


EnsemDeepCADx: Empowering Colorectal Cancer Diagnosis with Mixed-Dataset Features and Ensemble Fusion CNNs on Evidence-Based CKHK-22 Dataset


Abstract
:1. Introduction
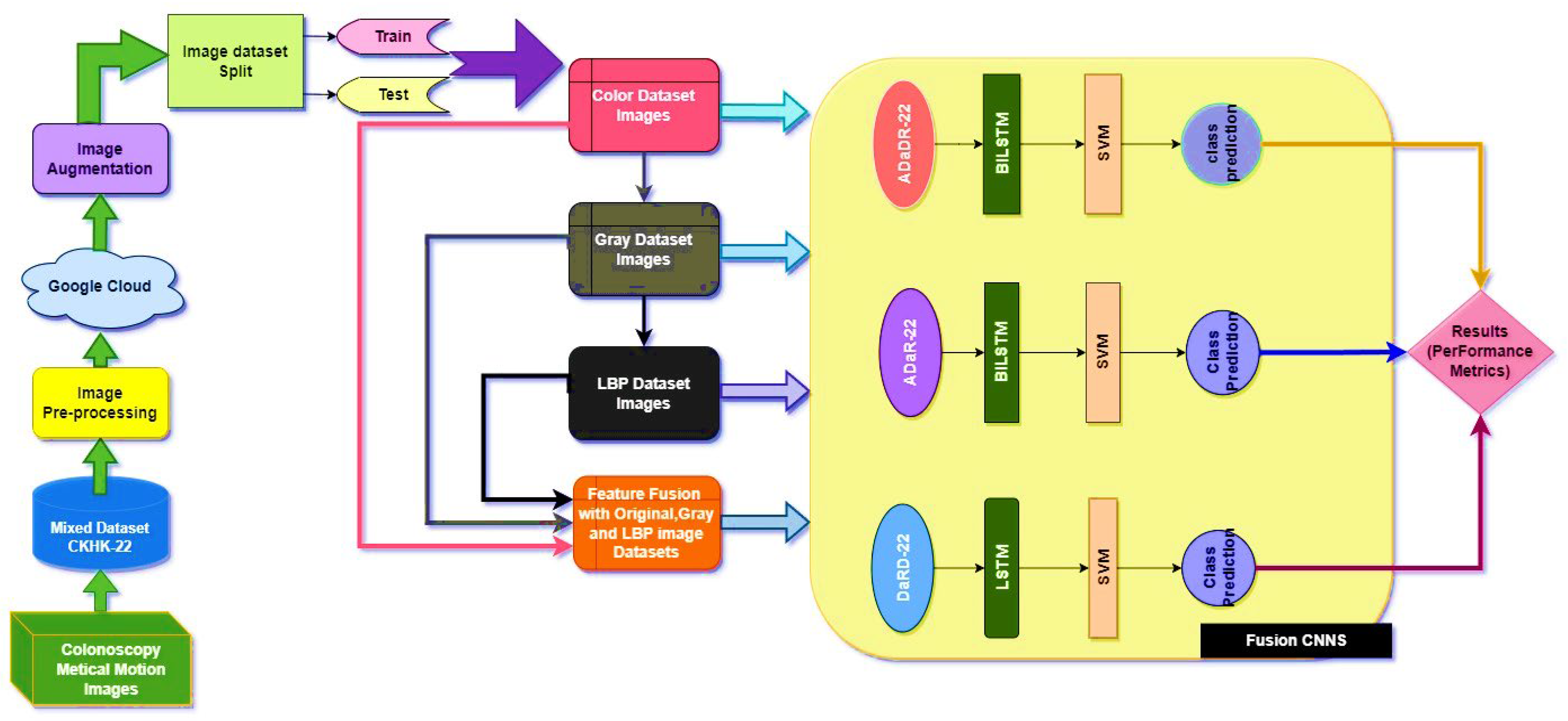
- The initial stage is to generate a dataset for feature fusion by combining the CKHK-22 mixed image datasets with others, such as the Grey and LBP datasets.
- Developing and training three ensemble fusion CNNs using the feature fusion CNN and the other featured datasets is the next step.
- In the subsequent stage, all CNNs are trained with SVM and transfer learning.
- In the final stage, temporal and spatial information is extracted using transfer learning ensemble fusion CNNs with BILSTM and SVM multi-class classification.
- At each stage, the EnsemDeepCADx model is inspected for inconsistencies and other performance metrics, and the resulting data is compared to determine the optimal approach.
1.1. Organisation of Study
1.2. Literature Survey
2. Materials and Methods
2.1. Colonoscopy Medical Motion Images
Datasets
2.2. Image Pre-Processing
2.2.1. Google Cloud
- Sign up for Google Cloud and create your first project to start;
- To begin storing the data, create a new container using the Cloud Storage interface;
- Using the Cloud Storage user interface or the command line utility, the CKHK-22 dataset may be added to the container;
- Ensure that the bucket is accessible to the public before uploading the data;
- Launch Google Authenticator and log in to your Co-lab account;
- Using gcsfuse, it can mount the container to Co-lab and access its contents as you would any other local disc;
- After mounting the container, the CKHK-22 dataset in Co-lab becomes as accessible as if it had been saved locally.
2.2.2. Image Augmentation
- Resize: creates images that are 224 by 224 pixels in dimension;
- Noise reduction enhances image clarity by removing distracting ambient noise;
- Image colour correction is the process of standardising the image’s colour distribution to reduce variations;
- Using the zoom function, it can double or halve the image size;
- Images can be rotated by a maximum of 15 degrees;
- The horizontal flip function mirrors the image by horizontally rotating it.
2.3. Train Test Split
2.3.1. Extracting Grey Scale Features from Original Image Dataset
- Use a library for processing images, such as OpenCV, to read the source colour images;
- Apply the following formula to transform every image from the RGB colour space into the greyscale colour space;
- Create a new folder to store the greyscale images in so they may be used in the image classification model’s testing and training stages.
2.3.2. Extracting Local Binary Pattern Features from Greyscale Dataset
- Create greyscale images that are typically 3 × 3 or 5 × 5 pixels in size;
- Determine the LBP of each pixel in the region by comparing its intensity to that of its neighbouring pixels;
- Replace the pixel’s original intensity value with a binary code representing the pattern of intensity differences between the central pixel and its companions;
- The LBP values of each pixel in the sub-region are added together to generate a singular LBP code;
- To generate a full set of LBP codes, the procedure must be repeated for each image’s subregion;
- To generate a feature vector that adequately characterises the image, the LBP codes are aggregated across the entire image using a histogram-based technique.
2.3.3. Feature Fusion as New Dataset
2.4. Image Classification Using Ensemble Fusion CNNs
2.4.1. Bidirectional LSTM
2.4.2. Support Vector Machines
2.5. The Classification Step
- The input CKHK-22 mixed dataset contains 10 classes and 14,287 images;
- Before extracting local binary pattern (LBP) features, images from the CKHK-22 mixed dataset are converted to greyscale as part of the pre-processing step. The feature fusion dataset is created by combining these features with the RGB features from the original dataset;
- The CADx system’s ensemble fusion CNNs consist of four pre-trained CNN models: AlexNet, DarkNet-19, DenseNet-201, and ResNet-50. aDaDR-22, aDaR-22, and DaRD-22 are combined in three ways to create a more robust and accurate CNN model. The original RGB images and LBP features extracted from greyscale images are used to train ensemble CNNs on the CKHK-22 mixed dataset;
- The BILSTM recurrent neural network is capable of processing data sequences in both forward and reverse directions. In the EnsemDeepCADx system, the BILSTM is used as a transfer learning technique to enhance the efficacy of the ensemble CNNs. The resultant sequence of image features is then processed by the BILSTM layer, which receives input from the CNN ensemble. This method may improve the accuracy of a classification model by capturing temporal dependencies and correlations between visual features;
- SVMs are a family of machine learning algorithms used for classification and regression testing. SVMs are utilised as a post-processing stage in the EnsemDeepCADx system following the acquisition of classification results from an ensemble of CNNs and a BILSTM. An SVM classifier receives the results from the BILSTM layer and transforms the features into a higher dimension using a kernel function. The SVM classifier searches for the hyperplane that divides the input features into distinct categories in order to classify them. This technique helps improve the classification model’s accuracy by reducing false positives and enhancing class separation. This discovers how to partition data into the ten classes provided as input;
- Before performing transfer learning using ensemble CNNs, the final fully connected layer and SoftMax activation layer were eliminated from each CNN model. The feature maps produced by the final convolutional layer of each CNN were then provided to the BiLSTM layer. A total of 64 hidden units within the BiLSTM layer employed the tanh activation function. The output of the BiLSTM layer was input into a fully connected layer consisting of 32 hidden units and the ReLU activation function after final classification using a multi-Class SVM;
- Training the models: in this EnsemDeepCADx system, it can train the models using the pre-processed datasets and the hyperparameters specified for each model. The EnsemDeepCADx system can use techniques such as early stopping and learning rate scheduling to optimise the training process;
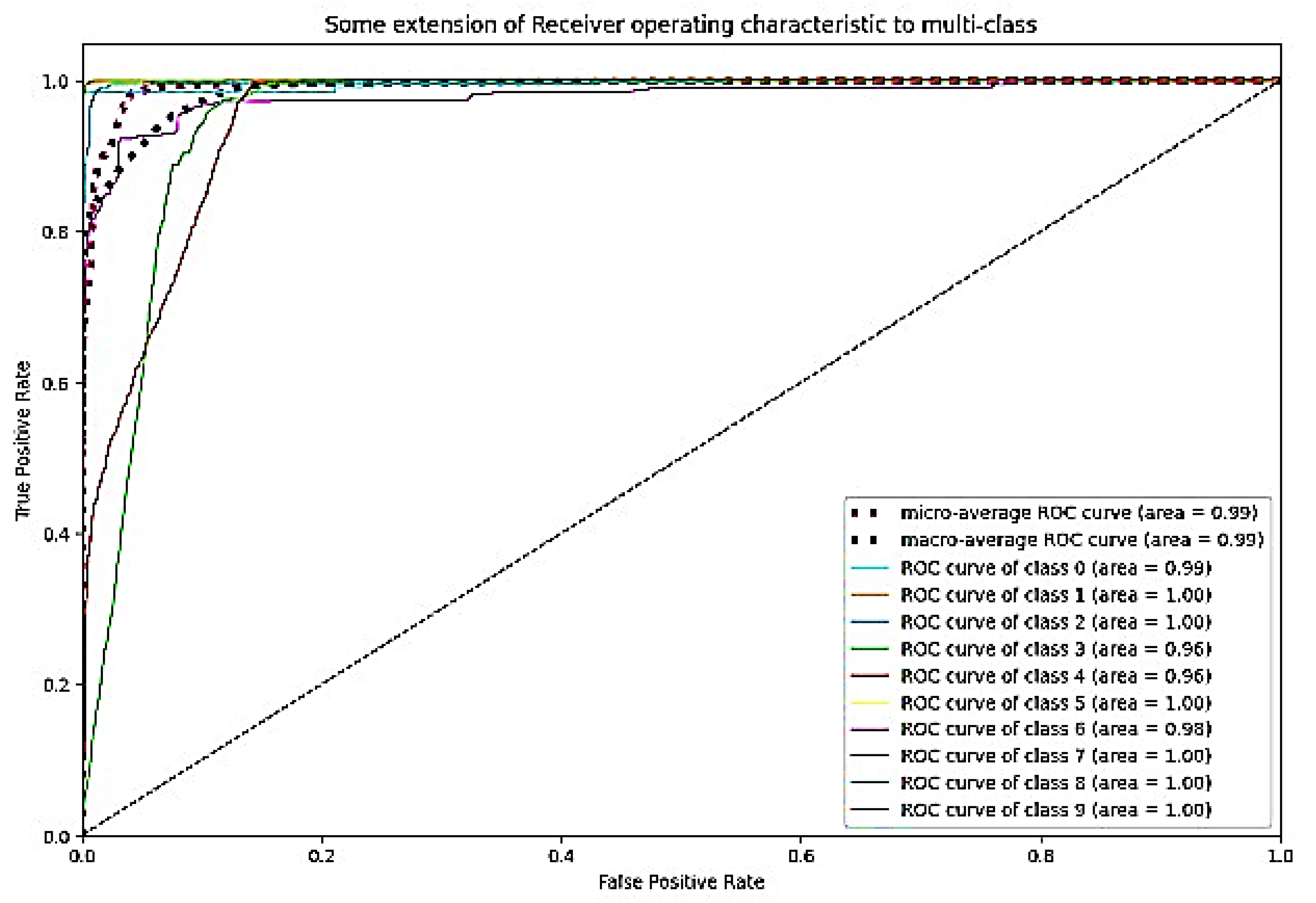
- Evaluating the models:Ie EnsemDeepCADx system can evaluate the models on the test set using metrics such as accuracy, precision, recall, and F1 score. In this system, the efficacy of a model is evaluated by producing ROC curves and calculating the area under the curve (AUC). To evaluate the efficacy of the trained models in real-world scenarios, an independent set of images from the CKHK-22 mixed dataset is used.
- Future images of colorectal cancer can be identified accurately using the completed EnsemDeepCADx system.
- Stage 1:
- The CKHK-22 mixed image dataset is pre-processed to extract features from the original RGB images, as well as grey and LBP images, resulting in the creation of three new feature datasets. These three datasets are then merged to form a new feature fusion dataset.
- Stage 2:
- Three ensemble fusion CNN models—ADaDR-22, ADaR-22, and DaRD-22—are trained and tested with each of the four feature datasets (original, grey, LBP, and feature fusion).
- Stage 3:
- The three trained ensemble fusion CNN models are combined with BiLSTM models through transfer learning. The resulting models are then trained and tested with each of the four feature datasets.
- Stage 4:
- The three trained ensemble fusion CNN models are combined with BiLSTM and multi-class SVM models through transfer learning. The resulting models are then trained and tested with each of the four feature datasets.
3. Experimental Setup
4. Results
4.1. Stage 1 Experimentation
4.2. Stage 2 Experimentation: Ensemble Fusion CNNs
4.3. Stage 3 Experimentation: Ensemble Fusion CNNs + Multi-Class SVM
4.4. Stage 4 Experimentation: Ensemble Fusion CNNs + BiLSTM + Multi-Class SVM
5. Discussion
- On the CVC Clinic DB dataset, Liew et al. (2021) [11] used an ensemble classifier approach with ResNet50 + Adaboost, AlexNet, GoogLeNet, and VGG-19 models to achieve an accuracy of 97.91%. Their method’s execution time was 2.5 h;
- Omneya Attallah et al. (2021) [17] obtained an accuracy of 97.3% and 99.7% on the Kvasir2 and Hyper Kvasir datasets, respectively, using the GastroCADx method with AlexNet, DarkNet19, ResNet50, DenseNet-201, DWT, DCT, and SVM. The duration of execution for both datasets was three hours;
- Maryem Souaidi et al. (2022) [21] applied the MP-FSSD technique with VGG16 and feature Fusion Module to the CVC Clinic DB and WCE datasets. They obtained an accuracy of 91.56 percent in 2.5 h of execution;
- Pallabi Sharma et al. (2022) [49] utilised an ensemble classifier technique with ResNet101, GoogleNet, and XceptionNet models on the CVC Clinic DB and Aichi Medical Dataset. They obtained a 98.3% accuracy rate in 2.45 h of execution;
- Nisha J.S. et al. (2022) [50] applied the DP-CNN technique with the Dual Path CNN model to the CVC Clinic DB and ETIS-Larib datasets, achieving a 99.6% accuracy. Their method’s execution time was two hours;
- ColoRectalCADx was developed by Akella S. Narasimha Raju et al. [51] using ResNet-50V2, DenseNet-201, VGG16, LSTM, and SVM models on Hyper Kvasir Balanced and Mixed Dataset Balanced. They attained 98.91% and 96.13% accuracy with execution times of 2.15 and 2.10 h, respectively;
- EnsemDeepCADx, the proposed model (2023), employed Ensemble CNN DaRD-22, BLSTM, and SVM with feature fusion on the CKHK-22 mixed dataset. The accuracy was 97.89% and the execution time was 2 h.
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Global Health. Available online: https://ourworldindata.org/health-meta (accessed on 25 April 2023).
- Available online: https://www.who.int/news-room/fact-sheets/detail/cancer (accessed on 15 April 2023).
- Available online: https://data.worldbank.org/indicator/SH.MED.PHYS.ZS (accessed on 23 April 2023).
- Xi, Y.; Xu, P. Global Colorectal Cancer Burden in 2020 and Projections to 2040. Transl. Oncol. 2020, 14, 101174. [Google Scholar] [CrossRef] [PubMed]
- Survival Rates for Colorectal Cancer. Available online: https://www.cancer.org/cancer/colon-rectal-cancer/detection-diagnosis-staging/survival-rates.html (accessed on 2 December 2022).
- Indian Council of Medical Research. Consensus Document for Management of Colorectal Cancer; Aravali Printers & Publishers (P) Ltd.: New Delhi, India, 2014. [Google Scholar]
- Wu, Z.; Li, Y.; Zhang, Y.; Hu, H.; Wu, T.; Liu, S.; Chen, W.; Xie, S.; Lu, Z. Colorectal Cancer Screening Methods and Molecular Markers for Early Detection. Technol. Cancer Res. Treat. 2020, 19, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Costas, L.; Frias-Gomez, J.; Guardiola, M.; Benavente, Y.; Pineda, M.; Pavón, M.Á.; Martínez, J.M.; Climent, M.; Barahona, M.; Canet, J.; et al. New Perspectives on Screening and Early Detection of Endometrial Cancer. Int. J. Cancer 2019, 145, 3194–3206. [Google Scholar] [CrossRef] [PubMed]
- Doubeni, C.; Corley, D.; Quinn, V.; Jensen, C.; Zauber, A.; Goodman, M.; Johnson, J.; Mehta, S.; Becerra, T.; Zhao, W. Effectiveness of Screening Colonoscopy in Reducing the Risk of Death from Right and Left Colon Cancer: A Large Community-based Study. Gut 2018, 67, 291–298. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Larsen, S.; Mori, Y. Artificial Intelligence in Colonoscopy: A Review on the Current Status. DEN Open 2022, 2, e109. [Google Scholar] [CrossRef] [PubMed]
- Liew, W.S.; Tang, T.B.; Lu, C. Computer-aided Diagnostic Tool for Classification of Colonic Polyp Assessment. In Proceedings of the International Conference on Artificial Intelligence for Smart Community, Perak, Malaysia, 17–18 December; Ibrahim, R., Porkumaran, K., Kannan, R., Mohd Nor, N., Prabakar, S., Eds.; Lecture Notes in Electrical Engineering; Springer: Singapore, 2022. [Google Scholar]
- Fonollà, R.; Vander Zander, Q.E.W.; Schreude, R.M.; Masclee, A.A.M.; Schoon, E.J.; van der Sommen, F.; de With, P.H.N. A CNN Cadx System for Multimodal Classification of Colorectal Polyps Combining WL, BLI, and LCI Modalities. Appl. Sci. 2020, 10, 5040. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J. Review of Deep Learning: Concepts, CNN Architectures, Challenges, Applications, Future Directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef]
- Ragab, M.; Mostafa Mahmoud4, M.; Asseri, A.H.; Choudhry, H.; Yacoub, H.A. Optimal Deep Transfer Learning Based Colorectal Cancer Detection and Classification Model. Comput. Mater. Contin. 2022, 74, 3279–3295. [Google Scholar] [CrossRef]
- Nogueira-Rodríguez, A.; Domínguez-Carbajales, R.; López-Fernández, H.; Iglesias, Á.; Cubiella, J.; Fdez-Riverola, F.; Reboiro-Jato, M.; Glez-Peña, D. Deep Neural Networks Approaches for Detecting and Classifying Colorectal Polyps. Neurocomputing 2021, 423, 721–734. [Google Scholar] [CrossRef]
- Hwang, Y.; Syu, H.; Chen, Y.; Chung, C.; Tseng, Y.; Ho, S.; Huang, C.; Wu, I.; Wang, H. Endoscopic Images by a Single-shot Multibox Detector for the Identification of Early Cancerous Lesions in the Esophagus: A Pilot Study. Cancers 2021, 13, 321. [Google Scholar] [CrossRef]
- Attallah, O.; Sharkas, M. Gastro-cadx: A Three Stages Framework for Diagnosing Gastrointestinal Diseases. PeerJ Comput. Sci. 2021, 7, e423. [Google Scholar] [CrossRef] [PubMed]
- Kavitha, M.S.; Gangadaran, P.; Jackson, A.; Venmathi Maran, B.A.; Kurita, T.; Ahn, B.-C. Deep Neural Network Models for Colon Cancer Screening. Cancers 2022, 14, 3707. [Google Scholar] [CrossRef] [PubMed]
- Cao, Z.; Pan, X.; Yu, H.; Hua, S.; Wang, D.; Chen, D.Z.; Zhou, M.; Wu, J. A Deep Learning Approach for Detecting Colorectal Cancer via Raman Spectra. BME Front. 2022, 2022, 9872028. [Google Scholar] [CrossRef]
- Ozturik, S.; Ozakaya, U. Residual LSTM Layered CNN for Classification of Gastrointestinal Tract Diseases. J. Biomed. Inform. 2021, 113, 103638. [Google Scholar] [CrossRef]
- Souaidi, M.; El Ansari, M. A New Automated Polyp Detection Network MP-FSSD in WCE and Colonoscopy Images Based Fusion Single Shot Multibox Detector and Transfer Learning. IEEE Access 2022, 10, 47124–47140. [Google Scholar] [CrossRef]
- Nguyen, T.D.; Nguyen, T.O.; Nguyen, T.T.; Tran, M.T.; Dinh, V.S. Colonformer: An Efficient Transformer Based Method for Colon Polyp Segmentation. IEEE Access 2022, 10, 80575–80586. [Google Scholar]
- Saito, H.; Tanimoto, T.; Ozawa, T.; Ishihara, S.; Fujishiro, M.; Shichijo, S.; Hirasawa, D.; Matsuda, T.; Endo, Y.; Tada, T. Automatic Anatomical Classification of Colonoscopic Images Using Deep Convolutional Neural Networks. Gastroenterol. Rep. 2021, 9, 226–233. [Google Scholar] [CrossRef]
- Guo, Z.; Xie, J.; Wan, Y.; Zhang, M.; Qiao, L.; Yu, J.; Chen, S.; Li, B.; Yao, Y. A Review of the Current State of the Computer-aided Diagnosis (CAD) Systems for Breast Cancer Diagnosis. Open Life Sci. 2022, 17, 1600–1611. [Google Scholar] [CrossRef]
- Available online: https://www.kaggle.com/balraj98/cvcclinicdb (accessed on 25 May 2023).
- Pogorelov, K.; Randel, K.R.; Griwodz, C.; Eskeland, S.L.; de Lange, T. KVASIR: A Multi-class Image Dataset for Computer Aided Gastrointestinal Disease Detection. In Proceedings of the 8th ACM on Multimedia Systems Conference, Taipei Taiwan, 20–23 June 2017. [Google Scholar]
- Available online: https://datasets.simula.no/kvasir/ (accessed on 3 May 2023).
- Available online: https://datasets.simula.no/hyper-kvasir/ (accessed on 3 May 2023).
- Borgli, H.; Thambawita, V.; Smedsrud, P.H.; Hicks, S.; Jha, D.; Eskeland, S.; Randel, K.; Pogorelov, K.; Lux, M.; Nguyen, D. Hyperkvasir, a Comprehensive Multi-class Image and Video Dataset for Gastrointestinal Endoscopy. Sci. Data 2020, 7, 283. [Google Scholar] [CrossRef]
- Masoudi, S.; Harmon, S.; Mehralivand, S.; Walker, S.; Raviprakash, H.; Bagci, U.; Choyke, P.; Turkbey, B. Quick Guide on Radiology Image Pre-processing for Deep Learning Applications in Prostate Cancer Research. J. Med. Imaging 2021, 8, 010901. [Google Scholar] [CrossRef]
- Carneiro, T.; Medeiros Da NóBrega, R.V.; Nepomuceno, T.; Bian, G.-B.; De Albuquerque, V.H.C.; Filho, P.P.R. Performance Analysis of Google Colaboratory as a Tool for Accelerating Deep Learning Applications. IEEE Access 2018, 6, 61677–61685. [Google Scholar] [CrossRef]
- Oza, P.; Sharma, P.; Patel, S.; Adedoyin, F.; Bruno, A. Image Augmentation Techniques for Mammogram Analysis. J. Imaging 2022, 8, 141. [Google Scholar] [CrossRef] [PubMed]
- Gholamy, A.; Kreinovich, V.; Kosheleva, O. Why 70/30 or 80/20 Relation Between Training and Testing Sets: A Pedagogical Explanation; Departmental Technical Reports: New York, NY, USA, 2018. [Google Scholar]
- Vrhel, M.J. Color Image Resolution Conversion. IEEE Trans. Image Process. 2005, 14, 328–333. [Google Scholar] [CrossRef]
- Porebski, A.; Truong Hoang, V.; Vandenbroucke, N.; Hamad, D. Combination of LBP Bin and Histogram Selections for Color Texture Classification. J. Imaging 2020, 6, 53. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.; Jiang, Y. Optimization of Face Recognition Algorithm Based on Deep Learning Multi Feature Fusion Driven by Big Data. Image Vis. Comput. 2020, 104, 104023. [Google Scholar] [CrossRef]
- Lu, X.; Duan, X.; Mao, X.; Li, Y.; Zhang, X. Feature Extraction and Fusion Using Deep Convolutional Neural Networks for Face Detection. Math. Probl. Eng. 2017, 2017, 9. [Google Scholar] [CrossRef] [Green Version]
- Zhen, L.; Sun, X. The Research of Convolutional Neural Network Based on Integrated Classification in Question Classification. Sci. Program. 2021, 2021, 4176059. [Google Scholar] [CrossRef]
- Wang, R.; Xu, J.; Han, T.X. Object Instance Detection with Pruned Alexnet and Extended Training Data. Signal Process. Image Commun. 2019, 70, 145–156. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L. Densely Connected Convolutional Networks. arXiv 2018, arXiv:160806993. [Google Scholar]
- Ghatwary, N.; Ye, X.; Zolgharni, M. Esophageal Abnormality Detection Using Densenet Based Faster R-CNN with Gabor Features. IEEE Access 2019, 7, 84374–84385. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-resnet and the Impact of Residual Connections on Learning. Proc. AAAI Conf. Artif. Intell. 2017, 31, 4278–4284. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Imrana, Y.; Xiang, Y.; Ali, L.; Abdul-Rauf, Z. A Bidirectional LSTM Deep Learning Approach for Intrusion Detection. Expert Syst. Appl. 2021, 135, 115524. [Google Scholar] [CrossRef]
- Öztürk, Ş.; Özkaya, U. Gastrointestinal Tract Classification Using Improved LSTM Based CNN. Multimed. Tools Appl. 2020, 79, 28825–28840. [Google Scholar] [CrossRef]
- Wu, H.; Huang, Q.; Wang, D.; Gao, L. A CNN-SVM Combined Model for Pattern Recognition of Knee Motion Using Mechanomyography Signals. J. Electromyogr. Kinesiol. 2018, 42, 136–142. [Google Scholar] [CrossRef] [PubMed]
- Don, D.R. Multiclass Classification Using Support Vector Machines. Master’s Thesis, Georgia Southern University, Statesboro, GA, USA, 2018. [Google Scholar]
- Sharma, P.; Balabantaray, B.K.; Bora, K.; Mallik, S.; Kasugai, K.; Zhao, Z. An Ensemble-based Deep Convolutional Neural Network for Computer-aided Polyps Identification from Colonoscopy. Front. Genet. 2022, 13, 844391. [Google Scholar] [CrossRef]
- Nisha, J.S.; Gopi, V.P.; Palanisamy, P. Automated Colorectal Polyp Detection Based on Image Enhancement and Dual-path CNN Architecture. Biomed. Signal Process. Control. 2022, 73, 103465. [Google Scholar] [CrossRef]
- Raju, A.S.N.; Jayavel, K.; Rajalakshmi, T. ColoRectalCADx: Expeditious Recognition of Colorectal Cancer with Integrated Convolutional Neural Networks and Visual Explanations Using Mixed Dataset Evidence. Comput. Math. Methods Med. 2022, 2022, 8723957. [Google Scholar] [CrossRef]





























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classes | CKHK-22 Mixed Dataset | Images |
|---|---|---|
| 0 | bbps-0-1 | 653 |
| 1 | bbps-2-3 | 1148 |
| 2 | cecum | 2009 |
| 3 | dyed-lifted-polyps | 2003 |
| 4 | dyed-resection-margins | 1990 |
| 5 | non-polyps | 818 |
| 6 | polyps | 818 |
| 7 | pylorus | 2150 |
| 8 | retroflex-stomach | 765 |
| 9 | z-line | 1933 |
| Total images in dataset | 14,287 |
| CNN Architecture Models | Introduced Year | Total Params | Trainable Params | Non-Trainable Params | Layers |
|---|---|---|---|---|---|
| ADaDR-22 | 2022 | 89,491,098 | 47,570,314 | 41,920,784 | 293 |
| ADaR-22 | 2022 | 70,062,380 | 46,463,580 | 23,598,800 | 92 |
| DaRD-22 | 2022 | 61,401,236 | 19,501,588 | 41,899,648 | 270 |
| Datasets | Ensemble Fusion CNNs | Precision (%) | Recall (%) | F1 Score (%) | Training Accuracy (%) | Testing Accuracy (%) |
|---|---|---|---|---|---|---|
| Original CKHK-22 | ADaDR-22 | 90.35 | 88.11 | 87.72 | 95.72 | 88.11 |
| Datasets | ADaR-22 | 89.34 | 86.33 | 85.66 | 94.22 | 86.33 |
| DaRD-22 | 90.78 | 89 | 88.52 | 96.2 | 89 | |
| Datasets | Ensemble Fusion CNNs | Precision (%) | Recall (%) | F1 Score (%) | Training Accuracy (%) | Testing Accuracy (%) |
| Greyscale | ADaDR-22 | 85.33 | 82.97 | 82.22 | 92.82 | 82.97 |
| CKHK-22 Datasets | ADaR-22 | 85.47 | 81.31 | 82.07 | 91.33 | 81.31 |
| DaRD-22 | 81.95 | 80.66 | 79.57 | 89.66 | 81.66 | |
| Datasets | Ensemble Fusion CNNs | Precision (%) | Recall (%) | F1 Score (%) | Training Accuracy (%) | Testing Accuracy (%) |
| LBP CKHK-22 | ADaDR-22 | 68.74 | 66.03 | 64.4 | 69.5 | 66.03 |
| Datasets | ADaR-22 | 67.82 | 65.31 | 64.98 | 67.8 | 65.31 |
| DaRD-22 | 69.92 | 68.96 | 67.56 | 71.83 | 68.96 | |
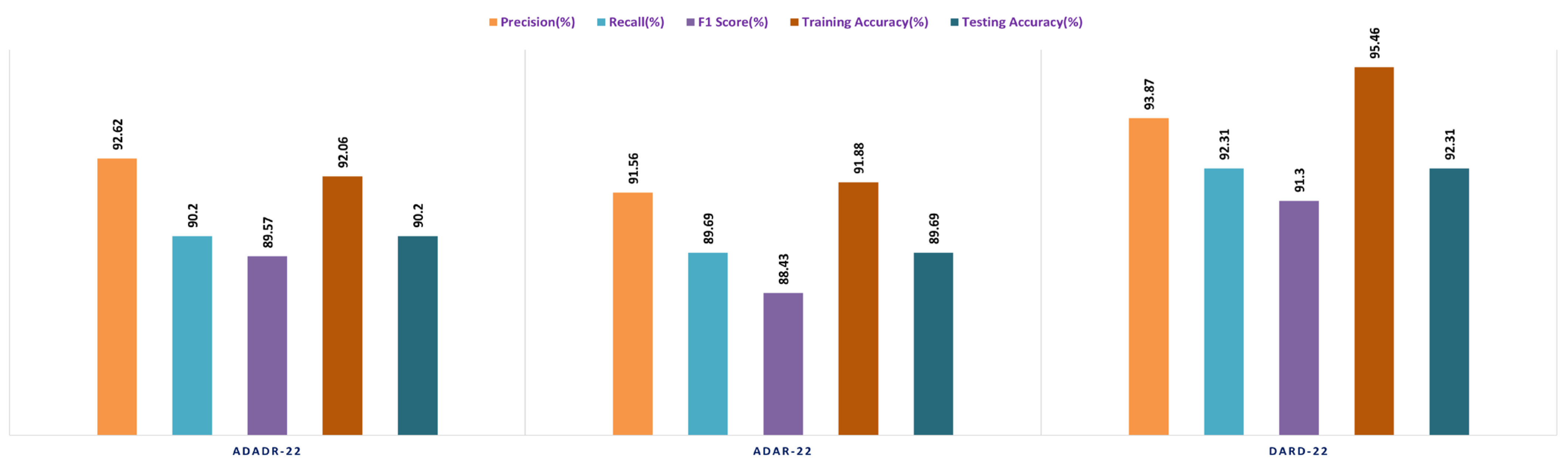
| Datasets | Ensemble Fusion CNNs | Precision (%) | Recall (%) | F1 Score (%) | Training Accuracy (%) | Testing Accuracy (%) |
| Feature Fusion | ADaDR-22 | 92.62 | 90.2 | 89.57 | 92.06 | 90.2 |
| CKHK-22 Datasets | ADaR-22 | 91.56 | 89.69 | 88.43 | 91.88 | 89.69 |
| DaRD-22 | 93.87 | 92.31 | 91.3 | 95.46 | 92.31 |
| Datasets | Ensemble Fusion CNNs | Precision (%) | Recall (%) | F1 Score (%) | Training Accuracy (%) | Testing Accuracy (%) |
|---|---|---|---|---|---|---|
| Original CKHK-22 Datasets | ADaDR-22 | 85.56 | 86.44 | 82.61 | 87.72 | 86.44 |
| ADaR-22 | 86.62 | 83.04 | 82.91 | 84.91 | 84.04 | |
| DaRD-22 | 86.79 | 85.55 | 84.53 | 88.67 | 85.55 | |
| Datasets | Ensemble Fusion CNNs | Precision (%) | Recall (%) | F1 Score (%) | Training Accuracy (%) | Testing Accuracy (%) |
| Greyscale CKHK-22 Datasets | ADaDR-22 | 81.32 | 79.91 | 78.83 | 87.84 | 79.91 |
| ADaR-22 | 80.29 | 77.79 | 76.1 | 82.32 | 77.19 | |
| DaRD-22 | 82.32 | 80.62 | 79.57 | 89.69 | 80.62 | |
| Datasets | Ensemble Fusion CNNs | Precision (%) | Recall (%) | F1 Score (%) | Training Accuracy (%) | Testing Accuracy (%) |
| LBP CKHK-22 Datasets | ADaDR-22 | 65.94 | 64.81 | 63.32 | 68.31 | 64.82 |
| ADaR-22 | 66.14 | 64.53 | 62.21 | 67.57 | 65.53 | |
| DaRD-22 | 69.46 | 68.1 | 67.51 | 70.11 | 68.1 | |
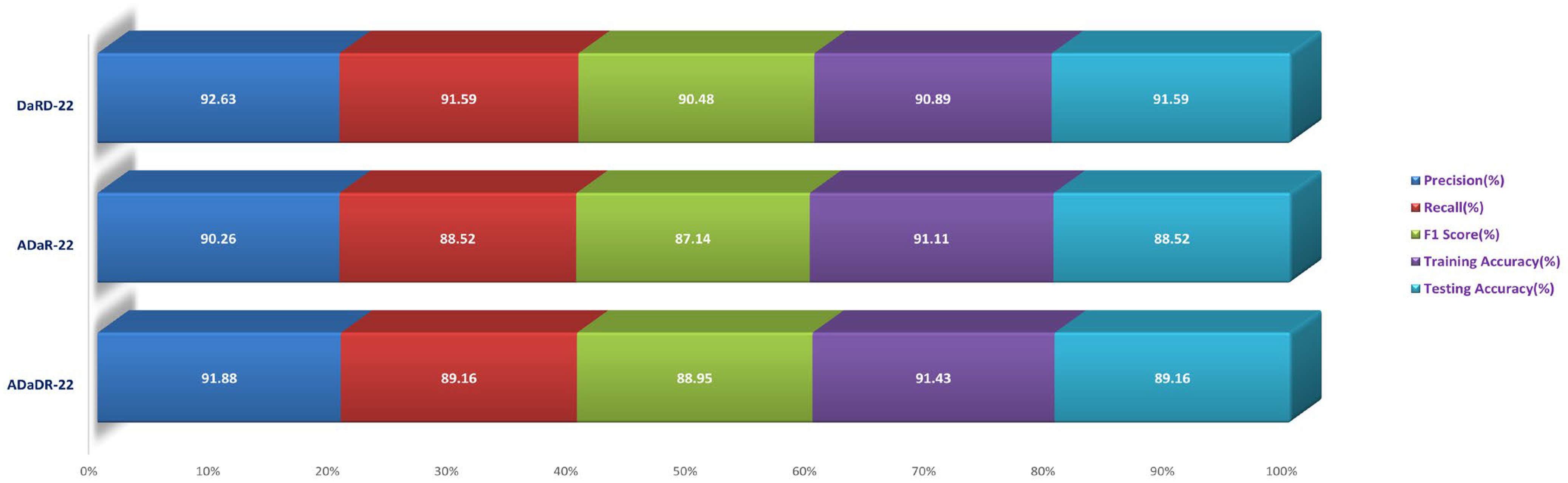
| Datasets | Ensemble Fusion CNNs | Precision (%) | Recall (%) | F1 Score (%) | Training Accuracy (%) | Testing Accuracy (%) |
| Feature Fusion CKHK-22 Datasets | ADaDR-22 | 91.88 | 89.16 | 88.95 | 91.43 | 89.16 |
| ADaR-22 | 90.26 | 88.52 | 87.14 | 91.11 | 88.52 | |
| DaRD-22 | 92.63 | 91.59 | 90.48 | 90.89 | 91.59 |
| Datasets | Ensemble Fusion CNNs | Precision (%) | Recall (%) | F1 Score (%) | Training Accuracy (%) | Testing Accuracy (%) |
|---|---|---|---|---|---|---|
| Original CKHK-22 Datasets | ADaDR-22 | 89.92 | 93.47 | 86.76 | 97.74 | 93.47 |
| ADaR-22 | 92.12 | 91.58 | 85.61 | 96.95 | 91.58 | |
| DaRD-22 | 95.31 | 94.96 | 93.47 | 98.64 | 95.96 | |
| Datasets | Ensemble Fusion CNNs | Precision (%) | Recall (%) | F1 Score (%) | Training Accuracy (%) | Testing Accuracy (%) |
| Greyscale CKHK-22 Datasets | ADaDR-22 | 89.23 | 87.89 | 86.42 | 92.11 | 87.89 |
| ADaR-22 | 84.92 | 83.09 | 82.57 | 85.54 | 83.09 | |
| DaRD-22 | 90.46 | 88.79 | 87.62 | 95.56 | 88.79 | |
| Datasets | Ensemble Fusion CNNs | Precision (%) | Recall (%) | F1 Score (%) | Training Accuracy (%) | Testing Accuracy (%) |
| LBP CKHK-22 Datasets | ADaDR-22 | 70.67 | 69.92 | 67.41 | 72.56 | 69.92 |
| ADaR-22 | 71.11 | 68.85 | 67.96 | 71.87 | 68.85 | |
| DaRD-22 | 75.11 | 73.54 | 72.67 | 75.89 | 73.54 | |
| Datasets | Ensemble Fusion CNNs | Precision (%) | Recall (%) | F1 Score (%) | Training Accuracy (%) | Testing Accuracy (%) |
| Feature Fusion CKHK-22 Datasets | ADaDR-22 | 95.69 | 94.96 | 93.37 | 95.67 | 94.96 |
| ADaR-22 | 94.98 | 93.77 | 92.59 | 95.08 | 93.77 | |
| DaRD-22 | 96.98 | 97.12 | 95.98 | 98.72 | 97.89 |
| Classes | Precision | Recall | F1 Score | Support |
|---|---|---|---|---|
| bbps-0-1 | 0.99 | 0.98 | 0.99 | 594 |
| bbps-2-3 | 0.99 | 0.99 | 0.99 | 1035 |
| cecum | 0.88 | 0.99 | 0.93 | 1809 |
| dyed-lifted-polyps | 0.58 | 0.92 | 0.71 | 1803 |
| dyed-resection-margins | 0.86 | 0.43 | 0.57 | 1791 |
| Non-Polyps | 0.98 | 0.96 | 0.97 | 771 |
| polyps | 0.96 | 0.82 | 0.88 | 2604 |
| pylorus | 0.97 | 1 | 0.98 | 1800 |
| retroflex-stomach | 0.99 | 0.99 | 0.99 | 690 |
| z-line | 1 | 0.99 | 0.99 | 1740 |
| Author | Method | Model Approach | Dataset | Time Elapsed | Accuracy (%) |
|---|---|---|---|---|---|
| Omneya Attallah et al. (2021) [17] | GastroCADx | AlexNet, DarkNet19, ResNet50 and DenseNet-201, DWT and DCT functions, SVM | Kvasir2, | 3 h | 97.3 |
| Hyper Kvasir | 3 h | 99.7 | |||
| Liew et al. (2021) [11] | Ensemble classifier | ResNet50 + Adaboost, AlexNet, GoogLeNet, and VGG-19 | CVC Clinic DB | 2.5 h | 97.91 |
| Pallabi Sharma et al. (2022) [49] | Ensemble classifier | ResNet101, GoogleNet and XceptionNet | CVC Clinic DB, Aichi Medical Dataset | 2.45 h | 98.3 |
| Kvasir2, | 2.25 h | 97 | |||
| Nisha J.S et al. (2022) [50] | DP-CNN | Dual Path CNN | CVC Clinic DB, ETIS-Larib | 2 h | 99.6 |
| Maryem Souaidi et al. (2022) [21] | MP-FSSD | VGG16 with feature Fusion Module | CVC Clinic DB, WCE dataset | 2.5 h | 91.56 |
| Akella S Narasimha Raju et al. (2022) [51] | ColoRectalCADx | ResNet-50V2, DenseNet-201, VGG16, LSTM and SVM | Hyper Kvasir Balanced | 2.15 h | 98.91 |
| Mixed Dataset Balanced | 2.10 h | 96.13 | |||
| Proposed Model (2023) | EnsemDeepCADx | Ensemble CNN DaRD-22, BLSTM, SVM with feature fusion | CKHK-22 Mixed Dataset | 2 h | 97.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Raju, A.S.N.; Venkatesh, K. EnsemDeepCADx: Empowering Colorectal Cancer Diagnosis with Mixed-Dataset Features and Ensemble Fusion CNNs on Evidence-Based CKHK-22 Dataset. Bioengineering 2023, 10, 738. https://doi.org/10.3390/bioengineering10060738
Raju ASN, Venkatesh K. EnsemDeepCADx: Empowering Colorectal Cancer Diagnosis with Mixed-Dataset Features and Ensemble Fusion CNNs on Evidence-Based CKHK-22 Dataset. Bioengineering. 2023; 10(6):738. https://doi.org/10.3390/bioengineering10060738
Chicago/Turabian StyleRaju, Akella Subrahmanya Narasimha, and Kaliyamurthy Venkatesh. 2023. "EnsemDeepCADx: Empowering Colorectal Cancer Diagnosis with Mixed-Dataset Features and Ensemble Fusion CNNs on Evidence-Based CKHK-22 Dataset" Bioengineering 10, no. 6: 738. https://doi.org/10.3390/bioengineering10060738
APA StyleRaju, A. S. N., & Venkatesh, K. (2023). EnsemDeepCADx: Empowering Colorectal Cancer Diagnosis with Mixed-Dataset Features and Ensemble Fusion CNNs on Evidence-Based CKHK-22 Dataset. Bioengineering, 10(6), 738. https://doi.org/10.3390/bioengineering10060738