


Deep Learning Forecasts a Strained Turbulent Flow Velocity Field in Temporal Lagrangian Framework: Comparison of LSTM and GRU



Abstract
:1. Introduction
2. Theory
2.1. Fluid Flow in Lagrangian Framework
2.2. LSTM and GRU Architecture
3. Experiment and Dataset
3.1. Apparatus and Experiment Setup
3.2. Sequential Velocity Dataset
- -
- Velocity component in y direction;
- -
- Velocity component in x direction;
- -
- Time vector specifies the time t for every tracking point.
4. LSTM and GRU Model Set Up
5. Result and Discussion
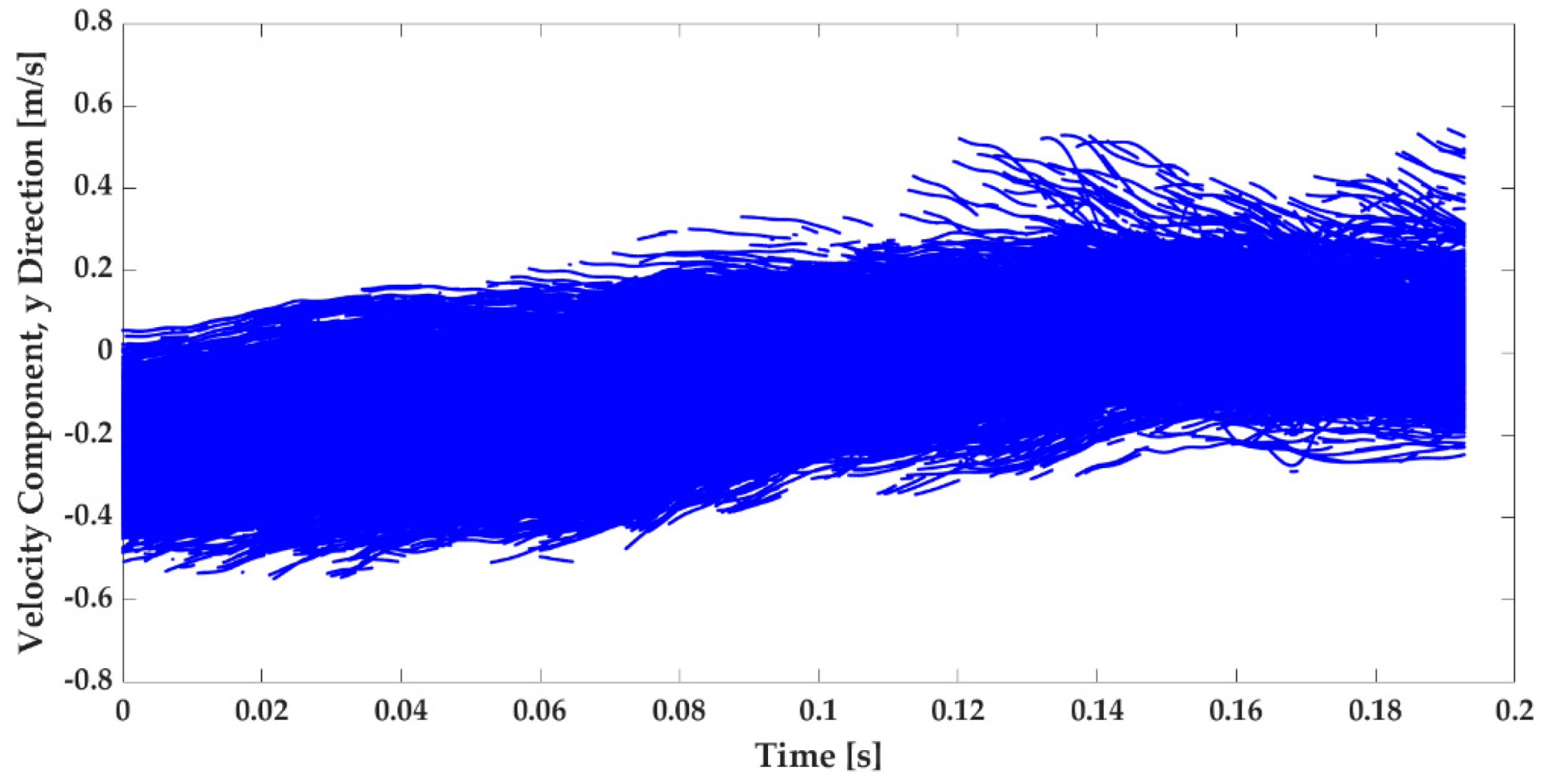
5.1. Meseured Turbulent Flow Velocity
5.2. Turbulent Flow Velocity Predicition via LSTM and GRU
5.3. LSTM and GRU Models Performance
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pope, S.B. Turbulent Flows; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Tennekes, H.; Lumley, J.L. A First Course in Turbulence; The MIT Press: Cambridge, MA, USA, 1972. [Google Scholar]
- Davidson, P.A. Turbulence: An Introduction for Scientists and Engineers; Oxford University Press: Oxford, UK, 2004. [Google Scholar]
- Toschi, F.; Bodenschatz, E. Lagrangian Properties of Particles in Turbulence. Annu. Rev. Fluid Mech. 2009, 41, 375–404. [Google Scholar] [CrossRef]
- Lee, C.; Gylfason, Á.; Perlekar, P.; Toschi, F. Inertial particle acceleration in strained turbulence. J. Fluid Mech. 2015, 785, 31–53. [Google Scholar] [CrossRef] [Green Version]
- Bukka, S.R.; Gupta, R.; Magee, A.R.; Jaiman, R.K. Assessment of unsteady flow predictions using hybrid deep learning based reduced-order models. Phys. Fluids 2021, 33, 013601. [Google Scholar] [CrossRef]
- Srinivasan, P.A.; Guastoni, L.; Azizpour, H.; Schlatter, P.; Vinuesa, R. Predictions of turbulent shear flows using deep neural networks. Phys. Rev. Fluids 2019, 4, 054603. [Google Scholar] [CrossRef] [Green Version]
- Eivazi, H.; Veisi, H.; Naderi, M.H.; Esfahanian, V. Deep neural networks for nonlinear model order reduction of unsteady flows. Phys. Fluids 2020, 32, 105104. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1999, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Zou, R.; Liu, F.; Zhang, L.; Liu, Q. A review of wind speed and wind power forecasting with deep neural networks. Appl. Energy 2021, 304, 117766. [Google Scholar] [CrossRef]
- Gu, C.; Li, H. Review on deep learning research and applications in wind and wave energy. Energies 2022, 15, 1510. [Google Scholar] [CrossRef]
- Duru, C.; Alemdar, H.; Baran, O.U. A deep learning approach for the transonic flow field predictions around airfoils. Comput. Fluids 2022, 236, 105312. [Google Scholar] [CrossRef]
- Lumely, J.L. The structure of inhomogeneous turbulent flows. In Atmospheric Turbulence and Radio Wave Propagation; Publishing House Nauka: Moscow, Russia, 1967. [Google Scholar]
- Lumely, J.L. Stochastic Tools in Turbulence; Elsevier: Amsterdam, The Netherlands, 1970. [Google Scholar]
- Schmid, P.J. Dynamic mode decomposition of numerical and experimental data. J. Fluid Mech. 2010, 656, 5–28. [Google Scholar] [CrossRef]
- Cengel, Y.Y.; Cimbala, J. Fluid Mechanics Fundamentals and Applications; McGraw Hill: New York, NY, USA, 2017. [Google Scholar]
- Hassanian, R.; Riedel, M.; Helgadottir, A.; Costa, P.; Bouhlali, L. Lagrangian Particle Tracking Data of a Straining Turbulent Flow Assessed Using Machine Learning and Parallel Computing. In Proceedings of the 33rd Parallel Computational Fluid Dynamics (ParCFD) 2022, Alba, Italy, 25–27 May 2022. [Google Scholar]
- Hassanian, R.; Riedel, M.; Lahcen, B. The capability of recurrent neural networks to predict turbulence flow via spatiotemporal features. In Proceedings of the IEEE 10th Jubilee International Conference on Computational Cybernetics and Cyber-Medical Systems (ICCC 2022), Reykjavik, Iceland, 6–9 July 2022. [Google Scholar]
- Hassanian, R.; Helgadottir, A.; Riedel, M. Parallel computing accelerates sequential deep networks model in turbulent flow forecasting. In Proceedings of the International Conference for High Performance Computing, Networking, Storage, and Analysis, SC22, Dallas, TX, USA, 15–17 November 2022. [Google Scholar]
- Elman, J.L. Finding structure in time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S.; Bengio, Y.; Frasconi, P.; Schmidhuber, J. Gradient Flow in Recurrent Nets the Difficulty of Learning Long-Term Dependencies; IEEE Press: Piscataway, New Jersey, USA, 2001. [Google Scholar]
- Kyunghyun, C.; Bart, V.M.; Dzmitry, B.; Yoshua, B. On the Properties of Neural Machine Translation: Encoder-Decoder Approaches. In Proceedings of the SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, Doha, Qatar, 25 October 2014. [Google Scholar]
- Junyoung, C.; Caglar, G.; Kyunghyun, C.; Yoshua, B. Empirical evaluation of gated recurrent neural networks on sequence modeling. In NIPS 2014 Workshop on Deep Learning; Curran Associates, Inc.: Brooklyn, NJ, USA, 2014. [Google Scholar]
- Hassanian, R. An Experimental Study of Inertial Particles in Deforming Turbulence: In Context to Loitering of Blades in Wind Turbines; Reykjavik University: Reykjavik, Iceland, 2020. [Google Scholar]
- Bouhlali, L. On the Effects of Buoyancy on Passive Particle Motions in the Convective Boundary Layer from the Lagrangian Viewpoint; Reykjavik University: Reykjavik, Iceland, 2012. [Google Scholar]
- Ireland, P.; Bragg, A.; Collins, L. The effect of Reynolds number on inertial particle dynamics in isotropic turbulence. Part 1. Simulations without gravitational effects. J. Fluid Mech. 2016, 796, 617–658. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensoreFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the 12th Usenix Symposium on Operating Systems Design and Implementation (OSDI ’16), Savannah, GA, USA, 2–4 November 2016. [Google Scholar]
- Kramer, O. Scikit-Learn. In Machine Learning for Evolution Strategies; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Riedel, M.; Sedona, R.; Barakat, C.; Einarsson, P.; Hassanian, R.; Cavallaro, G.; Book, M.; Neukirchen, H.; Lintermann, A. Practice and Experience in using Parallel and Scalable Machine Learning with Heterogenous Modular Supercomputing Architectures. In Proceedings of the 2021 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Portland, OR, USA, 17–21 June 2021. [Google Scholar]
- TensorFlow. TensorFlow Core Tutorials; TensorFlow: Mountain View, CA, USA, 2022. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Proportion | Computing Module | Performance | LSTM | GRU |
|---|---|---|---|---|
| 80% | 1 node, 1 GPU | Scalability | 1 | 1.12 |
| MAE | 0.001 | 0.002 | ||
| R2 score | 0.984 | 0.984 | ||
| 1 node, 4 GPUs | Scalability | 3.45 | 3.20 | |
| MAE | 0.002 | 0.002 | ||
| R2 score | 0.983 | 0.983 | ||
| 60% | 1 node, 1 GPU | Scalability | 1 | 1.08 |
| MAE | 0.0015 | 0.0015 | ||
| R2 score | 0.985 | 0.987 | ||
| 1 node, 4 GPUs | Scalability | 3.61 | 3.36 | |
| MAE | 0.002 | 0.002 | ||
| R2 score | 0.985 | 0.987 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hassanian, R.; Helgadóttir, Á.; Riedel, M. Deep Learning Forecasts a Strained Turbulent Flow Velocity Field in Temporal Lagrangian Framework: Comparison of LSTM and GRU. Fluids 2022, 7, 344. https://doi.org/10.3390/fluids7110344
Hassanian R, Helgadóttir Á, Riedel M. Deep Learning Forecasts a Strained Turbulent Flow Velocity Field in Temporal Lagrangian Framework: Comparison of LSTM and GRU. Fluids. 2022; 7(11):344. https://doi.org/10.3390/fluids7110344
Chicago/Turabian StyleHassanian, Reza, Ásdís Helgadóttir, and Morris Riedel. 2022. "Deep Learning Forecasts a Strained Turbulent Flow Velocity Field in Temporal Lagrangian Framework: Comparison of LSTM and GRU" Fluids 7, no. 11: 344. https://doi.org/10.3390/fluids7110344
APA StyleHassanian, R., Helgadóttir, Á., & Riedel, M. (2022). Deep Learning Forecasts a Strained Turbulent Flow Velocity Field in Temporal Lagrangian Framework: Comparison of LSTM and GRU. Fluids, 7(11), 344. https://doi.org/10.3390/fluids7110344