Dakota provides in the output file the discretized PDFs of the response functions, i.e., the probability density values inside each ‘bin’, which corresponds to a pre-definite response level.
6.1. Surrogate-Based UQ Main Outcomes
The Surrogate-based UQ approach consists in the application of the Latin Hypercube sampling on the generated meta-model, in order to evaluate the response functions statistics.
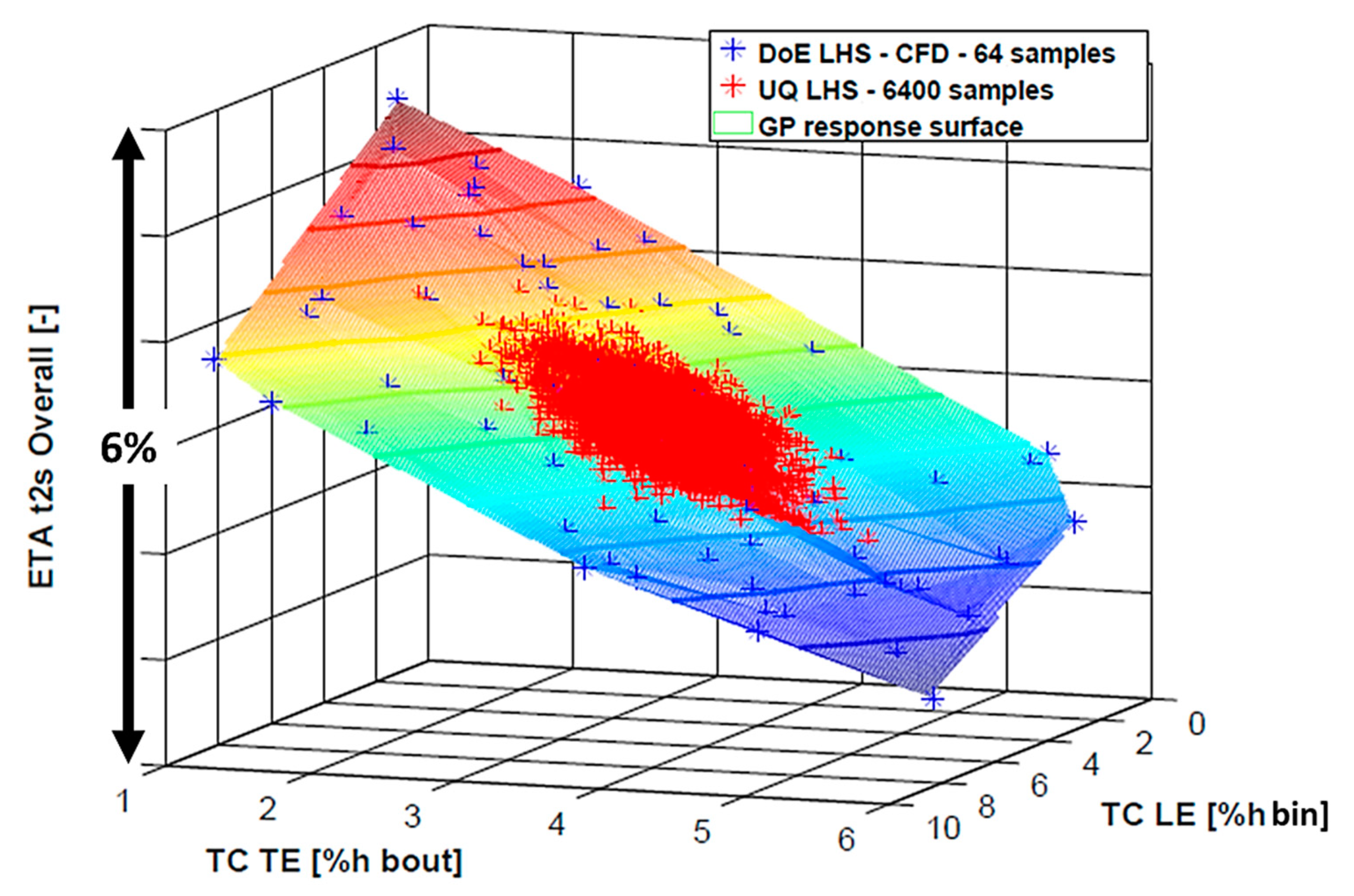
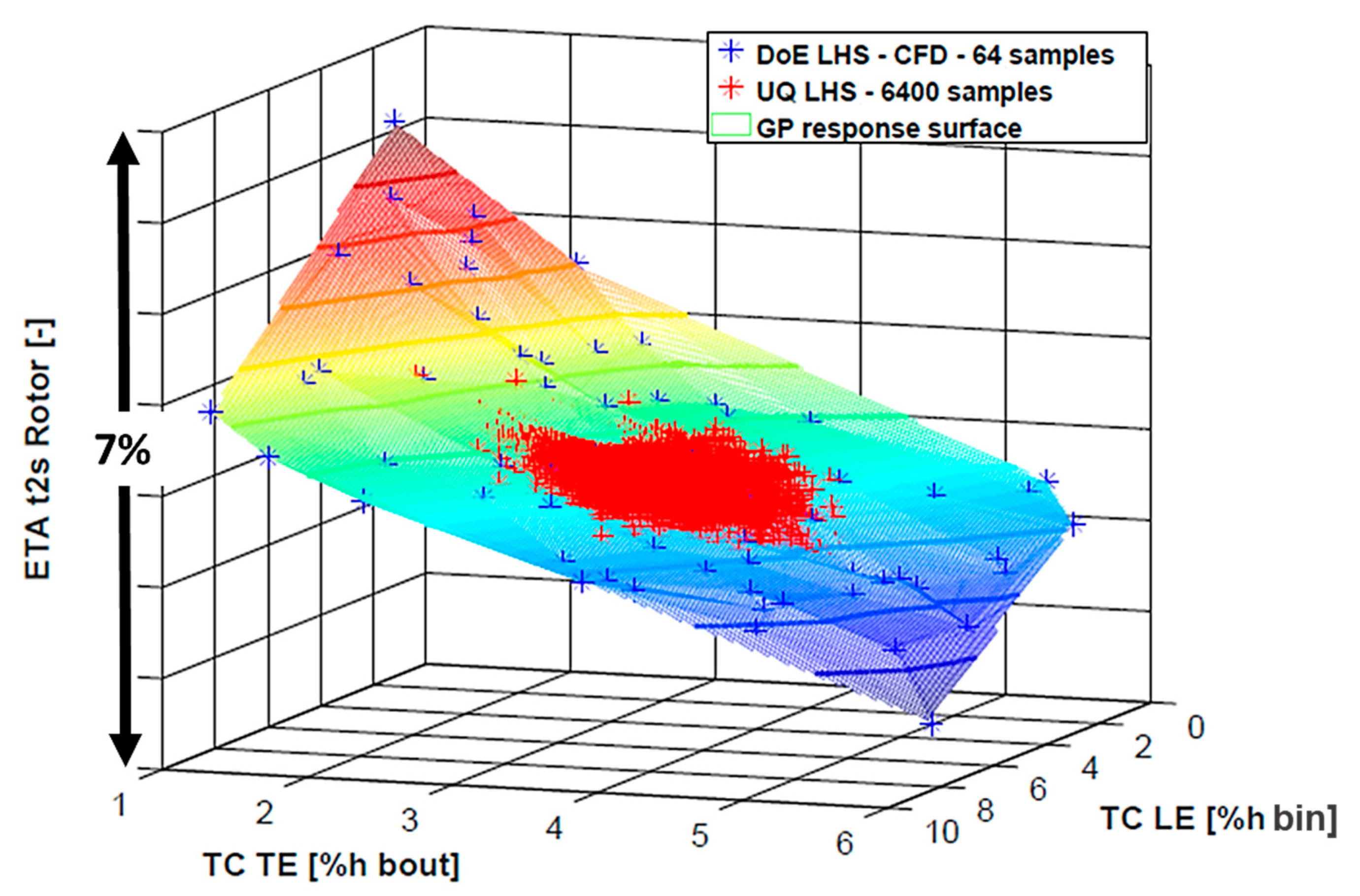
An example of the surrogate generated with the SB-UQ approach is reported in
Figure 5 for the overall total to static turbine efficiency (Equation (6)).
Contours have been reported on the response surface to display the overall variation in turbine efficiency as a function of the input parameters (tip clearances at rotor LE and TE). The blue scattered points represent the 64 points of the DoE, which correspond to 64 different combinations of rotor clearance values, i.e., to a database of 64 CFD simulations. This computational effort is necessary to build a reliable surrogate of the CFD model through the RSM (Gaussian Process Equation (7)): the overall efficiency variation inside the DoE is about 6% (see
Figure 5 vertical axis).
In order to compute the statistics of the response function, the SB-UQ algorithm performs 6400 (2 orders of magnitude greater than the DoE) function evaluations on the meta-model, which are visible in red scatter in
Figure 5. The discretized probability distribution of the overall turbine efficiency is plotted in
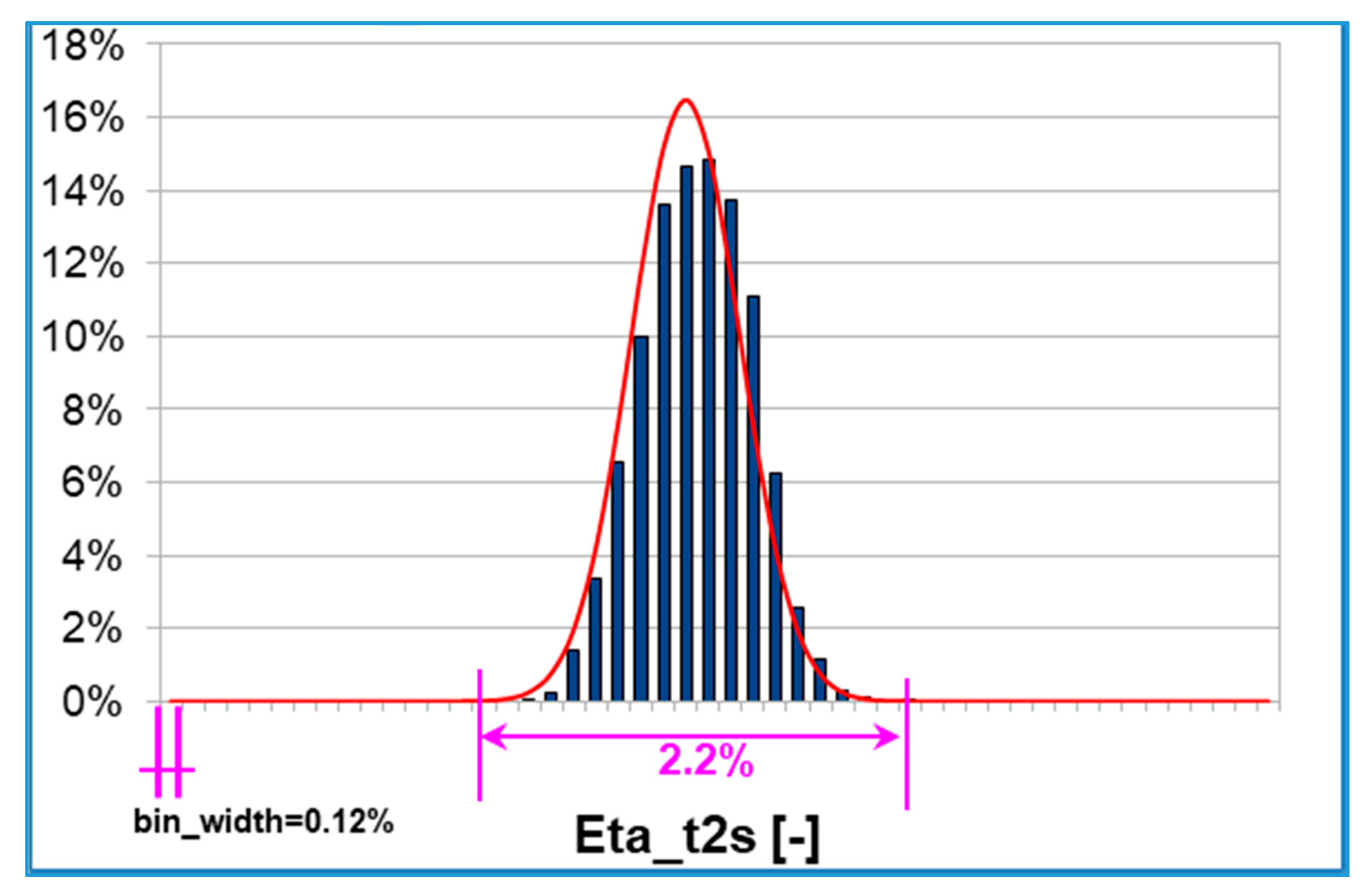
Figure 6, where each bin of the histogram is equal to a 0.12% efficiency difference.
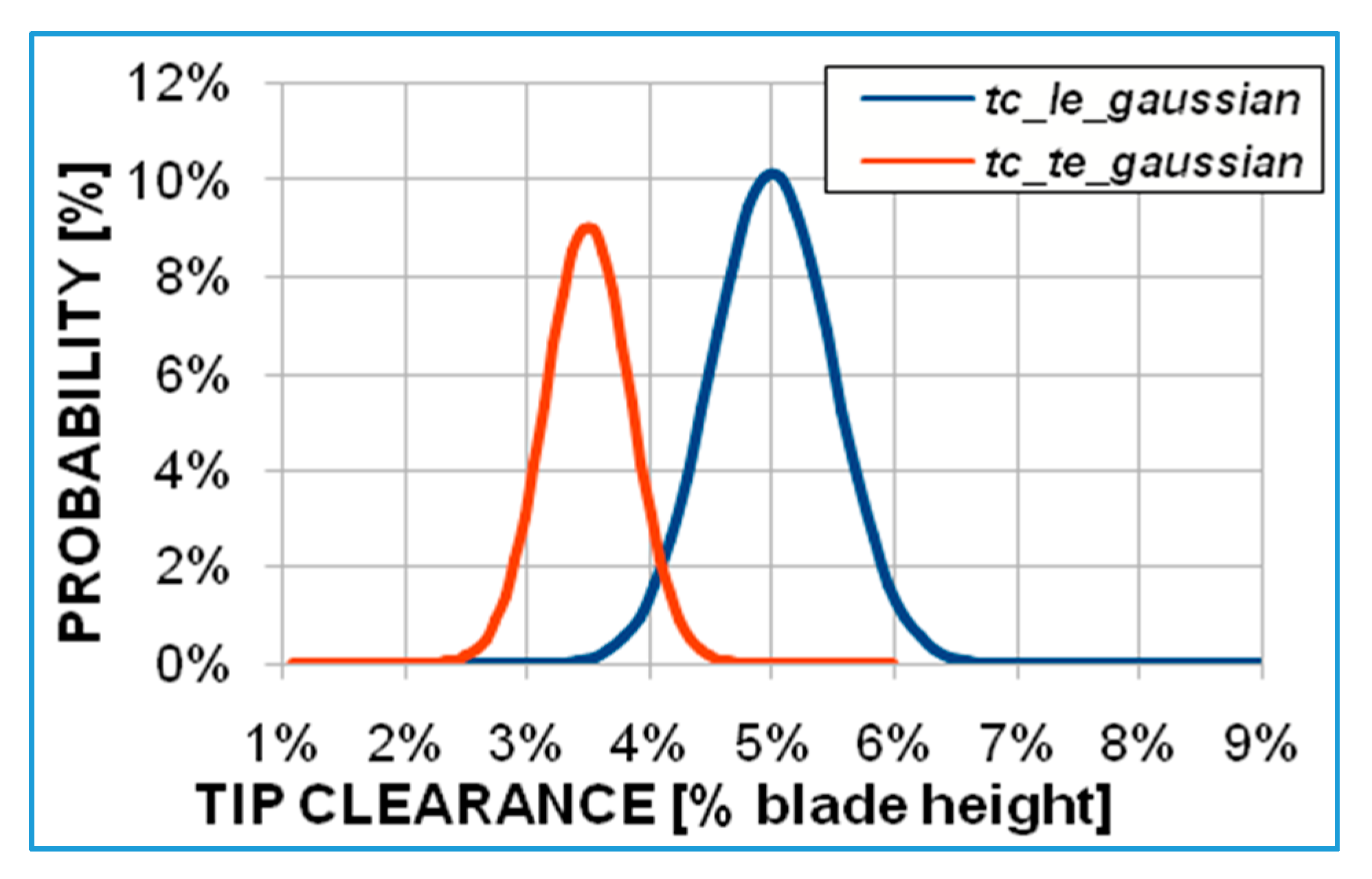
The input uncertainties (
Figure 4) correspond to a 2.2% efficiency variation range, where it is possible to fall with non-zero probability. This is a significant outcome: for a fixed turbine operating point subject to rotor tip gap uncertainties (see
Table 2) the overall efficiency variability is about 2%. The red line plotted in
Figure 6 over the probability bars represents the corresponding Gaussian distribution with the same average and standard deviation of the discretized PDF computed by Dakota.
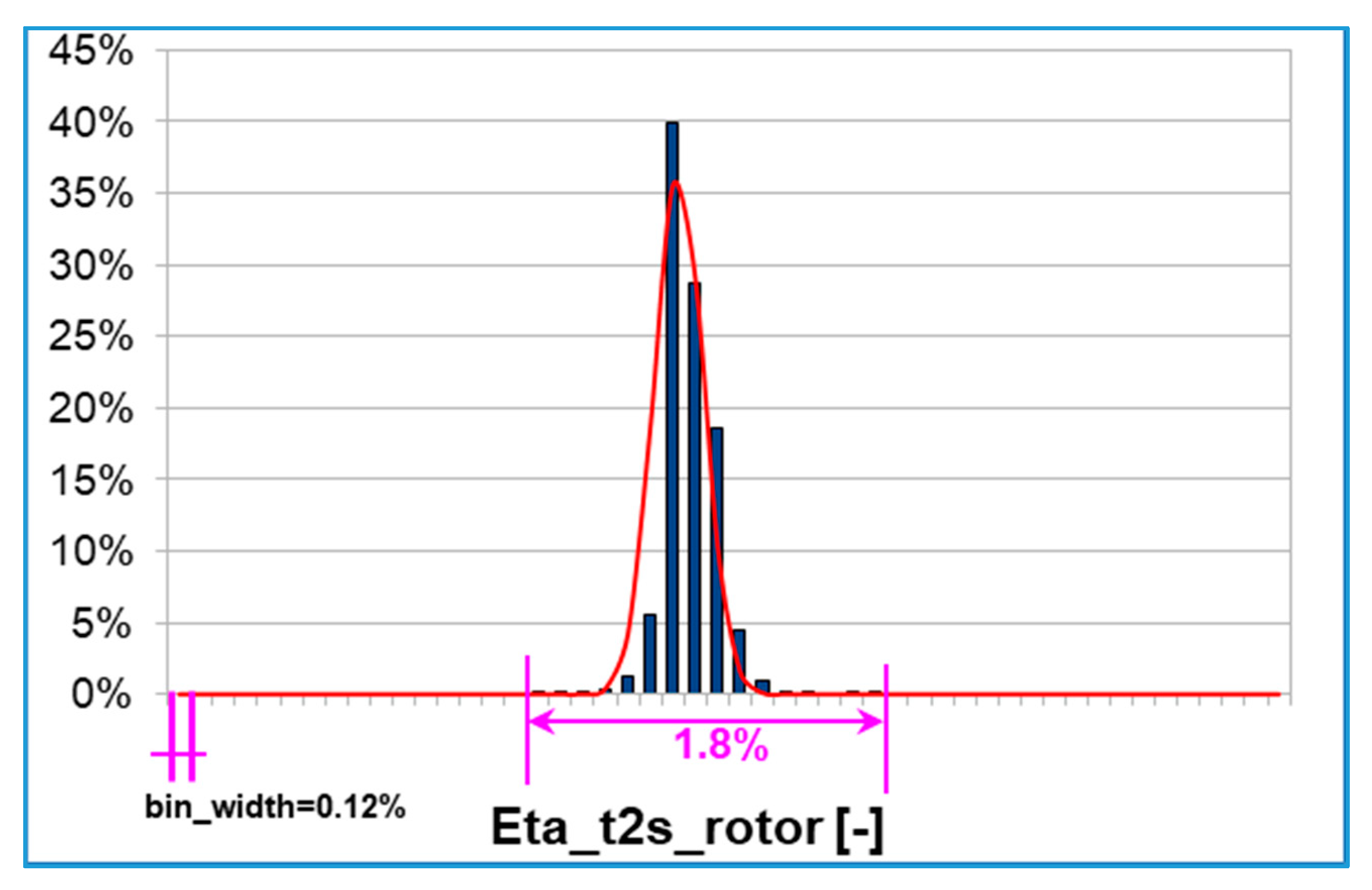
Rotor total to static efficiency (calculated with the rotor expansion ratio
) has a slightly different behavior and a wider variability inside the DoE: about 7% variation as indicated in
Figure 7.
The rotor efficiency larger sensitivity (compare
Figure 5,
Figure 6 and
Figure 7) can be explained considering that tip gap variations directly affect the rotor efficiency while the stage efficiency also includes volute and tailpipe losses that tend to hide the effect of tip clearance gap.
However, the rotor total to static efficiency probability distribution is sharper and less dispersed than the previous one (compare
Figure 6,
Figure 7 and
Figure 8).
Among the statistical quantities provided by the UQ analysis, the Skewness (Equation (13)) and the excess Kurtosis (Equation (14)) are obtained from the following equations:
where
is the mean,
the standard deviation and
E is the expectation operator.
The skewness (Sk) is a measure of the asymmetry of the probability distribution of a real-valued random variable about its mean, while the excess Kurtosis (Ku) describes the shape of a PDF with respect to the Gaussian distribution having Ku = 0.
The corresponding values of these statistics moments are reported in
Table 3 and the following considerations can be drawn:
overall efficiency: comparing the discretized probability with the corresponding Gaussian (
Figure 6) it is clear that the distribution is left-skewed (Sk < 0), i.e., the left tail is longer and the mass of the distribution is concentrated on the right of the figure. Moreover, Ku < 0 and the distribution is defined ‘platykurtic’, i.e., it is flatter than the corresponding Gaussian, resulting in thinner tails;
rotor efficiency: the distribution is right-skewed (Sk > 0) instead, i.e., the right tail is longer and the mass of the distribution is concentrated on the left of the figure. Ku > 0 and the distribution is defined ‘leptokurtic’, i.e., it is sharper than the corresponding Gaussian, resulting in fatter tails.
The difference between rotor and stage efficiency probability distributions can be explained comparing the corresponding response surfaces. In
Figure 7 the surface has an inflection at the tip clearance average values. Since the input distributions are Gaussian, the majority of UQ samples falls around the mean values giving a lower variability of the rotor efficiency.
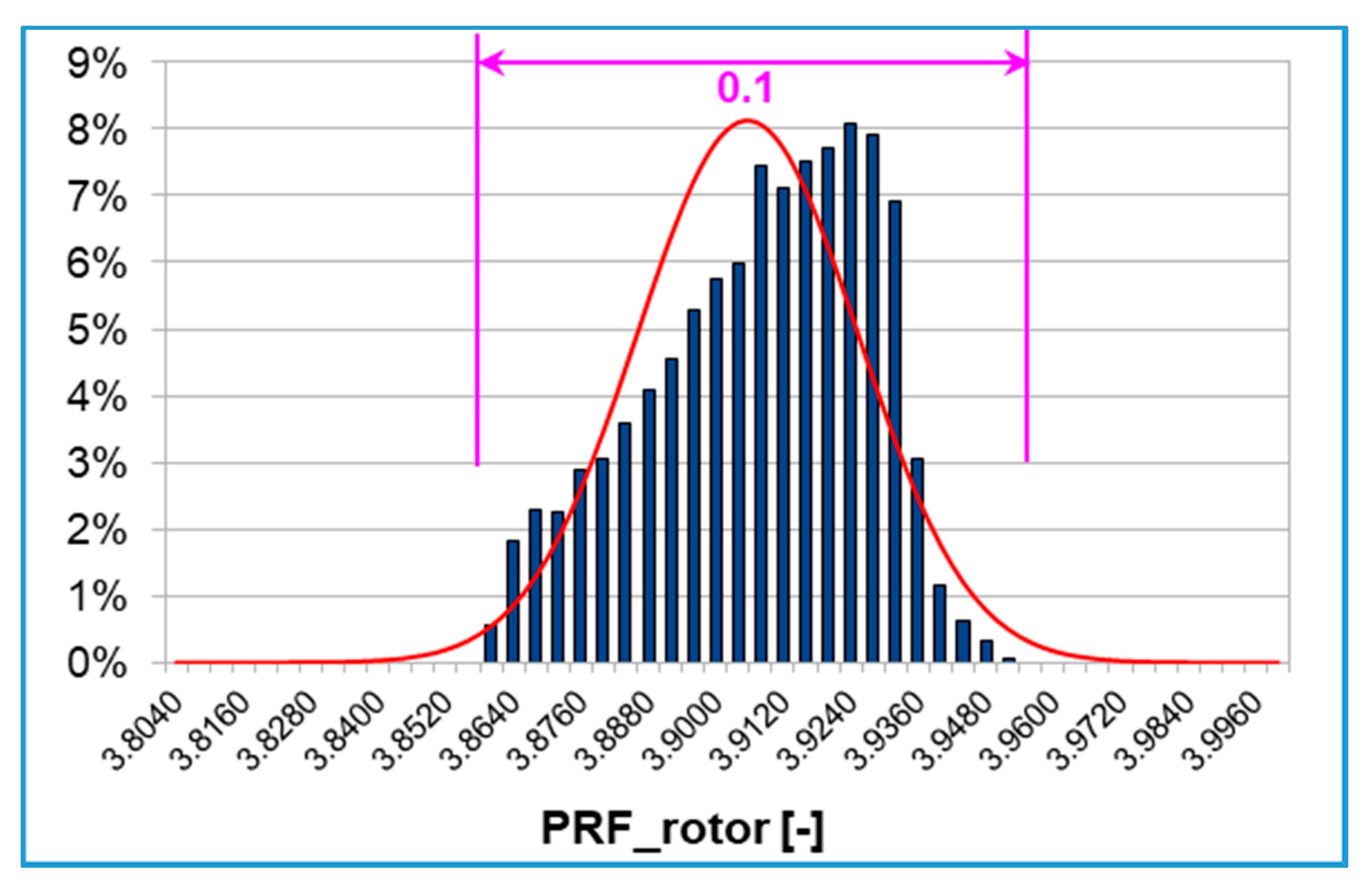
The abovementioned inflection in rotor efficiency response surface is due to the peculiar behavior of the rotor pressure ratio, whose response surface is shown in
Figure 9.
The resulting PDF is displayed in
Figure 10 where the input uncertainties correspond to about 0.1 rotor pressure ratio variation range. The rotor pressure ratio probability distribution is almost uniform within this range with the highest peaks at around 8%.
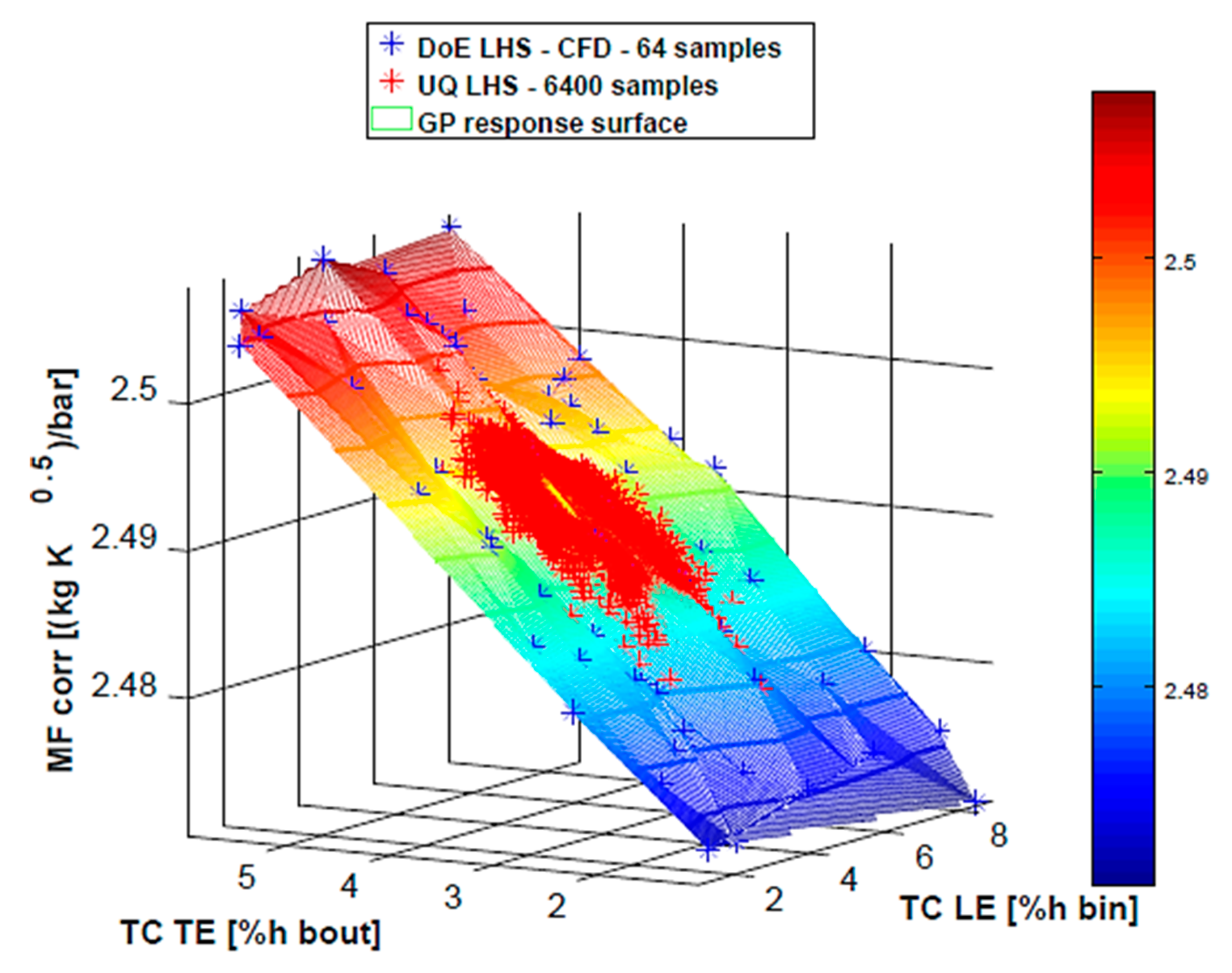
Figure 11 shows the response surface of the mass flow parameter with the dataset points. It is evident from the surface gradient that the tip gap at blade TE has a higher influence on the MFP than the tip gap at the blade LE.
The TE tip clearance reduction (i.e., TE blade tip closer to the shroud) leads to an appreciable lowering of the mass flow parameter, i.e., of the turbine exhaust gas swallowing capacity. This result matches the radial turbines design theory where the aerodynamic blockage in the exducer (final part of the blade) limits the impeller blades number.
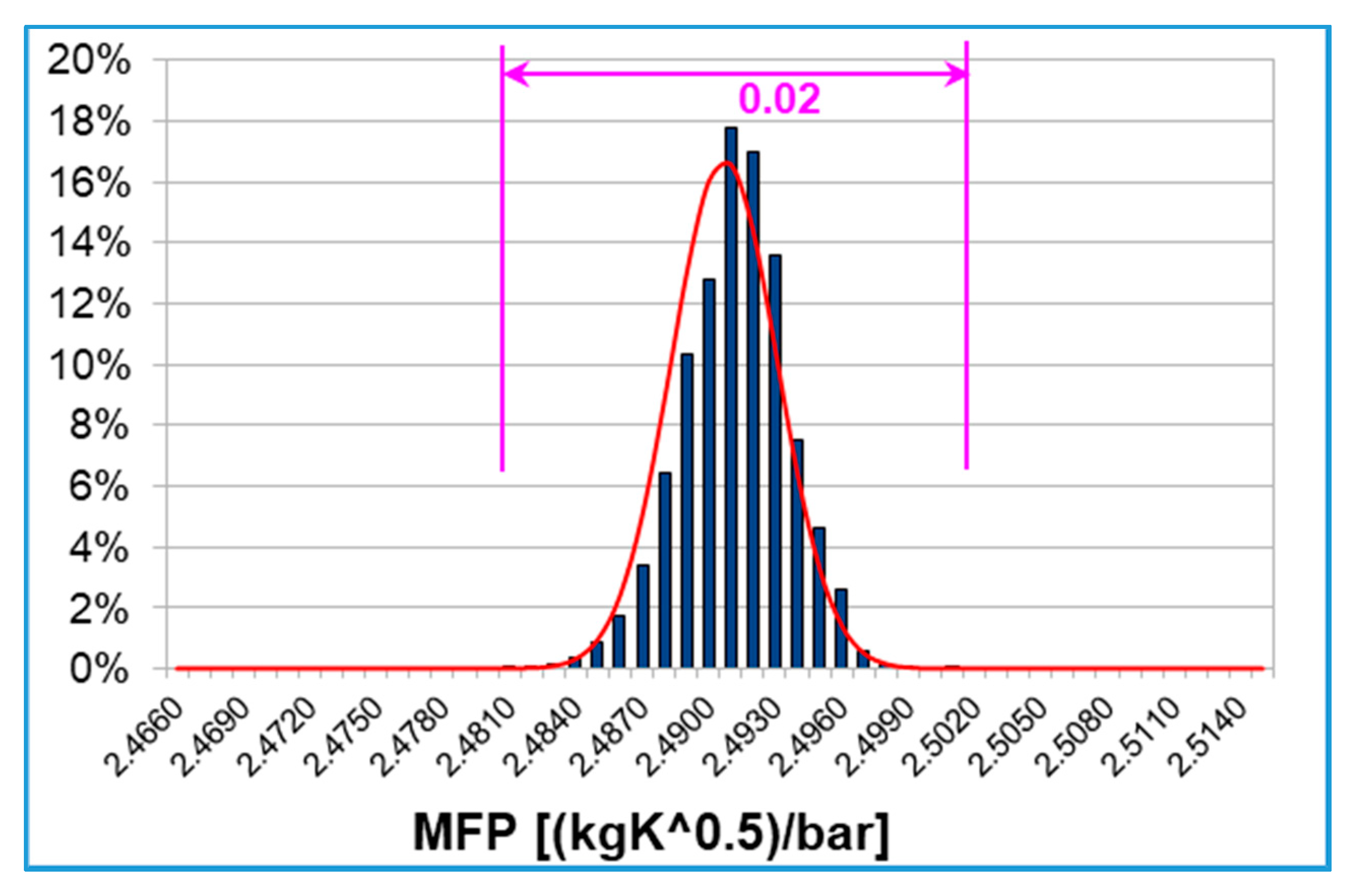
The MFP discretized probability distribution is reported in
Figure 12. The 6400 results of the sampling-based UQ algorithm are concentrated in a small range of 0.02 [(kgK
0.5)/bar], equal to 0.8% of the mean value of the distribution. It can be observed that tip gap uncertainties have a limited impact on turbine mass flow, which is slightly affected by TE tip clearance.
6.2. Surrogate Model Validation
The surrogate models given by Dakota’s Surfpack toolset allows to compute diagnostics metrics on the basis of [
8]:
- 1)
simple prediction error with respect to the training data. In this case the points are those used to train the model;
- 2)
prediction error estimated by cross-validation, when the points are selectively omitted from the build;
- 3)
prediction error with respect to challenge data, which are supplementary points provided by the user.
The resulting metrics must be interpreted very carefully; in case of interpolatory models, like those used for the surrogate generation, simple prediction error (1) will almost always be zero. The determination coefficient () is meaningful for polynomial models, but less for other model types.
In order to check the meta-model reliability, a cross-validation was performed. At first the k-fold cross-validation is considered: the DoE dataset is divided into k partitions and k meta-models are generated, each excluding the k-th partition of training data. Each surrogate is tested at the points that were excluded for the generation and the user-specified diagnostic metrics are computed with respect to the held-out data [
8]. The results obtained from a 4-fold cross-validation are reported in
Table 4, including the Root Mean Squared, the Mean Absolute Value and the Maximum Absolute Value of the prediction error (calculated between the observed value and the surrogate model prediction for the training data points). The average and maximum absolute values of the prediction error (last two rows of
Table 4) are reported in relative percentage form with respect to the corresponding average values of the 64-points DoE.
The results confirm the reliability of the model, with average errors never above 0.5% and maximum errors contained within 1.5%. In addition, the Leave-one-out cross-validation or Prediction Error Sum of Squares (PRESS) was performed. In this special case of k-fold cross-validation the number of partitions is equal to the number of data points. The results given by this analysis are summarized in
Table 5.
The results of
Table 5 confirm the outcome of the 4-fold cross validation. The maximum error slightly increases (1.71%) as expected because the number of partitions used to evaluate the statistical quantities corresponds to the number of training points. Maximum errors within 2% are considered acceptable and confirm the validity of the UQ results discussed in
Section 6.1. The SB-UQ approach is therefore taken as reference to assess the quality of the PDFs obtained with PCE of different orders.
6.3. PCE: Results Comparison among Different Expansion Orders
The Polynomial Chaos Expansion technique requires the order of expansion of the multivariate polynomial approximation and the polynomial order bounds for each input variable.
The GP algorithm previously used in the Surrogate-based approach (
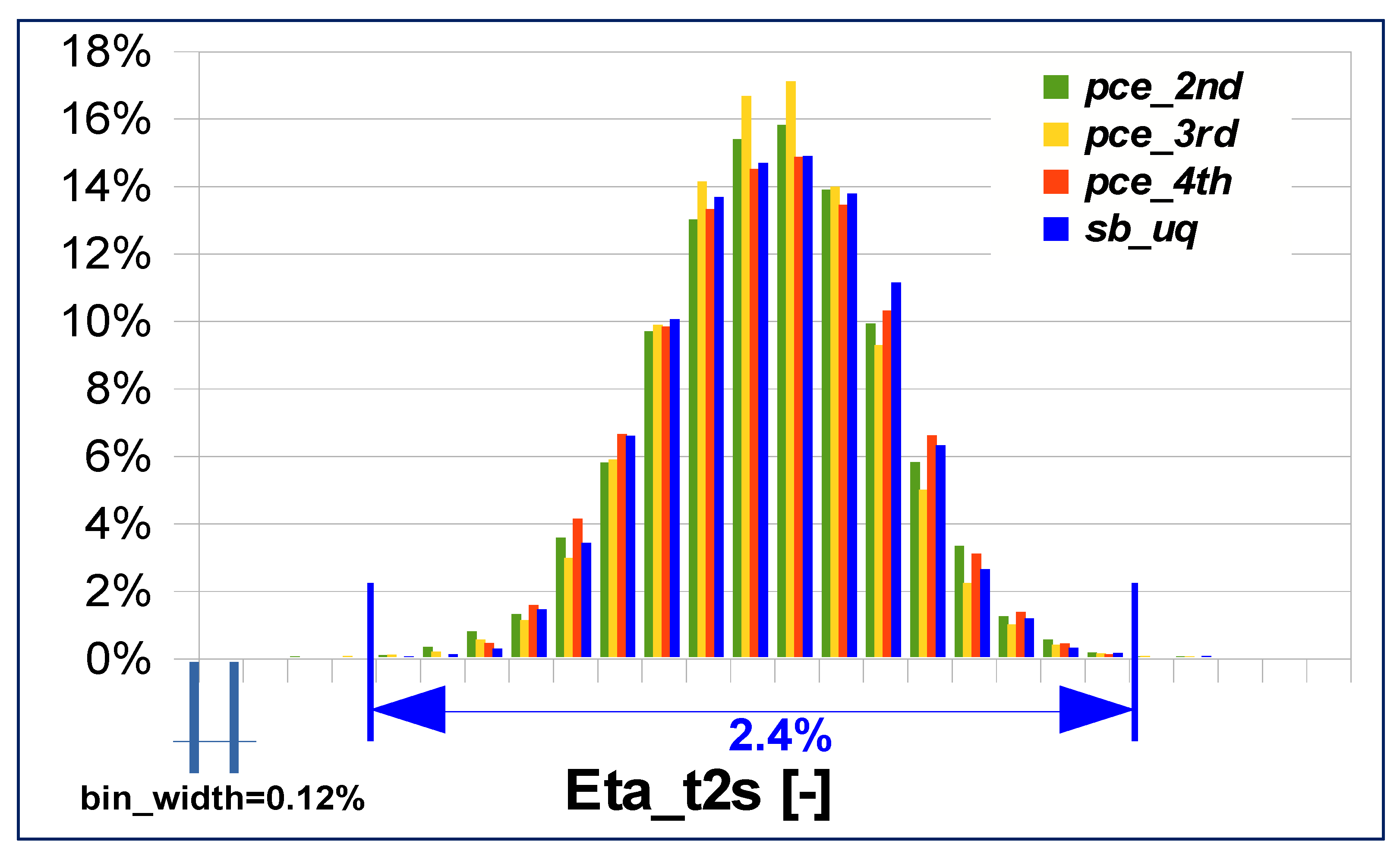
Section 6.1) requests a 2nd order polynomial for the trend function of each response function and the highest total polynomial order of any term in the trend function is 2. However, if no information on the response behavior is available, it is essential to compare the output PDF resulting from different orders of the polynomial expansion. In this paper the results from a 2nd, 3rd and 4th order polynomial expansions are compared, in order to give some guidelines for future applications of UQ approaches on twin scroll radial turbines. The comparison of the overall total to static efficiency discretized PDFs is shown in
Figure 13.
It is interesting to note that 2nd and 4th order PDFs are more similar close to the mean value, while 3rd order polynomial expansion PDF differs from the previous ones, with higher probability peaks close to the distributions average value.
If the SB-UQ distribution is taken as reference, the closest is the 4th order expansion, especially taking into account the central bars, related to higher probability levels. Looking at the absolute maximum probability difference between the PCE and the SB-UQ distributions (
Table 6), the 2nd and 4th differs only for 0.4%.
At this point the question is legitimate: is it worth doing 16 CFD simulations instead of 4 (minimum required number for 4th and 2nd order PCE respectively) for such a small improvement? The answer to this question can be given considering the assembly of all response functions.
One interesting result is that again the 3rd order PCE is the more distant from SB-UQ probability prediction.
Figure 13 and
Table 6 highlight an interesting fact: with the 2nd order PCE it is possible to get an overall efficiency probability distribution which differs from the SB-UQ by a maximum of 1%.
The PCE technique allows to obtain optimal probability predictions with a much lower computational effort: from 64 CFD simulations required for the meta-model to only 4 simulations for the 2nd order multivariate polynomial chaos expansion.
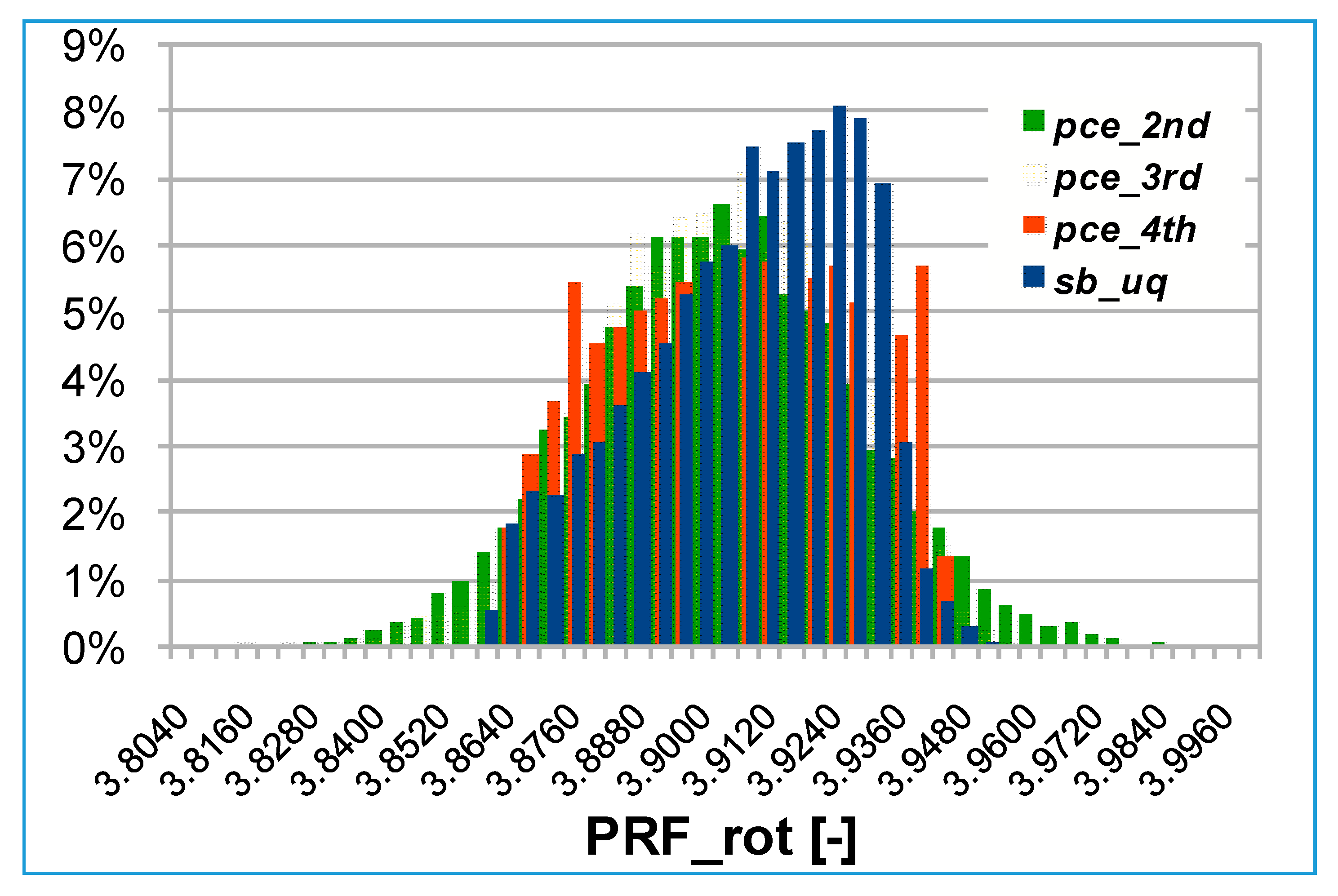
The rotor total to static efficiency is plotted in
Figure 14. It can be noted that, as the overall efficiency, the 3rd order polynomial expansion is the sharpest distribution.
Lower order expansions (2nd and 3rd) show more concentrated probabilities around the PDFs mean value, while 4th order and SB-UQ have a larger probability dispersion.
The difference between the 2nd and 4th order polynomial PDFs is larger in this case as reported in
Table 7; the 2nd order maximum probability difference from the SB-UQ is twice than with the 4th order PCE. The larger difference found in the rotor efficiency probability distributions would require the adoption of a 4th order PCE.
All the probability distributions for the rotor pressure ratio from the PCE differ in shape from the reference; moreover, lower orders (2nd and 3rd) have a larger dispersion within the dataset as shown in
Figure 15.
The maximum percentage difference from the surrogate model is always around 3–4%, as confirmed by
Table 8. However, it must be stressed that the 4th order PCE is the one that qualitatively best fits the results of the SB-UQ.
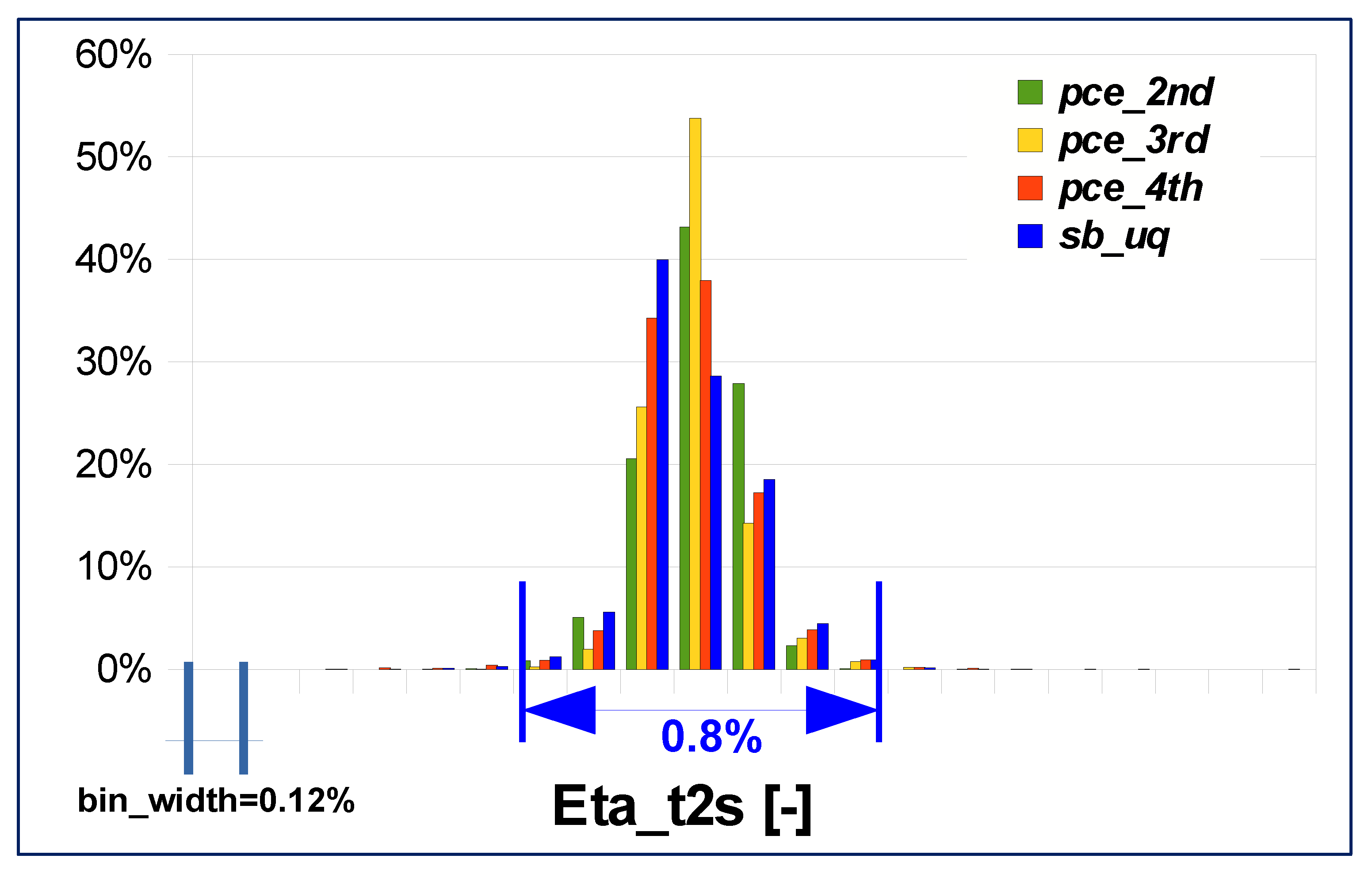
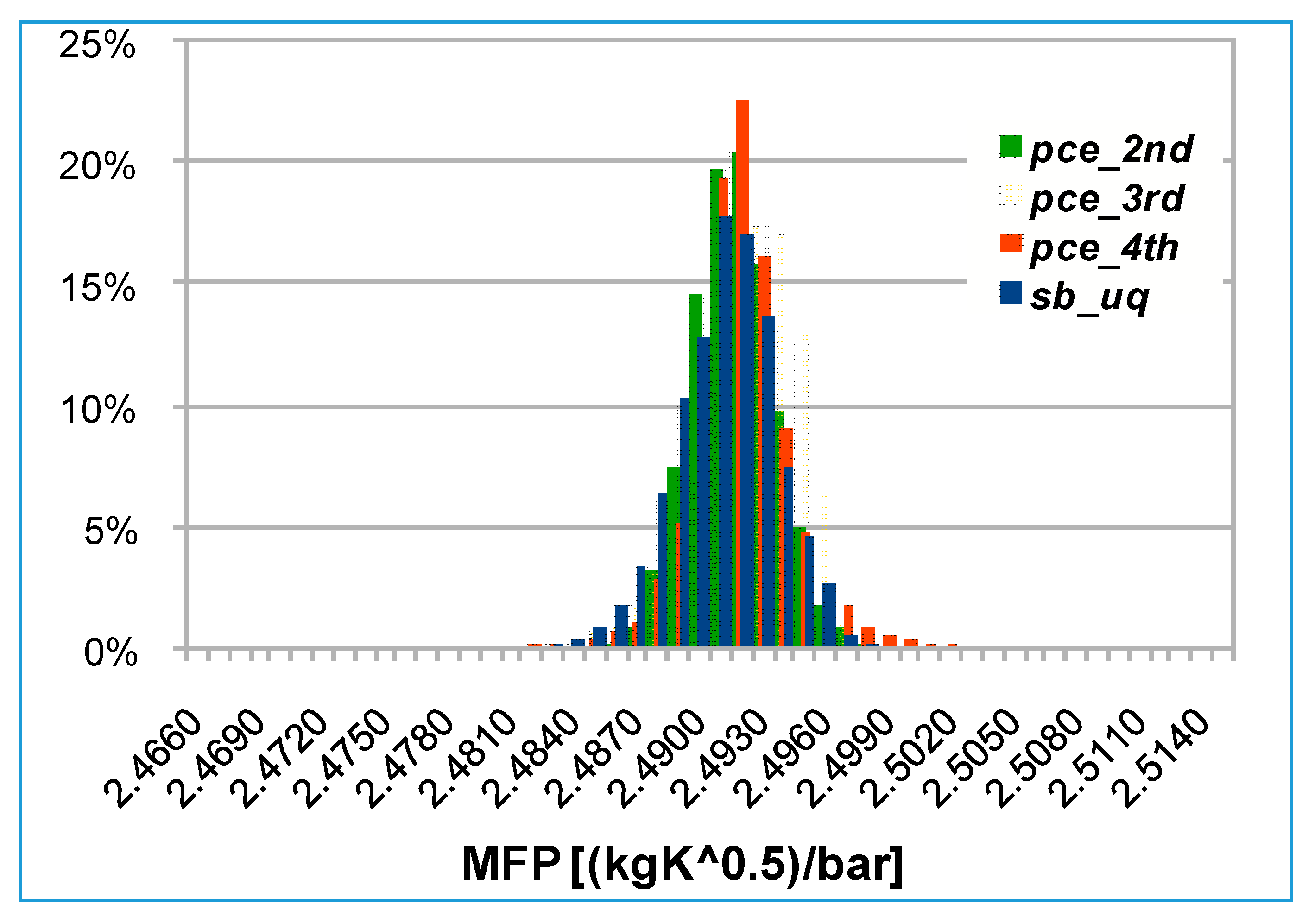
Finally, the mass flow parameter is considered: PDFs are almost entirely contained in a range of amplitude equal to 0.8% of the average value of the distribution (see
Figure 16). Analyzing the data in
Table 9 it can be concluded that quantitatively the 4th order PCE is the solution that best approximates the probability distribution of the surrogate-based approach with a maximum error of about 3%.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}