LIMPID: A Lightweight Image-to-Curve MaPpIng moDel for Extremely Low-Light Image Enhancement


Abstract
:1. Introduction
- We introduce image-to-curve mapping to extremely low-light enhancement for the first time.
- We design a lightweight network for real-time extremely low-light image enhancement.
- We propose an adaptive multi-scale fusion strategy in terms of color and texture optimization.
2. Related Work
2.1. End-to-End Methods
2.2. Image-to-Curve Methods
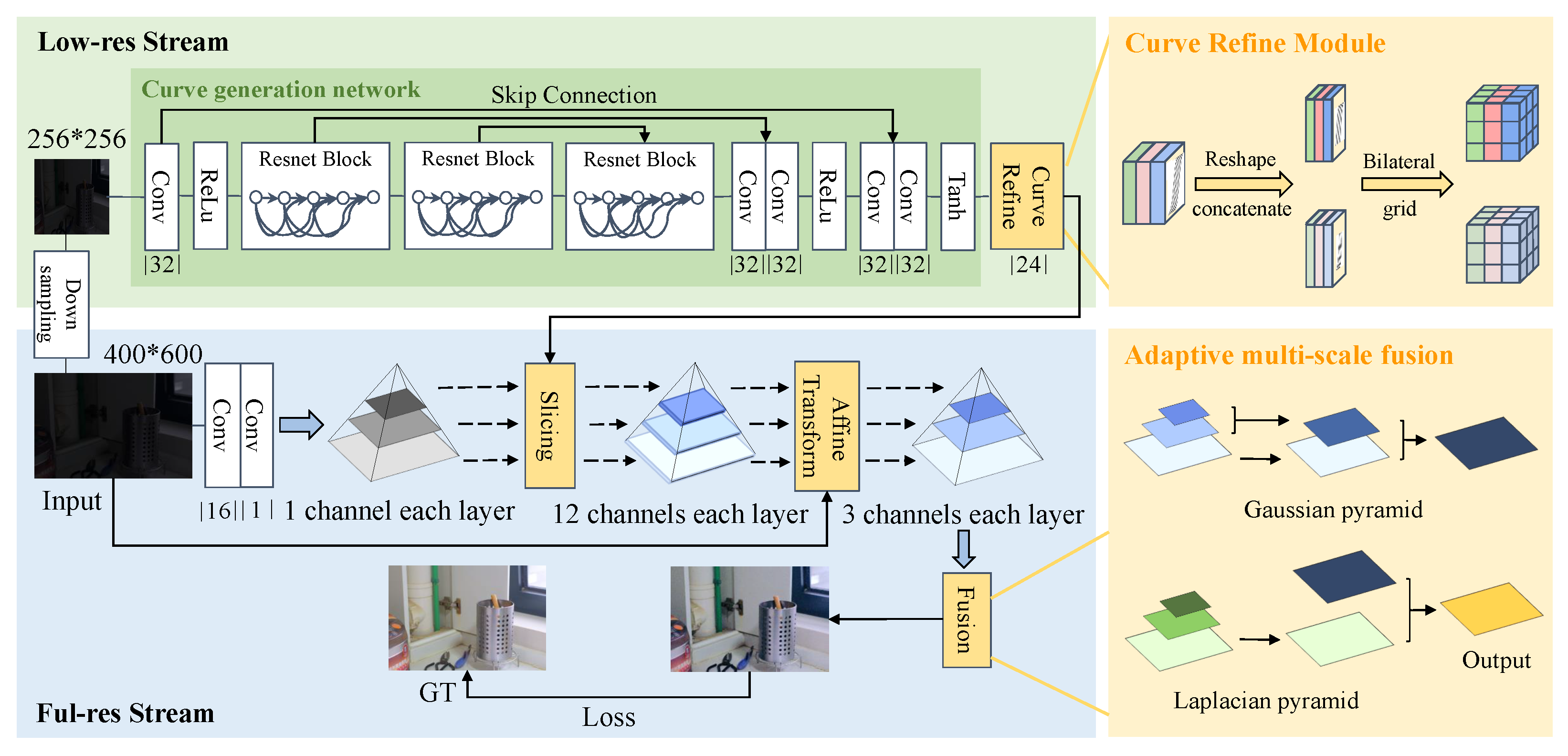
3. The Proposed Method
3.1. Image-to-Curve Mapping
3.2. Curve Generation and Refinement
3.3. Adaptive Multi-Scale Fusion
3.4. Overall Architecture
- Spatial consistency loss: enhances the spatial consistency of the image by preserving the differences in adjacent regions between the enhanced image and the ground truth:
- Reconstruction loss: compares the difference between the generated image and the ground truth pixel by pixel and takes the absolute value for the distance between pixels in case the positive and negative values cancel each other out.where P denotes the area of a patch, while N is the number of pixels contained within it.
- Illumination smoothness loss: preserves a monotonic relationship among adjacent pixels by controlling the smoothing on curve parameter matrices A:
4. Experiments
4.1. Experimental Settings
- Implementation details: Our implementation was carried out with PyTorch and trained for 2499 epochs with a mini-batch size of 6 on an NVidia GTX 1070 GPU. We used the Adam optimizer with an initial learning rate of , and we also used the learning rate decay strategy, which reduces the learning rate to after 500 epochs.
- Evaluation metrics: We choose PSNR [42], SSIM [43], GMSD [44], and FSIM [45] as objective metrics to evaluate image quality. PSNR [42] reflects the image fidelity, SSIM [43] and GMSD [44] compare the similarity of two images in terms of image structure, and FSIM compares the similarity of images in terms of luminance components.
- Datasets: The LOL-V1 dataset [6] includes 500 pairs of images taken from real scenes, each pair comprising a low-light image and a normal-light image of the same scene, with 485 pairs in the training set and 15 pairs in the testing set. The SID dataset [16] contains 5094 raw short-exposure images, each with a reference long-exposure image. The ELD dataset [17] is an extremely low-light denoising dataset composed of 240 raw image pairs in total captured over 10 indoor scenes using various camera devices. We used the training set of the LOL-V1 dataset [6] for training, and to verify the effectiveness of LIMPID, subjective and objective comparisons were made with existing SOTA methods on the testing sets of the SID dataset [16] and the ELD dataset [17].
4.2. Perceptual Comparisons
4.3. Quantitative Comparisons
4.4. Ablation Study
- Network Replacing our curve generation network and curve refinement module with a few superficial convolutional layers, the PSNR metric decreases by compared to the performance of LIMPID, and subjectively the enhancement effect is limited for relatively darker regions (see the partially enlarged area), illustrating the stability and effectiveness of our network.
- Multi-scale pyramidal fusion: With only one image as the guide map for the slicing layer and removing the subsequent image fusion, the result is significantly dimmer in color and brightness than that of LIMPID, with PSNR and SSIM reduced by about 40 percent and 20 percent, respectively, due to the dynamic enhancement of color and detail carried out by the fusion of the different scale feature maps in LIMPID.
- Loss function: The second row of Figure 7 shows the results of training through various combinations of loss functions. The absence of the L1 loss function leads to a decrease in PSNR of about and a more erratic appearance of color bias, indicating that the L1 loss function has a significant impact on the specification of the pixel-by-pixel similarity comparison between the input and the enhanced image. Removing the spatial consistency loss yields a result with somewhat higher contrast than the full result, as can be observed by the inconspicuous yellow color of the water pipe above the local zoom in Figure 7, along with a slight drop of about 4 percent in both PSNR and SSIM, demonstrating the importance of spatial consistency loss in preserving differences in adjacent regions of the image. Lastly, the removal of the illumination smoothing loss results in an objective decrease of in PSNR and a subjective decrease in the correlation between adjacent regions, thus blurring the edges, suggesting that the illumination smoothing loss preserves the monotonic relationship between adjacent pixels. Hence, it can be seen that the combination of the loss functions selected can more effectively constrain to recover the color and texture details of the image.
5. Conclusions
6. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, L.W.; Liu, Z.S.; Siu, W.C.; Lun, D.P. Lightening Network for Low-Light Image Enhancement. IEEE Trans. Image Process. 2020, 29, 7984–7996. [Google Scholar] [CrossRef]
- Li, J.; Li, J.; Fang, F.; Li, F.; Zhang, G. Luminance-aware Pyramid Network for Low-light Image Enhancement. IEEE Trans. Multimed. 2020, 23, 3153–3165. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, J.; Guo, X. Kindling the darkness: A practical low-light image enhancer. In Proceedings of the ACMMM, Nice, France, 21–25 October 2019; pp. 1632–1640. [Google Scholar]
- Fan, M.; Wang, W.; Yang, W.; Liu, J. Integrating semantic segmentation and retinex model for low-light image enhancement. In Proceedings of the ACMMM, Seattle, WA, USA, 12–16 October 2020; pp. 2317–2325. [Google Scholar]
- Xu, J.; Hou, Y.; Ren, D.; Liu, L.; Zhu, F.; Yu, M.; Wang, H.; Shao, L. Star: A structure and texture aware retinex model. IEEE Trans. Image Process. 2020, 29, 5022–5037. [Google Scholar] [CrossRef] [Green Version]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep retinex decomposition for low-light enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar]
- Zhu, A.; Zhang, L.; Shen, Y.; Ma, Y.; Zhao, S.; Zhou, Y. Zero-shot restoration of underexposed images via robust retinex decomposition. In Proceedings of the ICME, London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Zhang, Y.; Guo, X.; Ma, J.; Liu, W.; Zhang, J. Beyond Brightening Low-light Images. Int. J. Comput. Vis. 2021, 129, 1013–1037. [Google Scholar] [CrossRef]
- Atoum, Y.; Ye, M.; Ren, L.; Tai, Y.; Liu, X. Color-wise attention network for low-light image enhancement. In Proceedings of the CVPRW, Seattle, WA, USA, 14–19 June 2020; pp. 506–507. [Google Scholar]
- Li, S.; Cheng, Q.; Zhang, J. Deep Multi-path Low-Light Image Enhancement. In Proceedings of the MIPR, Shenzhen, China, 6–8 August 2020; pp. 91–96. [Google Scholar]
- Hu, Q.; Guo, X. Low-light Image Enhancement via Breaking Down the Darkness. arXiv 2021, arXiv:2111.15557. [Google Scholar]
- Zhu, M.; Pan, P.; Chen, W.; Yang, Y. Eemefn: Low-light image enhancement via edge-enhanced multi-exposure fusion network. In Proceedings of the AAAI, Hilton, NY, USA, 7–12 February 2020; Volume 34, pp. 13106–13113. [Google Scholar]
- Lv, F.; Liu, B.; Lu, F. Fast enhancement for non-uniform illumination images using light-weight CNNs. In Proceedings of the ACMMM, Seattle, WA, USA, 12–16 October 2020; pp. 1450–1458. [Google Scholar]
- Sun, X.; Li, M.; He, T.; Fan, L. Enhance Images as You Like with Unpaired Learning. arXiv 2021, arXiv:2110.01161. [Google Scholar]
- Wang, Y.; Wan, R.; Yang, W.; Li, H.; Chau, L.P.; Kot, A. Low-light image enhancement with normalizing flow. In Proceedings of the AAAI, Virtual, 22 February– 1 March 2022; Volume 36, pp. 2604–2612. [Google Scholar]
- Chen, C.; Chen, Q.; Xu, J.; Koltun, V. Learning to see in the dark. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3291–3300. [Google Scholar]
- Wei, K.; Fu, Y.; Yang, J.; Huang, H. A physics-based noise formation model for extreme low-light raw denoising. In Proceedings of the CVPR, Seattle, WA, USA, 14–19 June 2020; pp. 2758–2767. [Google Scholar]
- Zhang, L.; Zhang, L.; Liu, X.; Shen, Y.; Zhang, S.; Zhao, S. Zero-shot restoration of back-lit images using deep internal learning. In Proceedings of the ACMMM, Nice, France, 21–25 October 2019; pp. 1623–1631. [Google Scholar]
- Moran, S.; Marza, P.; McDonagh, S.; Parisot, S.; Slabaugh, G. Deeplpf: Deep local parametric filters for image enhancement. In Proceedings of the CVPR, Seattle, WA, USA, 14–19 June 2020; pp. 12826–12835. [Google Scholar]
- Moran, S.; McDonagh, S.; Slabaugh, G. Curl: Neural curve layers for global image enhancement. In Proceedings of the ICPR, IEEE, Milan, Italy, 10–15 January 2021; pp. 9796–9803. [Google Scholar]
- Guo, C.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the CVPR, Seattle, WA, USA, 14–19 June 2020; pp. 1780–1789. [Google Scholar]
- Li, C.; Guo, C.; Ai, Q.; Zhou, S.; Loy, C.C. Flexible Piecewise Curves Estimation for Photo Enhancement. arXiv 2020, arXiv:2010.13412. [Google Scholar]
- Gharbi, M.; Chen, J.; Barron, J.T.; Hasinoff, S.W.; Durand, F. Deep Bilateral Learning for Real-Time Image Enhancement. ACM Trans. Graph. 2017, 36, 118. [Google Scholar] [CrossRef]
- Jobson, D.J.; Rahman, Z.u.; Woodell, G.A. A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans. Image Process. 1997, 6, 965–976. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Di, X.; Zhang, B.; Wang, C. Self-supervised image enhancement network: Training with low light images only. arXiv 2020, arXiv:2002.11300. [Google Scholar]
- Wang, Y.; Cao, Y.; Zha, Z.J.; Zhang, J.; Xiong, Z.; Zhang, W.; Wu, F. Progressive retinex: Mutually reinforced illumination-noise perception network for low-light image enhancement. In Proceedings of the ACMMM, Nice, France, 21–25 October 2019; pp. 2015–2023. [Google Scholar]
- Ren, X.; Yang, W.; Cheng, W.H.; Liu, J. Lr3m: Robust low-light enhancement via low-rank regularized retinex model. IEEE Trans. Image Process. 2020, 29, 5862–5876. [Google Scholar] [CrossRef]
- Hao, S.; Han, X.; Guo, Y.; Xu, X.; Wang, M. Low-light image enhancement with semi-decoupled decomposition. IEEE Trans. Multimed. 2020, 22, 3025–3038. [Google Scholar] [CrossRef]
- Yang, W.; Wang, W.; Huang, H.; Wang, S.; Liu, J. Sparse gradient regularized deep retinex network for robust low-light image enhancement. IEEE Trans. Image Process. 2021, 30, 2072–2086. [Google Scholar] [CrossRef]
- Hai, J.; Xuan, Z.; Yang, R.; Hao, Y.; Zou, F.; Lin, F.; Han, S. R2RNet: Low-light Image Enhancement via Real-low to Real-normal Network. arXiv 2021, arXiv:2106.14501. [Google Scholar] [CrossRef]
- McCartney, E.J. Optics of the atmosphere: Scattering by molecules and particles. New York 1976. Available online: https://ui.adsabs.harvard.edu/abs/1976nyjw.book.....M/abstract (accessed on 1 March 2023).
- Nayar, S.K.; Narasimhan, S.G. Vision in bad weather. In Proceedings of the Seventh IEEE International Conference on Computer Vision, IEEE, Corfu, Greece, 20–27 September 1999; Volume 2, pp. 820–827. [Google Scholar]
- Sun, B.; Ramamoorthi, R.; Narasimhan, S.; Nayar, S. A practical analytic single scattering model for real time rendering. ACM Trans. Graph. 2005, 24, 1040–1049. [Google Scholar] [CrossRef] [Green Version]
- Narasimhan, S.G.; Gupta, M.; Donner, C.; Ramamoorthi, R.; Nayar, S.K.; Jensen, H.W. Acquiring Scattering Properties of Participating Media by Dilution. ACM Trans. Graph. 2006, 25, 1003–1012. [Google Scholar] [CrossRef]
- Guo, X.; Yu, L.; Ling, H. LIME: Low-light Image Enhancement via Illumination Map Estimation. IEEE Trans. Image Process. 2016, 26, 983–993. [Google Scholar] [CrossRef]
- Tsiotsios, C.; Angelopoulou, M.E.; Kim, T.K.; Davison, A.J. Backscatter Compensated Photometric Stereo with 3 Sources. In Proceedings of the CVPR, Columbus, OH, USA, 23–28 June 2014; pp. 2259–2266. [Google Scholar] [CrossRef] [Green Version]
- Paris, S.; Durand, F. A fast approximation of the bilateral filter using a signal processing approach. In Proceedings of the ECCV, Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 568–580. [Google Scholar]
- Chen, J.; Paris, S.; Durand, F. Real-time edge-aware image processing with the bilateral grid. ACM Trans. Graph. 2007, 26, 103-es. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yang, W.; Wang, S.; Fang, Y.; Wang, Y.; Liu, J. Band representation-based semi-supervised low-light image enhancement: Bridging the gap between signal fidelity and perceptual quality. IEEE Trans. Image Process. 2021, 30, 3461–3473. [Google Scholar] [CrossRef]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. Enlightengan: Deep light enhancement without paired supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef] [PubMed]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the ICPR, IEEE, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xue, W.; Zhang, L.; Mou, X.; Bovik, A.C. Gradient Magnitude Similarity Deviation: A Highly Efficient Perceptual Image Quality Index. IEEE Trans. Image Process. 2014, 23, 684–695. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Zhang, L.; Mou, X.; Zhang, D. FSIM: A Feature Similarity Index for Image Quality Assessment. IEEE Trans. Image Process. 2011, 20, 2378–2386. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Xu, D.; Yang, W.; Fan, M.; Huang, H. Benchmarking low-light image enhancement and beyond. Int. J. Comput. Vis. 2021, 129, 1153–1184. [Google Scholar] [CrossRef]
- Cai, J.; Gu, S.; Zhang, L. Learning a deep single image contrast enhancer from multi-exposure images. IEEE Trans. Image Process. 2018, 27, 2049–2062. [Google Scholar] [CrossRef]
- Bychkovsky, V.; Paris, S.; Chan, E.; Durand, F. Learning photographic global tonal adjustment with a database of input/output image pairs. In Proceedings of the CVPR 2011, IEEE, Colorado Springs, CO, USA, 20–25 June 2011; pp. 97–104. [Google Scholar]
- Loh, Y.P.; Chan, C.S. Getting to know low-light images with the exclusively dark dataset. Comput. Vis. Image Underst. 2019, 178, 30–42. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Datasets | SID [16] | ELD [17] | ||||||
|---|---|---|---|---|---|---|---|---|---|
| SSIM ↑ | PSNR (dB) ↑ | FSIM ↑ | GMSD ↓ | SSIM ↑ | PSNR (dB) ↑ | FSIM ↑ | GMSD ↓ | ||
| KinD++ [8] | 240 synthetic and 460 pairs in LOL-V1 [6] | 0.4340 | 12.9617 | 0.6259 | 0.2586 | 0.7443 | 21.3444 | 0.7731 | 0.2120 |
| SSIENet [25] | 485 low-light images in LOL-V1 [6] | 0.5904 | 17.0290 | 0.7301 | 0.2075 | 0.6840 | 18.9030 | 0.7923 | 0.1808 |
| LLFlow [15] | LOL-V1 [6] and VE-LOL [46] | 0.3835 | 11.8328 | 0.5569 | 0.2961 | 0.7034 | 21.7252 | 0.7961 | 0.2034 |
| DRBN [40] | 689 image pairs in LOL-V2 [29] | 0.5753 | 17.4195 | 0.7483 | 0.2173 | 0.6925 | 19.6543 | 0.8116 | 0.2363 |
| EnlightenGAN [41] | 914 low-light and 1016 normal-light images | 0.5887 | 16.8599 | 0.7321 | 0.2141 | 0.7486 | 21.5746 | 0.8244 | 0.1718 |
| HDRNet [23] | 485 low-light pairs in LOL-V1 [6] | 0.3841 | 12.0539 | 0.5661 | 0.2891 | 0.6888 | 20.6590 | 0.8039 | 0.1686 |
| ExCNet [18] | No prior training | 0.5113 | 16.7881 | 0.7069 | 0.2416 | 0.6177 | 17.7844 | 0.7167 | 0.2369 |
| Zero-DCE [21] | 3022 multi-exposure images in SICE Part1 [47] | 0.5158 | 15.1180 | 0.7265 | 0.2151 | 0.7374 | 19.2834 | 0.8317 | 0.1553 |
| cGAN [14] | 6559 images in LOL-V1 [6], MIT5k [48], ExDARK [49] | 0.5423 | 15.3855 | 0.6676 | 0.2354 | 0.6515 | 17.1118 | 0.8018 | 0.1792 |
| LIMPID | 485 image pairs in LOL-V1 [6] | 0.5478 | 17.2573 | 0.7383 | 0.2199 | 0.7280 | 23.0485 | 0.8239 | 0.1767 |
| Method | Parameters (in M) ↓ | Times (s) ↓ | FLOPs (G)↓ |
|---|---|---|---|
| KinD++ [8] | 8.275 | 0.392 | 371.27 |
| SSIENet [25] | 0.682 | 0.124 | 29.46 |
| LLFlow [15] | 17.421 | 0.287 | 286.67 |
| DRBN [40] | 0.577 | 2.561 | 28.47 |
| EnlightenGAN [41] | 8.637 | 0.057 | 16.58 |
| HDRNet [23] | 0.482 | 0.008 | 0.05 |
| EXCNet [18] | 8.274 | 23.280 | - |
| Zero-DCE [21] | 0.079 | 0.010 | 5.21 |
| cGAN [14] | 0.997 | 1.972 | 18.98 |
| LIMPID | 0.091 | 0.002 | 5.96 |
| Network | Pyramid Fusion | PSNR (dB) ↑ | SSIM ↑ | |||
|---|---|---|---|---|---|---|
| ✓ | ✓ | ✓ | ✓ | 21.41 | 0.82 | |
| ✓ | ✓ | ✓ | ✓ | 13.15 | 0.64 | |
| ✓ | ✓ | ✓ | ✓ | 21.43 | 0.80 | |
| ✓ | ✓ | ✓ | ✓ | 20.82 | 0.80 | |
| ✓ | ✓ | ✓ | ✓ | 19.55 | 0.81 | |
| ✓ | ✓ | ✓ | ✓ | ✓ | 21.76 | 0.83 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, W.; Wang, W.; Yuan, X.; Xu, X. LIMPID: A Lightweight Image-to-Curve MaPpIng moDel for Extremely Low-Light Image Enhancement. Photonics 2023, 10, 273. https://doi.org/10.3390/photonics10030273
Wu W, Wang W, Yuan X, Xu X. LIMPID: A Lightweight Image-to-Curve MaPpIng moDel for Extremely Low-Light Image Enhancement. Photonics. 2023; 10(3):273. https://doi.org/10.3390/photonics10030273
Chicago/Turabian StyleWu, Wanyu, Wei Wang, Xin Yuan, and Xin Xu. 2023. "LIMPID: A Lightweight Image-to-Curve MaPpIng moDel for Extremely Low-Light Image Enhancement" Photonics 10, no. 3: 273. https://doi.org/10.3390/photonics10030273
APA StyleWu, W., Wang, W., Yuan, X., & Xu, X. (2023). LIMPID: A Lightweight Image-to-Curve MaPpIng moDel for Extremely Low-Light Image Enhancement. Photonics, 10(3), 273. https://doi.org/10.3390/photonics10030273