
How Artificial Intelligence Is Shaping Medical Imaging Technology: A Survey of Innovations and Applications


Abstract
:1. Introduction
2. Methodology
3. Technological Innovations
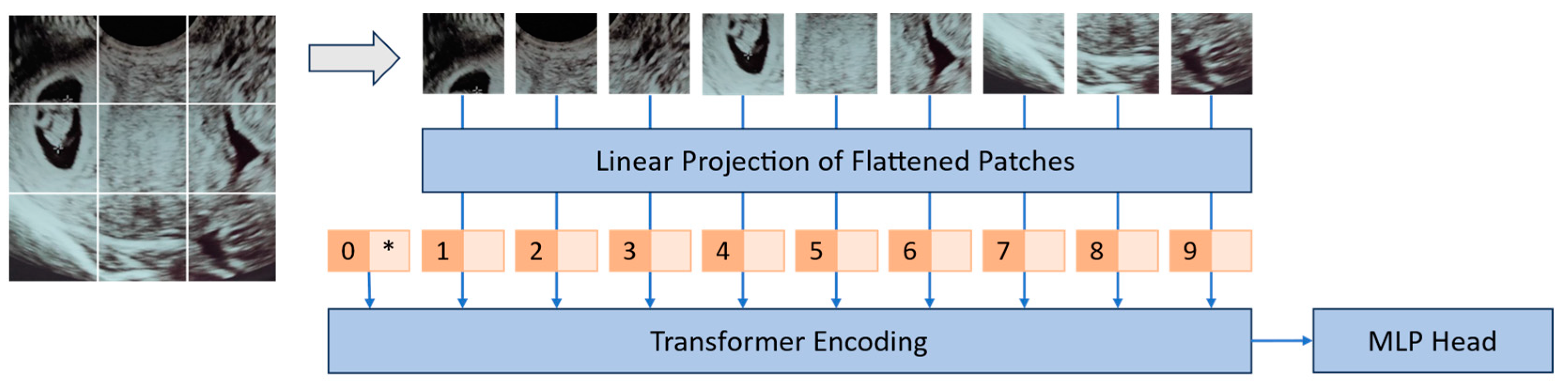
3.1. Transformers
3.2. Generative Models
3.3. Deep Learning Techniques and Performance Optimization
4. Applications
4.1. Medical Image Analysis for Disease Detection and Diagnosis
4.2. Imaging and Modeling Techniques for Surgical Planning and Intervention
4.3. Image and Model Enhancement for Improved Analysis
4.4. Medical Imaging Datasets
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ghaffar Nia, N.; Kaplanoglu, E.; Nasab, A. Evaluation of Artificial Intelligence Techniques in Disease Diagnosis and Prediction. Discov. Artif. Intell. 2023, 3, 5. [Google Scholar] [CrossRef]
- Kumar, Y.; Koul, A.; Singla, R.; Ijaz, M.F. Artificial Intelligence in Disease Diagnosis: A Systematic Literature Review, Synthesizing Framework and Future Research Agenda. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 8459–8486. [Google Scholar] [CrossRef] [PubMed]
- Hosny, A.; Parmar, C.; Quackenbush, J.; Schwartz, L.H.; Aerts, H.J.W.L. Artificial Intelligence in Radiology. Nat. Rev. Cancer 2018, 18, 500–510. [Google Scholar] [CrossRef]
- Waldstein, S.M.; Seeböck, P.; Donner, R.; Sadeghipour, A.; Bogunović, H.; Osborne, A.; Schmidt-Erfurth, U. Unbiased Identification of Novel Subclinical Imaging Biomarkers Using Unsupervised Deep Learning. Sci. Rep. 2020, 10, 12954. [Google Scholar] [CrossRef] [PubMed]
- Plested, J.; Gedeon, T. Deep Transfer Learning for Image Classification: A Survey. arXiv 2022, arXiv:2205.09904. [Google Scholar]
- Alowais, S.A.; Alghamdi, S.S.; Alsuhebany, N.; Alqahtani, T.; Alshaya, A.I.; Almohareb, S.N.; Aldairem, A.; Alrashed, M.; Bin Saleh, K.; Badreldin, H.A.; et al. Revolutionizing Healthcare: The Role of Artificial Intelligence in Clinical Practice. BMC Med. Educ. 2023, 23, 689. [Google Scholar] [CrossRef] [PubMed]
- Sinha, A.; Dolz, J. Multi-Scale Self-Guided Attention for Medical Image Segmentation. IEEE J. Biomed. Health Inform. 2020, 25, 121–130. [Google Scholar] [CrossRef] [PubMed]
- Popescu, D.; Stanciulescu, A.; Pomohaci, M.D.; Ichim, L. Decision Support System for Liver Lesion Segmentation Based on Advanced Convolutional Neural Network Architectures. Bioengineering 2022, 9, 467. [Google Scholar] [CrossRef]
- Altini, N.; Brunetti, A.; Puro, E.; Taccogna, M.G.; Saponaro, C.; Zito, F.A.; De Summa, S.; Bevilacqua, V. NDG-CAM: Nuclei Detection in Histopathology Images with Semantic Segmentation Networks and Grad-CAM. Bioengineering 2022, 9, 475. [Google Scholar] [CrossRef]
- van de Sande, D.; Sharabiani, M.; Bluemink, H.; Kneepkens, E.; Bakx, N.; Hagelaar, E.; van der Sangen, M.; Theuws, J.; Hurkmans, C. Artificial Intelligence Based Treatment Planning of Radiotherapy for Locally Advanced Breast Cancer. Phys. Imaging Radiat Oncol. 2021, 20, 111–116. [Google Scholar] [CrossRef]
- Schork, N.J. Artificial Intelligence and Personalized Medicine. Cancer Treat Res. 2019, 178, 265–283. [Google Scholar] [CrossRef] [PubMed]
- Uddin, M.; Wang, Y.; Woodbury-Smith, M. Artificial Intelligence for Precision Medicine in Neurodevelopmental Disorders. npj Digit. Med. 2019, 2, 112. [Google Scholar] [CrossRef] [PubMed]
- Hashimoto, D.A.; Rosman, G.; Rus, D.; Meireles, O.R. Artificial Intelligence in Surgery: Promises and Perils. Ann. Surg. 2018, 268, 70–76. [Google Scholar] [CrossRef] [PubMed]
- Literature Map Software for Lit Reviews & Research|Litmaps. Available online: https://www.litmaps.com/ (accessed on 8 December 2023).
- Iramuteq—IRaMuTeQ. Available online: http://www.iramuteq.org/ (accessed on 8 July 2023).
- Sarmet, M.; Kabani, A.; Coelho, L.; dos Reis, S.S.; Zeredo, J.L.; Mehta, A.K. The Use of Natural Language Processing in Palliative Care Research: A Scoping Review. Palliat. Med. 2023, 37, 275–290. [Google Scholar] [CrossRef] [PubMed]
- Roodschild, M.; Gotay Sardiñas, J.; Will, A. A New Approach for the Vanishing Gradient Problem on Sigmoid Activation. Prog. Artif. Intell. 2020, 9, 351–360. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning, Madison, WI, USA, 21 June 2010; pp. 807–814. [Google Scholar]
- Agarap, A.F. Deep Learning Using Rectified Linear Units (ReLU). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Deng, L. The MNIST Database of Handwritten Digit Images for Machine Learning Research [Best of the Web]. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent Advances in Convolutional Neural Networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- O’Shea, K.; Nash, R. An Introduction to Convolutional Neural Networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Yandex, A.B.; Lempitsky, V. Aggregating Local Deep Features for Image Retrieval. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7 December 2015; pp. 1269–1277. [Google Scholar]
- Nwankpa, C.; Ijomah, W.; Gachagan, A.; Marshall, S. Activation Functions: Comparison of Trends in Practice and Research for Deep Learning. arXiv 2018, arXiv:1811.03378. [Google Scholar]
- Szandała, T. Review and Comparison of Commonly Used Activation Functions for Deep Neural Networks. In Bio-Inspired Neurocomputing; Bhoi, A.K., Mallick, P.K., Liu, C.-M., Balas, V.E., Eds.; Studies in Computational Intelligence; Springer: Singapore, 2021; pp. 203–224. ISBN 9789811554957. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Maurício, J.; Domingues, I.; Bernardino, J. Comparing Vision Transformers and Convolutional Neural Networks for Image Classification: A Literature Review. Appl. Sci. 2023, 13, 5521. [Google Scholar] [CrossRef]
- Shamshad, F.; Khan, S.; Zamir, S.W.; Khan, M.H.; Hayat, M.; Khan, F.S.; Fu, H. Transformers in Medical Imaging: A Survey. Med Image Anal. 2022, 88, 102802. [Google Scholar] [CrossRef] [PubMed]
- Ali, H.; Mohsen, F.; Shah, Z. Improving Diagnosis and Prognosis of Lung Cancer Using Vision Transformers: A Scoping Review. BMC Med. Imaging 2023, 23, 129. [Google Scholar] [CrossRef] [PubMed]
- Al-hammuri, K.; Gebali, F.; Kanan, A.; Chelvan, I.T. Vision Transformer Architecture and Applications in Digital Health: A Tutorial and Survey. Vis. Comput. Ind. Biomed. Art 2023, 6, 14. [Google Scholar] [CrossRef]
- He, K.; Gan, C.; Li, Z.; Rekik, I.; Yin, Z.; Ji, W.; Gao, Y.; Wang, Q.; Zhang, J.; Shen, D. Transformers in Medical Image Analysis. Intell. Med. 2023, 3, 59–78. [Google Scholar] [CrossRef]
- Katar, O.; Yildirim, O. An Explainable Vision Transformer Model Based White Blood Cells Classification and Localization. Diagnostics 2023, 13, 2459. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2019. [Google Scholar]
- Touvron, H.; Cord, M.; Sablayrolles, A.; Synnaeve, G.; Jégou, H. Going Deeper with Image Transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Nwoye, C.I.; Yu, T.; Gonzalez, C.; Seeliger, B.; Mascagni, P.; Mutter, D.; Marescaux, J.; Padoy, N. Rendezvous: Attention Mechanisms for the Recognition of Surgical Action Triplets in Endoscopic Videos. Med. Image Anal. 2022, 78, 102433. [Google Scholar] [CrossRef] [PubMed]
- Rao, A.; Park, J.; Woo, S.; Lee, J.-Y.; Aalami, O. Studying the Effects of Self-Attention for Medical Image Analysis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- You, H.; Wang, J.; Ma, R.; Chen, Y.; Li, L.; Song, C.; Dong, Z.; Feng, S.; Zhou, X. Clinical Interpretability of Deep Learning for Predicting Microvascular Invasion in Hepatocellular Carcinoma by Using Attention Mechanism. Bioengineering 2023, 10, 948. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin Transformer V2: Scaling Up Capacity and Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- He, B.; Hofmann, T. Simplifying Transformer Blocks. arXiv 2023, arXiv:2311.01906. [Google Scholar]
- Henry, E.U.; Emebob, O.; Omonhinmin, C.A. Vision Transformers in Medical Imaging: A Review. arXiv 2022, arXiv:2211.10043. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Tayebi, R.M.; Mu, Y.; Dehkharghanian, T.; Ross, C.; Sur, M.; Foley, R.; Tizhoosh, H.R.; Campbell, C.J.V. Automated Bone Marrow Cytology Using Deep Learning to Generate a Histogram of Cell Types. Commun. Med. 2022, 2, 45. [Google Scholar] [CrossRef] [PubMed]
- Mammeri, S.; Amroune, M.; Haouam, M.-Y.; Bendib, I.; Corrêa Silva, A. Early Detection and Diagnosis of Lung Cancer Using YOLO v7, and Transfer Learning. Multimed. Tools Appl. 2023, 1–16. [Google Scholar] [CrossRef]
- Mortada, M.J.; Tomassini, S.; Anbar, H.; Morettini, M.; Burattini, L.; Sbrollini, A. Segmentation of Anatomical Structures of the Left Heart from Echocardiographic Images Using Deep Learning. Diagnostics 2023, 13, 1683. [Google Scholar] [CrossRef]
- Su, Y.; Liu, Q.; Xie, W.; Hu, P. YOLO-LOGO: A Transformer-Based YOLO Segmentation Model for Breast Mass Detection and Segmentation in Digital Mammograms. Comput. Methods Programs Biomed. 2022, 221, 106903. [Google Scholar] [CrossRef]
- Amiri Tehrani Zade, A.; Jalili Aziz, M.; Majedi, H.; Mirbagheri, A.; Ahmadian, A. Spatiotemporal Analysis of Speckle Dynamics to Track Invisible Needle in Ultrasound Sequences Using Convolutional Neural Networks: A Phantom Study. Int. J. CARS 2023, 18, 1373–1382. [Google Scholar] [CrossRef]
- Guo, S.; Sheng, S.; Lai, Z.; Chen, S. Trans-U: Transformer Enhanced U-Net for Medical Image Segmentation. In Proceedings of the 2022 3rd International Conference on Computer Vision, Image and Deep Learning & International Conference on Computer Engineering and Applications (CVIDL & ICCEA), Changchun, China, 20–22 May 2022; pp. 628–631. [Google Scholar]
- Zhang, Z.; Lu, X.; Cao, G.; Yang, Y.; Jiao, L.; Liu, F. ViT-YOLO:Transformer-Based YOLO for Object Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 2799–2808. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. IEEE Signal Process. Mag. 2014, 35, 53–65. [Google Scholar] [CrossRef]
- Platscher, M.; Zopes, J.; Federau, C. Image Translation for Medical Image Generation: Ischemic Stroke Lesion Segmentation. Biomed. Signal Process. Control. 2022, 72, 103283. [Google Scholar] [CrossRef]
- Armanious, K.; Jiang, C.; Fischer, M.; Küstner, T.; Hepp, T.; Nikolaou, K.; Gatidis, S.; Yang, B. MedGAN: Medical Image Translation Using GANs. Comput. Med. Imaging Graph. 2020, 79, 101684. [Google Scholar] [CrossRef] [PubMed]
- Kazeminia, S.; Baur, C.; Kuijper, A.; van Ginneken, B.; Navab, N.; Albarqouni, S.; Mukhopadhyay, A. GANs for Medical Image Analysis. Artif. Intell. Med. 2020, 109, 101938. [Google Scholar] [CrossRef] [PubMed]
- Skandarani, Y.; Jodoin, P.-M.; Lalande, A. GANs for Medical Image Synthesis: An Empirical Study. J. Imaging 2023, 9, 69. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.; Lei, Y.; Fu, Y.; Wynne, J.F.; Curran, W.J.; Liu, T.; Yang, X. A Review on Medical Imaging Synthesis Using Deep Learning and Its Clinical Applications. J. Appl. Clin. Med. Phys. 2021, 22, 11–36. [Google Scholar] [CrossRef] [PubMed]
- Ehrhardt, J.; Wilms, M. Chapter 8-Autoencoders and Variational Autoencoders in Medical Image Analysis. In Biomedical Image Synthesis and Simulation; Burgos, N., Svoboda, D., Eds.; The MICCAI Society Book Series; Academic Press: Cambridge, MA, USA, 2022; pp. 129–162. ISBN 978-0-12-824349-7. [Google Scholar]
- Kebaili, A.; Lapuyade-Lahorgue, J.; Ruan, S. Deep Learning Approaches for Data Augmentation in Medical Imaging: A Review. J. Imaging 2023, 9, 81. [Google Scholar] [CrossRef] [PubMed]
- Elbattah, M.; Loughnane, C.; Guérin, J.-L.; Carette, R.; Cilia, F.; Dequen, G. Variational Autoencoder for Image-Based Augmentation of Eye-Tracking Data. J. Imaging 2021, 7, 83. [Google Scholar] [CrossRef]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion Models Beat GANs on Image Synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 8780–8794. [Google Scholar]
- Kazerouni, A.; Aghdam, E.K.; Heidari, M.; Azad, R.; Fayyaz, M.; Hacihaliloglu, I.; Merhof, D. Diffusion Models in Medical Imaging: A Comprehensive Survey. Med. Image Anal. 2023, 88, 102846. [Google Scholar] [CrossRef]
- Yang, R.; Srivastava, P.; Mandt, S. Diffusion Probabilistic Modeling for Video Generation. Entropy 2023, 25, 1469. [Google Scholar] [CrossRef] [PubMed]
- Bobrow, T.L.; Golhar, M.; Vijayan, R.; Akshintala, V.S.; Garcia, J.R.; Durr, N.J. Colonoscopy 3D Video Dataset with Paired Depth from 2D-3D Registration. Med. Image Anal. 2023, 90, 102956. [Google Scholar] [CrossRef] [PubMed]
- Bond-Taylor, S.; Leach, A.; Long, Y.; Willcocks, C.G. Deep Generative Modelling: A Comparative Review of VAEs, GANs, Normalizing Flows, Energy-Based and Autoregressive Models. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 7327–7347. [Google Scholar] [CrossRef] [PubMed]
- Rezende, D.; Mohamed, S. Variational Inference with Normalizing Flows. In Proceedings of the 32nd International Conference on Machine Learning, Lile, France, 1 June 2015; pp. 1530–1538. [Google Scholar]
- Ho, J.; Chen, X.; Srinivas, A.; Duan, Y.; Abbeel, P. Flow++: Improving Flow-Based Generative Models with Variational Dequantization and Architecture Design. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
- Sun, H.; Mehta, R.; Zhou, H.H.; Huang, Z.; Johnson, S.C.; Prabhakaran, V.; Singh, V. DUAL-GLOW: Conditional Flow-Based Generative Model for Modality Transfer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 10611–10620. [Google Scholar]
- Uemura, T.; Näppi, J.J.; Ryu, Y.; Watari, C.; Kamiya, T.; Yoshida, H. A Generative Flow-Based Model for Volumetric Data Augmentation in 3D Deep Learning for Computed Tomographic Colonography. Int. J. CARS 2021, 16, 81–89. [Google Scholar] [CrossRef] [PubMed]
- Yi, X.; Walia, E.; Babyn, P. Generative Adversarial Network in Medical Imaging: A Review. Med. Image Anal. 2019, 58, 101552. [Google Scholar] [CrossRef]
- Laptev, V.V.; Gerget, O.M.; Markova, N.A. Generative Models Based on VAE and GAN for New Medical Data Synthesis. In Society 5.0: Cyberspace for Advanced Human-Centered Society; Kravets, A.G., Bolshakov, A.A., Shcherbakov, M., Eds.; Studies in Systems, Decision and Control; Springer International Publishing: Cham, Switzerland, 2021; pp. 217–226. ISBN 978-3-030-63563-3. [Google Scholar]
- Trevisan de Souza, V.L.; Marques, B.A.D.; Batagelo, H.C.; Gois, J.P. A Review on Generative Adversarial Networks for Image Generation. Comput. Graph. 2023, 114, 13–25. [Google Scholar] [CrossRef]
- Adeshina, S.A.; Adedigba, A.P. Bag of Tricks for Improving Deep Learning Performance on Multimodal Image Classification. Bioengineering 2022, 9, 312. [Google Scholar] [CrossRef]
- Saleh, G.A.; Batouty, N.M.; Haggag, S.; Elnakib, A.; Khalifa, F.; Taher, F.; Mohamed, M.A.; Farag, R.; Sandhu, H.; Sewelam, A.; et al. The Role of Medical Image Modalities and AI in the Early Detection, Diagnosis and Grading of Retinal Diseases: A Survey. Bioengineering 2022, 9, 366. [Google Scholar] [CrossRef]
- Han, J.-H. Artificial Intelligence in Eye Disease: Recent Developments, Applications, and Surveys. Diagnostics 2022, 12, 1927. [Google Scholar] [CrossRef]
- Daich Varela, M.; Sen, S.; De Guimaraes, T.A.C.; Kabiri, N.; Pontikos, N.; Balaskas, K.; Michaelides, M. Artificial Intelligence in Retinal Disease: Clinical Application, Challenges, and Future Directions. Graefes Arch. Clin. Exp. Ophthalmol. 2023, 261, 3283–3297. [Google Scholar] [CrossRef]
- Zain Eldin, H.; Gamel, S.A.; El-Kenawy, E.-S.M.; Alharbi, A.H.; Khafaga, D.S.; Ibrahim, A.; Talaat, F.M. Brain Tumor Detection and Classification Using Deep Learning and Sine-Cosine Fitness Grey Wolf Optimization. Bioengineering 2023, 10, 18. [Google Scholar] [CrossRef]
- Forte, G.C.; Altmayer, S.; Silva, R.F.; Stefani, M.T.; Libermann, L.L.; Cavion, C.C.; Youssef, A.; Forghani, R.; King, J.; Mohamed, T.-L.; et al. Deep Learning Algorithms for Diagnosis of Lung Cancer: A Systematic Review and Meta-Analysis. Cancers 2022, 14, 3856. [Google Scholar] [CrossRef] [PubMed]
- Hunger, T.; Wanka-Pail, E.; Brix, G.; Griebel, J. Lung Cancer Screening with Low-Dose CT in Smokers: A Systematic Review and Meta-Analysis. Diagnostics 2021, 11, 1040. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.-C.; So, E.C.; Saidy, L.; Wang, M.-J. Lung Field Segmentation in Chest X-Ray Images Using Superpixel Resizing and Encoder–Decoder Segmentation Networks. Bioengineering 2022, 9, 351. [Google Scholar] [CrossRef] [PubMed]
- Lee, K.W.; Chin, R.K.Y. Diverse COVID-19 CT Image-to-Image Translation with Stacked Residual Dropout. Bioengineering 2022, 9, 698. [Google Scholar] [CrossRef] [PubMed]
- Danala, G.; Maryada, S.K.; Islam, W.; Faiz, R.; Jones, M.; Qiu, Y.; Zheng, B. A Comparison of Computer-Aided Diagnosis Schemes Optimized Using Radiomics and Deep Transfer Learning Methods. Bioengineering 2022, 9, 256. [Google Scholar] [CrossRef] [PubMed]
- Adedigba, A.P.; Adeshina, S.A.; Aibinu, A.M. Performance Evaluation of Deep Learning Models on Mammogram Classification Using Small Dataset. Bioengineering 2022, 9, 161. [Google Scholar] [CrossRef]
- Zebari, D.A.; Ibrahim, D.A.; Zeebaree, D.Q.; Mohammed, M.A.; Haron, H.; Zebari, N.A.; Damaševičius, R.; Maskeliūnas, R. Breast Cancer Detection Using Mammogram Images with Improved Multi-Fractal Dimension Approach and Feature Fusion. Appl. Sci. 2021, 11, 12122. [Google Scholar] [CrossRef]
- Cè, M.; Caloro, E.; Pellegrino, M.E.; Basile, M.; Sorce, A.; Fazzini, D.; Oliva, G.; Cellina, M. Artificial Intelligence in Breast Cancer Imaging: Risk Stratification, Lesion Detection and Classification, Treatment Planning and Prognosis—A Narrative Review. Explor. Target. Antitumor. Ther. 2022, 3, 795–816. [Google Scholar] [CrossRef]
- Zhang, T.; Tan, T.; Samperna, R.; Li, Z.; Gao, Y.; Wang, X.; Han, L.; Yu, Q.; Beets-Tan, R.G.H.; Mann, R.M. Radiomics and Artificial Intelligence in Breast Imaging: A Survey. Artif Intell. Rev. 2023, 56, 857–892. [Google Scholar] [CrossRef]
- Pesapane, F.; De Marco, P.; Rapino, A.; Lombardo, E.; Nicosia, L.; Tantrige, P.; Rotili, A.; Bozzini, A.C.; Penco, S.; Dominelli, V.; et al. How Radiomics Can Improve Breast Cancer Diagnosis and Treatment. J. Clin. Med. 2023, 12, 1372. [Google Scholar] [CrossRef] [PubMed]
- Luo, C.; Zhao, S.; Peng, C.; Wang, C.; Hu, K.; Zhong, X.; Luo, T.; Huang, J.; Lu, D. Mammography Radiomics Features at Diagnosis and Progression-Free Survival among Patients with Breast Cancer. Br. J. Cancer 2022, 127, 1886–1892. [Google Scholar] [CrossRef] [PubMed]
- Granzier, R.W.Y.; Verbakel, N.M.H.; Ibrahim, A.; van Timmeren, J.E.; van Nijnatten, T.J.A.; Leijenaar, R.T.H.; Lobbes, M.B.I.; Smidt, M.L.; Woodruff, H.C. MRI-Based Radiomics in Breast Cancer: Feature Robustness with Respect to Inter-Observer Segmentation Variability. Sci. Rep. 2020, 10, 14163. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization Cancer. Key Facts. Available online: https://www.who.int/news-room/fact-sheets/detail/cancer (accessed on 16 June 2023).
- Bilic, P.; Christ, P.; Li, H.B.; Vorontsov, E.; Ben-Cohen, A.; Kaissis, G.; Szeskin, A.; Jacobs, C.; Mamani, G.E.H.; Chartrand, G.; et al. The Liver Tumor Segmentation Benchmark (LiTS). Med. Image Anal. 2023, 84, 102680. [Google Scholar] [CrossRef] [PubMed]
- Cardobi, N.; Dal Palù, A.; Pedrini, F.; Beleù, A.; Nocini, R.; De Robertis, R.; Ruzzenente, A.; Salvia, R.; Montemezzi, S.; D’Onofrio, M. An Overview of Artificial Intelligence Applications in Liver and Pancreatic Imaging. Cancers 2021, 13, 2162. [Google Scholar] [CrossRef] [PubMed]
- Huang, X.; Wang, H.; She, C.; Feng, J.; Liu, X.; Hu, X.; Chen, L.; Tao, Y. Artificial Intelligence Promotes the Diagnosis and Screening of Diabetic Retinopathy. Front. Endocrinol. 2022, 13, 946915. [Google Scholar] [CrossRef] [PubMed]
- Sheng, B.; Chen, X.; Li, T.; Ma, T.; Yang, Y.; Bi, L.; Zhang, X. An Overview of Artificial Intelligence in Diabetic Retinopathy and Other Ocular Diseases. Front. Public Health 2022, 10, 971943. [Google Scholar] [CrossRef]
- Li, S.; Zhao, R.; Zou, H. Artificial Intelligence for Diabetic Retinopathy. Chin. Med. J. Engl. 2022, 135, 253–260. [Google Scholar] [CrossRef]
- Banerjee, I.; de Sisternes, L.; Hallak, J.A.; Leng, T.; Osborne, A.; Rosenfeld, P.J.; Gregori, G.; Durbin, M.; Rubin, D. Prediction of Age-Related Macular Degeneration Disease Using a Sequential Deep Learning Approach on Longitudinal SD-OCT Imaging Biomarkers. Sci. Rep. 2020, 10, 15434. [Google Scholar] [CrossRef]
- Yin, C.; Moroi, S.E.; Zhang, P. Predicting Age-Related Macular Degeneration Progression with Contrastive Attention and Time-Aware LSTM. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 14 August 2022; pp. 4402–4412. [Google Scholar]
- Jin, K.; Ye, J. Artificial Intelligence and Deep Learning in Ophthalmology: Current Status and Future Perspectives. Adv. Ophthalmol. Pract. Res. 2022, 2, 100078. [Google Scholar] [CrossRef]
- Bai, J.; Wan, Z.; Li, P.; Chen, L.; Wang, J.; Fan, Y.; Chen, X.; Peng, Q.; Gao, P. Accuracy and Feasibility with AI-Assisted OCT in Retinal Disorder Community Screening. Front. Cell Dev. Biol. 2022, 10, 1053483. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Zhao, C.; Wang, L.; Wang, G.; Lv, B.; Lv, C.; Xie, G.; Wang, F. Evaluation of an OCT-AI–Based Telemedicine Platform for Retinal Disease Screening and Referral in a Primary Care Setting. Transl. Vis. Sci. Technol. 2022, 11, 4. [Google Scholar] [CrossRef] [PubMed]
- Bertolini, M.; Rossoni, M.; Colombo, G. Operative Workflow from CT to 3D Printing of the Heart: Opportunities and Challenges. Bioengineering 2021, 8, 130. [Google Scholar] [CrossRef] [PubMed]
- Cappello, I.A.; Candelari, M.; Pannone, L.; Monaco, C.; Bori, E.; Talevi, G.; Ramak, R.; La Meir, M.; Gharaviri, A.; Chierchia, G.B.; et al. 3D Printed Surgical Guide for Coronary Artery Bypass Graft: Workflow from Computed Tomography to Prototype. Bioengineering 2022, 9, 179. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Li, Y.; Shin, B.-S. Robust Medical Image Colorization with Spatial Mask-Guided Generative Adversarial Network. Bioengineering 2022, 9, 721. [Google Scholar] [CrossRef] [PubMed]
- National Library of Medicine Visible Human Project. Available online: https://www.nlm.nih.gov/research/visible/visible_human.html (accessed on 16 June 2023).
- Bloch, B.N.; Madabhushi, A.; Huisman, H.; Freymann, J.; Kirby, J.; Grauer, M.; Enquobahrie, A.; Jaffe, C.; Clarke, L.; Farahani, K. NCI-ISBI 2013 Challenge: Automated Segmentation of Prostate Structures (ISBI-MR-Prostate-2013). 2015. Available online: https://www.cancerimagingarchive.net/analysis-result/isbi-mr-prostate-2013/ (accessed on 16 June 2023).
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]
- Zaffino, P.; Marzullo, A.; Moccia, S.; Calimeri, F.; De Momi, E.; Bertucci, B.; Arcuri, P.P.; Spadea, M.F. An Open-Source COVID-19 CT Dataset with Automatic Lung Tissue Classification for Radiomics. Bioengineering 2021, 8, 26. [Google Scholar] [CrossRef]
- Ahmad, W.; Ali, H.; Shah, Z.; Azmat, S. A New Generative Adversarial Network for Medical Images Super Resolution. Sci. Rep. 2022, 12, 9533. [Google Scholar] [CrossRef]
- Bing, X.; Zhang, W.; Zheng, L.; Zhang, Y. Medical Image Super Resolution Using Improved Generative Adversarial Networks. IEEE Access 2019, 7, 145030–145038. [Google Scholar] [CrossRef]
- Zhu, J.; Yang, G.; Lio, P. A Residual Dense Vision Transformer for Medical Image Super-Resolution with Segmentation-Based Perceptual Loss Fine-Tuning. arXiv 2023, arXiv:2302.11184. [Google Scholar]
- Wei, C.; Ren, S.; Guo, K.; Hu, H.; Liang, J. High-Resolution Swin Transformer for Automatic Medical Image Segmentation. Sensors 2023, 23, 3420. [Google Scholar] [CrossRef]
- Zhang, K.; Hu, H.; Philbrick, K.; Conte, G.M.; Sobek, J.D.; Rouzrokh, P.; Erickson, B.J. SOUP-GAN: Super-Resolution MRI Using Generative Adversarial Networks. Tomography 2022, 8, 905–919. [Google Scholar] [CrossRef]
- Yang, H.; Wang, Z.; Liu, X.; Li, C.; Xin, J.; Wang, Z. Deep Learning in Medical Image Super Resolution: A Review. Appl. Intell. 2023, 53, 20891–20916. [Google Scholar] [CrossRef]
- Chen, C.; Wang, Y.; Zhang, N.; Zhang, Y.; Zhao, Z. A Review of Hyperspectral Image Super-Resolution Based on Deep Learning. Remote Sens. 2023, 15, 2853. [Google Scholar] [CrossRef]
- Menze, B.H.; Jakab, A.; Bauer, S.; Kalpathy-Cramer, J.; Farahani, K.; Kirby, J.; Burren, Y.; Porz, N.; Slotboom, J.; Wiest, R.; et al. The Multimodal Brain Tumor Image Segmentation Benchmark (BRATS). IEEE Trans. Med. Imaging 2015, 34, 1993–2024. [Google Scholar] [CrossRef]
- The 2023 Kidney Tumor Segmentation Challenge. Available online: https://kits-challenge.org/kits23/ (accessed on 20 October 2023).
- Rajpurkar, P.; Irvin, J.; Bagul, A.; Ding, D.; Duan, T.; Mehta, H.; Yang, B.; Zhu, K.; Laird, D.; Ball, R.L.; et al. MURA: Large Dataset for Abnormality Detection in Musculoskeletal Radiographs. arXiv 2018, arXiv:1712.06957. [Google Scholar]
- MedPix. Available online: https://medpix.nlm.nih.gov/home (accessed on 12 December 2023).
- NIH Chest X-rays. Available online: https://www.kaggle.com/datasets/nih-chest-xrays/data (accessed on 12 December 2023).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Description | Reference |
|---|---|---|
| BRATS | The Multimodal Brain Tumor Segmentation Benchmark (BRATS) is an annual challenge that aims to compare different algorithms for brain tumor segmentation. The dataset, which has received several enhancements over the years, consists of preoperative multimodal MRI scans of glioblastoma and lower-grade glioma with ground truth labels and survival data for participants to segment and predict the tumor. | [118] |
| KiTS | The Kidney Tumor Segmentation Benchmark (KiTS) is a dataset used to evaluate and compare algorithms for kidney tumor segmentation. The dataset consists of CT scans of the kidneys and kidney tumors, with 300 scans in total. The data and segmentations are provided by various clinical sites around the world. | [119] |
| LiTS | The Liver Tumor Segmentation Benchmark (LiTS) is a dataset used to evaluate and compare liver tumor segmentation algorithms. The dataset consists of CT scans of the liver and liver tumors, with 130 scans in the training set and 70 scans in the test set. The data and segmentations are provided by various clinical sites around the world. | [94] |
| MURA | The Musculoskeletal Radiographs (MURA) dataset is a large dataset of musculoskeletal radiographs containing 40,561 images from 14,863 studies. Each study is manually labeled by radiologists as either normal or abnormal. | [120] |
| MedPix | A free online medical image database with over 59,000 indexed and curated images from over 12,000 patients. | [121] |
| NIH Chest X-rays | A large dataset of chest X-ray images containing over 112,000 images from more than 30,000 unique patients. The images are labeled with 14 common disease labels. | [122] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pinto-Coelho, L. How Artificial Intelligence Is Shaping Medical Imaging Technology: A Survey of Innovations and Applications. Bioengineering 2023, 10, 1435. https://doi.org/10.3390/bioengineering10121435
Pinto-Coelho L. How Artificial Intelligence Is Shaping Medical Imaging Technology: A Survey of Innovations and Applications. Bioengineering. 2023; 10(12):1435. https://doi.org/10.3390/bioengineering10121435
Chicago/Turabian StylePinto-Coelho, Luís. 2023. "How Artificial Intelligence Is Shaping Medical Imaging Technology: A Survey of Innovations and Applications" Bioengineering 10, no. 12: 1435. https://doi.org/10.3390/bioengineering10121435
APA StylePinto-Coelho, L. (2023). How Artificial Intelligence Is Shaping Medical Imaging Technology: A Survey of Innovations and Applications. Bioengineering, 10(12), 1435. https://doi.org/10.3390/bioengineering10121435