Urban Mobility Demand Profiles: Time Series for Cars and Bike-Sharing Use as a Resource for Transport and Energy Modeling



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
2.1. Vehicles Profiles
2.1.1. Raw Data
2.1.2. Data Processing
2.1.3. Output Data
- Starting time
- n: number of accurate sensors on which the statistics are based
- mean, standard deviation and median value for the vehicles flow
- mean, standard deviation and median value for the vehicles speed
2.2. Bike Sharing Profiles
2.2.1. Raw Data
2.2.2. Data Processing
2.2.3. Output Data
3. Results
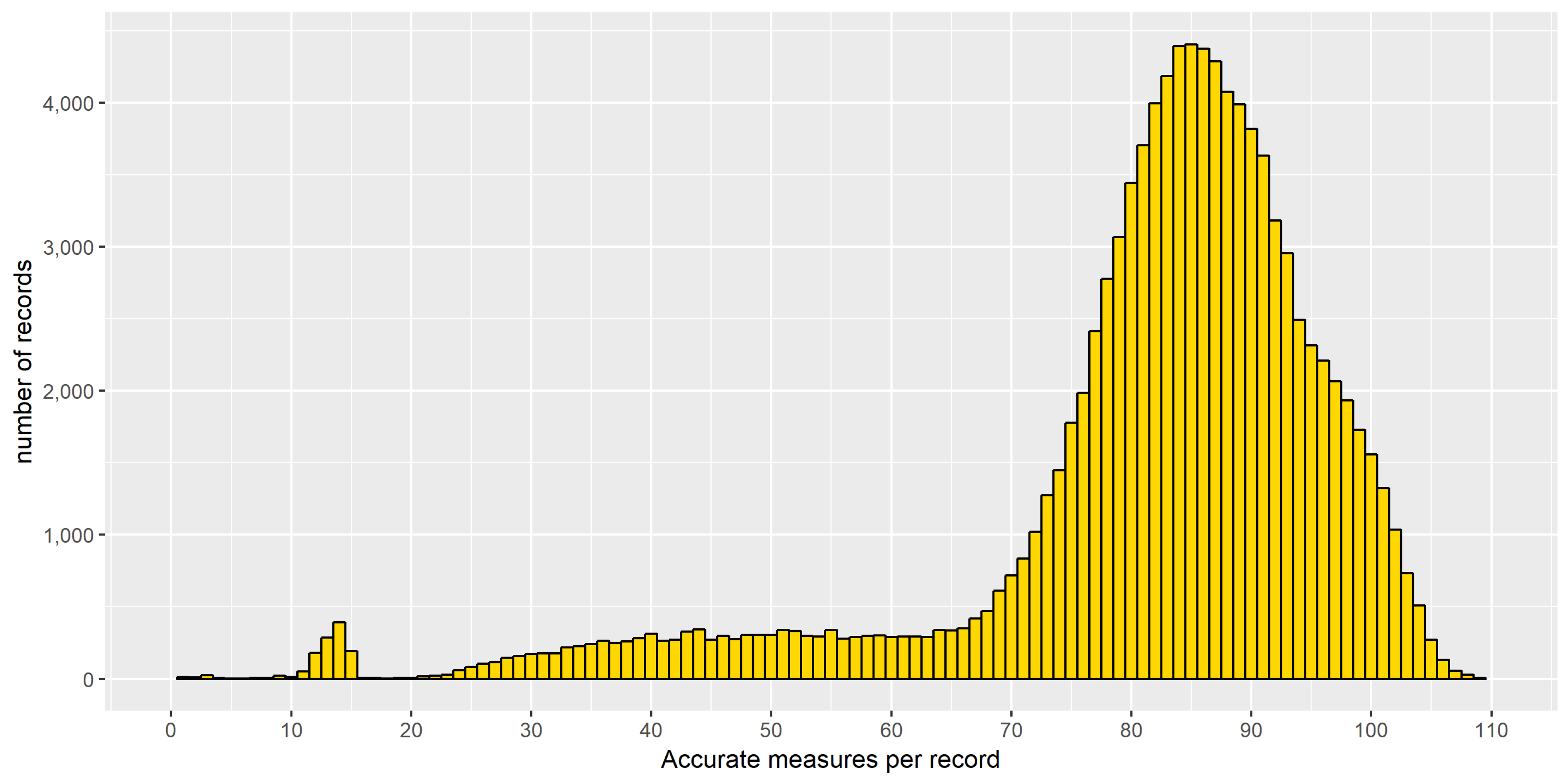
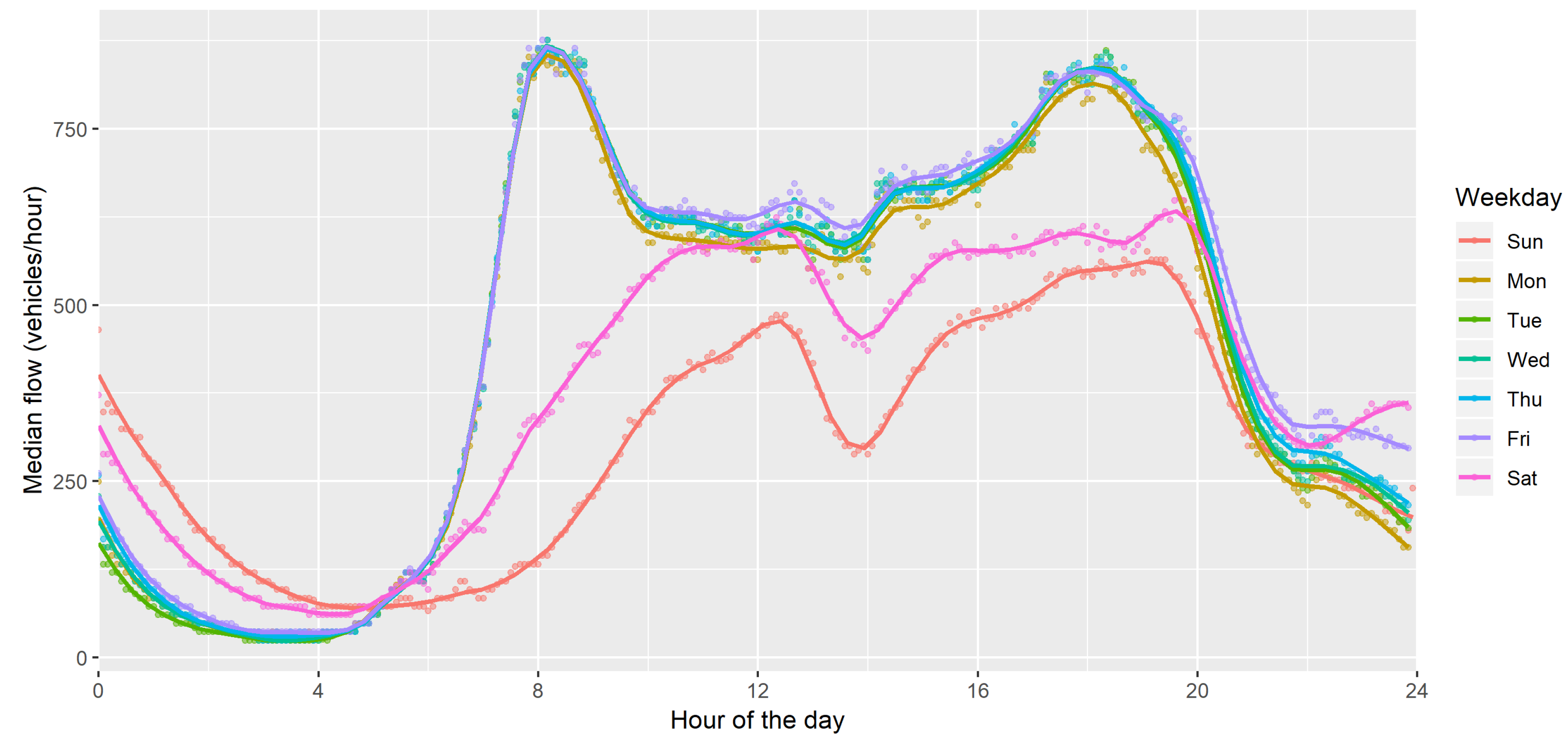
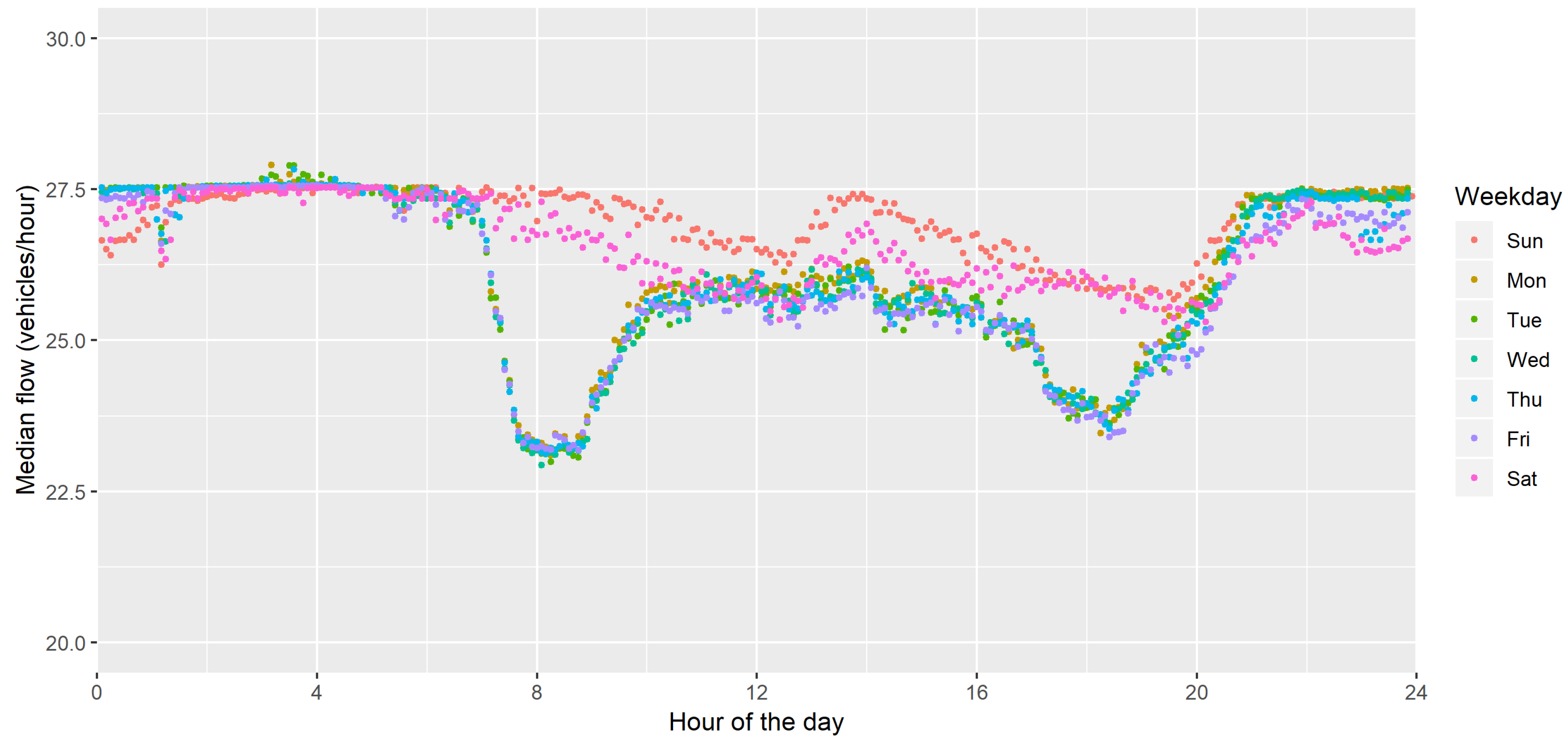
3.1. Road Traffic
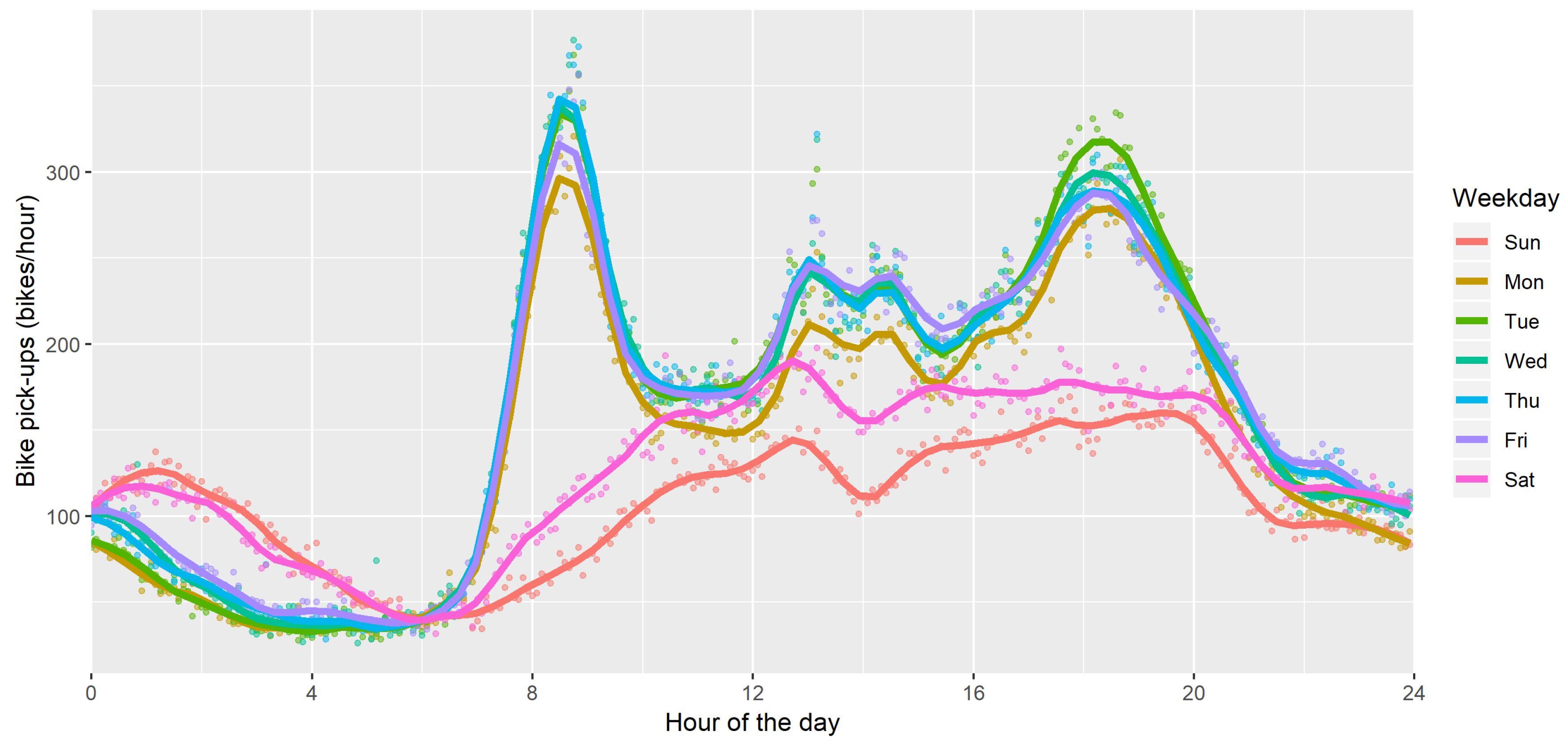
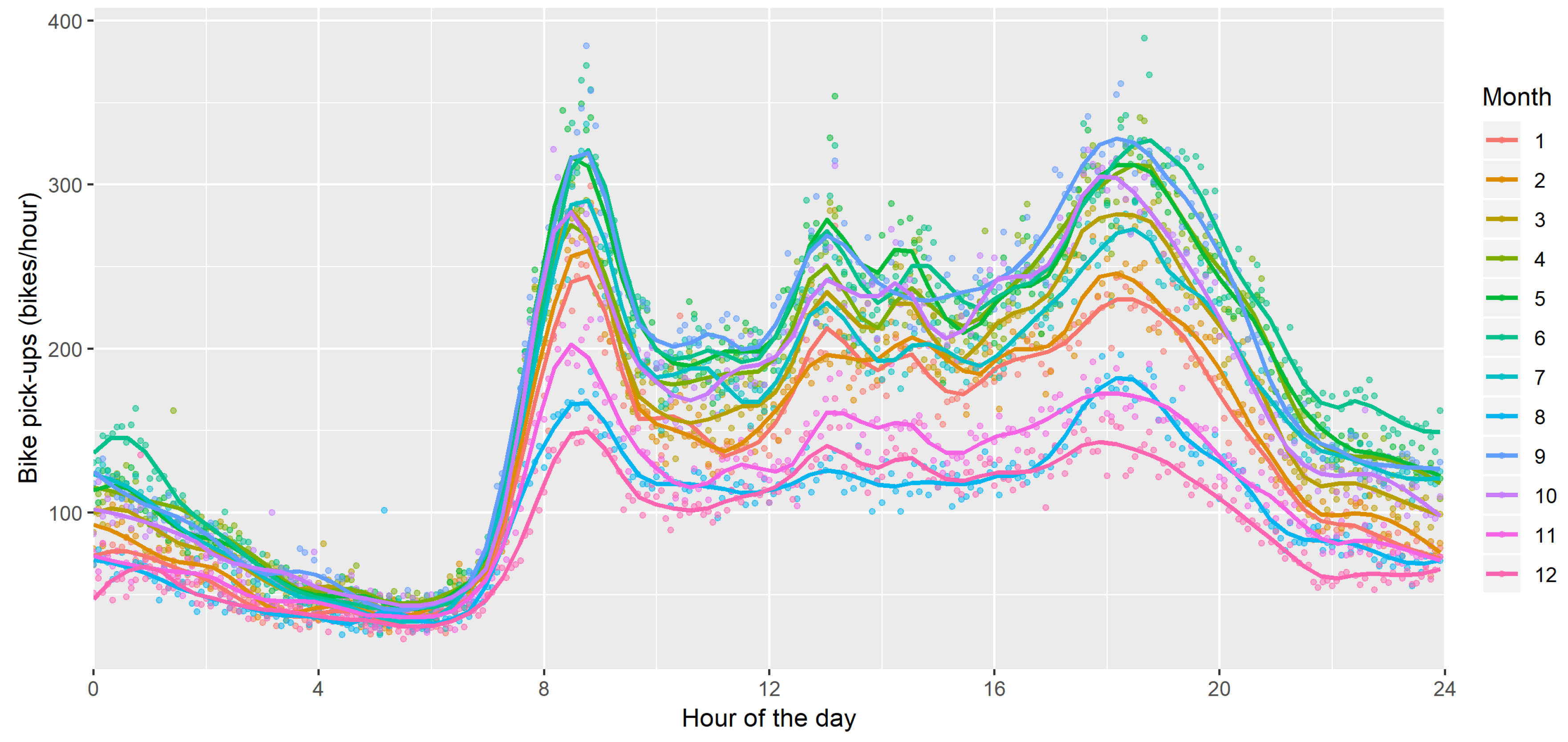
3.2. Bike Sharing
3.3. Potential Applications
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- International Energy Agency. World Energy Outlook 2017. Available online: https://www.iea.org (accessed on 15 June 2019).
- International Transport Forum. ITF Transport Outlook 2017. Available online: https://www.itf-oecd.org (accessed on 15 June 2019).
- Gota, S.; Huizenga, C.; Peet, K.; Medimorec, N.; Bakker, S. Decarbonising transport to achieve Paris Agreement targets. Energy Effic. 2019, 12, 363–386. [Google Scholar] [CrossRef]
- Veryard, D.; Perkins, S.; Aguilar-Jaber, A.; Samsonova, T. Integrating Urban Public Transport Systems and Cycling; ITF/OECD: Paris, France, 2017. [Google Scholar]
- Lazarus, J.; Shaheen, S.; Young, S.E.; Fagnant, D.; Voege, T.; Baumgardner, W.; Fishelson, J.; Lott, J.S. Shared Automated Mobility and Public Transport; Springer International Publishing: Basel, Switzerland, 2018; pp. 142–160. [Google Scholar]
- Erhardt, G.D.; Roy, S.; Cooper, D.; Sana, B.; Chen, M.; Castiglione, J. Do transportation network companies decrease or increase congestion? Sci. Adv. 2019, 5, eaau2670. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Noussan, M. Effects of the Digital Transition in Passenger Transport—An Analysis of Energy Consumption Scenarios in Europe. FEEM Work. Pap. 2019, 2019-01. [Google Scholar] [CrossRef]
- Kay, W.A.; Andreas, H.; Kai, N. The Multi-Agent Transport Simulation MATSim; Ubiquity Press: London, UK, 2016. [Google Scholar]
- Luis Miguel Martinez, J.M.V. Assessing the impacts of deploying a shared self-driving urban mobility system: An agent-based model applied to the city of Lisbon, Portugal. Int. J. Transp. Technol. 2017, 6, 13–27. [Google Scholar] [CrossRef]
- Haasz, T.; Vilchez, J.J.G.; Kunze, R.; Deane, P.; Fraboulet, D.; Fahl, U.; Mulholland, E. Perspectives on decarbonizing the transport sector in the EU-28. Energy Strategy Rev. 2018, 20, 124–132. [Google Scholar] [CrossRef]
- International Energy Agency. World Energy Outlook 2018. Available online: https://www.iea.org (accessed on 15 June 2019).
- Salvucci, R.; Tattini, J.; Gargiulo, M.; Lehtila, A.; Karlsson, K. Modelling transport modal shift in TIMES models through elasticities of substitutions. Appl. Energy 2018, 232, 740–751. [Google Scholar] [CrossRef]
- Tattini, J.; Gargiulo, M.; Karlsson, K. Reaching carbon neutral transport sector in Denmark—Evidence from the incorporation of modal shift into the TIMES energy system modeling framework. Energy Policy 2018, 113, 571–583. [Google Scholar] [CrossRef]
- Lazarus, J.; Shaheen, S.; Young, S.E.; Fagnant, D.; Voege, T.; Baumgardner, W.; Fishelson, J.; Lott, J.S. Detailed assessment of global transport-energy models’ structures and projections. Transp. Res. Part D 2016, 55, 294–309. [Google Scholar] [CrossRef]
- Andersen, F.M.; Larsen, H.V.; Boomsmab, T.K. Long-term forecasting of hourly electricity load: Identification of consumption profiles and segmentation of customers. Energy Convers. Manag. 2013, 68, 244–252. [Google Scholar] [CrossRef]
- Zhang, F.; Wu, L.; Zhu, D.; Liu, Y. Social sensing from street-level imagery: A case study in learning spatio-temporal urban mobility patterns. ISPRS J. Photogramm. Remote. Sens. 2019, 153, 48–58. [Google Scholar] [CrossRef]
- Jelica, D.; Taljegard, M.; Thorson, L.; Johnsson, F. Hourly electricity demand from an electric road system—A Swedish case study. Appl. Energy 2018, 228, 141–148. [Google Scholar] [CrossRef]
- Sekuła, P.; Marković, N.; Laan, Z.V.; Sadabadi, K.F. Estimating Historical Hourly Trac Volumes via Machine Learning and Vehicle Probe Data: A Maryland Case Study. arXiv, 2017; arXiv:1711.00721. [Google Scholar]
- Regional Integrated Transportation Information System (RITIS). 2016. Available online: www.cattlab.umd.edu/?portfolio=ritis (accessed on 10 June 2019).
- The Study on Integrated Urban Transportation Master Plan for Istanbul Metropolitan Area in the Republic of Turkey. 2006. Available online: http://openjicareport.jica.go.jp/pdf/1196572003.pdf (accessed on 10 June 2019).
- Oppermann, M.; Möller, T.; Sedlmair, M. Bike Sharing Atlas: Visual Analysis of Bike-Sharing Networks. Int. J. Transp. 2018, 6, 1–14. [Google Scholar] [CrossRef]
- Levy, N.; Golani, C.; Ben-Elia, E. An exploratory study of spatial patterns of cycling in Tel Aviv using passively generated bike-sharing data. J. Transp. Geogr. 2019, 76, 325–334. [Google Scholar] [CrossRef]
- Kou, Z.; Cai, H. Understanding bike sharing travel patterns: An analysis of trip data from eight cities. Phys. A 2019, 515, 785–797. [Google Scholar] [CrossRef]
- Ashqar, H.I.; Elhenawy, M.; Rakha, H.A. Modeling bike counts in a bike-sharing system considering the effect of weather conditions. Case Stud. Transp. Policy 2019, 7, 261–268. [Google Scholar] [CrossRef]
- McKenzie, G. Spatiotemporal comparative analysis of scooter-share and bike-share usage patterns in Washington, D.C. J. Transp. Geogr. 2019, 78, 19–28. [Google Scholar] [CrossRef]
- Jestico, B.; Nelson, T.; Winters, M. Mapping ridership using crowdsourced cycling data. J. Transp. Geogr. 2016, 52, 90–97. [Google Scholar] [CrossRef] [Green Version]
- Safety through Disruption (Safe-D) National University Transportation Center. Vehicle Operating Speed on Urban Arterial Roadways. 2019. Available online: www.cattlab.umd.edu/?portfolio=ritis (accessed on 10 June 2019).
- SANDAG. San Diego Regional Bike and Pedestrian Counters. 2019. Available online: http://www.eco-public.com/ParcPublic/?id=681 (accessed on 10 June 2019).
- CENSIS-ANIASA. L’Evoluzione Della Mobilità degli Italiani—Dallo Scenario Attuale al 2020–2030. Technical Report. 2015. (In Italian). Available online: https://www.aniasa.it/aniasa/aniasa-informa/public/pubblicazioni/2081 (accessed on 10 June 2019).
- 5T. Opendata 5T. 2019. Available online: http://opendata.5t.torino.it/getunderlinetag|fdt (accessed on 10 June 2019).
- Solez, I.P. Study on Specific Supply Chains in Professional Urban Freight Transport and Delivery Services. 2007. Available online: https://www.interreg-central.eu/Content.Node/SOLEZ/DT221-Study-on-urban-freight-transport.pdf (accessed on 10 June 2019).
- Italian Open Data Licence. 2019. Available online: https://www.dati.gov.it/content/italian-open-data-license-v20 (accessed on 10 June 2019).
- TObike. TObike Website—Stations. 2019. Available online: http://www.tobike.it/frmLeStazioni.aspx (accessed on 10 June 2019).
- Agenzia della Mobilità Piemontese. Approfondimento sull’uso della Bicicletta e del Servizio di Bikesharing a Torino; Technical Report; AMP: Turin, Italy, 2016. (In Italian) [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Wickham, H. Tidyverse: Easily Install and Load the ’Tidyverse’, R Package Version 1.2.1; 2017. Available online: https://tidyverse.tidyverse.org/ (accessed on 10 June 2019).






© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Noussan, M.; Carioni, G.; Sanvito, F.D.; Colombo, E. Urban Mobility Demand Profiles: Time Series for Cars and Bike-Sharing Use as a Resource for Transport and Energy Modeling. Data 2019, 4, 108. https://doi.org/10.3390/data4030108
Noussan M, Carioni G, Sanvito FD, Colombo E. Urban Mobility Demand Profiles: Time Series for Cars and Bike-Sharing Use as a Resource for Transport and Energy Modeling. Data. 2019; 4(3):108. https://doi.org/10.3390/data4030108
Chicago/Turabian StyleNoussan, Michel, Giovanni Carioni, Francesco Davide Sanvito, and Emanuela Colombo. 2019. "Urban Mobility Demand Profiles: Time Series for Cars and Bike-Sharing Use as a Resource for Transport and Energy Modeling" Data 4, no. 3: 108. https://doi.org/10.3390/data4030108
APA StyleNoussan, M., Carioni, G., Sanvito, F. D., & Colombo, E. (2019). Urban Mobility Demand Profiles: Time Series for Cars and Bike-Sharing Use as a Resource for Transport and Energy Modeling. Data, 4(3), 108. https://doi.org/10.3390/data4030108