
Diverse COVID-19 CT Image-to-Image Translation with Stacked Residual Dropout


Abstract
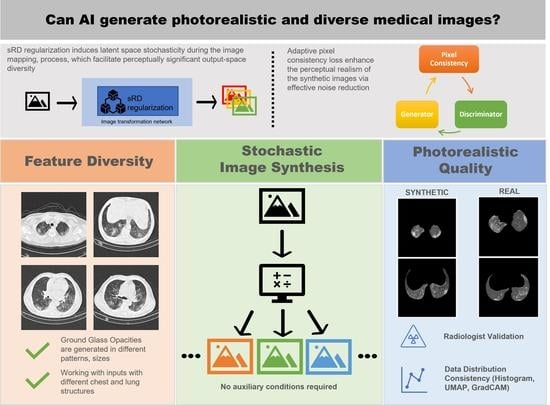
:
1. Introduction
- Diverse style attributes of GGO features: the radiographic features of COVID-19 on chest CT contain the formation of GGO in various shapes and sizes. This setting is in contrast with the general-purpose unimodal I2I approaches, where the style attributes are easily identified with a single representation, such as black and white lines (zebra), brown color region (horse), and orange color regions (orange) [45]. Therefore, the non-COVID19-to-COVID19 translation is a more challenging task and requires translating the style attributes presented in different patterns and locations within the region of the lungs.
- Requirement of high-frequency structures: in the general-purpose I2I translation setting, minor and detailed variations of style attributes generated on the outputs usually do not affect the global representation of the image due to the low requirement for high-frequency representation. However, the natural attributes of the GGO features are represented in high-frequency details and manifested in different shapes, locations, and sizes [16,17,19]. Therefore, these detailed GGO patterns generated within the lung parenchyma are essential in deciding the perceptual realism of the synthetic COVID-19 CT images.
- High tolerance of texture artifacts: ideal image translation generates images containing no traits of style attributes that overlap with the source domain, also known as style artifacts. Texture or style artifacts refer to the translation error of style attributes, which cause overlapping style attributes that belong to both image domains. Such concern is negligible for non-COVID-19-to-COVID-19 translation because the style attributes of the images from both domains share similar radiographic representations. As such, overlapping style attributes in style artifacts are hardly visible, and do not affect the general realistic representation of the synthetic outputs.
2. Material and Methods
2.1. Datasets
2.2. Stacked Residual Dropout (sRD) Mechanism
2.2.1. Assumption
2.2.2. Building Block of Residual Connections
2.2.3. Two-Mode Structure of sRD Mechanism
2.3. Stacked Residual Dropout GAN Framework (sRD-GAN)
2.3.1. Overview of sRD-GAN
2.3.2. Models
2.4. Lost Function and Formulation
2.4.1. Adaptive Pixel Consistency Loss
2.4.2. Adversarial Loss
2.4.3. Cycle Consistency Loss
2.4.4. Identity Loss
2.4.5. Full Objective Functions
2.5. Experiment Setup
2.5.1. Implementation
- (1)
- xi is fed as input to learn the forward mapping G(xi) → yi′, and backpropagate G and DY.
- (2)
- yi is fed as input to learn the reverse mapping G(yi) → xi′, and backpropagate G and DX.
2.5.2. Software and Hardware Specification
2.6. Performance Evaluation
2.6.1. Radiologist Examination
2.6.2. Learned Perceptual Image Patch Similarity (LPIPS)
2.6.3. Fréchet Inception Distance (FID)
2.6.4. Statistical Analysis
3. Result and Discussion
3.1. sRD-GAN in Training and Inference Modes
3.2. Impact of Different RD-Block Designs
3.2.1. Residual Dropout Rate
3.2.2. Single RD Activation at Different Latent Depths
3.2.3. Sequential Stacked RD Activation
3.3. Qualitative Assessment
3.4. Effective Noise Reduction via Pixel Consistency Loss
3.4.1. Adaptive Pixel Consistency Loss
3.4.2. Difference between Pixel and Cycle Consistency
3.5. Additional Analysis
3.5.1. GradCAM Analysis
3.5.2. Pixel Intensity Distributions and UMAP Analysis
3.5.3. Performance on HUST-19 Dataset
3.6. Benchmarking with Existing GANs
3.7. External Validation on Different Clinical Cases
4. Discussion
4.1. Key Findings
- Instance diversity. The main contribution of the novel sRD-GAN is the ability to facilitate perceptually visible instance diversity using a simple regularization-based strategy that is highly generalizable across GAN-based algorithms and without relying on auxiliary conditions. In this study, the experiment result suggests that sRD regularization can facilitate sufficient latent space stochasticity to induce a significant perceptual difference between the instance-diverse outputs. The in-depth investigation of the sRD mechanism from different perspectives reveals the positive correlation between the number of RD-blocks, dropout rate, and latent depths with the magnitude of instance diversity. Specifically, larger numbers of RD-blocks and larger dropout rates can enlarge the space of stochasticity and ultimately lead to increased instance diversity at the cost of perceptual quality degradation. In addition, the stochasticity induced at higher dimensionality can cause enormous structural changes, which lead to larger amplification of latent stochasticity compared to lower-dimensional latent spaces.
- Perceptual realism and quality. While the perceptual quality can be evaluated using the standard FID metric, the actual reality of the synthetic COVID-19 remains challenging due to the domain knowledge requirement. With the help of an experienced radiologist, the Visual Turing Test reveals a promising result achieved by the synthetic images for generating radiography findings of GGO, which is consistent with the real COVID-19 CT images. Furthermore, exhaustive experiments demonstrate the consistent adversary correlation between image diversity and perceptual quality due to the underlying property of the stacked residual dropout, which induces latent space stochasticity and simultaneously encourages a more unconstrained space of image mapping. Thereby, a larger magnitude of stochasticity can generate additional noise artifacts that could be detrimental to the overall perceptual quality and realism of the images. The impact of the adversarial relationship between perceptual quality and image diversity is addressed by a reduced dropout rate at higher dimensional latent spaces. As a result, drastic improvement in the perceptual quality was noticed without affecting the significance of synthetic features generated on the output images. Furthermore, the sRD-GAN also demonstrated superior performance in terms of perceptual quality compared to other GAN baselines, where images generated from the GAN are distorted by a significant amount of noise artifacts. In contrast, the images generated from CycleGAN and one-to-one CycleGAN models failed to effectively eliminate the noise artifacts.
- Effective noise reduction. The comparison between the images generated with and without pixel consistency and cycle consistency reveals the distinctive differences between the consistency losses in the image translation task. In particular, the proposed adaptive pixel consistency loss demonstrated superior performance in reducing the noise artifacts of the synthetic images. The effectiveness of the noise reduction is due to the strong connection enforced by the pixel consistency loss, which encourages the output image to be similar to the input image. Moreover, the adaptive setting of the pixel consistency loss addresses the problem of the diminished magnitude of the translated GGO features caused by the pixel consistency constraint. A possible explanation is that the conditional weight updates of the loss are based on the generator’s performance. The superior performance of the adaptive setting of the pixel consistency and its high effectiveness in reducing noise artifacts is also demonstrated on other GAN baselines.
4.2. Failure in Image Synthesis and Limitations
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Block | Components | Output Shape |
|---|---|---|
| Input Block | c7s1-64 | 256, 256, 64 |
| Down-sampling Block 1 | d128 | 128, 128, 128 |
| Down-sampling Block 2 | d256 | 64, 64, 256 |
| Residual Block 1 | R256 | 64, 64, 256 |
| Residual Block 2 | R256 | 64, 64, 256 |
| Residual Block 3 | R256 | 64, 64, 256 |
| Residual Block 4 | R256 | 64, 64, 256 |
| Residual Block 5 | R256 | 64, 64, 256 |
| Residual Block 6 | R256 | 64, 64, 256 |
| Residual Block 7 | R256 | 64, 64, 256 |
| Residual Block 8 | R256 | 64, 64, 256 |
| Residual Block 9 | R256 | 64, 64, 256 |
| Up-sampling Block 1 | u128 | 128, 128, 128 |
| Up-sampling Block 2 | u64 | 256, 256, 64 |
| Output Block | c7s1-3 | 256, 256, 3 |
| Block | Components | Output Shape |
|---|---|---|
| Convolution Block 1 | C64 | 128, 128, 64 |
| Convolution Block 2 | C128 | 64, 64, 128 |
| Convolution Block 3 | C256 | 32, 32, 256 |
| Convolution Block 4 | C512 | 16, 16, 512 |
| Output Block |
References
- Alshazly, H.; Linse, C.; Barth, E.; Martinetz, T. Explainable COVID-19 detection using chest CT scans and deep learning. Sensors 2021, 21, 455. [Google Scholar] [CrossRef] [PubMed]
- Ouyang, X.; Huo, J.; Xia, L.; Shan, F.; Liu, J.; Mo, Z.; Yan, F.; Ding, Z.; Yang, Q.; Song, B.; et al. Dual-sampling attention network for diagnosis of COVID-19 from community acquired pneumonia. IEEE Trans. Med. Imaging 2020, 39, 2595–2605. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Bao, Y.; Wen, Y.; Lu, H.; Luo, H.; Xiang, Y.; Li, X.; Liu, C.; Qian, D. Prior-attention residual learning for more discriminative COVID-19 screening in CT images. IEEE Trans. Med. Imaging 2020, 39, 2572–2583. [Google Scholar] [CrossRef]
- Ning, W.; Lei, S.; Yang, J.; Cao, Y.; Jiang, P.; Yang, Q.; Zhang, J.; Wang, X.; Chen, F.; Geng, Z.; et al. Open resource of clinical data from patients with pneumonia for the prediction of COVID-19 outcomes via Deep Learning. Nat. Biomed. Eng. 2020, 4, 1197–1207. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Xia, L. Coronavirus disease 2019 (COVID-19): Role of chest CT in diagnosis and management. Am. J. Roentgenol. 2020, 214, 1280–1286. [Google Scholar] [CrossRef] [PubMed]
- Zhao, W.; Zhong, Z.; Xie, X.; Yu, Q.; Liu, J. Relation between chest CT findings and clinical conditions of coronavirus disease (COVID-19) pneumonia: A multicenter study. Am. J. Roentgenol. 2020, 214, 1072–1077. [Google Scholar] [CrossRef] [PubMed]
- Harmon, S.A.; Sanford, T.H.; Xu, S.; Turkbey, E.B.; Roth, H.; Xu, Z.; Yang, D.; Myronenko, A.; Anderson, V.; Amalou, A.; et al. Artificial Intelligence for the detection of COVID-19 pneumonia on chest CT using multinational datasets. Nat. Commun. 2020, 11, 1–7. [Google Scholar] [CrossRef]
- Rubin, G.D.; Ryerson, C.J.; Haramati, L.B.; Sverzellati, N.; Kanne, J.P.; Raoof, S.; Schluger, N.W.; Volpi, A.; Yim, J.-J.; Martin, I.B.; et al. The role of chest imaging in patient management during the COVID-19 pandemic: A multinational consensus statement from the Fleischner Society. Radiology 2020, 296, 172–180. [Google Scholar] [CrossRef] [Green Version]
- Xu, X.; Jiang, X.; Ma, C.; Du, P.; Li, X.; Lv, S.; Yu, L.; Ni, Q.; Chen, Y.; Su, J.; et al. A deep learning system to screen novel coronavirus disease 2019 pneumonia. Engineering 2020, 6, 1122–1129. [Google Scholar] [CrossRef]
- Jin, C.; Chen, W.; Cao, Y.; Xu, Z.; Tan, Z.; Zhang, X.; Deng, L.; Zheng, C.; Zhou, J.; Shi, H.; et al. Development and evaluation of an artificial intelligence system for COVID-19 diagnosis. Nat. Commun. 2020, 11, 1–14. [Google Scholar] [CrossRef]
- Song, Y.; Zheng, S.; Li, L.; Zhang, X.; Zhang, X.; Huang, Z.; Chen, J.; Wang, R.; Zhao, H.; Chong, Y.; et al. Deep learning enables accurate diagnosis of novel coronavirus (COVID-19) with CT images. IEEE/ACM Trans. Comput. Biol. Bioinform. 2021, 18, 2775–2780. [Google Scholar] [CrossRef] [PubMed]
- Shi, F.; Xia, L.; Shan, F.; Song, B.; Wu, D.; Wei, Y.; Yuan, H.; Jiang, H.; He, Y.; Gao, Y.; et al. Large-scale screening to distinguish between COVID-19 and community-acquired pneumonia using infection size-aware classification. Phys. Med. Biol. 2021, 66, 065031. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Qin, L.; Xu, Z.; Yin, Y.; Wang, X.; Kong, B.; Bai, J.; Lu, Y.; Fang, Z.; Song, Q.; et al. Using artificial intelligence to detect COVID-19 and community-acquired pneumonia based on pulmonary CT: Evaluation of the diagnostic accuracy. Radiology 2020, 296, E65–E71. [Google Scholar] [CrossRef] [PubMed]
- Pascarella, G.; Strumia, A.; Piliego, C.; Bruno, F.; Del Buono, R.; Costa, F.; Scarlata, S.; Agrò, F.E. COVID-19 diagnosis and management: A comprehensive review. J. Intern. Med. 2020, 288, 192–206. [Google Scholar] [CrossRef]
- Mei, X. Predicting five-year overall survival in patients with non-small cell lung cancer by Relieff algorithm and random forests. In Proceedings of the 2017 IEEE 2nd Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 25–26 March 2017. [Google Scholar] [CrossRef]
- Jin, Y.-H.; Cai, L.; Cheng, Z.-S.; Cheng, H.; Deng, T.; Fan, Y.-P.; Fang, C.; Huang, D.; Huang, L.-Q.; Huang, Q.; et al. A rapid advice guideline for the diagnosis and treatment of 2019 novel coronavirus (2019-ncov) infected pneumonia (standard version). Mil. Med. Res. 2020, 7, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Bernheim, A.; Mei, X.; Huang, M.; Yang, Y.; Fayad, Z.A.; Zhang, N.; Diao, K.; Lin, B.; Zhu, X.; Li, K.; et al. Chest CT findings in coronavirus disease-19 (COVID-19): Relationship to duration of infection. Radiology 2020, 295, 200463. [Google Scholar] [CrossRef] [Green Version]
- CDC. What You Need to Know about Variants. Available online: https://www.cdc.gov/coronavirus/2019ncov/variants/variant.html (accessed on 10 November 2021).
- Kato, S.; Ishiwata, Y.; Aoki, R.; Iwasawa, T.; Hagiwara, E.; Ogura, T.; Utsunomiya, D. Imaging of COVID-19: An update of current evidences. Diagn. Interv. Imaging 2021, 102, 493–500. [Google Scholar] [CrossRef]
- Wang, T.; Lei, Y.; Fu, Y.; Wynne, J.F.; Curran, W.J.; Liu, T.; Yang, X. A review on medical imaging synthesis using deep learning and its clinical applications. J. Appl. Clin. Med. Phys. 2020, 22, 11–36. [Google Scholar] [CrossRef]
- Jiang, H.; Tang, S.; Liu, W.; Zhang, Y. Deep learning for COVID-19 chest CT (computed tomography) image analysis: A lesson from lung cancer. Comput. Struct. Biotechnol. J. 2020, 19, 1391–1399. [Google Scholar] [CrossRef]
- Waheed, A.; Goyal, M.; Gupta, D.; Khanna, A.; Al-Turjman, F.; Pinheiro, P.R. Covidgan: Data Augmentation using auxiliary classifier gan for improved COVID-19 detection. IEEE Access 2020, 8, 91916–91923. [Google Scholar] [CrossRef]
- Zunair, H.; Hamza, A.B. Synthesis of COVID-19 chest X-rays using unpaired image-to-image translation. Soc. Netw. Anal. Min. 2021, 11, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Laffont, P.-Y.; Ren, Z.; Tao, X.; Qian, C.; Hays, J. Transient attributes for high-level understanding and editing of outdoor scenes. ACM Trans. Graph. (TOG) 2014, 33, 149. [Google Scholar] [CrossRef]
- Xie, S.; Tu, Z. Holistically-nested edge detection. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1395–1403. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A. Colorful image colorization. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 649–666. [Google Scholar]
- Jiang, Y.; Chen, H.; Loew, M.; Ko, H. COVID-19 CT image synthesis with a conditional generative adversarial network. IEEE J. Biomed. Health Inform. 2021, 25, 441–452. [Google Scholar] [CrossRef] [PubMed]
- Sekuboyina, A.; Rempfler, M.; Kukacka, J.; Tetteh, G.; Valentinitsch, A.; Kirschke, J.S.; Menze, B.H. Btrfly net: Vertebrae labelling with energy-based adversarial learning of local spine prior. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2018—21st International Conference, Granada, Spain, 16–18 September 2018; pp. 649–657. [Google Scholar]
- Rezaei, M.; Harmuth, K.; Gierke, W.; Kellermeier, T.; Fischer, M.; Yang, H.; Meinel, C. A conditional adversarial network for semantic segmentation of brain tumor. In Proceedings of the International MICCAI Brainlesion Workshop, Quebec City, QC, Canada, 14 September 2017; pp. 241–252. [Google Scholar]
- Chen, Y.; Shi, F.; Christodoulou, A.G.; Xie, Y.; Zhou, Z.; Li, D. Efficient and accurate mri super-resolution using a generative adversarial network and 3d multi-level densely connected network. In Proceedings of the 2018 International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; pp. 91–99. [Google Scholar]
- Chen, X.; Konukoglu, E. Unsupervised detection of lesions in brain mri using constrained adversarial auto-encoders. arXiv 2018, arXiv:1806.04972. [Google Scholar]
- Karras, T.; Lain, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. In Proceedings of the 2019 Computer Vision and Pattern Recognition Conference (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative Adversarial Networks. arXiv 2016, arXiv:1511.06434. [Google Scholar]
- Liu, M.-Y.; Breuel, T.; Kautz, J. Unsupervised image-to-image translation networks. arXiv 2018, arXiv:1703.00848. [Google Scholar]
- Shen, Z.; Chen, Y.; Huang, T.S.; Zhou, S.K.; Georgescu, B.; Liu, X. One-to-one mapping for unpaired image-to-image translation. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020. [Google Scholar] [CrossRef]
- Zhu, J.-Y.; Zhang, R.; Pathak, D.; Darrell, T.; Efros, A.A.; Wang, O.; Shechtman, E. Toward multimodal image-to-image translation. arXiv 2018, arXiv:1711.11586. [Google Scholar]
- Huang, X.; Liu, M.-Y.; Belongie, S.; Kautz, J. Multimodal unsupervised image-to-image translation Computer Vision. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 179–196. [Google Scholar] [CrossRef] [Green Version]
- Lee, H.-Y.; Tseng, H.-Y.; Huang, J.-B.; Singh, M.; Yang, M.-H. Diverse image-to-image translation via disentangled representations. Computer Vision. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 36–52. [Google Scholar] [CrossRef] [Green Version]
- Bao, J.; Chen, D.; Wen, F.; Li, H.; Hua, G. CVAE-gan: Fine-grained image generation through asymmetric training. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef] [Green Version]
- Xiong, W.; He, Y.; Zhang, Y.; Luo, W.; Ma, L.; Luo, J. Fine-grained image-to-image transformation towards visual recognition. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 September 2020. [Google Scholar] [CrossRef]
- Li, H.; Hu, Y.; Li, S.; Lin, W.; Liu, P.; Higashita, R.; Liu, J. CT scan synthesis for Promoting computer-aided DIAGNOSIS capacity of COVID-19. In Proceedings of the 16th International Conference on Intelligent Computing Theories and Application, Bari, Italy, 2–5 October 2020; pp. 413–422. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for Deep Learning. J. Big Data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Odena, A.; Olah, C.; Shlens, J. Conditional image synthesis with auxiliary classifier gans. arXiv 2016, arXiv:1610.09585. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef] [Green Version]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Yang, D.; Hong, S.; Jang, Y.; Zhao, T.; Lee, H. Diversity-sensitive conditional generative adversarial networks. arXiv 2019, arXiv:1901.09024. [Google Scholar]
- Yan, T.; Wong, P.K.; Ren, H.; Wang, H.; Wang, J.; Li, Y. Automatic distinction BETWEEN COVID-19 and Common Pneumonia USING multi-scale convolutional neural network on chest CT scans. Chaos Solitons Fractals 2020, 140, 110153. [Google Scholar] [CrossRef] [PubMed]
- Viradiya, P. COVID-19 Radiography Dataset; Kaggle, 22 May 2022. Available online: https://www.kaggle.com/datasets/preetviradiya/covid19-radiography-dataset (accessed on 25 July 2021).
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. JMLR 2014, 15, 1929–1958. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Cambridge, MA, USA, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local Nash equilibrium. arXiv 2018, arXiv:1706.08500. [Google Scholar]
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform manifold approximation and projection for dimension reduction. arXiv 2020, arXiv:1802.03426. [Google Scholar]
- Lee, K.W.; Chin, R.K. An adaptive data processing framework for cost-effective COVID-19 and pneumonia detection. In Proceedings of the 2021 IEEE International Conference on Signal and Image Processing Applications (ICSIPA), Kuala Terenganu, Terenganu, Malaysia, 13–15 September 2021; pp. 150–155. [Google Scholar]





















| Source | Modality | Class | Quantity |
|---|---|---|---|
| [4] | CT | COVID-19 | 100 patients |
| Non-COVID-19 | 200 patients | ||
| [4] | CT | Non-COVID-19 | 9575 images |
| [48] | CT | COVID-19 | 416 patients |
| CAP | 412 patients | ||
| [49] | X-ray | COVID-19 | 3216 images |
| Non-COVID-19 | 10,192 images |
| Model | LPIPS | FID |
|---|---|---|
| sRD-GAN | ||
| Adaptive | 0.1254 | 38.9390 |
| Constant = 10 | 0.1265 | 62.2360 |
| Constant = 20 | 0.1186 | 43.3440 |
| Constant = 30 | 0.0825 | 37.7170 |
| CycleGAN | ||
| Adaptive | 0.2862 | 116.8220 |
| Constant = 10 | 0.2776 | 125.7760 |
| Constant = 20 | 0.2553 | 79.0550 |
| Constant = 30 | 0.1973 | 63.4590 |
| GAN | ||
| Adaptive | 0.2244 | 110.0560 |
| Constant = 10 | 0.2132 | 89.7050 |
| Constant = 20 | 0.1879 | 91.8460 |
| Constant = 30 | 0.2072 | 94.6160 |
| Model | Training Duration | LPIPS (Significance of Features) | FID |
|---|---|---|---|
| sRD-GAN | ~106.67 h | 0.1370 | 58.6774 |
| One-to-one CycleGAN | ~106.67 h | 0.1952 | 94.1130 |
| CycleGAN | ~106.67 h | 0.3055 | 115.1420 |
| GAN | ~58.67 h | 0.3905 | 157.1800 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, K.W.; Chin, R.K.Y. Diverse COVID-19 CT Image-to-Image Translation with Stacked Residual Dropout. Bioengineering 2022, 9, 698. https://doi.org/10.3390/bioengineering9110698
Lee KW, Chin RKY. Diverse COVID-19 CT Image-to-Image Translation with Stacked Residual Dropout. Bioengineering. 2022; 9(11):698. https://doi.org/10.3390/bioengineering9110698
Chicago/Turabian StyleLee, Kin Wai, and Renee Ka Yin Chin. 2022. "Diverse COVID-19 CT Image-to-Image Translation with Stacked Residual Dropout" Bioengineering 9, no. 11: 698. https://doi.org/10.3390/bioengineering9110698
APA StyleLee, K. W., & Chin, R. K. Y. (2022). Diverse COVID-19 CT Image-to-Image Translation with Stacked Residual Dropout. Bioengineering, 9(11), 698. https://doi.org/10.3390/bioengineering9110698