
Enhancing Error Detection on Medical Knowledge Graphs via Intrinsic Label


Abstract
:1. Introduction
- Noting the abundance of entities’ labels in medical KGs, we propose a novel method that extracts the intrinsic label information of entities via a hyper-view KG. Further, we establish the hyper-view KG ourselves due to its absence;
- Aiming to integrate the topological information and intrinsic label information, we propose a hyper-view GAT consisting of a bi-LSTM layer for capturing local structural messages and a modified graph attention mechanism for modeling neighborhood information with potential labels’ messages;
- Ranking the triplet by confidence score, we conduct comprehensive experiments on three medical KGs and a general KG and outperform other methods.
2. Related Work
2.1. Knowledge Graph Representation Learning
2.2. Error-Aware Knowledge Graph Embedding
2.3. Knowledge Graph Error Detection
3. Problem Statement
4. Methodology
4.1. Hyper-View GAT for Representation Learning

4.1.1. Local Structural Information Modeling
4.1.2. Intrinsic Label Information in Hyper-View KG
4.1.3. Neighborhood Information Modeling
4.2. Joint Training Strategy
4.3. Confidence Score
| Algorithm 1 Error detection on medical knowledge graphs via intrinsic label information |
| Input: Knowledge graph with noise Output: KG embeddings and confidence score
|
5. Experiments and Discussion
5.1. Experimental Settings
5.1.1. Benchmark Datasets
5.1.2. Baseline Methods
5.1.3. Evaluation Metrics
5.1.4. Implementation Details
5.2. Results and Analysis
5.2.1. Main Results
5.2.2. Ablation Study
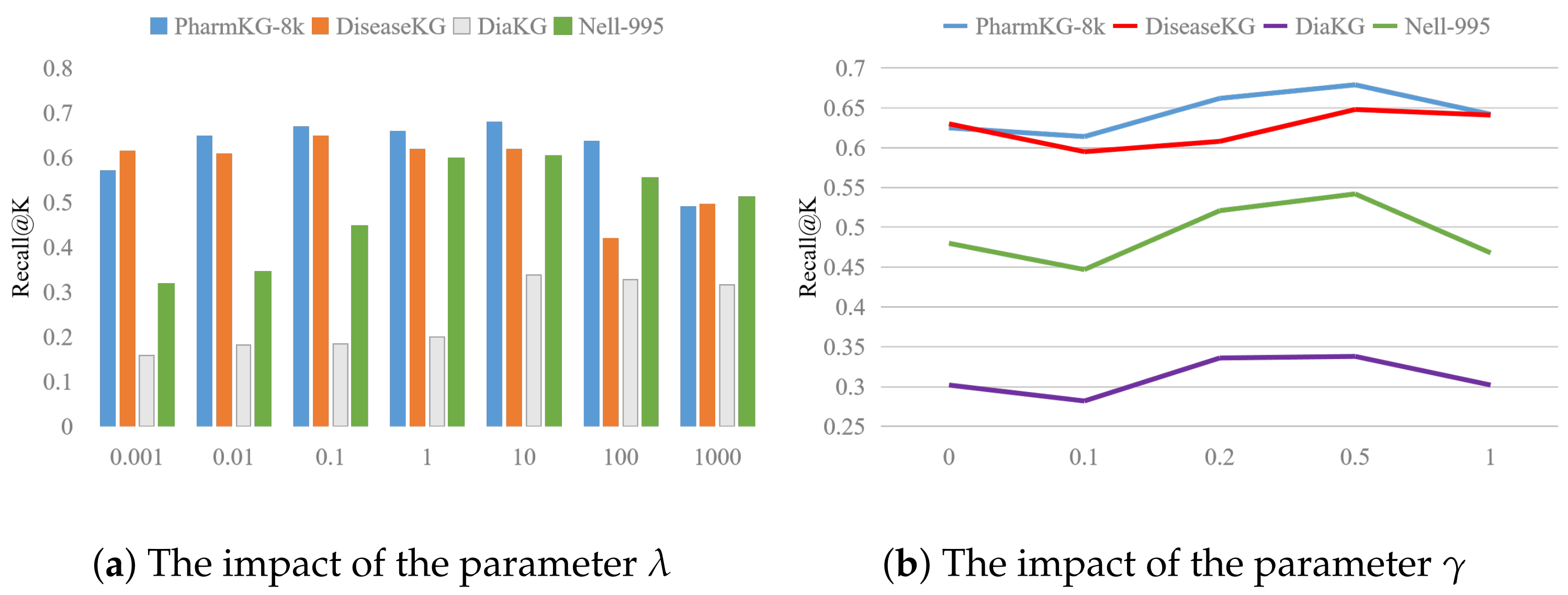
5.2.3. Parameter Analysis
5.3. Case Study
6. Conclusions
- Existing error detection methods [19,21,22,23] only take into account the entities and relations already present in the knowledge graph, while error triplets could originate from outside the dataset [43]. To address the limitation, combining textual information from large language models with graph structure information is a promising direction [44,45].
- The currently used max dataset size is approximately 500,000, and in the future, we will consider conducting more experiments on large-scale graphs while maintaining the effectiveness and reducing the training time.
- We will explore more meaningful downstream tasks, such as knowledge-based question answering in the medical field.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Suchanek, F.M.; Kasneci, G.; Weikum, G. Yago: A core of semantic knowledge. In Proceedings of the 16th International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 697–706. [Google Scholar]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; Van Kleef, P.; Auer, S.; et al. Dbpedia—A large-scale, multilingual knowledge base extracted from wikipedia. Semant. Web 2015, 6, 167–195. [Google Scholar] [CrossRef]
- Yuan, J.; Jin, Z.; Guo, H.; Jin, H.; Zhang, X.; Smith, T.; Luo, J. Constructing biomedical domain-specific knowledge graph with minimum supervision. Knowl. Inf. Syst. 2020, 62, 317–336. [Google Scholar] [CrossRef]
- Zehra, S.; Mohsin, S.F.M.; Wasi, S.; Jami, S.I.; Siddiqui, M.S.; Syed, M.K.U.-R.R. Muhammad Khaliq-Ur-Rahman Raazi Syed Muhammad Shoaib Siddiqui Financial knowledge graph based financial report query system. IEEE Access 2021, 9, 69766–69782. [Google Scholar] [CrossRef]
- Finlayson, S.G.; LePendu, P.; Shah, N.H. Building the graph of medicine from millions of clinical narratives. Sci. Data 2014, 1, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Papageorgiou, E.I.; Huszka, C.; De Roo, J.; Douali, N.; Jaulent, M.C.; Colaert, D. Application of probabilistic and fuzzy cognitive approaches in semantic web framework for medical decision support. Comput. Methods Programs Biomed. 2013, 112, 580–598. [Google Scholar] [CrossRef]
- Mohamed, S.K.; Nováček, V.; Nounu, A. Discovering protein drug targets using knowledge graph embeddings. Bioinformatics 2020, 36, 603–610. [Google Scholar] [CrossRef]
- Ettorre, A.; Rocha Rodríguez, O.; Faron, C.; Michel, F.; Gandon, F. A knowledge graph enhanced learner model to predict outcomes to questions in the medical field. In Proceedings of the International Conference on Knowledge Engineering and Knowledge Management, Bolzano, Italy, 16–20 September 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 237–251. [Google Scholar]
- Fei, X.; Chen, P.; Wei, L.; Huang, Y.; Xin, Y.; Li, J. Quality Management of Pulmonary Nodule Radiology Reports Based on Natural Language Processing. Bioengineering 2022, 9, 244. [Google Scholar] [CrossRef]
- Blagec, K.; Barbosa-Silva, A.; Ott, S.; Samwald, M. A curated, ontology-based, large-scale knowledge graph of artificial intelligence tasks and benchmarks. Sci. Data 2022, 9, 322. [Google Scholar] [CrossRef] [PubMed]
- Zheng, S.; Rao, J.; Song, Y.; Zhang, J.; Xiao, X.; Fang, E.F.; Yang, Y.; Niu, Z. PharmKG: A dedicated knowledge graph benchmark for bomedical data mining. Brief. Bioinform. 2021, 22, bbaa344. [Google Scholar] [CrossRef]
- Teng, F.; Yang, W.; Chen, L.; Huang, L.; Xu, Q. Explainable prediction of medical codes with knowledge graphs. Front. Bioeng. Biotechnol. 2020, 8, 867. [Google Scholar] [CrossRef]
- Heindorf, S.; Potthast, M.; Stein, B.; Engels, G. Vandalism detection in wikidata. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; pp. 327–336. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. Adv. Neural Inf. Process. Syst. 2013, 26, 2787–2795. [Google Scholar]
- Yang, B.; Yih, W.T.; He, X.; Gao, J.; Deng, L. Embedding entities and relations for learning and inference in knowledge bases. arXiv 2014, arXiv:1412.6575. [Google Scholar]
- Sun, Z.; Deng, Z.H.; Nie, J.Y.; Tang, J. Rotate: Knowledge graph embedding by relational rotation in complex space. arXiv 2019, arXiv:1902.10197. [Google Scholar]
- Melo, A.; Paulheim, H. Detection of relation assertion errors in knowledge graphs. In Proceedings of the Knowledge Capture Conference, Austin, TX, USA, 4–6 December 2017; pp. 1–8. [Google Scholar]
- Abedini, F.; Keyvanpour, M.R.; Menhaj, M.B. Correction Tower: A general embedding method of the error recognition for the knowledge graph correction. Int. J. Pattern Recognit. Artif. Intell. 2020, 34, 2059034. [Google Scholar] [CrossRef]
- Xie, R.; Liu, Z.; Lin, F.; Lin, L. Does william shakespeare really write hamlet? Knowledge representation learning with confidence. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32, p. 11924. [Google Scholar]
- Shan, Y.; Bu, C.; Liu, X.; Ji, S.; Li, L. Confidence-aware negative sampling method for noisy knowledge graph embedding. In Proceedings of the 2018 IEEE International Conference on Big Knowledge (ICBK), Singapore, 17–18 November 2018; pp. 33–40. [Google Scholar]
- Jia, S.; Xiang, Y.; Chen, X.; Wang, K. Triple trustworthiness measurement for knowledge graph. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 2865–2871. [Google Scholar]
- Zhang, Q.; Dong, J.; Duan, K.; Huang, X.; Liu, Y.; Xu, L. Contrastive knowledge graph error detection. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, 17–21 October 2022; pp. 2590–2599. [Google Scholar]
- Zhang, Q.; Dong, J.; Tan, Q.; Huang, X. Integrating entity attributes for error-aware knowledge graph embedding. IEEE Trans. Knowl. Data Eng. 2023. [Google Scholar] [CrossRef]
- Li, Q.; Li, L.; Zhong, J.; Huang, L.F. Real-time sepsis severity prediction on knowledge graph deep learning networks for the intensive care unit. J. Vis. Commun. Image Represent. 2020, 72, 102901. [Google Scholar] [CrossRef]
- Jiang, J.; Wang, H.; Xie, J.; Guo, X.; Guan, Y.; Yu, Q. Medical knowledge embedding based on recursive neural network for multi-disease diagnosis. Artif. Intell. Med. 2020, 103, 101772. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge graph embedding by translating on hyperplanes. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; Volume 28, pp. 1112–1119. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 29, pp. 2181–2187. [Google Scholar]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge graph embedding via dynamic mapping matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Beijing, China, 26–31 July 2015; pp. 687–696. [Google Scholar]
- Nickel, M.; Tresp, V.; Kriegel, H.P. A three-way model for collective learning on multi-relational data. In Proceedings of the 28th International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011; Volume 11, pp. 809–816. [Google Scholar]
- Trouillon, T.; Welbl, J.; Riedel, S.; Gaussier, É.; Bouchard, G. Complex embeddings for simple link prediction. In Proceedings of the 33rd International Conference on Machine Learning, PMLR, New York, NY, USA, 19–24 June 2016; pp. 2071–2080. [Google Scholar]
- Nguyen, D.Q.; Nguyen, T.D.; Nguyen, D.Q.; Phung, D. A novel embedding model for knowledge base completion based on convolutional neural network. arXiv 2017, arXiv:1712.02121. [Google Scholar]
- Vashishth, S.; Sanyal, S.; Nitin, V.; Talukdar, P. Composition-based multi-relational graph convolutional networks. arXiv 2019, arXiv:1911.03082. [Google Scholar]
- Dettmers, T.; Minervini, P.; Stenetorp, P.; Riedel, S. Convolutional 2d knowledge graph embeddings. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32, pp. 1811–1818. [Google Scholar]
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; Van Den Berg, R.; Titov, I.; Welling, M. Modeling relational data with graph convolutional networks. In Proceedings of the The Semantic Web: 15th International Conference, ESWC 2018, Heraklion, Greece, 3–7 June 2018; Proceedings 15. Springer: Berlin/Heidelberg, Germany, 2018; pp. 593–607. [Google Scholar]
- Nathani, D.; Chauhan, J.; Sharma, C.; Kaul, M. Learning attention-based embeddings for relation prediction in knowledge graphs. arXiv 2019, arXiv:1906.01195. [Google Scholar]
- Dong, X.; Gabrilovich, E.; Heitz, G.; Horn, W.; Lao, N.; Murphy, K.; Strohmann, T.; Sun, S.; Zhang, W. Knowledge vault: A web-scale approach to probabilistic knowledge fusion. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 601–610. [Google Scholar]
- Zhao, Y.; Feng, H.; Gallinari, P. Embedding learning with triple trustiness on noisy knowledge graph. Entropy 2019, 21, 1083. [Google Scholar] [CrossRef]
- Ma, Y.; Gao, H.; Wu, T.; Qi, G. Learning disjointness axioms with association rule mining and its application to inconsistency detection of linked data. In Proceedings of the Semantic Web and Web Science: 8th Chinese Conference, CSWS 2014, Wuhan, China, 8–12 August 2014; Revised Selected Papers 8. Springer: Berlin/Heidelberg, Germany, 2014; pp. 29–41. [Google Scholar]
- Wang, X.; Wang, X.L.; Wilkes, D.M. A minimum spanning tree-inspired clustering-based outlier detection technique. In Proceedings of the Advances in Data Mining. Applications and Theoretical Aspects: 12th Industrial Conference, ICDM 2012, Berlin, Germany, 13–20 July 2012; Proceedings 12. Springer: Berlin/Heidelberg, Germany, 2012; pp. 209–223. [Google Scholar]
- Debattista, J.; Lange, C.; Auer, S. A preliminary investigation towards improving linked data quality using distance-based outlier detection. In Proceedings of the Semantic Technology: 6th Joint International Conference, JIST 2016, Singapore, 2–4 November 2016; Revised Selected Papers 6. Springer: Berlin/Heidelberg, Germany, 2016; pp. 116–124. [Google Scholar]
- Ge, C.; Gao, Y.; Weng, H.; Zhang, C.; Miao, X.; Zheng, B. Kgclean: An embedding powered knowledge graph cleaning framework. arXiv 2020, arXiv:2004.14478. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Xue, B.; Zou, L. Knowledge graph quality management: A comprehensive survey. IEEE Trans. Knowl. Data Eng. 2022, 35, 4969–4988. [Google Scholar] [CrossRef]
- Yao, L.; Mao, C.; Luo, Y. KG-BERT: BERT for knowledge graph completion. arXiv 2019, arXiv:1909.03193. [Google Scholar]
- Zhang, Y.; Chen, Z.; Zhang, W.; Chen, H. Making Large Language Models Perform Better in Knowledge Graph Completion. arXiv 2023, arXiv:2310.06671. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| the original knowledge graph | |
| (h, r, t) | a triplet with the head, relation, and tail |
| the triplet-level KG constructed from | |
| the hyper-view KG constructed from | |
| the set of the tail entities share the same (h, r) | |
| x | representation of the triplet |
| z | representation learned from x |
| confidence score of the triplet (h, r, t) |
| Datasets | Entities | Relations | Triplets | In-Degree |
|---|---|---|---|---|
| PharmKG-8k | 7262 | 28 | 500,958 | 58.86 |
| DiaKG | 2658 | 15 | 4099 | 1.55 |
| DiseaseKG | 43,972 | 12 | 312,159 | 6.74 |
| Nell-995 | 75,492 | 200 | 154,213 | 1.98 |
| Datasets | PharmKG-8k | DiseaseKG | DiaKG | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| K | K = 1% | K = 2% | K = 3% | K = 4% | K = 5%* | K = 1% | K = 2% | K = 3% | K = 4% | K = 5% * | K = 1% | K = 2% | K = 3% | K = 4% | K = 5% * | |
| Precision@K | TransE [14] † | 0.812 | 0.681 | 0.584 | 0.515 | 0.461 | 0.623 | 0.498 | 0.425 | 0.370 | 0.331 | 0.341 | 0.280 | 0.227 | 0.207 | 0.175 |
| DistMult [15] † | 0.802 | 0.722 | 0.664 | 0.607 | 0.547 | 0.754 | 0.636 | 0.533 | 0.458 | 0.402 | 0.439 | 0.304 | 0.252 | 0.219 | 0.200 | |
| RotatE [16] † | 0.871 | 0.762 | 0.681 | 0.609 | 0.563 | 0.727 | 0.601 | 0.501 | 0.427 | 0.374 | 0.487 | 0.317 | 0.260 | 0.225 | 0.195 | |
| CAGED [22] † | 0.958 | 0.917 | 0.845 | 0.761 | 0.674 | 0.936 | 0.870 | 0.776 | 0.687 | 0.611 | 0.562 | 0.459 | 0.400 | 0.371 | 0.326 | |
| EMKGEL(our) | 0.963 | 0.923 | 0.852 | 0.763 | 0.679 | 0.962 | 0.899 | 0.813 | 0.727 | 0.648 | 0.596 | 0.487 | 0.418 | 0.378 | 0.338 | |
| Recall@K | TransE [14] † | 0.162 | 0.272 | 0.350 | 0.411 | 0.461 | 0.124 | 0.199 | 0.255 | 0.296 | 0.331 | 0.068 | 0.112 | 0.136 | 0.165 | 0.175 |
| DistMult [15] † | 0.160 | 0.288 | 0.398 | 0.486 | 0.547 | 0.150 | 0.254 | 0.319 | 0.367 | 0.402 | 0.087 | 0.122 | 0.151 | 0.175 | 0.200 | |
| RotatE [16] † | 0.174 | 0.304 | 0.408 | 0.487 | 0.563 | 0.142 | 0.241 | 0.301 | 0.342 | 0.374 | 0.097 | 0.126 | 0.156 | 0.180 | 0.195 | |
| CAGED [22] † | 0.191 | 0.366 | 0.507 | 0.608 | 0.674 | 0.187 | 0.347 | 0.465 | 0.550 | 0.611 | 0.112 | 0.183 | 0.240 | 0.297 | 0.326 | |
| EMKGEL(our) | 0.192 | 0.369 | 0.511 | 0.611 | 0.679 | 0.192 | 0.359 | 0.487 | 0.581 | 0.648 | 0.119 | 0.194 | 0.251 | 0.302 | 0.338 | |
| Ratio | 5% | 10% | 15% | ||||||
|---|---|---|---|---|---|---|---|---|---|
| K | K = 5% | K = 10% | K = 15% | K = 5% | K = 10% | K = 15% | K = 5% | K = 10% | K = 15% |
| Precision@K | |||||||||
| TransE [14] † | 0.358 | 0.255 | 0.196 | 0.546 | 0.432 | 0.356 | 0.666 | 0.569 | 0.490 |
| DistMult [15] † | 0.286 | 0.235 | 0.205 | 0.489 | 0.421 | 0.375 | 0.605 | 0.540 | 0.494 |
| RotatE [16] † | 0.352 | 0.237 | 0.193 | 0.454 | 0.378 | 0.324 | 0.626 | 0.544 | 0.474 |
| CKRL [22] | 0.450 | 0.306 | 0.236 | 0.679 | 0.524 | 0.421 | 0.745 | 0.646 | 0.560 |
| KGTtm [22] | 0.481 | 0.320 | 0.242 | 0.713 | 0.527 | 0.437 | 0.788 | 0.673 | 0.576 |
| CAGED [22] | 0.516 | 0.325 | 0.251 | 0.799 | 0.585 | 0.458 | 0.823 | 0.729 | 0.599 |
| EMKGEL(our) | 0.542 | 0.344 | 0.264 | 0.807 | 0.606 | 0.488 | 0.842 | 0.732 | 0.626 |
| Recall@K | |||||||||
| TransE [14] † | 0.358 | 0.511 | 0.589 | 0.273 | 0.432 | 0.534 | 0.222 | 0.379 | 0.490 |
| DistMult [15] † | 0.286 | 0.471 | 0.616 | 0.244 | 0.421 | 0.562 | 0.201 | 0.360 | 0.494 |
| RotatE [16] † | 0.352 | 0.474 | 0.579 | 0.227 | 0.378 | 0.487 | 0.208 | 0.363 | 0.474 |
| CKRL [22] | 0.450 | 0.612 | 0.708 | 0.340 | 0.524 | 0.632 | 0.248 | 0.431 | 0.560 |
| KGTtm [22] | 0.481 | 0.640 | 0.726 | 0.357 | 0.527 | 0.656 | 0.263 | 0.449 | 0.576 |
| CAGED [22] | 0.516 | 0.650 | 0.753 | 0.400 | 0.585 | 0.687 | 0.274 | 0.486 | 0.599 |
| EMKGEL(our) | 0.542 | 0.689 | 0.792 | 0.403 | 0.606 | 0.732 | 0.281 | 0.488 | 0.732 |
| Precision@K | Recall@K | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| K | K = 1% | K = 2% | K = 3% | K = 4% | K = 5% | K = 1% | K = 2% | K = 3% | K = 4% | K = 5% |
| EMKGEL | 0.887 | 0.792 | 0.692 | 0.613 | 0.542 | 0.177 | 0.317 | 0.415 | 0.490 | 0.542 |
| EMKGEL w/o bi-LSTM | 0.793 | 0.711 | 0.621 | 0.549 | 0.492 | 0.158 | 0.284 | 0.373 | 0.439 | 0.492 |
| EMKGEL w/o HyGAT | 0.798 | 0.721 | 0.630 | 0.561 | 0.507 | 0.159 | 0.288 | 0.378 | 0.448 | 0.507 |
| EMKGEL w/o local | 0.866 | 0.759 | 0.658 | 0.574 | 0.507 | 0.173 | 0.303 | 0.394 | 0.459 | 0.507 |
| EMKGEL w/o global | 0.828 | 0.754 | 0.677 | 0.594 | 0.518 | 0.165 | 0.301 | 0.406 | 0.475 | 0.518 |
| EMKGEL w RotatE | 0.885 | 0.768 | 0.661 | 0.583 | 0.523 | 0.177 | 0.307 | 0.397 | 0.467 | 0.523 |
| Triplet | Number of Share(h, r) | Number of Share(r, t) | Confidence Score | ||
|---|---|---|---|---|---|
| Grounded | Our | CAGED | |||
| X | 66 | 9 | True | 0.8703 | 0.8549 |
| 66 | 9 | True | 0.8301 | 0.7924 | |
| 66 | 11 | True | 0.9201 | 0.8773 | |
| 66 | 10 | Noisy | 0.6521 | 0.4891 | |
| 5 | 2 | Noisy | 0.2431 | 0.6312 | |
| 4 | 1 | Noisy | 0.1003 | 0.5455 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, G.; Ye, Q.; Ruan, T. Enhancing Error Detection on Medical Knowledge Graphs via Intrinsic Label. Bioengineering 2024, 11, 225. https://doi.org/10.3390/bioengineering11030225
Yu G, Ye Q, Ruan T. Enhancing Error Detection on Medical Knowledge Graphs via Intrinsic Label. Bioengineering. 2024; 11(3):225. https://doi.org/10.3390/bioengineering11030225
Chicago/Turabian StyleYu, Guangya, Qi Ye, and Tong Ruan. 2024. "Enhancing Error Detection on Medical Knowledge Graphs via Intrinsic Label" Bioengineering 11, no. 3: 225. https://doi.org/10.3390/bioengineering11030225
APA StyleYu, G., Ye, Q., & Ruan, T. (2024). Enhancing Error Detection on Medical Knowledge Graphs via Intrinsic Label. Bioengineering, 11(3), 225. https://doi.org/10.3390/bioengineering11030225