Fourier Single-Pixel Imaging Based on Online Modulation Pattern Binarization


Abstract
:1. Introduction
- (1)
- The binarization Fourier basis pattern is used to replace the grayscale Fourier basis patterns to improve the modulation speed of DMD and realize fast Fourier single-pixel imaging.
- (2)
- The F2SPI-GAN method is proposed to obtain high-quality reconstruction results, in which the generator adopts double-skip connections between corresponding layers and adds an attention block to each skip connection.
- (3)
- Numerical simulation and experimentation demonstrate the effectiveness of the proposed method. The F2SPI-GAN method can achieve fast and high-quality imaging at a low-sampling rate. This work speeds up the application process for Fourier single-pixel imaging.
2. Related Work
2.1. The Method of Fourier Basis Pattern Binarization
2.2. Reconstruction Network
3. Method
3.1. Forward Imaging Model
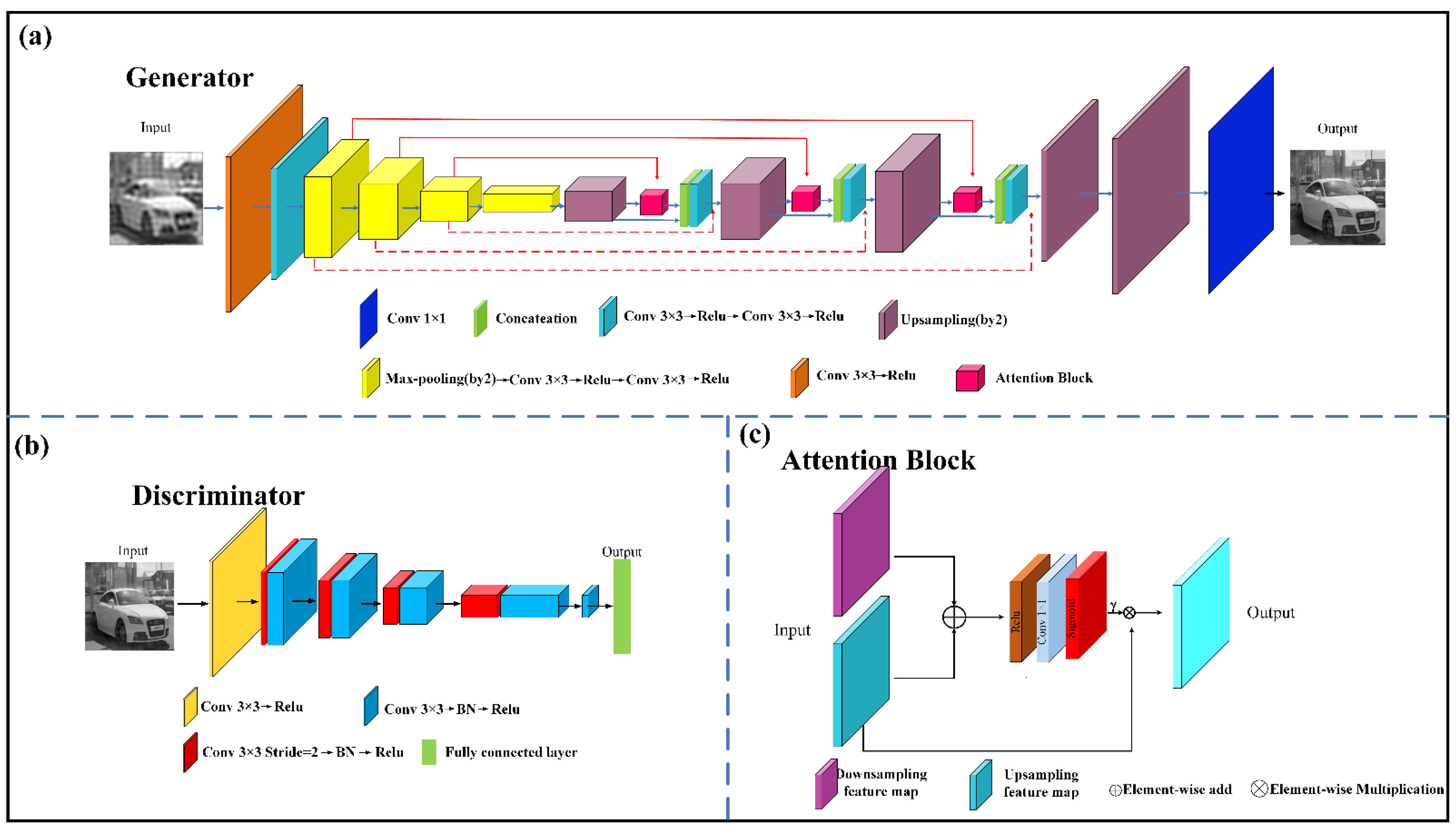
3.2. Network Architecture
- Concatenation Connection: The introduction of concatenation connections serves two primary objectives. Firstly, as the network’s depth increases, there is a risk of losing intricate image details, which might not be easily recoverable through the deconvolution process alone. The feature maps transferred via the concatenation connections hold valuable detail information that aids the deconvolution process in producing more accurate and clear reconstructions. Secondly, when employing gradient-based backpropagation during training, the concatenation connections contribute to smoother and more efficient training dynamics. This promotes better convergence and improved training stability.
- Element-wise Add Connection: The integration of element-wise addition connections proves highly beneficial, particularly due to the important analogous characteristics shared by the input and output layers. This configuration results in a discernible enhancement in performance compared to a similar network lacking element-wise added connections. Furthermore, these connections effectively mitigate the vanishing gradient problem that can arise during training, leading to a more effective optimization process and improved overall training performance.
3.3. Loss Function of F2SPI-GAN
4. Numerical Simulations and Experimental Results
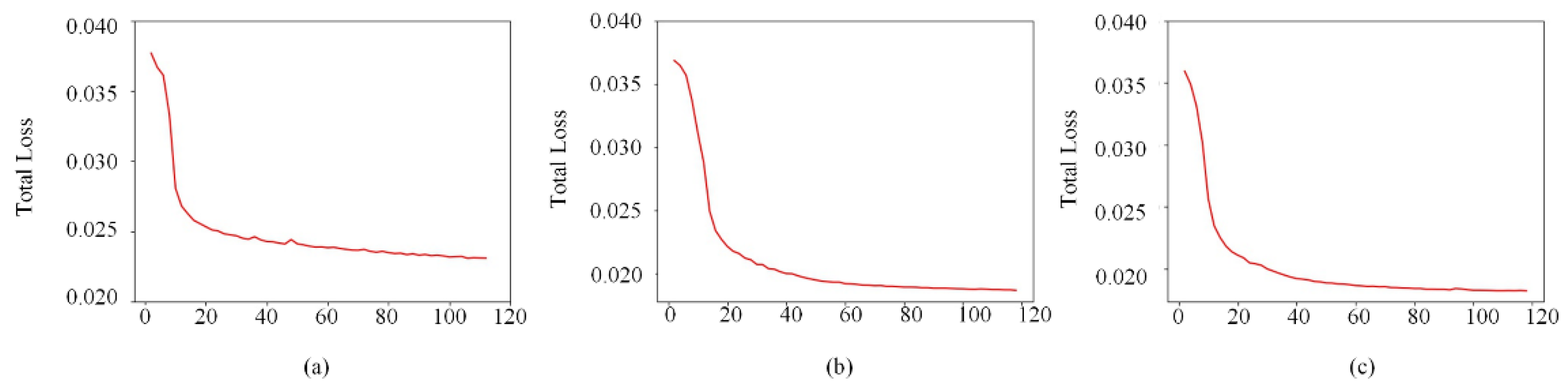
4.1. Dataset Preparation and Training Process
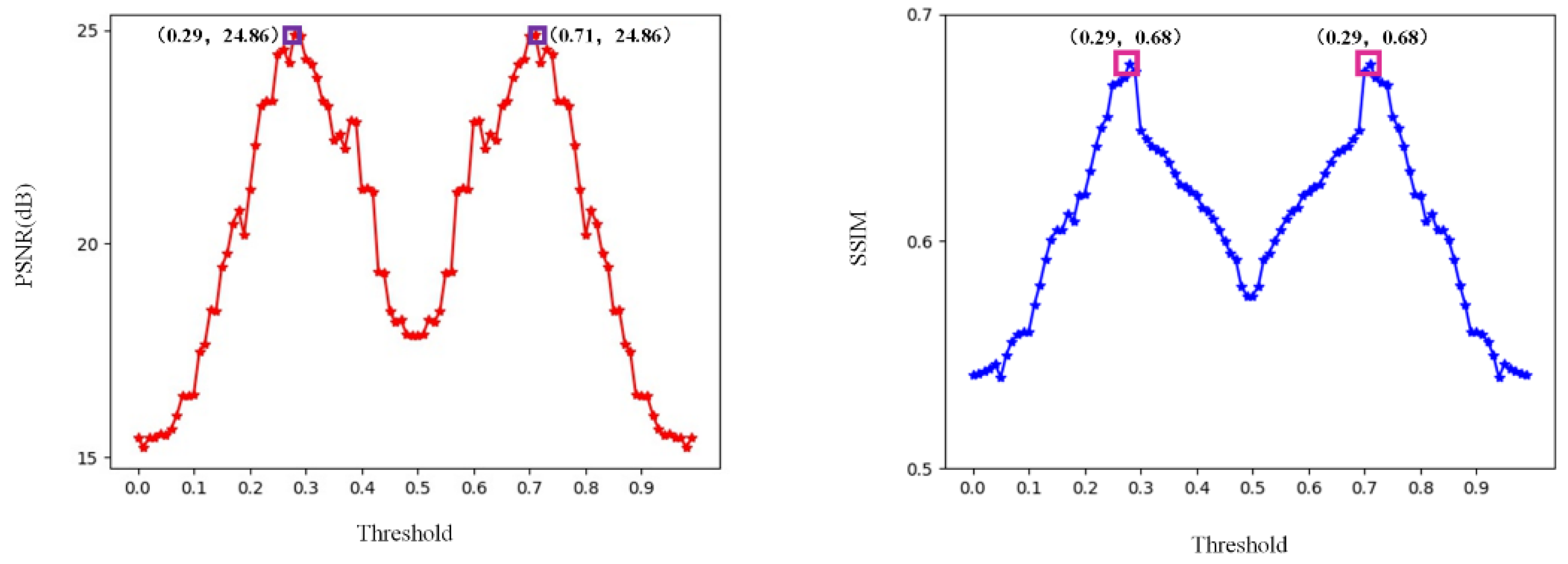
4.2. Binarization Threshold Selection Verification
4.3. Numerical Simulations of F2SPI-GAN
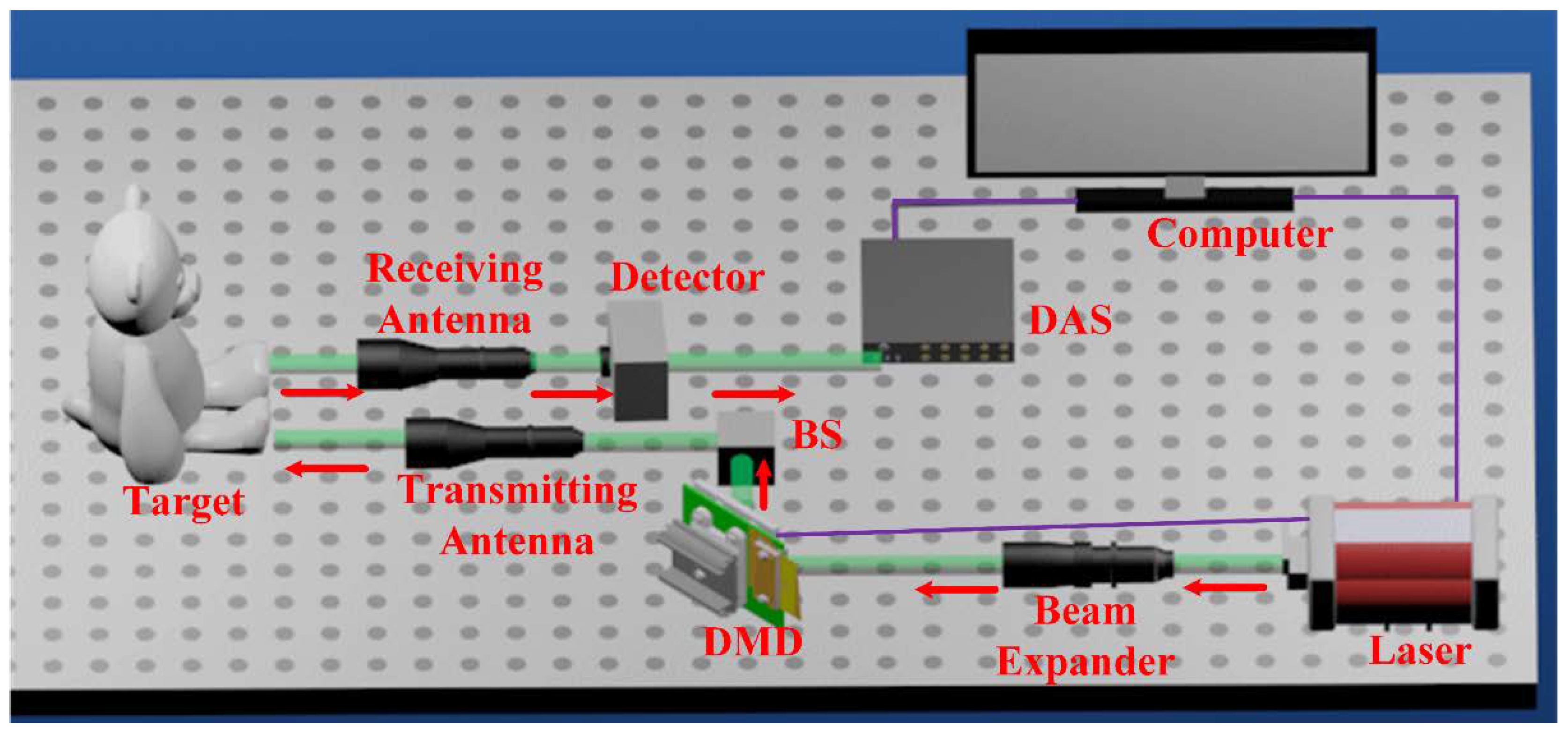
4.4. Real-World Experiments
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Edgar, M.P.; Gibson, G.M.; Padgett, M.J. Principles and Prospects for Single-Pixel Imaging. Nat. Photonics 2019, 13, 13–20. [Google Scholar] [CrossRef]
- Gibson, G.M.; Johnson, S.D.; Padgett, M.J. Single-Pixel Imaging 12 Years on: A Review. Opt. Express 2020, 28, 28190–28208. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Hu, X.; Wu, J.; Fan, K.; Chen, B.; Zhang, C.; Hu, W.; Cao, X.; Jin, B.; Lu, Y.; et al. Dual-Color Terahertz Spatial Light Modulator for Single-Pixel Imaging. Light Sci. Appl. 2022, 11, 191. [Google Scholar] [CrossRef] [PubMed]
- Olivieri, L.; Gongora, J.S.T.; Peters, L.; Cecconi, V.; Cutrona, A.; Tunesi, J.; Tucker, R.; Pasquazi, A.; Peccianti, M. Hyperspectral Terahertz Microscopy via Nonlinear Ghost-Imaging. Optica 2020, 7, 186–191. [Google Scholar] [CrossRef]
- Ma, Y.; Yin, Y.; Jiang, S.; Li, X.; Huang, F.; Sun, B. Single Pixel 3D Imaging with Phase-Shifting Fringe Projection. Opt. Laser. Eng. 2021, 140, 106532. [Google Scholar] [CrossRef]
- Jiang, H.; Li, Y.; Zhao, H.; Li, X.; Xu, Y. Parallel Single-Pixel Imaging: A General Method for Direct–Global Separation and 3D Shape Reconstruction Under Strong Global Illumination. Int. J. Comput. Vision 2021, 129, 1060–1086. [Google Scholar] [CrossRef]
- Rousset, F.; Ducros, N.; Peyrin, F.; Valentini, G.; D’Andrea, C.; Farina, A. Time-resolved multispectral imaging based on an adaptive single-pixel camera. Opt. Express. 2018, 26, 10550–10558. [Google Scholar] [CrossRef]
- Tao, C.; Zhu, H.; Wang, X.; Zheng, S.; Xie, Q.; Wang, C.; Wu, R.; Zheng, Z. Compressive Single-Pixel Hyperspectral Imaging Using RGB Sensors. Opt. Express 2021, 29, 11207–11220. [Google Scholar] [CrossRef]
- Wu, J.; Li, S. Optical Multiple-Image Compression-Encryption via Single-Pixel Radon Transform. Appl. Opt. 2020, 59, 9744–9754. [Google Scholar] [CrossRef]
- Deng, Q.; Zhang, Z.; Zhong, J. Image-free real-time 3-D tracking of a fast-moving object using dual-pixel detection. Opt. Lett. 2020, 45, 4734–4737. [Google Scholar] [CrossRef]
- Zha, L.; Shi, D.; Huang, J.; Yuan, K.; Meng, W.; Yang, W.; Jiang, R.; Chen, Y.; Wang, Y. Single-Pixel Tracking of Fast-Moving Object Using Geometric Moment Detection. Opt. Express 2021, 29, 30327–30336. [Google Scholar] [CrossRef]
- Wu, J.; Hu, L.; Wang, J. Fast Tracking and Imaging of Moving Object with Single-Pixel Imaging. Opt. Express 2021, 29, 42589–42598. [Google Scholar] [CrossRef]
- Deng, S.; Liu, W.; Shen, H. Laser Polarization Imaging Method Based on Frequency-Shifted Optical Feedback. Opt. Laser. Technol. 2023, 161, 109099. [Google Scholar] [CrossRef]
- Yu, T.; Wang, X.; Xi, S.; Mu, Q.; Zhu, Z. Underwater Polarization Imaging for Visibility Enhancement of Moving Targets in Turbid Environments. Opt. Express 2023, 31, 459–468. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Yu, Z.; Xu, L.; Hu, J.; Wu, L.; Yang, C.; Zhang, W.; Zhang, J.; Zhang, Y. Underwater Ghost Imaging Based on Generative Adversarial Networks with High Imaging Quality. Opt. Express 2021, 29, 28388–28405. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Yu, Z.; Jiang, P.; Xu, L.; Hu, J.; Wu, L.; Zou, B.; Zhang, Y.; Zhang, J. Deblurring Ghost Imaging Reconstruction Based on Underwater Dataset Generated by Few-Shot Learning. Sensors 2022, 22, 6161. [Google Scholar] [CrossRef]
- Wang, F.; Wang, C.; Chen, M.; Gong, W.; Zhang, Y.; Han, S.; Situ, G. Far-Field Super-Resolution Ghost Imaging with a Deep Neural Network Constraint. Light Sci. Appl. 2022, 11, 1. [Google Scholar] [CrossRef]
- Ma, S.; Liu, Z.; Wang, C.; Hu, C.; Li, E.; Gong, W.; Tong, Z.; Wu, J.; Shen, X.; Han, S. Ghost Imaging LiDAR via Sparsity Constraints Using Push-Broom Scanning. Opt. Express 2019, 27, 13219–13228. [Google Scholar] [CrossRef] [PubMed]
- Li, R.; Hong, J.; Zhou, X.; Li, Q.; Zhang, X. Fractional Fourier Single-Pixel Imaging. Opt. Express 2021, 29, 27309–27321. [Google Scholar] [CrossRef]
- Gao, Z.; Li, M.; Zheng, P.; Xiong, J.; Tang, Z.; Liu, H. Single-pixel imaging with Gao-Boole patterns. Opt. Express 2022, 30, 35923–35936. [Google Scholar] [CrossRef]
- He, R.; Weng, Z.; Zhang, Y.; Qin, C.; Zhang, J.; Chen, Q.; Zhang, W. Adaptive Fourier Single Pixel Imaging Based on the Radial Correlation in the Fourier Domain. Opt. Express 2021, 29, 36021–36037. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.-N.; Hou, H.-Y.; Han, J.-C.; Cao, D.-Z.; Zhang, S.-H.; Liu, H.-C.; Liang, B.-L. Complex-Amplitude Fourier Single-Pixel Imaging via Coherent Structured Illumination. Chin. Phys. B 2022, 32, 064201. [Google Scholar] [CrossRef]
- Wenwen, M.; Dongfeng, S.; Jian, H.; Kee, Y.; Yingjian, W.; Chengyu, F. Sparse Fourier Single-Pixel Imaging. Opt. Express 2019, 27, 31490–31503. [Google Scholar] [CrossRef] [PubMed]
- Qiu, Z.; Guo, X.; Lu, T.; Qi, P.; Zhang, Z.; Zhong, J. Efficient Fourier Single-Pixel Imaging with Gaussian Random Sampling. Photonics 2021, 8, 319. [Google Scholar] [CrossRef]
- Rizvi, S.; Cao, J.; Zhang, K.; Hao, Q. Improving Imaging Quality of Real-Time Fourier Single-Pixel Imaging via Deep Learning. Sensors 2019, 19, 4190. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, X.; Zheng, G.; Zhong, J. Fast Fourier Single-Pixel Imaging via Binary Illumination. Sci. Rep. 2017, 7, 12029. [Google Scholar] [CrossRef]
- Huang, J.; Shi, D.; Yuan, K.; Hu, S.; Wang, Y. Computational-Weighted Fourier Single-Pixel Imaging via Binary Illumination. Opt. Express 2018, 26, 16547–16559. [Google Scholar] [CrossRef]
- Li, J.; Cheng, K.; Qi, S.; Zhang, Z.; Zheng, G.; Zhong, J. Full-resolution, full-field-of-view, and high-quality fast Fourier single-pixel imaging. Opt. Lett. 2023, 48, 49–52. [Google Scholar] [CrossRef]
- Yang, X.; Jiang, P.; Jiang, M.; Xu, L.; Wu, L.; Yang, C.; Zhang, W.; Zhang, J.; Zhang, Y. High Imaging Quality of Fourier Single Pixel Imaging Based on Generative Adversarial Networks at Low Sampling Rate. Opt. Lasers Eng. 2021, 140, 106533. [Google Scholar] [CrossRef]
- Jiang, P.; Liu, J.; Wu, L.; Xu, L.; Hu, J.; Zhang, J.; Zhang, Y.; Yang, X. Fourier Single Pixel Imaging Reconstruction Method Based on the U-Net and Attention Mechanism at a Low Sampling Rate. Opt. Express 2022, 30, 18638–18654. [Google Scholar] [CrossRef]
- Falk, T.; Mai, D.; Bensch, R.; Çiçek, Ö.; Abdulkadir, A.; Marrakchi, Y.; Böhm, A.; Deubner, J.; Jäckel, Z.; Seiwald, K.; et al. U-Net: Deep Learning for Cell Counting, Detection, and Morphometry. Nat. Methods 2019, 16, 67–70. [Google Scholar] [CrossRef] [PubMed]
- Schlemper, J.; Oktay, O.; Schaap, M.; Heinrich, M.; Kainz, B.; Glocker, B.; Rueckert, D. Attention Gated Networks: Learning to Leverage Salient Regions in Medical Images. Med. Image Anal. 2019, 53, 197–207. [Google Scholar] [CrossRef] [PubMed]
- Mao, X.-J.; Shen, C.; Yang, Y.-B. Image Restoration Using Very Deep Convolutional Encoder-Decoder Networks with Symmetric Skip Connections. Advances in Neural Information Processing Systems 29. 2016. Available online: https://proceedings.neurips.cc/paper_files/paper/2016/hash/0ed9422357395a0d4879191c66f4faa2-Abstract.html (accessed on 21 August 2016).
- Rajinikanth, V.; Joseph Raj, A.N.; Thanaraj, K.P.; Naik, G.R. A Customized VGG19 Network with Concatenation of Deep and Handcrafted Features for Brain Tumor Detection. Appl. Sci. 2020, 10, 3429. [Google Scholar] [CrossRef]
- Krause, J.; Stark, M.; Deng, J.; Fei-Fei, L. 3D Object Representations for Fine-Grained Categorization. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, NSW, Australia, 2–8 December 2013; pp. 554–561. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
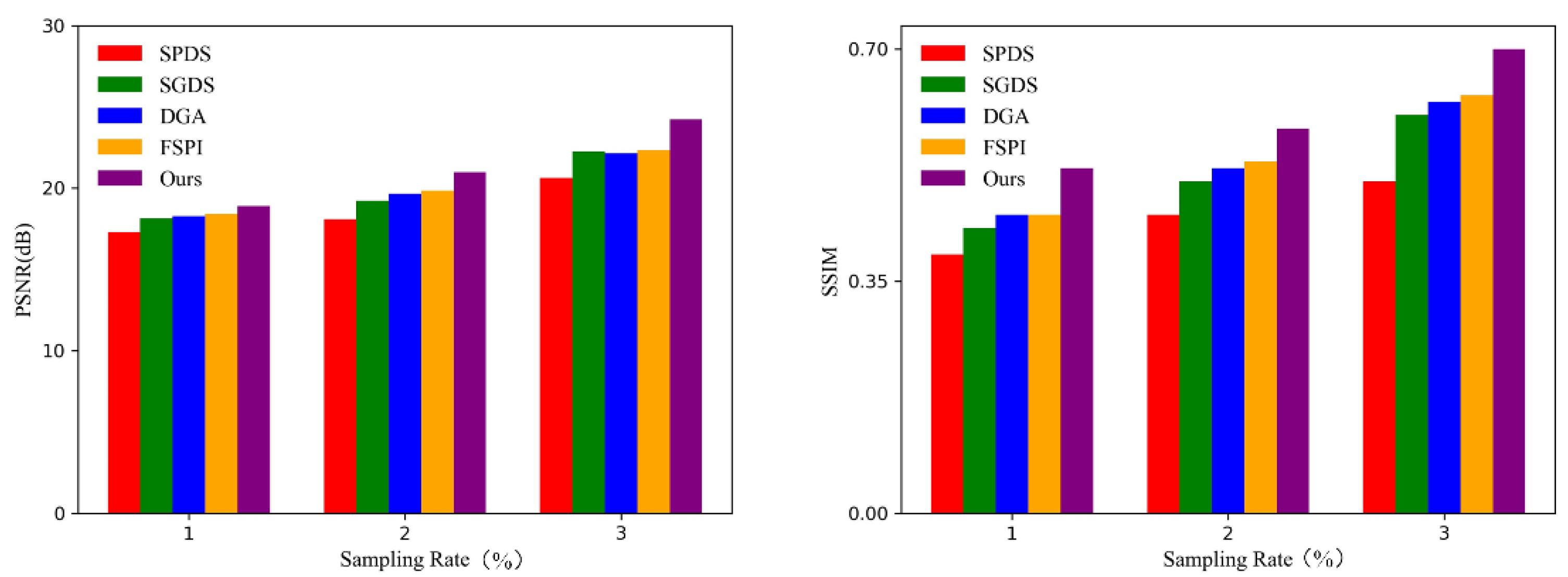{kind=link}
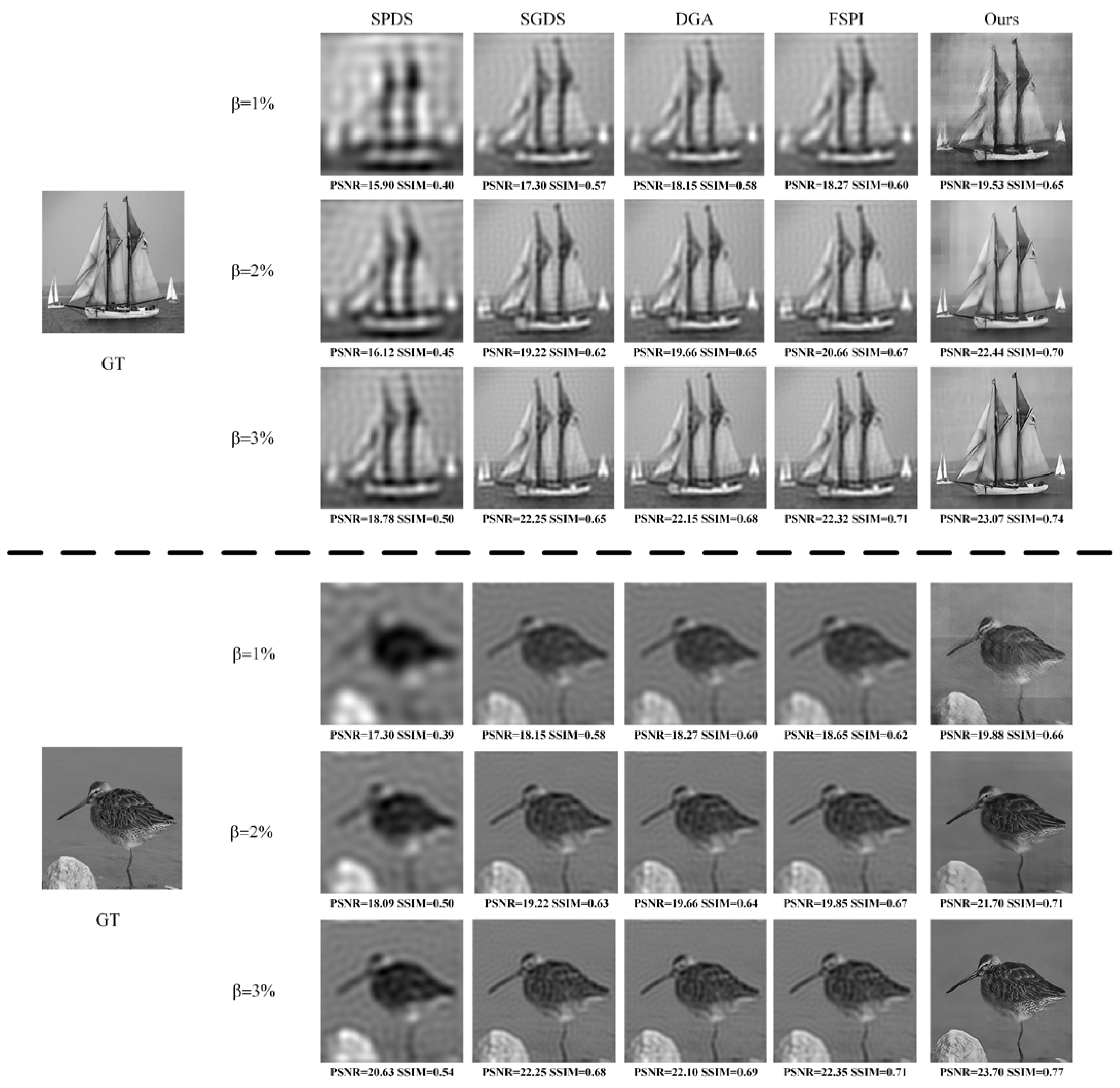{kind=link}
{kind=link}
| Method | IDAQ | IIFT | IRES | IT |
|---|---|---|---|---|
| SPDS | 1.311 s | 4 ms | / | 1.314 s |
| SGDS | 7.864 s | 4 ms | / | 7.868 s |
| DGA | 2.621 s | 4 ms | / | 2.625 s |
| FSPI | 9.039 s | 4 ms | / | 9.043 s |
| Ours | 1.311 s | 4 ms | 14 ms | 1.329 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, X.; Tong, Z.; Yu, Z.; Jiang, P.; Xu, L.; Wu, L.; Chen, M.; Zhang, Y.; Zhang, J.; Yang, X. Fourier Single-Pixel Imaging Based on Online Modulation Pattern Binarization. Photonics 2023, 10, 963. https://doi.org/10.3390/photonics10090963
Jiang X, Tong Z, Yu Z, Jiang P, Xu L, Wu L, Chen M, Zhang Y, Zhang J, Yang X. Fourier Single-Pixel Imaging Based on Online Modulation Pattern Binarization. Photonics. 2023; 10(9):963. https://doi.org/10.3390/photonics10090963
Chicago/Turabian StyleJiang, Xinding, Ziyi Tong, Zhongyang Yu, Pengfei Jiang, Lu Xu, Long Wu, Mingsheng Chen, Yong Zhang, Jianlong Zhang, and Xu Yang. 2023. "Fourier Single-Pixel Imaging Based on Online Modulation Pattern Binarization" Photonics 10, no. 9: 963. https://doi.org/10.3390/photonics10090963
APA StyleJiang, X., Tong, Z., Yu, Z., Jiang, P., Xu, L., Wu, L., Chen, M., Zhang, Y., Zhang, J., & Yang, X. (2023). Fourier Single-Pixel Imaging Based on Online Modulation Pattern Binarization. Photonics, 10(9), 963. https://doi.org/10.3390/photonics10090963