7 for the SIS model. The finite set of transition rules are passed as a lookup table or, if available, a dictionary. Data is organized as follows: Each entry represents a one or two-body configuration whose value corresponds to one tuple. Each tuple holds two immutable values: the configuration to which the entry transitions to and the assigned coupling strength.
With off-diagonal transition rules in hand, one-body actions are evaluated by scanning each agent and applying the corresponding transition rule in Algorithm A4. The resulting one-body transitions are stored in the
outcome variable.
Figure 8 depicts an example for
and one infected agent at
. Two-body operators differ from their one-body counterparts due to the fact they require two agent loops and information from the adjacency matrix
A, as seen in Algorithm A5.
Figure 9 exhibits an example for
. After both one- and two-body transitions are computed, the diagonal element is obtained
via probability conservation:
. The process is iterated until all eigenvectors and their respective transitions are accounted.
5. Casimir Vector Space
The recent advances in the disease spreading dynamics in realistic populations are intimately linked to network theory [
12,
24]. Networks are traditionally associated with graphs holding a large number of nodes and links [
25]. The graph must be large enough to produce a degree distribution, which describes the probability distribution of links per node. The degree distribution, or alternatively its statistical moments, characterizes the network type and its properties. However, some networks, including random networks, require an ensemble of graphs to provide an accurate picture. Thus, a graph becomes a sample or realization of the network. Statistical properties of networks are derived for each graph, followed by ensemble average and deviation. In practice, when graphs in the ensemble are large enough (
) and representatives, statistics may also be evaluated for each graph and extrapolated as those of the network.
Two cases hold particular importance for applications of network theory in epidemic models: the mean field and random networks. In the first case, all agents are connected, meaning one infected agent may potentially infect anyone. Hence, the disease tends to spread faster than in constrained networks. Furthermore, all graphs in the mean field ensemble share the same adjacency . In the other case, the connection between agent i and j occurs with fixed probability . However, graphs in the random network ensemble differ from each other. Here, we only consider ensemble averages as a way to extract statistical properties, which is equivalent to set . Thus, all relevant symmetries lie only in the mean field adjacency matrix . Naturally, remains invariant under cyclic permutations, enabling the application of the algorithm explained in the previous sections. However, is also symmetric under the action of any permutation, which drastically reduces the diagonal blocks of from to .
Here, our primary concern is to employ the cyclic permutation eigenvectors
to generate the eigenvectors of the complete permutation group,
. The eigenvectors
reduce
in mean field or random networks to block diagonal form with dimension
. The indices
s and
m may assume the following values
with
and
, respectively. The relationship between
s and
m are the same as those observed for quantum spin operators. The explanation goes as follows. As shown in Reference [
16], Equation (
4), in either mean field or random networks, contains operators
and
. From the important relation
, one retains spin operators and the upper bound
, as expected from the combination of
N-spin particles.
In what follows, we only consider the
sector. First, let
be the Casimir operator, so that
for
and
. Accordingly,
and
s and
p are good quantum numbers. In general, the eigenvector
may always be expressed as:
Clearly,
if the number of infected agents in the configuration
,
, fails to satisfy the constraint
. The idea is to write Equation (
12) as a linear combination of representative vectors
with
infected agents, ensuring all available permutations are accounted for. The implications for numerical codes is quite obvious: it allows the reuse of numerical codes to obtain eigenvectors
.
The most relevant sector for epidemic models contains the configuration with all (none) infected agents. According to previous sections, this implies
while
requires
. In the
sector, the desired linear combination is:
with normalization
. The prime indicates the sum is subjected to the constraint
for
. The result in Equation (
13) agrees with the standard theory of spin addition. Generalization for
p and
s is straightforward and omitted. It is worth mentioning the formalism adopted here already accounted for forbidden states in
sectors.
Examples are available to appreciate Equation (
13) for increasing values of
N. We begin considering
. This translates into
and
. The relevant representative eigenvectors
are expressed in
Table 2. The only non-trivial correspondence occurs for
,
Next, consider
which fixes
and
. The eigenvector
holds contributions from four cyclic eigenvectors or, equivalently, 20 configurations:
6. Discussion
The algorithms presented in this study assumed only two health states for each agent. Generalization for
q number of states is readily available by changing to the integer representation
, with
, concomitant with additional off-diagonal transitions. For instance, the susceptible-infected-recovered-susceptible (SIRS) ABEM generalizes the SIS model as it introduces the removed (R) health state for agents. This additional state often means the agent has recovered from the illness and developed immunity, has been vaccinated, or has passed away. In any case, once removed, the agent takes no part in the dynamics of disease transmission, hindering infection events [
12]. As such, recovery with immunization or death events produce the transition
, with probability
while vaccination
occurs with probability
. If death events are excluded, temporary immunization is achieved via
with probability
. Therefore, the vectors
with
or 2 describe configurations of the SIRS model. However, the algorithm to explore cyclic permutations remains unchanged as it explores symmetries of the underlying network. As a result, eigenvalues and number of sectors are the same, but degeneracy and eigenvectors change to accommodate the increased number of health states.
Parallelism merits further discussion. The computation of representative vector space may be performed in parallel by dividing the set of integers among Q processes. Each process runs one local set of representative vectors which, posteriorly, is compared against the sets from the remaining processes. The union of all Q sets produces the desired representative vector space. Parallelism is also obtained at the evaluation of : Columns ( ) are distributed among Q processes and the corresponding matrix elements are calculated for each process. The union of all matrix elements from each process produces the complete description of in the representative vector space. Lastly, parallelism is also available for sparse products necessary to execute the time evolution.
We also emphasize the algorithms explained here are most useful to evaluate quantities within a single permutation sector of . This is likely the case whenever the probability for disease eradication or complete population contamination are concerned. Another relevant situation occurs when the initial condition itself falls within a single sector. For instance, the initial probability vector states only one among agents is infected. However, the identity of the infected agent is unknown a priori, so that configurations with one infected agent occurs with equal probability . Now, the decomposition of in the basis results in . Thus, the time evolution of by the action of is again restricted to a single permutation sector.
Without loss of generality, the initial condition can always be written as
, where the primed sum runs only over the indices
, which also labels the representative vectors. The cyclic permutation
generates the remaining configurations related to
whereas the coefficients
are the corresponding initial probabilities. Using the eigenvalue equation for
, one calculates the scalar product:
where
is the discrete Fourier transform of
. Using the previous example, with one infected among
agents,
, with
so that
,
, and the previous result is recovered.
Now we address the case where the evaluation of the desired statistics requires several permutation sectors. In the worst case scenario, every permutation sector contributes equally to the computation. Therefore one must diagonalize each block in order to obtain the relevant eigenvalues and eigenvectors. As a crude approximation, one may consider that the
N blocks have the same dimension
for a
d-dimensional vector space. The complexity of diagonalization methods in the LAPACK library range from
up to
for each block [
26], whereas the complexity range for full diagonalization is
. Thus diagonalization of
N blocks reduces the total complexity from
up to
. More importantly, blocks can be diagonalized in different processors because they are disjointed.
The algorithms presented here are most suitable for networks with invariance by cyclic permutations. However, they are also convenient whenever the algebraic commutator can be approximated by , where the operator is symmetric under cyclic permutations, . In particular, , with constant () and , creates interesting disease-spreading dynamics, such as a localized disease source for .
Finally, we compare performances of the SIS ABEM using the transition matrix method with and without our algorithm. Numerical experiments were performed using Python on an Intel-PC i7-7700 3.8 GHz. The decision to pick up Python instead of a more performance-oriented language was based on the ability to quickly disseminate the method. For data intensive research, we strongly recommend performance-oriented languages, such as C or high-performance Fortran. The results are summarized in
Table 3. As expected, cyclic permutations greatly improve computation times, most noticeable for large populations sizes. For
, the improved numerical code runs two orders of magnitude faster, while only consuming a fraction—about 6%—of the original memory. We reiterate methods involving the transition matrix to compute the probabilities of each configuration available to the system
, with
, up to numerical errors (floating point and rounding errors), often around
. Because they include all configurations, they can provide accurate statistics and data predictions along the evolution of the epidemics. However, direct Monte Carlo methods (DMCM) are far more efficient if one is solely interested in a few statistical moments of relevant variables, not in the entire joint pdf [
27,
28]. There are mainly two flavors of DMCM, depending on whether the time interval is fixed or distributed according to a given PDF [
29]. The latter case is more commonly known as the Gillespie algorithm [
30,
31,
32], and it has been successful to simulate epidemics. In DMCMs, execution times are directly related to the number of independent runs
m, with error scaling as
. Usually,
produces errors around
. Smaller errors can be obtained by increasing
m. Regardless, DMCM are always more efficient if the joint PDF is not required, as they probe the configurations that are more likely to occur. Indeed, computation times of DMCM with
,
s, are far lower than the 41 s obtained previously. Furthermore, DMCM hold small memory footprint and can simulate ABEM with
.

 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
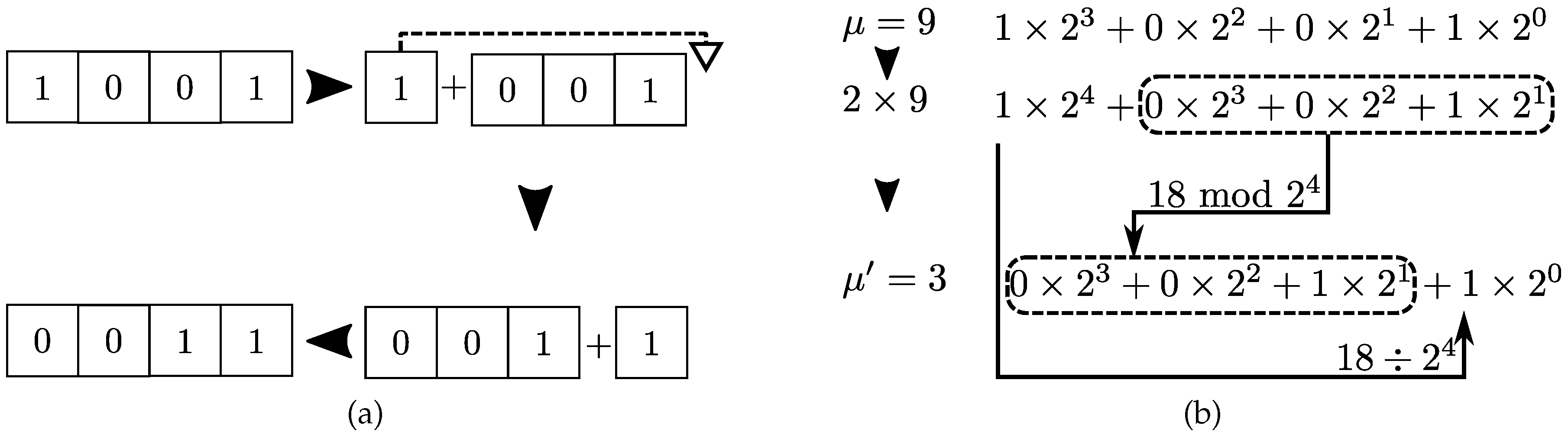{kind=link}
{kind=link}
{kind=link}
{kind=link}