
Speech- and Language-Based Classification of Alzheimer’s Disease: A Systematic Review



Abstract
:1. Introduction
1.1. Context and Objectives
1.2. Speech and Language Impairments in Alzheimer’s Disease
2. Materials and Methods
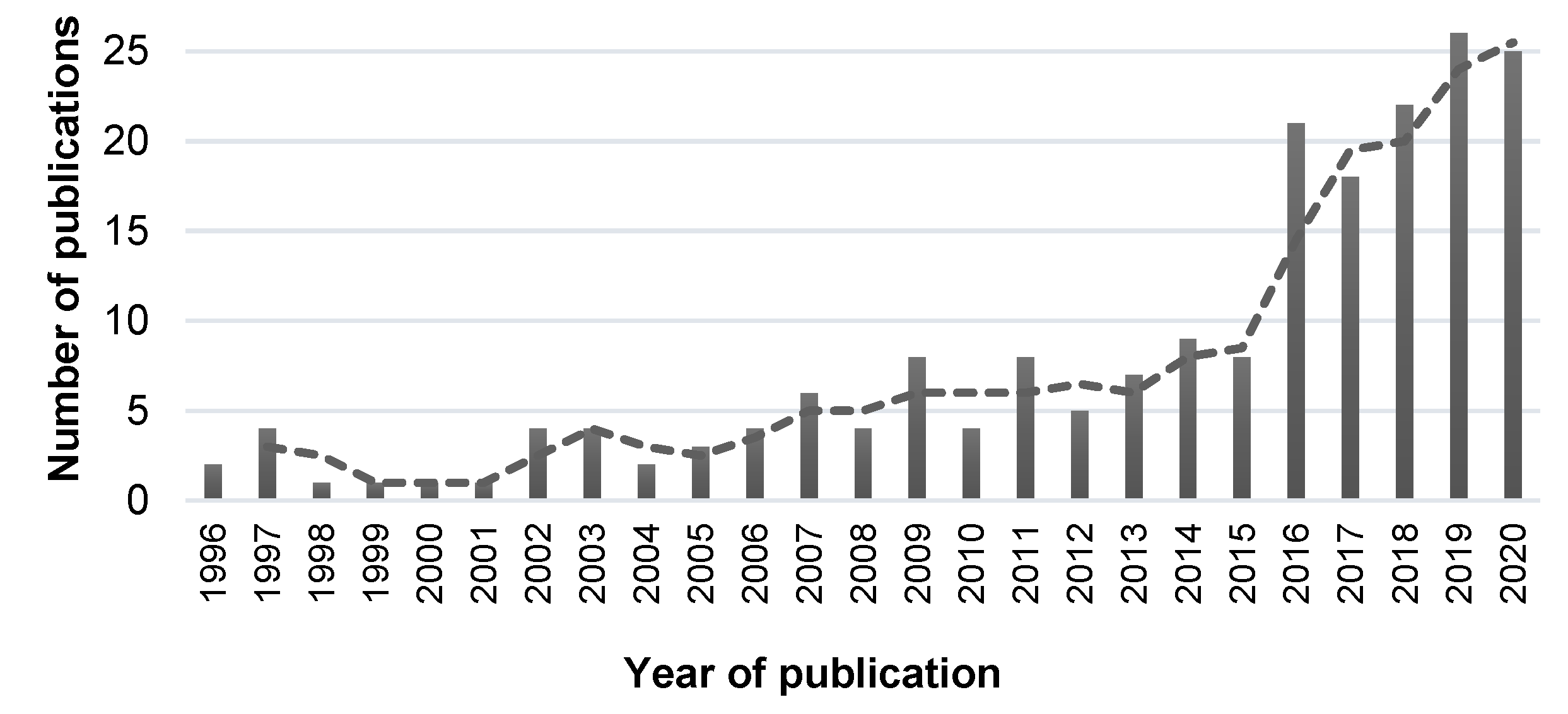
3. Results
3.1. Machine Learning Pipeline
- Data Preparation: In this step the extraction, optimization and normalization of features occurs. This consists in the selection of the most significant features (by removal of the non-dominant features) and in the transformation of ranges to similar limits, which will reduce training time and the complexity of the classification models. Metadata are “the data of the data”, more specifically, structured, and organized information on a given object (in this case voice recordings) that allow certain characteristics of it to be known. This metadata together with the results of the pre-processing of the recordings makes the final database. Incorrect or poor-quality data (e.g., outliers, wrong labels, noise, …), if not properly cared for, will lead to under optimized models and to unsatisfactory results. If data is not enough, for example when deep learning algorithms are used, then data augmentation techniques can be useful.
- Training and Validation: The supporting database is divided into subsets, usually 70–90% for training and 30–10% for testing. The subsets can be randomly generated several times and the results can be averaged for additional confidence in the results, a procedure that is designated by cross-validation. The data model is trained, i.e., the involved parameters are adjusted, by one or many optimizers, and the performance is calculated using the test subset. This step allows categorizing and organizing the data to promote better analysis [30]. When data is not enough, then transfer learning approaches can be used.
- Optimization: After model evaluation, it is possible to conclude on the parameters that need to be improved, as well as to proceed in a more effective way to the selection of the most interesting and relevant features, so that a new extraction and consequently a new process (iteration) of Training and Validation can be performed.
- Run-Time: Having concluded the previous points, the system is ready to be deployed and to classify new unseen inputs. More specifically, from the recording of a patient’s voice, to classify it as possible healthy or possible Alzheimer’s patient.
3.2. Speech and Language Resources
3.3. Language and Speech Features
3.4. Classification Models
3.5. Testing and Performance Indicators
4. Discussion
4.1. Base Model for System Development
- DATABASE. The DementiaBank database, provided by the TalkBank platform, would be used due to its versatility in terms of population, types of tasks, and languages; This is robust resource, widely known and used, that can be useful when comparing systems using a common linguistic base.
- FEATURES. A combination of linguistic and acoustic features seems to provide the best results, namely the duration and the total number of silences, voice segments, and hesitations, as well as the fundamental frequency, jitter, and shimmer, as they are of the characteristics where a greater difference between healthy individuals and individuals with AD.
- TASK. Given the previously mentioned features, spontaneous speech would be used as the main task for assessment, using questions that would generate a fluent and spontaneous conversation.
- CLASSIFICATION MODELS. As classification models, Artificial Neural Networks should constitute the base model for decision due to their flexibility to data patterns and because the provide a high dimension parameter space that can be explored and tuned. Systems based on these models have the highest reported accuracies.
- EVALUATION MODELS. As it is the most recurrent, cross-validation should be applied to evaluate the classification models. Accuracy and F-score should be the comparison metrics.
4.2. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Brookmeyer, R.; Johnson, E.; Ziegler-Graham, K.; Arrighi, H.M. Forecasting the Global Burden of Alzheimer’s Disease. Alzheimer’s Dement. 2007, 3, 186–191. [Google Scholar] [CrossRef] [Green Version]
- Prince, M.; Bryce, R.; Albanese, E.; Wimo, A.; Ribeiro, W.; Ferri, C.P. The Global Prevalence of Dementia: A Systematic Review and Metaanalysis. Alzheimer’s Dement. 2013, 9, 63–75.e2. [Google Scholar] [CrossRef] [PubMed]
- Khachaturian, Z.S. Diagnosis of Alzheimer’s Disease. Arch. Neurol. 1985, 42, 1097–1105. [Google Scholar] [CrossRef]
- Weller, J.; Budson, A. Current Understanding of Alzheimer’s Disease Diagnosis and Treatment. F1000Res 2018, 7, F1000 Faculty Rev-1161. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pereira, T.; Ferreira, F.L.; Cardoso, S.; Silva, D.; de Mendonça, A.; Guerreiro, M.; Madeira, S.C.; for the Alzheimer’s Disease Neuroimaging Initiative. Neuropsychological Predictors of Conversion from Mild Cognitive Impairment to Alzheimer’s Disease: A Feature Selection Ensemble Combining Stability and Predictability. BMC Med. Inform. Decis. Mak. 2018, 18, 137. [Google Scholar] [CrossRef] [Green Version]
- Belleville, S.; Fouquet, C.; Hudon, C.; Zomahoun, H.T.V.; Croteau, J.; Consortium for the Early Identification of Alzheimer’s disease-Quebec. Neuropsychological Measures That Predict Progression from Mild Cognitive Impairment to Alzheimer’s Type Dementia in Older Adults: A Systematic Review and Meta-Analysis. Neuropsychol. Rev. 2017, 27, 328–353. [Google Scholar] [CrossRef]
- Battista, P.; Salvatore, C.; Berlingeri, M.; Cerasa, A.; Castiglioni, I. Artificial Intelligence and Neuropsychological Measures: The Case of Alzheimer’s Disease. Neurosci. Biobehav. Rev. 2020, 114, 211–228. [Google Scholar] [CrossRef]
- Soldan, A.; Gazes, Y.; Stern, Y. Alzheimer’s Disease☆. In Reference Module in Neuroscience and Biobehavioral Psychology; Elsevier: Amsterdam, The Netherlands, 2017; ISBN 978-0-12-809324-5. [Google Scholar]
- Nussbaum, R.L.; Ellis, C.E. Alzheimer’s Disease and Parkinson’s Disease. N. Engl. J. Med. 2003, 348, 1356–1364. [Google Scholar] [CrossRef] [Green Version]
- Pulido, M.L.B.; Hernández, J.B.A.; Ballester, M.Á.F.; González, C.M.T.; Mekyska, J.; Smékal, Z. Alzheimer’s Disease and Automatic Speech Analysis: A Review. Expert Syst. Appl. 2020, 150, 113213. [Google Scholar] [CrossRef]
- Logsdon, R.G.; Gibbons, L.E.; McCurry, S.M.; Teri, L. Quality of Life in Alzheimer’s Disease: Patient and Caregiver Reports. J. Ment. Health Aging 1999, 5, 21–32. [Google Scholar]
- McKhann, G.M.; Knopman, D.S.; Chertkow, H.; Hyman, B.T.; Jack, C.R.; Kawas, C.H.; Klunk, W.E.; Koroshetz, W.J.; Manly, J.J.; Mayeux, R.; et al. The Diagnosis of Dementia Due to Alzheimer’s Disease: Recommendations from the National Institute on Aging-Alzheimer’s Association Workgroups on Diagnostic Guidelines for Alzheimer’s Disease. Alzheimer’s Dement. 2011, 7, 263–269. [Google Scholar] [CrossRef] [Green Version]
- Toth, L.; Hoffmann, I.; Gosztolya, G.; Vincze, V.; Szatloczki, G.; Banreti, Z.; Pakaski, M.; Kalman, J. A Speech Recognition-Based Solution for the Automatic Detection of Mild Cognitive Impairment from Spontaneous Speech. Curr. Alzheimer Res. 2018, 15, 130–138. [Google Scholar] [CrossRef]
- Alberdi, A.; Aztiria, A.; Basarab, A. On the Early Diagnosis of Alzheimer’s Disease from Multimodal Signals: A Survey. Artif. Intell. Med. 2016, 71, 1–29. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.Y.; LaBardi, B.A.; Raskind, M.A.; Peskind, E.R. Chapter 14—Alzheimer’s Disease and Other Neurocognitive Disorders. In Handbook of Mental Health and Aging, 3rd ed.; Hantke, N., Etkin, A., O’Hara, R., Eds.; Academic Press: San Diego, CA, USA, 2020; pp. 161–183. ISBN 978-0-12-800136-3. [Google Scholar]
- Cacho, J.; Benito-León, J.; García-García, R.; Fernández-Calvo, B.; Vicente-Villardón, J.L.; Mitchell, A.J. Does the Combination of the MMSE and Clock Drawing Test (Mini-Clock) Improve the Detection of Mild Alzheimer’s Disease and Mild Cognitive Impairment? J. Alzheimers Dis. 2010, 22, 889–896. [Google Scholar] [CrossRef] [Green Version]
- Hancock, P.; Larner, A.J. Test Your Memory Test: Diagnostic Utility in a Memory Clinic Population. Int. J. Geriatr. Psychiatry 2011, 26, 976–980. [Google Scholar] [CrossRef]
- Ferris, S.H.; Farlow, M. Language Impairment in Alzheimer’s Disease and Benefits of Acetylcholinesterase Inhibitors. Clin. Interv. Aging 2013, 8, 1007–1014. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Schuff, N.; Camacho, M.; Chao, L.L.; Fletcher, T.P.; Yaffe, K.; Woolley, S.C.; Madison, C.; Rosen, H.J.; Miller, B.L.; et al. MRI Markers for Mild Cognitive Impairment: Comparisons between White Matter Integrity and Gray Matter Volume Measurements. PLoS ONE 2013, 8, e66367. [Google Scholar] [CrossRef] [Green Version]
- Axer, H.; Klingner, C.M.; Prescher, A. Fiber Anatomy of Dorsal and Ventral Language Streams. Brain Lang. 2013, 127, 192–204. [Google Scholar] [CrossRef]
- Banovic, S.; Zunic, L.J.; Sinanovic, O. Communication Difficulties as a Result of Dementia. Mater. Sociomed 2018, 30, 221–224. [Google Scholar] [CrossRef]
- Soria Lopez, J.A.; González, H.M.; Léger, G.C. Alzheimer’s Disease. Handb Clin. Neurol. 2019, 167, 231–255. [Google Scholar] [CrossRef]
- Szatloczki, G.; Hoffmann, I.; Vincze, V.; Kalman, J.; Pakaski, M. Speaking in Alzheimer’s Disease, Is That an Early Sign? Importance of Changes in Language Abilities in Alzheimer’s Disease. Front. Aging Neurosci. 2015, 7. [Google Scholar] [CrossRef] [Green Version]
- Meilán, J.J.G.; Martínez-Sánchez, F.; Carro, J.; López, D.E.; Millian-Morell, L.; Arana, J.M. Speech in Alzheimer’s Disease: Can Temporal and Acoustic Parameters Discriminate Dementia? Dement. Geriatr. Cogn. Disord. 2014, 37, 327–334. [Google Scholar] [CrossRef]
- Campbell, E.L.; Fernández, L.D.; Raboso, J.J.; García-Mateo, C. Alzheimer’s Dementia Detection from Audio and Language Modalities in Spontaneous Speech. IberSPEECH 2021. [Google Scholar] [CrossRef]
- Mahajan, P.; Baths, V. Acoustic and Language Based Deep Learning Approaches for Alzheimer’s Dementia Detection From Spontaneous Speech. Front. Aging Neurosci. 2021, 13, 623607. [Google Scholar] [CrossRef]
- Tricco, A.C.; Lillie, E.; Zarin, W.; O’Brien, K.K.; Colquhoun, H.; Levac, D.; Moher, D.; Peters, M.D.J.; Horsley, T.; Weeks, L.; et al. PRISMA Extension for Scoping Reviews (PRISMA-ScR): Checklist and Explanation. Ann. Intern. Med. 2018, 169, 467–473. [Google Scholar] [CrossRef] [Green Version]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 Statement: An Updated Guideline for Reporting Systematic Reviews. BMJ 2021, 372, n71. [Google Scholar] [CrossRef]
- Walker, L., Jr.; Schaffer, J.D. The Art and Science of Machine Intelligence; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Allen, M.; Cervo, D. Multi-Domain Master Data Management; Elsevier: Amsterdam, The Netherlands, 2015; ISBN 978-0-12-800835-5. [Google Scholar]
- Braga, D.; Madureira, A.M.; Coelho, L.; Abraham, A. Neurodegenerative Diseases Detection Through Voice Analysis. In Proceedings of the Hybrid Intelligent Systems; Abraham, A., Muhuri, P.K., Muda, A.K., Gandhi, N., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 734, pp. 213–223. [Google Scholar]
- Boller, F.; Becker, J. Dementiabank Database Guide; University of Pittsburgh: Pittsburgh, PA, USA, 2005. [Google Scholar]
- Becker, J.T.; Boller, F.; Lopez, O.L.; Saxton, J.; McGonigle, K.L. The Natural History of Alzheimer’s Disease. Description of Study Cohort and Accuracy of Diagnosis. Arch. Neurol. 1994, 51, 585–594. [Google Scholar] [CrossRef]
- Mueller, K.D.; Koscik, R.L.; Hermann, B.P.; Johnson, S.C.; Turkstra, L.S. Declines in Connected Language Are Associated with Very Early Mild Cognitive Impairment: Results from the Wisconsin Registry for Alzheimer’s Prevention. Front. Aging Neurosci. 2018, 9, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Land, W.H.; Schaffer, J.D. A Machine Intelligence Designed Bayesian Network Applied to Alzheimer’s Detection Using Demographics and Speech Data. Procedia Comput. Sci. 2016, 95, 168–174. [Google Scholar] [CrossRef] [Green Version]
- König, A.; Satt, A.; Sorin, A.; Hoory, R.; Toledo-Ronen, O.; Derreumaux, A.; Manera, V.; Verhey, F.; Aalten, P.; Robert, P.H.; et al. Automatic Speech Analysis for the Assessment of Patients with Predementia and Alzheimer’s Disease. Alzheimer’s Dement. Diagn. Assess. Dis. Monit. 2015, 1, 112–124. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- König, A.; Satt, A.; Sorin, A.; Hoory, R.; Derreumaux, A.; David, R.; Robert, P.H. Use of Speech Analyses within a Mobile Application for the Assessment of Cognitive Impairment in Elderly People. Curr. Alzheimer Res. 2018, 15, 120–129. [Google Scholar] [CrossRef] [PubMed]
- König, A.; Linz, N.; Tröger, J.; Wolters, M.; Alexandersson, J.; Robert, P. Fully Automatic Speech-Based Analysis of the Semantic Verbal Fluency Task. Dement. Geriatr. Cogn. Disord. 2018, 45, 198–209. [Google Scholar] [CrossRef]
- Mirzaei, S.; El Yacoubi, M.; Garcia-Salicetti, S.; Boudy, J.; Kahindo, C.; Cristancho-Lacroix, V.; Kerhervé, H.; Rigaud, A.S. Two-Stage Feature Selection of Voice Parameters for Early Alzheimer’s Disease Prediction. Irbm 2018, 39, 430–435. [Google Scholar] [CrossRef]
- Rentoumi, V.; Paliouras, G.; Danasi, E.; Arfani, D.; Fragkopoulou, K.; Varlokosta, S.; Papadatos, S. Automatic Detection of Linguistic Indicators as a Means of Early Detection of Alzheimer’s Disease and of Related Dementias: A Computational Linguistics Analysis. In Proceedings of the 2017 8th IEEE International Conference on Cognitive Infocommunications (CogInfoCom), Debrecen, Hungary, 11–14 September 2017; pp. 33–38. [Google Scholar]
- Gosztolya, G.; Vincze, V.; Tóth, L.; Pákáski, M.; Kálmán, J.; Hoffmann, I. Identifying Mild Cognitive Impairment and Mild Alzheimer’s Disease Based on Spontaneous Speech Using ASR and Linguistic Features. Comput. Speech Lang. 2019, 53, 181–197. [Google Scholar] [CrossRef]
- Beltrami, D.; Calzà, L.; Gagliardi, G.; Ghidoni, E.; Marcello, N.; Favretti, R.R.; Tamburini, F. Automatic Identification of Mild Cognitive Impairment through the Analysis of Italian Spontaneous Speech Productions. In Proceedings of the Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016; European Language Resources Association (ELRA): Portorož, Slovenia, 2016; pp. 2086–2093. [Google Scholar]
- Chien, Y.-W.; Hong, S.-Y.; Cheah, W.-T.; Yao, L.-H.; Chang, Y.-L.; Fu, L.-C. An Automatic Assessment System for Alzheimer’s Disease Based on Speech Using Feature Sequence Generator and Recurrent Neural Network. Sci. Rep. 2019, 9, 19597. [Google Scholar] [CrossRef] [PubMed]
- Qiao, Y.; Xie, X.-Y.; Lin, G.-Z.; Zou, Y.; Chen, S.-D.; Ren, R.-J.; Wang, G. Computer-Assisted Speech Analysis in Mild Cognitive Impairment and Alzheimer’s Disease: A Pilot Study from Shanghai, China. J. Alzheimer’s Dis. 2020, 75, 211–221. [Google Scholar] [CrossRef]
- Toledo, C.M.; Aluísio, S.M.; dos Santos, L.B.; Brucki, S.M.D.; Trés, E.S.; de Oliveira, M.O.; Mansur, L.L. Analysis of Macrolinguistic Aspects of Narratives from Individuals with Alzheimer’s Disease, Mild Cognitive Impairment, and No Cognitive Impairment. Alzheimer’s Dement. Diagn. Assess. Dis. Monit. 2018, 10, 31–40. [Google Scholar] [CrossRef] [PubMed]
- López-de-Ipiña, K.; Alonso-Hernández, J.B.; Solé-Casals, J.; Travieso-González, C.M.; Ezeiza, A.; Faúndez-Zanuy, M.; Calvo, P.M.; Beitia, B. Feature Selection for Automatic Analysis of Emotional Response Based on Nonlinear Speech Modeling Suitable for Diagnosis of Alzheimer’s Disease. Neurocomputing 2015, 150, 392–401. [Google Scholar] [CrossRef] [Green Version]
- Lopéz-de-Ipiña, K.; Martinez-de-Lizarduy, U.; Calvo, P.M.; Mekyska, J.; Beitia, B.; Barroso, N.; Estanga, A.; Tainta, M.; Ecay-Torres, M. Advances on Automatic Speech Analysis for Early Detection of Alzheimer Disease: A Non-Linear Multi-Task Approach. Curr. Alzheimer Res. 2017, 14, 139–148. [Google Scholar] [CrossRef]
- Solé-Casals, J.; Lopéz-de-Ipiña, K.; Eguiraun, H.; Alonso, J.B.; Travieso, C.M.; Ezeiza, A.; Barroso, N.; Ecay-Torres, M.; Martinez-Lage, P.; Beitia, B. Feature Selection for Spontaneous Speech Analysis to Aid in Alzheimer’s Disease Diagnosis: A Fractal Dimension Approach. Comput. Speech Lang. 2015, 30, 43–60. [Google Scholar] [CrossRef] [Green Version]
- Martínez-Sánchez, F.; Meilán, J.J.G.; Carro, J.; Ivanova, O. A Prototype for the Voice Analysis Diagnosis of Alzheimer’s Disease. J. Alzheimer’s Dis. 2018, 64, 473–481. [Google Scholar] [CrossRef]
- Fraser, K.C.; Lundholm Fors, K.; Kokkinakis, D. Multilingual Word Embeddings for the Assessment of Narrative Speech in Mild Cognitive Impairment. Comput. Speech Lang. 2019, 53, 121–139. [Google Scholar] [CrossRef]
- Fraser, K.C.; Lundholm Fors, K.; Eckerström, M.; Öhman, F.; Kokkinakis, D. Predicting MCI Status From Multimodal Language Data Using Cascaded Classifiers. Front. Aging Neurosci. 2019, 11. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Themistocleous, C.; Eckerström, M.; Kokkinakis, D. Identification of Mild Cognitive Impairment From Speech in Swedish Using Deep Sequential Neural Networks. Front. Neurol. 2018, 9, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Khodabakhsh, A.; Yesil, F.; Guner, E.; Demiroglu, C. Evaluation of Linguistic and Prosodic Features for Detection of Alzheimer’s Disease in Turkish Conversational Speech. Eurasip J. Audio Speech Music Processing 2015, 2015. [Google Scholar] [CrossRef] [Green Version]
- Khodabakhsh, A.; Kuscuoglu, S.; Demiroglu, C. Detection of Alzheimer’s Disease Using Prosodic Cues in Conversational Speech. In Proceedings of the 2014 22nd Signal Processing and Communications Applications Conference (SIU), Trabzon, Turkey, 23–25 April 2014; pp. 1003–1006. [Google Scholar]
- Khodabakhsh, A.; Demiroglu, C. Analysis of Speech-Based Measures for Detecting and Monitoring Alzheimer’s Disease. In Data Mining in Clinical Medicine; 2015; Volume 1246, pp. 159–173 ISBN 9781493919857.
- Neuberger, T.; Gyarmathy, D.; Gráczi, T.E.; Horváth, V.; Gósy, M.; Beke, A. Development of a Large Spontaneous Speech Database of Agglutinative Hungarian Language. In Proceedings of the Text, Speech and Dialogue; Sojka, P., Horák, A., Kopeček, I., Pala, K., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 424–431. [Google Scholar]
- Mar, J.; Arrospide, A.; Soto-Gordoa, M.; Machón, M.; Iruin, Á.; Martinez-Lage, P.; Gabilondo, A.; Moreno-Izco, F.; Gabilondo, A.; Arriola, L. Validity of a Computerised Population Registry of Dementia Based on Clinical Databases. Neurología (Engl. Ed.) 2020. [Google Scholar] [CrossRef]
- Johnson, S.C.; Koscik, R.L.; Jonaitis, E.M.; Clark, L.R.; Mueller, K.D.; Berman, S.E.; Bendlin, B.B.; Engelman, C.D.; Okonkwo, O.C.; Hogan, K.J.; et al. The Wisconsin Registry for Alzheimer’s Prevention: A Review of Findings and Current Directions. Alzheimers Dement (Amst.) 2018, 10, 130–142. [Google Scholar] [CrossRef]
- Hoffmann, I.; Nemeth, D.; Dye, C.D.; Pákáski, M.; Irinyi, T.; Kálmán, J. Temporal Parameters of Spontaneous Speech in Alzheimer’s Disease. Int J. Speech Lang Pathol 2010, 12, 29–34. [Google Scholar] [CrossRef]
- Horley, K.; Reid, A.; Burnham, D. Emotional Prosody Perception and Production in Dementia of the Alzheimer’s Type. J. Speech Lang. Hear Res. 2010, 53, 1132–1146. [Google Scholar] [CrossRef]
- Hernández-Domínguez, L.; Ratté, S.; Sierra-Martínez, G.; Roche-Bergua, A. Computer-Based Evaluation of Alzheimer’s Disease and Mild Cognitive Impairment Patients during a Picture Description Task. Alzheimers Dement (Amst) 2018, 10, 260–268. [Google Scholar] [CrossRef]
- Land, W.H.; Schaffer, J.D. Alzheimer’s Disease and Speech Background. In The Art and Science of Machine Intelligence: With An Innovative Application for Alzheimer’s Detection from Speech; Land, W.H., Jr., Schaffer, J.D., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 107–135. ISBN 978-3-030-18496-4. [Google Scholar]
- Mueller, K.D.; Hermann, B.; Mecollari, J.; Turkstra, L.S. Connected Speech and Language in Mild Cognitive Impairment and Alzheimer’s Disease: A Review of Picture Description Tasks. J. Clin. Exp. Neuropsychol. 2018, 40, 917–939. [Google Scholar] [CrossRef]
- Kalapatapu, P.; Goli, S.; Arthum, P.; Malapati, A. A Study on Feature Selection and Classification Techniques of Indian Music. Procedia Comput. Sci. 2016, 98, 125–131. [Google Scholar] [CrossRef] [Green Version]
- Yahyaoui’s, A.; Yahyaoui, I.; Yumuşak, N. Machine Learning Techniques for Data Classification. In Advances in Renewable Energies and Power Technologies; Elsevier: Amsterdam, The Netherlands, 2018; pp. 441–450. [Google Scholar]
- Orimaye, S.O.; Wong, J.S.M.; Golden, K.J.; Wong, C.P.; Soyiri, I.N. Predicting Probable Alzheimer’s Disease Using Linguistic Deficits and Biomarkers. BMC Bioinform. 2017, 18, 34. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Carvajal, G.; Maucec, M.; Cullick, S. Components of Artificial Intelligence and Data Analytics. In Intelligent Digital Oil and Gas Fields; Elsevier: Amsterdam, The Netherlands, 2018; pp. 101–148. [Google Scholar]
- Capozzoli, A.; Cerquitelli, T.; Piscitelli, M.S. Enhancing Energy Efficiency in Buildings through Innovative Data Analytics Technologiesa. In Pervasive Computing; Elsevier: Amsterdam, The Netherlands, 2016; pp. 353–389. [Google Scholar]
- Hoffman, J.I.E. Logistic Regression. In Basic Biostatistics for Medical and Biomedical Practitioners; Elsevier: Amsterdam, The Netherlands, 2019; pp. 581–589. [Google Scholar]
- Stanimirova, I.; Daszykowski, M.; Walczak, B. Robust Methods in Analysis of Multivariate Food Chemistry Data. In Data Handling in Science and Technology; Elsevier: Amsterdam, The Netherlands, 2013; pp. 315–340. [Google Scholar]
- Siau, K. E-Creativity and E-Innovation. In The International Handbook on Innovation; Elsevier: Amsterdam, The Netherlands, 2003; pp. 258–264. [Google Scholar]
- Guo, Z.; Ling, Z.; Li, Y. Detecting Alzheimer’s Disease from Continuous Speech Using Language Models. J. Alzheimers Dis. 2019, 70, 1163–1174. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Function | Early Stages | Moderate to Severe Stages |
|---|---|---|
| Spontaneous Speech | Fluent, grammatical | Non-fluent, echolalic |
| Paraphrastic errors | Semantics | Semantic and phonetic |
| Repetition | Intact | Very affected |
| Naming objects | Slightly affected | Very affected |
| Understanding the words | Intact | Very affected |
| Syntactical understanding | Intact | Very affected |
| Reading | Intact | Very affected |
| Writing | Intact | Very affected |
| Semantic knowledge of words and objects | Difficulties with less used words and objects. | Very affected |
| Language | Database Name | Task | Population | Availability | Refs. | ||
|---|---|---|---|---|---|---|---|
| HC M/F | MCI M/F | AD M/F | |||||
| English | DementiaBank (TalkBank) | DF | 99 | - | 169 | Upon request | [32] |
| English | Pitt Corpus | PD | 75/142 | 27/16 | 87/170 | Upon request | [33] |
| English | WRAP | PD | 59/141 | 28/36 | - | Upon request | [34] |
| English | - | PD | 112 | - | 98 | Undefined | [35] |
| French | - | Mixed | 6/9 | 11/12 | 13/13 | Undefined | [36] |
| French | - | VF, PD, SS Counting | - | 19/25 | 12/15 | Undefined | [37] |
| French | - | VF, Semantics | 5/19 | 23/24 | 8/16 | Undefined | [38] |
| French | - | Reading | 16 | 16 | 16 | Undefined | [39] |
| Greek | - | PD | 16/14 | - | 13/17 | Undefined | [40] |
| Hungarian | BEA | SS | 13/23 | 16/32 | - | Upon request | [13] [41] |
| 25 | 25 | 25 | |||||
| Italian | - | Mixture | 48 | 48 | - | Undefined | [42] |
| Mandarin | Lu Corpus | PD/SS | 4/6 | - | 6/4 | Upon request | [43] |
| Mandarin | - | PD/SS | 24 | 20 | 20 | Undefined | [44] |
| Portuguese | Cinderella | SS | 20 | 20 | 20 | Undefined | [45] |
| Spanish | AZTITXIKI (AZTIAHO) | SS | 5 | - | 5 | Undefined | [46] |
| Spanish | AZTIAHORE (AZTIAHO) | SS | 11/9 | - | 8/12 | Undefined | [47,48] |
| Spanish | PGA-OREKA | VF | 26/36 | 17/21 | - | Upon request | [47] |
| Mini-PGA | PD | 4/8 | - | 1/5 | |||
| Spanish | - | Reading | 30/68 | - | 14/33 | Undefined | [49] |
| Swedish | Gothenburg | PD | 13/23 | 15/16 | - | Undefined | [50] |
| Swedish | - | Mixed | 12/14 | 8/21 | - | Upon request | [51] |
| Swedish | - | Reading | 11/19 | 12/13 | - | Undefined | [52] |
| Turkish | - | SS/Interview | 31/20 | - | 18/10 | Undefined | [53] |
| Turkish | - | SS/Interview | 12/15 | 17/10 | Undefined | [54] | |
| Turkish | - | SS | 12/15 | - | 17/10 | Undefined | [55] |
| Feature Type | Feature Name |
|---|---|
| Occurrence frequency | Words (3); Verbs (2); Nouns, Predicates (1); Coordinate and Subordinate Phrases (2); Reduced phrases (2); Incomplete Phrases/Ideas (3); Filling words (1); Unique words (2); Revisions/Repetitions (1); Word Replacement (2) |
| Time/Duration | Total speech (3); Speech Rate (3); Speech time (2); Average of syllables (2); Pauses (4); Maximum pause (2). |
| Parts of speech ratio | Nouns/Verbs (2); Pronouns/Substantives (1); Determinants/Substantives (2); Type/Token (2); Silence/Speaking (4); Hesitation/Speaking (3). |
| Semantic density | The density of the idea (1); Efficiency of the idea (1); Density of information (2); Density of the sentences (1). |
| POS (Parts-of-Speech) | Text tags (4). |
| Complexity | The entropy of words (1); Honore’s Statistics (1). |
| Lexical Variation | Variation: nominal (2), adjective (1), modifier (1), adverb (1), verbal (1), word (1); Brunet’s Index (1). |
| Feature Type | Feature Name |
|---|---|
| Hesitations | Filled Pauses (2); Silent Pauses (4); Long Pauses (3); Short Pauses (3); Voice Breaks (5). |
| Voice Segments | Period (4); Average duration (4); Accentuation (2). |
| Frequency | Fundamental frequency (8); Short term energy (7); Spectral centroid (1); Autocorrelation (2); Variation of voice frequencies (2). |
| Regularity | Jitter (11); Shimmer (11); Intensity (6); Square Energy Operator (1); Teager-Kaiser Energy Operator (1); Root Mean Square Amplitude (2). |
| Noise | Harmonic-Noise ratio (3); Noise-Harmonic ratio (2). |
| Phonetics | Articulation dynamics (1); the rate of articulation (1); Pause rate (5). |
| Intensity | From the voice segments (1); From the pause segments (1); |
| Timbre | Formant’s Structure (6); Formant’s Frequency (8). |
| Model | Characterization | References | |
|---|---|---|---|
| NB | Consists of a network, composed of a main node with other associated descending nodes that follow Bayes’ theorem [65]. | [13,35,40,53] | |
| SVM | Consists of building the hyperplane with maximum margin capable of optimally separating two classes of a data set [65]. | [13,37,38,39,40,41,50,51,52,53,54,55,61,66] | |
| RF | Relies on the creation of a large number of uncorrelated decision trees based on the average random selection of predictor variables [67]. | [13,61] | |
| DT | Consists of building a decision tree where each node in the tree specifies a test on an attribute, each branch descending from that node corresponds to one of the possible values for that attribute, and each leaf represents class labels associated with the instance. The instances of the training set are classified following the path from the root to a leaf, according to the result of the tests along the path [68]. | [39,53,54,55] | |
| KNN | Based on the memory principle in the sense that it stores all cases and classifies new cases based on similar measures [65]. | [42,46,48] | |
| LR | A model capable of finding an equation that predicts an outcome for a binary variable from one or more response variables [69]. | [42,51] | |
| LDA | It is a discriminatory approach based on the differences between samples of certain groups. Unsupervised learning technique where the objective is to maximize the relationship between the variance between groups and the variance within the same group [70]. | [54,55] | |
| ANN | DNN | Naturally inspired models. Supervised learning approach based on a theory of association (pattern recognition) between cognitive elements [71]. There are many possibilities with different elements, structures, layers, etc. The larger the number of parameters then the larger the dataset must be. | [42,43,46,47,48,52,53] |
| CNN | |||
| RNN | |||
| MLP | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vigo, I.; Coelho, L.; Reis, S. Speech- and Language-Based Classification of Alzheimer’s Disease: A Systematic Review. Bioengineering 2022, 9, 27. https://doi.org/10.3390/bioengineering9010027
Vigo I, Coelho L, Reis S. Speech- and Language-Based Classification of Alzheimer’s Disease: A Systematic Review. Bioengineering. 2022; 9(1):27. https://doi.org/10.3390/bioengineering9010027
Chicago/Turabian StyleVigo, Inês, Luis Coelho, and Sara Reis. 2022. "Speech- and Language-Based Classification of Alzheimer’s Disease: A Systematic Review" Bioengineering 9, no. 1: 27. https://doi.org/10.3390/bioengineering9010027
APA StyleVigo, I., Coelho, L., & Reis, S. (2022). Speech- and Language-Based Classification of Alzheimer’s Disease: A Systematic Review. Bioengineering, 9(1), 27. https://doi.org/10.3390/bioengineering9010027