Extraction of Missing Tendency Using Decision Tree Learning in Business Process Event Log


Abstract
:1. Introduction
2. Background Knowledge
2.1. Event Logs
2.2. Data Quality
- (1) Missing Data:
- This corresponds to the situation where data that should be recorded is missing. For example, events and attributes in the log and their relationships are lost. Missing values are caused by problems with the logging system or human error.
- (2) Incorrect Data:
- This corresponds to the situation where the log is different from what should be recorded. For example, the entity or value recorded in the log are incorrect.
- (3) Imprecise Data:
- This corresponds to the case where the recorded data is coarse. If such data were recorded, we would not be able to perform the analysis that requires more accurate data. For example, if the timestamp unit is days, it is difficult to analyze in hours or minutes.
- (4) Irrelevant Data:
- This is when more data are recorded that are not of current interest than are needed. Filtering irrelevant data is difficult and is an important issue in process mining.
3. Proposed Method
3.1. Vectorization of Traces with Missing Activity
| Algorithm 1 Generation of feature set focusing on missing values |
|
3.2. Construction and Interpretation of Decision Trees
4. Evaluation
4.1. Details of the Experiment
- pattern 1:
- The activity immediately before or after the activity with an ID of 0 is deleted and the missing values are generated.
- pattern 2:
- When an activity with an activity ID of 0 or 2 occurs during a trace, the next activity is deleted and a missing value is generated.
- pattern 3:
- When an activity with IDs 5, 6, 7, 9, and 10 is performed during a trace, it generates a random number from 0 to 100. If the generated random number is greater than 40, the activity of IDs 5, 6, 7, 9 and 10 are deleted and the missing value is generated.
4.2. Results
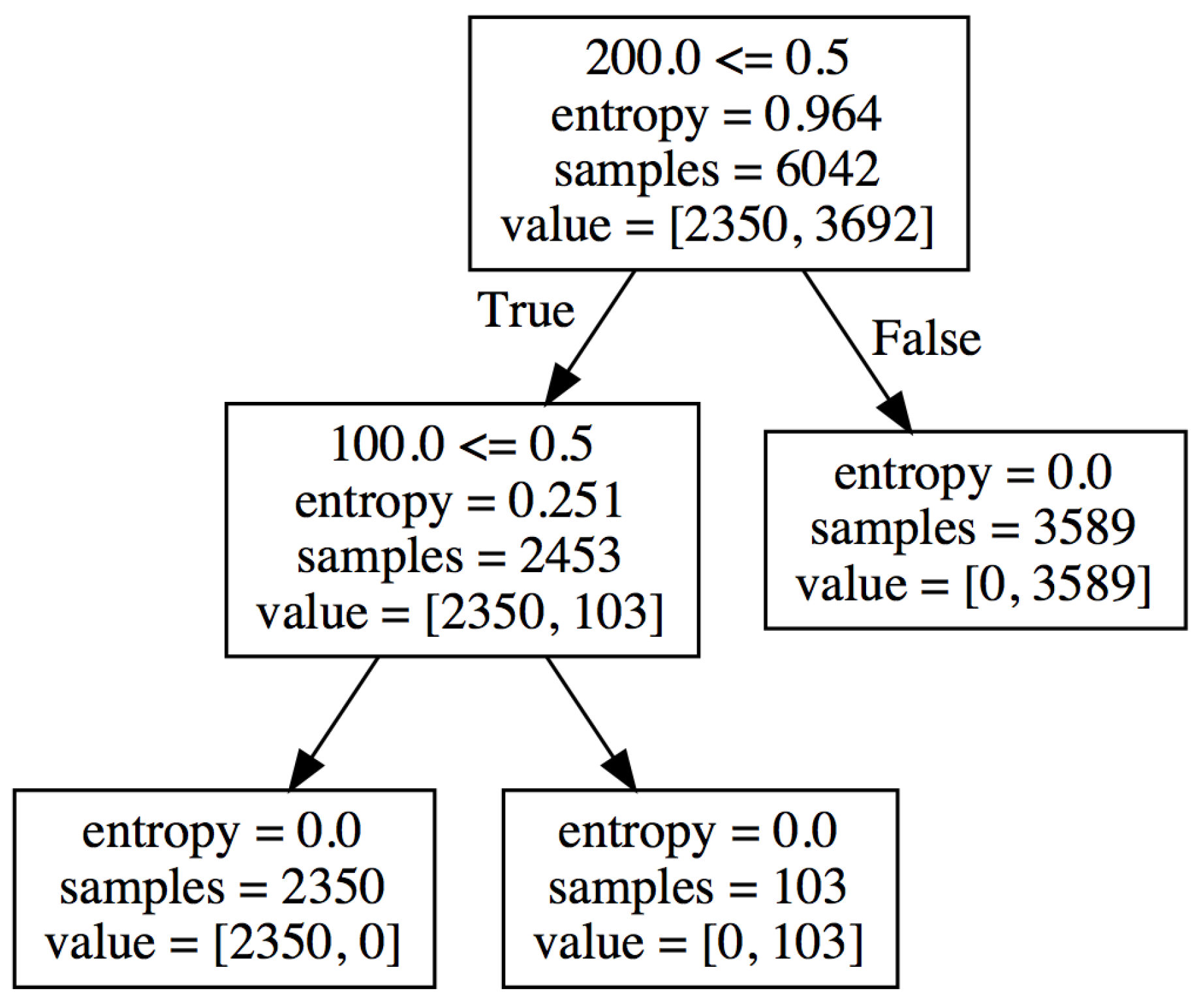
4.2.1. Result of Pattern 1
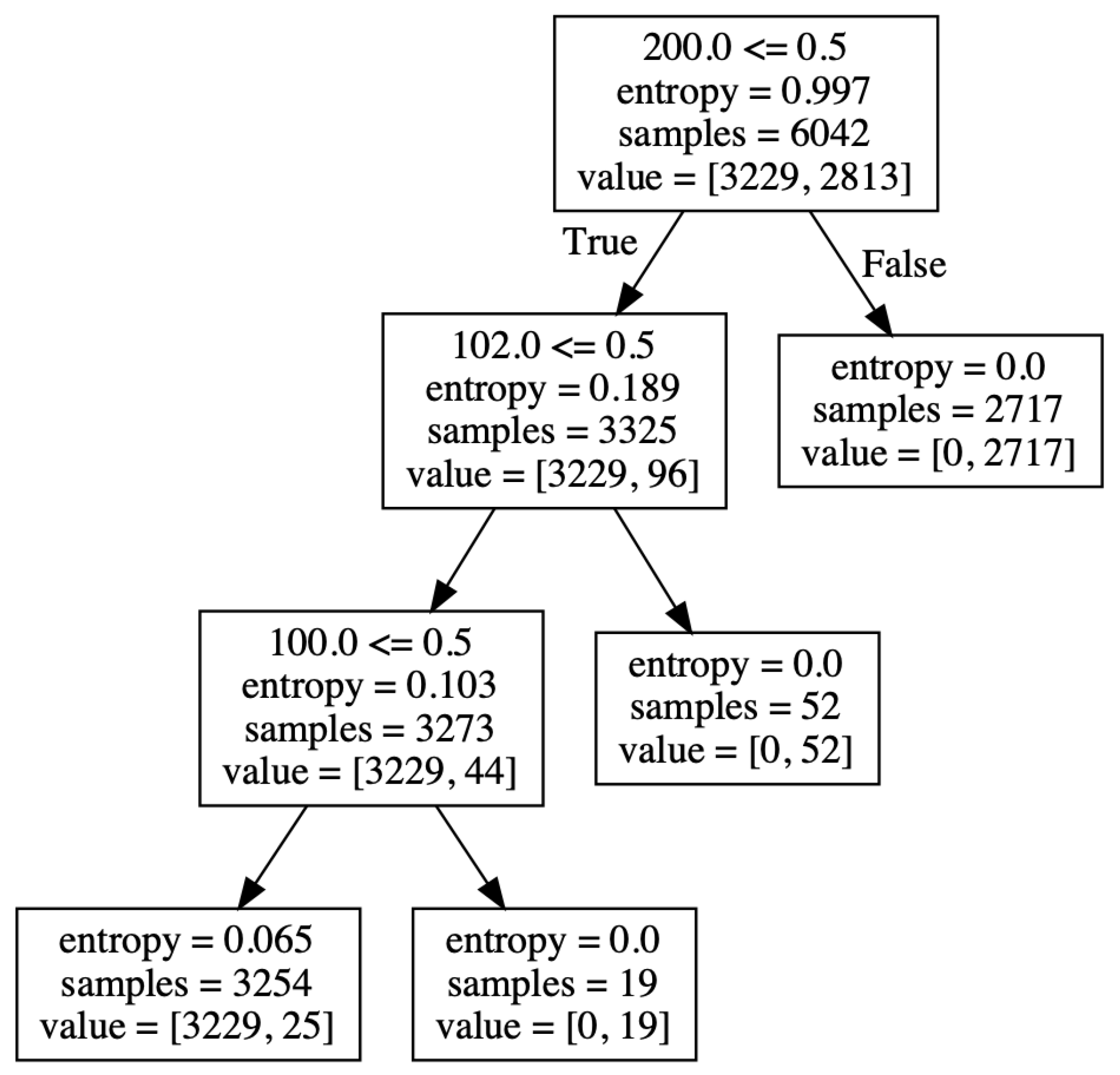
4.2.2. Result of Pattern 2
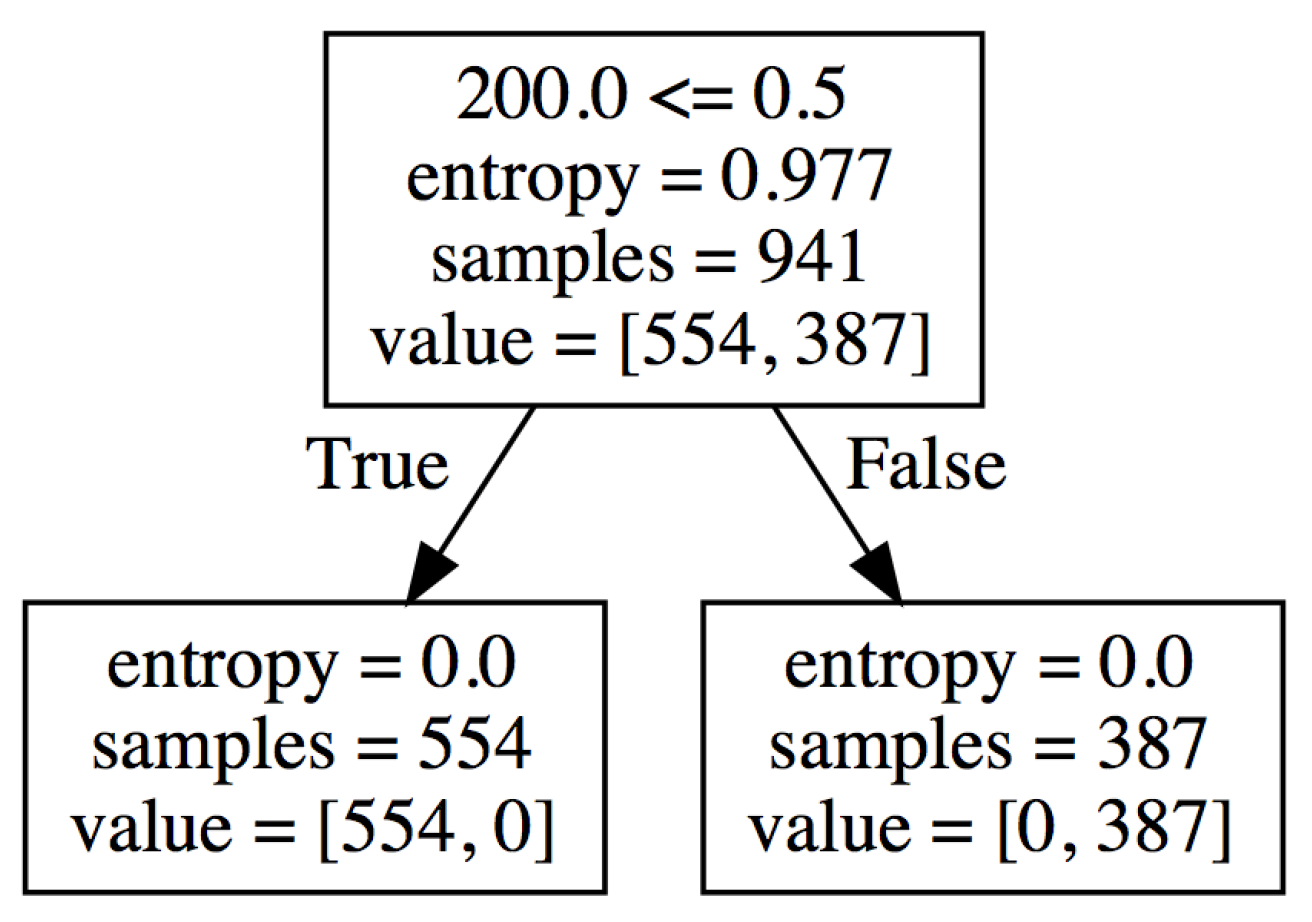
4.2.3. Result of Pattern 3
4.2.4. Summary and Discussion of the Results
5. Related Works
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Van der Aalst, W.M.P. Process Mining—Data Science in Action, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar] [CrossRef]
- Van Eck, M.L.; Lu, X.; Leemans, S.J.; van der Aalst, W.M. PM2: A Process Mining Project Methodology. In Proceedings of the International Conference on Advanced Information Systems Engineering, Stockholm, Sweden, 8–12 June 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 297–313. [Google Scholar]
- Wang, J.; Song, S.; Zhu, X.; Lin, X. Efficient recovery of missing events. Proc. VLDB Endow. 2013, 6, 841–852. [Google Scholar] [CrossRef] [Green Version]
- Bose, R.J.C.; Mans, R.S.; van der Aalst, W.M. Wanna improve process mining results? In Proceedings of the 2013 IEEE Symposium on Computational Intelligence and Data Mining (CIDM), Singapore, 16–19 April 2013; pp. 127–134. [Google Scholar]
- Mans, R.S.; van der Aalst, W.M.; Vanwersch, R.J.; Moleman, A.J. Process mining in healthcare: Data challenges when answering frequently posed questions. In Process Support and Knowledge Representation in Health Care; Springer: Berlin/Heidelberg, Germany, 2012; pp. 140–153. [Google Scholar]
- Song, W.; Jacobsen, H.A. Static and dynamic process change. IEEE Trans. Serv. Comput. 2016, 11, 215–231. [Google Scholar] [CrossRef]
- Wynn, M.T.; Sadiq, S. Responsible process mining-A data quality perspective. In Proceedings of the International Conference on Business Process Management, Vienna, Austria, 1–6 September 2019; Springer: Cham, Switzerland, 2019; pp. 10–15. [Google Scholar]
- Batini, C.; Cappiello, C.; Francalanci, C.; Maurino, A. Methodologies for data quality assessment and improvement. ACM Comput. Surv. (CSUR) 2009, 41, 1–52. [Google Scholar] [CrossRef] [Green Version]
- Cai, L.; Zhu, Y. The challenges of data quality and data quality assessment in the big data era. Data Sci. J. 2015, 14. [Google Scholar] [CrossRef]
- Sim, S.; Bae, H.; Choi, Y. Likelihood-based Multiple Imputation by Event Chain Methodology for Repair of Imperfect Event Logs with Missing Data. In Proceedings of the 2019 International Conference on Process Mining (ICPM), Aachen, Germany, 24–26 June 2019; pp. 9–16. [Google Scholar]
- Conforti, R.; La Rosa, M.; ter Hofstede, A. Timestamp Repair for Business Process Event Logs; University of Melbourne: Melbourne, Australia, 2018. [Google Scholar]
- Emamjome, F.; Andrews, R.; ter Hofstede, A.H. A case study lens on process mining in practice. In Proceedings of the OTM Confederated International Conferences “On the Move to Meaningful Internet Systems”, Rhodes, Greece, 21–25 October 2019; Springer: Cham, Switzerland, 2019; pp. 127–145. [Google Scholar]
- Emamjome, F.; Andrews, R.; ter Hofstede, A.H.; Reijers, H.A. Alohomora: Unlocking Data Quality Causes Through Event Log Context. In Proceedings of the 28th European Conference on Information Systems (ECIS), Marrakech, Morocco, 15–17 June 2020. [Google Scholar]
- Van Der Aalst, W.; Adriansyah, A.; De Medeiros, A.K.A.; Arcieri, F.; Baier, T.; Blickle, T.; Bose, J.C.; Van Den Brand, P.; Brandtjen, R.; Buijs, J.; et al. Process mining manifesto. In Proceedings of the International Conference on Business Process Management, Clermont-Ferrand, France, 29 August–2 September 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 169–194. [Google Scholar]
- Batini, C.; Scannapieco, M. Data and Information Quality; Springer International Publishing: Cham, Switzerland, 2016; p. 43. [Google Scholar]
- Xu, J.; Liu, J. A Profile Clustering Based Event Logs Repairing Approach for Process Mining. IEEE Access 2019, 7, 17872–17881. [Google Scholar] [CrossRef]
- Teinemaa, I.; Dumas, M.; Rosa, M.L.; Maggi, F.M. Outcome-oriented predictive process monitoring: Review and benchmark. ACM Trans. Knowl. Discov. Data 2019, 13, 1–57. [Google Scholar] [CrossRef]
- Loh, W.Y. Classification and regression trees. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2011, 1, 14–23. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Song, W.; Jacobsen, H.A.; Zhang, P. Self-Healing Event Logs. IEEE Trans. Knowl. Data Eng. 2019. [Google Scholar] [CrossRef]
- Nguyen, H.T.C.; Lee, S.; Kim, J.; Ko, J.; Comuzzi, M. Autoencoders for improving quality of process event logs. Expert Syst. Appl. 2019, 131, 132–147. [Google Scholar] [CrossRef]
- Sani, M.F.; van Zelst, S.J.; van der Aalst, W.M. Repairing Outlier Behaviour in Event Logs using Contextual Behaviour. Enterp. Model. Inf. Syst. Archit. 2019, 14, 1–24. [Google Scholar]
- Cheng, H.J.; Kumar, A. Process mining on noisy logs—Can log sanitization help to improve performance? Decis. Support Syst. 2015, 79, 138–149. [Google Scholar] [CrossRef]
- Kong, L.; Li, C.; Ge, J.; Li, Z.; Zhang, F.; Luo, B. An Efficient Heuristic Method for Repairing Event Logs Independent of Process Models. In Proceedings of the 4th International Conference on Internet of Things, Big Data and Security, Heraklion, Greece, 2–4 May 2019. [Google Scholar]
- Dixit, P.M.; Suriadi, S.; Andrews, R.; Wynn, M.T.; ter Hofstede, A.H.; Buijs, J.C.; van der Aalst, W.M. Detection and interactive repair of event ordering imperfection in process logs. In Proceedings of the International Conference on Advanced Information Systems Engineering, Tallinn, Estonia, 11–15 June 2018; Springer: Cham, Switzerland, 2018; pp. 274–290. [Google Scholar]
- Suriadi, S.; Andrews, R.; ter Hofstede, A.H.; Wynn, M.T. Event log imperfection patterns for process mining: Towards a systematic approach to cleaning event logs. Inf. Syst. 2017, 64, 132–150. [Google Scholar] [CrossRef]
- Song, W.; Xia, X.; Jacobsen, H.A.; Zhang, P.; Hu, H. Heuristic recovery of missing events in process logs. In Proceedings of the 2015 IEEE International Conference on Web Services, New York, NY, USA, 27 June–2 July 2015; pp. 105–112. [Google Scholar]
- Rogge-Solti, A.; Mans, R.S.; van der Aalst, W.M.; Weske, M. Improving documentation by repairing event logs. In Proceedings of the IFIP Working Conference on The Practice of Enterprise Modeling, Riga, Latvia, 6–7 November 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 129–144. [Google Scholar]
- Song, S.; Cao, Y.; Wang, J. Cleaning timestamps with temporal constraints. Proc. VLDB Endow. 2016, 9, 708–719. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Song, S.; Lin, X.; Zhu, X.; Pei, J. Cleaning structured event logs: A graph repair approach. In Proceedings of the 2015 IEEE 31st International Conference on Data Engineering, Seoul, Korea, 13–17 April 2015; pp. 30–41. [Google Scholar]
- Ly, L.T.; Indiono, C.; Mangler, J.; Rinderle-Ma, S. Data transformation and semantic log purging for process mining. In Proceedings of the International Conference on Advanced Information Systems Engineering, Gdansk, Poland, 25–29 June 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 238–253. [Google Scholar]
- Corizzo, R.; Ceci, M.; Japkowicz, N. Anomaly detection and repair for accurate predictions in geo-distributed big data. Big Data Res. 2019, 16, 18–35. [Google Scholar] [CrossRef]
- Sefidian, A.M.; Daneshpour, N. Estimating missing data using novel correlation maximization based methods. Appl. Soft Comput. 2020, 91, 106249. [Google Scholar] [CrossRef]
- Rekatsinas, T.; Chu, X.; Ilyas, I.F.; Ré, C. HoloClean: Holistic Data Repairs with Probabilistic Inference. Proc. VLDB Endow. 2017, 10, 1190–1201. [Google Scholar] [CrossRef]
- Yakout, M.; Elmagarmid, A.K.; Neville, J.; Ouzzani, M.; Ilyas, I.F. Guided Data Repair. Proc. VLDB Endow. 2011, 4, 279–289. [Google Scholar] [CrossRef]
- Zhang, A.; Song, S.; Wang, J.; Yu, P.S. Time series data cleaning: From anomaly detection to anomaly repairing. Proc. VLDB Endow. 2017, 10, 1046–1057. [Google Scholar] [CrossRef] [Green Version]
- Ge, C.; Gao, Y.; Miao, X.; Yao, B.; Wang, H. A Hybrid Data Cleaning Framework Using Markov Logic Networks. IEEE Trans. Knowl. Data Eng. 2020. [Google Scholar] [CrossRef]
- Chu, X.; Ilyas, I.F.; Krishnan, S.; Wang, J. Data cleaning: Overview and emerging challenges. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 26 June 2016; pp. 2201–2206. [Google Scholar]
- Wang, X.; Wang, C. Time Series Data Cleaning: A Survey. IEEE Access 2019, 8, 1866–1881. [Google Scholar] [CrossRef]
- Sadeghianasl, S.; ter Hofstede, A.H.; Wynn, M.T.; Suriadi, S. A contextual approach to detecting synonymous and polluted activity labels in process event logs. In Proceedings of the OTM Confederated International Conferences “On the Move to Meaningful Internet Systems”, Rhodes, Greece, 21–25 October 2019; Springer: Cham, Switzerland, 2019; pp. 76–94. [Google Scholar]
- Andrews, R.; Suriadi, S.; Ouyang, C.; Poppe, E. Towards event log querying for data quality. In Proceedings of the OTM Confederated International Conferences “On the Move to Meaningful Internet Systems”, Valletta, Malta, 22–26 October 2018; Springer: Cham, Switzerland, 2018; pp. 116–134. [Google Scholar]
- Kherbouche, M.O.; Laga, N.; Masse, P.A. Towards a better assessment of event logs quality. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, 6–9 December 2016; pp. 1–8. [Google Scholar]
- Lu, X.; Fahland, D. A Conceptual Framework for Understanding Event Data Quality for Behavior Analysis. In Proceedings of the 9th Central European Workshop on Services and their Composition Zeus Workshop 2017, Lugano, Switzerland, 13–14 February 2017; pp. 11–14. [Google Scholar]
- Andrews, R.; van Dun, C.G.; Wynn, M.T.; Kratsch, W.; Röglinger, M.; ter Hofstede, A.H. Quality-informed semi-automated event log generation for process mining. Decis. Support Syst. 2020, 132, 113265. [Google Scholar] [CrossRef]
- Sani, M.F. Preprocessing Event Data in Process Mining. In Proceedings of the 32nd International Conference on Advanced Information Systems Engineering, Grenoble, France, 8–12 June 2020; pp. 1–10. [Google Scholar]
- Fox, F.; Aggarwal, V.R.; Whelton, H.; Johnson, O. A data quality framework for process mining of electronic health record data. In Proceedings of the 2018 IEEE International Conference on Healthcare Informatics (ICHI), New York, NY, USA, 4–7 June 2018; pp. 12–21. [Google Scholar]
- Kurniati, A.P.; Rojas, E.; Hogg, D.; Hall, G.; Johnson, O.A. The assessment of data quality issues for process mining in healthcare using Medical Information Mart for Intensive Care III, a freely available e-health record database. Health Inf. J. 2019, 25, 1878–1893. [Google Scholar] [CrossRef] [PubMed]
- Andrews, R.; Wynn, M.T.; Vallmuur, K.; Ter Hofstede, A.H.; Bosley, E.; Elcock, M.; Rashford, S. Leveraging data quality to better prepare for process mining: An approach illustrated through analysing road trauma pre-hospital retrieval and transport processes in Queensland. Int. J. Environ. Res. Public Health 2019, 16, 1138. [Google Scholar] [CrossRef] [Green Version]
| 1 |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Trace ID | Timestamp | Event | Activity | Resource | ⋯ |
|---|---|---|---|---|---|
| 1 | 2019/10/5 11:31 | A | Bob | ⋯ | |
| 1 | 2019/10/6 12:01 | B | Alice | ⋯ | |
| 1 | 2019/10/6 15:05 | C | Alice | ⋯ | |
| 1 | 2019/10/6 17:05 | D | Bob | ⋯ | |
| 2 | 2019/10/8 10:03 | A | Bob | ⋯ | |
| 2 | 2019/10/9 11:03 | B | Alice | ⋯ | |
| 2 | 2019/10/9 15:03 | - | - | Bob | ⋯ |
| 2 | 2019/10/10 11:03 | D | Alice | ⋯ | |
| ⋮ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ |
| Features of the Missing Value Relationship | |||||
|---|---|---|---|---|---|
| Trace ID | Trace | 103 | 204 | ⋯ | Label |
| T1 | <0,0,1,2,3> | 0 | 0 | ⋯ | 0 |
| T2 | <0,1,4,-,3> | 1 | 1 | ⋯ | 1 |
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| Activity ID | Activity Name |
|---|---|
| 0 | Accepted in-progress |
| 1 | Queued-Awaiting-assignment |
| 2 | Completed-resolve |
| 3 | Accepted assigned |
| 4 | Completed closed |
| 5 | Accepted wait-user |
| 6 | Accepted wait-implementation |
| 7 | Accepted wait |
| 8 | Completed In Call |
| 9 | Accepted wait-vender |
| 10 | Accepted wait-customer |
| 11 | Unmatched Unmatched |
| 12 | Completed cancelled |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Horita, H.; Kurihashi, Y.; Miyamori, N. Extraction of Missing Tendency Using Decision Tree Learning in Business Process Event Log. Data 2020, 5, 82. https://doi.org/10.3390/data5030082
Horita H, Kurihashi Y, Miyamori N. Extraction of Missing Tendency Using Decision Tree Learning in Business Process Event Log. Data. 2020; 5(3):82. https://doi.org/10.3390/data5030082
Chicago/Turabian StyleHorita, Hiroki, Yuta Kurihashi, and Nozomi Miyamori. 2020. "Extraction of Missing Tendency Using Decision Tree Learning in Business Process Event Log" Data 5, no. 3: 82. https://doi.org/10.3390/data5030082
APA StyleHorita, H., Kurihashi, Y., & Miyamori, N. (2020). Extraction of Missing Tendency Using Decision Tree Learning in Business Process Event Log. Data, 5(3), 82. https://doi.org/10.3390/data5030082