1. Introduction
The Job Shop Scheduling Problem (JSSP) has enormous industrial applicability. This problem consists of a set of jobs, formed by operations, which must be processed in a set of machines subject to constraints of precedence and resource capacity. Finding the optimal solution for this problem is too complex, and so it is classified in the NP-hard class [
1,
2]. On the other hand, the JSSP foundations provide a theoretical background for developing efficient algorithms for other significant sequencing problems, which have many production systems applications [
3]. Furthermore, designing and evaluating new algorithms for JSSP is relevant not only because it represents a big challenge but also for its high industrial applicability [
4].
There are several JSSP taxonomies; one of which is single-objective and multi-objective optimization. The single-objective optimization version has been widely studied for many years, and the Simulated Annealing (SA) [
5] is among the best algorithms. The Threshold Accepting (TA) algorithm from the same family is also very efficient in this area [
6]. In contrast, in the case of Multi-Objective Optimization Problems (MOOPs), both algorithms for JSSP and their comparison are scarce.
Published JSSP algorithms for MOOP include only a few objectives, and only a few performance metrics are reported. However, it is common for the industrial scheduling requirements to have several objectives, and then the Multi-Objective JSSP (MOJSSP) becomes an even more significant challenge. Thus, many industrial production areas require the multi-objective approach [
7,
8].
In single-objective optimization, the goal is to find the optimal feasible solution of an objective function. In other words, to find the best value of the variables which fulfill all the constraints of the problem. On the other hand, for MOJSSP, the problem is to find the optimum of a set of objective functions
,
depending on a set of variables
x and subject to a set of constraints defined by these variables. To find the optimal solution is usually impossible because fulfilling some objective functions may not optimize the other objectives of the problem. In MOOP, a preference relation or Pareto dominance relation produces a set of solutions commonly called the Pareto optimal set [
9]. The Decision Makers (DMs) should select from the Pareto set the solution that satisfies their preferences, which can be subjective, based on experience, or will most likely be influenced by the industrial environment’s needs [
10]. Therefore, the DM needs to have a Pareto front that contains multiple representative compromise solutions, which exhibit both good convergence and diversity [
11].
In the study of single-objective JSSP, many algorithms have been applied. Some of the most common are SA, Genetic Algorithms (GAs), Tabu Search (TS), and Ant Systems (ASs) [
12]. In addition, as we mention below, few works in the literature solve JSSP instances with more than two objectives and applying more than two metrics to evaluate their performance. Nevertheless, for MOJSSP, the number of objectives and performance metrics remains too small [
8,
13,
14,
15]. The works of Zhao [
14] and Mendez [
8] are exceptions because the authors have presented implementations with two or three significant objective functions and two performance metrics. Moreover, SA and TA have shown to be very efficient for solving NP-hard problems. Thus, this paper’s motivation is to develop new efficient SA algorithms for MOJSSP with two or more objective functions and a larger number of performance metrics.
The first adaptation of SA to MOOP was an algorithm proposed in 1992, also known as MOSA [
16]. An essential part of this algorithm is that it applies the Boltzmann criterion for accepting bad solutions, commonly used in single-objective JSSP. MOSA combines several objective functions. The single-objective JSSP optimization with SA algorithm and MOSA algorithm for multi-objective optimization is different in several aspect related to determining the energy functions, using and generating new solutions, and measuring their quality as is well known, these energy functions are required in the acceptance criterion. Multiple versions of MOSA have been proposed in the last few years. One of them, published in 2008, is AMOSA, that surpassed other MOOP algorithms at this time [
17]. In this work, we adapt this algorithm for MOJSSP. TA [
6] is an algorithm for single-objective JSSP, which is very similar to Simulated Annealing. These two algorithms have the same structure, and both use a temperature parameter, and they accept some bad solutions for escaping from local optima. In addition, these algorithms are among the best JSSP algorithms, and their performance is very similar. Nevertheless, for MOJSSP, a TA algorithm has not been published, and so for obvious reason, it was not compared with the SA multi-objective version.
MOJSSP has been commonly solved using IMOEA/D [
14], NSGA-II [
18], SPEA [
19], MOPSO [
20], and CMOEA [
21]; the latter was renamed CMEA in [
8]. Nevertheless, the number of objectives and performance metrics of these algorithms remains too small. The Evolutionary Algorithm based on decomposition proposed in 2016 by Zhao in [
14] was considered the best algorithm [
22]. The Multi-Objective Q-Learning algorithm (MOQL) for JSSP was published in 2017 [
23]; this approach uses several agents to solve JSSP. An extension of MOQL is MOMARLA, which was proposed in 2019 by Mendez [
8]. This MOJSSP algorithm uses two objective functions: makespan and total tardiness. MOMARLA overcomes the classical multi-objective algorithms SPEA [
19], CMOEA [
21], and MOPSO [
20].
The two new algorithms presented in this paper for JSSP are Chaotic Multi-Objective Simulated Annealing (CMOSA) and Chaotic Multi-Objective Threshold Accepting (CMOTA). The first algorithm is inspired by the classic MOSA algorithm [
17]. However, CMOSA is different in three aspects: (1) for the first time it is designed specifically for MOJSSP, (2) it uses an analytical tuning of the cooling scheme parameters, and (3) it uses chaotic perturbations for finding new solutions and for escaping from local optima. This process allows the search to continue from a different point in the solution space and it contributes to a better diversity of the generated solutions. Furthermore, CMOTA is based on CMOSA and Threshold Accepting, and it does not require the Boltzmann distribution. Instead, it uses a threshold strategy for accepting bad solutions to escape from local optima. In addition, a chaotic perturbation function is applied.
In this paper, we present two new alternatives for MOJSSP, and we consider three objective functions: makespan, total tardiness, and total flow time. The first objective is very relevant for production management applications [
7], while the other two are critical for enhancing client attention service [
23]. In addition, we use six metrics for the evaluation of these algorithms, and they are Mean Ideal Distance (MID), Spacing (S), Hypervolume (HV), Spread (
), Inverted Generational Distance (IGD), and Coverage (C). We also apply an analytical tuning parameter method to these algorithms. Finally, we compare the achieved results with those obtained with the JSSP algorithm cited below in [
8,
14].
The rest of the paper is organized as follows. In
Section 2, we make a qualitative comparison of related MOJSSP works. In
Section 3, we present MOJSSP concepts and the performance metrics that were applied.
Section 4 presents the formulation of MOJSSP with three objectives. The proposed algorithms, their tuning method, and the chaotic perturbation are also shown in
Section 5.
Section 6 shows the application of the proposed algorithms to a set of 70, 58, and 15 instances. Finally, the results are shown and compared with previous works. In
Section 7, we present our conclusions.
2. Related Works
As mentioned above, in single-objective optimization, the JSSP community has broadly investigated the performance of the different solution methods. However, the situation is entirely different for MOJSSP, and there is a small number of published works. In 1994, an analysis of SA family algorithms for JSSP was presented [
24]; two of them were SA and TA, which we briefly explain in the next paragraph. These algorithms suppose that the solutions define a set of macrostates of a set of particles, while the objective functions’ values represent their energy, and both algorithms have a Metropolis cycle where the neighborhood of solutions is explored. In single-objective optimization, for the set of instances used to evaluate JSSP algorithms, SA obtained better results than TA. Furthermore, a better solution than the previous one is always accepted, while a worse solution may be accepted depending on the Boltzmann distribution criterion. This distribution is related to the current temperature value and the increment or decrement of energy (associated with the objective functions) in the current temperature value. In the TA case, a worse solution than the previous one may be accepted using a criterion that tries to emulate the Boltzmann distribution. This criterion establishes a possible acceptance of a worse solution when the decrement of energy is smaller than a threshold value depending on the temperature and a parameter
that is very close to one. Then at the beginning of the process, the threshold values are enormous because they depend on the temperatures. Subsequently, the temperature parameter is gradually decreased until a value close to zero is achieved, and then this threshold is very small.
In 2001, a Multi-Objective Genetic Algorithm was proposed to minimize the makespan, total tardiness, and the total idle time [
25]. The proposed methodology for JSSP was assessed with 28 benchmark problems. In this publication, the authors randomly weighted the different fitness functions to determine their results.
In 2006, SA was used for two objectives: the makespan and the mean flow time [
26]. This algorithm was called Pareto Archived Simulated Annealing (PASA), which used the Simulated Annealing algorithm with an overheating strategy to escape from local optima and to improve the quality of the results. The performance of this algorithm was evaluated with 82 instances taken from the literature. Unfortunately, this method has not been updated for three or more objective functions.
In 2011, a two-stage genetic algorithm (2S-GA) was proposed for JSSP with three objectives to minimize the makespan, total weighted earliness, and total weighted tardiness [
13]. In the first stage, a parallel GA found the best solution for each objective function. Then, in the second stage, the GA combined the populations, which evolved using the weighted aggregating objective function.
Researchers from the Contemporary Design and Integrated Manufacturing Technology (CDIMT) laboratory proposed an algorithm named Improved Multi-Objective Evolutionary Algorithm based on Decomposition (IMOEA/D) to minimize the makespan, tardiness, and total flow time [
14]. The authors experiment with 58 benchmark instances, and they use the performance metrics Coverage [
27] and Mean Ideal Distance (MID) [
28] to evaluate their algorithm. We notice in
Table 1, studies with two or three objectives, but they do not report any metric. On the other hand, IMOEA/D stands out from the rest of the literature, not only because the authors reported good results but also because they considered a more significant number of objectives, and they applied two metrics.
In 2008, the AMOSA algorithm based on SA for several objectives was proposed [
17]. In this paper, the authors reported that the AMOSA algorithm performed better than some MOEA algorithms, one of them NSGA-II [
29]. They presented the main Boltzmann rules for accepting bad solutions. Unfortunately, a MOJSSP with AMOSA and with more than two objectives has not been published.
In 2017, a hybrid algorithm between an NSGA-II and a linear programming approach was proposed [
15]; it was used to solve the FT10 instance of Taillard [
30]. This algorithm minimized the weighted tardiness and energy costs. To evaluate the performance, the authors only used the HV metric.
In 2019, MOMARLA was proposed, a new algorithm based on Q-Learning to solve MOJSSP [
8]. This work provided flexibility to use decision-maker preferences; each agent represented a specific objective and used two action selection strategies to find a diverse and accurate Pareto front. In
Table 1, we present the last related studies for MOJSSP and the proposed algorithms.
This paper analyzes our algorithms CMOSA and CMOTA, as follows: (a) comparing CMOSA and CMOTA versus IMOEA/D [
14], (b) comparing our algorithms with the results published for MOMARLA, MOPSO, CMOEA, and SPEA, and (c) comparing CMOSA versus CMOTA.
3. Multi-Objective Optimization
In a single-objective problem, the algorithm finishes its execution when it finds the solution that optimizes the objective function or a very close optimal solution. However, for Multi-Objective Optimization, the situation is more complicated since several objectives must be optimized simultaneously. Then, it is necessary to find a set of solutions optimizing each of the objectives individually. These solutions can be contrasting because we can obtain the best solution for an objective function that is not the best for other objective functions.
3.1. Concepts
Definitions of some concepts of Multi-Objective Optimization are shown below.
Pareto Dominance: In general, for any optimization problem, solution A dominates another solution B if the following conditions are met [
31]: A is strictly better than B on at least one objective, and A is not worse than B for any objective function.
Non-dominated set: In a set of P solutions, the non-dominated solutions P1 is integrated by solutions that accomplish the following conditions [
31]: any pair of P1 solutions must be non-dominated (one regarding the other), and any solution that does not belong to P1 is dominated by at least one member of P1.
Pareto optimal set: The set of non-dominated solutions of the total search space.
Pareto front: The graphic representation of the non-dominated solutions of the multi-objective optimization problem.
3.2. Performance Metrics
In an experimental comparison of different optimization techniques or algorithms, it is always necessary to have the notion of performance. In the case of Multi-Objective Optimization, the definition of quality is much more complicated than for single-objective optimization problems because the multi-objective optimization criteria itself consists of multiple objectives, of which, the most important are:
To minimize the distance of the resulting non-dominated set to the true Pareto front.
To achieve an adequate distribution (for instance, uniform) of the solutions is desirable.
To maximize the extension of the non-dominated front for each of the objectives. In other words, a wide range of values must be covered by non-dominated solutions.
In general, it is difficult to find a single performance metric that encompasses all of the above criteria. In the literature, a large number of performance metrics can be found. The most popular performance metrics were used in this research and are described below:
Mean Ideal Distance: Evaluates the closeness of the calculated Pareto front (
) solutions with an ideal point, which is usually (0, 0) [
28].
where
and
are the values of the
i-th non-dominated solution for their first, second, and third objective function, and
Q is the number of solutions in the
.
Spacing: Evaluates the distribution of non-dominated solutions in the
. When several algorithms are evaluated with this metric, the best is that with the smallest
S value [
32].
where
measures the distance in the space of the objective functions between the
i-th solution and its nearest neighbor; that is the
j-th solution in the
of the algorithm,
Q is the number of the solutions in the
,
is the average of the
, that is
and
, where
are the values of the
i-th non-dominated solution for their first and second objective function,
are the values of the
j-th non-dominated solution for their first and second objective function respectively,
M is the number of objective functions and
.
Hypervolume: Calculates the volume in the objective space that is covered by all members of the non-dominated set [
33]. The
metric is measured based on a reference point (
W), and this can be found simply by constructing a vector with the worst values of the objective function.
where
is a hypercube and is constructed with a reference point
W and the solution
i as the diagonal corners of the hypercube [
31]. An algorithm that obtains the largest
value is better. The data should be normalized by transforming the value in the range [0, 1] for each objective separately to perform the calculation.
Spread: This metric was proposed to have a more precise coverage value and considers the distance to the (extreme points) of the true Pareto front (
) [
29].
where
measures the distance between the “extreme” point of the
for the
k-th objective function, and the nearest point of
,
corresponds to the distance between the solution
i-th of the
, while its nearest neighbor,
corresponds to the average of the
and
M is the number of objectives.
Inverted Generational Distance: It is an inverted indicator version of the Generational Distance (GD) metric, where all the distances are measured from the
to the
[
1].
where
that is, the solutions in the
and
is the cardinality of
T,
p is an integer parameter, in this paper
and
is the Euclidean distance from
to its nearest objective vector
q in
Q, according to (
6).
where
is the
m-th objective function value of the
t-th member of T and M is the number of objectives.
Coverage: Represents the dominance between set
A and set
B [
27]. It is the ratio of the number of solutions in set
B that were dominated by solutions in set
A and the total number of solutions in set
B. The
C metric is defined by (
7).
When , all B solution are dominated or equal to solutions in A. Otherwise, , represents situations in which none of the solutions in B is dominated by any solution in A. The higher the value of , the more solutions in B are dominated by solutions in A. Both and should be considered, since is not necessarily equal to .
4. Multi-Objective Job Shop Scheduling Problem
In JSSP, there are a set of n different jobs consisting of operations that must be processed in m different machines. There are a set of precedence constraints for these operations, and there are also resource capacity constraints for ensuring that each machine should process only one operation at the same time. The processing time of each operation is known in advance. The objective of JSSP is to determine the sequence of the operations in each machine (the start and finish time of each operation) to minimize certain objective functions subject to the constraints mentioned above. The most common objective is the makespan, which is the total time in which all the problem operations are processed. Nevertheless, real scheduling problems are multi-objective, and several objectives should be considered simultaneously.
The three objectives that are addressed in the present paper are:
Makespan: the maximum time of completion of all jobs.
Total tardiness: it is calculated as the total positive differences between the makespan and the due date of each job.
Total flow time: it is the summation of the completion times of all jobs.
The formal MOJSSP model can be formulated as follows [
34,
35]:
where
q is the number of objectives,
x is the vector of decision variables, and
S represents the feasible region. Defined by the next precedence and capacity constraints, respectively:
where
, are the starting times for the jobs i, .
and are the processing times for the jobs i, .
it is the set of jobs.
it is the set of machines.
O is the set of operations (operation i of the job j).
The objective functions of makespan, total tardiness, and total flow time, are defined by Equations (
9)–(
11), respectively.
where
is the makespan of job
j.
where
is the tardiness of job
j, and
is the due date of job
j and is calculated with
[
36], where
is the time required to process the job
j in the machine
i. In this case, the due date of the
j job is the sum of the processing time of all its operations on all machines, multiplied by a narrowing factor (
), which is in the range
[
14,
36].
6. Main Methodology for CMOSA and CMOTA
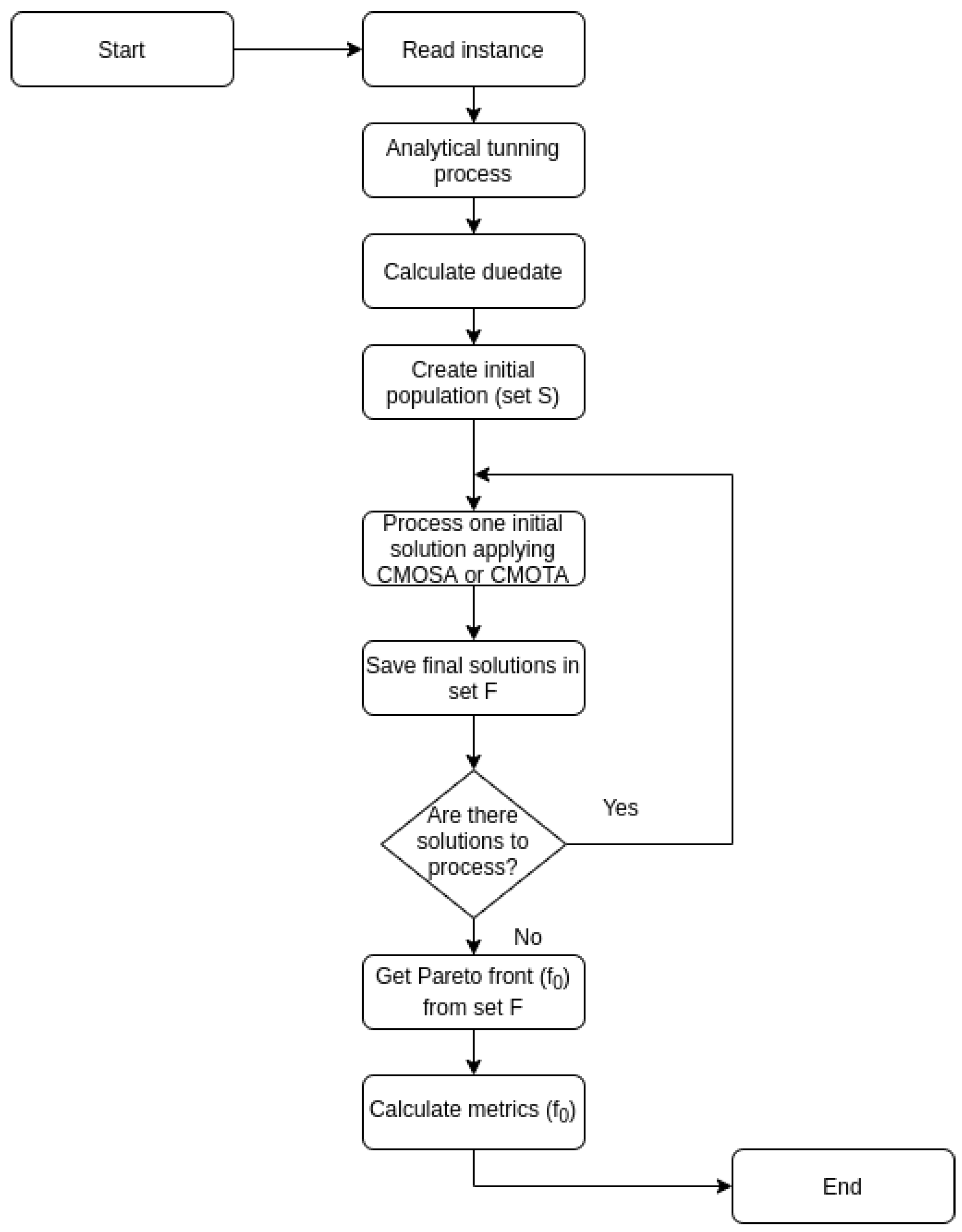
Figure 1 shows the main module for each of the two proposed algorithms CMOSA and CMOTA, which may be considered the main processes in any high-level language.
In this main module, the instance to be solved is read, then the tuning process is performed. The due date is calculated, which is an essential element for calculating the tardiness. The set of initial solutions (S) is generated randomly, as follows. First, a collection of feasible operations are determined, then one of them is randomly selected and added to the solution until all the job operations are added.
Once the set of initial solutions has been generated, an algorithm (CMOSA or CMOTA) is applied to improve each initial solution, and the generated solution is stored in a set of final solutions (
F). To obtain the set of non-dominated solutions, also called the zero front (
) from the set of final solutions, we applied the fast non-dominated Sorting algorithm [
29]. To know the quality of the non-dominated set obtained, the MID, Spacing, HV, Spread, IGD, and Coverage metrics are calculated. To perform the calculation of the spread and IGD, the true Pareto front (
) is needed. However, for the instances used in this paper, the
has not been published for all the instances. For this reason, the calculation was made using an approximate Pareto front (
), which we obtained from the union of the fronts calculated with previous executions of the two algorithms presented here (CMOSA and CMOTA).
6.1. Computational Experimentation
A set of 70 instances of different authors was used to evaluate the performance of the algorithms, including: (1) FT06, FT10, and FT20 proposed by [
40]; (2) ORB01 to ORB10 proposed by [
41]; (3) LA01 to LA40 proposed by [
42]; (4) ABZ5, ABZ6, ABZ7, ABZ8, and ABZ9 proposed by [
43]; (5) YN1, YN2, YN3, and YN4 proposed by [
44], and (6) TA01, TA11, TA21, TA31, TA41, TA51, TA61, and TA71 proposed by [
30].
As already explained, to perform the analytical tuning, some previous executions of the algorithm are necessary. The parameters used for those previous executions are shown in
Table 2, and the parameters used in the final experimentation for each instance are shown in
Table 3.
The execution of the algorithm was carried out on one of the terminals of the Ehecatl cluster at the TecNM/IT Ciudad Madero, which has the following characteristics: Intel® Xeon® processor at 2.30 GHz, Memory: 64 GB (4 × 16 GB) ddr4-2133, Linux operating system CentOS, and C language was used for the implementation. We developed CMOSA (
https://github.com/DrJuanFraustoSolis/CMOSA-JSSP.git) and CMOTA (
https://github.com/DrJuanFraustoSolis/CMOTA-JSSP.git) and we tested the software and using three data sets reported in the paper and taken from the literature.
In the first experiment, the algorithms CMOSA and CMOTA were compared with AMOSA algorithm using the 70 described instances and six performance metrics. In a second experiment, we compared CMOSA and CMOTA with the IMOEA/D algorithm, with the 58 instances used by Zhao [
14]. In the second experiment, we used the same MID metric of this publication. The third experiment was based on the 15 instances reported in [
8], where the results of the next MOJSSP algorithms are published: SPEA, CMOEA, MOPSO, and MOMARLA. In this publication the authors used two objective functions and two metrics (HV and Coverage); they determined that the best algorithm is MOMARLA followed by MOPSO. We executed CMOSA and CMOTA for the instances of this dataset and we compared our results using the HV metric with those published in [
8]. However, a comparison using the coverage metric was impossible because the Pareto fronts of these methods have not been reported [
8]. In our case, we show in
Appendix A the fronts of non-dominated solutions obtained with 70 instances.
6.2. Results
The average values of 30 runs, for the six metrics obtained by CMOSA and CMOTA for the complete data set of 70 instances are shown in
Table 4 and
Table 5. We observed that CMOSA obtained the best values for MID and IGD metrics. For Spacing and Spread, CMOTA obtained the best results. For the HV metric, both algorithms achieved the same result (0.42). We observed in
Table 5 that CMOSA obtained the best coverage result.
A two-tailed Wilcoxon test was performed with a significance level of 5% (last column in
Table 4) and this shows that there are no significant differences between the CMOSA and CMOTA except in MID and IGD metrics.
Table 6 shows the comparison of CMOSA and AMOSA. We observed that CMOSA obtains the best performance in all the metrics evaluated. In addition, the Wilcoxon test indicates that there are significant differences in most of them; thus, CMOSA overtakes AMOSA. We compared CMOTA and AMOSA in
Table 7. In this case, CMOTA also obtains the best average results in all the metrics; however, according to the Wilcoxon test, there are significant differences in only two metrics.
We compare in
Table 8 the CMOSA and CMOTA with the IMOEA/D algorithm using the 58 common instances published in [
14] where the MID metric was measured. This table shows the MID average value of this metric for the non-dominated set of solutions of CMOSA and CMOTA. The results showed that CMOSA and CMOTA obtain better performances than IMOEA/D. We notice that both algorithms, CMOSA and CMOTA, achieved smaller MID values than IMOEA/D, which indicates that the Pareto fronts of our algorithms are closer to the reference point (0,0,0). The Wilcoxon test confirms that CMOSA and CMOTA surpassed the IMOEA/D.
The results of CMOSA and CMOTA were compared with the SPEA, CMOEA, MOPSO, and MOMARLA algorithms [
8]. In the last reference, only two objective functions were reported, the makespan and total tardiness. The experimentation was carried out with 15 instances and the average HV values were calculated to perform the analysis of the results, which are shown in
Table 9. We notice that MOMARLA surpassed SPEA, CMOEA, and MOPSO. We can observe that CMOSA obtained a better performance than MOMARLA and the other algorithms. Comparing CMOTA and MOMARLA, we notice that both algorithms obtained the same HV average results.
6.3. CMOSA-CMOTA Complexity and Run Time Results
In this section, we present the complexity of the algorithms analyzed in this paper. The algorithms’ complexity is presented in
Table 10, and it was obtained directly when it was explicitly published or determined from the algorithms’ pseudocodes. In this table,
M is the number of objectives,
is the population size,
T is the neighborhood size,
n is the number of iterations (temperatures for AMOSA, CMOSA, and CMOTA), and
p is the problem size. The latter is equal to
where
j and
m are the number of jobs and machines, respectively. Because the algorithms with the best quality metrics are CMOSA, CMOTA MOMARLA, and MOPSO, their complexity is compared in this section.
It is well known that the complexity of classical SA is
[
45]. However, we notice from
Table 10 that CMOSA, and CMOTA have a different complexity even though they are based on SA. This is because these new algorithms applied a different chaotic perturbation and another local search (see Algorithms 2 and 6 in lines 10–20).
The temporal function of MOMARLA, CMOSA, and CMOTA belong to . For MOMARLA, n is the number of iterations, a variable used at the beginning of this algorithm. On the other hand, for CMOSA and CMOTA, n is the number of temperatures used in the algorithm, also at its beginning; in any case, the difference will be only a constant.
We note that AMOSA and MOPSO have a similar complexity class expression, that is
and
respectively. However, MOPSO overtakes AMOSA because
M is in general lower than
n. We observe that CMOSA, CMOTA and MOMARLA belong to
class complexity, while MOPSO belongs to
[
46]. Thus, the relation between them is
which in general is lower than one. Thus CMOSA, CMOTA and MOMARLA have a lower complexity than MOPSO. Moreover, CMOSA, CMOTA, and MOMARLA have better HV metric quality as is shown in
Table 9.
In the next paragraph, we present a comparative analysis of the execution time of the algorithms implemented in this paper.
In
Table 11 we show the execution time, expressed in seconds, for the three algorithms (CMOSA, CMOTA, and AMOSA) implemented in this paper for three data sets (70, 58, and 15 instances). In all these cases, we emphasize that the AMOSA algorithm was the base to design the other two algorithms. In fact, all of them have the same structure except that CMOSA and CMOTA apply chaotic perturbations when they detect a possible stagnation. Thus, all of them have similar complexity measures for the worst-case.
Table 11 shows the percentage of time saved by these two algorithms concerning AMOSA. For these datasets, we measured that AMOSA saved 2.1, 19.87, and 42.48 percent of the AMOSA run time; on the other hand, these figures of CMOTA versus AMOSA are 55, 68.89, and 46.73 percent. Thus, both of our proposed algorithms CMOSA and CMOTA are significantly more efficient than AMOSA. Unfortunately, we do not have the tools to compare these algorithms versus the other algorithms’ execution time in
Table 1. Nevertheless, we made the quality comparisons by using the metrics previously published.
7. Conclusions
This paper presents two multi-objective algorithms for JSSP, named CMOSA and CMOTA, with three objectives and six metrics. The objective functions for these algorithms are makespan, total tardiness, and total flow time. Regarding the results from the comparison of CMOSA and CMOTA with AMOSA, we observe that both algorithms obtained a well-distributed Pareto front, closest to the origin, and closest to the approximate Pareto front as was indicated by Spacing, MID, and IGD metrics, respectively. Thus, using these five metrics, we found that CMOSA and CMOTA surpassed the AMOSA algorithm. Regarding the volume covered by the front calculated by the HV metric, it was observed that both algorithms, CMOSA and CMOTA, have the same performance; however, CMOSA has a higher convergence than CMOTA. In addition, the proposed algorithms surpass IMOEA/D when MID metric was used. Moreover, we use the HV to compare the proposed algorithms with SPEA, CMOEA, MOPSO, and MOMARLA. We found that CMOSA outperforms these algorithms, followed by CMOTA, MOMARLA, and MOPSO.
We observe that CMOSA and CMOTA have similar complexity as the best algorithms in the literature. In addition, we show that CMOSA and CMOTA surpass AMOSA when we compare them using execution time for three data sets. We found CMOTA is, on average, 50 percent faster than AMOSA and CMOSA. Finally, we conclude that CMOSA and CMOTA have similar temporal complexity than the best literature algorithms, and the quality metrics show that the proposed algorithms outperform them.

 ,
, 



{kind=link}
