The Fundamental Clustering and Projection Suite (FCPS): A Dataset Collection to Test the Performance of Clustering and Data Projection Algorithms



Abstract
:1. Summary
2. Data Description
2.1. General Properties of the FCPS Datasets
2.2. Description of the Single Datasets
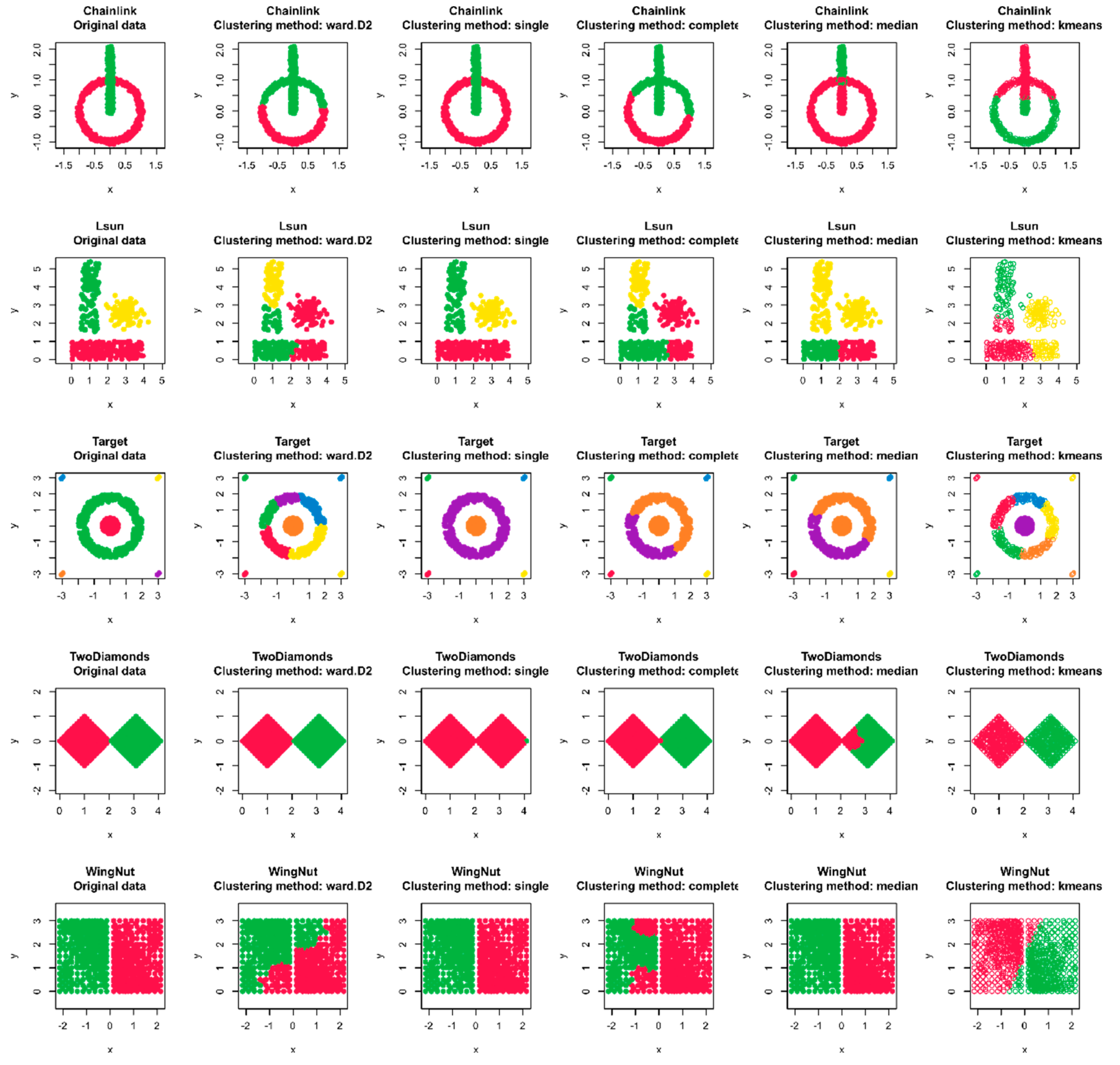
2.2.1. Chainlink
2.2.2. GolfBall
2.2.3. Lsun
2.2.4. Atom
2.2.5. EngyTime
2.2.6. Hepta
2.2.7. Target
2.2.8. Tetra
2.2.9. TwoDiamonds
2.2.10. WingNut
3. Clustering and Data Projection
3.1. Performance of Different Clusteriung Algorithms
3.2. Performance of Different Data Projection Methods
4. Methods
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Wilcox, R.H. Adaptive control processes—a guided tour, by Richard Bellman, Princeton University Press, Princeton, New Jersey, 1961, 255 pp., $6.50. Naval Res. Logist. Q. 1961, 8, 315–316. [Google Scholar] [CrossRef]
- Peters, M.H. On the shrinking volume of the hypersphere. College Math. J. 2015, 46, 178–180. [Google Scholar] [CrossRef]
- Ultsch, A.; Lötsch, J. Machine-learned cluster identification in high-dimensional data. J. Biomed. Inform. 2017, 66, 95–104. [Google Scholar] [CrossRef] [PubMed]
- Ultsch, A. U*c: Self-Organized Clustering with Emergent Feature Maps. In Proceedings of the Lernen, Wissensentdeckung und Adaptivität (LWA) 2005, GI Workshops, Saarbrücken, Germany, 10–12 October 2005; pp. 240–244. [Google Scholar]
- Lötsch, J.; Ultsch, A. Current projection methods-induced biases at subgroup detection for machine-learning based data-analysis of biomedical data. Int. J. Mol. Sci. 2019, 21, 79. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Freund, Y.; Schapire, R.E. Large margin classification using the perceptron algorithm. Machine Learn. 1999, 37, 277–296. [Google Scholar] [CrossRef]
- Baggenstoss, P.M. Statistical Modeling Using Gaussian Mixtures and HMMs with MATLAB; Technical Report; Naval Undersea Warfare Center: Newport, RI, USA, 2002. [Google Scholar]
- Maechler, M.; Rousseeuw, P.; Struyf, A.; Hubert, M.; Hornik, K. Cluster: Cluster analysis basics and extensions R package version 2.0. 1. 2015. 2017. [Google Scholar]
- R Development Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018; Available online: https://www.R-project.org/ (accessed on 26 December 2019).
- Le, S.; Josse, J.; Husson, F.c. Factominer: A package for multivariate analysis. J. Stat. Softw. 2008, 25, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Krijthe, J.H. Rtsne: T-distributed stochastic neighbor embedding using barnes-hut implementation. 2015. Available online: https://github.com/jkrijthe/Rtsne (accessed on 26 December 2019).
- Lammers, B. Ann2: Artificial neural networks for anomaly detection. 2019. Available online: https://rdrr.io/cran/ANN2/ (accessed on 26 December 2019).
- Ward Jr, J.H. Hierarchical grouping to optimize an objective function. J. Am. Stat. Assoc. 1963, 58, 236–244. [Google Scholar] [CrossRef]
- Gower, J.C. A comparison of some methods of cluster analysis. Biometrics 1967, 23, 623–637. [Google Scholar] [CrossRef] [PubMed]
- Pearson, K. LIII. On lines and planes of closest fit to systems of points in space. London, Edinburgh&Dublin Philosoph. Mag. J. Sci. 1901, 2, 559–572. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Van der Maaten, L. Accelerating t-SNE using tree-based algorithms. J. Machine Learn. Res. 2014, 15, 3221–3245. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Name | Cases | Dimensions | Classes |
|---|---|---|---|
| Atom | 800 | 3 | 2 |
| Chainlink | 1000 | 3 | 2 |
| EngyTime | 4096 | 2 | 2 |
| GolfBall | 4002 | 3 | 1 |
| Hepta | 212 | 3 | 7 |
| Lsun | 400 | 2 | 3 |
| Target | 770 | 2 | 6 |
| Tetra | 400 | 3 | 4 |
| TwoDiamonds | 800 | 2 | 2 |
| WingNut | 1016 | 2 | 2 |
| Name | Hyperplane-Separable | Changing Variances | Typical Inner Class Distance1 | Typical Interclass Distance2 | Inter/Inner Ratio |
|---|---|---|---|---|---|
| Atom | 1 | 2.82 | 41.49 | 14.71 | |
| Chainlink | 0.08 | 0.98 | 11.59 | ||
| EngyTime | 1 | 2.70 | 2.70 | 1.00 | |
| GolfBall | 1.41 | 1.41 | 1.00 | ||
| Hepta | 1 | 1 | 0.58 | 3.07 | 5.32 |
| Lsun | 1 | 1 | 0.17 | 0.87 | 5.21 |
| Target | 1 | 0.07 | 2.19 | 30.23 | |
| Tetra | 1 | 0.45 | 1.01 | 2.26 | |
| TwoDiamonds | 1 | 0.08 | 1.09 | 13.34 | |
| WingNut | 1 | 0.11 | 0.34 | 3.06 |
| Name | Key Problems |
|---|---|
| Atom | Linearly not separable, different inner class distances |
| Chainlink | Linear not separable |
| EngyTime | Density defined classes |
| GolfBall | No cluster structure |
| Hepta | Different inner class variances |
| Lsun | None |
| Target | Outlier |
| Tetra | Small inter class distances |
| TwoDiamonds | Touching classes |
| WingNut | Density variation within class |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ultsch, A.; Lötsch, J. The Fundamental Clustering and Projection Suite (FCPS): A Dataset Collection to Test the Performance of Clustering and Data Projection Algorithms. Data 2020, 5, 13. https://doi.org/10.3390/data5010013
Ultsch A, Lötsch J. The Fundamental Clustering and Projection Suite (FCPS): A Dataset Collection to Test the Performance of Clustering and Data Projection Algorithms. Data. 2020; 5(1):13. https://doi.org/10.3390/data5010013
Chicago/Turabian StyleUltsch, Alfred, and Jörn Lötsch. 2020. "The Fundamental Clustering and Projection Suite (FCPS): A Dataset Collection to Test the Performance of Clustering and Data Projection Algorithms" Data 5, no. 1: 13. https://doi.org/10.3390/data5010013
APA StyleUltsch, A., & Lötsch, J. (2020). The Fundamental Clustering and Projection Suite (FCPS): A Dataset Collection to Test the Performance of Clustering and Data Projection Algorithms. Data, 5(1), 13. https://doi.org/10.3390/data5010013