1. Introduction
Segmentation is an essential task in medical imaging that is common across different imaging modalities and fields such as cardiac, abdominal, musculoskeletal, and lung imaging, amongst others [
1,
2,
3,
4]. Deep learning (DL) has enabled high performance on these challenges, but the power-law relationship between algorithmic performance and the amount of high-quality labeled training data fundamentally limits robustness and widespread use [
5].
Recent advances in self-supervised learning (SSL) provide an opportunity to reduce the annotation burden for deep learning models [
6]. In SSL, a model is first pretrained on a “pretext” task, during which unlabeled images are perturbed and the model is trained to predict or correct the perturbations. The model is then fine-tuned for downstream tasks. Previous works have shown that such models can achieve high performance even when fine-tuned on only a small labeled training set [
7,
8,
9]. While most SSL models in computer vision have been used for the downstream task of image classification, segmentation comparatively remains an under-explored task [
10].
In this work, we systematically evaluate the efficacy of SSL for medical image segmentation across two domains—MRI and CT. We investigate “context prediction” [
7] and “context restoration” [
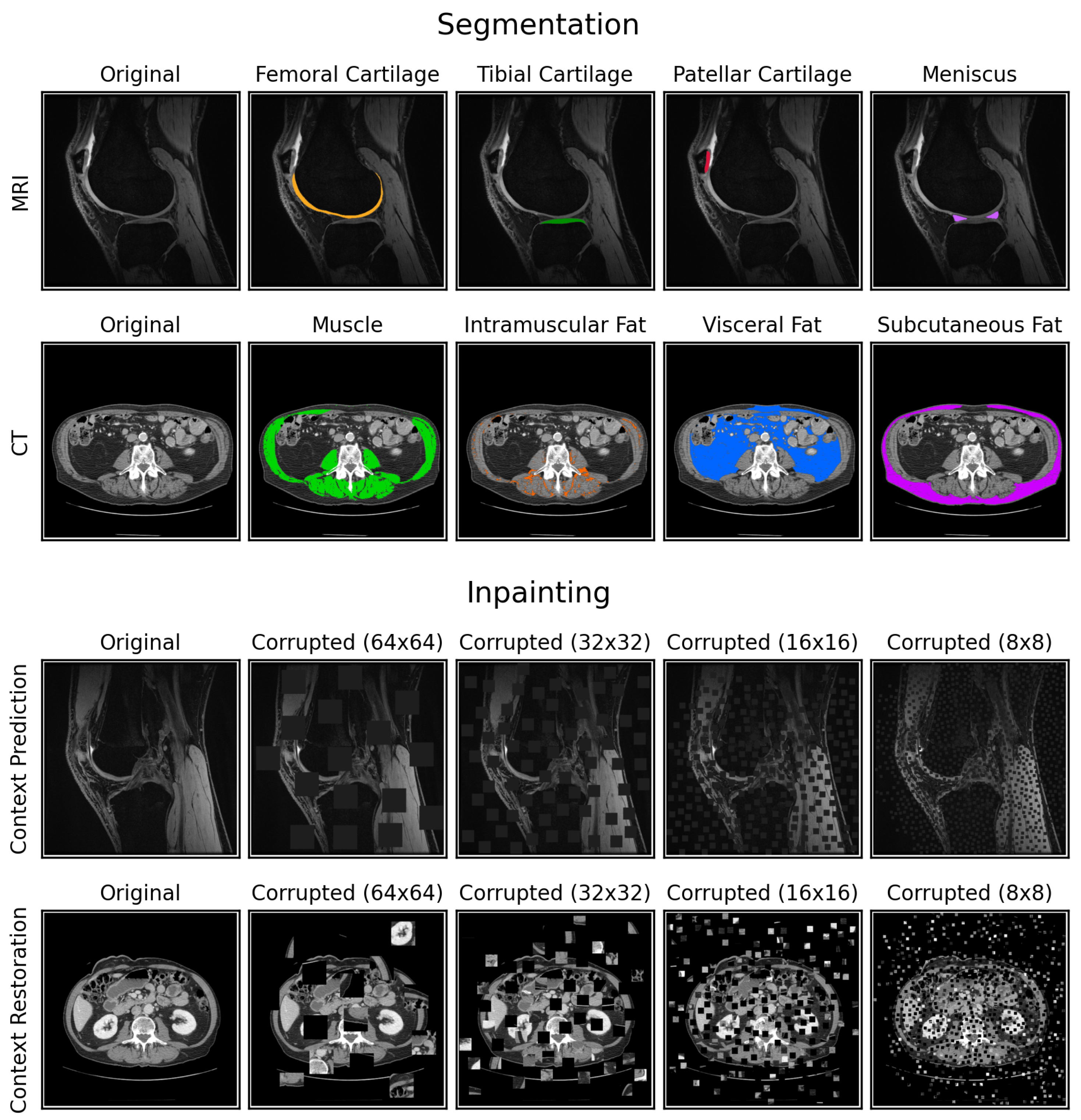
8], two well-known and easy-to-implement archetypes of restoration-based pretext tasks that produce image-level representations during pretraining for eventual fine-tuning. Context prediction sets pixel values in random image patches to zero, while context restoration randomly swaps pairs of image patches within an image while maintaining the distribution of pixel values (
Figure 1). For both tasks, the model needs to recover the original image given the corrupted image, a process we refer to as “inpainting”. We consider these two tasks because they maintain same input-output sizes, akin to segmentation. We hypothesize that such pretext tasks allow construction of useful, image-level representations that are more suitable for downstream segmentation.
While context prediction and context restoration have been proposed before, the effects of the large space of design choices for these two pretext tasks, such as patch sizes for image corruption and learning rates for transfer learning, are unexplored. In addition, prior works exploring SSL for medical image segmentation have primarily focused on the accuracy of segmentation using metrics such as Dice scores [
8,
11], but have not investigated if SSL can improve clinically-relevant metrics, such as T2 relaxation times for musculoskeletal MRI scans and mean Hounsfield Unit (HU) values for CT scans. These metrics can provide biomarkers of biochemical changes in tissue structure prior to the onset of gross morphological changes [
12,
13]. Furthermore, within the context of empirical data scaling laws in DL, past SSL works have rarely explored benefits of increasing the number of unlabeled images during pretraining [
14]. Characterizing the efficiency of SSL methods with unlabeled data can lead to more informed decisions regarding data collection, an important practical consideration for medical image segmentation. In this work, we address the above gaps by (1) investigating how different design choices in SSL implementation affect the quality of the pretrained model, (2) calculating how varying unlabeled data extents affects SSL performance for downstream segmentation, (3) quantifying our results using clinically-relevant metrics to investigate if SSL can outperform supervised learning in label-limited scenarios, (4) evaluating where SSL can improve performance, across different extents of labeled training data availability, and (5) providing detailed analyses, recommendations, and open-sourcing our code to build optimal SSL models for medical image segmentation (code available at
https://github.com/ad12/MedSegPy).
2. Materials and Methods
2.1. Datasets
2.1.1. MRI Dataset
We used 155 labeled knee 3D MRI volumes (around 160 slices per volume) from the SKM-TEA dataset [
15] and 86 unlabeled volumes (around 160 to 180 slices per volume), each with slice dimensions of 512 × 512 (other scan parameters in [
15]). All volumes were acquired using a 5-min 3D quantitative double-echo in steady-state (qDESS) sequence, which has been used for determining morphological and quantitative osteoarthritis biomarkers and for routine diagnostic knee MRI [
16,
17,
18,
19]. The labeled volumes included manual segmentations for the femoral, tibial, and patellar cartilages, and the meniscus. The labeled volumes were split into 86 volumes for training, 33 for validation, and 36 for testing, following the splits prescribed in [
15]. The 86 training volumes were further split into additional subsets, consisting of 50% (43 volumes), 25% (22 volumes), 10% (9 volumes), and 5% (5 volumes) training data, to represent label-limited scenarios. All scans in smaller subsets were included in larger subsets.
2.1.2. CT Dataset
The 2D CT dataset consisted of 886 labeled and 7799 unlabeled abdominal CT slices at the L3 vertebral level. The unlabeled images were used in a prior study exploring the impact of body composition on cardiovascular outcomes [
20]. The labeled slices included manual segmentations for subcutaneous, visceral, and intramuscular adipose tissue and muscle. These labeled slices were split into 709 slices for training, 133 for validation, and 44 for testing. The training set was split in a similar manner as the MRI volumes into 4 additional subsets of 50% (354 slices), 25% (177 slices), 10% (71 slices), and 5% (35 slices) training data. No metadata from the dataset were used in any models.
2.2. Data Preprocessing
All models segmented 2D slices for MRI and CT images. Each CT image was preprocessed at different windows and levels (W/L) of HU to emphasize different image contrasts, resulting in three-channel images: soft-tissue (W/L = 400/50), bone (W/L = 1800/40), and a custom setting (W/L = 500/50). All images were normalized to have zero mean and unit standard deviation, with MR images normalized by volume and CT images normalized per channel.
2.3. Model Architecture and Optimization
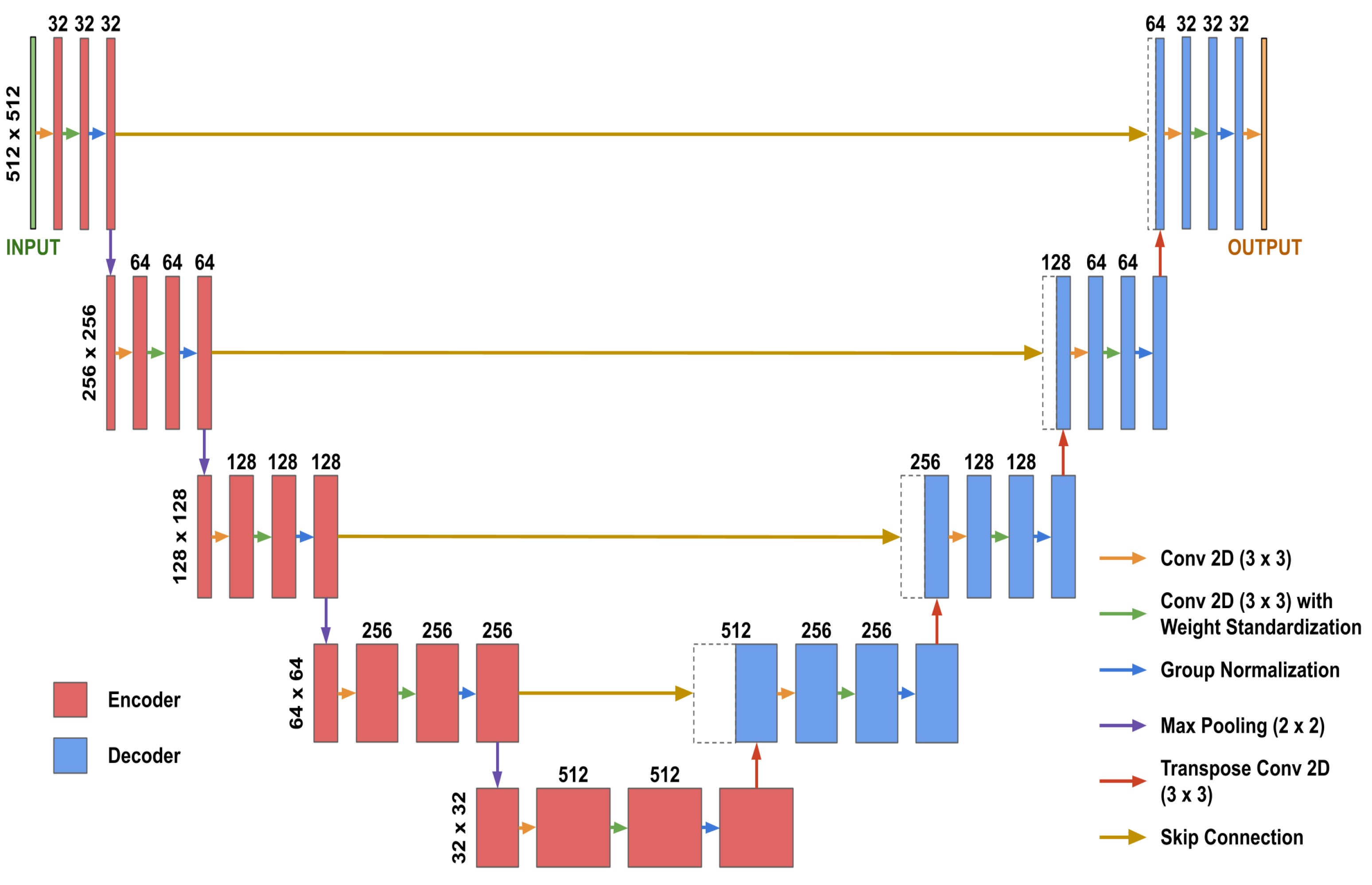
2D U-Net models [
21] with Group Normalization [
22], weight standardization [
23], and He random weight initializations [
24] were used for inpainting and segmentation (
Figure 2). Both inpainting and segmentation used identical U-Nets, except for the final convolutional layer, which we refer to as the “post-processing” layer. For inpainting, the post-processing layer produced an output image with the same number of channels as the input image, whereas for segmentation, it produced a 4-channel image for the four segmentation classes in each dataset.
We used L2 norm loss for inpainting and Dice loss, aggregated over mini-batches per segmentation class, for segmentation. All training was performed with early stopping and the ADAM optimizer [
25] (
= 0.99 and
= 0.995) with a batch size of 9 on an NVIDIA 2080Ti GPU. Additional details are in
Appendix A.1.
2.4. Image Corruption for Pretext Tasks
We incorporated random block selection to select the square image patches to corrupt during pretraining. To ensure the amount of corruption per image was fixed and did not affect later comparison, the patches for each image were iteratively selected and corrupted until 1/4 of the total image area was corrupted.
For context prediction, we selected and set random patches of dimensions
K ×
K to zero in an iterative manner until the number of pixels set to zero equaled or exceeded 1/4 of the total image area. For context restoration, randomly selected pairs of non-overlapping
K ×
K image patches were swapped in an iterative manner until the number of corrupted pixels equaled or exceeded 1/4 of the total image area. We refer to the result of both methods as “masks”. The context prediction binary mask specified which pixels were zero and the context restoration mask was a list of patch pairs to be swapped. When pretraining with multi-channel CT images, the locations of the patch corruptions were identical across channels to avoid shortcut learning [
26]. Example image corruptions are shown in
Figure 1.
To train the model to inpaint any arbitrarily corrupted image region without memorization of image content, we sampled a random mask every iteration for all images. For computational efficiency, we precomputed 100 random masks before training. We further randomly rotated the masks by either 0, 90, 180, or 270° counter-clockwise to increase the effective number of masks used during training to 400.
2.5. Design Choices for SSL Implementation
Design choices for inpainting-based SSL segmentation revolving around pretraining task implementations [
7,
8] and transfer learning [
27,
28,
29] have not been systematically compared. To overcome these shortcomings, we explored the following questions:
Which pretrained weights should be transferred for fine-tuning?
How should the transferred pretrained weights be fine-tuned?
What should be the initial learning rate when fine-tuning?
What patch size should be used when corrupting images for inpainting?
How should the locations of the patches be sampled when corrupting images for inpainting?
2.5.1. Design Choices for Transfer Learning (#1–3)
For design choice #1 (which pretrained weights to transfer), we compared transferring only the U-Net encoder weights [
7] with transferring both the encoder and decoder weights [
8].
For design choice #2, we compare (i) fine-tuning all pretrained weights immediately after transferring [
27,
28], and (ii) freezing pretrained weights after transferring and training until convergence, then subsequently unfreezing pretrained weights and training all weights until convergence [
29,
30].
For design choice #3, we selected four initial learning rates: 1 × 10, 1 × 10, 1 × 10, and 1 × 10, to evaluate whether pretrained features are distorted with larger learning rates.
To compare different combinations of these three design choices, we performed a grid search and defined the best combination to be the one with the best segmentation performance on the MRI test set when trained with the MRI training subset with 5% training data. More details are in
Appendix B.1.
2.5.2. Design Choices for Pretraining (#4–5)
For design choice #4, we compare patch sizes of 64 × 64, 32 × 32, 16 × 16, and 8 × 8 (
Figure 1). For design choice #5, we compare two sampling methods: (i) fully-random sampling where the location of each patch was selected at random and constrained to lie completely within the image [
7,
8], and (ii) Poisson-disc sampling that enforces the centers of all
K ×
K patches to lie at least
pixels away from each other to prevent overlapping patches [
31]. To compare different combinations of design choices #4 and #5 and the two pretext tasks, we performed a grid search by training a model for each combination five times, each time using one of the five training data subsets, for both datasets. We also trained a fully-supervised model for each dataset and training data subset for a baseline comparison. All models were fine-tuned in an identical manner with the same random seed after pretraining, using the best combination of design choices #1–3. All inpainting models were compared by computing the L2 norm of the generated inpainted images. When computing the L2 norm value for each three-channel CT image, the L2 norm value was computed per channel and averaged across all channels. All segmentation models were compared by computing the Dice coefficient for each segmentation class in the test set, averaged across all available volumes/slices.
2.5.3. Optimal Pretraining Evaluation
We defined the optimal pretraining strategy as the strategy that provided the most benefit over supervised learning, across image modalities and training data extents, in the experiment described in
Section 2.5.2.
For each baseline (fully-supervised model) and SSL model trained in the experiment using 50%, 25%, 10%, and 5% training data, we computed class-averaged Dice scores for every test volume/slice in the MRI and CT datasets. For each pretraining strategy and dataset, we compared whether the set of Dice scores of the corresponding SSL models were significantly higher than that of the respective fully-supervised models using one-sided Wilcoxon signed-rank tests. As a heuristic, the pretraining strategies were sorted by their associated p-values and the pretraining strategy that appeared in the top three for both the MRI and CT datasets was selected as the optimal pretraining strategy. We defined the optimally trained model for each dataset as the SSL model that was pretrained with this optimal pretraining strategy and fine-tuned for segmentation using the best combination of design choices #1-3.
2.6. Impact of Extent of Unlabeled Data
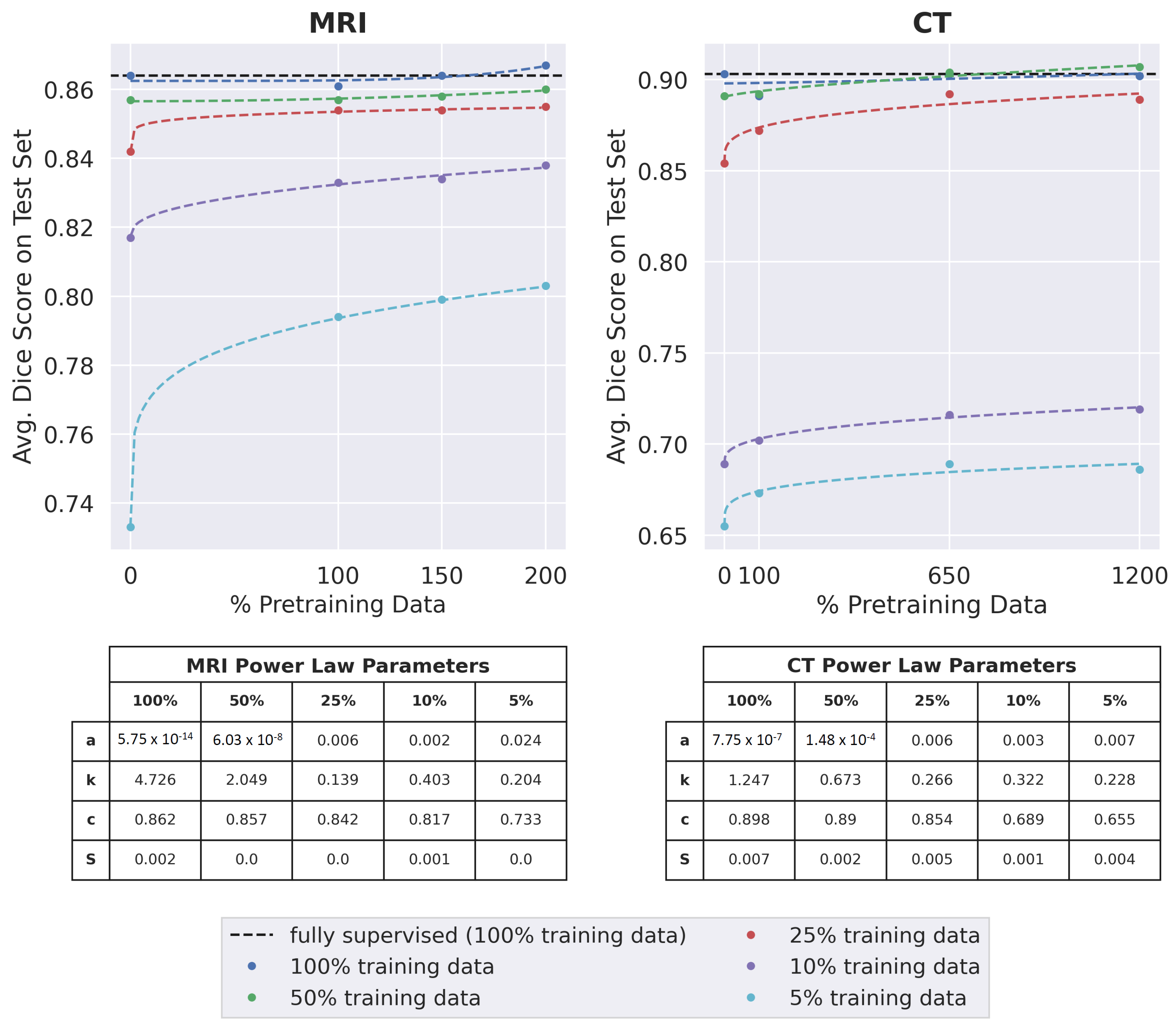
To measure the effect of the number of pretraining images on downstream segmentation performance, the optimally trained model was pretrained with the standard training set as well as two supersets of the training set containing additional unlabeled imaging data. We refer to the standard training set as 100% pretraining data (86 volumes for MRI and 709 slices for CT). For the MRI dataset, the second and third sets consisted of 150% (129 volumes) and 200% (172 volumes) pretraining data, respectively. For the CT dataset, the second and third sets consisted of 650% (4608 slices) and 1200% (8508 slices) pretraining data, respectively. After pretraining, all the pretrained models were fine-tuned with the five subsets of labeled training data and a Dice score was computed for each fine-tuned model, averaged across all segmentation classes and all volumes/slices in the test set. To quantify the relationship between Dice score and the amount of pretraining data for each subset of labeled training data, a curve of best fit was found using non-linear least squares. The Residual Standard Error, defined as , was computed to quantify how well the curve of best fit fits the data.
For MRI and CT, the pretraining dataset that led to the best average Dice score across the extents of labeled training data was chosen for further experiments.
2.7. Comparing SSL and Fully-Supervised Learning
We compared baseline fully-supervised models and the optimally trained models pretrained with the chosen pretraining dataset from the experiment described in
Section 2.6. For each training data subset, models were evaluated using two clinically-relevant metrics for determining cartilage, muscle, and adipose tissue health status. For MRI, we computed mean T2 relaxation time per tissue and tissue volume [
32]. For CT, we computed cross-sectional area and mean HU value per tissue. We calculated their percentage errors by comparing them to values derived from using ground truth segmentations to compute the metrics.
To determine which images benefit maximally with SSL, we compared and visualized the percentage error in the clinically-relevant metrics between supervised learning and SSL. For both supervised learning and SSL, the percentage error for each test image was averaged over all classes and label-limited scenarios.
2.8. Statistical Analysis
All statistical comparisons were computed using one-sided Wilcoxon signed-rank tests. All statistical analyses were performed using the SciPy (v1.5.2) library [
33], with Type-1
.
3. Results
The subject demographics of all labeled and unlabeled volumes/slices are shown in
Table 1.
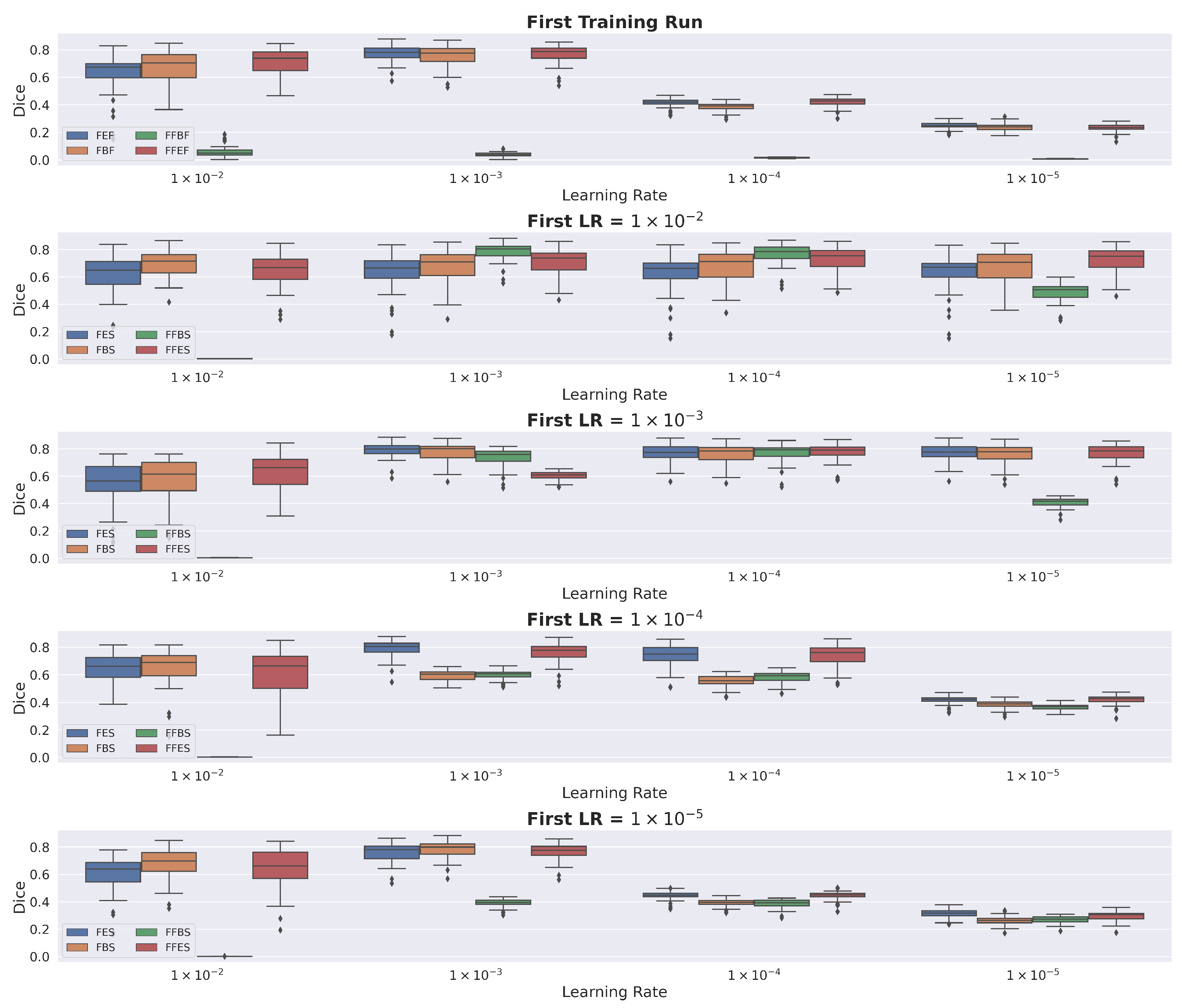
3.1. Design Choices for Transfer Learning
We observed that all pretrained model variants had high performance when first fine-tuned with an initial learning rate of 1 × 10
and then fine-tuned a second time with an initial learning rate of 1 × 10
. Transferring pretrained encoder weights only and fine-tuning once immediately with an initial learning rate of 1 × 10
achieved similar performance, with the added benefit of reduced training time. Consequently, we used these as the best combination of the three design choices for transfer learning. Additional details are in
Appendix B.2.
3.2. Design Choices for Pretraining
The L2 norm consistently decreased as a function of patch size for all combinations of pretext tasks (context prediction and context restoration) and sampling methods (random and Poisson-disc) (
Table 2). Furthermore, L2 norms for Poisson-disc sampling were significantly lower than those for random sampling (
p < 0.05).
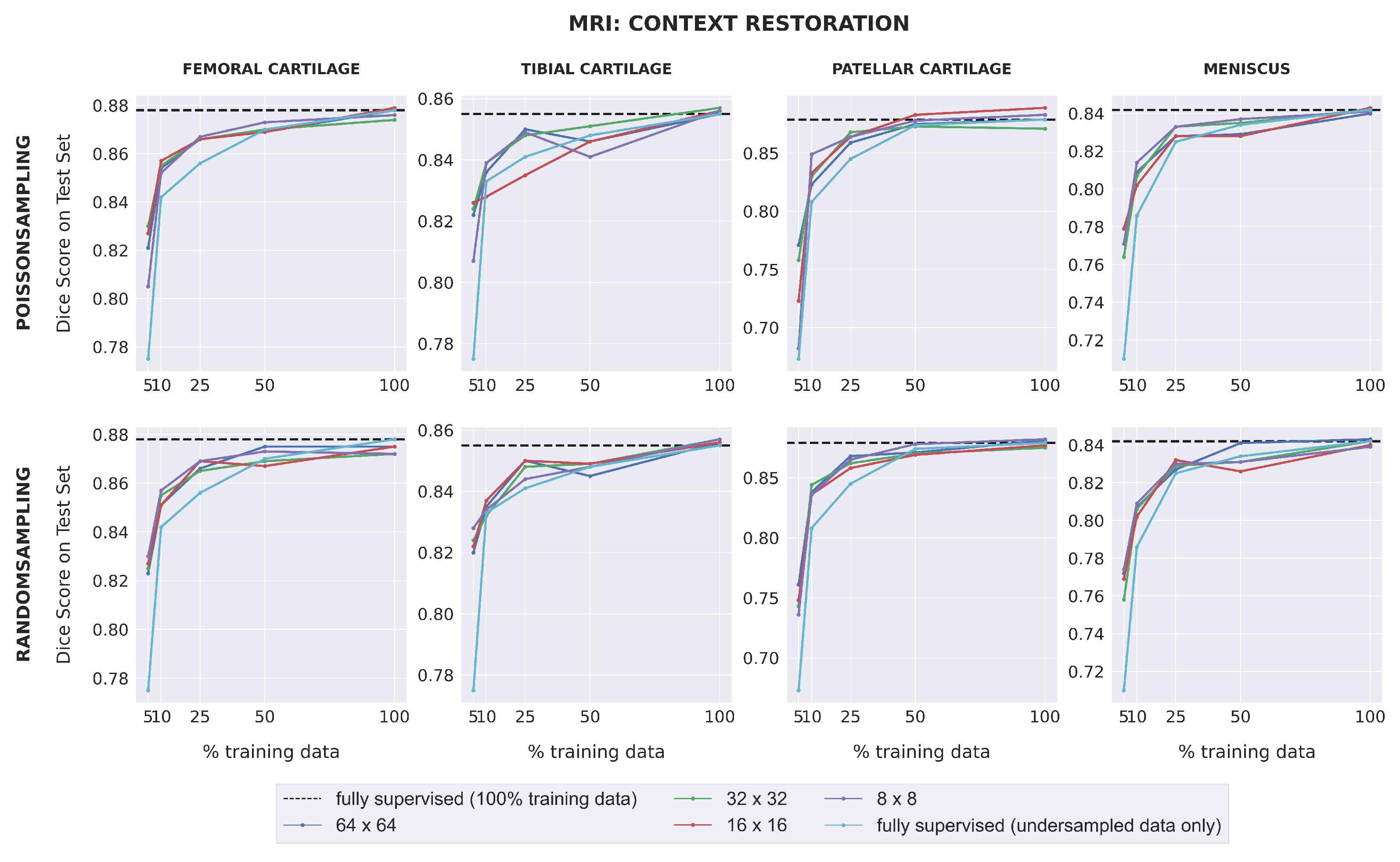
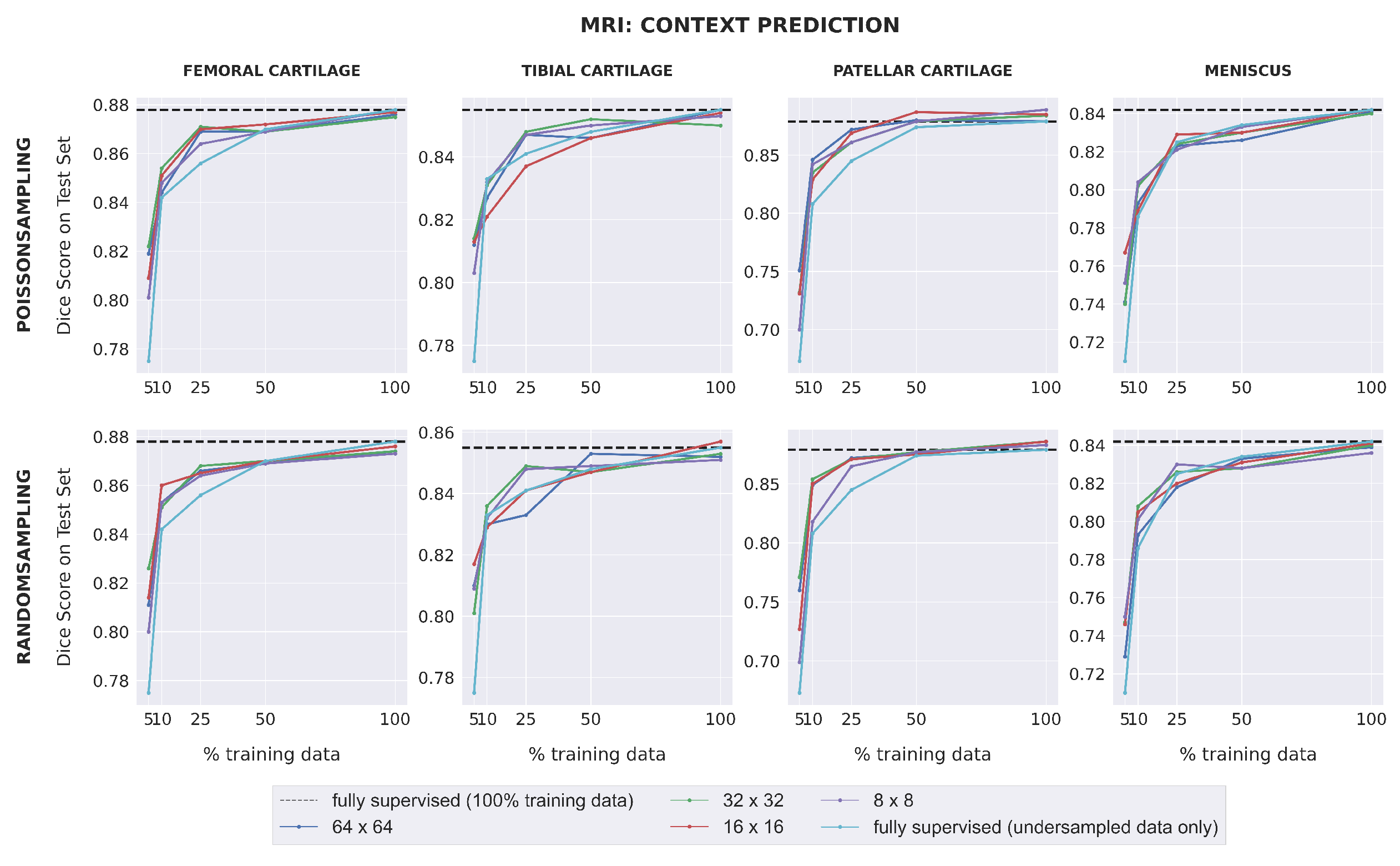
Dice scores for fully-supervised baselines ranged from 0.67–0.88 across subsets of training data for MR images. Downstream segmentation performance for the MRI dataset was similar for all combinations of pretext task, patch size, and sampling method (
Figure 3). All SSL models matched (within 0.01) or outperformed the fully-supervised model in low-label regimes with 25% training data or less for the femoral cartilage, patellar cartilage, and meniscus, and had comparable performance for higher data extents. For the tibial cartilage, all SSL models outperformed the fully-supervised model when trained on 5% training data and had comparable performance for higher data extents. The difference in Dice score between each self-supervised model and the fully-supervised model generally increased as the amount of labeled training data decreased. SSL pretraining also enabled some models to outperform the fully-supervised model trained with 100% training data in patellar cartilage segmentation.
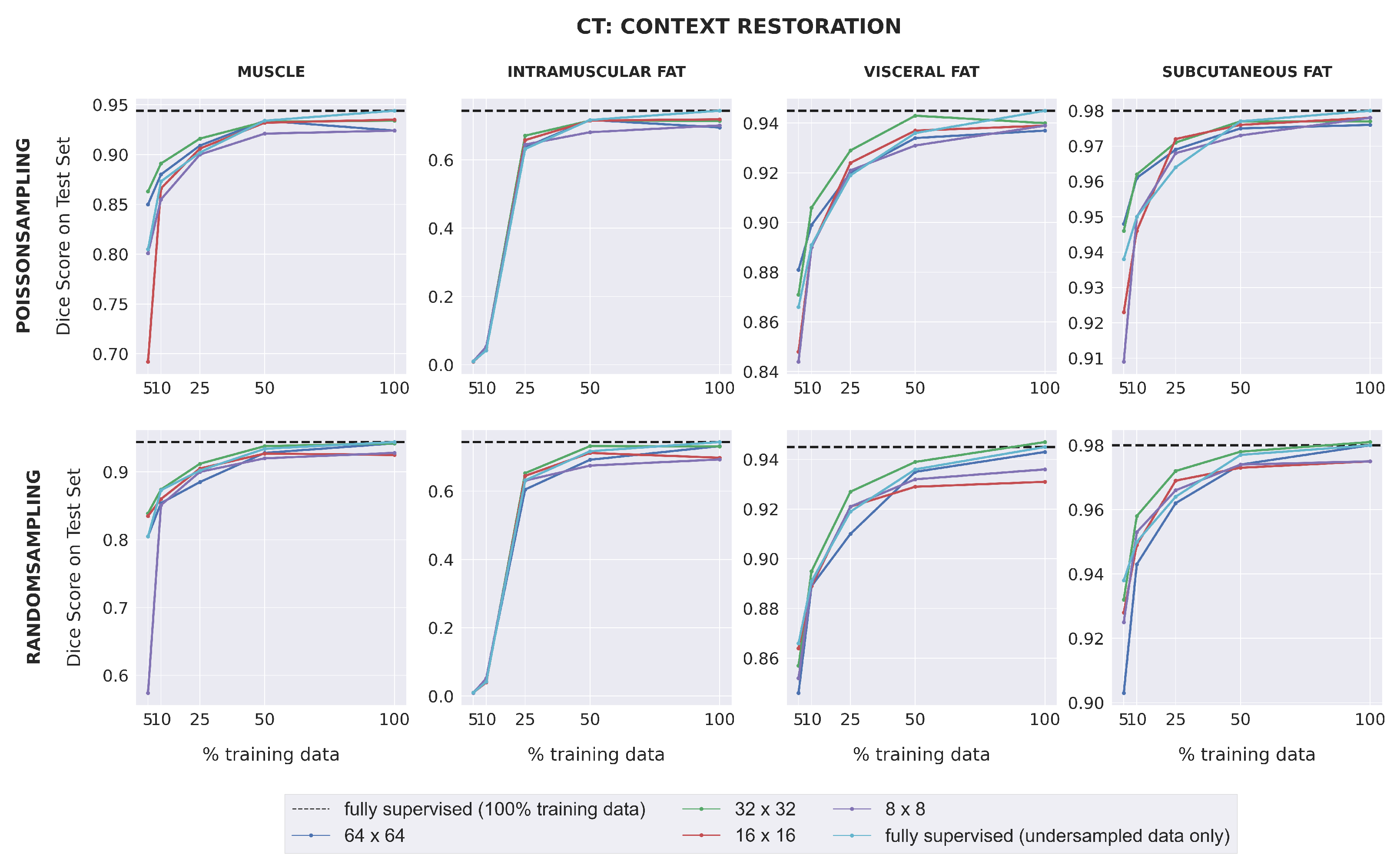
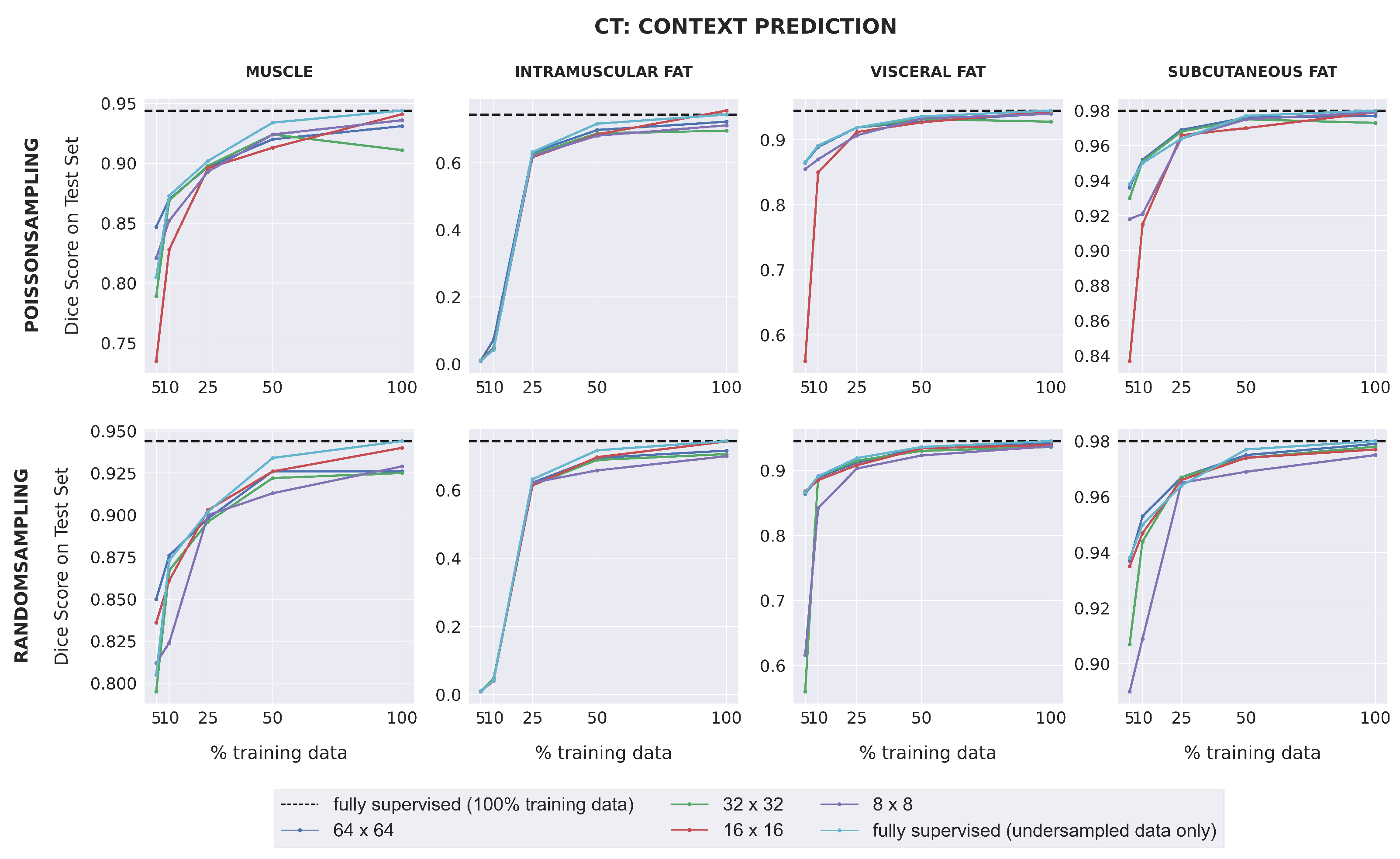
Dice scores for fully-supervised baselines were consistently higher for CT images than for MR images, with the exception of intramuscular adipose tissue. Unlike with the MRI dataset, downstream SSL segmentation for CT in low-label regimes depended on the pretext task and the patch size used during pretraining (
Figure 4). Models pretrained with larger patch sizes (64 × 64; 32 × 32) often outperformed those pretrained with smaller patch sizes (16 × 16; 8 × 8) for muscle, visceral fat, and subcutaneous fat segmentation, when trained with either 5% or 10% labeled data. Furthermore, when 25% training data or less was used, models pretrained with 32 × 32 patches using context restoration almost always outperformed fully-supervised models for muscle, visceral fat, and subcutaneous fat segmentation, but rarely did so when pretrained using context prediction. For intramuscular fat, all SSL models had comparable performance with fully-supervised models in low-label regimes. For high-label regimes (over 25% labeled data), all SSL models had comparable performance with fully-supervised models for all four segmentation classes.
3.3. Optimal Pretraining Evaluation
The top 5 pretraining strategies for the MRI dataset and the top 3 pretraining strategies for the CT dataset led to significantly better segmentation performance compared to fully-supervised learning (
p < 0.001) (
Table 3).
For MRI, the top 5 strategies all consisted of pretraining with context restoration, with minimal differences in p-value based on the patch size and sampling method used. For CT, the top 5 strategies used a patch size of at least 32 × 32 during pretraining. The strategy of pretraining with context restoration, 32 × 32 patches, and Poisson-disc sampling was in the top 3 for both datasets, and was therefore selected as the optimal pretraining strategy.
3.4. Impact of Extent of Unlabeled Data
For both datasets and for most subsets of labeled training data used during fine-tuning (except 25% and 10% labeled training data for MRI), the optimally trained model performed significantly better in downstream segmentation when pretrained on the maximum amount of data per dataset (200% pretraining data for MRI and 1200% pretraining data for CT) than when pretrained on only the training set (
p < 0.05) as seen in
Figure 5. When 25% or 10% labeled training data was used for MRI segmentation, the optimally trained model achieved a higher mean Dice score when pretrained on 200% pretraining data, but this was not statistically significant (
p = 0.3 for 25% labeled training data and
p = 0.02 for 10% labeled training data).
For MRI, Dice scores almost always improved as the amount of pretraining data increased. This improvement was greatest when only 5% of the labeled training data was used for training segmentation. Improvements in segmentation performance were slightly higher for CT. For all extents of labeled training data, segmentation performances improved when the amount of pretraining data increased from 100% to 650%. There was limited improvement when the amount of pretraining data increased from 650% to 1200%. For both datasets, when 25%, 10%, or 5% of the labeled training data was used, the change in dice score as a function of the amount of pretraining data followed a power-law relationship of the form (residual standard errors ≤ 0.005), where the value of k was less than 0.5.
Pretraining on the maximum amount of data enabled the optimally trained models to surpass the performance of fully-supervised models for all extents of labeled training data, in both MRI and CT. For the MRI dataset, the highest improvement over supervised learning was observed when 5% labeled training data was used. For CT, considerable improvements over supervised learning were observed when 5%, 10%, or 25% labeled training data was used.
For both the MRI and CT datasets, the best average Dice score over all extents of labeled training data occurred when the maximum possible amount of pretraining data was used (200% pretraining data for MRI and 1200% pretraining data for CT).
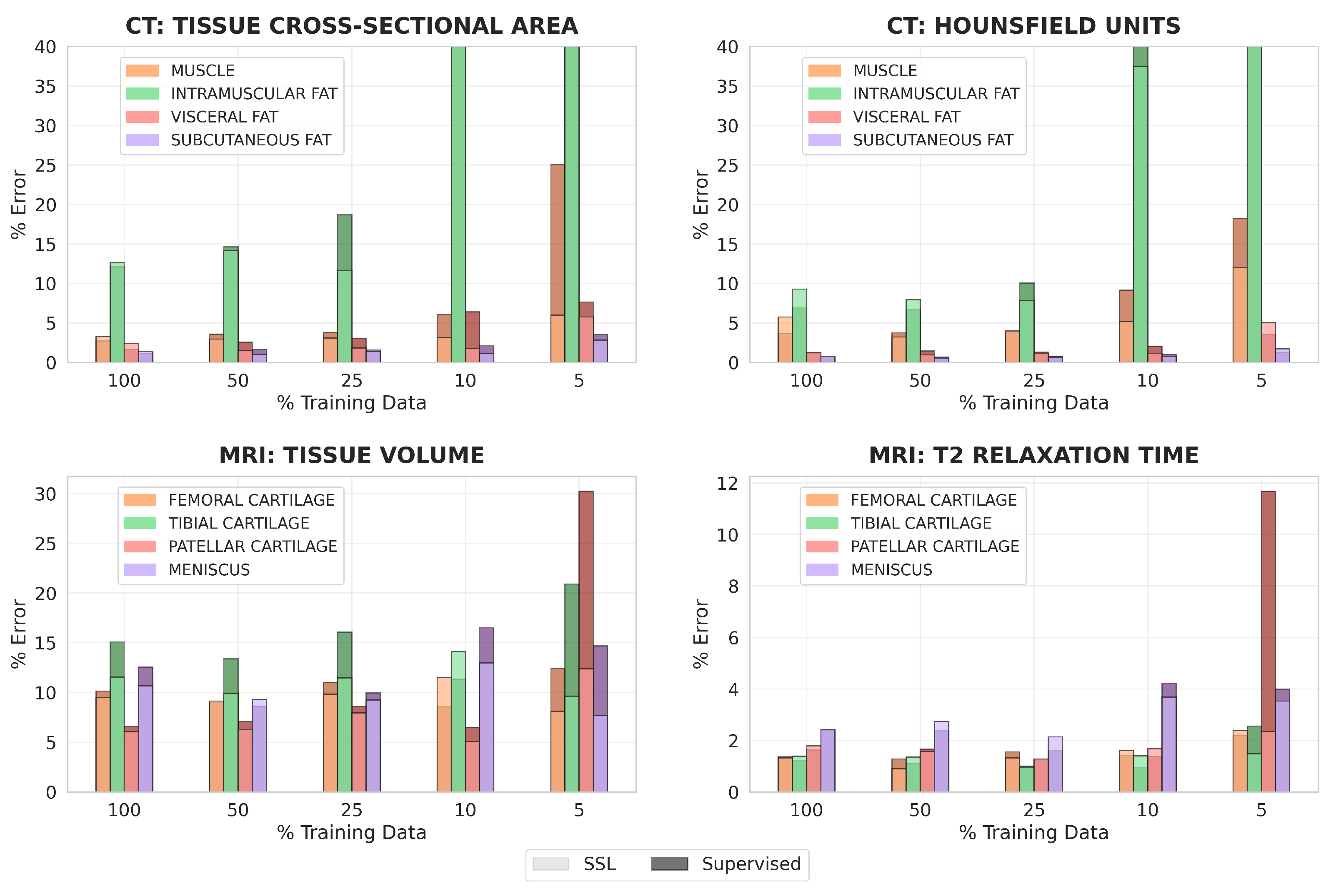
3.5. Comparing SSL and Fully-Supervised Learning
For each dataset, optimally trained models were pretrained with the maximum amount of pretraining data from
Section 3.4.
For all clinical metrics, using optimally trained models generally led to lower percent errors than using fully-supervised models in regimes of 10% and 5% labeled training data (
Figure 6). These differences were especially pronounced for CT tissue cross-sectional area, MRI tissue volume, and MRI mean T2 relaxation time. With 5% labeled training data for MRI, segmentations from optimally trained models more than halved the percent error for both tissue volume and mean T2 relaxation time of patellar cartilage, compared to segmentations from fully-supervised models.
With 100% or 50% labeled training data, percent errors for all clinical metrics had lower improvement when optimally trained models were used. This was observed for CT tissue cross-sectional area, CT mean HU value, and MRI T2 relaxation time, where optimally trained models had similar or slightly worse performance than fully-supervised models when 100% or 50% labeled data was available. However, for MRI tissue volume, optimally trained models almost always outperformed the fully-supervised models, even in scenarios with large amounts of labeled training data.
For both datasets, clinical metrics improved the most for the most challenging classes to segment. This included intramuscular adipose tissue for CT, where percent error decreased from around 3940% to 3600% for tissue cross-sectional area when 10% labeled training data was used, and patellar cartilage for MRI, where percent error decreased from around 30% to 12% for tissue volume when 5% labeled training data was used.
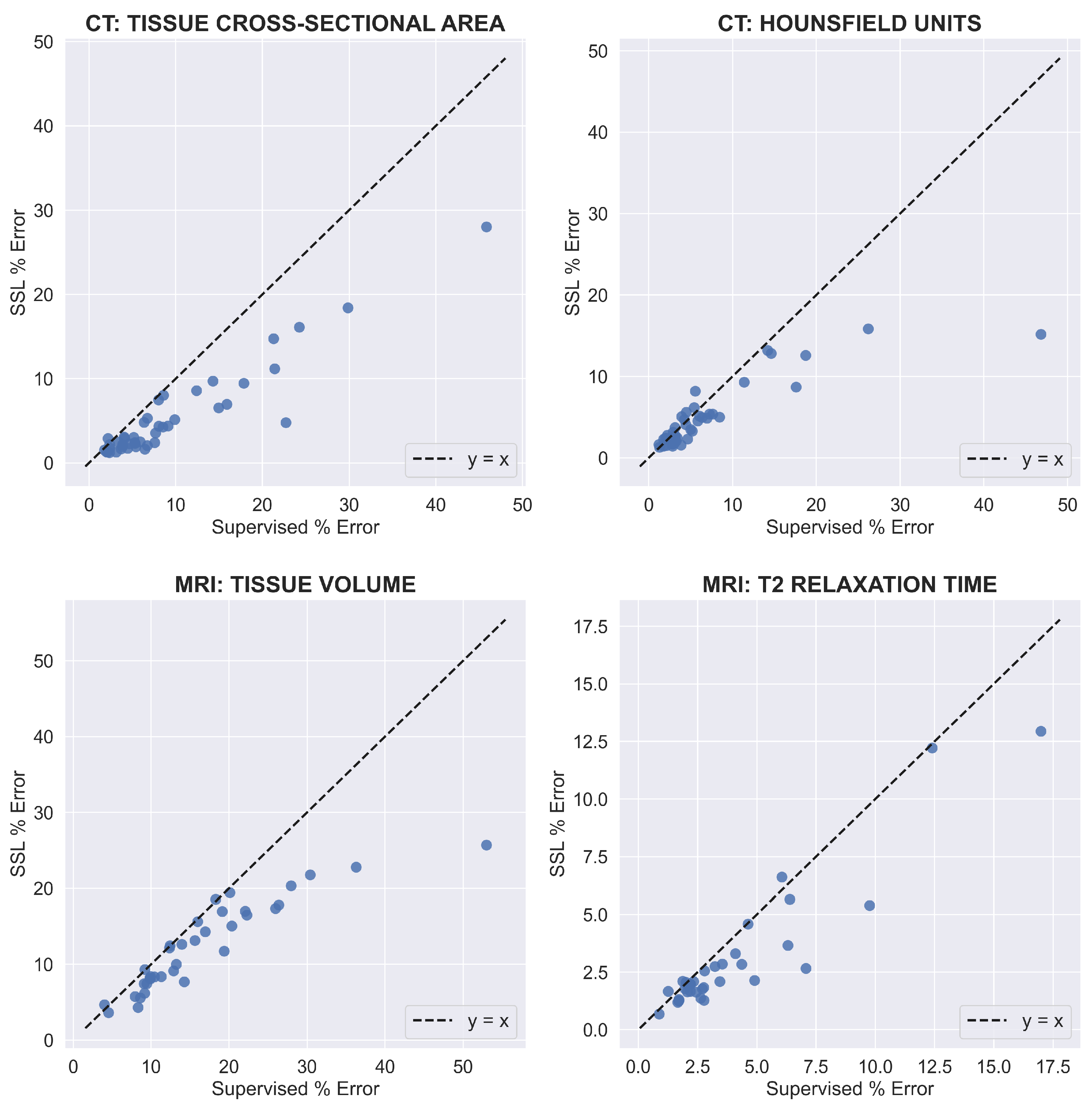
On a per-image basis, using SSL consistently matched or reduced the percent errors of supervised learning across both datasets and all clinical metrics (
Figure 7). Furthermore, when using SSL, the percent error for all clinical metrics improved more for test images with larger percent errors when using supervised learning. For tissue cross-sectional area and mean HU value for CT, the improvement in SSL percent error gradually increased as the supervised percent error increased beyond 10%. The same pattern existed for MRI tissue volume as the supervised percent error increased beyond 20%. For MRI mean T2 relaxation time, the improvement in percent error when using SSL increased for most test images as the supervised percent error increased beyond 5%, but this was not as consistent as for the other clinical metrics. On average, when excluding intramuscular fat for CT, SSL decreased per-image percent errors for CT tissue cross-sectional area, CT mean HU value, MRI tissue volume, and MRI mean T2 relaxation time by 4.1, 1.9, 4.1, and 2.2%, respectively.
4. Discussion
In this work, we investigated several key, yet under-explored design choices associated with pretraining and transfer learning in inpainting-based SSL for tissue segmentation. We examined the effect of inpainting-based SSL on the performance of tissue segmentation in various data and label regimes for MRI and CT scans, and compared it with fully-supervised learning. We quantified performance using standard Dice scores and four clinically-relevant metrics of imaging biomarkers.
We observed that the crosstalk between the initial and fine-tuning learning rate was a design choice that most affected model performance. All model variants achieved optimal performance with an initial learning rate of 1 × 10
and a fine-tuning learning rate of 1 × 10
(
Figure A1). This suggests the need for not perturbing the pretrained representations from the pretext task with a large learning rate. Moreover, although freezing and then fine-tuning the transferred weights provided an improvement over fine-tuning immediately for this learning rate combination (
Figure A1), the improvement was very small. This result matches the findings of Kumar et al. [
30], where the performance of linear probing (freezing) and then fine-tuning only slightly improved the performance of fine-tuning immediately after transferring. Additional details are provided in
Appendix B.3.
Here, we suggest some best practices for inpainting-based SSL for medical imaging segmentation tasks. We observed that downstream segmentation performance for MRI was similar for all combinations of pretext tasks, patch sizes, and sampling techniques. This observation remained consistent despite significant differences in the L2 norms of the inpainted images. While decreasing patch sizes and sampling patch locations via Poisson-disc sampling to ensure non-overlapping patches both resulted in significantly lower L2 norms, they did not improve downstream segmentation performance. These observations suggest a discordance between learning semantically meaningful representations and the accuracy of the pretext task metric. Thus, simply performing good enough pretraining may be more important than optimizing pretext task performance.
For both MRI and CT, segmentation performance usually increased in proportion to the amount of pretraining data. The highest improvements over supervised learning were observed in the context of very low labeled data regimes of 5–25% labeled data. These empirical observations across both MRI and CT demonstrate that pretraining with large enough datasets improves performance compared to only supervised training, especially when the amount of available training data is limited.
Similar to supervised learning, improvements in SSL Dice scores tended to follow a power-law relationship of the form
as the size of the unlabeled corpora increased [
5]. The observations that the value of
k was less than 0.5 when 25%, 10%, or 5% labeled data was used for either dataset and pretraining on 650% and 1200% CT pretraining data led to similar improvements over supervised learning suggest a limit exists where the learning capacity of a model saturates and additional unlabeled data may not improve downstream performance. A good practice for future segmentation studies may be to create
Figure 5 to evaluate the trade-off between the challenges of annotating more images and acquiring more unlabeled images.
Compared to fully-supervised models, optimally trained models generally led to more accurate values for all clinical metrics in label-limited scenarios. We also observed that clinical metrics improved the most with SSL for tissue classes that had the highest percent error with fully-supervised learning—intramuscular adipose tissue in CT and patellar cartilage in MRI. This observation, combined with the Dice score improvement in low labeled data regimes, suggests that SSL may be most efficacious when the performance of the baseline fully-supervised model is low.
A similar pattern was observed on a per test image basis. For all clinical metrics, the improvement in percent error when using optimally trained models was greater for test images that performed poorly when using fully-supervised models. This suggests that SSL pretraining can reduce worst-case errors that occur with traditional supervised learning. Moreover, our observation that SSL percent errors consistently either matched or were lower than supervised percent errors indicates SSL pretraining also increases the robustness of models in label-limited scenarios.
However, we also observed that optimally trained models sometimes had similar or even worse performance than fully-supervised models for CT tissue cross-sectional area, CT mean HU value, and MRI T2 relaxation time in scenarios with 100% or 50% labeled data. This observation suggests that SSL does not have much benefit when the labeled dataset is large. In such cases, it may be more efficient to simply train a fully-supervised model, rather than spend additional time pretraining with unlabeled data.
When training with 5% labeled data for all MRI classes and muscle on CT, our optimal pretraining strategy improved Dice scores by over 0.05, compared to fully-supervised learning. In such cases, the Dice score for fully-supervised learning was 0.8 or lower, which suggests a critical performance threshold where inpainting-based SSL can improve segmentation performance over supervised learning. SSL may be beneficial in these cases because the models still have the capacity to learn more meaningful representations, compared to models with Dice scores over 0.8 that may already be saturated in their capacity to represent the underlying image.
Importantly, it should be noted that the improvement in segmentation performance with SSL pretraining in label-limited scenarios is on the similar order as prior advances that used complex DL architectures and training strategies [
34,
35,
36]. Comparatively, our proposed SSL training paradigm offers an easy-to-use framework for improving model performance for both MRI and CT without requiring large and difficult to train DL models. Moreover, since we have already investigated different implementation design choices and experimentally determined the best ones, our proposed training paradigm will provide researchers with an implementation of inpainting-based SSL for their own work, without requiring them to spend resources/compute investigating these design choices again. This is especially important as we have shown that simply performing inpainting-based pretraining on the same data that is ordinarily only used for supervised learning improves segmentation accuracy compared to supervised learning only.
Study Limitations
There were a few limitations with this study. Although we investigated two different methods for selecting which pretrained weights to transfer, we did not conduct a systematic study across all possible choices due to computational constraints that made searching over the large search space too inefficient. We also leave other SSL strategies such as contrastive learning to future studies since it requires systematic evaluation of augmentations and sampling strategies. Furthermore, when we investigated the impact of unlabeled data extents on downstream segmentation performance, we did not pretrain our SSL models with equal extents of unlabeled MRI and CT data since we maximized the amount of available MRI data. In addition, our investigations in this work are limited to the U-Net architecture, though future work can explore other powerful segmentation architectures. Finally, we did not experiment with other optimizers potentially better than the ADAM optimizer. Recent studies [
37] have shown that there may be value in optimizers such as Stochastic Gradient Descent for better generalization in natural image classification and that there is potential trade off while choosing different optimizers. We leave the systematic investigation of this issue on medical imaging data for future follow up work.



 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}