
Cloud-Based Smart Contract Analysis in FinTech Using IoT-Integrated Federated Learning in Intrusion Detection

Abstract
:1. Introduction
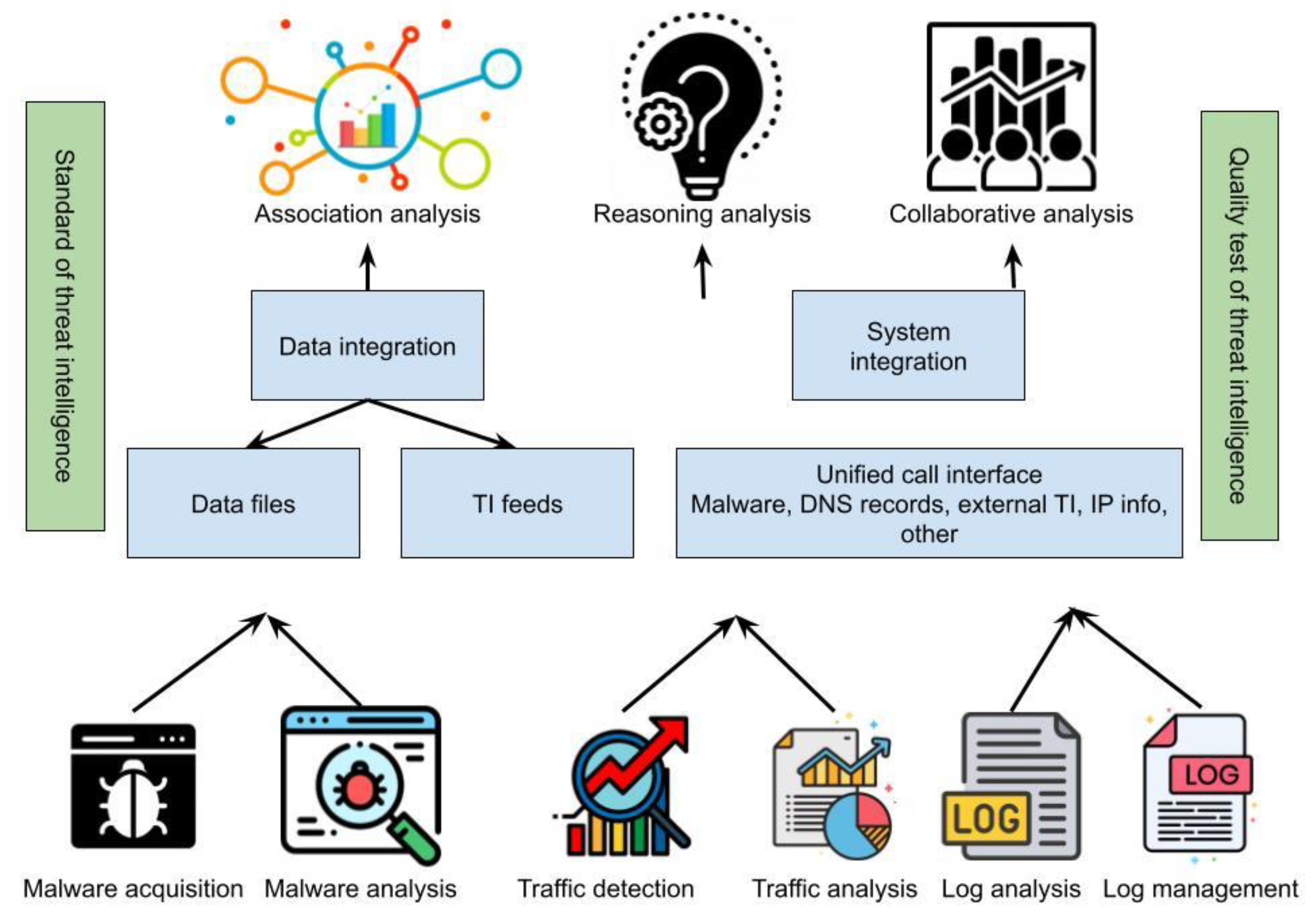
2. Literature Review
Existing FinTech Intrusion Detection System
3. Proposed Model
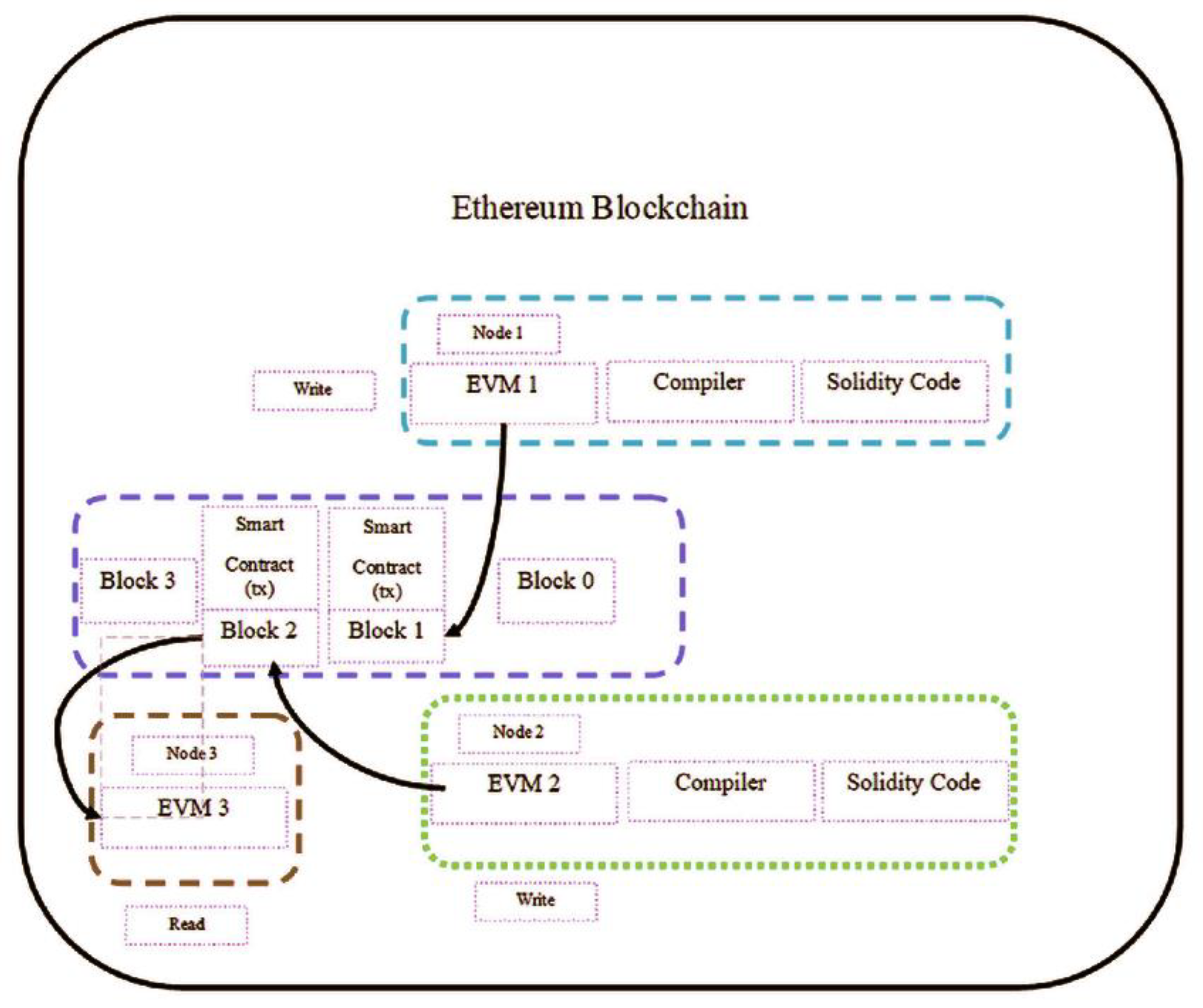
3.1. Cloud Based Smart Contract Analysis
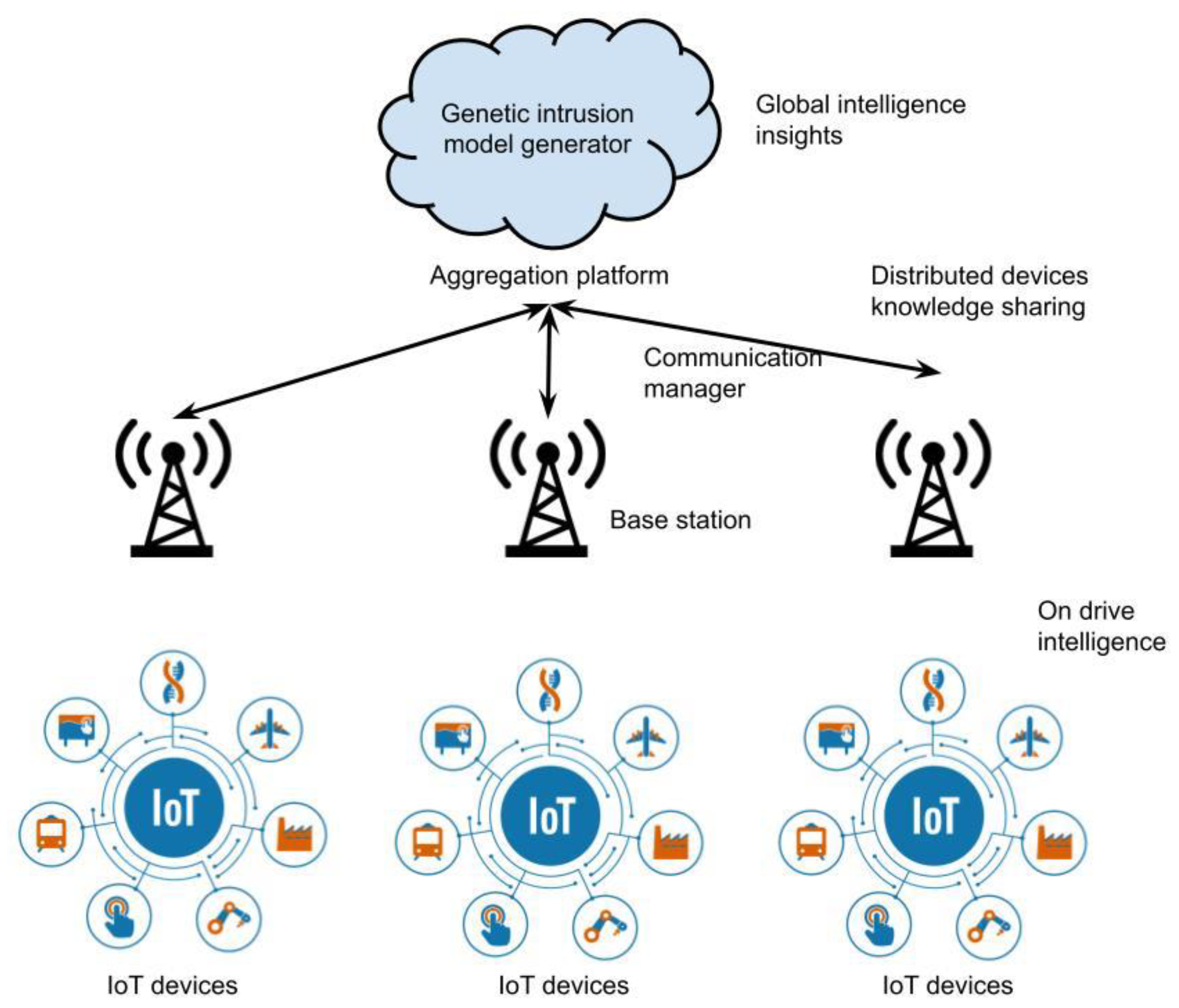
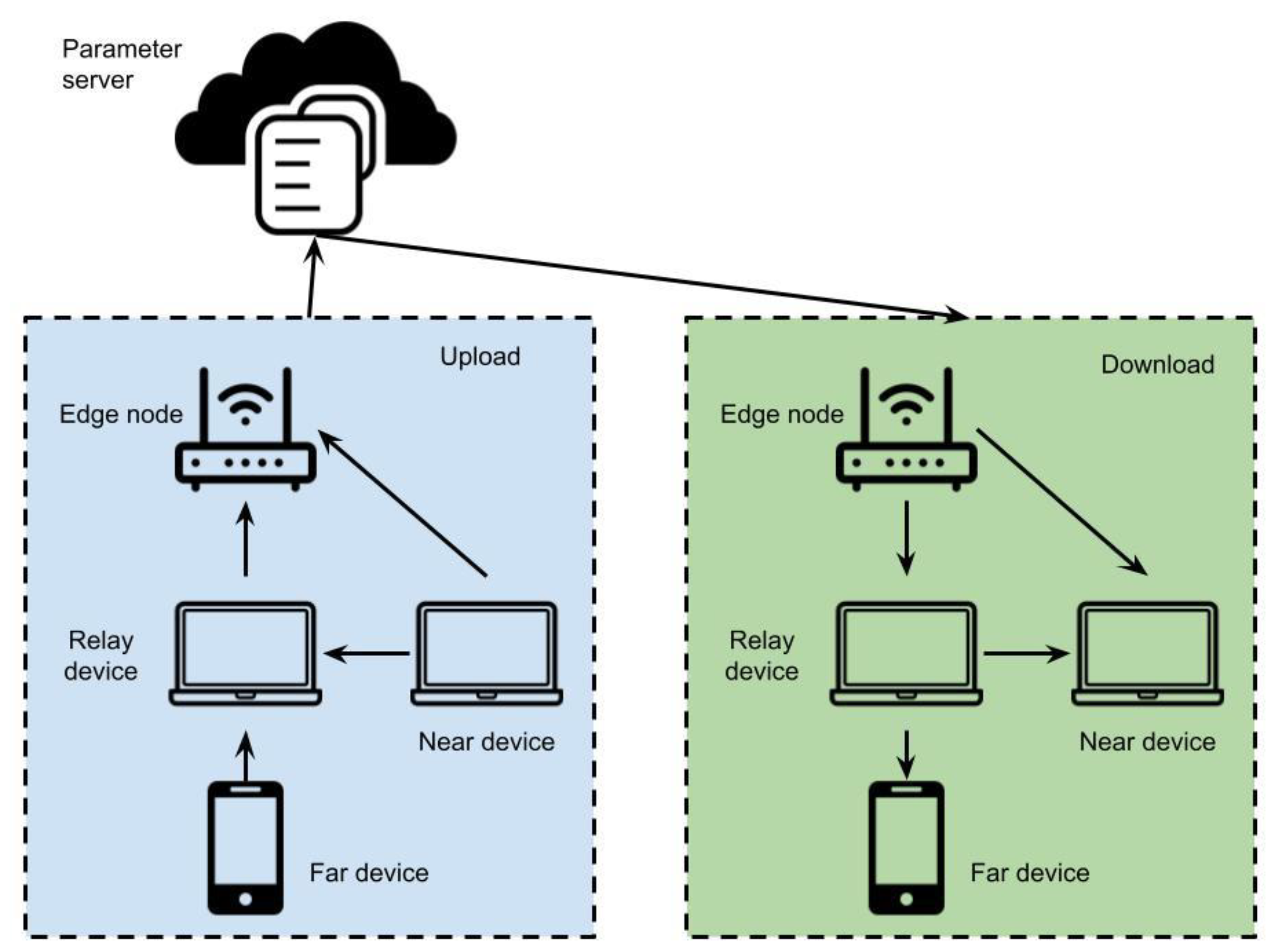
3.2. FinTech Intrusion Detection Based IoT Module Using Cyber Threat Federated Graphical Authentication System
- for Incident do
- for do
- Rearrange
- Reset replay buffer .
- .
- for do
- In every resource block , every EN gives and updates its observation to .
- Input into every EN’s policy and finds present pricing method
- End devices viewer and update their observations to
- Input to actor network and find transmit power and jamming coefficient
- End devices upload to specification server while near devices allocate jamming signals.
- PS combined global method for end devices with
- Updates into and evaluates rewards
- Store transitions in
4. Results and Discussion
4.1. Proposed Analysis
4.2. Comparative Analysis
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chuang, L.M.; Liu, C.C.; Kao, H.K. The adoption of fintech service: TAM perspective. Int. J. Manag. Adm. Sci. 2016, 3, 1–15. [Google Scholar]
- Hu, Z.; Ding, S.; Li, S.; Chen, L.; Yang, S. Adoption intention of fintech services for bank users: An empirical examination with an extended technology acceptance model. Symmetry 2019, 11, 340. [Google Scholar] [CrossRef]
- Dospinescu, O.; Dospinescu, N.; Agheorghiesei, D.T. Fintech Services and Factors Determining the Expected Benefits of Users: Evidence in Romania for Millennials and Generation Z; Technical University of Liberec: Liberec, Czechia, 2021. [Google Scholar]
- Nasir, A.; Shaukat, K.; Iqbal Khan, K.; Hameed, I.A.; Alam, T.M.; Luo, S. Trends and directions of financial technology (Fintech) in society and environment: A bibliometric study. Appl. Sci. 2021, 11, 10353. [Google Scholar] [CrossRef]
- Mai, T.; Yao, H.; Xu, J.; Zhang, N.; Liu, Q.; Guo, S. Automatic double-auction mechanism for federated learning service market in internet of things. IEEE Trans. Netw. Sci. Eng. 2022, 9, 3123–3135. [Google Scholar] [CrossRef]
- Aouedi, O.; Piamrat, K.; Muller, G.; Singh, K. Federated semisupervised learning for attack detection in industrial Internet of Things. IEEE Trans. Ind. Inform. 2022, 19, 286–295. [Google Scholar] [CrossRef]
- Wan, Y.; Qu, Y.; Gao, L.; Xiang, Y. Privacy-preserving blockchain-enabled federated learning for B5G-Driven edge computing. Comput. Netw. 2022, 204, 108671. [Google Scholar] [CrossRef]
- Noman, A.A.; Rahaman, M.; Pranto, T.H.; Rahman, R.M. Blockchain for medical collaboration: A federated learning-based approach for multi-class respiratory disease classification. Healthc. Anal. 2023, 3, 100135. [Google Scholar] [CrossRef]
- Islam, A.; Al Amin, A.; Shin, S.Y. FBI: A Federated Learning-Based Blockchain-Embedded Data Accumulation Scheme Using Drones for Internet of Things. IEEE Wirel. Commun. Lett. 2022, 11, 972–976. [Google Scholar] [CrossRef]
- Loh, Y.; Chen, Z.; Zhao, Y.; Yu, H. FLAS: A Platform for Studying Attacks on Federated Learning. In Social Computing and Social Media: Design, User Experience and Impact, Proceedings of the 14th International Conference, SCSM 2022, Held as Part of the 24th HCI International Conference, HCII 2022, Virtual Event, 26 June–1 July 2022, Part I; Springer International Publishing: Cham, Switzerland, 2022; pp. 160–169. [Google Scholar]
- Sheng, X.; Gao, Z.; Cui, X.; Yu, C. Federated Reinforcement Learning Technology and Application in Edge Intelligence Scene. In Advances in Internet, Data & Web Technologies, Proceedings of the 11th International Conference on Emerging Internet, Data & Web Technologies (EIDWT-2023), Semarang, Indonesia, 23–25 February 2023; Springer International Publishing: Cham, Switzerland, 2023; pp. 284–291. [Google Scholar]
- Lyu, L.; Yu, H.; Ma, X.; Chen, C.; Sun, L.; Zhao, J.; Yang, Q.; Philip, S.Y. Privacy and robustness in federated learning: Attacks and defenses. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Khadidos, A.; Subbalakshmi AV, V.S.; Khadidos, A.; Alsobhi, A.; Yaseen, S.M.; Mirza, O.M. Wireless communication based cloud network architecture using AI assisted with IoT for FinTech application. Optik 2022, 269, 169872. [Google Scholar] [CrossRef]
- Ali, A.; Almaiah, M.A.; Hajjej, F.; Pasha, M.F.; Fang, O.H.; Khan, R.; Teo, J.; Zakarya, M. An industrial IoT-based blockchain-enabled secure searchable encryption approach for healthcare systems using neural network. Sensors 2022, 22, 572. [Google Scholar] [CrossRef] [PubMed]
- Upreti, K.; Syed, M.H.; Khan, M.A.; Fatima, H.; Alam, M.S.; Sharma, A.K. Enhanced algorithmic modelling and architecture in deep reinforcement learning based on wireless communication Fintech technology. Optik 2023, 272, 170309. [Google Scholar] [CrossRef]
- Kumar, P.; Kumar, R.; Gupta, G.P.; Tripathi, R. BDEdge: Blockchain and deep-learning for secure edge-envisioned green CAVs. IEEE Trans. Green Commun. Netw. 2022, 6, 1330–1339. [Google Scholar] [CrossRef]
- Singh, R.; Deorari, R. Enhancing Collaborative Intrusion detection networks against insider attack using supervised learning technique. In Proceedings of the 2022 IEEE 2nd Mysore Sub Section International Conference (MysuruCon), Mysuru, India, 16–17 October 2022; pp. 1–6. [Google Scholar]
- Sheth, H.S.K.; Ilavarasi, A.K.; Tyagi, A.K. Deep Learning, blockchain based multi-layered Authentication and Security Architectures. In Proceedings of the 2022 International Conference on Applied Artificial Intelligence and Computing (ICAAIC), Salem, India, 9–11 May 2022; pp. 476–485. [Google Scholar]
- Baliker, C.; Baza, M.; Alourani, A.; Alshehri, A.; Alshahrani, H.; Choo, K.K.R. On the Applications of Blockchain in FinTech: Advancements and Opportunities. IEEE Trans. Eng. Manag. 2023. [Google Scholar] [CrossRef]
- Ch, R.; Srivastava, G.; Nagasree YL, V.; Ponugumati, A.; Ramachandran, S. Robust Cyber-Physical System Enabled Smart Healthcare Unit Using Blockchain Technology. Electronics 2022, 11, 3070. [Google Scholar] [CrossRef]
- Stojanović, B.; Božić, J. Robust Financial Fraud Alerting System Based in the Cloud Environment. Sensors 2022, 22, 9461. [Google Scholar] [CrossRef] [PubMed]
- Gehlot, A.; Joshi, A. Multilayer Statistical Intrusion Detection Model for Wireless Network. In Proceedings of the 2022 IEEE 2nd Mysore Sub Section International Conference (MysuruCon), Mysuru, India, 16–17 October 2022; pp. 1–7. [Google Scholar]
- Rana, A.; Srivastava, V.K. Design of IoT network using Deep learning model for Anomaly Detection. In Proceedings of the 2022 IEEE 2nd Mysore Sub Section International Conference (MysuruCon), Mysuru, India, 16–17 October 2022; pp. 1–8. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Applicable Domain | Objective | Contribution | Limitation |
|---|---|---|---|
| Blockchain and AI | A study on AI-related blockchain applications | The literature reviews on new blockchain platforms, applications, and protocols | Their study did not take into account issues such as privacy, smart contract security, trustworthy oracles, scalability, consensus protocols, standardization, interoperability, quantum computing robustness, and governance. |
| Blockchain technology | A thorough analysis of BC | In this study, BC architecture and fundamental aspects of BC were covered. | In this study, BC architecture and fundamental aspects of BC were covered. |
| Decentralized FL framework created in BC | A distributed FL architectural context that was created on BC with committee consensus (BFLC) | The quantity of consensus computation may be efficiently reduced with the use of a novel committee consensus technique, which may also lessen malicious attacks. | Time complexity was nottaken into account. |
| For the allocation of sensitive data in the Internet of Things, BC, and FL | Using blockchain technology, construct a secure data sharing architecture for numerous distributed participants. | The authors added FL to the permissioned BC consensus process, enabling the use of the consensus computing effort for federated training. | The study’s technological resources were insufficient. |
| Vehicle-based edge computing | A secure peer-to-peer data-exchange strategy for in-vehicle computing and systems was proposed. | A secure peer-to-peer data exchange strategy for in-vehicle computing and systems was proposed. | Limited dataset was employed in this investigation. |
| A federated learning methodology based on blockchain | To maintain the privacy and security of loHT data, FL, and discrepancy confidentiality (DC) were proposed, enabling isolated loHT data to be educated at the holder’s location. | The topic of integrating a minimal security and privacy solution into the FL environment was addressed by the authors. | The settings for the accuracy and loss measures are quite low, but they can be raised in the future. |
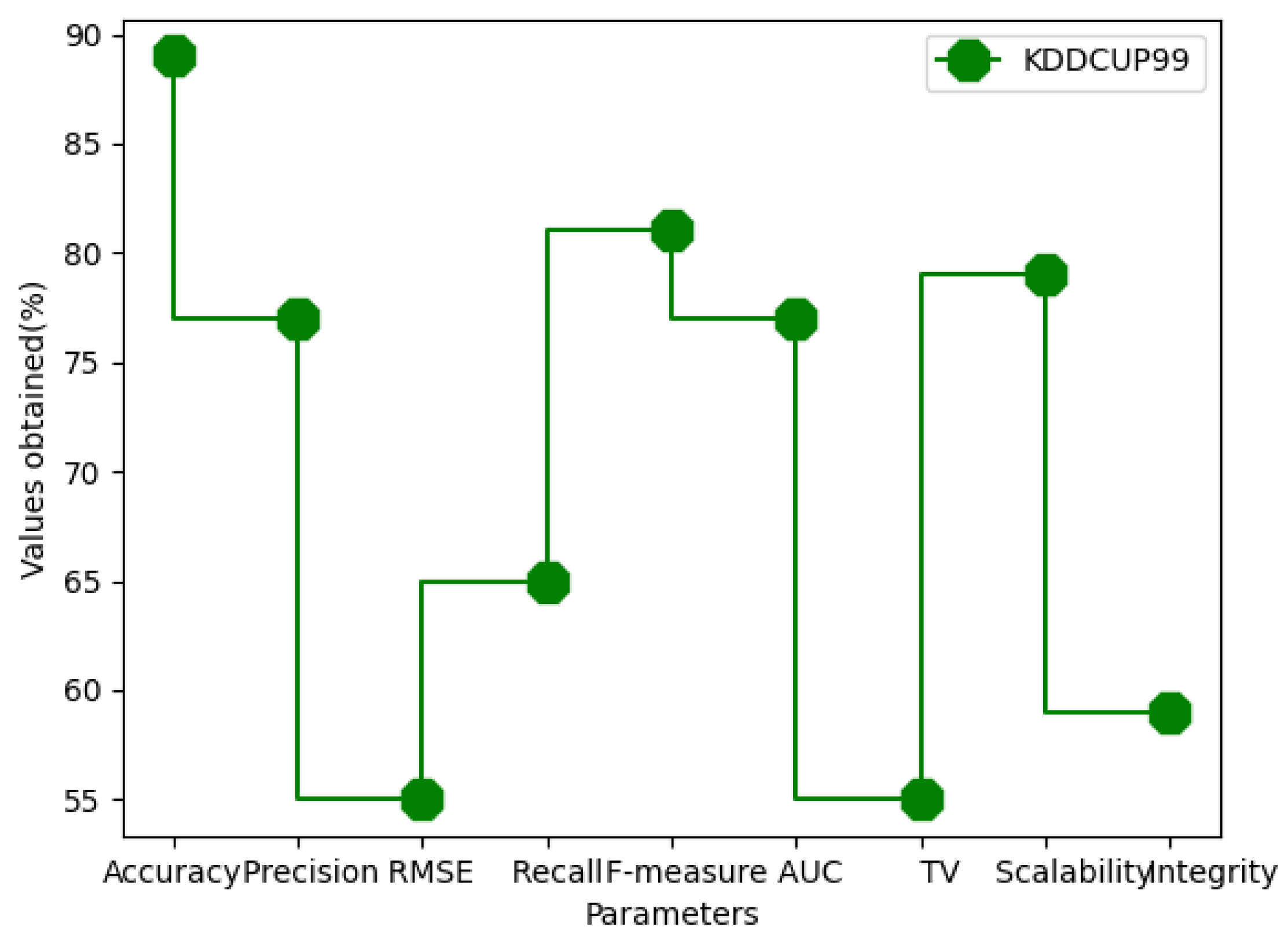
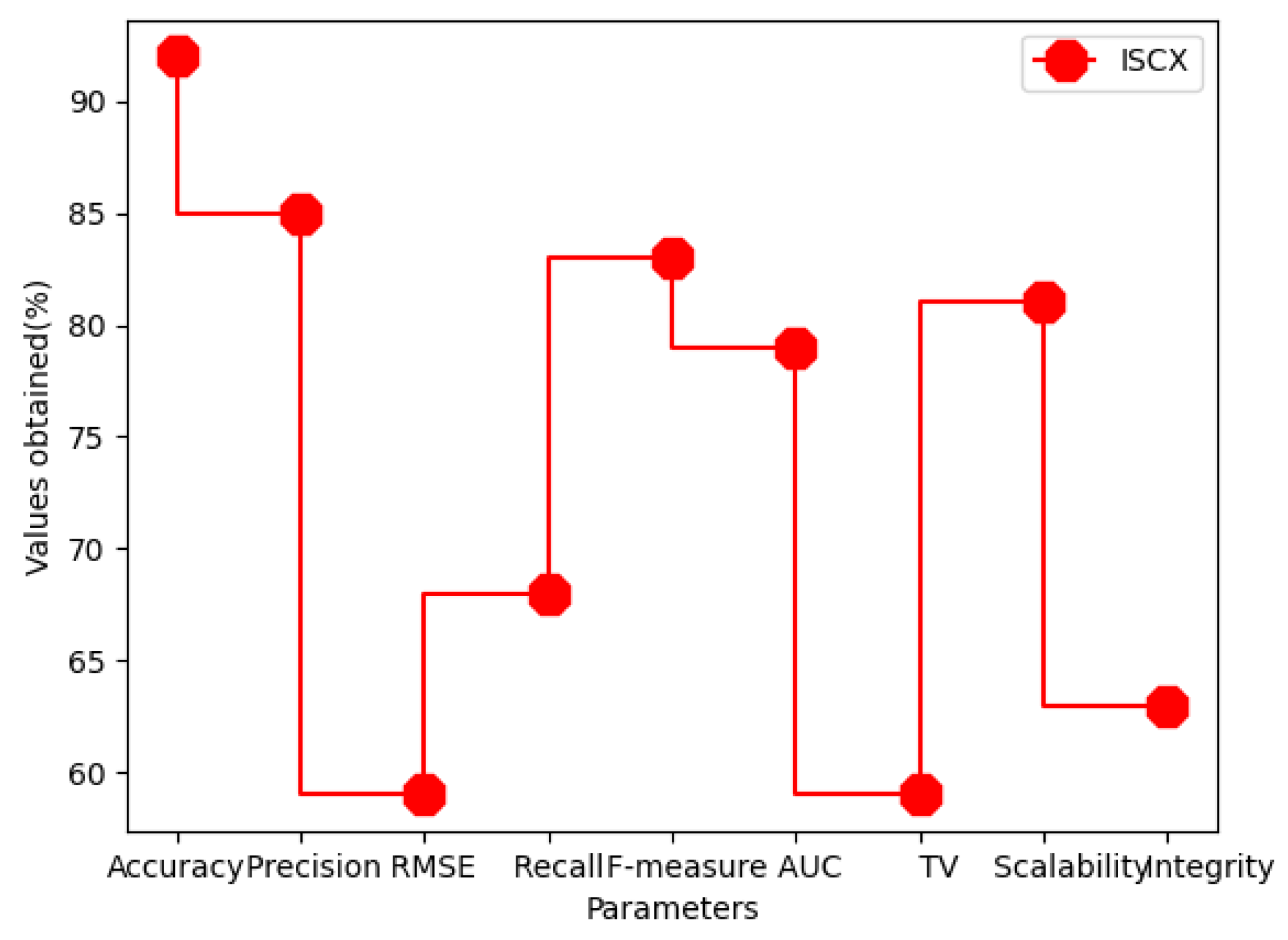
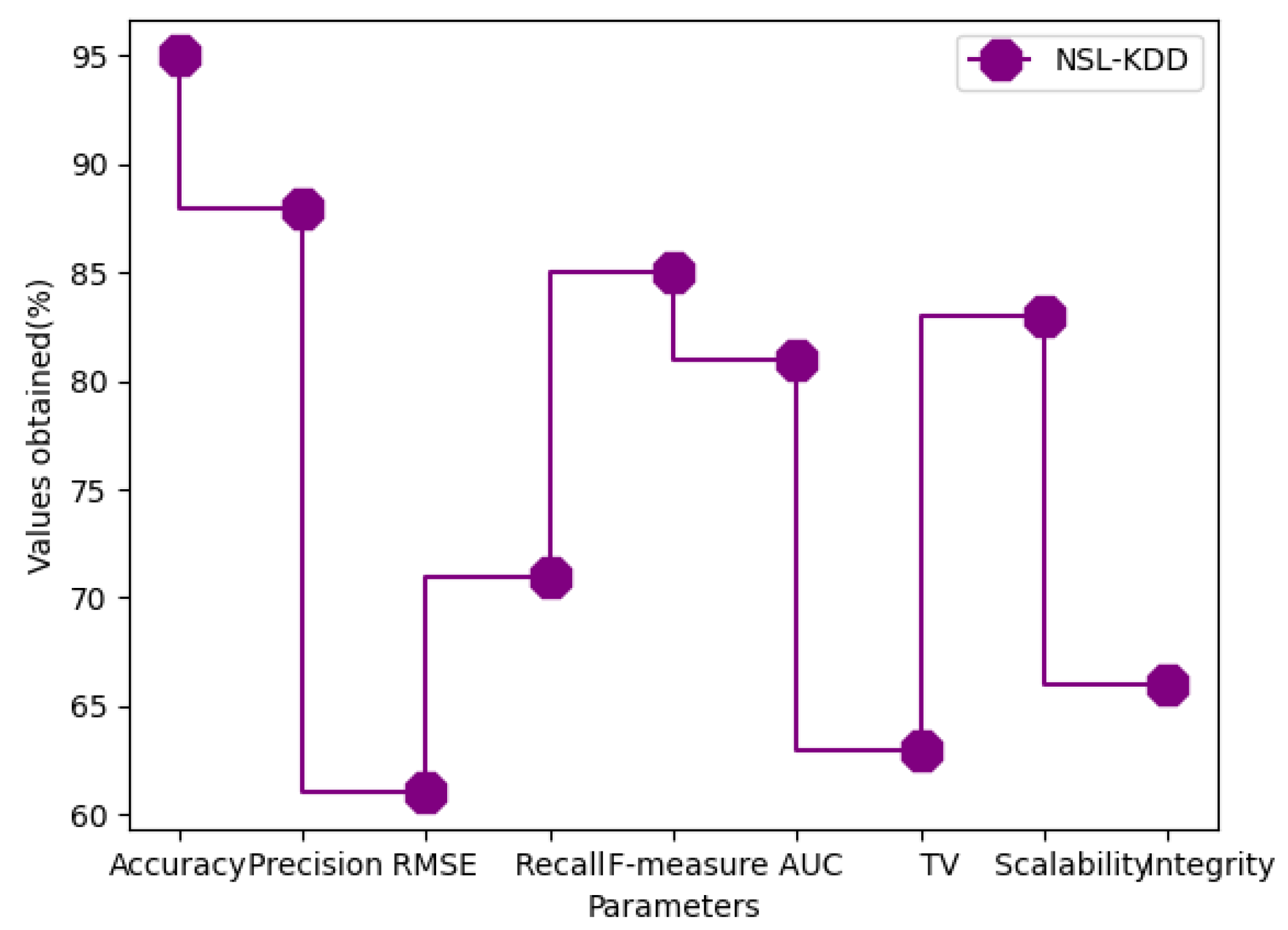
| Dataset | Accuracy | Precision | RMSE | Recall | F-Measure | AUC | Trust Value | Scalability | Integrity |
|---|---|---|---|---|---|---|---|---|---|
| KDDCUP99 | 89 | 77 | 55 | 65 | 81 | 77 | 55 | 79 | 59 |
| ISCX | 92 | 85 | 59 | 68 | 83 | 79 | 59 | 81 | 63 |
| NSL-KDD | 95 | 88 | 61 | 71 | 85 | 81 | 63 | 83 | 66 |
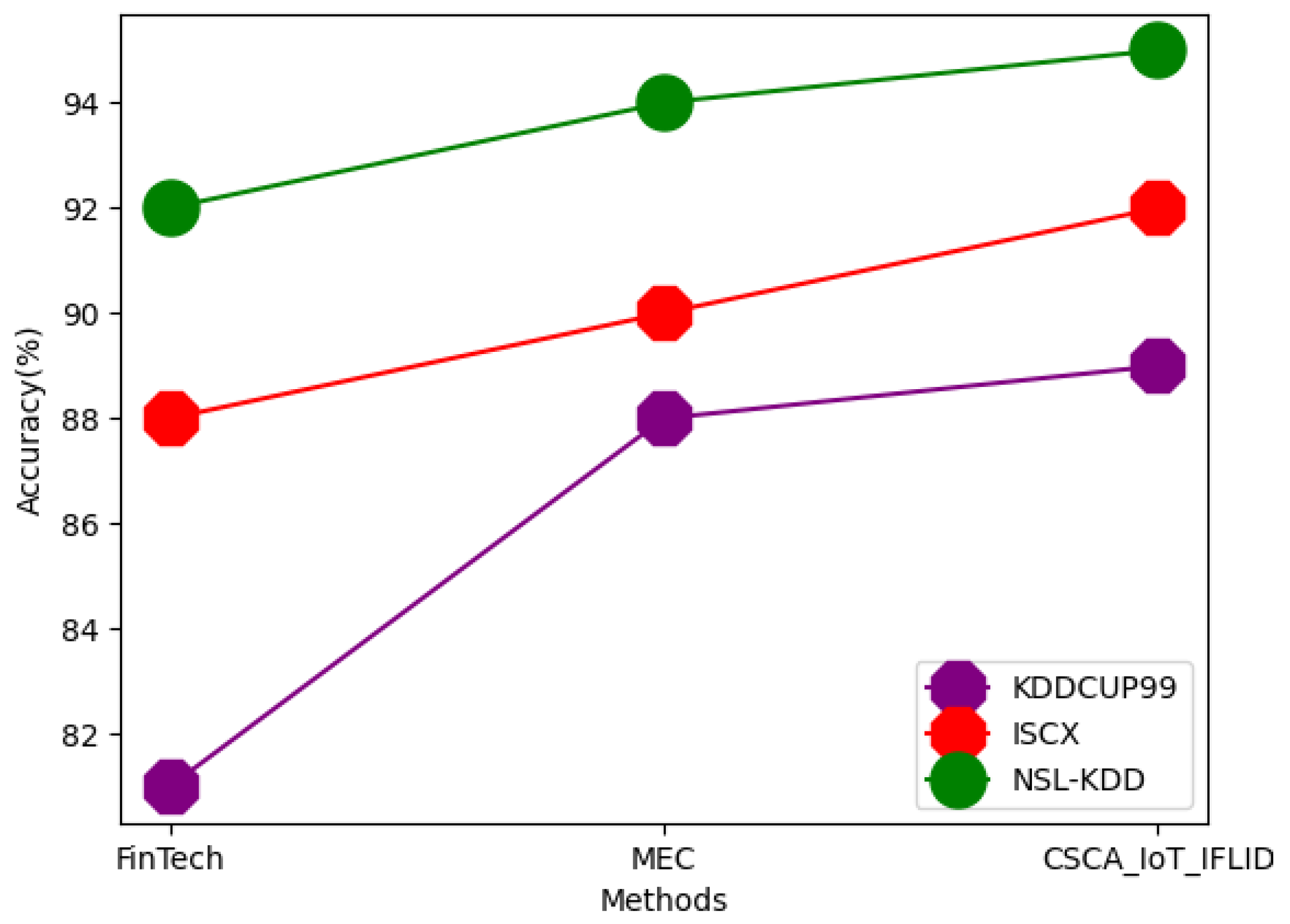
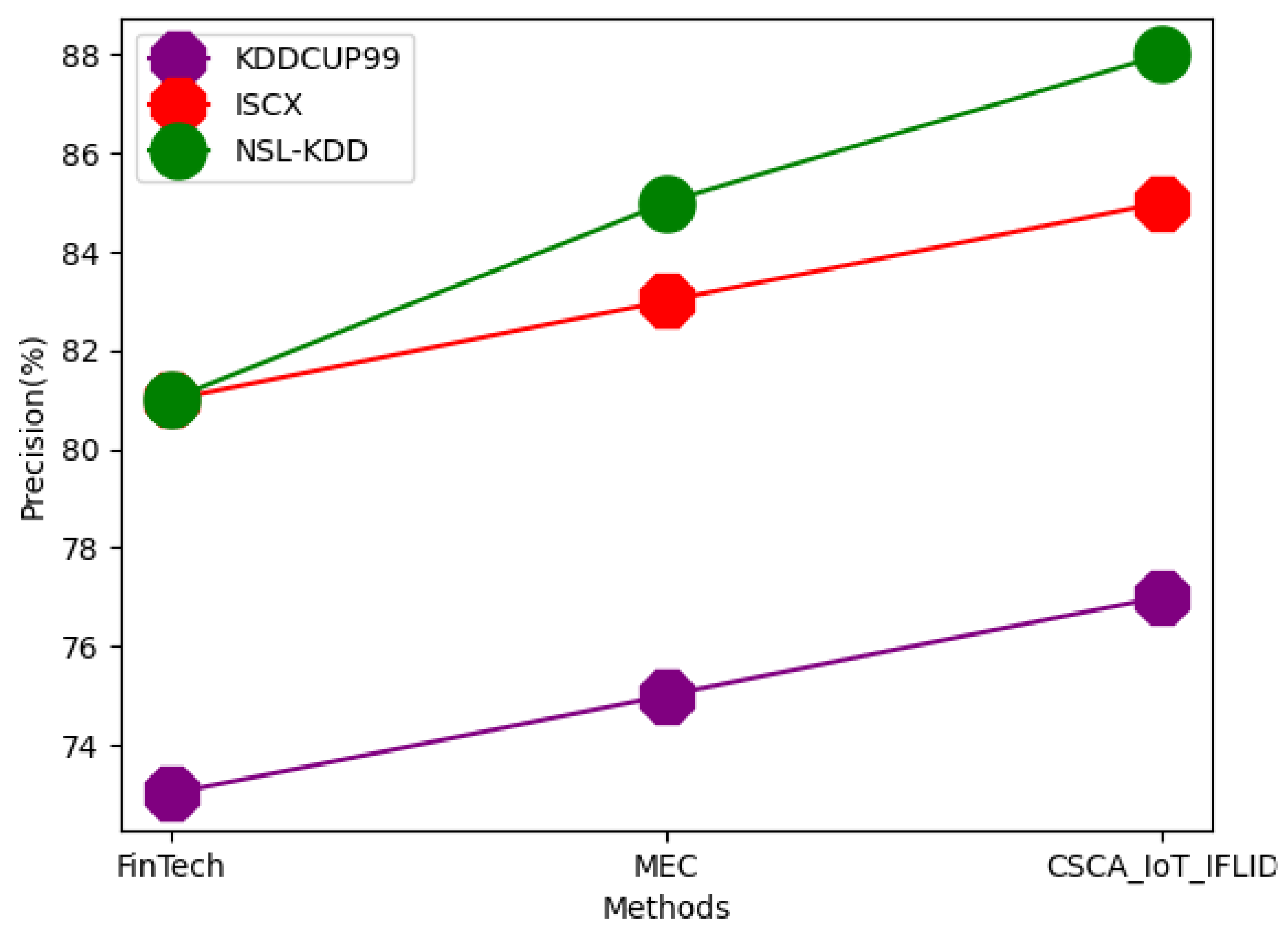
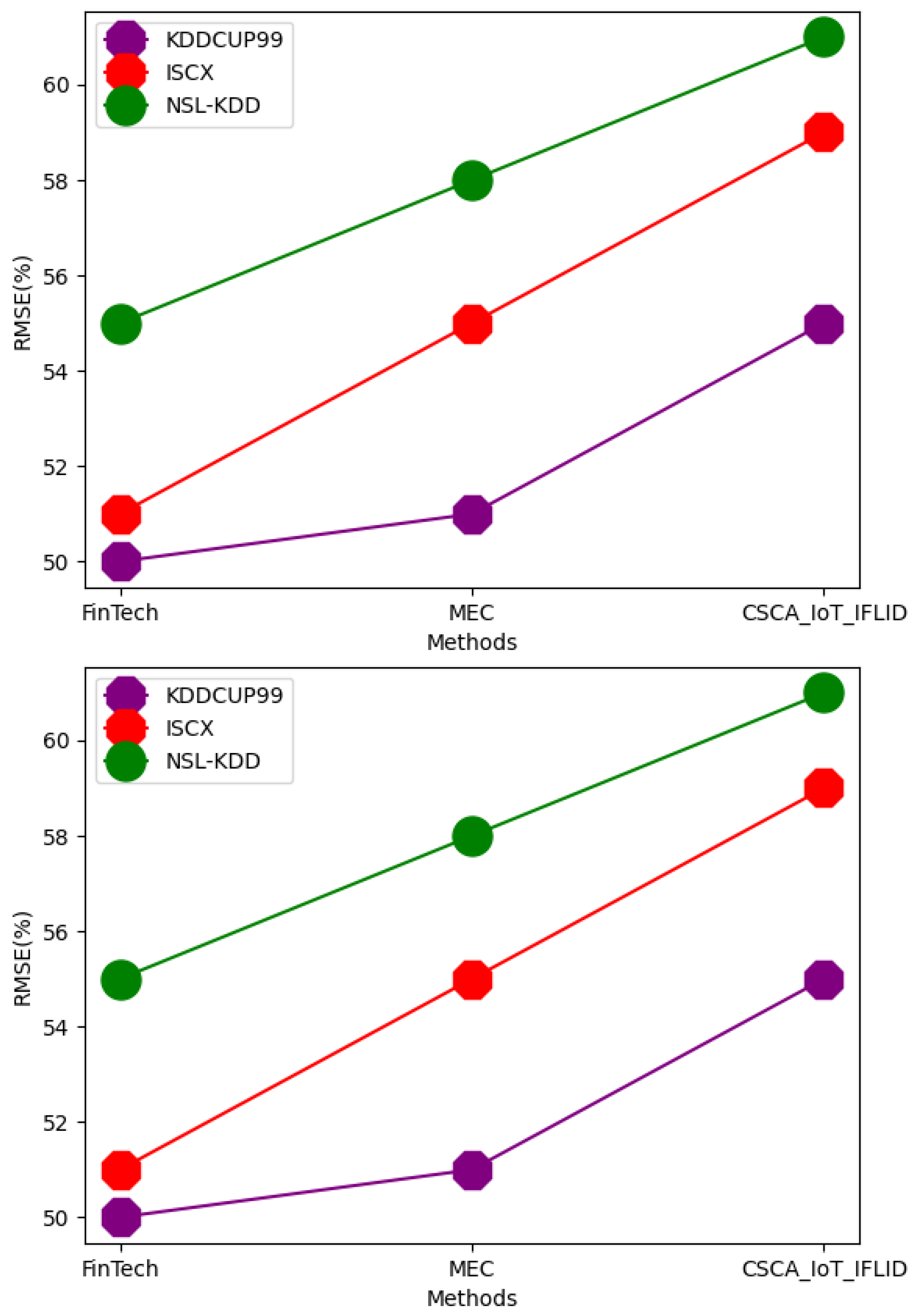
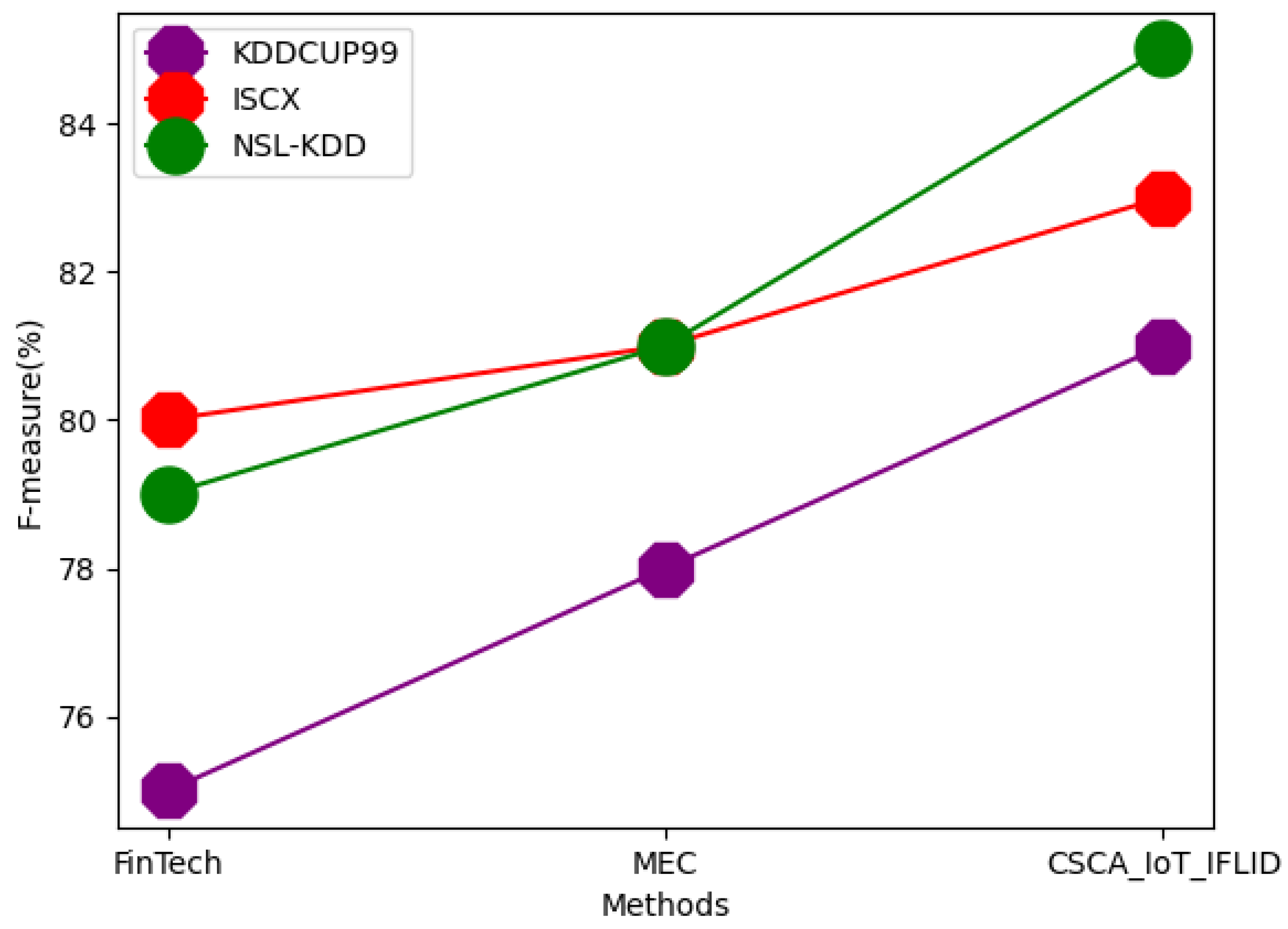
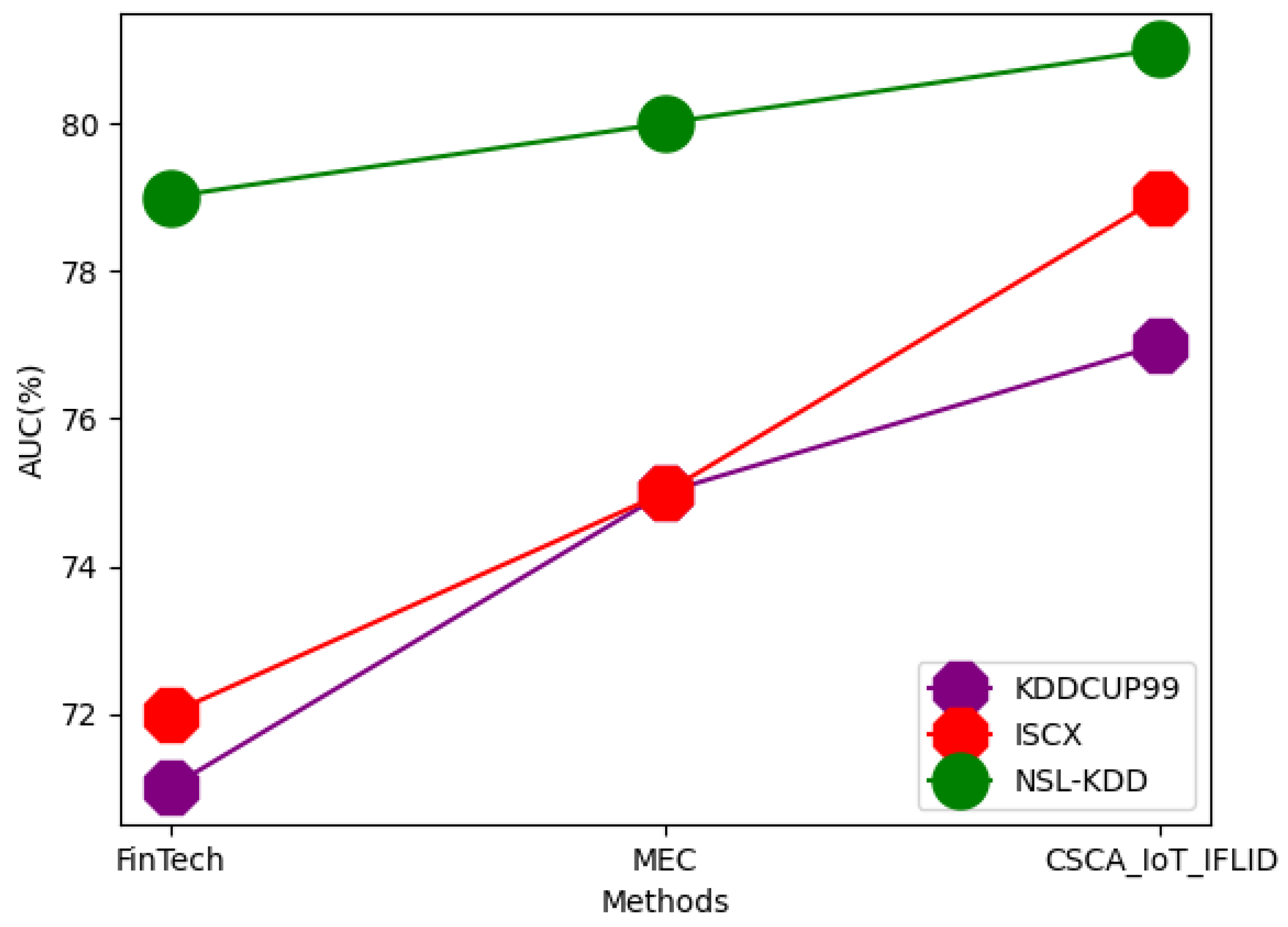
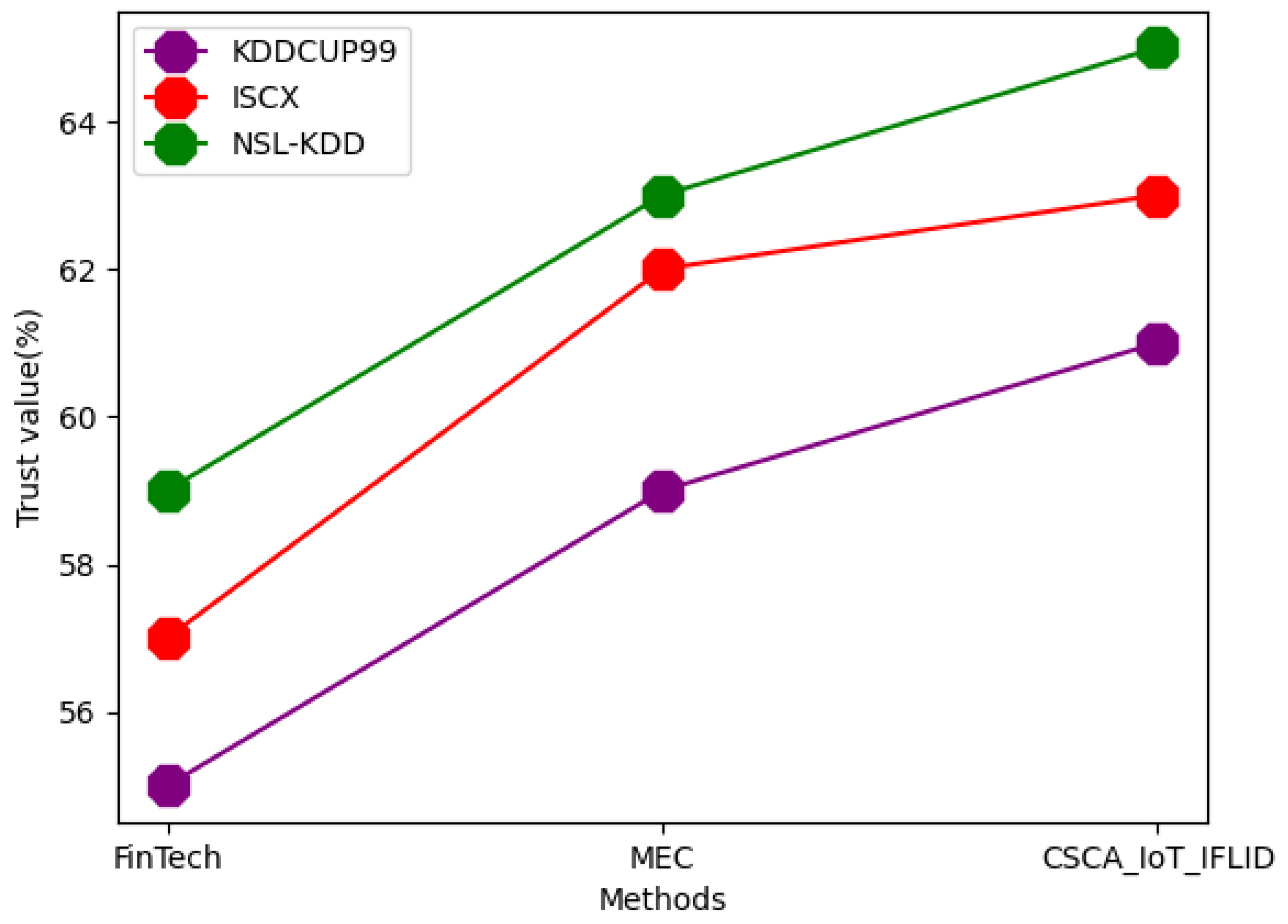
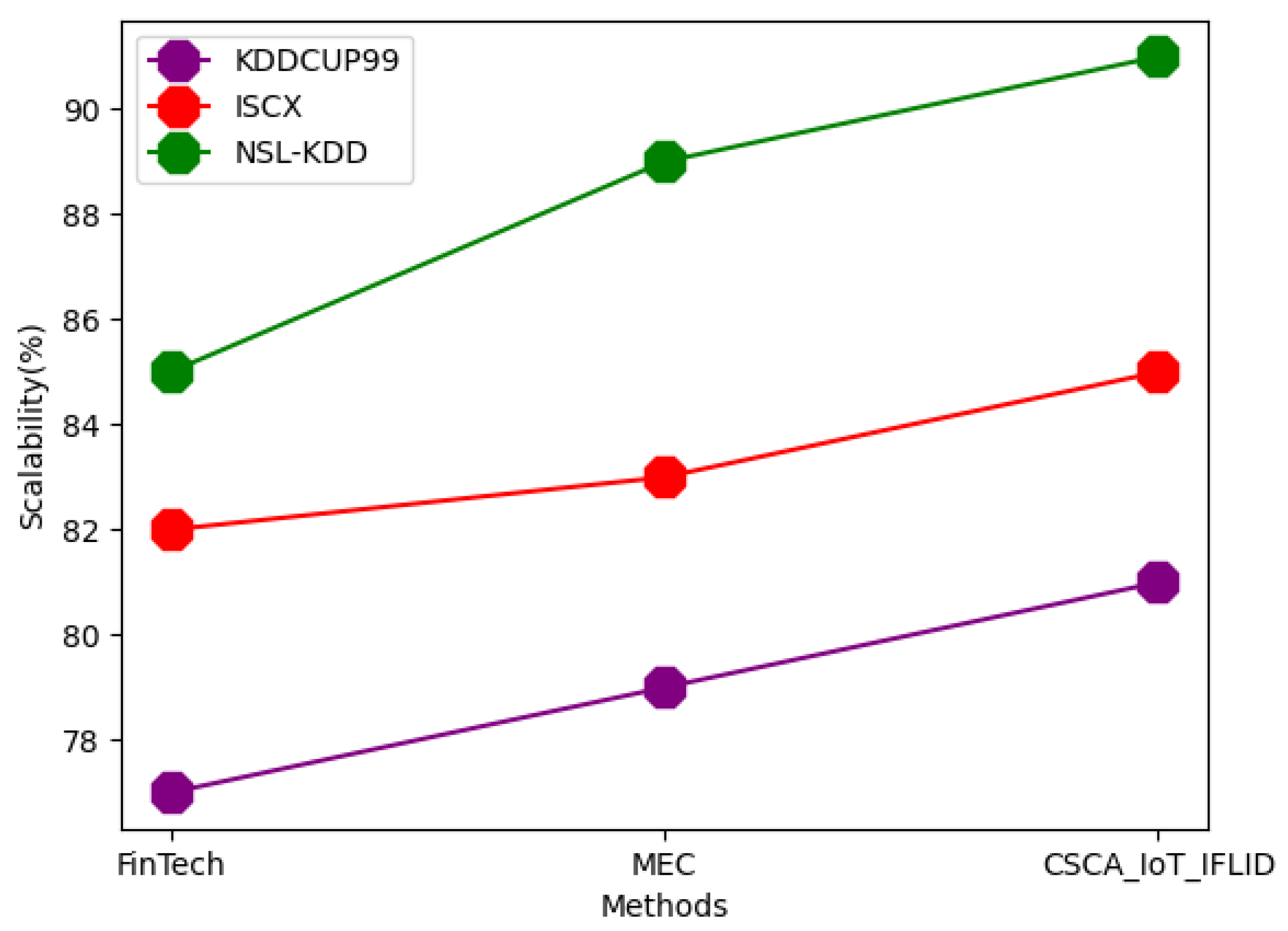
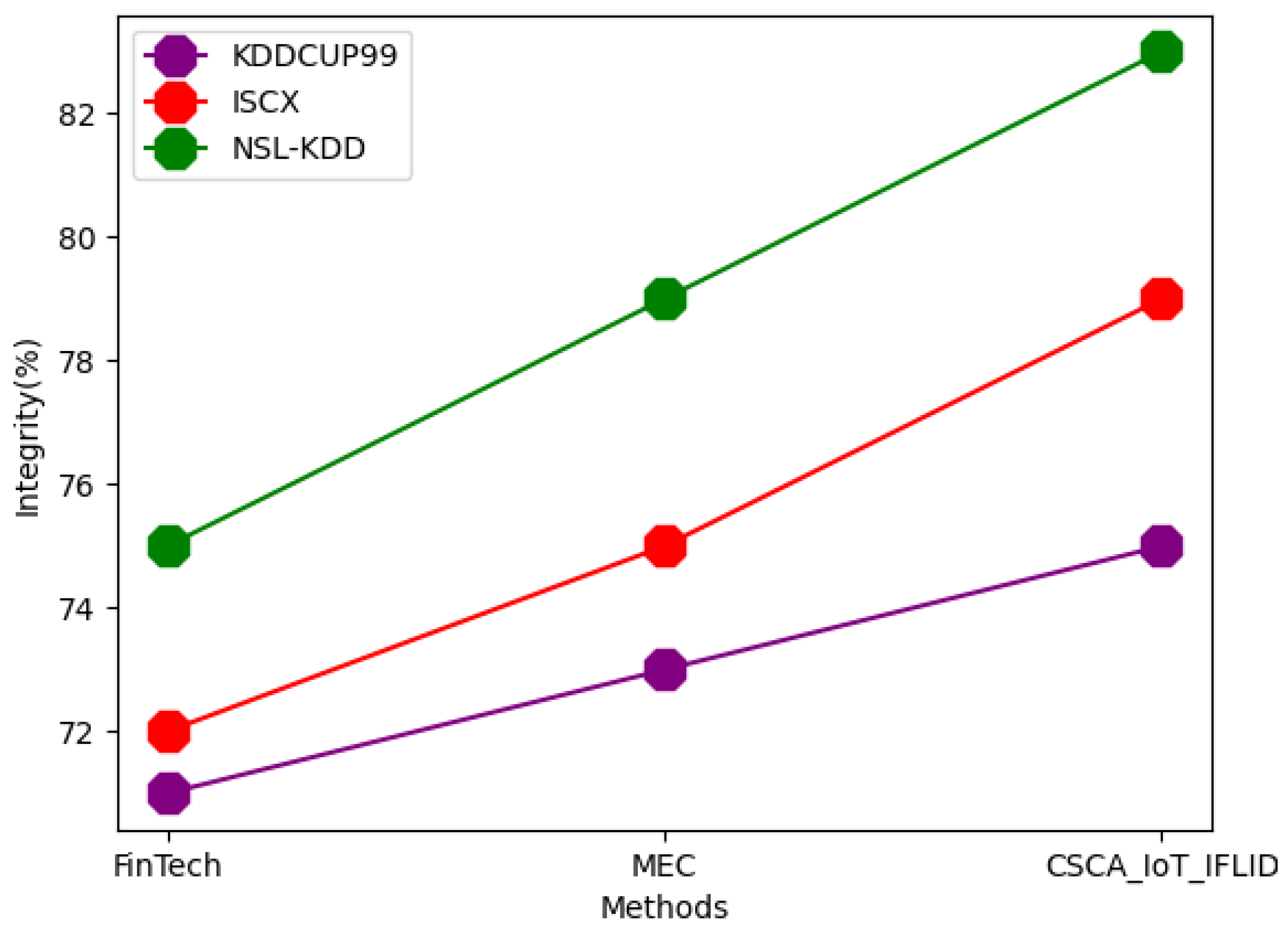
| Dataset | Techniques | Accuracy | Precision | RMSE | F-Measure | AUC | Trust Value | Scalability | Integrity |
|---|---|---|---|---|---|---|---|---|---|
| KDDCUP99 | FinTech | 81 | 73 | 50 | 75 | 71 | 55 | 77 | 71 |
| MEC | 88 | 75 | 51 | 78 | 75 | 59 | 79 | 73 | |
| CSCA_IoT_IFLID | 89 | 77 | 55 | 81 | 77 | 61 | 81 | 75 | |
| ISCX | FinTech | 88 | 81 | 51 | 80 | 72 | 57 | 82 | 72 |
| MEC | 90 | 83 | 55 | 81 | 75 | 62 | 83 | 75 | |
| CSCA_IoT_IFLID | 92 | 85 | 59 | 83 | 79 | 63 | 85 | 79 | |
| NSL-KDD | FinTech | 92 | 81 | 55 | 79 | 79 | 59 | 85 | 75 |
| MEC | 94 | 85 | 58 | 81 | 80 | 63 | 89 | 79 | |
| CSCA_IoT_IFLID | 95 | 88 | 61 | 85 | 81 | 65 | 91 | 83 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kollu, V.N.; Janarthanan, V.; Karupusamy, M.; Ramachandran, M. Cloud-Based Smart Contract Analysis in FinTech Using IoT-Integrated Federated Learning in Intrusion Detection. Data 2023, 8, 83. https://doi.org/10.3390/data8050083
Kollu VN, Janarthanan V, Karupusamy M, Ramachandran M. Cloud-Based Smart Contract Analysis in FinTech Using IoT-Integrated Federated Learning in Intrusion Detection. Data. 2023; 8(5):83. https://doi.org/10.3390/data8050083
Chicago/Turabian StyleKollu, Venkatagurunatham Naidu, Vijayaraj Janarthanan, Muthulakshmi Karupusamy, and Manikandan Ramachandran. 2023. "Cloud-Based Smart Contract Analysis in FinTech Using IoT-Integrated Federated Learning in Intrusion Detection" Data 8, no. 5: 83. https://doi.org/10.3390/data8050083
APA StyleKollu, V. N., Janarthanan, V., Karupusamy, M., & Ramachandran, M. (2023). Cloud-Based Smart Contract Analysis in FinTech Using IoT-Integrated Federated Learning in Intrusion Detection. Data, 8(5), 83. https://doi.org/10.3390/data8050083