Application of Rough Set Theory to Water Quality Analysis: A Case Study



Abstract
:1. Introduction
2. Materials and Methods
2.1. Rough Set Theory
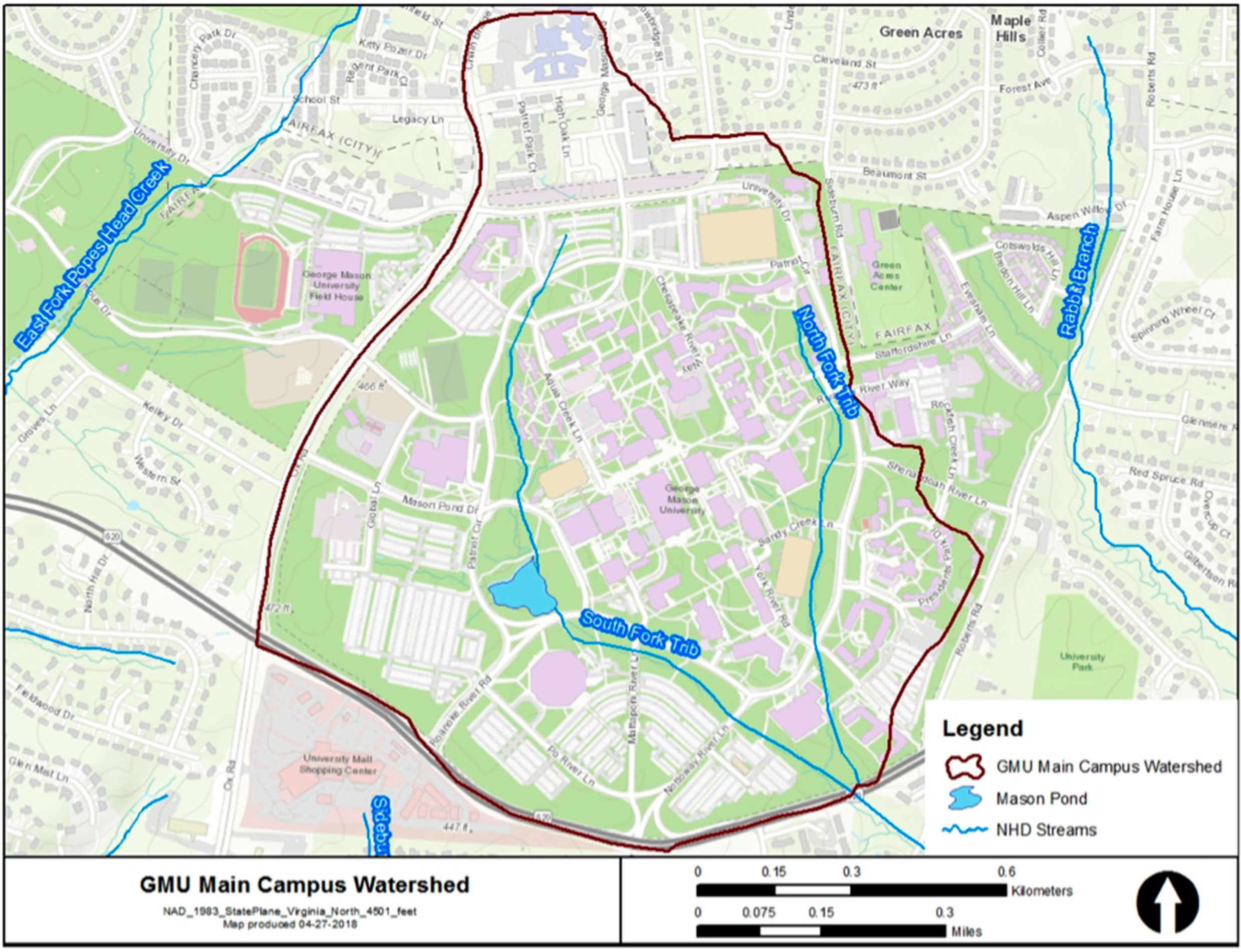
2.2. Study Area and Dataset
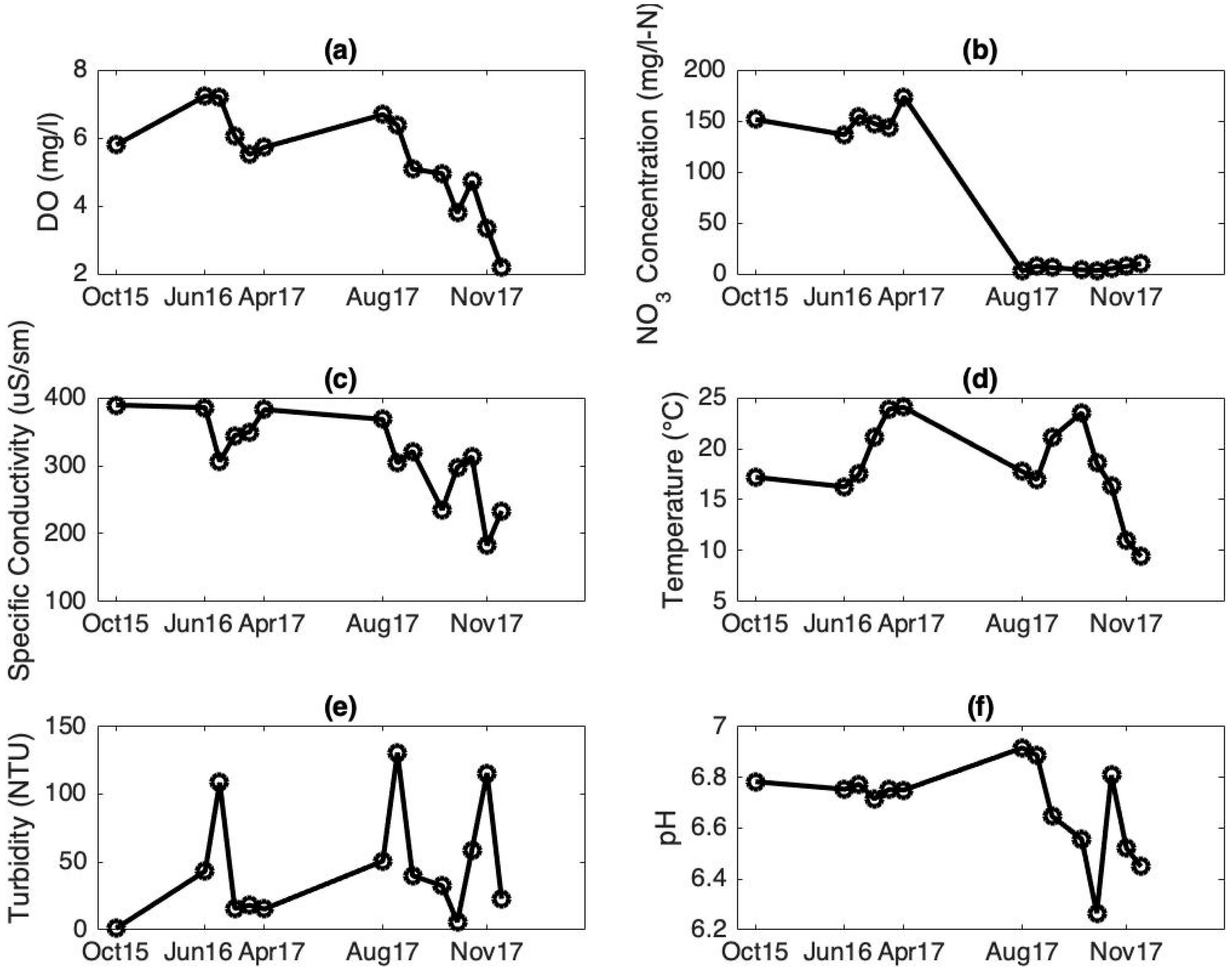
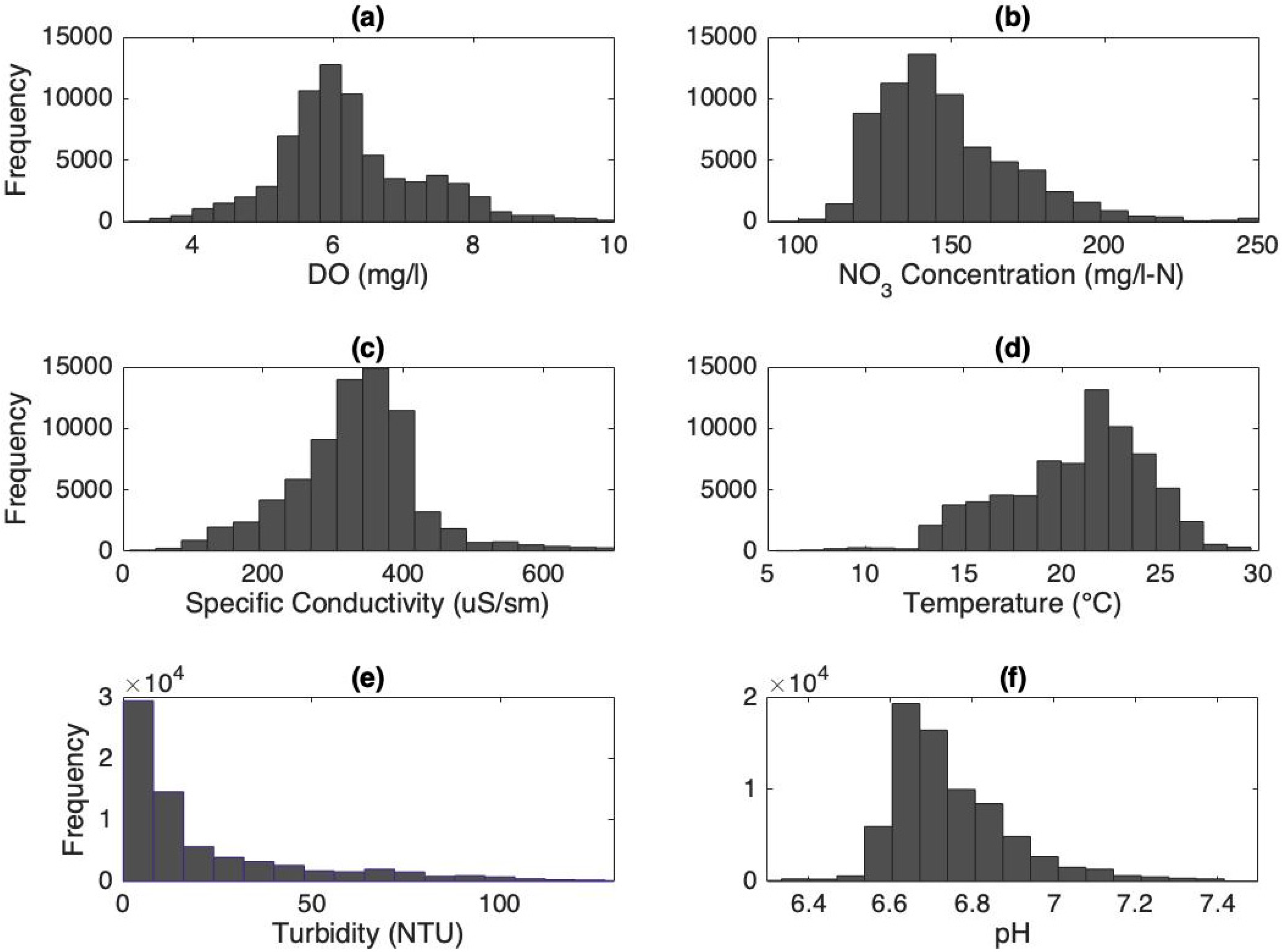
3. Results
4. Discussion
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
| (a) | (b) | ||||||||||||
| K | Tu | DO | N | Strength | Certainty | Coverage | DO | K | Tu | N | Strength | Certainty | Coverage |
| H | L | M | 1 | 0.07 | 1.00 | 0.20 | H | H | H | 1 | 0.07 | 1.00 | 0.14 |
| H | H | H | 1 | 0.07 | 1.00 | 0.50 | H | M | H | 1 | 0.07 | 1.00 | 0.14 |
| M | H | H | 1 | 0.07 | 1.00 | 0.50 | L | M | H | 2 | 0.14 | 0.50 | 0.29 |
| M | M | M | 2 | 0.14 | 0.50 | 0.40 | L | L | H | 1 | 0.07 | 0.33 | 0.14 |
| M | M | L | 2 | 0.14 | 0.50 | 0.29 | M | M | H | 2 | 0.14 | 0.50 | 0.29 |
| M | H | M | 2 | 0.14 | 0.40 | 0.40 | M | H | L | 1 | 0.07 | 1.00 | 1.00 |
| M | H | L | 2 | 0.14 | 0.40 | 0.40 | L | M | M | 2 | 0.14 | 0.50 | 0.33 |
| L | M | L | 2 | 0.14 | 1.00 | 0.40 | L | L | M | 2 | 0.14 | 0.67 | 0.33 |
| L | H | L | 1 | 0.07 | 1.00 | 0.20 | M | M | M | 2 | 0.14 | 0.50 | 0.33 |
| (c) | (d) | ||||||||||||
| K | Tu | NO3 | N | Strength | Certainty | Coverage | K | Tu | T | N | Strength | Certainty | Coverage |
| M | M | H | 1 | 0.07 | 0.25 | 1.00 | L | M | H | 1 | 0.07 | 0.50 | 0.33 |
| M | H | L | 2 | 0.14 | 0.40 | 0.25 | M | M | H | 2 | 0.14 | 0.50 | 0.67 |
| L | M | L | 2 | 0.14 | 1.00 | 0.25 | H | L | L | 1 | 0.07 | 1.00 | 0.13 |
| M | H | L | 1 | 0.07 | 0.20 | 0.13 | H | H | L | 1 | 0.07 | 1.00 | 0.13 |
| L | H | L | 1 | 0.07 | 1.00 | 0.13 | L | H | L | 1 | 0.07 | 1.00 | 0.13 |
| M | H | L | 1 | 0.07 | 0.20 | 0.13 | L | M | L | 1 | 0.07 | 0.50 | 0.13 |
| M | M | L | 1 | 0.07 | 0.25 | 0.13 | M | H | L | 4 | 0.29 | 0.80 | 0.50 |
| H | L | M | 1 | 0.07 | 1.00 | 0.20 | M | M | M | 2 | 0.14 | 0.50 | 0.67 |
| H | H | M | 1 | 0.07 | 1.00 | 0.20 | M | H | M | 1 | 0.07 | 0.20 | 0.33 |
| M | H | M | 1 | 0.07 | 0.20 | 0.20 | |||||||
| M | M | M | 2 | 0.14 | 0.50 | 0.40 | |||||||
| (e) | |||||||||||||
| T | Tu | K | N | Strength | Certainty | Coverage | |||||||
| L | L | H | 1 | 0.07 | 1.00 | 0.50 | |||||||
| L | H | H | 1 | 0.07 | 0.17 | 0.50 | |||||||
| H | M | L | 1 | 0.07 | 0.33 | 0.33 | |||||||
| L | H | L | 1 | 0.07 | 0.17 | 0.33 | |||||||
| L | M | L | 1 | 0.07 | 1.00 | 0.33 | |||||||
| M | M | M | 2 | 0.14 | 1.00 | 0.22 | |||||||
| H | M | M | 2 | 0.14 | 0.67 | 0.22 | |||||||
| L | H | M | 3 | 0.21 | 0.50 | 0.33 | |||||||
| M | H | M | 1 | 0.07 | 1.00 | 0.11 | |||||||
| L | H | M | 1 | 0.07 | 0.17 | 0.11 |
References
- Pai, P.-F.; Li, L.-L.; Hung, W.-Z.; Lin, K.-P. Using ADABOOST and Rough Set Theory for Predicting Debris Flow Disaster. Water Resour. Manag. 2014, 28, 1143–1155. [Google Scholar] [CrossRef]
- Wagner, R.J.; Boulger, R.W., Jr.; Oblinger, C.J.; Smith, B.A. Guidelines and Standard Procedures for Continuous Water-Quality Monitors: Station Operation, Record Computation, and Data Reporting [Internet]. 2006; [Cited 1 June 2018]. (Techniques and Methods). Report No.: 1-D3. Available online: http://pubs.er.usgs.gov/publication/tm1D3 (accessed on 5 November 2018).
- Lepot, M.; Aubin, J.-B.; Clemens, F.H.L.R. Interpolation in Time Series: An Introductive Overview of Existing Methods, Their Performance Criteria and Uncertainty Assessment. Water 2017, 9, 796. [Google Scholar] [CrossRef]
- Fu, L.; Wang, Y.-G. Statistical Tools for Analyzing Water Quality Data|IntechOpen [Internet]. 2012. [Cited 3 July 2018]. Available online: /books/water-quality-monitoring-and-assessment/statistical-tools-for-analyzing-water-quality-data (accessed on 5 November 2018).
- Liou, S.M.; Lo, S.L.; Hu, C.Y. Application of two-stage fuzzy set theory to river quality evaluation in Taiwan. Water Res. 2003, 37, 1406–1416. [Google Scholar] [CrossRef]
- Chen, X.; Li, Y.S.; Liu, Z.; Yin, K.; Li, Z.; Wai, O.W.; King, B. Integration of multi-source data for water quality classification in the Pearl River estuary and its adjacent coastal waters of Hong Kong. Cont. Shelf Res. 2004, 24, 1827–1843. [Google Scholar] [CrossRef]
- Shrestha, S.; Kazama, F. Assessment of surface water quality using multivariate statistical techniques: A case study of the Fuji river basin, Japan. Environ. Model. Softw. 2007, 22, 464–475. [Google Scholar] [CrossRef]
- Diamantopoulou, M.J.; Antonopoulos, V.Z.; Papamichail, D.M. Cascade Correlation Artificial Neural Networks for Estimating Missing Monthly Values of Water Quality Parameters in Rivers. Water Resour Manag. 2007, 21, 649–662. [Google Scholar] [CrossRef]
- Singh, A.P.; Ghosh, S.K.; Sharma, P. Water quality management of a stretch of river Yamuna: An interactive fuzzy multi-objective approach. Water Resour. Manag. 2007, 21, 515–532. [Google Scholar] [CrossRef]
- Manache, G.; Melching, C.S. Identification of reliable regression- and correlation-based sensitivity measures for importance ranking of water-quality model parameters. Environ. Model. Softw. 2008, 23, 549–562. [Google Scholar] [CrossRef]
- Qin, X.S.; Huang, G.H. An Inexact Chance-constrained Quadratic Programming Model for Stream Water Quality Management. Water Resour Manag. 2009, 23, 661. [Google Scholar] [CrossRef]
- Hou, D.; He, H.; Huang, P.; Zhang, G.; Loaiciga, H. Detection of water-quality contamination events based on multi-sensor fusion using an extended Dempster–Shafer method. Meas. Sci. Technol. 2013, 24, 055801. [Google Scholar] [CrossRef]
- Pawlak, Z. Rough sets. Int. J. Comput. Inf. Sci. 1982, 11, 341–356. [Google Scholar] [CrossRef]
- Polkowski, L. Rough Sets: Mathematical Foundations [Internet]. Physica-Verlag Heidelberg. 2002. [Cited 27 April 2018]. (Advances in Intelligent and Soft Computing). Available online: //www.springer.com/us/book/9783790815108 (accessed on 5 November 2018).
- Skowron, A.; Suraj, Z. Rough Sets and Intelligent Systems—Professor Zdzisław Pawlak in Memoriam; Springer Science & Business Media: Berlin, Germany, 2012; p. 682. [Google Scholar]
- Nguyen, T.-T.; Nguyen, P.-K. Reducing Attributes in Rough Set Theory with the Viewpoint of Mining Frequent Patterns. Int. J. Adv. Comput. Sci. Appl. 2013, 4. [Google Scholar] [CrossRef] [Green Version]
- Pawlak, Z. Rough set theory and its applications. J. Telecommun. Technol. 2002, 3, 7–10. [Google Scholar]
- Dong, S.-H.; Zhou, H.-C.; Xu, H.-J. A Forecast Model of Hydrologic Single Element Medium and Long-Period Based on Rough Set Theory. Water Resour. Manag. 2004, 18, 483–495. [Google Scholar] [CrossRef]
- Pai, P.-F.; Lee, F.-C. A Rough Set Based Model in Water Quality Analysis. Water Resour. Manag. 2010, 24, 2405–2418. [Google Scholar] [CrossRef]
- Shen, Q.; Chouchoulas, A. FuREAP: A Fuzzy–Rough Estimator of Algae Populations. Artif. Intell. Eng. 2001, 15, 13–24. [Google Scholar] [CrossRef]
- Barbagallo, S.; Consoli, S.; Pappalardo, N.; Greco, S.; Zimbone, S.M. Discovering Reservoir Operating Rules by a Rough Set Approach. Water Resour. Manag. 2006, 20, 19–36. [Google Scholar] [CrossRef]
- Predki, B.; Słowiński, R.; Stefanowski, J.; Susmaga, R.; Wilk, S. ROSE—Software Implementation of the Rough Set Theory. In Rough Sets and Current Trends in Computing [Internet]; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 1998; pp. 605–608. [Google Scholar]
- Ip, W.C.; Hu, B.Q.; Wong, H.; Xia, J. Applications of rough set theory to river environment quality evaluation in China. Water Resour. 2007, 34, 459–570. [Google Scholar] [CrossRef]
- Karami, J.; Alimohammadi, A.; Seifouri, T. Water quality analysis using a variable consistency dominance-based rough set approach. Comput. Environ. Urban Syst. 2014, 43, 25–33. [Google Scholar] [CrossRef]
- Pawlak, Z.; Grzymala-Busse, J.; Slowinski, R.; Ziarko, W. Rough Sets. Commun. ACM 1995, 38, 88–95. [Google Scholar] [CrossRef]
- Rissino, S.; Lambert-Torres, G. Rough Set Theory—Fundamental Concepts, Principals, Data Extraction, and Applications. In Data Mining and Knowledge Discovery in Real Life Applications; Ponce, J., Karahoca, A., Eds.; IN-TECH: Hong Kong, China, 2009; pp. 35–58. [Google Scholar]
- Department, V.; Quality, E. Virginia Administrative Code, Title 9. Environment, Agency 25. State Water Control Board, Chapter 260. Water Quality Standards. Available online: https://www.epa.gov/sites/production/files/2014-12/documents/vawqs.pdf (accessed on 5 November 2018).
- Mason MS4 Program|Facilities|George Mason University [Internet]. [Cited 24 October 2018]. Available online: https://facilities.gmu.edu/resources/land-development/ms4/ (accessed on 5 November 2018).
- NWSCIW. National Weather Service Sterling [Internet]. [Cited 27 October 2018]. Available online: https://w2.weather.gov/climate/local_data.php?wfo=lwx (accessed on 5 November 2018).
- Nitrogen and Water: USGS Water Science School [Internet]. [Cited 27 July 2018]. Available online: https://water.usgs.gov/edu/nitrogen.html (accessed on 5 November 2018).
- Copetti, D.; Marziali, L.; Viviano, G.; Valsecchi, L.; Guzzella, L.; Capodaglio, A.G.; Tartari, G.; Polesello, S.; Valsecchi, S.; Mezzanotte, V.; et al. Intensive monitoring of conventional and surrogate quality parameters in a highly urbanized river affected by multiple combined sewer overflows. Water Sci. Technol. Water Suppl. 2018. [Google Scholar] [CrossRef]
- Gholoom, A. Studying the Impact of Different Green Rooftop Designs on Stormwater [Internet] [Thesis]. 2018. [Cited 17 July 2018]. Available online: http://mars.gmu.edu/handle/1920/10916 (accessed on 5 November 2018).
- Dissolved Oxygen, from the USGS Water Science School: All about Water. [Internet]. [Cited 26 July 2018]. Available online: https://water.usgs.gov/edu/dissolvedoxygen.html (accessed on 5 November 2018).



| Dissolved Oxygen | Nitrate Concentration | Specific Conductivity | Temperature | Turbidity | pH | |
|---|---|---|---|---|---|---|
| Symbol | DO | NO3 | K | T | Tu | pH |
| Units | mg/L | mg/L | uS/cm | °C | NTU | - |
| Average | 6.14 | 136 | 342 | 20.7 | 40.9 | 6.75 |
| St. Deviation | 1.23 | 46.4 | 126 | 3.63 | 95.7 | 0.16 |
| 25th Quartile | 5.58 | 128 | 280 | 18.4 | 5.67 | 6.65 |
| 75th Quartile | 6.72 | 158 | 384 | 23.3 | 36 | 6.82 |
| Time Code | Date (M-Y) | DO | NO3 | K | T | Tu | pH |
|---|---|---|---|---|---|---|---|
| 1 | October-15 | M | M | H | L | L | M |
| 2 | April-16 | H | M | H | L | H | M |
| 3 | May-16 | H | M | M | L | H | M |
| 4 | June-16 | M | M | M | M | M | M |
| 5 | July-16 | L | M | M | H | M | M |
| 6 | August-16 | M | H | M | H | M | M |
| 7 | April-17 | M | L | M | L | H | H |
| 8 | May-17 | M | L | M | L | H | H |
| 9 | June-17 | L | L | M | M | H | L |
| 10 | August-17 | L | L | L | H | M | L |
| 11 | September-17 | L | L | M | M | M | L |
| 12 | October-17 | L | L | M | L | H | M |
| 13 | November-17 | L | L | L | L | H | L |
| 14 | December-17 | L | L | L | L | M | L |
| (a) | (b) | ||||||||||||
| Time Code | DO | NO3 | K | T | Tu | pH | Time Code | DO | NO3 | K | T | Tu | pH |
| 1 | M | M | H | L | L | M | 1 | M | H | L | L | M | |
| 2 | H | M | H | L | H | M | 2 | M | H | L | H | M | |
| 3 | H | M | M | L | H | M | 3 | M | M | L | H | M | |
| 4 | M | M | M | M | M | M | 4 | M | M | M | M | M | |
| 5 | L | M | M | H | M | M | 5 | M | M | H | M | M | |
| 6 | M | H | M | H | M | M | 6 | H | M | H | M | M | |
| 7 | M | L | M | L | H | H | 7 | L | M | L | H | H | |
| 8 | M | L | M | L | H | H | 8 | L | M | L | H | H | |
| 9 | L | L | M | M | H | L | 9 | L | M | M | H | L | |
| 10 | L | L | L | H | M | L | 10 | L | L | H | M | L | |
| 11 | L | L | M | M | M | L | 11 | L | M | M | M | L | |
| 12 | L | L | M | L | H | M | 12 | L | M | L | H | M | |
| 13 | L | L | L | L | H | L | 13 | L | L | L | H | L | |
| 14 | L | L | L | L | M | L | 14 | L | L | L | M | L | |
| (c) | (d) | ||||||||||||
| Time Code | DO | NO3 | K | T | Tu | pH | Time Code | DO | NO3 | K | T | Tu | pH |
| 1 | M | H | L | L | M | 1 | M | M | L | L | M | ||
| 2 | H | H | L | H | M | 2 | H | M | L | H | M | ||
| 3 | H | M | L | H | M | 3 | H | M | L | H | M | ||
| 4 | M | M | M | M | M | 4 | M | M | M | M | M | ||
| 5 | L | M | H | M | M | 5 | L | M | H | M | M | ||
| 6 | M | M | H | M | M | 6 | M | H | H | M | M | ||
| 7 | M | M | L | H | H | 7 | M | L | L | H | H | ||
| 8 | M | M | L | H | H | 8 | M | L | L | H | H | ||
| 9 | L | M | M | H | L | 9 | L | L | M | H | L | ||
| 10 | L | L | H | M | L | 10 | L | L | H | M | L | ||
| 11 | L | M | M | M | L | 11 | L | L | M | M | L | ||
| 12 | L | M | L | H | M | 12 | L | L | L | H | M | ||
| 13 | L | L | L | H | L | 13 | L | L | L | H | L | ||
| 14 | L | L | L | M | L | 14 | L | L | L | M | L | ||
| (e) | (f) | ||||||||||||
| Time Code | DO | NO3 | K | T | Tu | pH | Time Code | DO | NO3 | K | T | Tu | pH |
| 1 | M | M | H | L | M | 1 | M | M | H | L | M | ||
| 2 | H | M | H | H | M | 2 | H | M | H | L | M | ||
| 3 | H | M | M | H | M | 3 | H | M | M | L | M | ||
| 4 | M | M | M | M | M | 4 | M | M | M | M | M | ||
| 5 | L | M | M | M | M | 5 | L | M | M | H | M | ||
| 6 | M | H | M | M | M | 6 | M | H | M | H | M | ||
| 7 | M | L | M | H | H | 7 | M | L | M | L | H | ||
| 8 | M | L | M | H | H | 8 | M | L | M | L | H | ||
| 9 | L | L | M | H | L | 9 | L | L | M | M | L | ||
| 10 | L | L | L | M | L | 10 | L | L | L | H | L | ||
| 11 | L | L | M | M | L | 11 | L | L | M | M | L | ||
| 12 | L | L | M | H | M | 12 | L | L | M | L | M | ||
| 13 | L | L | L | H | L | 13 | L | L | L | L | L | ||
| 14 | L | L | L | M | L | 14 | L | L | L | L | L |
| Attribute C | U/Ind(C-{c}) | Pos(c-{c})(D) | Pos(c-{c})(D) = Posc(D)? | Indispensability |
|---|---|---|---|---|
| DO | (1), (2), (3), (4), (5), (6), (7,8), (9), (10), (11), (12), (13), (14) | (1), (2), (3), (4), (5), (6), (7,8), (9), (10), (11), (12), (13), (14) | Y | N |
| NO3 | (1), (2), (3), (4), (5), (6), (7,8), (9), (10), (11), (12), (13), (14) | (1), (2), (3), (4), (5), (6), (7,8), (9), (10), (11), (12), (13), (14) | Y | N |
| K | (1), (2,3), (4), (5), (6), (7,8), (9), (10), (11), (12,13), (14) | (1), (2,3), (4), (5), (6), (7,8), (9), (10), (11), (12), (13), (14) | N | Y |
| T | (1), (2), (3), (4), (5), (6), (7,8), (9), (10), (11), (12), (13), (14) | (1), (2), (3), (4), (5), (6), (7,8), (9), (10), (11), (12), (13), (14) | Y | N |
| Tu | (1), (2), (3), (4), (5), (6), (7,8), (9,11), (10), (12), (13,14) | (1), (2), (3), (4), (5), (6), (7,8), (9,11), (10), (12), (13,14) | N | Y |
| Decision Attribute | Indispensable Attribute 1 (Importance Degree) | Indispensable Attribute 2 (Importance Degree) |
|---|---|---|
| pH | Tu (0.14) | K (0.07) |
| DO | Tu (0.14) | K (0.07) |
| NO3 | Tu (0.14) | K (0.07) |
| T | Tu (0.14) | K (0.07) |
| Tu | K (0.07) | - |
| K | Tu (0.14) | T (0.07) |
| Decision Rule | K | Tu | pH | N | Strength | Certainty | Coverage |
|---|---|---|---|---|---|---|---|
| 1 | H | L | M | 1 | 0.07 | 1 | 0.14 |
| 2 | H | H | M | 1 | 0.07 | 1 | 0.14 |
| 3 | M | H | M | 2 | 0.14 | 0.4 | 0.29 |
| 4 | M | M | M | 3 | 0.21 | 0.75 | 0.43 |
| 5 | M | H | H | 2 | 0.14 | 0.4 | 1.00 |
| 6 | M | H | L | 1 | 0.07 | 0.2 | 0.20 |
| 7 | L | M | L | 2 | 0.14 | 1 | 0.40 |
| 8 | M | M | L | 1 | 0.07 | 0.25 | 0.20 |
| 9 | L | H | L | 1 | 0.07 | 1 | 0.20 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zavareh, M.; Maggioni, V. Application of Rough Set Theory to Water Quality Analysis: A Case Study. Data 2018, 3, 50. https://doi.org/10.3390/data3040050
Zavareh M, Maggioni V. Application of Rough Set Theory to Water Quality Analysis: A Case Study. Data. 2018; 3(4):50. https://doi.org/10.3390/data3040050
Chicago/Turabian StyleZavareh, Maryam, and Viviana Maggioni. 2018. "Application of Rough Set Theory to Water Quality Analysis: A Case Study" Data 3, no. 4: 50. https://doi.org/10.3390/data3040050
APA StyleZavareh, M., & Maggioni, V. (2018). Application of Rough Set Theory to Water Quality Analysis: A Case Study. Data, 3(4), 50. https://doi.org/10.3390/data3040050