Modeling Average Pressure and Volume Fraction of a Fluidized Bed Using Data-Driven Smart Proxy



Abstract
:1. Introduction
- Developing a unique engineering-based data preparation technology that optimizes the training of the neural networks. This innovative technique incorporates supervised fuzzy cluster analysis to:
- Identify the most influential parameters for the training process, and
- Identify the optimum partitioning of the data for training, calibration, and validation.
- Using an “ensemble-based” approach to building the smart proxy, taking advantage of multiple neural networks and intelligent agents to accomplish the objectives of the project.
2. Materials and Methods
2.1. MFIX
- is the phase volume fraction
- is the phase density
- is the phase velocity vector
- is mass transfer between phases
- is the phase stress tensor
- is the interaction force representing the momentum transfer between the phases
2.2. CFD Simulation Setup
2.3. Data Preparation
2.3.1. Tier System
2.3.2. Input Matrix
2.3.3. Neural Network Architecture
2.3.4. Data Partitioning
3. Proof of Concept
3.1. Early Time Versus Late Time
3.2. Cascading Versus Non-cascading in Time
3.3. Training with Multiple Time-Steps
4. Model Verification
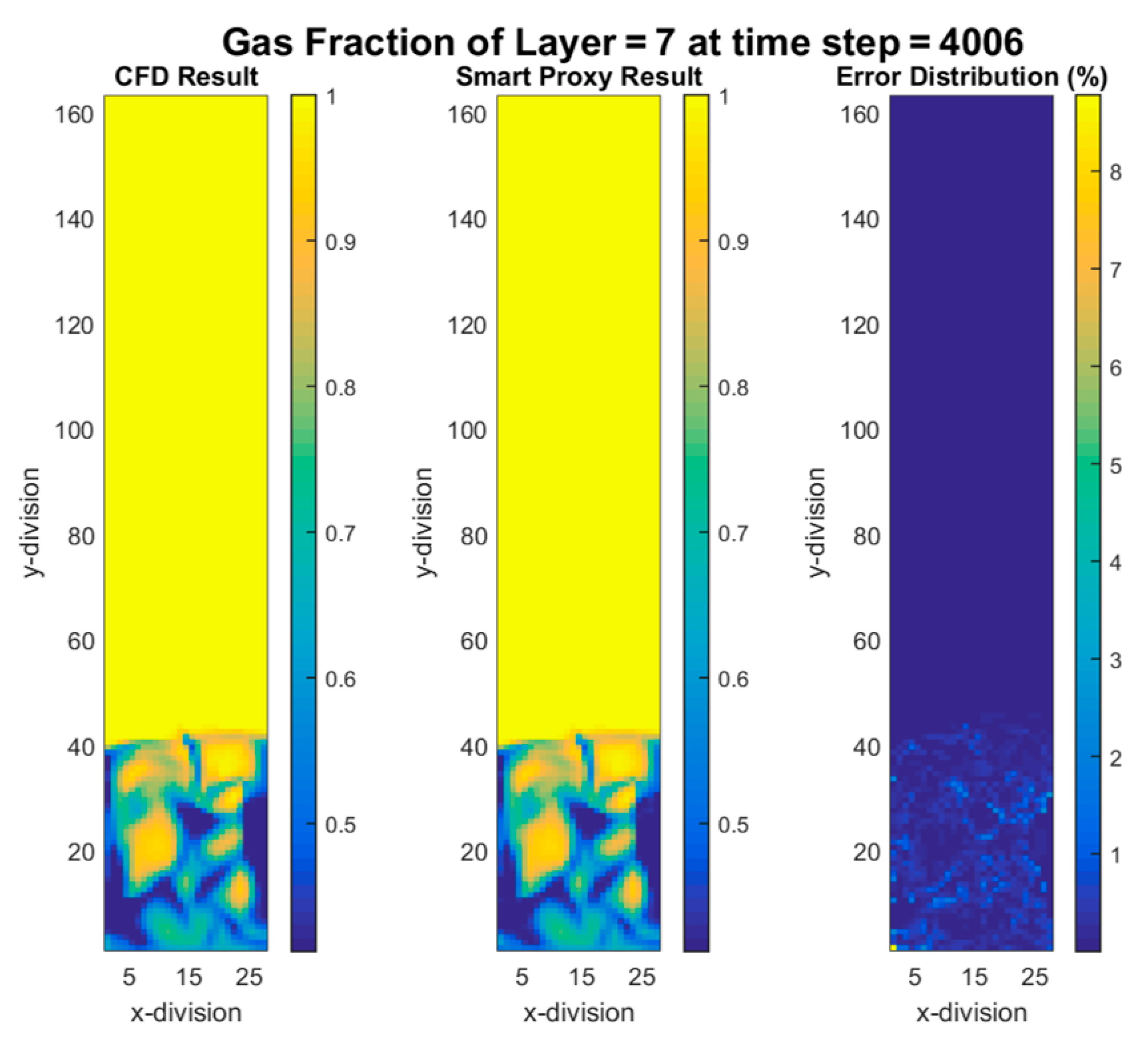
4.1. Layer Level
4.2. Training for Gas Pressure Using Static Parameters
4.3. Training for Gas Pressure Using Static and Dynamic Parameters
4.4. Time Average
5. Conclusion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
Fluid-Solids Momentum Transfer
Solids-Solids Momentum Transfer
References
- Gel, A.; Garg, R.; Tong, C.; Shahnam, M.; Guenther, C. Applying uncertainty quantification to multiphase flow computational fluid dynamics. Powder Technol. 2013, 242, 27–39. [Google Scholar] [CrossRef]
- Gel, A.; Shahnam, M.; Subramaniyan, A.K. Quantifying uncertainty of a reacting multiphase flow in a bench-scale fluidized bed gasifier. A Bayesian approach. Powder Technol. 2017, 311, 484–495. [Google Scholar] [CrossRef]
- Shahnam, M.; Musser, J.; Subramaniyan, A.K.; Dietiker, J.-F.; Gel, A. Nonintrusive Uncertainty Quantification of Computational Fluid Dynamics Simulations of a Bench-Scale Fluidized-Bed Gasifier. Ind. Eng. Chem. Res. 2016, 55, 12477–12490. [Google Scholar]
- Shahnam, M.; Gel, A.; Dietiker, J.F.; Subramaniyan, A.K.; Musser, J. The Effect of Grid Resolution and Reaction Models in Simulation of a Fluidized Bed Gasifier through Non-intrusive Uncertainty Quantification Techniques. ASME J. Verif. Valid. Uncert. Quantif. 2016, 1, 9. [Google Scholar]
- Fullmer, W.; Hrenya, C. Quantitative assessment of fine-grid kinetic theory based predictions of mean-slip in unbounded fluidization. AIChE J. 2016, 62, 11–17. [Google Scholar] [CrossRef]
- Amini, S.; Mohaghegh, S.; Gaskari, R.; Bromhal, G. Pattern Recognition and Data-Driven Analytics for Fast and Accurate Replication of Complex Numerical Reservoir Models at the Grid Block Level. In Proceedings of the SPE Intelligent Energy International Conference and Exhibition, Utrecht, The Netherlands, 1–3 April 2014. [Google Scholar]
- Mohaghegh, S.D. Converting detail reservoir simulation models into effective reservoir management tools using SRMs; case study three green fields in Saudi Arabia. Int. J. Oil Gas Coal Technol. 2014, 7, 115. [Google Scholar] [CrossRef]
- Mohaghegh, S.D.; Abdulla, F.; Gaskari, R.; Maysami, M.; Abdou, M. Smart Proxy: An Innovative Reservoir Management Tool; Case Study of a Giant Mature Oilfield in the UAE. In Proceedings of the Abu Dhabi International Petroleum Exhibition & Conference, Abu Dhabi, UAE, 9–12 November 2015. [Google Scholar]
- Shahkarami, A.; Mohaghegh, S.D.; Gholami, V.; Haghighat, A.; Moreno, D. Modeling Pressure and Saturation Distribution in a CO2 Storage Project Using a Surrogate Reservoir Model (SRM). Greenh. Gases Sci. Technol. 2014, 4, 289–315. [Google Scholar] [CrossRef]
- Krishnamurti, T.N.; Kishtawal, C.M.; Zhang, Z.; LaRow, T.; Bachiochi, D.; Williford, E.; Gadgil, S.; Surendran, S. Multimodel Ensemble Forecasts for Weather and Seasonal Climate. J. Clim. 2000, 13, 4196–4216. [Google Scholar] [CrossRef]
- Keane, A.J.; Prasanth, B.N. Computational Approaches for Aerospace Design: The Pursuit of Excellence; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2005. [Google Scholar]
- Esmaili, S.; Mohaghegh, S.D. Full Field Reservoir Modeling of Shale Assets using Advance Data-driven Analytics. Geosci. Front. 2016, 7, 11–20. [Google Scholar] [CrossRef]
- Mohaghegh, S.D. Data Driven Reservoir Modeling; Society of Petroleum Engineers (SPE): Richardson, TX, USA, 2017. [Google Scholar]
- Kalantari-Dahaghi, A.; Mohaghegh, S.; Esmaili, S. Data-driven proxy at hydraulic fracture cluster level: A technique for efficient CO2- enhanced gas recovery and storage assessment in shale reservoir. J. Nat. Gas Sci. Eng. 2015, 27, 515–530. [Google Scholar] [CrossRef] [Green Version]
- Sun, W.; Durlofsky, L.J. A New Data-Space Inversion Procedure for Efficient Uncertainty Quantification in Subsurface Flow Problems. Math. Geol. 2017, 49, 679–715. [Google Scholar] [CrossRef]
- Satija, A.; Scheidt, C.; Li, L.; Caers, J. Direct forecasting of reservoir performance using production data without history matching. Comput. Geosci. 2017, 21, 315–333. [Google Scholar] [CrossRef]
- Jeong, H.; Sun, A.Y.; Lee, J.; Min, B. A learning-based data-driven forecast approach for predicting future reservoir performance. Adv. Water Resour. 2018, 118, 95–109. [Google Scholar] [CrossRef]
- Ansari, A.; Mohaghegh, S.; Shahnam, M.; Dietiker, J.F.; Takbiri Borujeni, A.; Fathi, E. Data Driven Smart Proxy for CFD, Application of Big Data Analytics & Machine Learning in Computational Fluid Dynamics, Part One: Proof of Concept; NETL-PUB-21574, NETL Technical Report Series; U.S. Department of Energy, National Energy Technology Laboratory: Morgantown, WV, USA, 2017. Available online: http://www.osti.gov/scitech/servlets/purl/1417305 (accessed on 17 November 2017). [CrossRef]
- Ansari, A.; Mohaghegh, S.; Shahnam, M.; Dietiker, J.F.; Li, T. Data Driven Smart Proxy for CFD, Application of Big Data Analytics & Machine Learning in Computational Fluid Dynamics, Part Two: Model Building at the Cell Level; NETL-PUB-21634; NETL Technical Report Series; U.S. Department of Energy, National Energy Technology Laboratory: Morgantown, WV, USA, 2018. [CrossRef]
- Ansari, A.; Mohaghegh, S.; Shahnam, M.; Dietiker, J.F.; Li, T.; Gel, A. Data Driven Smart Proxy for CFD, Application of Big Data Analytics & Machine Learning in Computational Fluid Dynamics, Part Three: Model Building at the Layer Level; NETL-PUB-21860; NETL Technical Report Series; U.S. Department of Energy, National Energy Technology Laboratory: Morgantown, WV, USA, 2018. [CrossRef]
- Ansari, A. Developing a Smart Proxy for Fluidized Bed Using Machine Learning; West Virginia University: Morgantown, WV, USA, January 2016. [Google Scholar]
- Hosseini Boosari, S.S. Developing a Smart Proxy for Predicting the Fluid Dynamic in DamBreak Flow Simulation by Using Artificial Intelligence; West Virginia University: Morgantown, WV, USA, January 2017. [Google Scholar]
- Boosari, S.H. Predicting the Dynamic Parameters of Multiphase Flow in CFD (Dam-Break Simulation) Using Artificial Intelligence-(Cascading Deployment). Fluids 2019, 4, 44. [Google Scholar] [CrossRef]
- NETL Multiphase Flow Science. MFiX Software Suite; National Energy Technology Laboratory: Morgantown, WV, USA, 2016. Available online: http://mfix.netl.doe.gov (accessed on 1 January 2016).
- Syamlal, M.; Rogers, W.; OBrien, T.J. MFiX Documentation Theory Guide. Available online: https://mfix.netl.doe.gov/download/mfix/mfix_legacy_manual/Theory.pdf (accessed on 1 December 1993).
- Benyahia, S.; Syamlal, M. Summary of MFiX Equations. 2012. Available online: https://mfix.netl.doe.gov/download/mfix/mfix_current_documentation/MFIXEquations2012-1.pdf (accessed on 1 January 2012).





















































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Grid Classification | Grid No. (X × Y × Z) | Grid Resolution | No. of Cells |
|---|---|---|---|
| Coarse | 8 × 48 × 8 | 15 mm | 3,072 |
| Medium | 12 × 72 × 12 | 10 mm | 10,368 |
| Fine | 18 × 108 × 18 | 6.6 mm | 34,992 |
| Very Fine | 27 × 162 × 27 | 4.4 mm | 118,098 |
| Symbol | Description |
|---|---|
| Gas volume fraction | |
| Gas Pressure | |
| Solid Pressure | |
| Velocity of gas in x direction | |
| Velocity of gas in y direction | |
| Velocity of gas in z direction | |
| Velocity of solid in x direction | |
| Velocity of solid in y direction | |
| Velocity of solid in z direction |
| Network Type | Feed-Forward Back Propagation |
|---|---|
| Training Function | Levenberg-Marquardt |
| Adaption Learning Function | LEARNGDM |
| Performance Function | MSE |
| Transfer Function | TANSIG |
| Data | Training | Calibration | Validation |
|---|---|---|---|
| Percentage of data (%) | 70 | 15 | 15 |
| Method | Task | Required Time |
|---|---|---|
| CFD | Modeling and Simulation Time | 3 days on 4 CPUs |
| Smart Proxy | Data Preparation (CFD simulation) | 3 days for each case |
| Model Training | 24 to 36 hours | |
| Generating the results for a new case | 180 s on 1 CPU |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ansari, A.; Mohaghegh, S.D.; Shahnam, M.; Dietiker, J.-F. Modeling Average Pressure and Volume Fraction of a Fluidized Bed Using Data-Driven Smart Proxy. Fluids 2019, 4, 123. https://doi.org/10.3390/fluids4030123
Ansari A, Mohaghegh SD, Shahnam M, Dietiker J-F. Modeling Average Pressure and Volume Fraction of a Fluidized Bed Using Data-Driven Smart Proxy. Fluids. 2019; 4(3):123. https://doi.org/10.3390/fluids4030123
Chicago/Turabian StyleAnsari, Amir, Shahab D. Mohaghegh, Mehrdad Shahnam, and Jean-François Dietiker. 2019. "Modeling Average Pressure and Volume Fraction of a Fluidized Bed Using Data-Driven Smart Proxy" Fluids 4, no. 3: 123. https://doi.org/10.3390/fluids4030123
APA StyleAnsari, A., Mohaghegh, S. D., Shahnam, M., & Dietiker, J. -F. (2019). Modeling Average Pressure and Volume Fraction of a Fluidized Bed Using Data-Driven Smart Proxy. Fluids, 4(3), 123. https://doi.org/10.3390/fluids4030123