
Combining Different Stakeholders’ Opinions in Multi-Criteria Decision Analyses Applying Partial Order Methodology



Abstract
:1. Introduction
1.1. Ranking
1.2. Model Studies
1.3. Semantics
2. Materials and Methods
2.1. Partial Ordering—Basics
2.1.1. Main Equation, Compensation, Binary Relations
2.1.2. Hasse Diagram, Incomparabilities, Chains
2.1.3. Extension/Enrichment
2.2. Framework of Enrichments

{kind=link}
{kind=link}
{kind=link}
| Method | U (Number of Incomparisons) | Remark | References |
|---|---|---|---|
| Application of Equation (1) | May be very large. Data matrix analyzed without any pretreatment by partial order leading to an “input poset”. | No external information needed beyond the data matrix | [14,16] |
| Weights not as a sharp number but elements of certain intervals | U will be reduced | Stakeholders have to find intervals for the weights | [17] |
| Different weighting systems | U will be reduced | GLA (more details below) | [18] |
| Matrix of mutual ranking probability (MRP) | U will be reduced | Dominance structure of posets | [15,19,20] |
| Bucket order | U will be reduced | A systematic procedure to reduce U until the value 0 | [15,21,22,23] |
| POSAC (Partial Order Scalogram Analysis by coordinates) | U will be reduced | A bidimensional representation is searched keeping as much as possible the original comparabilities | [24] |
| Ranking due to mean of different heights | U = 0 | Any partial order can be equivalently described by a set of linear orders. The vertical position of an object within a linear order is called its height. | [25,26,27,28]: Concept of Composite, synthetic, indicator |
2.3. Enrichment of the MIS—Generalized Linear Aggregation
2.3.1. Need of Normalization/Data Pretreatment
2.3.2. Orientation
2.3.3. Aggregation Process
- (a)
- the system of weight-regimes can be checked; for example, the matrix G can be analyzed by correlation measures, or even by posetic tools.
- (b)
- Equation (5) can also be written as a mapping, performed by an operator Ĝ. Ĝ can be applied to set of indicators of the MIS(old) leading to a set of new indicators, MIS(new) (Equation (7)).
2.3.4. The Number of Incomparabilities as a Controlling Quantity
2.4. Software
3. Results
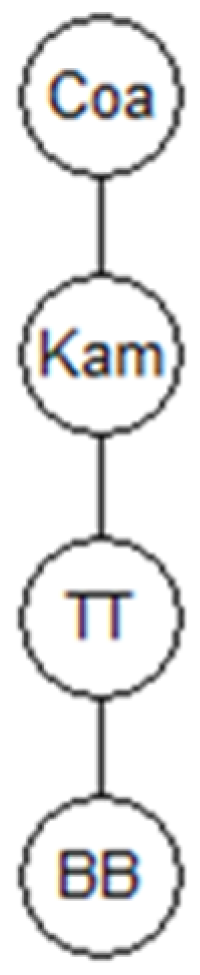
3.1. Evaluation Transportation Variants in Kampala
3.1.1. Normalization
3.1.2. Application of Two Different G Matrices
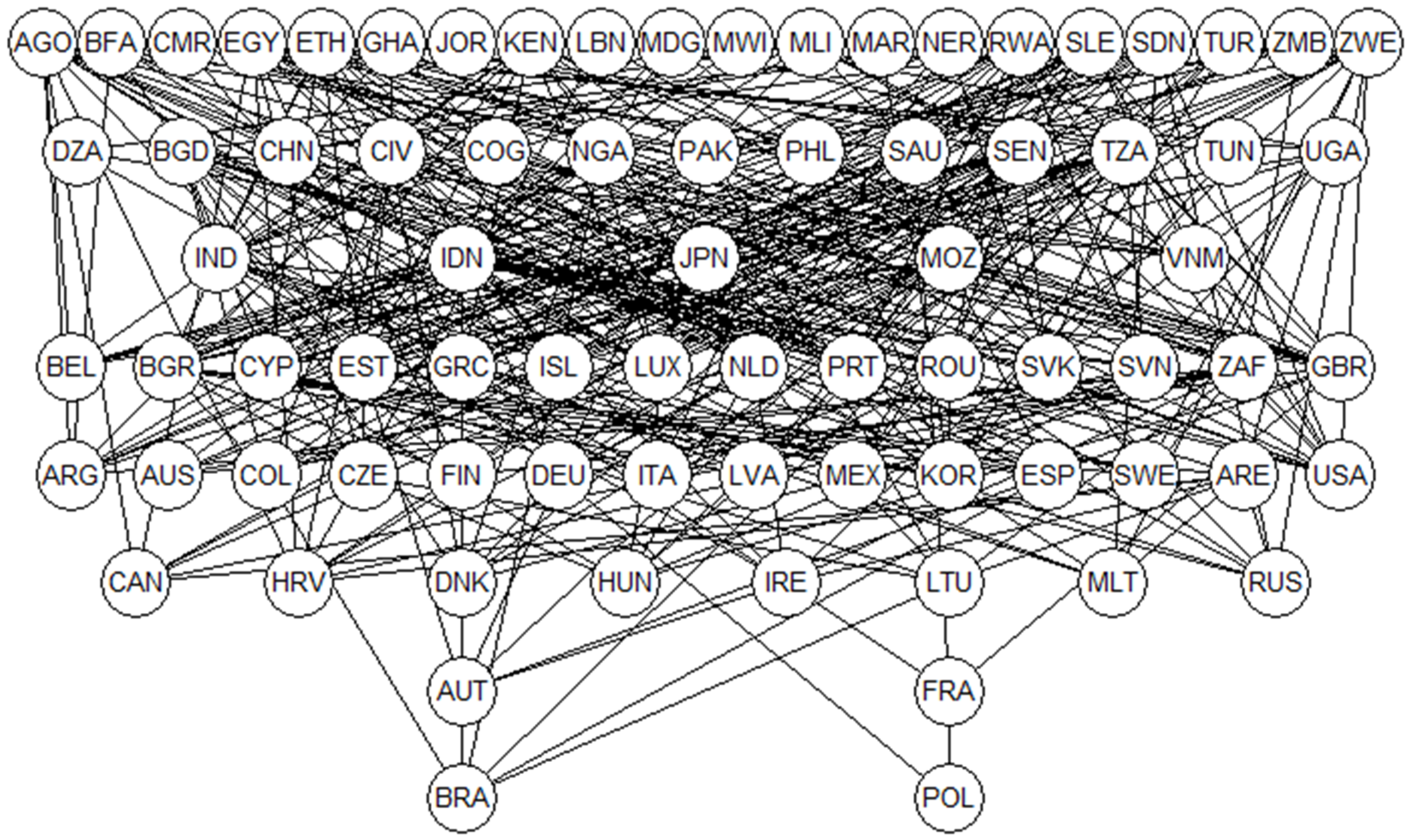
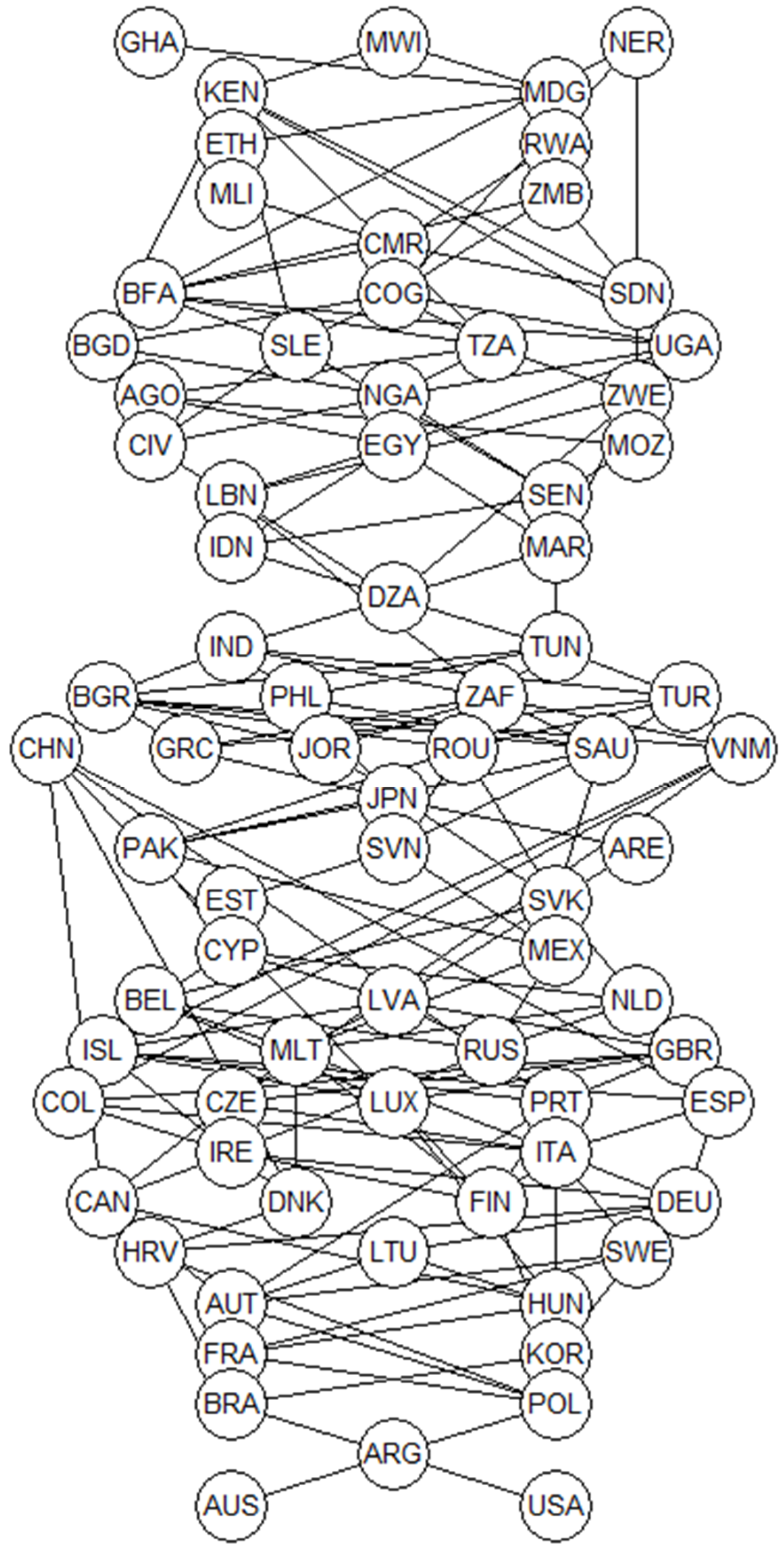
3.2. Evaluation of Food Sustainability within 78 Countries
4. Discussion
- (a)
- Partial order takes a relational point of view, even if numerical algorithms, as indicated by Equation (5) are applied. Hence, the MIS(new) will once again analyzed in terms of a graph, indicating comparabilities and incomparabilities. Consequently, the data are only used to decide whether a ≤ -relation can be established. This is seen as some zooming out; however, clearly numerical details must be a posteriori analyzed.
- (b)
- In Equation (5), needs weights are combined with indicator values and then summed up. In a strict mathematical reasoning, this can only be done when the scaling level is metric. If this is not the case, or when the indicator values have very different ranges, which may depend on the used unit of measurements, then a normalization is needed. A normalization in turn requires metric values; when MIS(old) contains ordinal indicators, then a normalization is a crucial step which needs a carefully justification.
- (c)
- The characterization of the weight scheme (matrix G) can be performed in many ways, as, e.g., different correlation measures can be applied. Further, G itself can be investigated by partial order methods to disclose whether some weight regimes dominate some others.
5. Conclusions and Outlook
5.1. Limitations and Future Work
5.2. The Novelty of the Here-Presented Approach
Author Contributions
Funding
Conflicts of Interest
References
- Brans, J.P.; Vincke, P. A Preference Ranking Organisation Method (The PROMETHEE Method for Multiple Criteria Decision—Making). Manag. Sci. 1985, 31, 647–656. [Google Scholar] [CrossRef] [Green Version]
- Brans, J.P.; Vincke, P.; Mareschal, B. How to select and how to rank projects: The Promethee method. Eur. J. Oper. Res. 1986, 24, 228–238. [Google Scholar] [CrossRef]
- Brans, J.-P.; Mareschal, B. The PROMCALC & GAIA decision support system for multicriteria decision aid. Decis. Support Syst. 1994, 12, 297–310. [Google Scholar] [CrossRef]
- Saaty, T.L. How to Make a Decision: The Analytical Hierarchy Process. Interfaces 1994, 24, 19–43. Available online: https://www.jstor.org/stable/25061950?origin=JSTOR-pdf (accessed on 3 October 2022). [CrossRef] [Green Version]
- Saaty, T.L. Vargas, The analytical network process. In Decision Making with the Analytic Network Process; Saaty, T.L., Var-gas, L., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1–26. [Google Scholar] [CrossRef]
- Li, H.-F.; Wang, J.-J. An Improved Ranking Method for ELECTRE III. In Proceedings of the 2007 International Conference on Wireless Communications, Net-working and Mobile Computing, Shanghai, China, 21–25 September 2007; pp. 6659–6662. [Google Scholar] [CrossRef]
- Carlsen, L.; Bruggemann, R. Partial Order as Decision Support between Statistics and Multicriteria Decision Analyses. Standards 2022, 2, 306–328. [Google Scholar] [CrossRef]
- Kalifa, M.; Özdemir, A.; Özkan, A.; Banar, M. Application of Multi-Criteria Decision analysis including sustainable indicators for prioritization of public transport system. Integr. Environ. Assess. Manag. 2021, 18, 25–38. [Google Scholar] [CrossRef] [PubMed]
- Food Suistainability Index 2021. Available online: https://impact.economist.com/projects/foodsustainability/ (accessed on 3 October 2022).
- Bruggemann, R.; Patil, G.P. Ranking and Prioritization for Multi-Indicator Systems—Introduction to Partial Order Applications; Springer: New York, NY, USA, 2011; Available online: https//www.springer.com/gp/book/9781441984760 (accessed on 3 October 2022).
- Carlsen, L. Happiness as a sustainability factor. The world happiness index: A posetic-based data analysis. Sustain. Sci. 2018, 13, 549–571. [Google Scholar] [CrossRef]
- Munda, G. Social Multi-Criteria Evaluation for a Sustainable Economy; Springer: Berlin/Heidelberg, Germany; New York, NY, USA, 2008; p. 227. [Google Scholar] [CrossRef]
- Nardo, M.; Saisana, M.; Saltelli, A.; Tarantola, S.; Hoffman, A.; Giovannini, E. Handbook on Constructing Composite Indicators. Methodology and User Guide; OECD: Ispra, Italy, 2008; Available online: https://www.oecd.org/sdd/42495745.pdf (accessed on 3 October 2022).
- Brüggemann, R.; Carlsen, L. Introduction to partial order theory exemplified by the Evaluation of Sampling Sites. In Partial Order in Environmental Sciences and Chemistry; Bruggemann, R., Carlsen, L., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 61–110. [Google Scholar] [CrossRef]
- Arcagni, A.; Avellone, A.; Fattore, M. Complexity reduction and approximation of multidomain systems of partially ordered data. Comput. Stat. Data Anal. 2022, 172, 107520. [Google Scholar] [CrossRef]
- Bruggemann, R.; Carlsen, L. (Eds.) Partial Order in Environmental Sciences and Chemistry; Springer: Berlin/Heidelberg, Germany, 2006; pp. 61–110. Available online: https://www.springer.com/gp/book/9783540339687 (accessed on 3 October 2022).
- Carlsen, L.; Bruggemann, R. Inequalities in the European Union—A Partial Order Analysis of the Main Indicators. Sustainability 2021, 13, 6278. [Google Scholar] [CrossRef]
- Bruggemann, R.; Carlsen, L. Uncertainty in Weights for Composite Indicators Generated by Weighted Sums. In Measuring and Understanding Complex Phenomena: Indicators and Their Analysis in Different Scientific Fields; Brüggemann, R., Carlsen, L., Beycan, T., Suter, C., Maggino, F., Eds.; Springer: Cham, Switzerland, 2021; pp. 45–62. [Google Scholar] [CrossRef]
- Brüggemann, R.; Carlsen, L.; Panahbehagh, B.; Pirintsos, S. A Study to Generate a Weak Order from a Partiallly Ordered Set, Taken Biomonitoring Measurements. In Measuring and Understanding Complex Phenomena; Indicators and Their Analysis in Different Scientific Fields; Brüggemann, R., Carlsen, L., Beycan, T., Suter, C., Maggino, F., Eds.; Springer: Cham, Switzerland, 2018; pp. 63–82. [Google Scholar] [CrossRef]
- de Loof, K.; de Baets, B.; de Meyer, H. Approximation of Average Ranks in Posets. MATCH—Commun. Math. Comput. Chem. 2011, 66, 219–229. Available online: https://match.pmf.kg.ac.rs/electronic_versions/Match66/n1/match66n1_219-229.pdf (accessed on 3 October 2022).
- Aledo, J.A.; Gámez, J.A.; Rosete, A. Utopia in the solution of the Bucket Order Problem. Decis. Support Syst. 2017, 97, 69–80. [Google Scholar] [CrossRef]
- Fernandez, P.L.; Heath, L.S.; Ramakrishnan, N.; Tan, M.; Vergara, J.P.C. Mining posets from linear orders. Discret. Math. Algorithms Appl. 2013, 5, 1350030. [Google Scholar] [CrossRef] [Green Version]
- Gionis, A.; Mannila, H.; Puolamäki, K.; Ukkonen, A. Algorithms for discovering bucket orders from data. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 561–566. [Google Scholar] [CrossRef] [Green Version]
- Shye, S. Partial Order scalogram analysis by coordinates (POSAC) as a facet theory measurement procedure: How to do POSAC in four simple steps. In Facet Theory and Scaling: In Search for Structure in Behavioral and Social Sciences Facet Theory; Cohen, A., Ed.; Association Press: New York, NY, USA, 2009; pp. 295–310. Available online: https://www.researchgate.net/publication/263932933_PARTIAL_ORDER_SCALOGRAM_ANALYSIS_BY_COORDINATES_POSAC_AS_A_FACET_THEORY_MEASUREMENT_PROCEDURE_HOW_TO_DO_POSAC_IN_FOUR_SIMPLE_STEPS (accessed on 3 October 2022).
- Bubley, R.; Dyer, M. Faster random generation of linear extensions. Discret. Math. 1999, 201, 81–88. [Google Scholar] [CrossRef] [Green Version]
- De Loof, K.; de Meyer, H.; de Baets, B. Exploiting the Lattice of Ideals Representation of a Poset. Fundam. Inform. 2006, 71, 309–321. [Google Scholar]
- Schröder, B.S.W. Ordered Sets—An Introduction; Birkhäuser: Boston, MA, USA, 2003. [Google Scholar] [CrossRef]
- di Bella, E.; Gandullia, L.; Leporatti, L.; Montefiori, M.; Orcamo, P. Ranking and Prioritization of Emergency Departments Based on Multi-indicator Systems. Soc. Indic. Res. 2018, 136, 1089–1107. [Google Scholar] [CrossRef]
- Mashunin, K.Y.; Mashunin, Y.K. Vector optimization with equivalent and priority criteria. J. Comput. Syst. Sci. Int. 2017, 56, 975–996. [Google Scholar] [CrossRef]
- Brüggemann, R.; Carlsen, L.; Voigt, K.; Wieland, R. PyHasse Software for Partial Order Analysis: Scientific Background and Description of Selected Modules. In Multi-Indicator Systems and Modelling in Partial Order; Springer: New York, NY, USA, 2014; pp. 389–423. [Google Scholar] [CrossRef]
- Food Sustainability Index 2017. Available online: http://foodsustainability.eiu.com/wp-content/uploads/sites/34/2016/09/FoodSustainabilityIndex2017GlobalExecutiveSummary.pdf (accessed on 3 October 2022).
- Comim, F. A Poset-Generalizability Method for Human Development Indicators. Soc. Indic. Res. 2021, 158, 1179–1198. [Google Scholar] [CrossRef]
- Brüggemann, R.; Carlsen, L. An Improved Estimation of Averaged Ranks of Partially Orders. MATCH Commun. Math. Comput. Chem. 2011, 65, 383–414. [Google Scholar]
- Brüggemann, R.; Sørensen, P.B.; Lerche, D.; Carlsen, L. Estimation of Averaged Ranks by a Local Partial Order Model. J. Chem. Inf. Comput. Sci. 2004, 44, 618–625. [Google Scholar] [CrossRef] [PubMed]
- Patil, G.P.; Joshi, S.W. Comparative Knowledge Discovery with Partial Orders and Composite indicators: Multi-indicator Sytemic Ranking, Advocacy and Reconciliation. In Multi-Indicator Systems and Modelling in Partial Order; Bruggemann, R., Carlsen, L., Wittmann, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 107–146. Available online: https://www.springerprofessional.de/comparative-knowledge-discovery-with-partial-orders-and-composit/1891480 (accessed on 3 October 2022).



| Cluster | Criteria | Unit | BodaBoda | Coaster | Kamunye | TukTuk |
|---|---|---|---|---|---|---|
| Benefit | c1 | Score 1–9 | 9 | 3 | 5 | 7 |
| c2 | Year | 1.5 | 3 | 2.5 | 2 | |
| c3 | Score 1–9 | 9 | 3 | 5 | 7 | |
| c4 | Score 1–9 | 3 | 9 | 7 | 5 | |
| c5 | Seats | 1 | 29 | 14 | 3 | |
| c6 | Score 1–9 | 3 | 9 | 7 | 5 | |
| c7 | Score 1–9 | 3 | 9 | 7 | 5 | |
| c8 | Year | 5 | 15 | 15 | 5 | |
| Cost | c9 | kg/100 km·passenger | 3.8 | 0.76 | 1 | 1.63 |
| c10 | $/day | 20 | 40 | 35 | 25 | |
| c11 | $/passenger·year | 165 | 23.3 | 29.3 | 87.9 | |
| Risk | c12 | Score 1–9 | 3 | 9 | 7 | 5 |
| c13 | Score 1–9 | 9 | 1 | 3 | 5 | |
| c14 | g CO2/pkm | 69 | 20 | 31 | 47 | |
| c15 | kJ/pkm | 2200 | 430 | 550 | 1000 |
| Criteria | nBB | nCoa | nKam | nTT |
|---|---|---|---|---|
| c1 | 1 | 0 | 0.333 | 0.667 |
| c2 | 0 | −1 | −0.667 | −0.333 |
| c3 | 1 | 0 | 0.333 | 0.667 |
| c4 | 0 | 1 | 0.667 | 0.333 |
| c5 | 0 | 1 | 0.464 | 0.071 |
| c6 | 0 | 1 | 0.667 | 0.333 |
| c7 | 0 | 1 | 0.667 | 0.333 |
| c8 | 0 | 1 | 1.000 | 0.000 |
| c9 | −1 | 0 | −0.079 | −0.286 |
| c10 | 0 | 1 | 0.750 | 0.250 |
| c11 | −1 | 0 | −0.042 | −0.456 |
| c12 | 0 | 1 | 0.667 | 0.333 |
| c13 | −1 | 0 | −0.250 | −0.500 |
| c14 | −1 | 0 | −0.224 | −0.551 |
| c15 | −1 | 0 | −0.068 | −0.322 |
| Regimes | c1 | c2 | c3 | c4 | c5 | c6 | c7 | c8 | c9 | c10 | c11 | c12 | c13 | c14 | c15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| cw1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| or | 2.7 | 5.4 | 5.4 | 2.7 | 5.4 | 5.4 | 2.7 | 5.4 | 7.5 | 15 | 7.5 | 13 | 8.8 | 6.6 | 6.6 |
| br | 3 | 5 | 6 | 7 | 7 | 8 | 1 | 6 | 12 | 15 | 15 | 20 | 5 | 5 | 2 |
| ca | 2 | 10 | 7 | 4 | 10 | 7 | 5 | 7 | 9 | 10 | 10 | 3 | 6 | 2 | 10 |
| cw1-or | na |
|---|---|
| cw1-br | na |
| cw1-ca | na |
| or-br | 0.7589 |
| or-ca | 0.2291 |
| br-ca | 0.1378 |
| Transportation Mode | cw1 | or | Br | ca |
|---|---|---|---|---|
| BB | −0.200 | −0.289 | −0.256 | −0.274 |
| Coa | 0.400 | 0.442 | 0.504 | 0.353 |
| Kam | 0.281 | 0.291 | 0.343 | 0.239 |
| TT | 0.036 | 0.000 | 0.038 | 0.022 |
| Regime | c1 | c2 | c3 | c4 | c5 | c6 | c7 | c8 | c9 | c10 | c11 | c12 | c13 | c14 | c15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| rd1 | 8 | 8 | 20 | 14 | 20 | 1 | 8 | 15 | 9 | 1 | 15 | 22 | 9 | 16 | 15 |
| rd2 | 3 | 9 | 18 | 6 | 0 | 5 | 1 | 22 | 0 | 17 | 6 | 19 | 21 | 22 | 8 |
| rd3 | 12 | 19 | 21 | 1 | 15 | 9 | 22 | 20 | 21 | 14 | 21 | 4 | 3 | 20 | 1 |
| rd4 | 1 | 5 | 1 | 8 | 22 | 11 | 1 | 11 | 14 | 4 | 10 | 18 | 11 | 6 | 9 |
| rd5 | 25 | 25 | 7 | 11 | 8 | 5 | 6 | 3 | 8 | 5 | 7 | 11 | 10 | 5 | 0 |
| rd6 | 18 | 14 | 2 | 11 | 2 | 23 | 9 | 19 | 1 | 18 | 4 | 12 | 14 | 25 | 5 |
| rd1–rd2 | 0.2295 |
|---|---|
| rd1–rd3 | −0.0201 |
| rd1–rd4 | 0.3906 |
| rd1–rd5 | −0.1483 |
| rd1–rd6 | −0.4426 |
| rd2–rd3 | −0.0804 |
| rd2–rd4 | −0.0891 |
| rd2–rd5 | −0.2134 |
| rd2–rd6 | 0.447 |
| rd3–rd4 | −0.2693 |
| rd3–rd5 | 0.0107 |
| rd3–rd6 | −0.1064 |
| rd4–rd5 | −0.2319 |
| rd4–rd6 | −0.2567 |
| rd5–rd6 | 0.1221 |
| Transportation Modes | rd1 | rd2 | rd3 | rd4 | rd5 | rd6 |
|---|---|---|---|---|---|---|
| BB | −0.199 | −0.229 | −0.163 | −0.364 | 0.015 | −0.164 |
| Coa | 0.403 | 0.389 | 0.325 | 0.530 | 0.176 | 0.452 |
| Kam | 0.281 | 0.289 | 0.256 | 0.308 | 0.161 | 0.326 |
| TT | 0.028 | −0.015 | 0.019 | −0.041 | 0.093 | 0.04 |
| Indicator | ||
|---|---|---|
| r1 | Pct. of sugar in diets | Percent sugar in diet |
| r2 | Meat consumption levels | Difference in meat consumption (g/capita(day)) from daily recommended intake (90 g/capita/day) |
| r3 | Saturated fat consumption | g/capita/day |
| r4 | Salt consumption | Average g/day sodium consumption |
| ID | r1 | r2 | r3 | r4 | |
|---|---|---|---|---|---|
| Algeria | DZA | 47.3 | 86.9 | 91 | 24.9 |
| Angola | AGO | 65.8 | 91.2 | 57.3 | 72.9 |
| Argentina | ARG | 12.2 | 7.4 | 14.9 | 59.2 |
| Australia | AUS | 13.3 | 11.4 | 6 | 48 |
| Austria | AUT | 22.4 | 41.1 | 28.3 | 33.8 |
| Bangladesh | BGD | 84.2 | 69.4 | 88.6 | 44.8 |
| Belgium | BEL | 15.7 | 76.9 | 31.9 | 47.2 |
| Brazil | BRA | 21.7 | 26.8 | 26.2 | 29.5 |
| Bulgaria | BGR | 40.9 | 70.8 | 69.4 | 42.6 |
| Burkina Faso | BFA | 78.2 | 79.4 | 80.8 | 62.5 |
| Cameroon | CMR | 74.9 | 78.2 | 79.8 | 83.6 |
| Canada | CAN | 19.6 | 35.3 | 48.8 | 40.2 |
| China | CHN | 84.6 | 68.2 | 15 | 10.2 |
| Colombia | COL | 27.5 | 69.4 | 30.5 | 30 |
| Cote d’Ivoire | CIV | 77.2 | 76.1 | 48 | 64.6 |
| Croatia | HRV | 4.1 | 48.7 | 40.2 | 40.2 |
| Cyprus | CYP | 46.8 | 52.2 | 58.1 | 30.8 |
| Czech Republic | CZE | 33.9 | 44.3 | 43.7 | 33 |
| Dem. Rep. of Congo | COG | 69.4 | 80.1 | 79.8 | 74.8 |
| Denmark | DNK | 7.5 | 49.2 | 29.8 | 52 |
| Egypt | EGY | 43.8 | 99.1 | 90.8 | 41 |
| Estonia | EST | 46.9 | 60.7 | 48 | 33.8 |
| Ethiopia | ETH | 77.5 | 72.5 | 94.3 | 78.8 |
| Finland | FIN | 40.7 | 50.6 | 0 | 36.5 |
| France | FRA | 25.4 | 49.6 | 8.3 | 38.6 |
| Germany | DEU | 22.6 | 49.9 | 26.1 | 44.8 |
| Ghana | GHA | 78 | 81.7 | 95.6 | 76.7 |
| Greece | GRC | 45.9 | 56.1 | 71.2 | 38.6 |
| Hungary | HUN | 31.2 | 44.1 | 25.8 | 26.3 |
| India | IND | 45.5 | 69.2 | 83.4 | 39.9 |
| Indonesia | IDN | 56.8 | 78.5 | 73.1 | 49.6 |
| Ireland | IRE | 25.4 | 50.8 | 33.9 | 39.4 |
| Israel | ISL | 53.8 | 28.2 | 43.9 | 38.1 |
| Italy | ITA | 42.3 | 46.6 | 31.4 | 21.2 |
| Japan | JPN | 41.9 | 82.1 | 77 | 8.6 |
| Jordan | JOR | 15.8 | 99.8 | 64.8 | 29 |
| Kenya | KEN | 49.6 | 82.1 | 90.1 | 100 |
| Latvia | LVA | 40.8 | 58.3 | 50.9 | 27.3 |
| Lebanon | LBN | 7.3 | 98.3 | 88.6 | 55.8 |
| Lithuania | LTU | 28 | 44.3 | 33.9 | 30.6 |
| Luxembourg | LUX | 49.1 | 46.6 | 11.1 | 30.6 |
| Madagascar | MDG | 74.2 | 79.5 | 94.1 | 80.7 |
| Malawi | MWI | 68.6 | 78.8 | 95.5 | 95.2 |
| Mali | MLI | 77.2 | 88 | 97.6 | 55.2 |
| Malta | MLT | 16.9 | 50.9 | 63.6 | 29.8 |
| Mexico | MEX | 10.2 | 60.6 | 35.2 | 65.7 |
| Morocco | MAR | 35.9 | 100 | 88.1 | 24.1 |
| Mozambique | MOZ | 60.2 | 75.4 | 60.5 | 79.6 |
| Netherlands | NLD | 32.3 | 60.7 | 34.7 | 50.7 |
| Niger | NER | 100 | 74.3 | 92.4 | 61.4 |
| Nigeria | NGA | 74 | 73 | 69.4 | 64.1 |
| Pakistan | PAK | 37.8 | 82.8 | 41.1 | 34.9 |
| Philippines | PHL | 43.7 | 96.8 | 48.2 | 24.7 |
| Poland | POL | 18.7 | 39 | 7.2 | 36.7 |
| Portugal | PRT | 52.3 | 32 | 30.4 | 26 |
| Romania | ROU | 50.4 | 65.5 | 63.8 | 29.2 |
| Russia | RUS | 19.8 | 53.4 | 57.9 | 27.9 |
| Rwanda | RWA | 70.4 | 73.3 | 80.4 | 96.8 |
| Saudi Arabia | SAU | 42.4 | 87.3 | 22.3 | 53.9 |
| Senegal | SEN | 54.2 | 81.4 | 74.8 | 55.2 |
| Sierra Leone | SLE | 84.9 | 74.4 | 52 | 72.4 |
| Slovakia | SVK | 29.1 | 73.9 | 65.1 | 26.3 |
| Slovenia | SVN | 45.3 | 60.2 | 64.1 | 26.3 |
| South Africa | ZAF | 30.4 | 66.4 | 57 | 73.2 |
| South Korea | KOR | 31.3 | 58.5 | 33.1 | 0 |
| Spain | ESP | 39 | 27.4 | 54.9 | 31.9 |
| Sudan | SDN | 23.8 | 88.3 | 95.5 | 76.1 |
| Sweden | SWE | 27.8 | 56.2 | 4.1 | 41.8 |
| Tanzania | TZA | 70 | 76.6 | 82.1 | 66 |
| Tunisia | TUN | 36 | 96.5 | 80.5 | 20.9 |
| Turkey | TUR | 46.9 | 94.1 | 43.4 | 29.8 |
| United Arab Emirates | ARE | 29.3 | 61.8 | 68.1 | 41.3 |
| Uganda | UGA | 62.7 | 78 | 69.2 | 83.1 |
| United Kingdom | GBR | 40.9 | 51.6 | 31.7 | 42.9 |
| United States | USA | 0 | 0 | 41.5 | 43.2 |
| Vietnam | VNM | 75.6 | 65.2 | 24.6 | 16.6 |
| Zambia | ZMB | 66 | 85.7 | 87.1 | 78.8 |
| Zimbabwe | ZWE | 27.9 | 85.3 | 100 | 56.6 |
| Indicators: | Expert | Political | Outcome | Uniform |
|---|---|---|---|---|
| r1: Percentage of sugar in diets | 0.375 | 0.143 | 0.400 | 0.250 |
| r2: Meat consumption levels | 0.250 | 0.286 | 0.200 | 0.250 |
| r3: Saturated fat consumption | 0.163 | 0.286 | 0.200 | 0.250 |
| r4: Salt consumption | 0.213 | 0.286 | 0.200 | 0.250 |
| ID | r1GLA | r2GLA | r3GLA | r4GLA | |
|---|---|---|---|---|---|
| Algeria | DZA | 0.595 | 0.647 | 0.595 | 0.625 |
| Angola | AGO | 0.723 | 0.727 | 0.706 | 0.718 |
| Argentina | ARG | 0.214 | 0.250 | 0.212 | 0.234 |
| Australia | AUS | 0.190 | 0.206 | 0.184 | 0.197 |
| Austria | AUT | 0.305 | 0.327 | 0.296 | 0.314 |
| Bangladesh | BGD | 0.728 | 0.700 | 0.742 | 0.718 |
| Belgium | BEL | 0.403 | 0.468 | 0.375 | 0.429 |
| Brazil | BRA | 0.254 | 0.267 | 0.252 | 0.261 |
| Bulgaria | BGR | 0.534 | 0.581 | 0.529 | 0.559 |
| Burkina Faso | BFA | 0.756 | 0.748 | 0.758 | 0.752 |
| Cameroon | CMR | 0.784 | 0.797 | 0.783 | 0.791 |
| Canada | CAN | 0.327 | 0.383 | 0.327 | 0.360 |
| China | CHN | 0.533 | 0.388 | 0.525 | 0.445 |
| Colombia | COL | 0.390 | 0.410 | 0.370 | 0.394 |
| Cote d’Ivoire | CIV | 0.695 | 0.649 | 0.686 | 0.665 |
| Croatia | HRV | 0.288 | 0.375 | 0.275 | 0.333 |
| Cyprus | CYP | 0.466 | 0.470 | 0.469 | 0.470 |
| Czech Republic | CZE | 0.379 | 0.394 | 0.378 | 0.387 |
| Dem. Rep. of Congo | COG | 0.749 | 0.770 | 0.747 | 0.760 |
| Denmark | DNK | 0.310 | 0.385 | 0.292 | 0.346 |
| Egypt | EGY | 0.647 | 0.722 | 0.637 | 0.687 |
| Estonia | EST | 0.477 | 0.474 | 0.473 | 0.474 |
| Ethiopia | ETH | 0.793 | 0.812 | 0.801 | 0.808 |
| Finland | FIN | 0.357 | 0.307 | 0.337 | 0.320 |
| France | FRA | 0.315 | 0.312 | 0.295 | 0.305 |
| Germany | DEU | 0.347 | 0.377 | 0.332 | 0.359 |
| Ghana | GHA | 0.815 | 0.837 | 0.820 | 0.830 |
| Greece | GRC | 0.510 | 0.540 | 0.515 | 0.530 |
| Hungary | HUN | 0.325 | 0.319 | 0.317 | 0.319 |
| India | IND | 0.564 | 0.615 | 0.567 | 0.595 |
| Indonesia | IDN | 0.633 | 0.656 | 0.630 | 0.645 |
| Ireland | IRE | 0.361 | 0.391 | 0.350 | 0.374 |
| Israel | ISL | 0.425 | 0.392 | 0.436 | 0.410 |
| Italy | ITA | 0.371 | 0.344 | 0.368 | 0.354 |
| Japan | JPN | 0.506 | 0.539 | 0.503 | 0.524 |
| Jordan | JOR | 0.476 | 0.576 | 0.450 | 0.524 |
| Kenya | KEN | 0.750 | 0.849 | 0.743 | 0.805 |
| Latvia | LVA | 0.439 | 0.448 | 0.436 | 0.443 |
| Lebanon | LBN | 0.536 | 0.704 | 0.515 | 0.625 |
| Lithuania | LTU | 0.336 | 0.351 | 0.330 | 0.342 |
| Luxembourg | LUX | 0.384 | 0.322 | 0.373 | 0.344 |
| Madagascar | MDG | 0.801 | 0.833 | 0.805 | 0.821 |
| Malawi | MWI | 0.812 | 0.868 | 0.813 | 0.845 |
| Mali | MLI | 0.785 | 0.798 | 0.790 | 0.795 |
| Malta | MLT | 0.357 | 0.436 | 0.356 | 0.403 |
| Mexico | MEX | 0.387 | 0.476 | 0.364 | 0.429 |
| Morocco | MAR | 0.579 | 0.658 | 0.568 | 0.620 |
| Mozambique | MOZ | 0.682 | 0.702 | 0.672 | 0.689 |
| Netherlands | NLD | 0.437 | 0.464 | 0.421 | 0.446 |
| Niger | NER | 0.841 | 0.795 | 0.856 | 0.820 |
| Nigeria | NGA | 0.709 | 0.696 | 0.709 | 0.701 |
| Pakistan | PAK | 0.490 | 0.508 | 0.469 | 0.492 |
| Philippines | PHL | 0.537 | 0.547 | 0.514 | 0.534 |
| Poland | POL | 0.257 | 0.264 | 0.241 | 0.254 |
| Portugal | PRT | 0.381 | 0.327 | 0.386 | 0.352 |
| Romania | ROU | 0.518 | 0.525 | 0.519 | 0.522 |
| Russia | RUS | 0.361 | 0.426 | 0.358 | 0.398 |
| Rwanda | RWA | 0.784 | 0.816 | 0.783 | 0.802 |
| Saudi Arabia | SAU | 0.528 | 0.528 | 0.497 | 0.515 |
| Senegal | SEN | 0.646 | 0.681 | 0.640 | 0.664 |
| Sierra Leone | SLE | 0.743 | 0.689 | 0.737 | 0.709 |
| Slovakia | SVK | 0.456 | 0.514 | 0.447 | 0.486 |
| Slovenia | SVN | 0.480 | 0.495 | 0.482 | 0.490 |
| South Africa | ZAF | 0.528 | 0.605 | 0.515 | 0.568 |
| South Korea | KOR | 0.317 | 0.306 | 0.308 | 0.307 |
| Spain | ESP | 0.372 | 0.382 | 0.384 | 0.383 |
| Sudan | SDN | 0.627 | 0.777 | 0.615 | 0.709 |
| Sweden | SWE | 0.340 | 0.331 | 0.315 | 0.325 |
| Tanzania | TZA | 0.728 | 0.742 | 0.729 | 0.737 |
| Tunisia | TUN | 0.551 | 0.617 | 0.540 | 0.585 |
| Turkey | TUR | 0.545 | 0.545 | 0.522 | 0.536 |
| United Arab Emirates | ARE | 0.463 | 0.531 | 0.460 | 0.501 |
| Uganda | UGA | 0.719 | 0.748 | 0.711 | 0.733 |
| United Kingdom | GBR | 0.425 | 0.419 | 0.416 | 0.418 |
| United States | USA | 0.160 | 0.242 | 0.169 | 0.212 |
| Vietnam | VNM | 0.521 | 0.412 | 0.515 | 0.455 |
| Zambia | ZMB | 0.771 | 0.813 | 0.767 | 0.794 |
| Zimbabwe | ZWE | 0.601 | 0.731 | 0.595 | 0.675 |
| Objects. | LPOMext | Rank |
|---|---|---|
| Top 10 | ||
| MWI | 77.556 | 1 |
| GHA | 77.275 | 2 |
| MDG | 75.467 | 3 |
| NER | 73.75 | 4 |
| ETH | 73.47 | 5 |
| RWA | 73.387 | 6 |
| KEN | 72 | 7 |
| MLI | 71.619 | 8 |
| ZMB | 70.762 | 9 |
| CMR | 69.708 | 10 |
| Bottom 10 | ||
| HUN | 9.748 | 69 |
| HRV | 8.305 | 70 |
| AUT | 7.844 | 71 |
| FRA | 7.109 | 72 |
| KOR | 6.728 | 73 |
| BRA | 4.5 | 74.5 |
| POL | 4.5 | 74.5 |
| ARG | 3 | 76 |
| AUS | 1.5 | 77.5 |
| USA | 1.5 | 77.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Carlsen, L.; Bruggemann, R. Combining Different Stakeholders’ Opinions in Multi-Criteria Decision Analyses Applying Partial Order Methodology. Standards 2022, 2, 503-521. https://doi.org/10.3390/standards2040035
Carlsen L, Bruggemann R. Combining Different Stakeholders’ Opinions in Multi-Criteria Decision Analyses Applying Partial Order Methodology. Standards. 2022; 2(4):503-521. https://doi.org/10.3390/standards2040035
Chicago/Turabian StyleCarlsen, Lars, and Rainer Bruggemann. 2022. "Combining Different Stakeholders’ Opinions in Multi-Criteria Decision Analyses Applying Partial Order Methodology" Standards 2, no. 4: 503-521. https://doi.org/10.3390/standards2040035
APA StyleCarlsen, L., & Bruggemann, R. (2022). Combining Different Stakeholders’ Opinions in Multi-Criteria Decision Analyses Applying Partial Order Methodology. Standards, 2(4), 503-521. https://doi.org/10.3390/standards2040035