1. Introduction
Peaches, belonging to the variety of
Prunus persica, contain a unique taste, flavor, sweetness and texture. They are rich in vitamin C, carotene, pectin, and many kinds of trace elements such as zinc and selenium [
1], and are widely welcomed by a broad range of ages. With the upgrade of consumption and living quality, consumers pay more attention to the internal quality of fruit, not just the external. Soluble solids content (SSC) is an important indicator of maturity and is commonly used to estimate the internal quality of a peach. The degree of SSC highly relates to the sensory and acceptance of consumers, and further influences the shelf-life price of fruit [
2,
3]. Obviously, SSC plays an important role to improve the competitiveness of fruit products and market economic value.
Currently, determination of peaches’ SSC mainly depends on the destructive refractometry detection method, it can obtain high precision, but it destroys the integrity of fruit samples, causing damage of fruit and affecting secondary sales. At the same time, the speed of the refractometry method is just for random determination, and thus it is not suitable to detect high-throughput samples [
4]. Therefore, the realization of a simple and rapid non-destructive determining technology for the internal quality of peaches, can not only improve the market economic value of peach fruit, but also standardize the management of the peach market and promote the income of fruit farmers, which has important guidance for the industrial upgrading of the fruit market [
5,
6,
7].
As an instrumental analytical technique, near infrared spectroscopy (NIRS) is well-known in sensing components of material [
8,
9]. Its major benefit is a non-destructive method, and usually just a simple, or no preparation, needs to be performed. It can yield an online response for analysis during manufacturing, being rapid, non-invasive, very flexible and robust. NIRS technology has been reportedly widely used in food, agriculture and medical areas [
4,
5,
10], especially in the rapid detection of fruit internal quality, such as pear [
11], orange [
12], apple [
13,
14]. In order to replace the destructive refractometry detection method, it is essential to guarantee accurate predictions by the application of NIRS technology. For modeling the relationship between spectral data and quality attributes, classical statistical methods of multivariate analysis, such as multiple linear regression (MLR), principal component regression (PCR) and partial least squares (PLS) have to be considered.
However, visible-near infrared spectra (Vis-NIR) usually contains hundreds of spectral variables, which not only contain useful information, but also involve a variety of invalid information, and there exists the co-linear problem between neighboring spectral variables [
15,
16]. It is therefore necessary to employ the screening methods aimed at reducing the dimension of spectra. Many variable selections have been proposed to select the informative variables and get the performance of model improved [
17], such as competitive adaptive re-weighted sampling (CARS), successive projections algorithm (SPA), uninformative variable elimination (UVE), simulated annealing (SA), and genetic algorithm (GA). But some selection methods enhance the predictive ability of models, and meanwhile increase the uncertainty of variable selection, including the number and the selected variables and their combinations, such as GA, which is proposed on the basis of evolutionary theory, that the ‘best’ individuals (i.e., wavelengths or variables) have a better chance to survive and a larger probability to spread their genomes by reproduction in a living system [
16,
17,
18,
19,
20].
At present, most modeling methods adopt a single or uni-vocal model to quantitatively predict the quality of fruit. One single model can overcome some kind of disturbance factor, but it can not avoid the influences of many other disturbance factors [
21,
22]. Those above variable selection methods can go through certain rules to obtain the best combination of useful variables, so as to make the model achieved of the best predictive performance. However, this commonly intends to overcome the interference of one specific factor. As for the GA method, the combination of the ‘best’ individuals varies from the initial genomes, and thus leads to a different number of variables and different spectral wavelengths. When GA is used to optimize the spectral model, the combination of the selected variables is differently varied from each running. This is going to increase the uncertainty of the result by the operation of GA. Besides, is there any useful information among the remaining variables? This should be explored. The full spectral variables involved in the model usually contain some redundant and irrelevant information, which complicates the model and reduces the prediction accuracy of the model. With utilization of GA variable selection, the performance of the calibration model can be enhanced, but results in uncertainty of the combination of the selected variables and the loss of information in residual variables, and different individuals are likely to lead to different results [
17,
23,
24].
To solve these problems, in this work the fusing strategy of the consensus model was proposed to combine the GA variable selection algorithm at the decision level of the member models, aiming to improve the prediction accuracy and reduce the uncertainly of the model [
17,
22,
25,
26,
27]. The regression member models were developed between the main indicator SSC of peaches and their interactive spectra. Member models were used to construct the consensus model through arranging the weightings according to their performances. One was the optimized model PLS
GA, which was developed with the selected variables by the GA method, and another was the PLS
RV model, which was developed with the residual variables that were not selected in the above GA running. It should be noted that more batches and orchards of peaches harvested with different degrees of maturity using vis-NIR spectroscopy need to be investigated, and thus the applicability of the developed model should be robust and achieve generalized feasibility.
2. Materials and Methods
2.1. Sample Preparation
The bagging juicy peaches of cultivar Xinchuanzhongdao were harvested at the period of harvestion at the end of July 2020 in Wenzhou city, Zhejiang province, China. Peach samples were collected every other day and, in total, four batches of peaches were arranged in this work. After transporting to the lab, peaches were unbagged to discard improper samples by technicians, and a total of 266 samples were selected without diseases, pests and mechanical damage et al., and were stored in an air-conditioned room of 22 °C for at least 6 h. The range of equatorial diameter of these peaches was in 45~75 mm and the weights were in between 110~330 g. Samples were orderly numbered and three sites were marked on samples’ equatorial line with equal interval, for subsequent measurements of spectral signal and reference value.
2.2. Spectral Acquisition
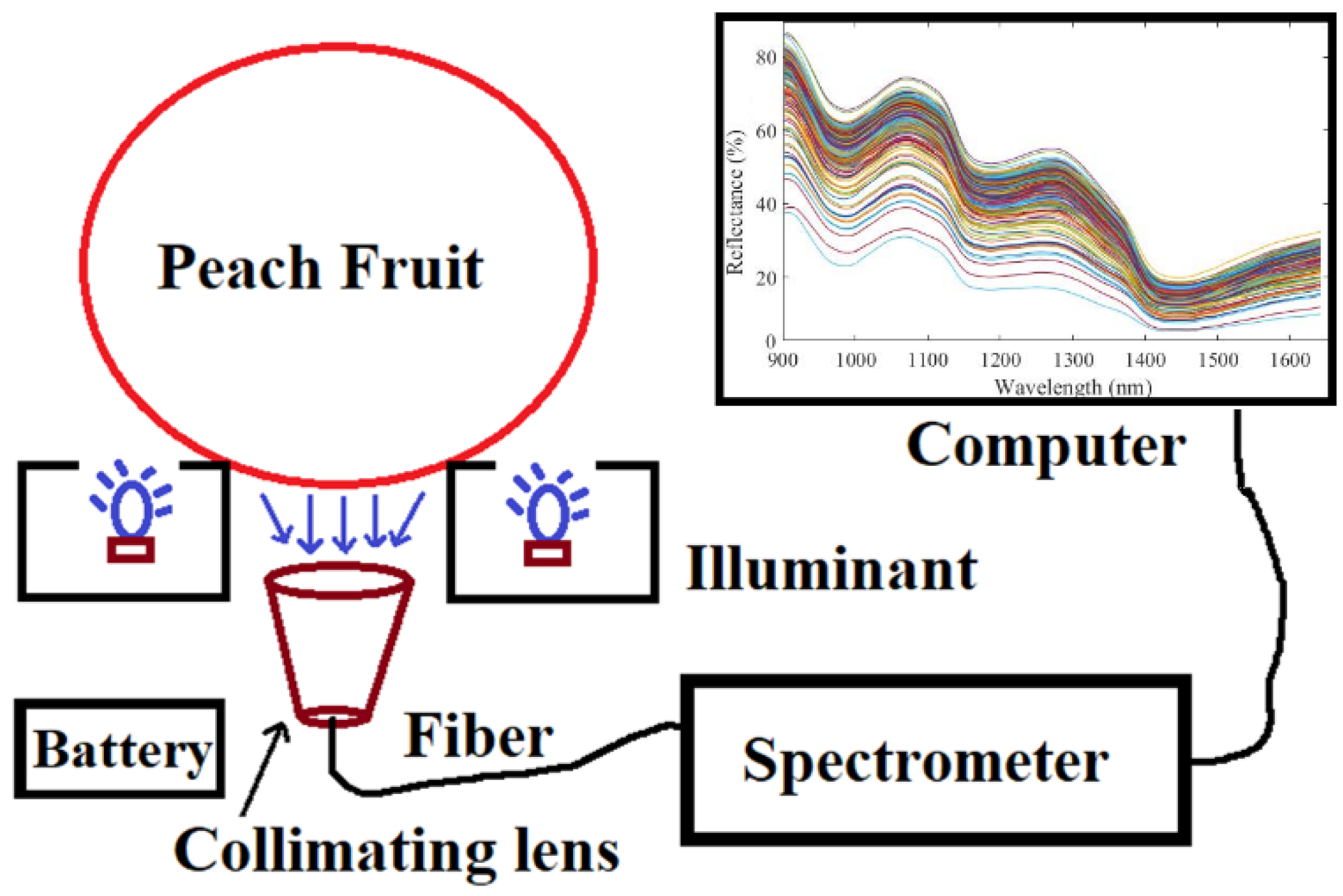
Interactance spectra of peaches are collected by an integrated portable NIR analyzer (
Figure 1), which is embedded with a commercial spectrometer (Model: flame-NIR, ocean Optics Inc., Dunedin, FL, USA), battery module, halogen sources (MR11, 12V 20W, Orsam) and a soft gasket holder for supporting the peach sample. Four halogen light sources are arranged symmetrically through the light channels upward to the sample’s holder. A soft silicone gasket is attached to the holder (with a diameter range of 10~15 mm), and thus it not only prevents the sample from moving, but also minimizes the interference of external light into the detector. The local penetrating signal of peach is filtered by a collimating lens and through the optical fiber transferring into the entrance of the flame-NIR spectrometer. The scanning band range of the spectrometer is 902.59~1648.61 nm with a resolution of 20.0 nm, and the number of spectral wavelengths is 227. The scanning parameter is set as the integration time of 0.2 s, a smoothing window of size 3, and the average scanning number of 4. In this experiment, spectral data are recorded from three different sites of each peach, and then the average spectrum is calculated as the final spectral curve of each peach sample.
2.3. Measurement of Soluble Solids Content
A digital refractometer PAL-1 (Atago Co., Ltd., Tokyo, Japan) is used to measure the soluble solids content (SSC) of peach with a precision of ±0.1% Brix. After peeling, the pulp is obtained around three marked sites (i.e., the spectral reading point), and mixed to squeeze into juice. The juice is measured on the digital refractometer. This process was repeated three times, and their values were averaged as SSC value for the peach sample.
2.4. Multivariable Data Analysis
Pretreatments, including the first derivation with Savitzky–Golay smoothly moving, using five points of second polynomial order (S-G D1st), multiplicative scatter correction (MSC), mean centering (MC) and standard normal variate (SNV), are employed to improve the quality of spectra and promote the ratio of signal to noise.
GA is used to select the “best” individuals (i.e., spectral variables) that have a greater chance of surviving and a higher probability to pass on their genomes by the reproduction of evolutionary theory [
19]. There are five primary steps contained in the spectral variables’ selection, and they are: variable encoding, population initiation, response evaluation, reproductions, and population. In the stage of the first two steps, the encoded genomes are varied, and thus the result of each GA’s operation is changed. Therefore, usually more than five runs are performed on the spectral data to select the optimized combination of spectral variables [
13].
Partial least square (PLS) is used to develop a quantitative model between spectral data and peaches’ attributes. Spectra are above the “best” individuals selected by the GA program, and are mapped into an orthogonal linear space, where the top several latent variables (LVs) accumulate useful spectral information, and the number of LVs in the PLS model is determined by the smallest RMSECV in the calibrating stage and considered as the optimal mappings corresponding to fit attributes [
28].
From the view of the fusing level [
26], in this work, the decision level of fusing strategy is adopted to construct the consensus model, which integrates several member models, rather than one single model. Based on the consensual rule, two or more member models are assigned with different weighting coefficients according to the significant degree of member models [
11,
25]. It can reduce the dependence of a single model to weaken the influence of some specific correlated factors. Its mathematical expression principle is that: (1) consensus model
F(
x) is expressed as the linear combination (Equation (1)) of
n member models with weightings of
wk; (2) the constraint conditions are required the minimization of summed residuals squares, and the weightings
wk in the range of 0~1, and their accumulation equals to 1 (Equation (2)); (3) the inferred surplus of
is solved by the Lagrange multiplier method [
25], where
ek was the predicted residual of the
kth member model.
where
is inferred from Equation (3), and its error
can be calculated as further expansion of Equation (4).
It is assumed that the predicted deviation ek obeys the normal distribution , and represents the ignored random factors in the k-th member model. These random factors are assumed to be independent of each in member models, and thus the array of {e1, e2, …, en}, as well as the final predicted deviation e in the developed consensus model should approximately obey the normal distribution. Thus, the impacts of error vector correlation in member models can be ignored, and in Equation (4) can be assumed.
All calculations in this study were performed in the MATLAB software (R2018a, Math Works Inc., Natick, MA, USA). The PLS algorithm was performed using the iToolbox [
28]. The fusion codes were programed referring to the above formulas.
3. Results
3.1. Distribution of SSC
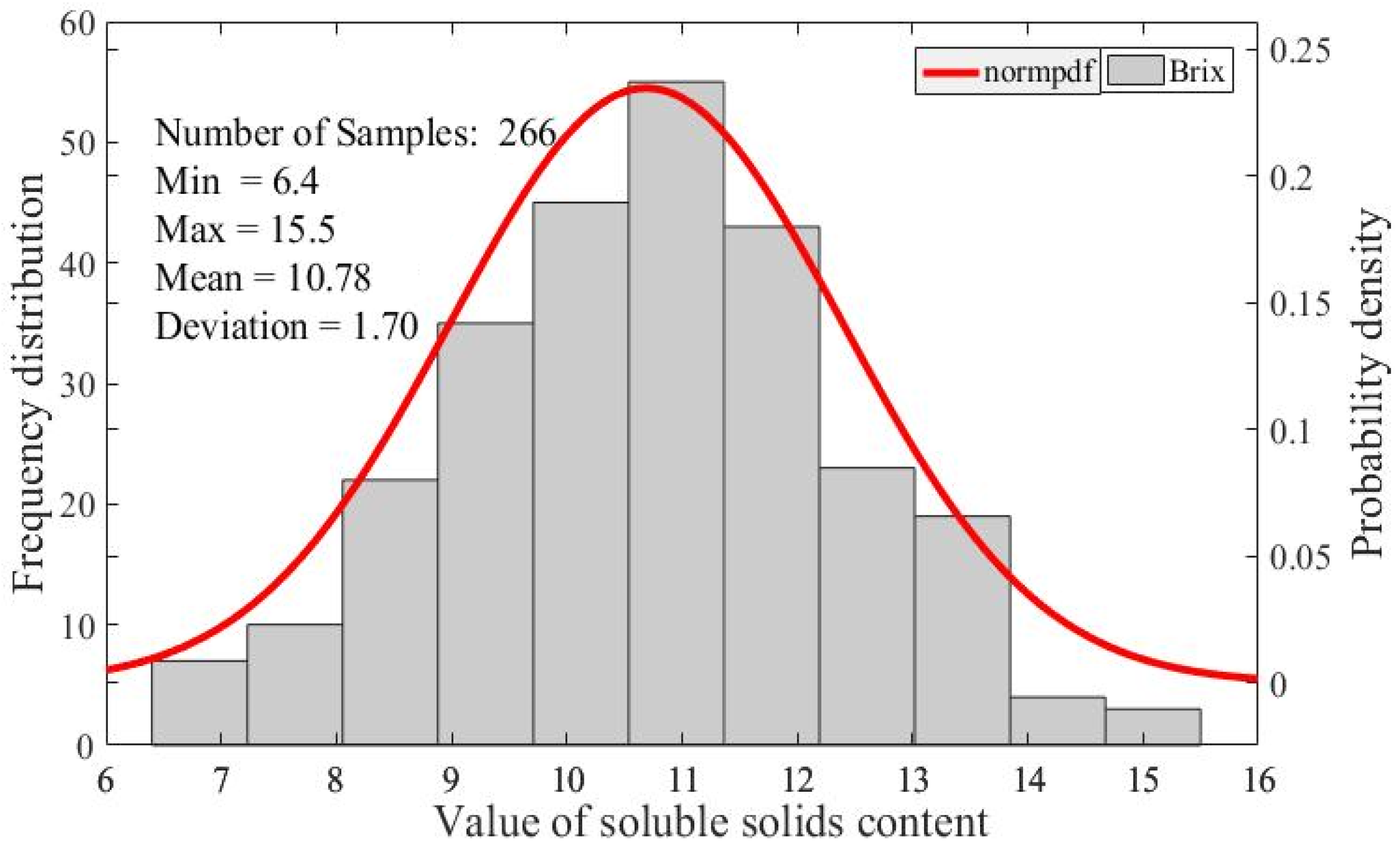
The histogram of peaches’ SSC is shown in
Figure 2. Values of SSC in these 266 samples are distributed normally in the range of 6.4 ~15.5%, and the average value is 10.89% with a standard deviation of 1.7%. The range of the ‘Xinchuanzhongdao’ cultivar’s SSC measured in this research is similar to that of ‘Hongmi’ cultivar [
29] and ‘Aurora-1’ cultivar peach fruit [
30], indicating the random harvest of sample fruits with a small difference of SSC between peaches’ cultivars. It also observes that during the period of harvest the maturity of peaches is in a broad range, inferred by the distribution of peaches’ SSC.
A total of 266 samples were divided into two subsets with the ratio of 2:1 by a typical duplex method as shown in
Table 1. One is the calibration subset, used to construct and train the calibration regression model, and the other one is the prediction subset, used to validate the feasibility of the developed regression model. The mean of SSC values in these two subsets are close, indicating that the homogeneous distribution of divisions is made to evenly develop the regression model.
3.2. Spectral Analysis and Pretreatment
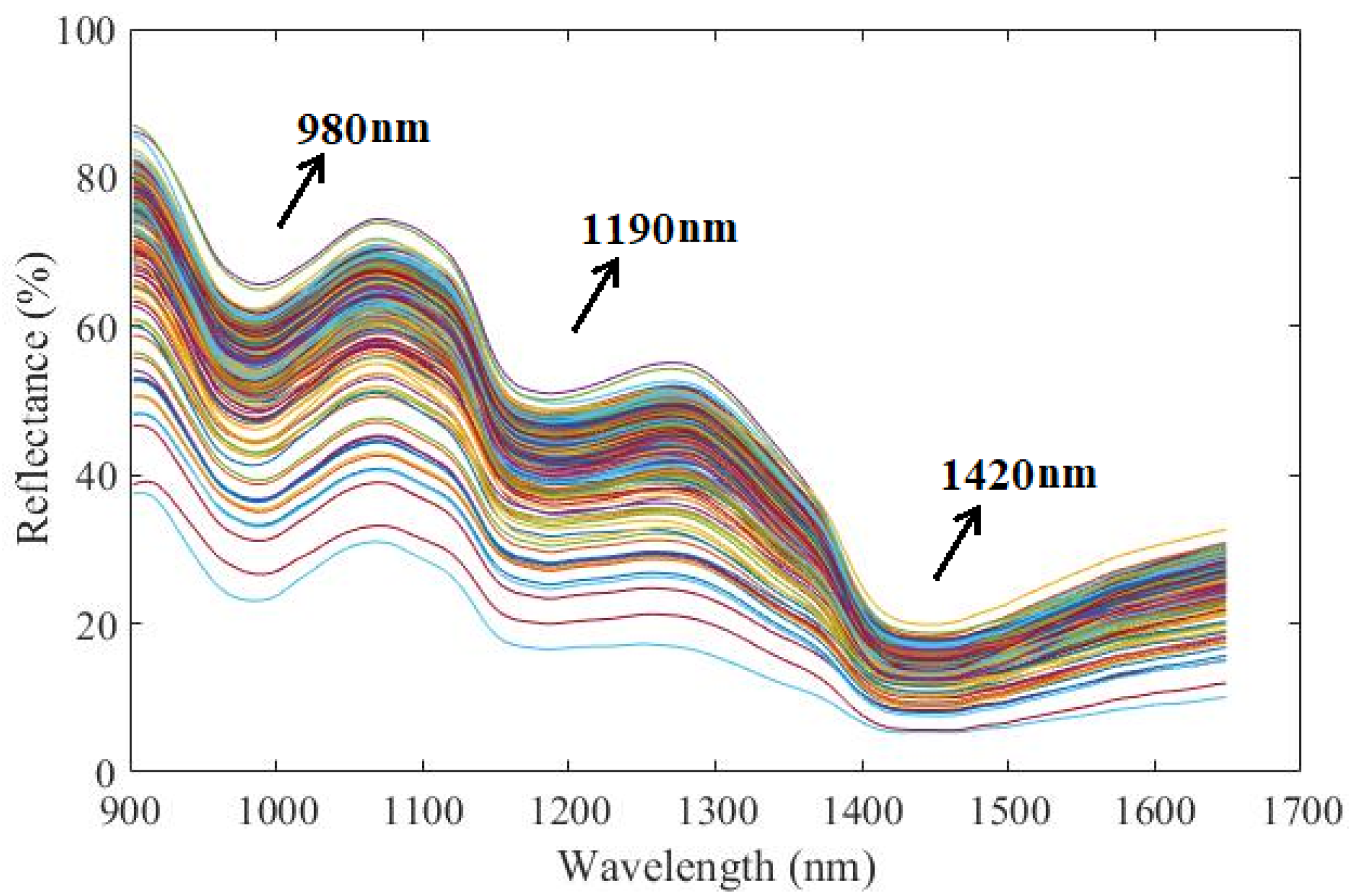
Figure 3 shows the original near infrared reflectance spectra of 266 peach samples, whose spectral tendency are consistent but with differences of spectral intensity. There are several valleys, mainly around at 980 nm, 1190 nm, and 1420 nm involved in the peach’s spectrum, indicating the absorption of energy by special functional groups of molecules [
31]. The valley at 980 nm is referred to associate with the second overtone of the O-H group. The valley at 1190 nm is related to the combination of C-H stretching, C-O stretching and O-H stretching groups in some macro-molecular substances, such as cellulose, pectin and starch. The strong absorption valley at 1420 nm is due to the first overtone of N-H stretching and the first overtone of O-H stretching groups, mainly caused by the 85–95% moisture in the intact peach fruit [
32]. Obviously, the spectral absorptions are correlated to the functional groups of samples’ attributes by the naked-eye, but the concentration value of attributes could not be given out through direct observation of the NIR spectral profile due to its severely overlapped information and the multivariate data modeling analysis needed for prediction.
To enhance the spectral efficient information and promote the performance of PLS calibration models, four different spectral pretreatments were employed to process the original spectra, and then the pre-processed spectra in the calibration subset were fully used to construct the PLS model, with cross validation in optimizing the number of latent variables (LVs).
Table 2 shows the statistical results of the developed PLS models’ performances in predicting the SSC of peaches. By comparison of parameters RMSE,
r and
Bias in these models, corresponding to pretreatments of SNV, MSC and MC, the PLS model based on the full pre-processed spectra obtained better performances than those without any pre-processed method, except that the performance of the PLS model with S-G D1
st pretreatment was worse. It may be explained that the differential operation not only removes the uninformative background signals, but also magnifies local noise involved in the spectra. The PLS model with MC pre-process had the best performance than any others, providing RMSECV of 1.017%brix in the cross validation stage, and RMSEP of 1.129%brix in the prediction stage. Clearly, MC can improve the ratio of signal to noise in the original spectra and reduce variations between spectra of multiple batches of peaches [
22], concerned on enhancing the predictive ability of the developed PLS model, reducing the RMSEP by 1.14%.
3.3. Variables Selected by GA Method
Since the above full spectral wavelengths are used to construct the quantitative PLS model, which comprises some redundant and useless variable information, this may compromise the predictive accuracy of the model. In this study, the commonly used genetic algorithm (GA) is adopted on the MC pre-processed spectra and the variables selected by the GA method are used to develop the PLS model (PLSGA, labelled as fi1), while the residual variables (that are unselected) are also used to develop the PLS model (PLSRV, labelled as fi2). Due to the random encoding of spectral wavelengths, 10-time runs of the GA method (more than 30 runs are taken out) are carried out successively, and the selected and the residual spectral variables are recorded for subsequent modeling.
Table 3 shows the statistical results of PLS member models’ performances in predicting the SSC of peaches by optimization of the GA method. Compared with the full spectral-based PLS model, the predictive performances of PLS
GA models are improved by less spectral variables. Parameter
Rcv of PLS
GA models are in the range of 0.811~0.832, and are clearly higher than that of the previous full spectral-based PLS model. RMSECV are all reduced and in the range of 0.9~0.954%. Compared to the original full spectral-based PLS model, the averaged RMSECV in these 10 PLS
GA models reduces from 10.1 percent to 0.926%, and in terms of predicting external samples, the RMSEP averagely reduces 2.3 percent to 1.116%. Among these optimized PLS
GA models, the 6th and 9th PLS
GA models are performed better than others. Meanwhile, just a small number of spectral variables are selected to develop these calibration models, and their performances get better than that of the original PLS model. The above shows that the GA method can reduce partial interference or useless information, and enhance the predictive captivity of the regression model.
Taking a close observation on
Table 3, PLS
RV models that are developed with the residual variables performed not worse, and some are closed to the original PLS model with the RMSECV in these PLS
RV models ranging from 1.055~1.096%. In terms of predicting, some PLS
RV models also performed well on the external samples. What is interesting is that the residual variables, not selected as the “best individuals” in the routine of GA processing, also comprise some useful spectral wavelengths through modeling. It can be said that PLS
RV models developed with the residual variables can achieve nearly approximate performance as the full-spectra-based models.
3.4. Fusion of Member Models
In order to make full use of the information from spectra, and to further improve the performance of the calibration model, the consensual regression model (
Fc) was proposed to integrate above two regression models, and they were PLS
GA model based on GA selected variables and PLS
RV models based on residual variable through GA runs, respectively. Thus, the
i-th consensual model (
Fic) was constructed based on the
i-th PLS
GA (
fi1) and the
i-th PLS
RV (
fi2) by the formula Equations (1) and (2) at the period of
i-th running of the GA program, and a total of 10
Fc models were obtained. Then, samples in the calibration set and prediction set were put into each consensual model, and parameters of prediction were counted, and are shown in
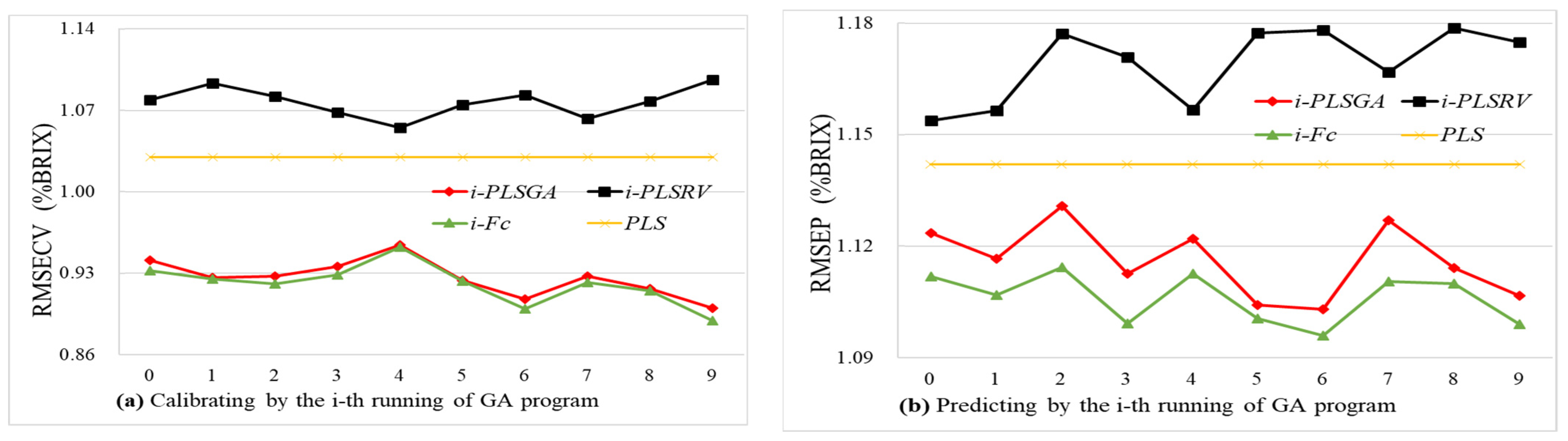
Figure 4.
It can be seen from
Figure 4a that the root mean squared error of cross-validation (i.e., RMSECV) in the calibration set by the consensus model (
Fc) is close to or slightly lower than that of the corresponding PLS
GA model (
fi1), and the tendency of these two models’ performances are consistently validated in the calibration set. However, it turns out to be completely different in the prediction stage. The consensus model obtained the average RMSEP of 1.106% with a standard deviation of 0.0068, while the optimized PLS
GA model achieved the averaged RMSEP of 1.116% with a standard deviation of 0.0097. In
Figure 4b, each consensus model (
Fc) performed better than the optimized PLS
GA model (
fi1) in predicting the prediction set, and their performances (
Fc) were promoted with an average of 2.27% in the range of 0.98~3.42% in the calibration set, and were enhanced an average of 3.14% in the range of 2.57~4.03% in the prediction set compared to the original PLS model. Among these, the
F6c consensual model reduced RMSRP to 1.096% with the highest improvement of predictive capacity. Obviously, consensual models among these developed models trended to be more stable with small fluctuations in the prediction stage.
Among these series of continuous running PLSGA, PLSRV, and consensual models, overall, PLSGA performed better than PLSRV, and meanwhile the consensual model performed better than PLSGA. In rare cases, concerning the prediction stage, the PLSRV model performed approximately to the PLSGA model and the full-spectral-based PLS model. On the one hand, although “the best individuals” useful variables are filtered out from the full spectra by the GA method, the residual spectral variables still contain some that can reflect the internal quality of peach fruit. On the other hand, a genetic algorithm is not deterministic to construct PLS model, but is a relatively well-behaved approach to optimize the combination of spectral variables.
To sum up, the consensual modeling approach makes full use of the spectral information in avoiding the loss of remaining spectral variables, and fuses member models into a consensual measurement on highlighting the individuality of member models and compressing their commonality, and thus to improve the prediction performance of consensual models, and avoid the uncertainty caused by genetic algorithms or other variable selection methods.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}