1. Introduction
Wind energy is among the most important renewable energies. In 2021, the installation of offshore wind turbine plants was 3-fold greater than in 2020 and this increased the global power output from wind power plants to 837 GW, showing a growth of 12% compared to 2020 [
1]. The wind energy industry has been growing drastically lately as governments all around the world understand the importance of wind energy in achieving the target of 1.5 °C global warming by 2100 set by the Paris Agreement [
2]. A total 557 GW of wind power output is expected to be achieved by 2026 [
1]. Further, BloombergNEF (BNEF) forecasted that global offshore WT capacity will reach 5.3 GW by 2030 [
3]. The Global Energy Wind Council stated that the wind energy industry needs to scale up annual wind turbine plant installation by 4 fold to meet the global warming target of 1.5 °C [
1].
However, the wind energy industry is facing higher operation and maintenance (O&M) costs and unplanned replacement costs amid uncertainties. O&M costs are expected to grow 8% annually by 2025, from USD 13.7 billion in 2016 to an estimated USD 27.4 billion in 2025 [
4].
Figure 1 shows that the O&M cost took up to 21% of the total cost in a wind turbine project [
5].
The cost of unplanned maintenance is significantly high as well.
Table 1 shows the cost of replacement of three different subsystems in an offshore WT. The replacement cost of a gearbox is double the cost of a generator or blade as replacements for such systems require a vessel and crane [
5].
Virus outbreaks and tensions between countries are resulting in financial stress in the wind energy industry due to the rise in the prices of key materials and logistics. The price of future projects in wind energy plants will remain high in 2022 according to a BNEF report [
3]. Further, wind plant operators will face higher costs and lower profits when unscheduled maintenance occur due to long downtimes as major parts such as generators and gearboxes require longer downtimes for maintenance and repair.
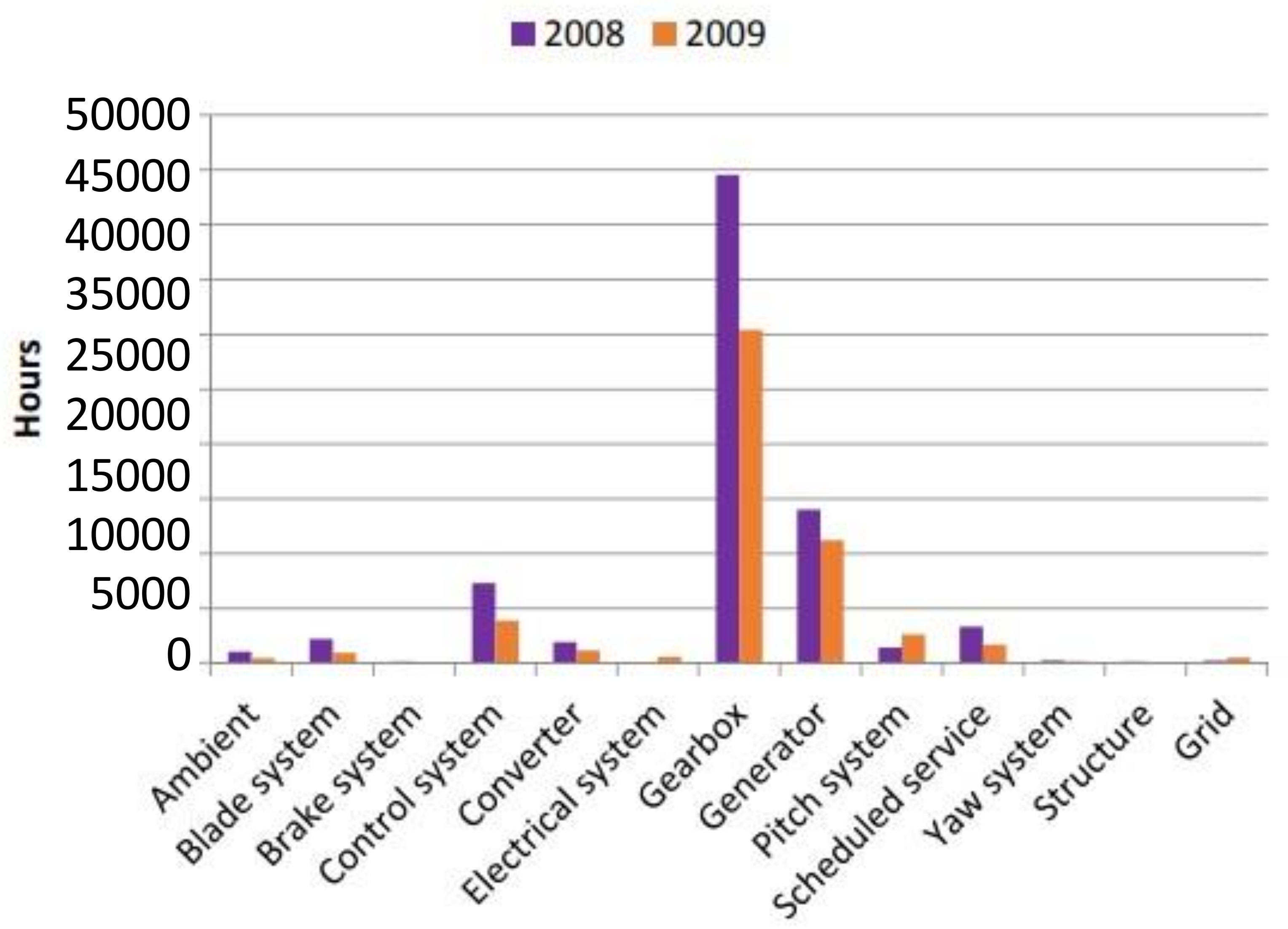
Figure 2 showed that gearboxes and generators cause the longest downtime for WTs.
BNEF stated that a series of wind turbine faults in the past could lead to greater turbine faults in the future [
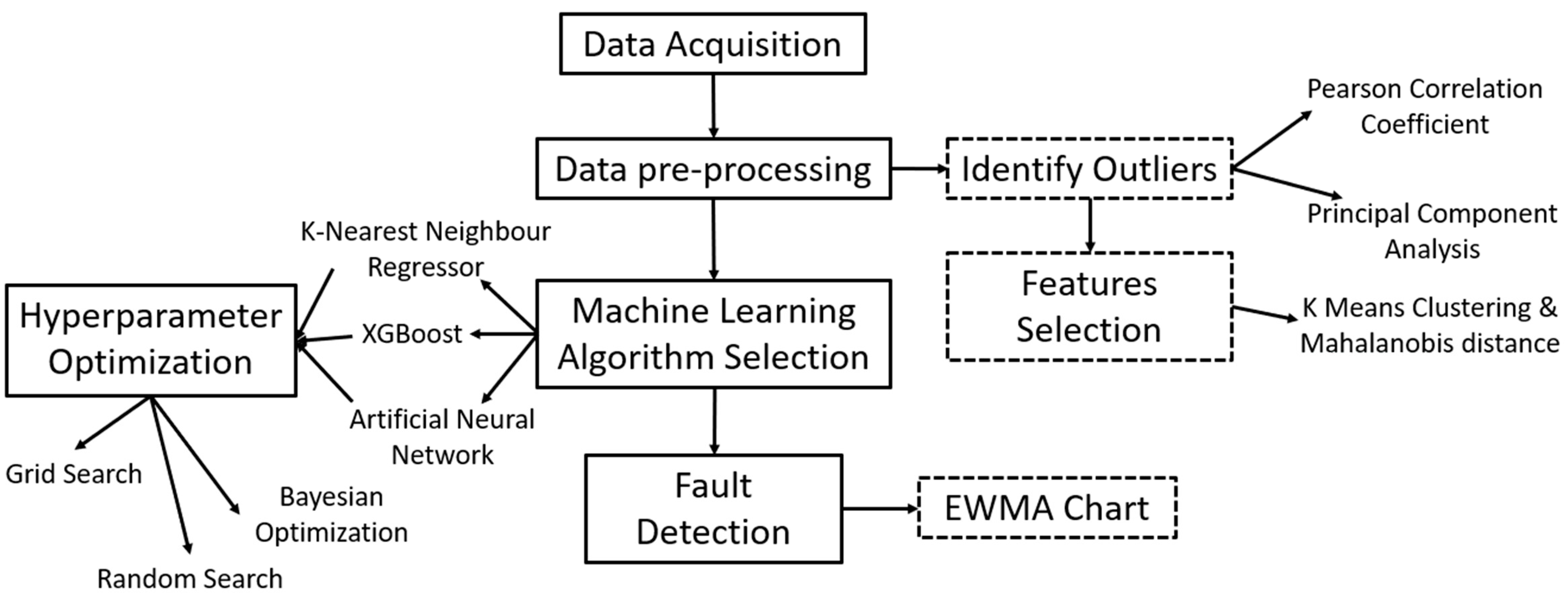
3]. Hence, it is important to analyze and study the behavior of wind turbine plants so as to avoid any unnecessary costs by developing a condition monitoring system (CM) based on Supervisory Control and Data Acquisition (SCADA) data such as wind speed, gearbox bearing temperature, and generator bearing temperature.
CMs help to take effective advanced maintenance action by detecting any impending faults in WTs. CMs can help to save up to 25% of maintenance costs compared with scheduled maintenance costs [
6]. CMs can constitute applying machine learning on the SCADA data collected by sensors in WTs. Machine learning could study the behavior of WTs and it is possible to detect if a fault is developing in WTs. The term machine learning was created by Arthur Samuel in 1959 while at IBM [
7]. Machine learning is a branch of artificial intelligence and computer science which applies an algorithm network on a set of data to model what humans learn [
8]. Machines are able to solve issues or provide signals based on what they learn. However, according to Alpaydn, to solve a problem on a computer, an algorithm is needed [
9]. Machine learning algorithms are publicly available and include TensorFlow [
10] and PyTorch [
11]. Machine learning has been widely used in different industries such as the medical [
12], food and beverage [
13], construction [
14] and renewable energy fields [
15]. The SCADA data have been used to detect potential catastrophic failures in wind turbines by applying a regression model [
16]. A study showed that a bagging regressor managed to achieve a early fault alarm 9 days earlier than the actual failure without stating the computational time required by the proposed method [
17]. Studies have proven the efficiency of machine learning on fault diagnosis in wind turbines, but the computation times of different machine learning models were not highly emphasized although this is among the main factors of model selection as computation time will affect the setup cost and computation resources. Further, data pre-processing methods have not been studied together with the performance of different machine learning models.
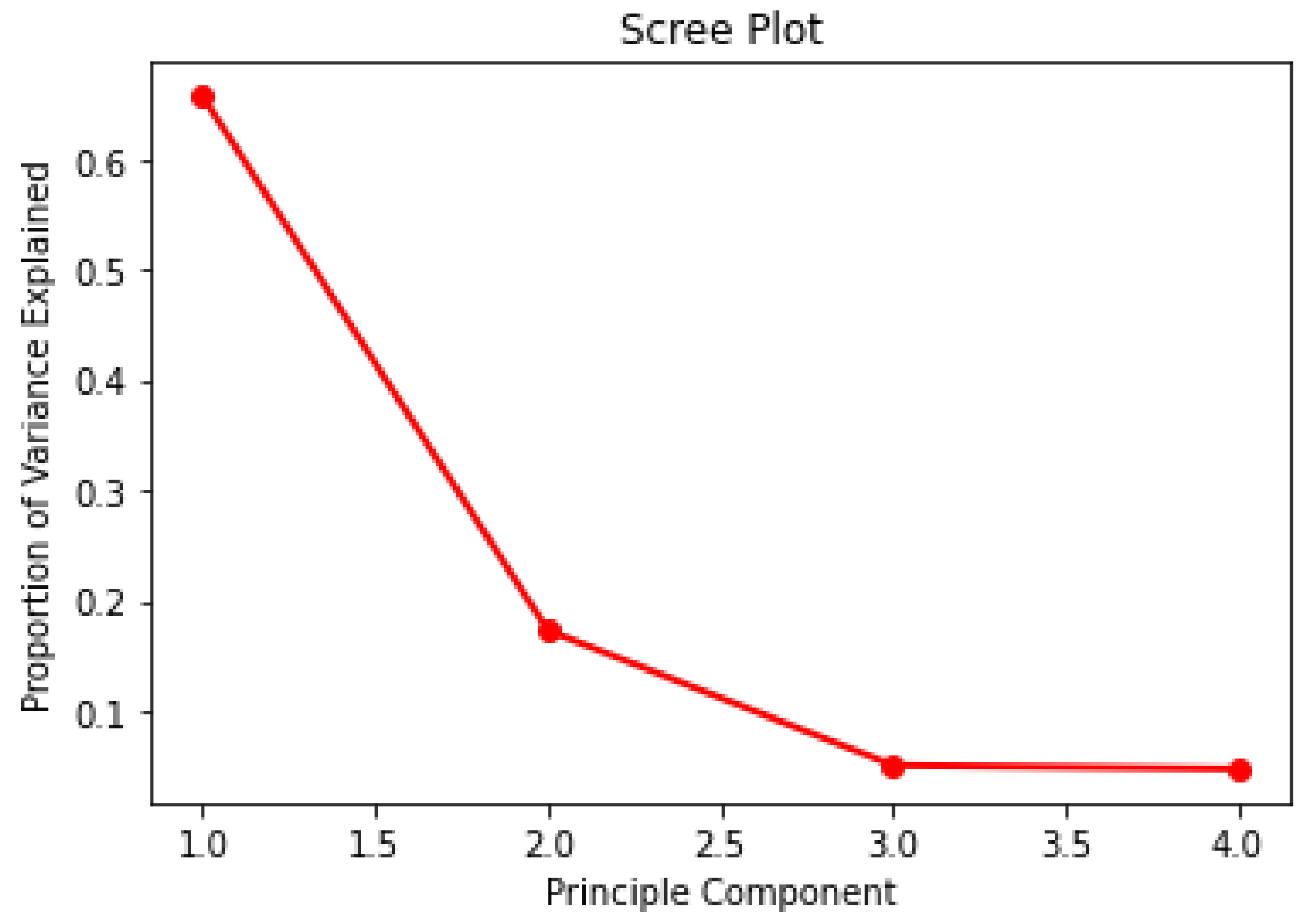
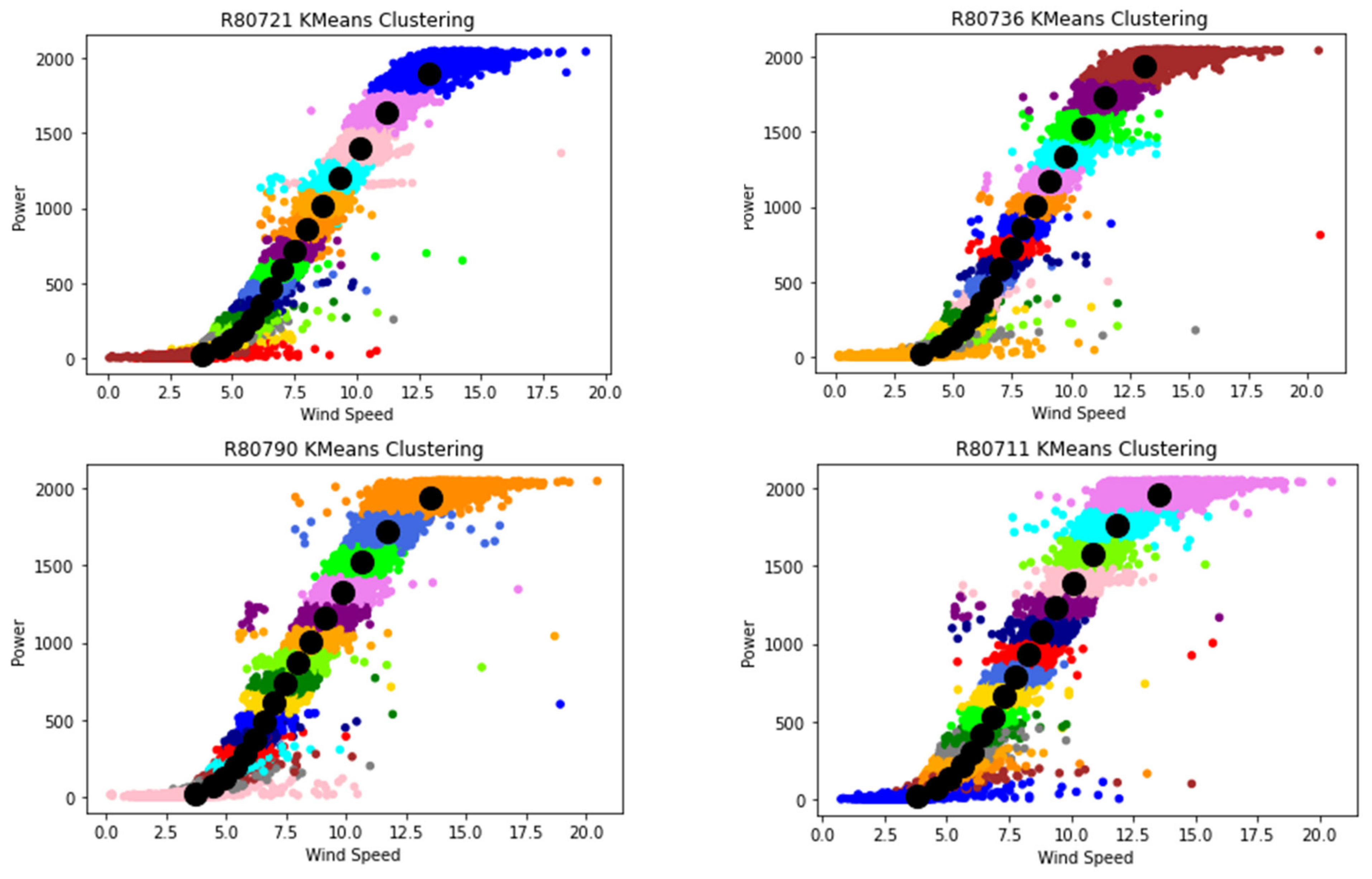
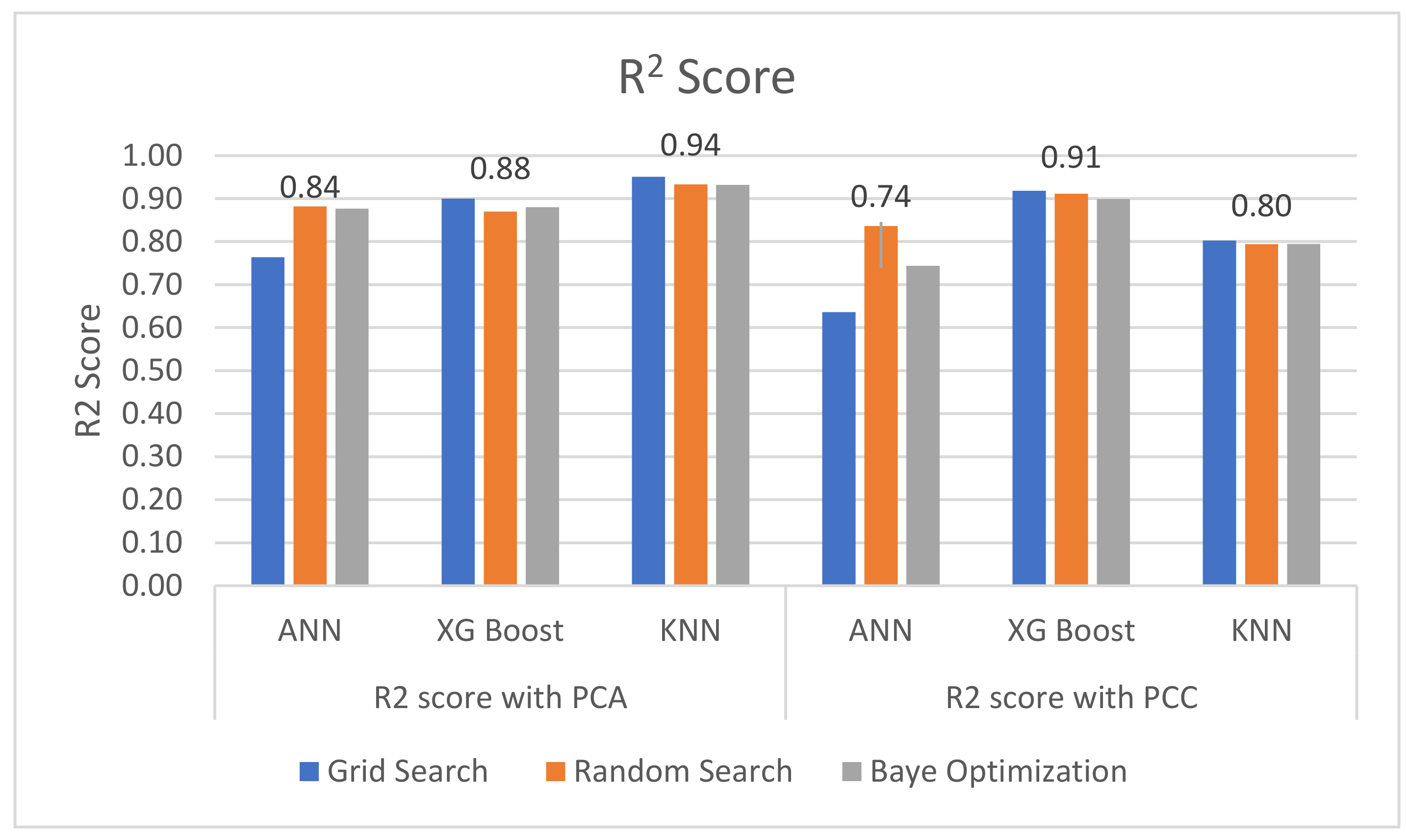
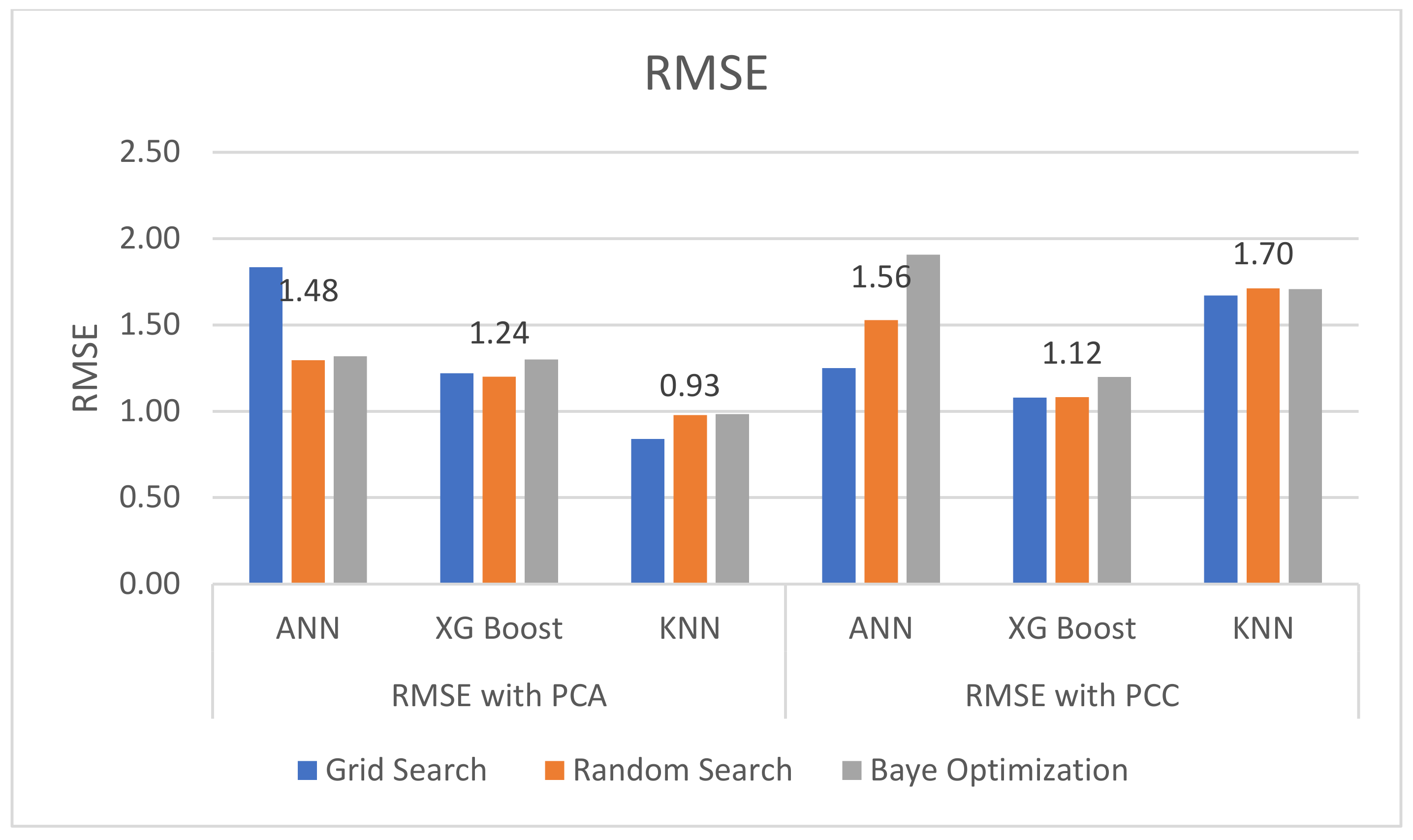
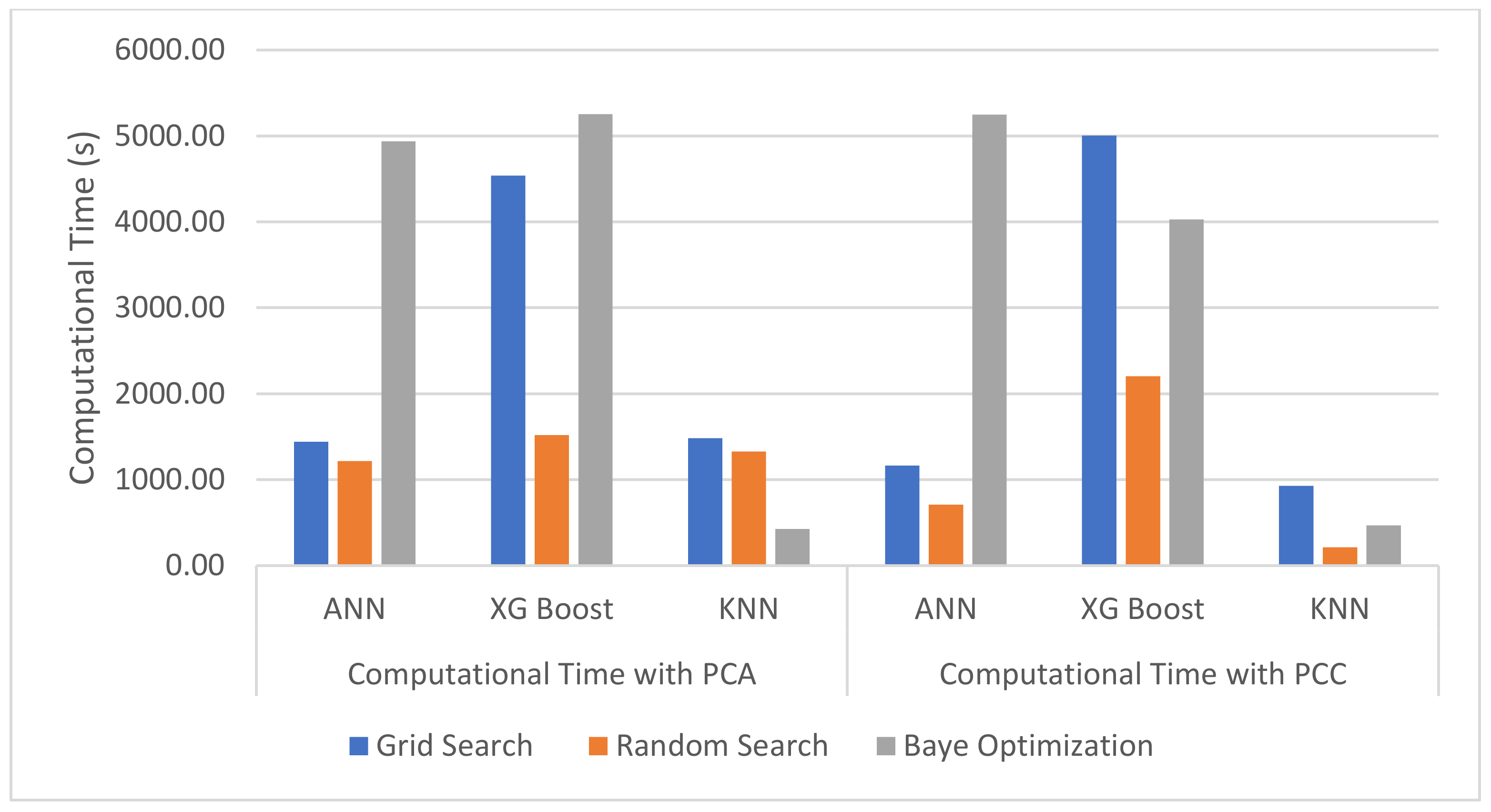
Therefore, the purpose of this study is to determine an algorithm network to diagnose fault patterns on gearbox oil sump temperature in WTs. Three different machine learning algorithms, K-nearest neighbor (kNN) with a bagging regressor algorithm, the extreme gradient boosting (XGBoost) algorithm and an artificial neural network (ANN), will be applied in this study and their performance and computational time will be compared and discussed. The algorithm with the best performance in terms of the lowest root mean square error (RMSE) and the highest R2 score will be chosen to train the condition monitoring model. Further, feature selection methods, namely the Pearson correlation coefficient and principal component analysis, and hyperparameter optimization methods, namely a grid search, a random search and Bayesian optimization, will be applied in this study and their results will be discussed. A set of SCADA wind turbine data from ENGIE, a wind turbine operator, will be used to train the three algorithm networks.
4. Conclusions
This study evaluated the performance of two feature selection methods, namely PCA and PCC, and three different hyperparameter optimization methods, namely a grid search, a random search and Bayesian optimization, and also compared the accuracy of three different machine learning algorithms on fault diagnosis on WTs.
Overall, PCA gave a better result in terms of R2 score and the RMSE compared with PCC. The number of features reduced by using PCA is greater compared with using PCC. Therefore, this may cause overfitting of the trained model as the dataset was too large. Further, Bayesian optimization takes the longest computational time compared with the other two hyperparameter optimization methods. In this study, a grid search was proposed to give the best outcome, but the grid search required high computational memory as it ran through one after another hyperparameter and stored the results for comparison. Therefore, hyperparameter optimization needs to be carefully selected as this could affect the CPU performance of the condition monitoring model.
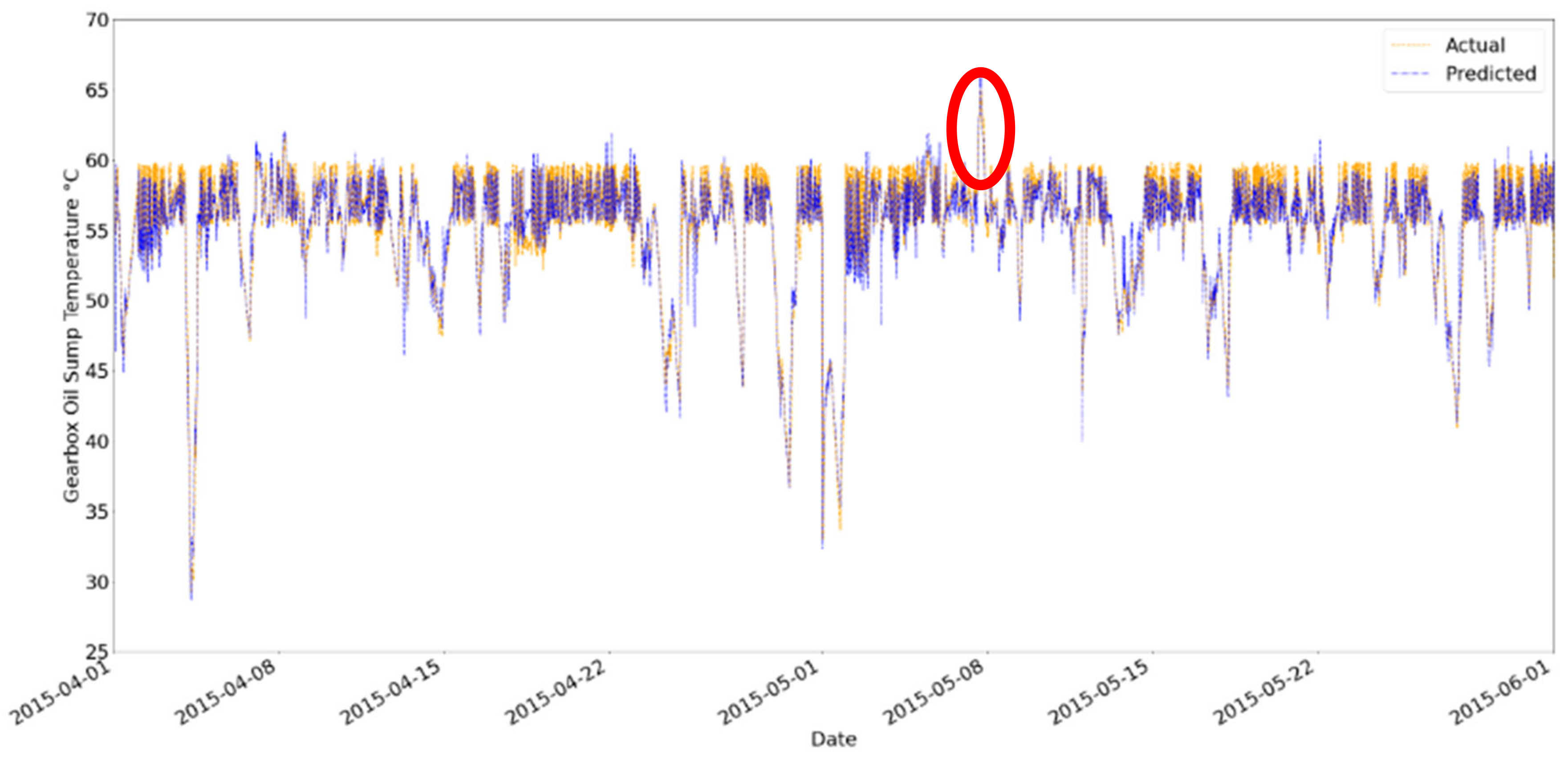
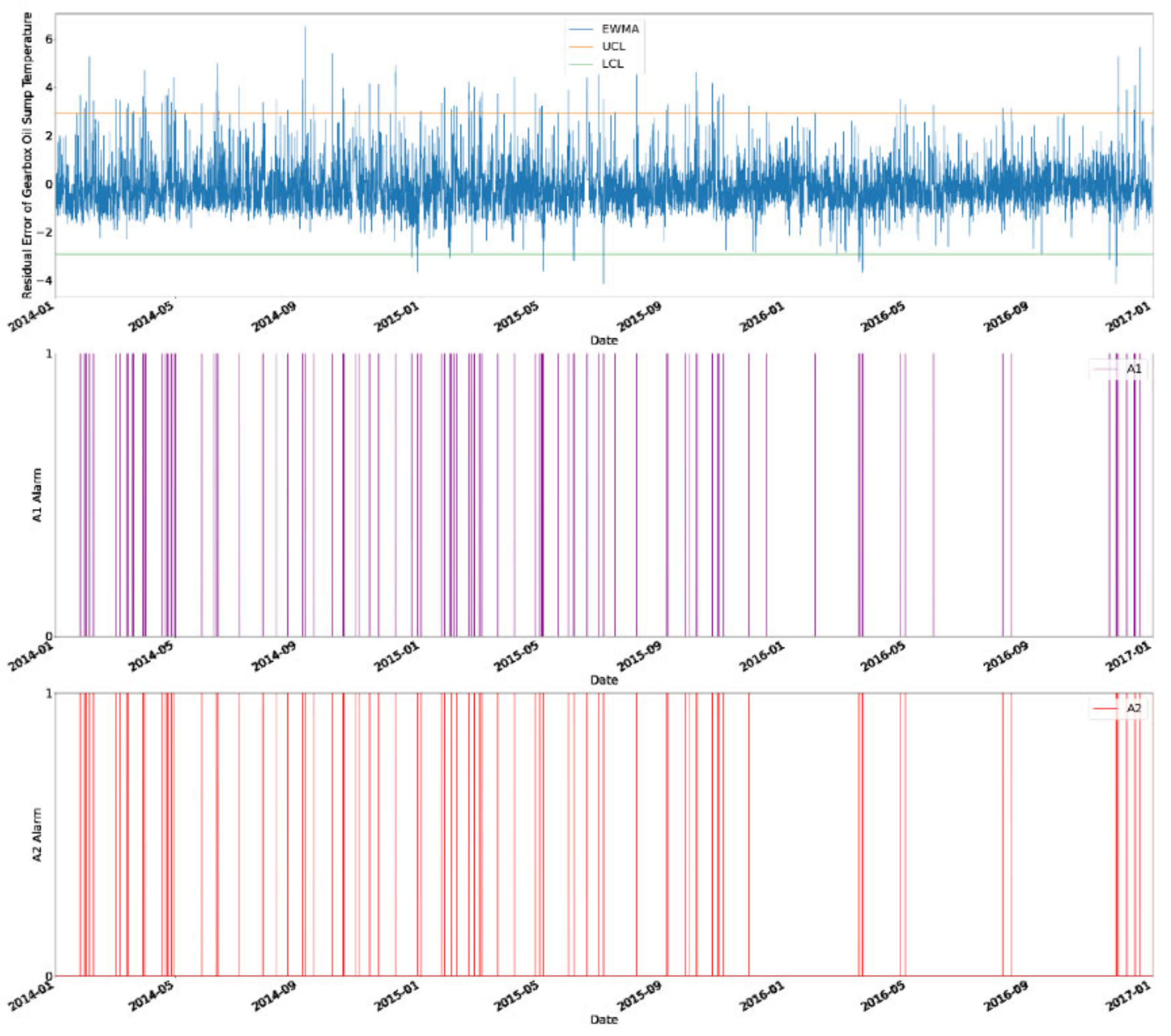
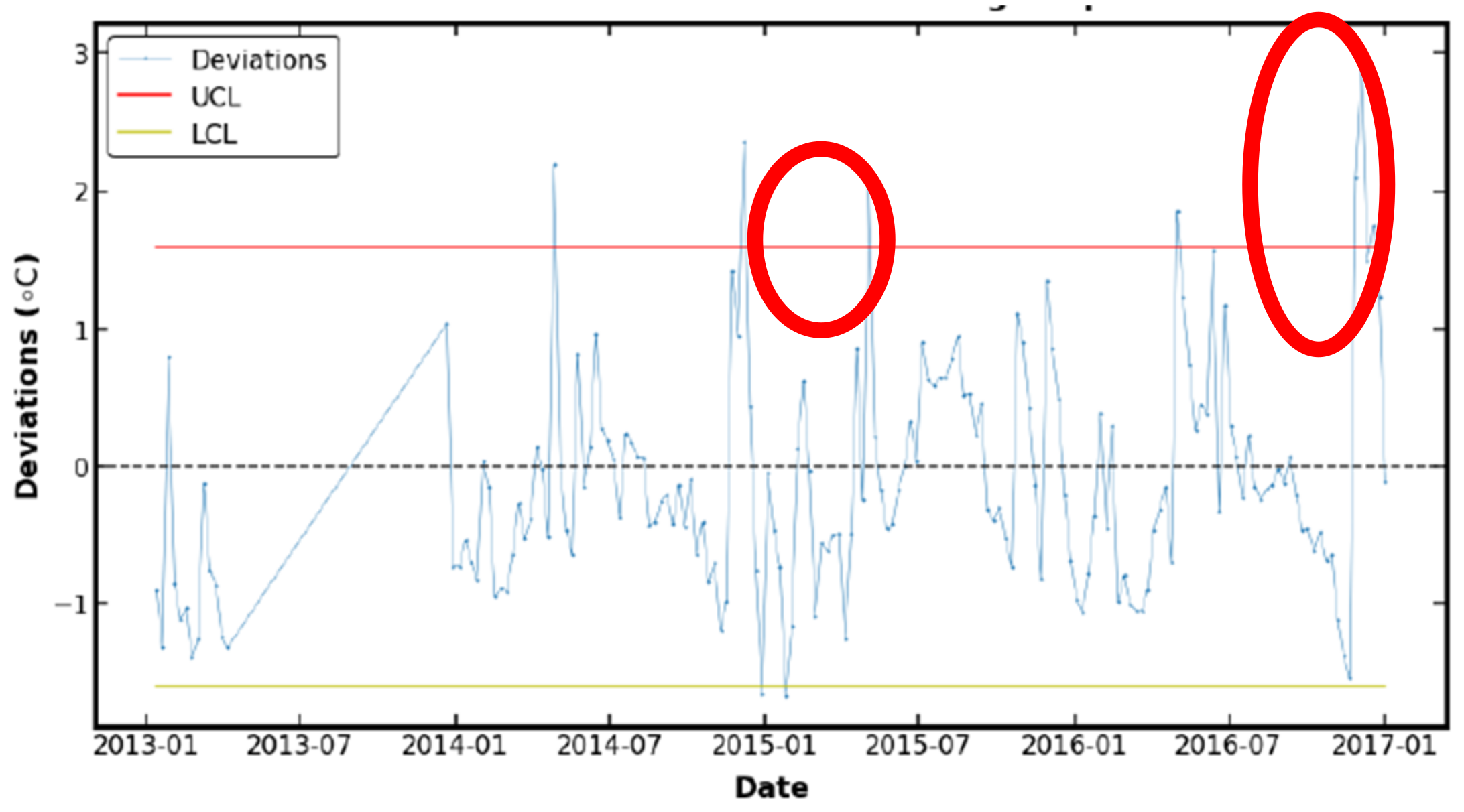
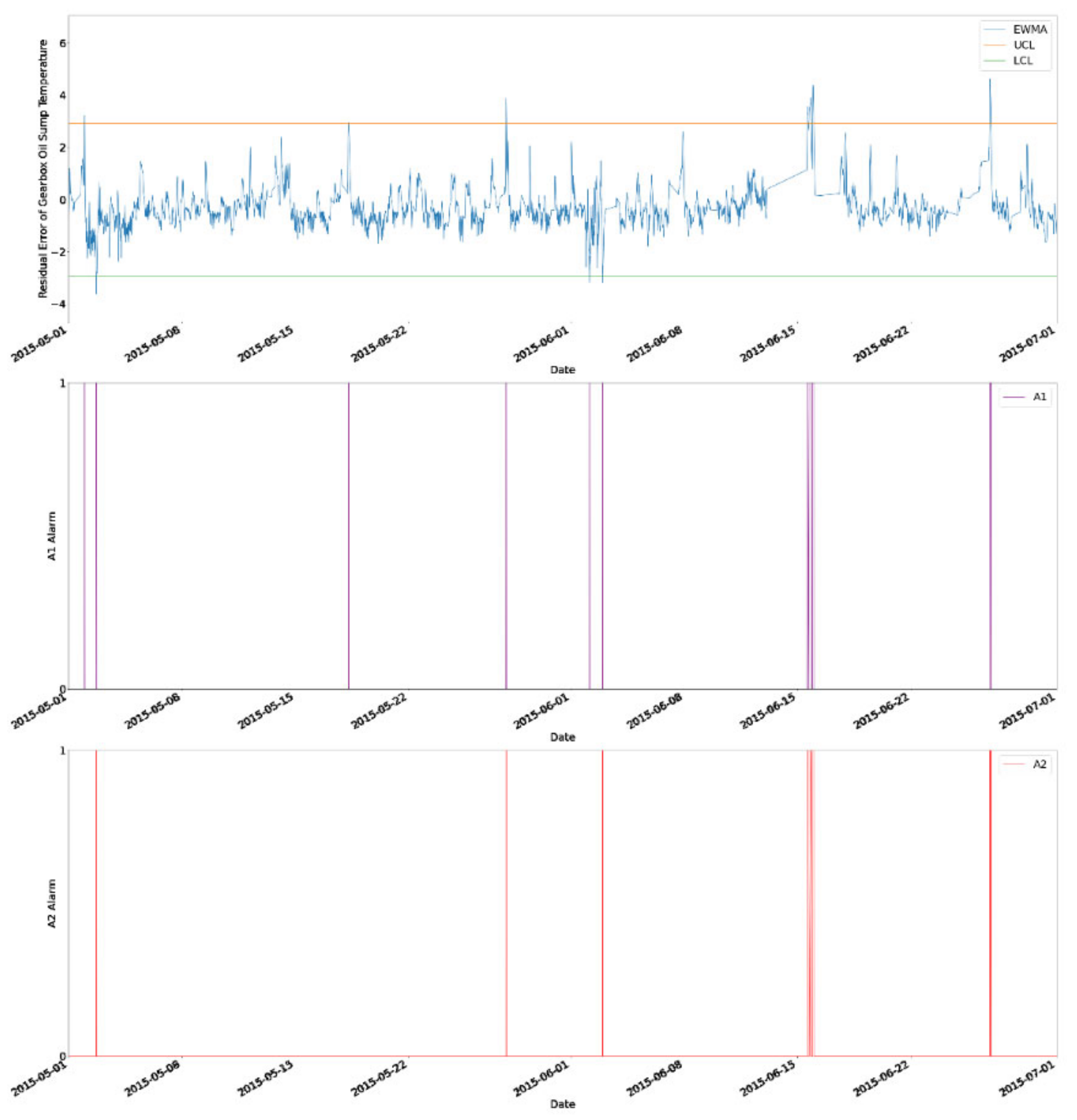
KNN with a bagging regressor by using PCA as a feature selection method and a grid search for hyperparameter optimization was proposed in this study for fault diagnosis on WTs by predicting the gearbox oil sump temperature. The SCADA data from a wind turbine operator, ENGIE, were used in this study for validation. The results showed that the proposed method was managed to provide early alarm on WTs at least 4 weeks in advance by monitoring the residual error of gearbox oil sump temperature on an EWMA control chart and it used the shortest computational time. However, the proposed method was not as good as the method used in a study that applied the multivariate state estimation technique (MSET). The MSET is proven to give a lower rate of fault alarm [
53]. Furthermore, a proper validation applied was not applied in this study as the validation part was performed based on the reference taken from another study because the actual maintenance report of the WT from ENGIE was not made available to the public.
In the future, the proposed kNN with a bagging regressor model can be further studied to improve its accuracy and can be used to provide fault alarm on other parts of WTs such as rotor blades or generators. KNN with a bagging regressor model could be trained in hybrid with a Support Vector Machine as studies have been performed on this hybrid model and show enhanced model performance [
58]. Furthermore, it can be consolidated by hyperparameter optimization. The range of hyperparameters selected for optimization could be wider as the range here is limited due to the computational resource constraints in this study. If a wider range of hyperparameters are selected for optimization, this could further improve the performance of the trained model. Further, another parameter such as gearbox bearing temperature could be selected as the target variable for the chosen algorithm to determine the reliability of the algorithm. The artificial neural network can be further consolidated by applying Bayesian Physics-Informed Neural Networks as this neural network is more suitable to real-world nonlinear dynamic systems such as WTs.
































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}