
The Rating Scale Paradox: Semantics Instability versus Information Loss


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Models and Methods
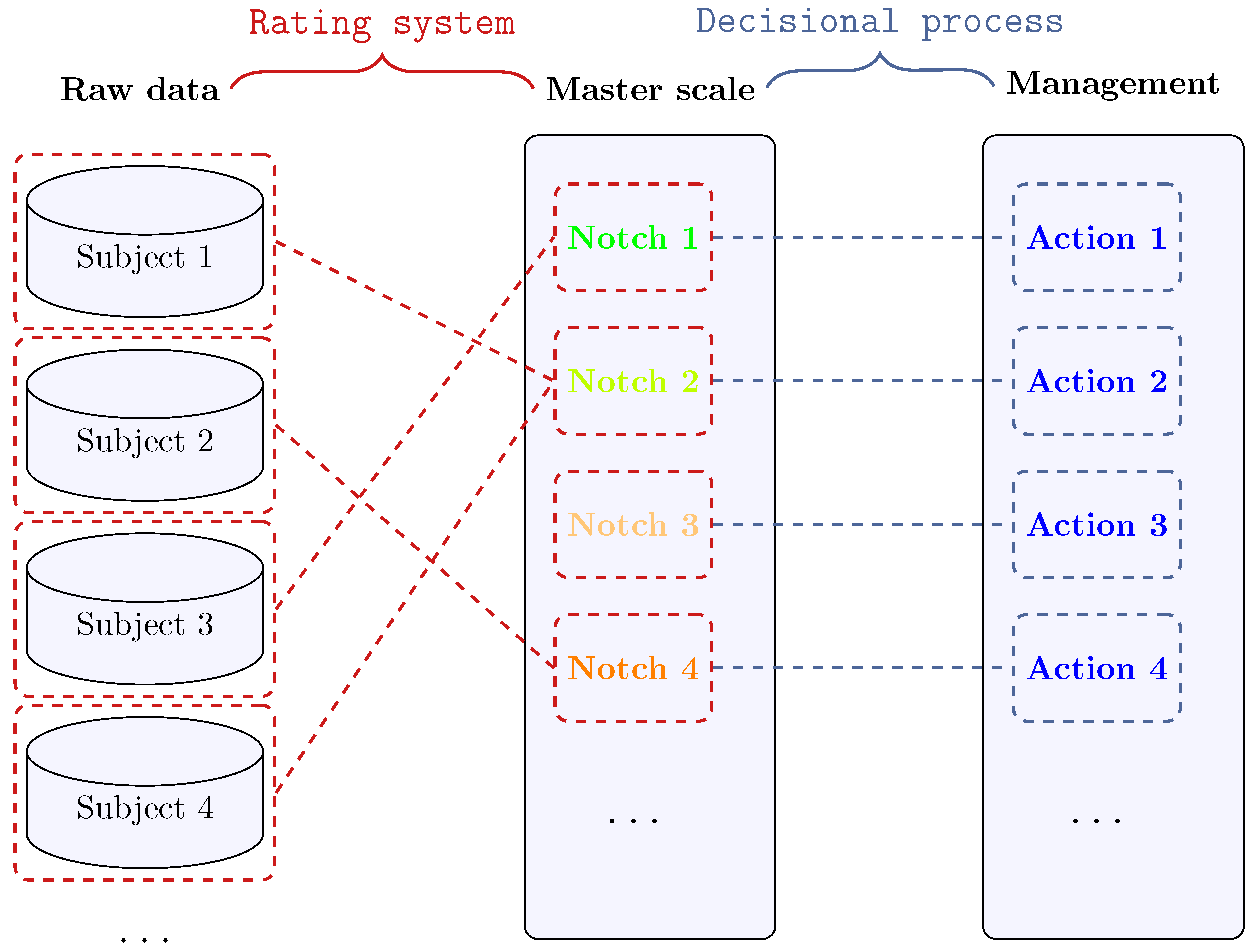
2.1. A Typical Rating System
- i.
- The deterministic relationship existing between a set of microeconomic variables describing the state of a firm and its creditworthiness;
- ii.
- The stochastic marginal dynamics of the considered microeconomic variables.
- a.
- Univariate selection of the variables to be included among predictors , according to a measure of their diagnostic ability;
- b.
- Multivariate validation of the selected predictors and dimensionality reduction of by the application of PCA or another factor analysis technique;
- c.
- Partition of the PD domain in a finite set of indexed subintervals (i.e., rating classes, also known as grades), each of them being associated with a symbol (e.g. AA, A, BBB, etc.) and with a qualitative description of the corresponding risk level (the so-called “master scale”);
- d.
- Allowance for expert-judgment-based override of the rating, leading to a joint usage of quantitative and qualitative results to produce a final evaluation of the firm creditworthiness.
2.2. Considered Partition Criteria
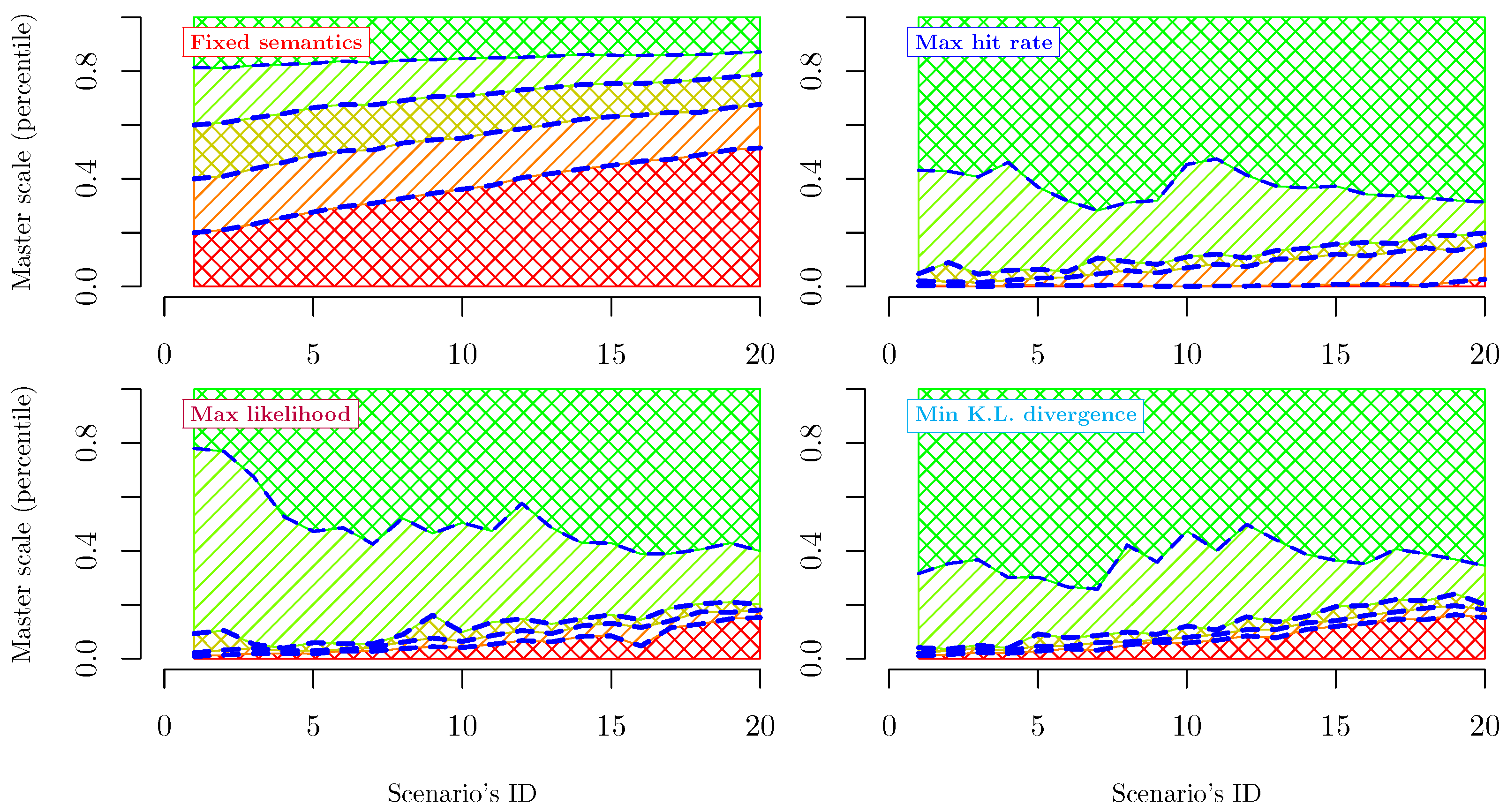
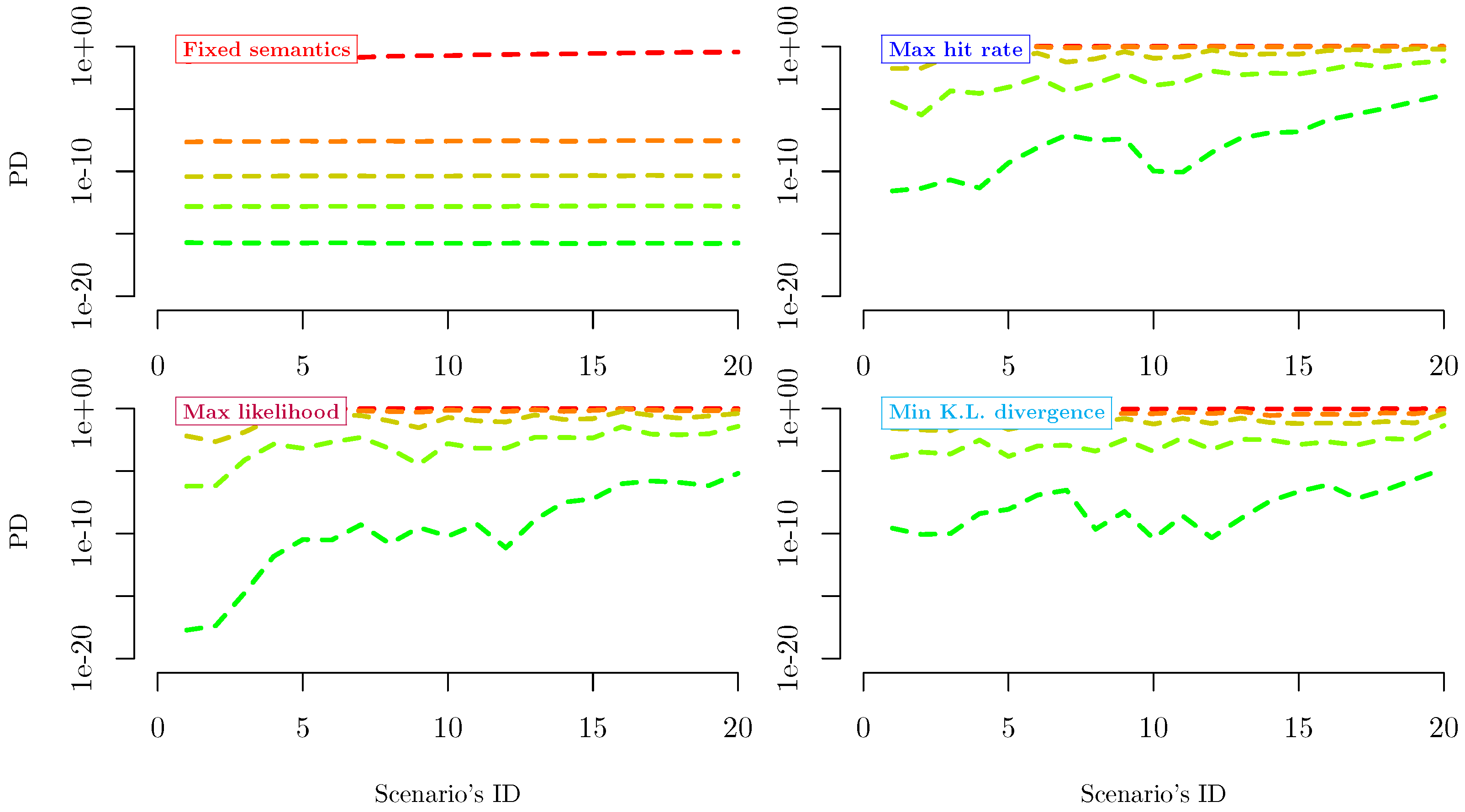
2.2.1. Fixed Semantics
2.2.2. Maximum Hit Rate
2.2.3. Maximum Likelihood
2.2.4. Minimum Kullback–Leibler Divergence
2.2.5. Hybrid Criteria
3. Numerical Comparison among Different Partition Criteria
3.1. Numerical Setup
3.2. Features of Fixed Semantics Criteria
3.3. Features of Maximum Information Criteria
4. Relative Evaluations and Absolute Decisions: Rating System Applied in a RAF
5. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hodgetts, T.J.; Hall, J.; Maconochie, I.; Smart, C. Paediatric triage tape. Prehosp. Immed. Care 2013, 2, 155–159. [Google Scholar]
- Cross, K.P.; Cicero, M.X. Head-to-head comparison of disaster triage methods in pediatric, adult, and geriatric patients. Ann. Emerg. Med. 2013, 61, 668–676. [Google Scholar]
- Lerner, E.B.; McKee, C.H.; Cady, C.E.; Cone, D.C.; Colella, M.R.; Cooper, A.; Coule, P.L.; Lairet, J.R.; Liu, J.M.; Pirrallo, R.G.; et al. A consensus-based gold standard for the evaluation of mass casualty triage systems. Prehosp. Emerg. Care 2015, 19, 267–271. [Google Scholar]
- Elo, A.E. The Proposed USCF Rating System. Chess Life 1967, XXII, 242–247. Available online: http://uscf1-nyc1.aodhosting.com/CL-AND-CR-ALL/CL-ALL/1967/1967_08.pdf (accessed on 21 June 2022).
- Glickman, M.E. Parameter estimation in large dynamic paired comparison experiments. Appl. Stat. 1999, 48, 377–394. [Google Scholar]
- Veček, N.; Mernik, M.; Črepinšek, M.; Hrnčič, D. A Comparison between Different Chess Rating Systems for Ranking Evolutionary Algorithms. In Proceedings of the 2014 Federated Conference on Computer Science and Information Systems, Warsaw, Poland, 7–10 September 2014; Ganzha, M., Maciaszek, L., Paprzycki, M., Eds.; 2014; Volume 2, pp. 511–518. [Google Scholar]
- Rating Symbols and Definitions. Moody’s Investors Service. 2 June 2022. Available online: https://www.moodys.com/researchdocumentcontentpage.aspx?docid=pbc_79004 (accessed on 21 June 2022).
- Oosterveld, B.; Bauer, S. Rating Definitions. FitchRatings Special Report, 21 March 2022. Available online: https://www.fitchratings.com/research/structured-finance/rating-definitions-21-03-2022 (accessed on 21 June 2021).
- Nehrebecka, N. Probability-of-default curve calibration and validation of internal rating systems. In Proceedings of the 8th IFC Conference on “Statistical Implications of the New Financial Landscape”, Basel, Switzerland, 8–9 September 2016; Available online: https://www.bis.org/ifc/publ/ifcb43_zd.pdf (accessed on 21 June 2021).
- Weissova, I.; Kollarb, B.; Siekelova, A. Rating as a Useful Tool for Credit Risk Measurement. Procedia Econ. Financ. 2015, 26, 278–285. [Google Scholar]
- Thurstone, L.L. Theory of attitude measurement. Psychol. Rev. 1929, 36, 222. [Google Scholar]
- Likert, R. A technique for the measurement of attitudes. Arch. Psychol. 1932, 22, 55. [Google Scholar]
- Parducci, A. Category ratings and the relational character of judgment. Adv. Psychol. 1983, 11, 262–282. [Google Scholar]
- Menold, N.; Wolf, C.; Bogner, K. Design aspects of rating scales in questionnaires. Math. Popul. Stud. 2018, 25, 63–65. [Google Scholar]
- Carey, M.; Hrycay, M. Parameterizing credit risk models with rating data. J. Bank. Financ. 2001, 25, 197–270. [Google Scholar]
- Delianis, G.; Geske, R. Credit Risk and Risk Neutral Default Probabilities: Information about Rating Migrations and Defaults. Working Paper, UCLA. Available online: https://escholarship.org/uc/item/7dm2d31p (accessed on 20 July 2022).
- Falkenstein, E. Validating commercial risk grade mapping: Why and how. J. Lend. Credit. Risk Manag. 2000, 82, 26–33. [Google Scholar]
- Sobehart, J.R.; Keenan, S.C.; Stein, R.M. Benchmarking Quantitative Default Risk Models: A Validation Methodology; Moody’s Investors Service: New York, NY, USA, 2020; Available online: http://www.rogermstein.com/wp-content/uploads/53621.pdf (accessed on 20 July 2022).
- Regan, K.W.; Macieja, B.; Haworth, G.M. Understanding distributions of chess performances. In Advances in Computer Games; Springer: Berlin/Heidelberg, Germany, 2011; pp. 230–243. [Google Scholar]
- FIDE Rating Regulations Effective from 1 January 2022. Available online: https://www.fide.com/docs/regulations/FIDE%20Rating%20Regulations%202022.pdf (accessed on 21 June 2022).
- Brindle, M.E.; Doherty, G.; Lillemoe, K.; Gawande, A. Approaching surgical triage during the COVID-19 pandemic. Ann. Surg. 2020, 272, e40. [Google Scholar]
- Erika, P.; Andrea, V.; Cillis, M.G.; Ioannilli, E.; Iannicelli, T.; Andrea, M. Triage decision-making at the time of COVID-19 infection: The Piacenza strategy. Intern. Emerg. Med. 2020, 15, 879–882. [Google Scholar]
- Giacomelli, J.; Passalacqua, L. Unsustainability Risk of Bid Bonds in Public Tenders. Mathematics 2021, 9, 2385. [Google Scholar]
- Giacomelli, J. Parametric estimation of latent default frequency in credit insurance. J. Oper. Res. Soc. 2022. [Google Scholar] [CrossRef]
- Merton, R.C. On the Pricing of Corporate Debt: The Risk Structure of Interest Rates. J. Financ. 1974, 29, 449–470. [Google Scholar]
- History of KMV. Available online: https://www.moodysanalytics.com/about-us/history/kmv-history (accessed on 21 June 2022).
- Nazeran, P.; Dwyer, D. Credit Risk Modeling of Public Firms: EDF9. Moody’s Analytics Quantitative Research Group 2015. Available online: https://www.moodysanalytics.com/-/media/whitepaper/2015/2012-28-06-public-edf-methodology.pdf (accessed on 21 June 2022).
- Stanghellini, E. Introduzione ai Metodi Statistici per il Credit Scoring, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Konrad, P.M. The Calibration of Rating Models. Estimation of the Probability of Default Based on Advanced Pattern Classification Methods, 1st ed.; Tectum Verlag Marburg: Marburg, Germany, 2012. [Google Scholar]
- Gurný, P.; Gurný, M. Comparison of credit scoring models on probability of defaults estimation for US banks. Prague Econ. Pap. 2013, 22, 163–181. [Google Scholar]
- Fankenstein, E.; Boral, A.; Carty, L.V. RiskCalc for Private Companies: Moody’s Default Model. Moody’s Investor Service Global Credit Research, May 2000. Available online: http://dx.doi.org/10.2139/ssrn.236011 (accessed on 28 July 2022).
- Basel Committee on Banking Supervision (BSBC). The Internal Ratings-Based Approach; Bank for International Settlements: Basel, Switzerland, 2001. [Google Scholar]
- Tasche, D. The art of probability-of-default curve calibration. J. Credit. Risk 2013, 9, 63–103. [Google Scholar]
- Durović, A. Macroeconomic Approach to Point in Time Probability of Default Modeling—IFRS 9 Challenges. J. Cent. Bank. Theory Pract. 2019, 1, 209–223. [Google Scholar]
- IASB. International Financial Reporting Standard 9 Financial Instruments. International Accounting Standards Board: London, UK, 2014. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar]
- Engelmann, B.; Hayden, E.; Tasche, D. Measuring the Discriminative Power of Rating Systems; Discussion Paper Series 2: Banking and Financial Supervision N° 01/2003 Deutsche Bundesbank. Available online: https://www.bundesbank.de/resource/blob/704150/b9fa10a16dfff3c98842581253f6d141/mL/2003-10-01-dkp-01-data.pdf (accessed on 21 June 2022).
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar]







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Giacomelli, J. The Rating Scale Paradox: Semantics Instability versus Information Loss. Standards 2022, 2, 352-365. https://doi.org/10.3390/standards2030024
Giacomelli J. The Rating Scale Paradox: Semantics Instability versus Information Loss. Standards. 2022; 2(3):352-365. https://doi.org/10.3390/standards2030024
Chicago/Turabian StyleGiacomelli, Jacopo. 2022. "The Rating Scale Paradox: Semantics Instability versus Information Loss" Standards 2, no. 3: 352-365. https://doi.org/10.3390/standards2030024
APA StyleGiacomelli, J. (2022). The Rating Scale Paradox: Semantics Instability versus Information Loss. Standards, 2(3), 352-365. https://doi.org/10.3390/standards2030024