

Accuracy Assessment of Machine Learning Algorithms Used to Predict Breast Cancer

Abstract
:1. Introduction
2. Literature Review
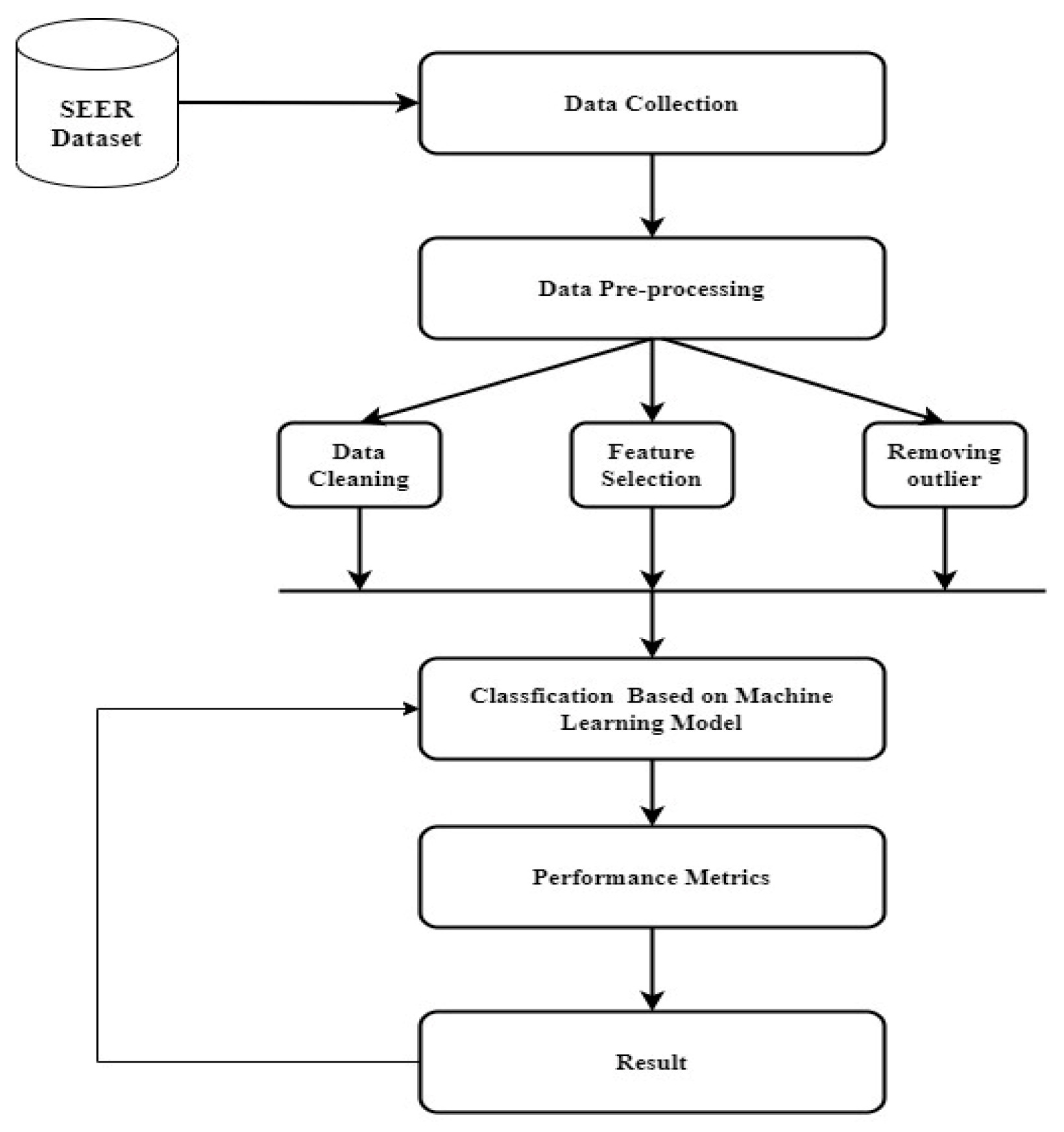
3. Materials and Methods
3.1. Dataset
3.2. Model Structure
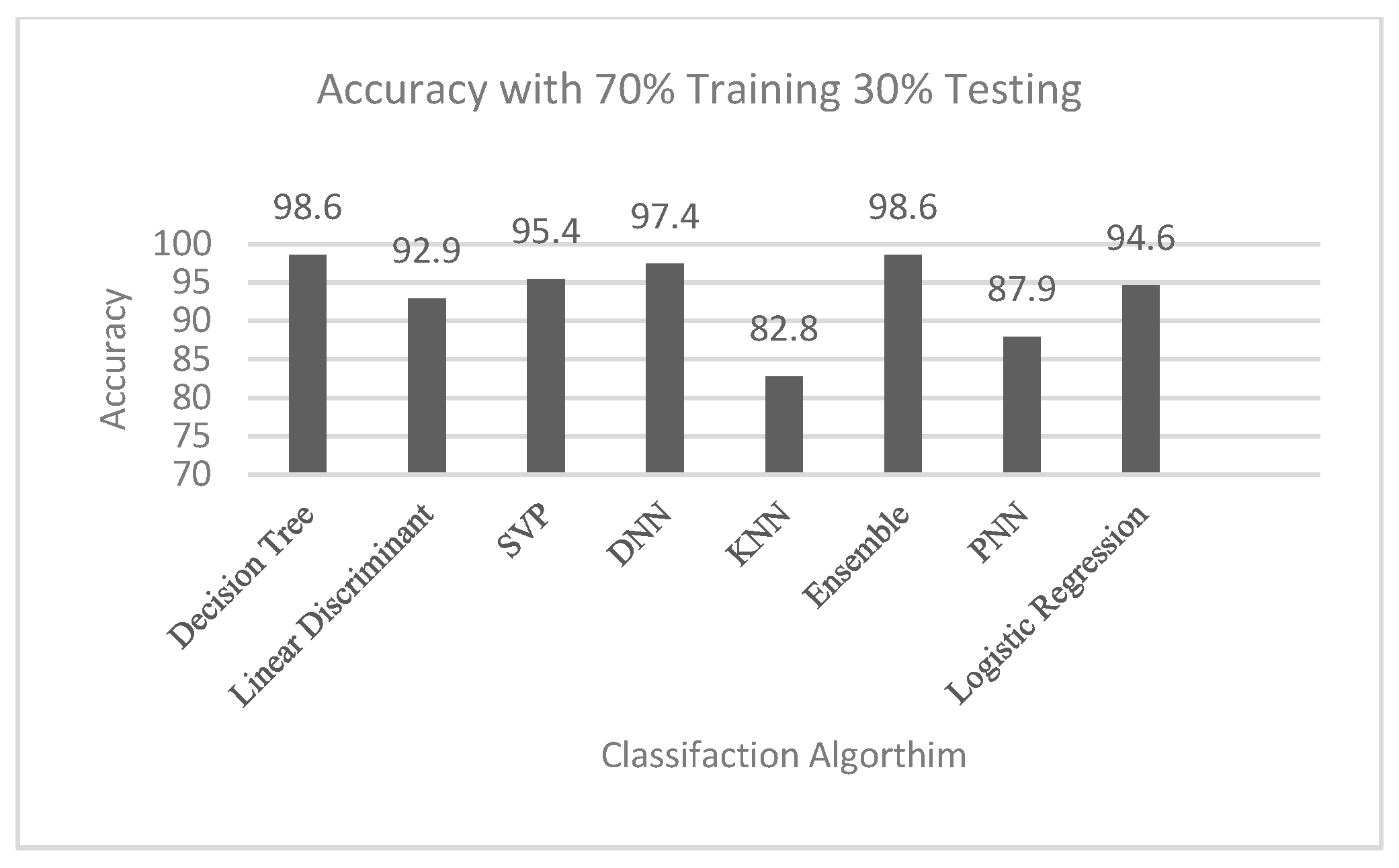
- Randomly, into 70% of data for training and 30% for testing;
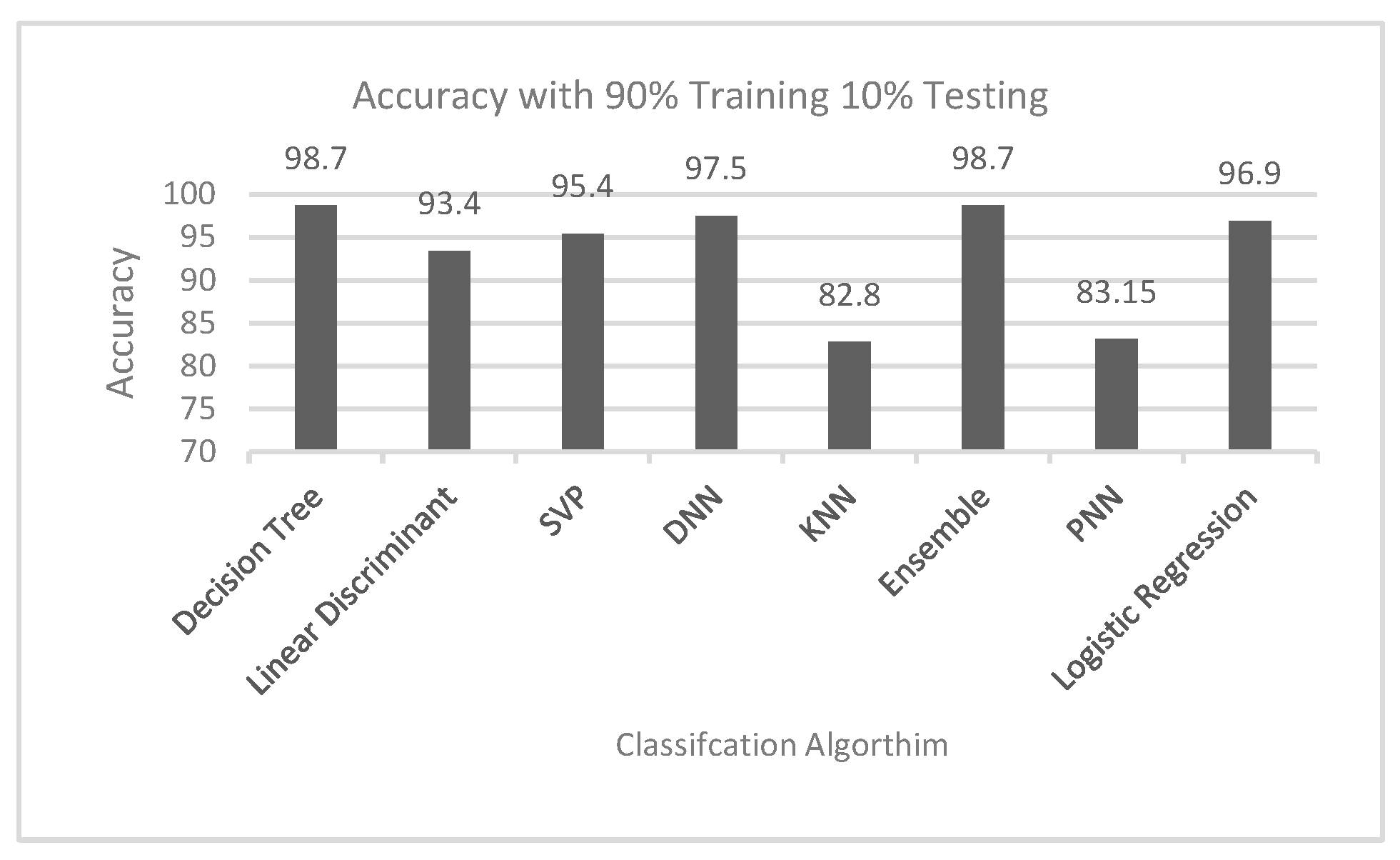
- Randomly, into 90% of data for training and 10% for testing;
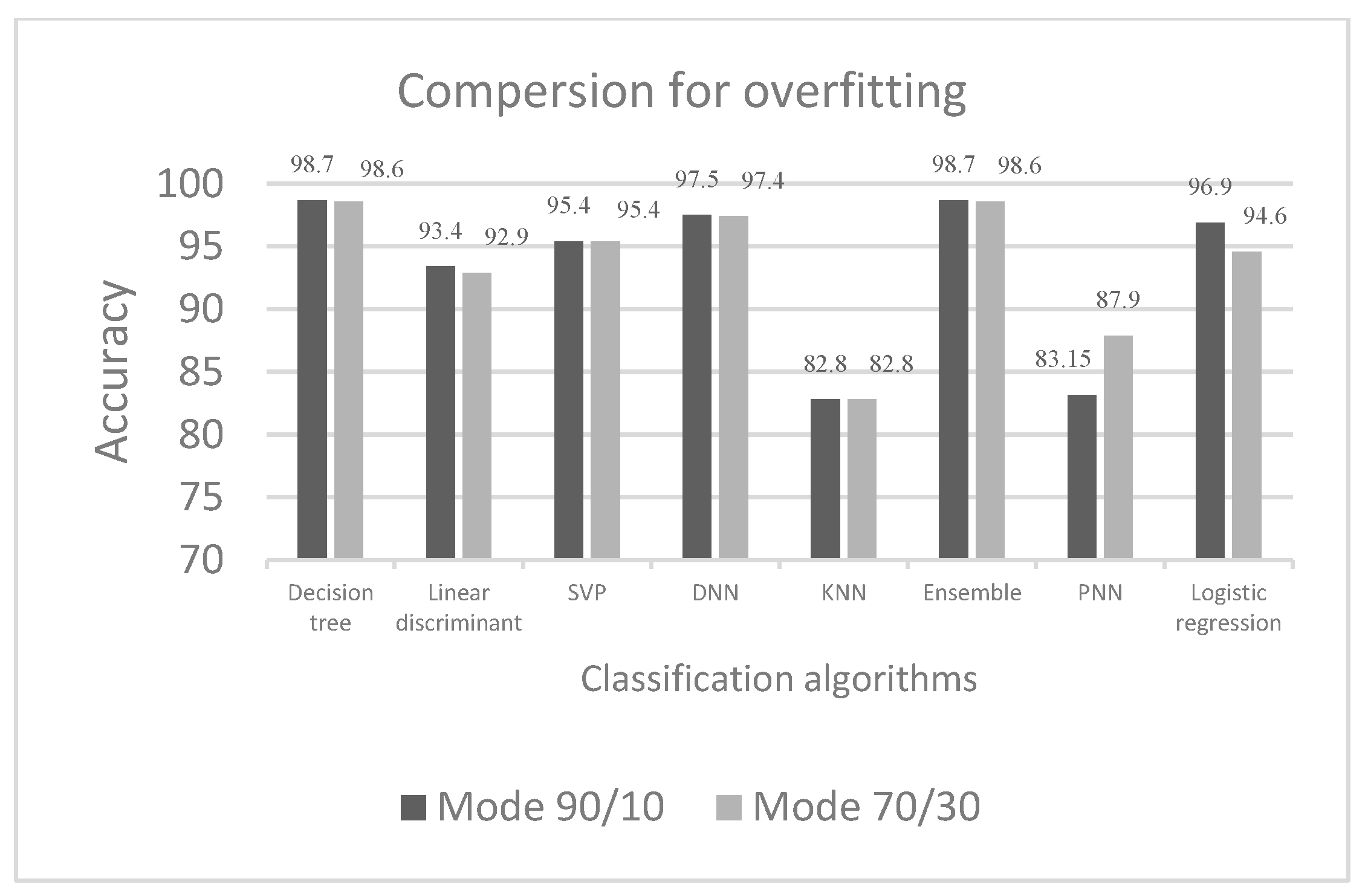
- The predictive accuracies of the fitted models were examined using a validation method. The validation estimated the models’ performances using new data compared to training data and protected them against overfitting. A cross-validation scheme was selected. The data were partitioned into k disjoint sets or folds and the number of cross-validation folds were 30 and 10. Each validation fold trained a model using training-fold observations and assessed model performance using validation-fold data. Next, the average validation errors over all folds were calculated before training any models, which enabled a comparison of all models using the same validation scheme.
3.3. Experimental Analysis and Results
3.4. Performance Analysis
- (1)
- Analysis without feature selection
- (2)
- Analysis with feature selection
4. Discussion
5. Conclusions
6. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
| # | Features | Feature Selection Algorithm | ||||||
| 1 | First malignant_primary_indicator | ECFS | FSCMCM | ILFS | INFFS | MUTINFFS | oobPermuted | RELIEFF |
| 2 | COD_to_site_rec_KM | ECFS | FSCMCM | FSCNCNA | ILFS | MUTINFFS | oobPermuted | |
| 3 | Record_number_recode | ECFS | FSCMCM | INFFS | MUTINFFS | oobPermuted | RELIEFF | |
| 4 | Total_number_of_in_situ_malignant_tumors_for_patient | ECFS | FSCMCM | FSCNCNA | MUTINFFS | oobPermuted | RELIEFF | |
| 5 | Histologic_Type_ICD_O_3 | ECFS | ILFS | INFFS | oobPermuted | RELIEFF | ||
| 6 | Derived_EOD_2018_M_2018_Plus | ECFS | ILFS | INFFS | oobPermuted | RELIEFF | ||
| 7 | RX_Summ_Surg_Oth_Reg_Dis_2003_Plus | ECFS | ILFS | INFFS | oobPermuted | RELIEFF | ||
| 8 | Tumor_Size_Summary_2016_Plus | ECFS | FSCNCNA | ILFS | INFFS | OobPermuted | ||
| 9 | Regional_nodes_examined_1988_Plus | ECFS | FSCNCNA | ILFS | INFFS | RELIEFF | ||
| 10 | Vital_status_recode_study_cutoff_used | ECFS | FSCNCNA | INFFS | oobPermuted | RELIEFF | ||
References
- Rose, S. Intersections of machine learning and epidemiological methods for health services research. Int. J. Epidemiol. 2021, 49, 1763–1770. [Google Scholar] [CrossRef] [PubMed]
- Oh, J.; Yun, K.; Maoz, U.; Kim, T.-S.; Chae, J.-H. Identifying depression in the National Health and Nutrition Examination Survey data using a deep learning algorithm. J. Affect. Disord. 2019, 257, 623–631. [Google Scholar] [CrossRef] [PubMed]
- Linardon, J.; Messer, M.; Helms, E.R.; McLean, C.; Incerti, L.; Fuller-Tyszkiewicz, M. Interactions between different eating patterns on recurrent binge-eating behavior: A machine learning approach. Int. J. Eat. Disord. 2020, 53, 533–540. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.B. Machine learning to advance the prediction, prevention and treatment of eating disorders. Eur. Eat. Disord. Rev. J. Eat. Disord. Assoc. 2021, 29, 683–691. [Google Scholar] [CrossRef]
- Breast Cancer-Metastatic: Statistics. Available online: https://www.cancer.net/cancer-types/breast-cancer-metastatic/statistics#:~:text=The%205%2Dyear%20survival%20rate%20for%20women%20with%20metastatic%20breast,is%20treatable%20at%20any%20stage (accessed on 11 June 2022).
- Cancer Facts & Figures 2022|American Cancer Society. Available online: https://www.cancer.org/research/cancer-facts-statistics/all-cancer-facts-figures/cancer-facts-figures-2022.html (accessed on 19 September 2022).
- Hastie, T.; Friedman, J.; Tibshirani, R. The Elements of Statistical Learning Data Mining, Inference, and Prediction, 1st ed.; Springer: New York, NY, USA, 2001. [Google Scholar] [CrossRef]
- Graves, A.; Mohamed, A.; Hinton, G. Speech recognition with deep recurrent neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 6645–6649. [Google Scholar] [CrossRef]
- Freund, Y.; Mason, L. The Alternating Decision Tree Learning Algorithm. In Proceedings of the Sixteenth International Conference on Machine Learning, San Francisco, CA, USA; 1999; pp. 124–133. [Google Scholar]
- Zou, B.; Li, L.; Xu, Z.; Luo, T.; Tang, Y.Y. Generalization Performance of Fisher Linear Discriminant Based on Markov Sampling. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 288–300. [Google Scholar] [CrossRef]
- Duda, R.O.; Hart, P.E. Pattern Classification and Scene Analysis; Wiley: New York, NY, USA, 1973. [Google Scholar]
- Fukunaga, K. Introduction to Statistical Pattern Recognition, 2nd ed.; Academic Press: New York, NY, USA, 1990. [Google Scholar] [CrossRef]
- Linear Regression in Python—Real Python. Available online: https://realpython.com/linear-regression-in-python/#linear-regression (accessed on 16 September 2022).
- “Sklearn.linear_model.LinearRegression,” Scikit-Learn. Available online: https://scikit-learn/stable/modules/generated/sklearn.linear_model.LinearRegression.html (accessed on 16 September 2022).
- Vapnik, V.N. Statistical Learning Theory; Wiley-Interscience: New York, NY, USA, 1998. [Google Scholar]
- Bartlett, P.; Freund, Y.; Lee, W.S.; Schapire, R.E. Boosting the margin: A new explanation for the effectiveness of voting methods. Ann. Stat. 1998, 26, 1651–1686. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Specht, D. Probabilistic neural networks and the polynomial Adaline as complementary techniques for classification. IEEE Trans. Neural Netw. 1990, 1, 111–121. [Google Scholar] [CrossRef]
- Nazif, A.M.; Sedky, A.A.H.; Badawy, O.M. MOOC’s Student Results Classification by Comparing PNN and other Classifiers with Features Selection. In Proceedings of the 2020 21st International Arab Conference on Information Technology (ACIT), Giza, Egypt, 28–30 November 2020; pp. 1–9. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Schmidhuber, J. Deep Learning in Neural Networks: An Overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef]
- Larochelle, H.; Erhan, D.; Courville, A.; Bergstra, J.; Bengio, Y. An empirical evaluation of deep architectures on problems with many factors of variation. In Proceedings of the 24th International Conference on Machine Learning, Corvalis, OR, USA, 20–24 June 2007; pp. 473–480. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.-W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Liu, H. Single-point wind forecasting methods based on reinforcement learning. Wind Forecast. Railw. Eng. 2021, 177–214. [Google Scholar] [CrossRef]
- Vijayakumar, T. Neural Network Analysis for Tumor Investigation and Cancer Prediction. J. Electron. Inform. 2019, 2019, 89–98. [Google Scholar] [CrossRef]
- Chugh, G.; Kumar, S.; Singh, N. Survey on Machine Learning and Deep Learning Applications in Breast Cancer Diagnosis. Cogn. Comput. 2021, 13, 1451–1470. [Google Scholar] [CrossRef]
- Sun, D.; Wang, M.; Li, A. A Multimodal Deep Neural Network for Human Breast Cancer Prognosis Prediction by Integrating Multi-Dimensional Data. IEEE/ACM Trans. Comput. Biol. Bioinform. 2019, 16, 841–850. [Google Scholar] [CrossRef]
- Wu, L.; Zhou, W.; Wan, X.; Zhang, J.; Shen, L.; Hu, S.; Ding, Q.; Mu, G.; Yin, A.; Huang, X.; et al. A deep neural network improves endoscopic detection of early gastric cancer without blind spots. Endoscopy 2019, 51, 522–531. [Google Scholar] [CrossRef] [Green Version]
- Ferroni, P.; Zanzotto, F.M.; Riondino, S.; Scarpato, N.; Guadagni, F.; Roselli, M. Breast Cancer Prognosis Using a Machine Learning Approach. Cancers 2019, 11, 328. [Google Scholar] [CrossRef]
- Zeid, M.A.-E.; El-Bahnasy, K.; Abo-Youssef, S.E. DeepBreast: Building Optimized Framework for Prognosis of Breast Cancer Classification Based on Computational Intelligence. In Proceedings of the 2022 2nd International Mobile, Intelligent, and Ubiquitous Computing Conference (MIUCC), Cairo, Egypt, 8–9 May 2022; pp. 438–445. [Google Scholar] [CrossRef]
- Yue, W.; Wang, Z.; Chen, H.; Payne, A.; Liu, X. Machine Learning with Applications in Breast Cancer Diagnosis and Prognosis. Designs 2018, 2, 13. [Google Scholar] [CrossRef]
- Delen, D.; Walker, G.; Kadam, A. Predicting breast cancer survivability: A comparison of three data mining methods. Artif. Intell. Med. 2005, 34, 113–127. [Google Scholar] [CrossRef]
- Azar, A.T.; El-Metwally, S.M. Decision tree classifiers for automated medical diagnosis. Neural Comput. Appl. 2012, 23, 2387–2403. [Google Scholar] [CrossRef]
- Chaurasia, V.; Pal, S. Data Mining Techniques: To Predict and Resolve Breast Cancer Survivability. Int. J. Comput. Sci. Mob. Comput. IJCSMC 2014, 3, 10–22. [Google Scholar]
- Djebbari, A.; Liu, Z.; Phan, S.; AND Famili, F. International journal of computational biology and drug design (ijcbdd). In Proceedings of the 21st Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2008. [Google Scholar]
- Aruna, S.; Nandakishore, L.V. Knowledge based analysis of various statistical tools in detecting breast cancer. Comput. Sci. Inf. Technol. 2011, 2, 37–45. [Google Scholar]
- Ojha, U.; Goel, S. A study on prediction of breast cancer recurrence using data mining techniques. In Proceedings of the 7th International Conference on Cloud Computing, Data Science & Engineering—Confluence, Noida, India, 12–13 January 2017; pp. 527–530. [Google Scholar] [CrossRef]
- Maldonado, S.; Weber, R.; Basak, J. Simultaneous feature selection and classification using kernel-penalized support vect machines. Inf. Sci. 2011, 181, 115–128. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Estimated New Cases | Estimated Deaths | ||||
|---|---|---|---|---|---|
| Both Sexes | Male | Female | Both Sexes | Male | Female |
| 290,560 | 2710 | 287,850 | 43,780 | 530 | 43,250 |
| Algorithms | Mode 90/10 | Mode 70/30 |
|---|---|---|
| Decision tree | 98.7 | 98.6 |
| Linear discriminant | 93.4 | 92.9 |
| SVP | 95.4 | 95.4 |
| DNN | 97.5 | 97.4 |
| KNN | 82.8 | 82.8 |
| Ensemble | 98.7 | 98.6 |
| PNN | 83.15 | 87.9 |
| Logistic regression | 96.9 | 94.6 |
| DT | LD | LR | SVP | KNN | Ensemble | Rnn | Pnn | DNN | |
|---|---|---|---|---|---|---|---|---|---|
| Precision | 0.966 | 0.819 | 0.909 | 0.888 | 0.677 | 0.972 | 0.964 | 0.789 | 0.974 |
| Recall | 0.344 | 0.309 | 0.341 | 0.327 | 0.288 | 0.345 | 0.764 | 0.298 | 0.350 |
| F1 score | 0.507 | 0.449 | 0.496 | 0.478 | 0.404 | 0.509 | 0.852 | 0.433 | 0.515 |
| DT | LD | LR | SVP | KNN | Ensemble | Rnn | Pnn | DNN | |
|---|---|---|---|---|---|---|---|---|---|
| Precision | 0.967 | 0.819 | 0.911 | 0.888 | 0.679 | 0.972 | 0.964 | 0.784 | 0.971 |
| Recall | 0.344 | 0.309 | 0.342 | 0.327 | 0.288 | 0.345 | 0.764 | 0.317 | 0.339 |
| F1 score | 0.344 | 0.449 | 0.497 | 0.478 | 0.404 | 0.509 | 0.852 | 0.451 | 0.503 |
| Algorithms | Accuracy without Feature Selection Algorithms | Accuracy with Feature Selection Algorithms |
|---|---|---|
| Decision tree | 98.7 | 98.6 |
| Linear discriminant | 93.4 | 92.2 |
| SVP | 95.4 | 97.9 |
| DNN | 83.2 | 97.9 |
| KNN | 82.8 | 95.9 |
| Ensemble | 98.7 | 98.6 |
| PNN | 97.6 | 95.3 |
| Logistic regression | 96.9 | 94.9 |
| RNN | 95.5 | 98.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ebrahim, M.; Sedky, A.A.H.; Mesbah, S. Accuracy Assessment of Machine Learning Algorithms Used to Predict Breast Cancer. Data 2023, 8, 35. https://doi.org/10.3390/data8020035
Ebrahim M, Sedky AAH, Mesbah S. Accuracy Assessment of Machine Learning Algorithms Used to Predict Breast Cancer. Data. 2023; 8(2):35. https://doi.org/10.3390/data8020035
Chicago/Turabian StyleEbrahim, Mohamed, Ahmed Ahmed Hesham Sedky, and Saleh Mesbah. 2023. "Accuracy Assessment of Machine Learning Algorithms Used to Predict Breast Cancer" Data 8, no. 2: 35. https://doi.org/10.3390/data8020035
APA StyleEbrahim, M., Sedky, A. A. H., & Mesbah, S. (2023). Accuracy Assessment of Machine Learning Algorithms Used to Predict Breast Cancer. Data, 8(2), 35. https://doi.org/10.3390/data8020035