A Computer Vision System Based on Majority-Voting Ensemble Neural Network for the Automatic Classification of Three Chickpea Varieties

 , , ,
, , ,  and
and 
Abstract
:1. Introduction
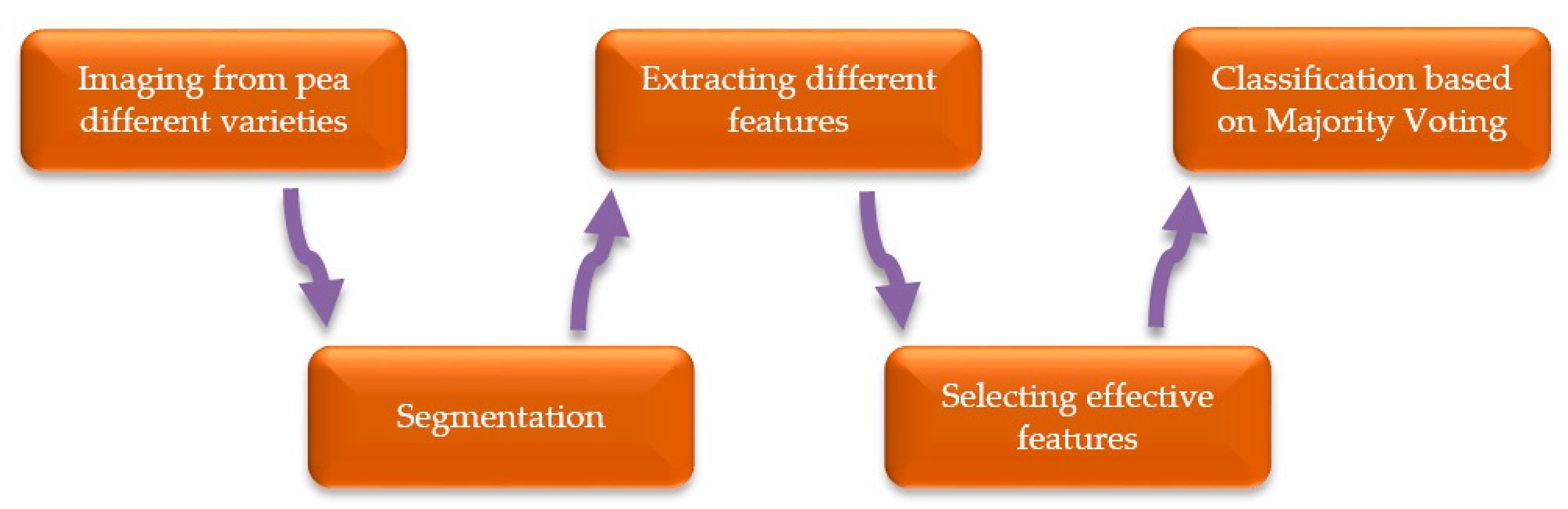
2. Materials and Methods
2.1. Varieties of Chickpea Used
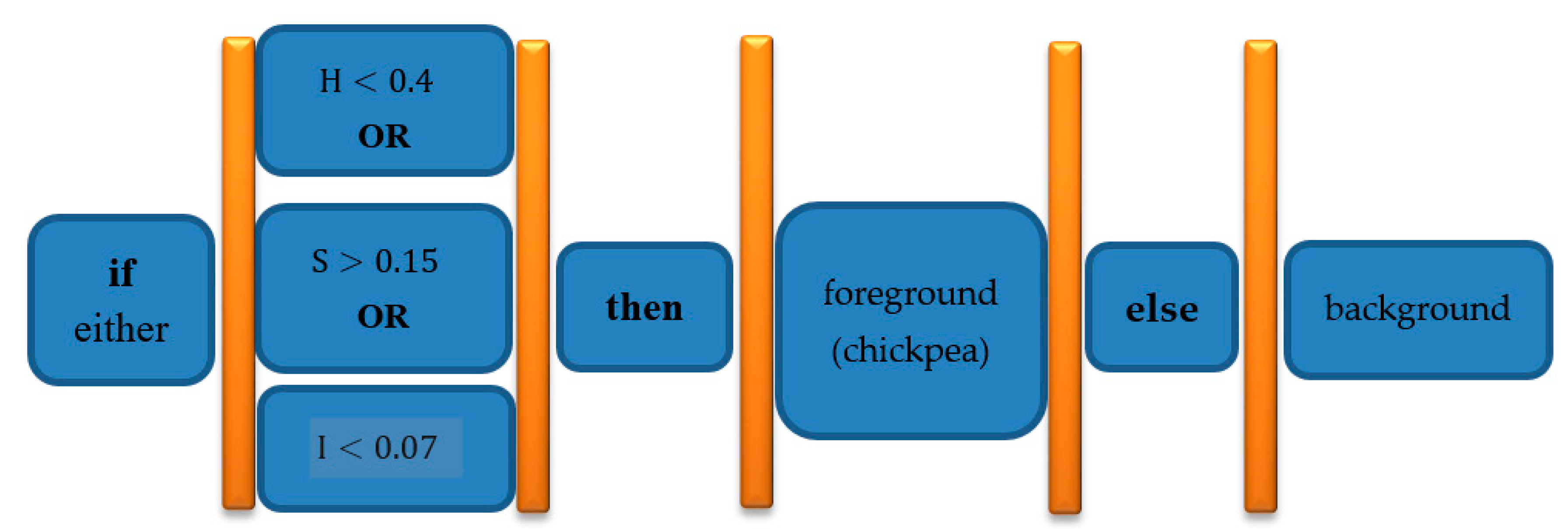
2.2. Segmentation Operation
2.3. Extraction of Different Properties of Each Chickpea Sample Image
2.4. Feature Selection
2.5. Ensemble Classification of Different Chickpea Varieties: Majority-Voting (MV)
2.5.1. Hybrid ANN-PSO Classifier
2.5.2. Hybrid ANN-ACO Classifier
2.5.3. Hybrid ANN-HS Classifier
2.5.4. Ensemble Final Classification through MV
2.6. Optimal Structures of ANNs Adjusted by Different Algorithms
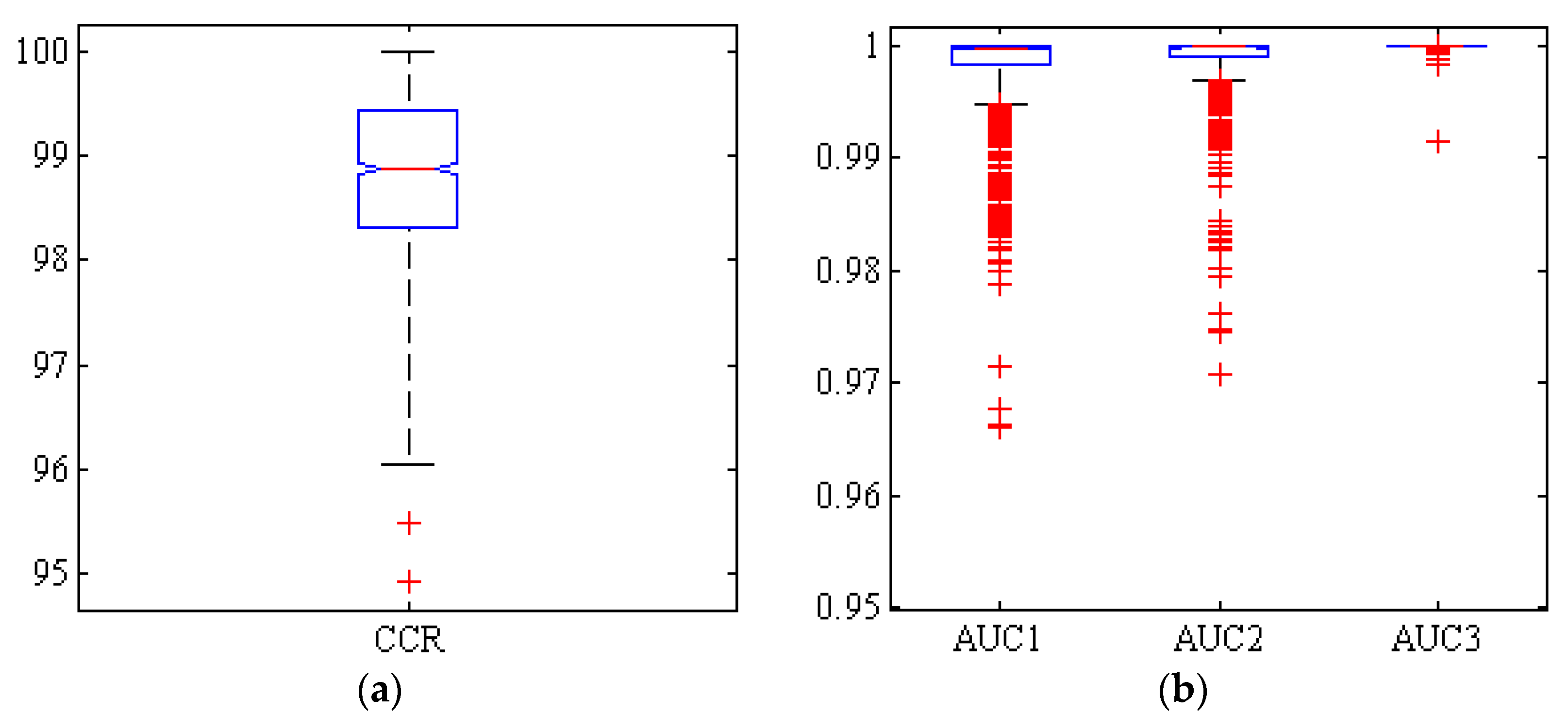
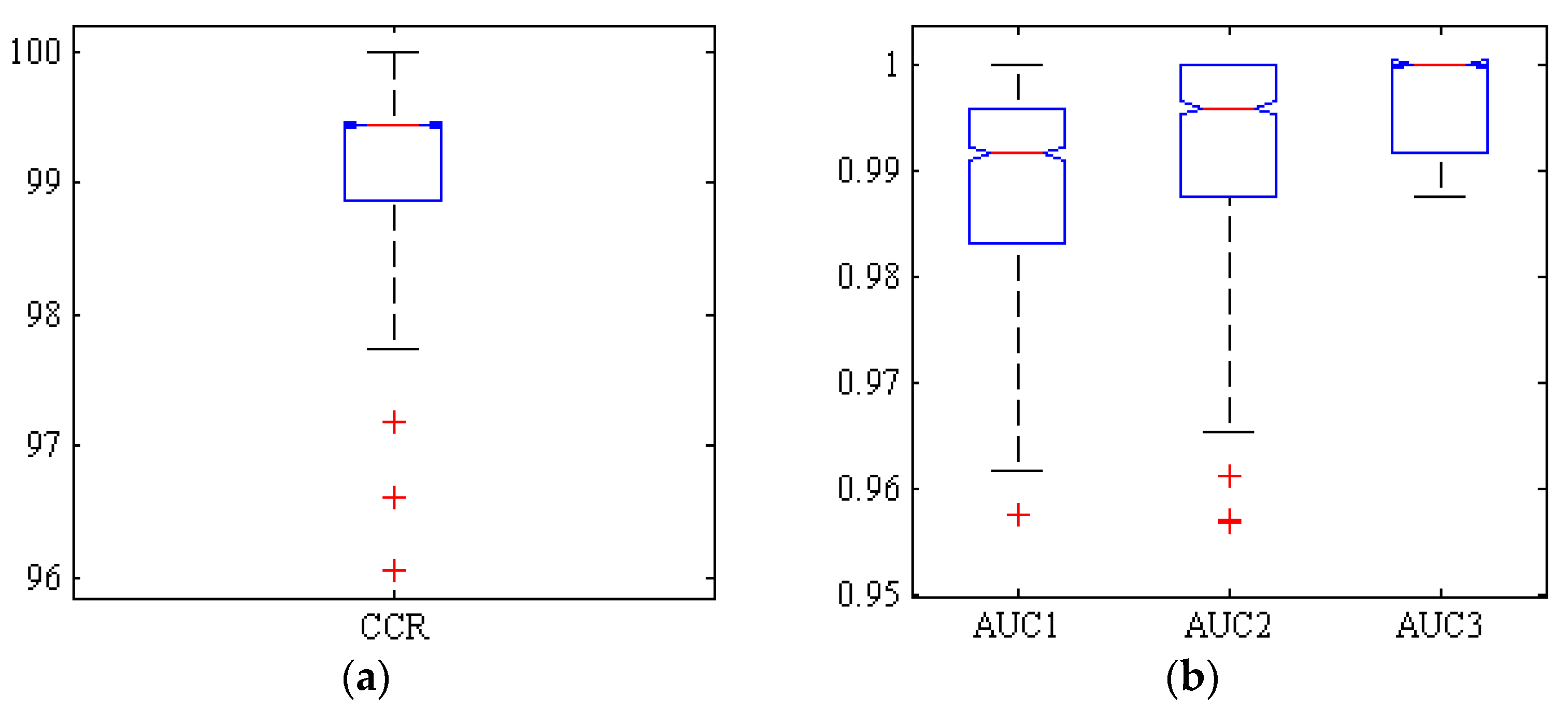
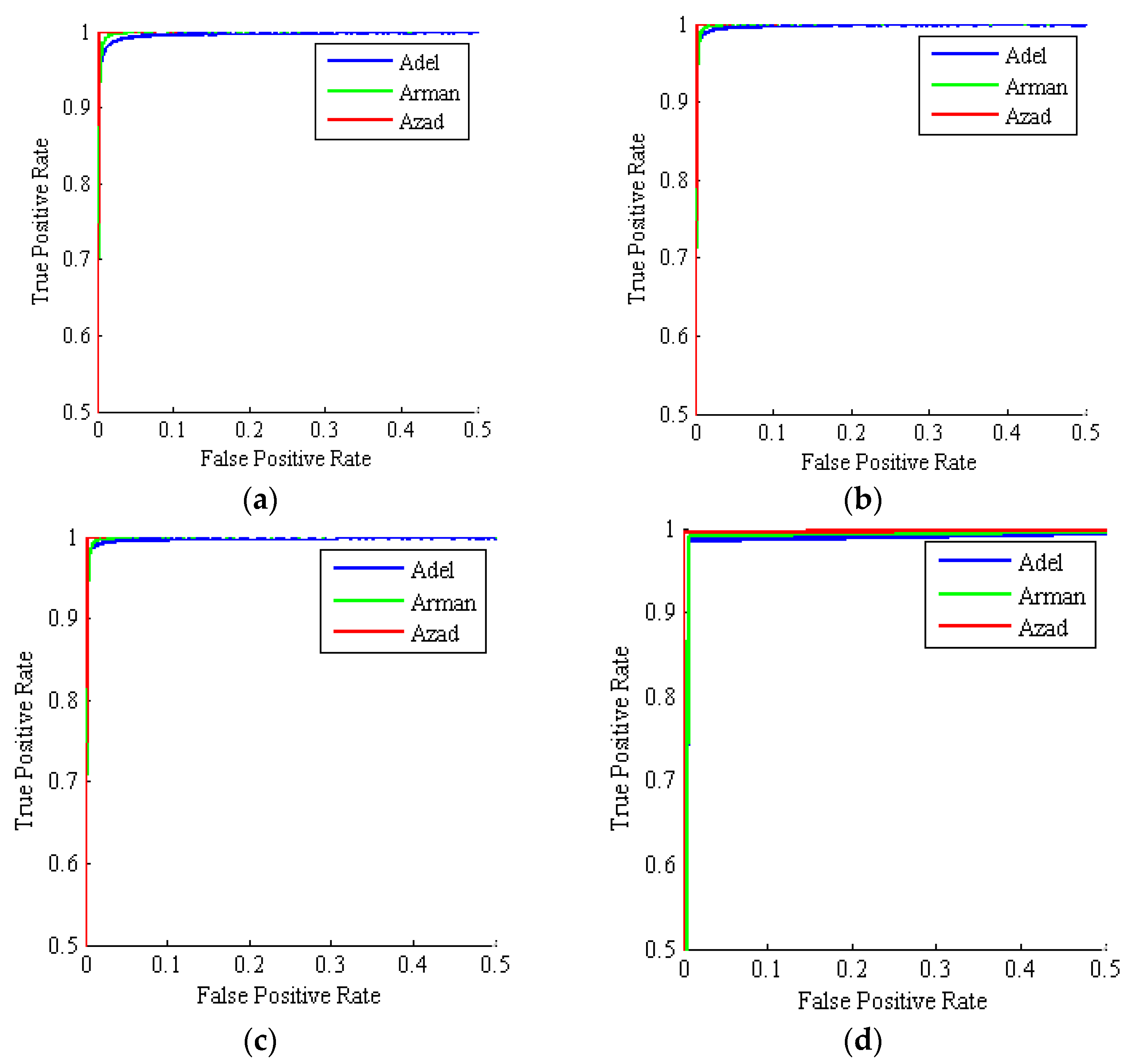
2.7. Criteria Used to Evaluate the Performance of the Different Classifiers: Confusion Matrices and Receiver Operating Curves (ROC) (Test Set)
- Sensitivity, recall, true positive (TP) rate or probability of detection: measures the proportion of actual positives that are correctly identified as such (2)
- Accuracy or correct classification rate (CCR): total percentage of correct system classifications (3)
- Specificity or true negative (TN) rate: percentage of inaccurate samples that are correctly identified (4)
- Precision or positive predictive value: is the fraction of relevant instances among the retrieved instances (5)
- F1-score: recall and precision harmonic weighted average (6).
3. Results
3.1. Effective Discrimiant Property (Feature) Selection
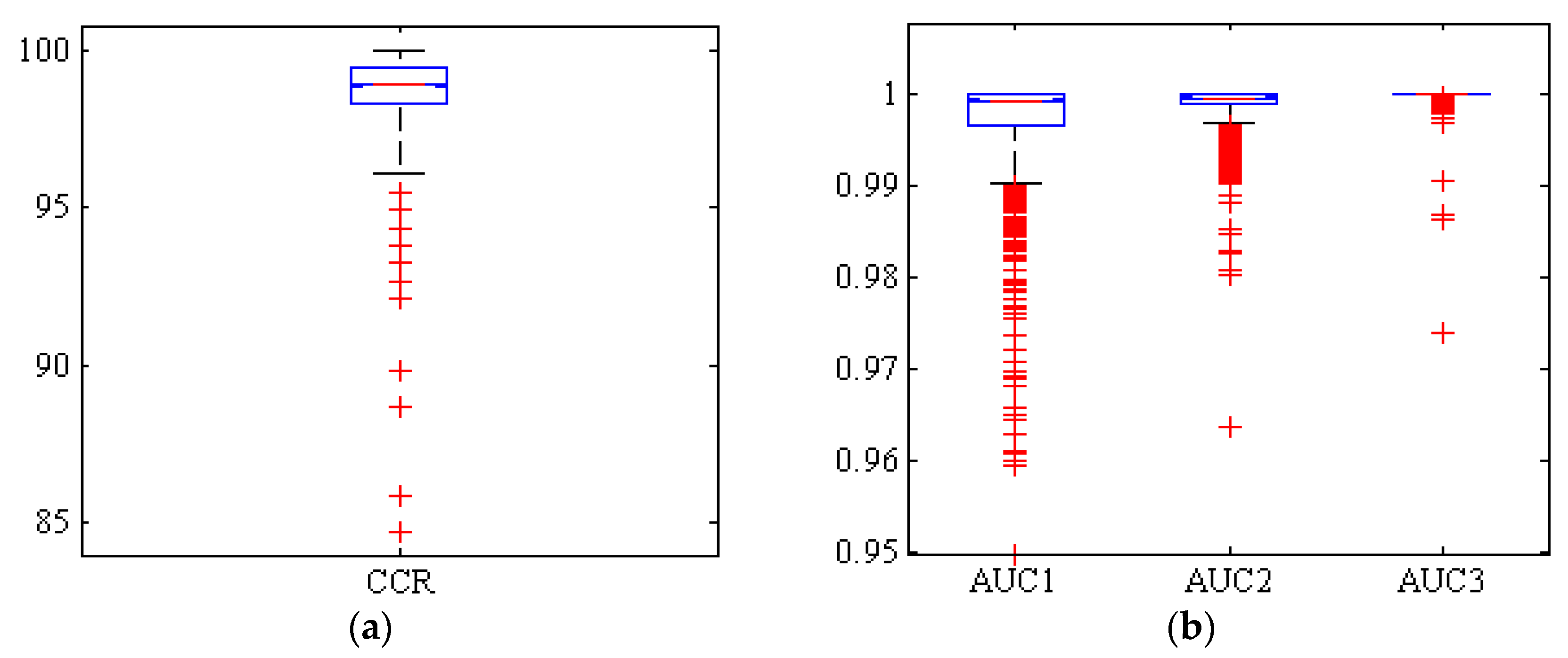
3.2. Classification Using Hybrid ANN-PSO Classifier
3.3. Classification Using Hybrid ANN-ACO Classifier
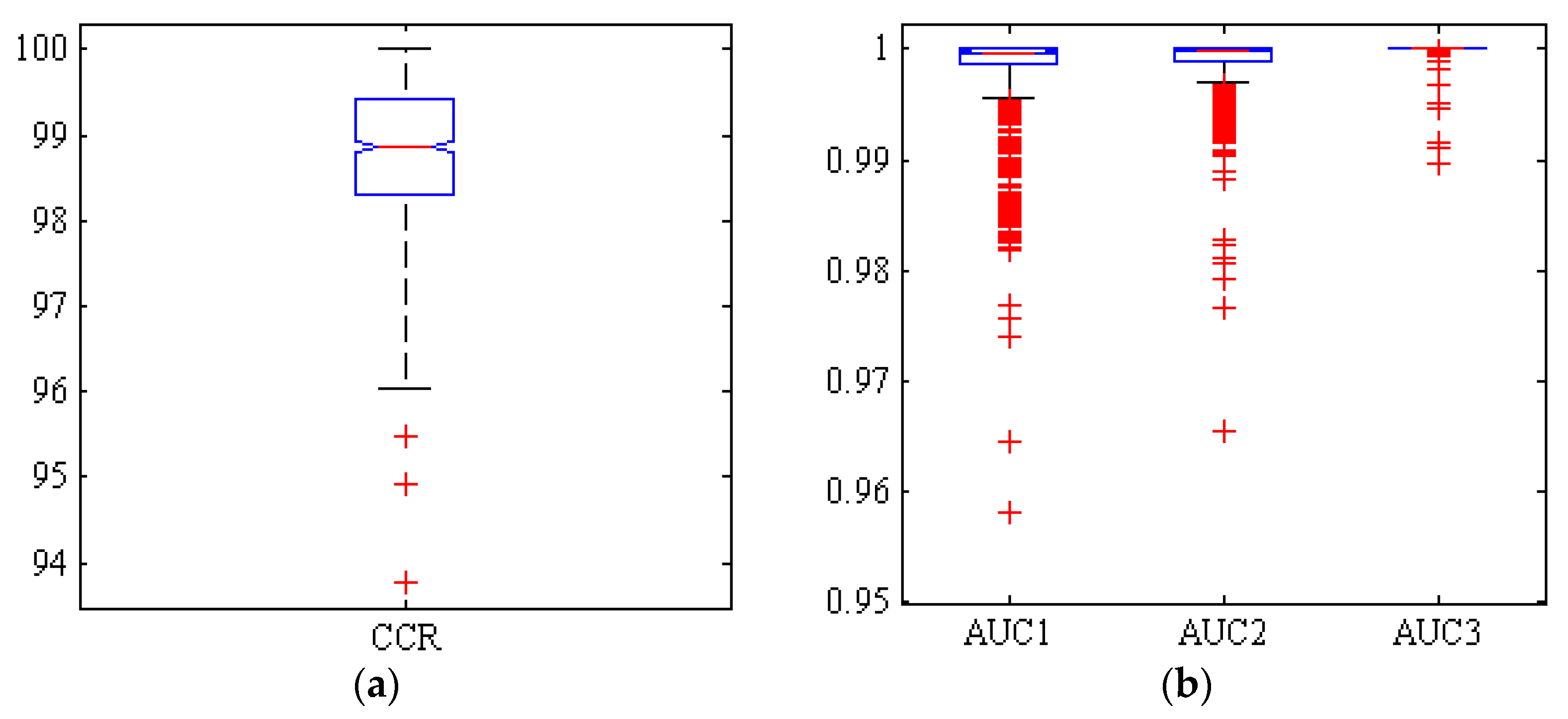
3.4. Classification Using Hybrid ANN-HS Classifier
4. Discussion
- Chickpea bunch imaging acquisition under light controlled conditions, with white LEDs with 425 lux intensity.
- Automatic chickpea image segmentation.
- Automatic extraction of different discriminant features, including: average channels of first, second, and third RGB color space, average first channel of HSI color space, neighborhood Entropy of 90° and 0° in GLCM, and third channel of YCbCr color space, from each input sample image.
- Output chickpea variety classification by a neural network ensemble majority-voting.
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Sabaghpour, S.H.; Mahmodi, A.A.; Saeed, A.; Kamel, M.; Malhotra, R.S. Study on chickpea drought tolerance lines under dryland condition of Iran. Indian J. Crop Sci. 2006, 1, 70–73. [Google Scholar]
- Kanouni, H.; Ahari, D.S.; Khoshroo, H.H. Chickpea Research and Production in Iran. In Proceedings of the 7th International Food Legume Research Conference, Marrakech, Morocco, 6–8 May 2018. [Google Scholar]
- Tabatabaeefar, A.; Aghagoolzadeh, A.H.; Mobli, H. Design and Development of an Auxiliary Chickpea Second Sieving and Grading Machine. Agric. Eng. Int. CIGR J. Sci. Res. Dev. 2003, 5, FP 03 005. [Google Scholar]
- Masoumi, A.A.; Tabil, L. Physical properties of chickpea (c. arietinum) cultivars. In Proceedings of the 2003 ASAE Annual Meeting, Las Vegas, NV, USA, 27–30 July 2003; American Society of Agricultural and Biological Engineers: St. Joseph, MI, USA, 2003; p. 1. [Google Scholar]
- Rybiński, W.; Banda, M.; Bocianowski, J.; Starzycka-Korbas, E.; Starzyck, M.; Nowosad, K. Estimation of the physicochemical variation of chickpea seeds. Agrophys 2019, 33, 67–80. [Google Scholar] [CrossRef]
- Carl, W.H.; Denny, C.D. Processing Equipment for Agricultural Products, 2nd ed.; The AVI Publishing Inc: Westport, CT, USA, 1979. [Google Scholar]
- Fawzi, N.M. Seed morphology and its implication in classification of some selected species of genus Corchorus, L. (Malvaceae). Middle East J. Agric. Res. 2018, 7, 1–11. [Google Scholar]
- Sabzi, S.; Abbaspour-Gilandeh, Y.; Hernandez-Hernandez, J.L.; Azadshahraki, F.; Karimzadeh, R. The Use of the Combination of Texture, Color and Intensity Transformation Features for Segmentation in the Outdoors with Emphasis on Video Processing. Agriculture 2019, 9, 104. [Google Scholar] [CrossRef] [Green Version]
- Gino, I.G.C.; Amelia, T. Fault Diagnosis for UAV Blades Using Artificial Neural Network. Robotics 2019, 8, 59. [Google Scholar]
- LeCun, L.Y.; Bottou, Y.B.; Hafner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Uijlings, J.R.R.; Van De Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef] [Green Version]
- Kurtulmus, F.; Unal, H. Discriminating rapeseed varieties using computer vision and machine learning. Expert Syst. Appl. 2015, 42, 1880–1891. [Google Scholar] [CrossRef]
- HemaChitra, H.S.; Suguna, S. Optimized feature extraction and classification technique for indian pulse seed recognition. Int. J. Comput. Eng. Appl. 2018, XII, 421–427. [Google Scholar]
- Liu, D.; Ning, X.; Li, Z.; Yang, D.; Li, H.; Gao, L. Discriminating and elimination of damaged soybean seeds based on image characteristics. J. Stored Prod. Res. 2015, 60, 67–74. [Google Scholar] [CrossRef]
- Golpour, I.; Parian, J.A.; Khazaei, J. Detection of rice varieties, brown and white rice based on image texture and artificial neural network. J. Agric. Mach. 2015, 5, 73–81. [Google Scholar]
- Pourdarbani, R.; Sabzi, S.; Hernández-Hernández, M.; Hernández-Hernández, J.L.; García-Mateos, G.; Kalantari, D.; Molina-Martínez, J.M. Comparison of Different Classifiers and the Majority Voting Rule for the Detection of Plum Fruits in Garden Conditions. Remote Sens. 2019, 11, 2546. [Google Scholar] [CrossRef] [Green Version]
- Clausi, D.A. An analysis of co-occurrence texture statistics as a function of grey level quantization. Can. J. Remote Sens. 2002, 28, 45–62. [Google Scholar] [CrossRef]
- Ali, M.Z.; Awad, N.H.; Suganthan, P.N.; Duwairi, R.M.; Reynolds, R.G. A novel hybrid Cultural Algorithms framework with trajectory-based search for global numerical optimization. Inf. Sci. 2016, 334, 219–249. [Google Scholar] [CrossRef]
- Sivanandam, S.N.; Deepa, S.N. Introduction to Neural Networks Using Matlab 6.0; Tata McGraw-Hill Education: New York, NY, USA, 2006; ISBN1 0070591121. ISBN2 9780070591127. [Google Scholar]
- Grzegorz, Z.; Jarosław, G.; Artur, G.; Ewelina, M.-J.; Thomas, B.; Alexandre, D. Multi-classifier majority voting analyses in provenance studies on iron artefacts. J. Archaeol. Sci. 2020, 113, 105055. [Google Scholar] [CrossRef]
- Caudill, M. Neural Networks Primer; Miller Freeman Publication: San Francisco, CA, USA, 1989. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle swarm optimization (PSO). In Proceedings of the IEEE International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar]
- Sen, T.; Mathur, H.D. A new approach to solve economic dispatch problem using a hybrid ACO–ABC–HS optimization algorithm. Int. J. Electr. Power Energy Syst. 2016, 78, 735–744. [Google Scholar] [CrossRef]
- Lee, K.S.; Geem, Z.W. A New Meta-Heuristic Algorithm for Continuous Engineering Optimization: Harmony Search Theory and Practice. Comput. Methods Appl. Mech. Eng. 2005, 194, 3902–3933. [Google Scholar] [CrossRef]
- Wisaeng, K. A comparison of decision tree algorithms for UCI repository classification. Int. J. Eng. Trends Technol. 2013, 4, 3393–3397. [Google Scholar]
- Guijarro, M.; Riomoros, I.; Pajares, G.; Zitinski, P. Discrete wavelets transform for improving greenness image segmentation in agricultural images. Comput. Electron. Agric. 2015, 118, 396–407. [Google Scholar] [CrossRef]
- Li, X.; Dai, B.; Sun, H.; Li, W. Corn Classification System based on Computer Vision. Symmetry 2019, 11, 591. [Google Scholar] [CrossRef] [Green Version]
- Men, S.; Yan, L.; Liu, J.; Qian, H.; Luo, Q. A classification method for seed viability assessment with infrared thermography. Sensors 2017, 17, 845. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aznan, A.A.; Rukunudin, I.H.; Shakaff, A.Y.M.; Ruslan, R.; Zakaria, A.; Saad, F.S.A. The use of machine vision technique to classify cultivated rice seed variety and weedy rice seed variants for the seed industry. Int. Food Res. J. 2016, 23, S31–S35. [Google Scholar]
- Kurtulmus, F.; Alibaş, İ.; Kavdır, I. Classification of pepper seeds using machine vision based on neural network. Int. J. Agric. Biol. Eng. 2016, 9, 51–62. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Color Space | Color Channel | Transformation from RGB Color Space |
|---|---|---|
| HSV | ||
| HSI | ||
| YCrCb | ||
| YIQ | ||
| CMY | ||
| Number | Feature Name | Number | Feature Name |
|---|---|---|---|
| 1 | Contrast | 11 | Inverse difference normalized (INN) |
| 2 | Sum of squares | 12 | Inverse difference moment normalized |
| 3 | Second diagonal moment | 13 | Diagonal moment |
| 4 | Mean | 14 | Sum average |
| 5 | Sum entropy | 15 | Variance |
| 6 | Difference variance | 16 | Sum variance |
| 7 | Difference entropy | 17 | Standard deviation |
| 8 | Information measure of correlation 1 | 18 | Coefficient of variation |
| 9 | Information measure of correlation 2 | 19 | Maximum probability |
| 10 | Inverse difference (INV) is homogeneity | 20 | Correlation |
| ANN Parameter | Value |
|---|---|
| Number of hidden layers | 2 |
| Number of neurons of the hidden layer | 8, 19 |
| Transfer function | tribas, tansig |
| Backpropagation network training function | trainlm |
| Backpropagation weight/bias learning function | learncon |
| Classifier | Num. of Layers | Number of Neurons | Transfer Function | Backpropagation Network Training Function | Backpropagation Weight/Bias Learning Function |
|---|---|---|---|---|---|
| ANN-PSO | 3 | First layer: 16 | First layer: netinv | learnlv1 | traingdx |
| Second layer: 9 | Second layer: satlins | ||||
| Third layer: 18 | Third layer: compet | ||||
| ANN-ACO | 3 | First layer: 12 | First layer: satlin | learnlv2 | traingd |
| Second layer: 3 | Second layer: satlin | ||||
| Third layer: 13 | Third layer: poslin | ||||
| ANN-HS | 3 | First layer: 13 | First layer: tansig | learnp | trainlm |
| Second layer: 10 | Second layer: satlin | ||||
| Third layer: 17 | Third layer: logsig |
| Classifier | Data Set Type | Real/Estimated Class | Adel (1) | Arman (2) | Azad (3) | Total Data | Classification Error Per Class (%) | CCR (%) |
|---|---|---|---|---|---|---|---|---|
| ANN-PSO | Test | Adel | 57,854 | 1048 | 98 | 59,000 | 1.94 | 98.65 |
| Arman | 852 | 57,147 | 1 | 58,000 | 1.47 | |||
| Azad | 386 | 0 | 59,614 | 60,000 | 0.643 | |||
| Train | Adel | 114,418 | 3582 | 0 | 118,000 | 3.03 | 98.71 | |
| Arman | 0 | 115,000 | 0 | 115,000 | 0 | |||
| Azad | 936 | 0 | 117,064 | 118,000 | 0.793 | |||
| Validation | Adel | 18,721 | 272 | 7 | 19,000 | 1.47 | 98.09 | |
| Arman | 68 | 18,932 | 0 | 19,000 | 0.358 | |||
| Azad | 741 | 0 | 18,259 | 19,000 | 3.9 |
| Classifier | Data Set Type | Real/Estimated Class | Adel (1) | Arman (2) | Azad (3) | Total Data | Classification Error Per Class (%) | CCR (%) |
|---|---|---|---|---|---|---|---|---|
| ANN-ACO | Test | Adel | 58,059 | 895 | 46 | 59,000 | 1.59 | 98.94 |
| Arman | 656 | 57,315 | 29 | 58,000 | 1.18 | |||
| Azad | 243 | 0 | 59,757 | 60,000 | 0.405 | |||
| Train | Adel | 117,074 | 926 | 0 | 118,000 | 0.785 | 99.52 | |
| Arman | 753 | 114,247 | 0 | 115,000 | 0.655 | |||
| Azad | 0 | 0 | 118,000 | 118,000 | 0 | |||
| Validation | Adel | 18,847 | 153 | 0 | 19,000 | 0.805 | 98.88 | |
| Arman | 0 | 18,804 | 196 | 19,000 | 1.03 | |||
| Azad | 0 | 289 | 18,711 | 19,000 | 1.52 |
| Classifier | Data Set Type | Real/Estimated Class | Adel (1) | Arman (2) | Azad (3) | Total Data | Classification Error Per Class (%) | CCR (%) |
|---|---|---|---|---|---|---|---|---|
| ANN-HS | Test | Adel | 58,059 | 895 | 46 | 59,000 | 1.59 | 98.99 |
| Arman | 601 | 57,381 | 18 | 58,000 | 1.07 | |||
| Azad | 235 | 0 | 59,765 | 60,000 | 0.392 | |||
| Train | Adel | 116,841 | 1159 | 0 | 118,000 | 0.982 | 99.67 | |
| Arman | 0 | 115,000 | 0 | 115,000 | 0 | |||
| Azad | 0 | 0 | 118,000 | 118,000 | 0 | |||
| Validation | Adel | 18,841 | 159 | 0 | 19,000 | 0.837 | 99.56 | |
| Arman | 89 | 18,911 | 0 | 19,000 | 0.468 | |||
| Azad | 0 | 0 | 19,000 | 19,000 | 0 |
| Ensemble Classifier | Real/Estimated Class | Adel (1) | Arman (2) | Azad (3) | Total Data | Classification Error Per Class (%) | CCR (%) |
|---|---|---|---|---|---|---|---|
| PSO/ACO/HS ensemble Majority-Voting | Adel | 58,184 | 804 | 12 | 59,000 | 1.38 | 99.10 |
| Arman | 508 | 57,490 | 2 | 58,000 | 0.879 | ||
| Azad | 266 | 0 | 59,734 | 60,000 | 0.443 |
| Classifier | Class | Recall (%) | Specificity (%) | Precision (%) | F1-Score (%) | AUC (Mean ± Std. Dev.) | Accuracy % (Mean ± Std. Dev.) |
|---|---|---|---|---|---|---|---|
| ANN-PSO | Adel | 97.91 | 99.03 | 98.06 | 97.98 | 0.9963 ± 0.0097 | 98.65 ± 1.31 |
| Arman | 98.19 | 99.28 | 98.53 | 98.36 | 0.9988 ± 0.0026 | ||
| Azad | 99.83 | 99.66 | 99.36 | 99.59 | 0.9999 ± 0.0011 | ||
| ANN-ACO | Adel | 98.47 | 99.2 | 98.4 | 98.44 | 0.9978 ± 0.0047 | 98.94 ± 0.89 |
| Arman | 98.46 | 99.42 | 98.82 | 98.64 | 0.9888 ± 0.0029 | ||
| Azad | 99.87 | 99.79 | 99.59 | 99.73 | 0.9999 ± 0.0006 | ||
| ANN-HS | Adel | 98.58 | 99.2 | 98.4 | 98.49 | 0.9975 ± 0.0051 | 98.99 ± 0.87 |
| Arman | 98.46 | 99.48 | 98.93 | 98.69 | 0.9984 ± 0.0035 | ||
| Azad | 99.89 | 99.79 | 99.61 | 99.75 | 1.0000 ± 0.0004 | ||
| ensemble ANN PSO/ACO/HS Majority-Voting | Adel | 98.69 | 99.31 | 98.62 | 98.65 | 0.9898 ± 0.0088 | 99.10 ± 0.75 |
| Arman | 98.62 | 99.57 | 99.12 | 98.87 | 0.9822 ± 0.0083 | ||
| Azad | 99.97 | 99.77 | 99.56 | 99.77 | 0.9977 ± 0.0037 |
| Chickpea Variety/Classifier | Adel | Arman | Azad |
|---|---|---|---|
| ANN-PSO | 0.9763 ± 0.0206 | 0.9794 ± 0.0098 | 0.9822 ± 0.0295 |
| ANN-ACO | 0.9799 ± 0.0083 | 0.9796 ± 0.0085 | 0.9831 ± 0.0031 |
| ANN-HS | 0.9795 ± 0.0081 | 0.9775 ± 0.0132 | 0.9832 ± 0.0024 |
| ensemble ANN PSO/ACO/HS Majority-Voting | 0.9766 ± 0.1001 | 0.9756 ± 0.0122 | 0.9818 ± 0.0029 |
| Paper | Number of Seed Samples | Correct Classification Rate (%) |
|---|---|---|
| Li et al. [27] (corn) | 100 | 96.67 |
| Men [28] (pea) | 120 | 95 |
| Aznan et al. [29] (rice) | 120 | 96 |
| Kurtulmus et al. [30] (pepper) | 832 | 84.94 |
| Here proposed (chickpea) | 177,000 | 99.10 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pourdarbani, R.; Sabzi, S.; Kalantari, D.; Hernández-Hernández, J.L.; Arribas, J.I. A Computer Vision System Based on Majority-Voting Ensemble Neural Network for the Automatic Classification of Three Chickpea Varieties. Foods 2020, 9, 113. https://doi.org/10.3390/foods9020113
Pourdarbani R, Sabzi S, Kalantari D, Hernández-Hernández JL, Arribas JI. A Computer Vision System Based on Majority-Voting Ensemble Neural Network for the Automatic Classification of Three Chickpea Varieties. Foods. 2020; 9(2):113. https://doi.org/10.3390/foods9020113
Chicago/Turabian StylePourdarbani, Razieh, Sajad Sabzi, Davood Kalantari, José Luis Hernández-Hernández, and Juan Ignacio Arribas. 2020. "A Computer Vision System Based on Majority-Voting Ensemble Neural Network for the Automatic Classification of Three Chickpea Varieties" Foods 9, no. 2: 113. https://doi.org/10.3390/foods9020113
APA StylePourdarbani, R., Sabzi, S., Kalantari, D., Hernández-Hernández, J. L., & Arribas, J. I. (2020). A Computer Vision System Based on Majority-Voting Ensemble Neural Network for the Automatic Classification of Three Chickpea Varieties. Foods, 9(2), 113. https://doi.org/10.3390/foods9020113