

Turbulent Flow Prediction-Simulation: Strained Flow with Initial Isotropic Condition Using a GRU Model Trained by an Experimental Lagrangian Framework, with Emphasis on Hyperparameter Optimization

 ,
,  ,
,  and
and
Abstract
:1. Introduction
2. Methodology
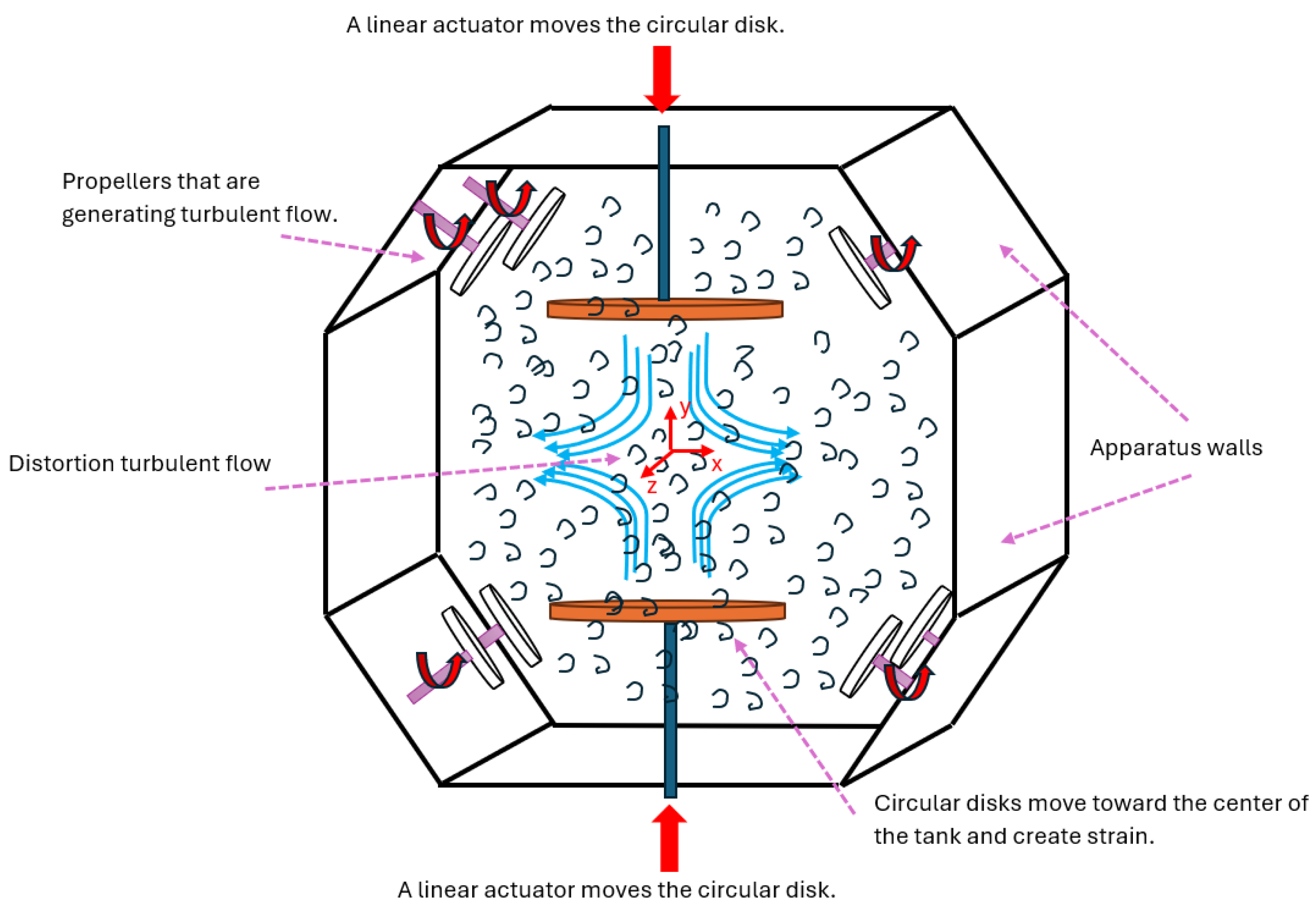
2.1. The Lagrangian Framework and Fluid Particles
2.2. Experimental Data
2.3. Sequential Velocity Dataset
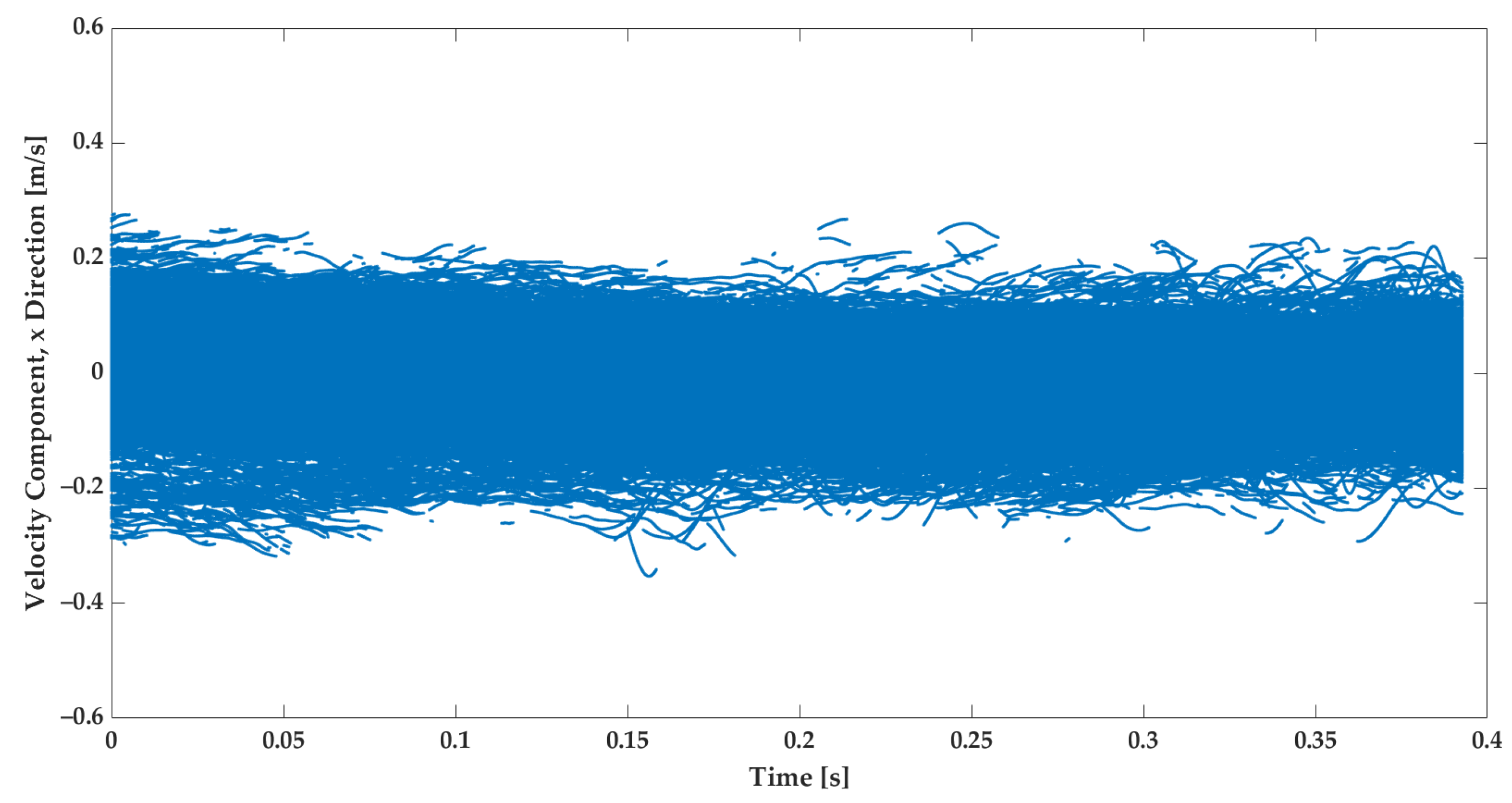
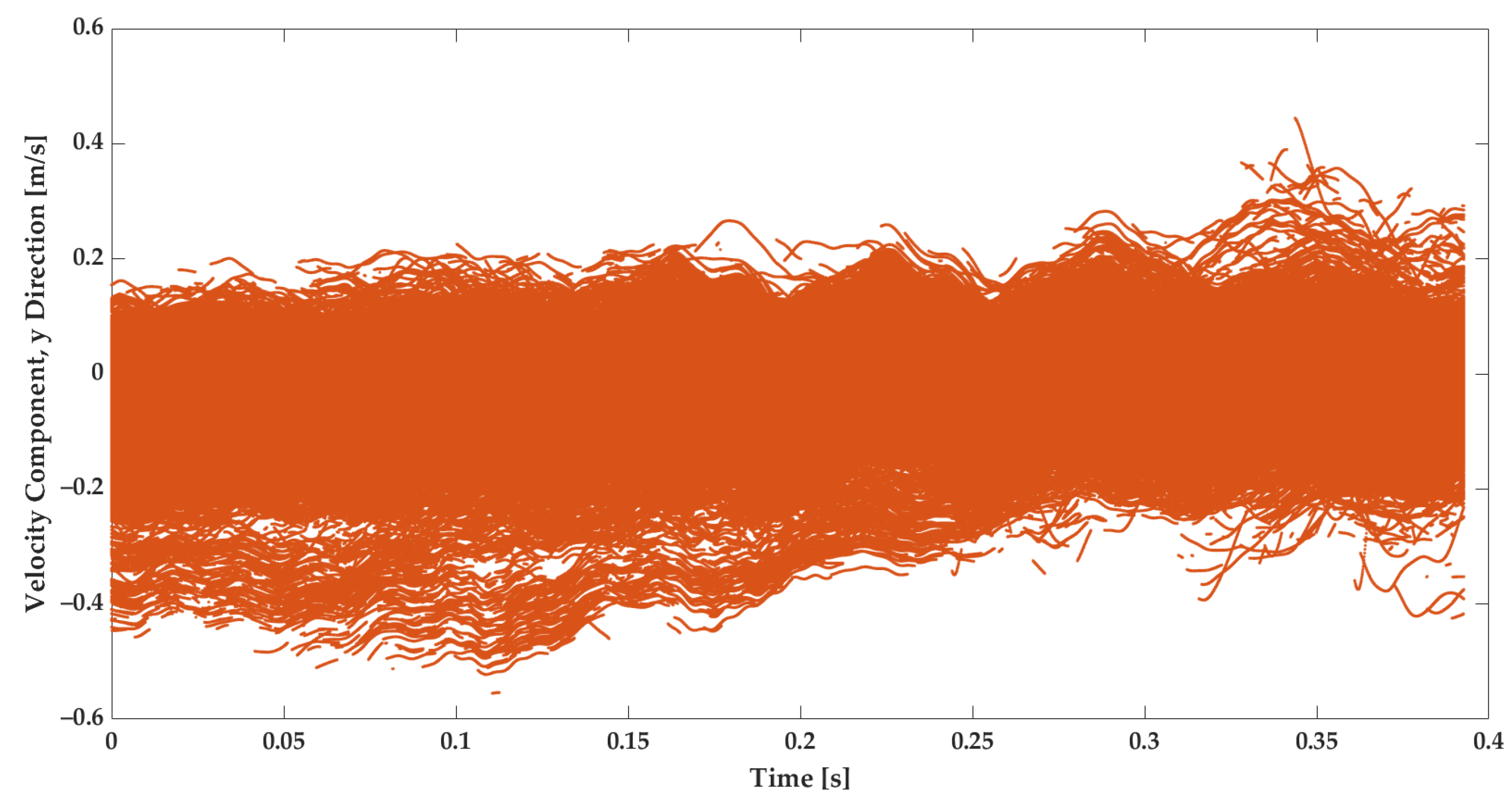
- Velocity component in the Y direction, ;
- Velocity component in the X direction, ;
- Location in the x coordinate;
- Location in the y coordinate;
- The time vector specifies the time t for every tracking point.
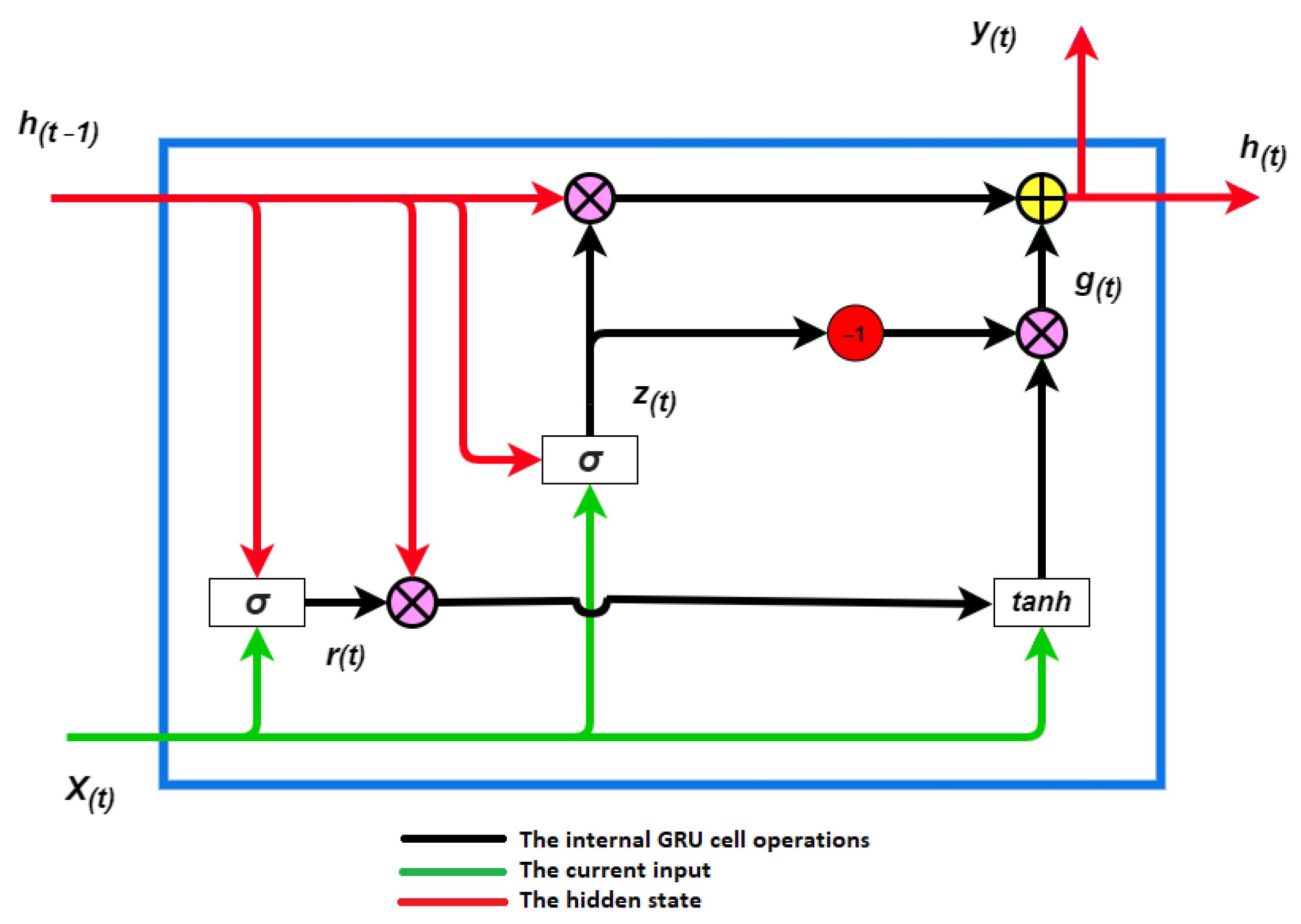
2.4. Gated Recurrent Unit Model
2.5. Forecasting Model Set Up and Parallel Computing
3. Results
3.1. Measured Turbulent Flow Velocity
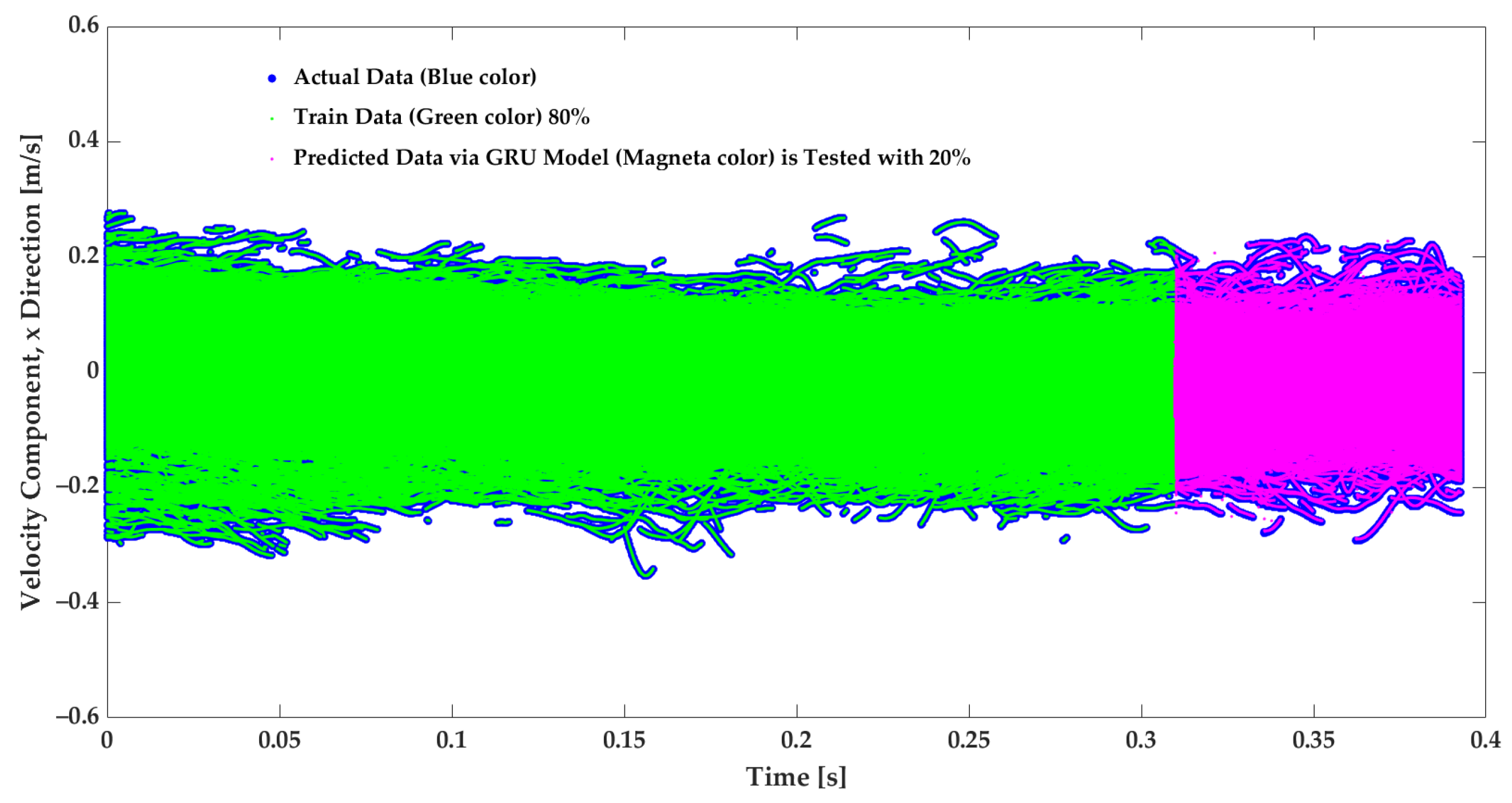
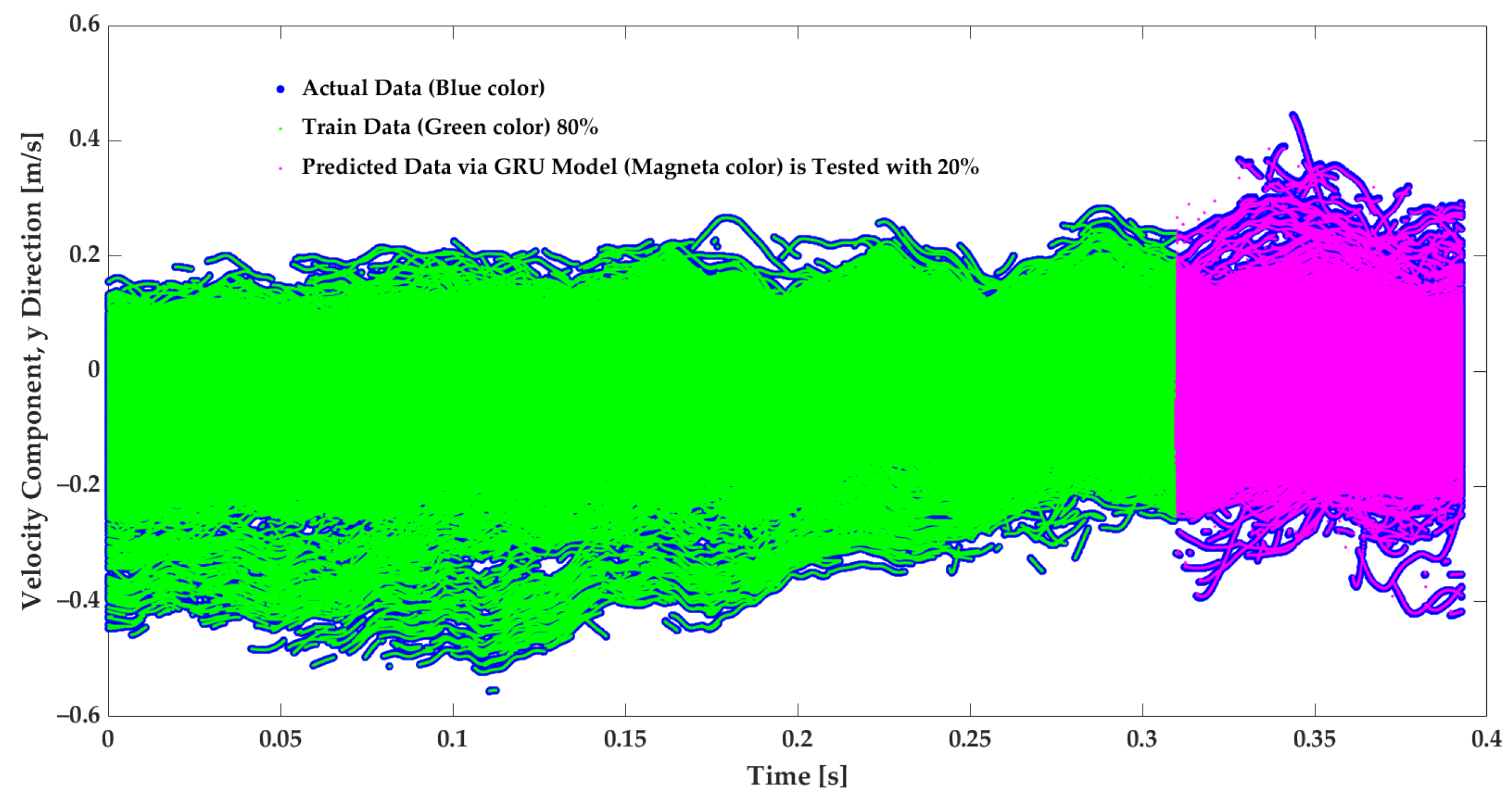
3.2. Predicted Velocity and GRU Model Evaluation
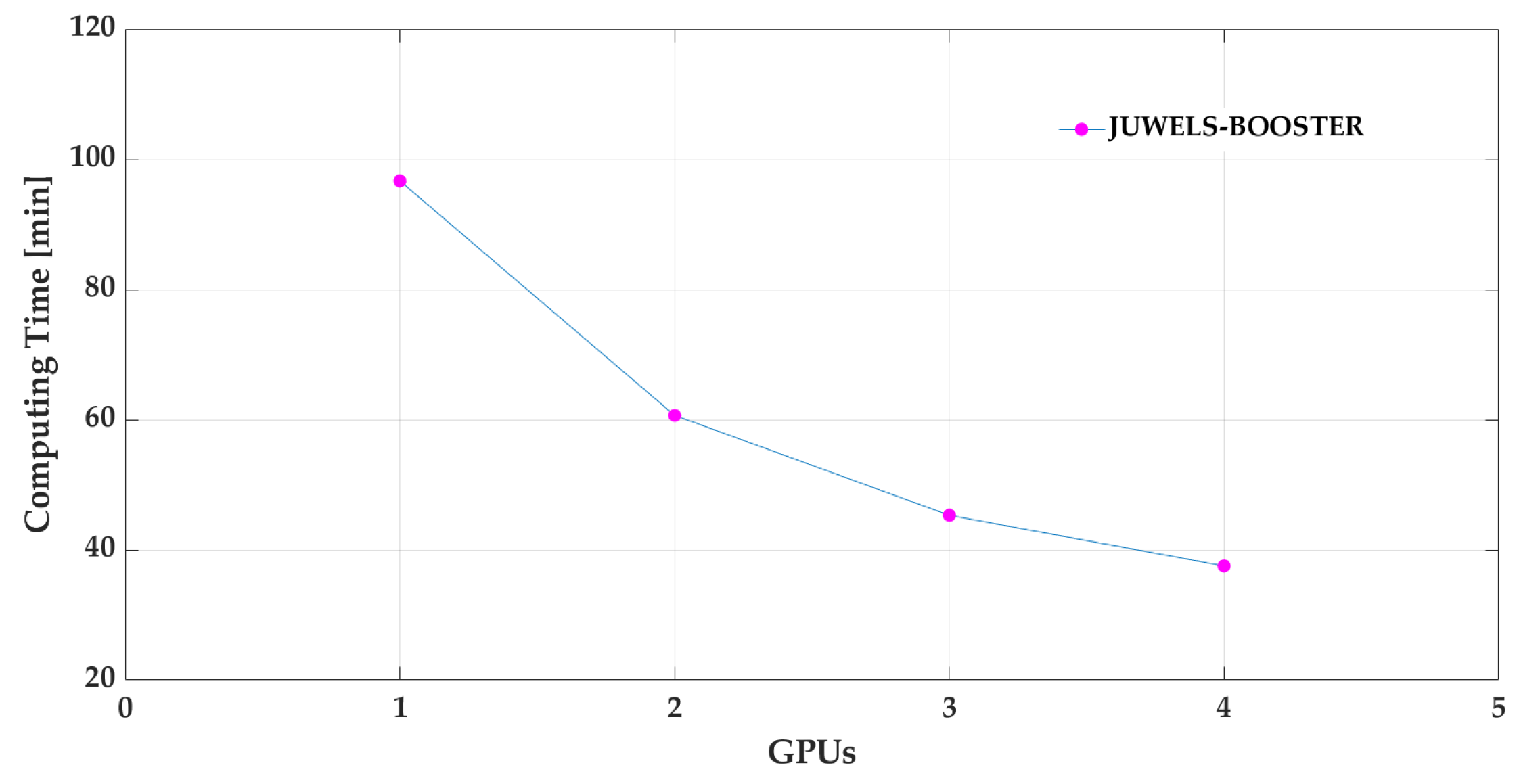
3.3. Parallel Computing Assessment
4. Summary and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CFD | Computational Fluid Dynamics |
| CNN | Convolutional Neural Network |
| CPU | Central Processing Unit |
| DL | Deep Learning |
| DMD | Dynamical Mode Decomposition |
| DNS | Direct Numerical Simulation |
| GPU | Graphics Processing Unit |
| GRU | Gated Recurrent Unit |
| HPC | High-Performance Computing |
| HPO | Hyperparameter Optimization |
| LES | Large Eddy Simulation |
| LPT | Lagrangian Particle Tracking |
| LSTM | Long Short-Term Memory |
| MAE | Mean Absolute Error |
| ML | Machine Learning |
| MLP | Multilayer Perceptron |
| MPI | Message Passing Interface |
| POD | Proper Orthogonal Decomposition |
| RANS | Reynolds-Averaged Navier Stokes |
| RANS | Reynolds-Averaged Navier Stokes |
| RNN | Recurrent Neural Network |
| ROM | Reduced-Order Model |
References
- Pope, S.B. Turbulent Flows; Cambridge University Press: London, UK, 2000. [Google Scholar]
- John, L.; Lumley, H.T. A First Course in Turbulence; MIT Press: Cambridge, MA, USA, 1972. [Google Scholar]
- Davidson, P.A. Turbulence: An Introduction for Scientists and Engineers; Oxford University Press: London, UK, 2004. [Google Scholar]
- Hassanian, R.; Riedel, M.; Bouhlali, L. The Capability of Recurrent Neural Networks to Predict Turbulence Flow via Spatiotemporal Features. In Proceedings of the 2022 IEEE 10th Jubilee International Conference on Computational Cybernetics and Cyber-Medical Systems (ICCC), Reykjavík, Iceland, 6–9 July 2022; pp. 000335–000338. [Google Scholar] [CrossRef]
- Bukka, S.R.; Gupta, R.; Magee, A.R.; Jaiman, R.K. Assessment of unsteady flow predictions using hybrid deep learning based reduced-order models. Phys. Fluids 2021, 33, 013601. [Google Scholar] [CrossRef]
- Cengel, Y.; Cimbala, J. Fluid Mechanics Fundamentals and Applications; McGraw Hill: New York, NY, USA, 2013. [Google Scholar]
- White, F. Fluid Mechanics; McGraw Hill: New York, NY, USA, 2015. [Google Scholar]
- Eivazi, H.; Veisi, H.; Naderi, M.H.; Esfahanian, V. Deep neural networks for nonlinear model order reduction of unsteady flows. Phys. Fluids 2020, 32, 105104. [Google Scholar] [CrossRef]
- Srinivasan, P.A.; Guastoni, L.; Azizpour, H.; Schlatter, P.; Vinuesa, R. Predictions of turbulent shear flows using deep neural networks. Phys. Rev. Fluids 2019, 4, 054603. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Zou, R.; Liu, F.; Zhang, L.; Liu, Q. A review of wind speed and wind power forecasting with deep neural networks. Appl. Energy 2021, 304, 117766. [Google Scholar] [CrossRef]
- Gu, C.; Li, H. Review on Deep Learning Research and Applications in Wind and Wave Energy. Energies 2022, 15, 1510. [Google Scholar] [CrossRef]
- Duru, C.; Alemdar, H.; Baran, O.U. A deep learning approach for the transonic flow field predictions around airfoils. Comput. Fluids 2022, 236, 105312. [Google Scholar] [CrossRef]
- Moehlis, J.; Faisst, H.; Eckhardt, B. A low-dimensional model for turbulent shear flows. New J. Phys. 2004, 6, 56. [Google Scholar] [CrossRef]
- Hassanian, R.; Helgadottir, A.; Riedel, M. Deep Learning Forecasts a Strained Turbulent Flow Velocity Field in Temporal Lagrangian Framework: Comparison of LSTM and GRU. Fluids 2022, 7, 344. [Google Scholar] [CrossRef]
- Hassanian, R.; Myneni, H.; Helgadottir, A.; Riedel, M. Deciphering the dynamics of distorted turbulent flows: Lagrangian particle tracking and chaos prediction through transformer-based deep learning models. Phys. Fluids 2023, 35, 075118. [Google Scholar] [CrossRef]
- Hassanian, R.; Helgadottir, A.; Bouhlali, L.; Riedel, M. An experiment generates a specified mean strained rate turbulent flow: Dynamics of particles. Phys. Fluids 2023, 35, 015124. [Google Scholar] [CrossRef]
- Pant, P.; Doshi, R.; Bahl, P.; Barati Farimani, A. Deep learning for reduced order modelling and efficient temporal evolution of fluid simulations. Phys. Fluids 2021, 33, 107101. [Google Scholar] [CrossRef]
- Fresca, S.; Manzoni, A. POD-DL-ROM: Enhancing deep learning-based reduced order models for nonlinear parametrized PDEs by proper orthogonal decomposition. Comput. Methods Appl. Mech. Eng. 2022, 388, 114181. [Google Scholar] [CrossRef]
- Papapicco, D.; Demo, N.; Girfoglio, M.; Stabile, G.; Rozza, G. The Neural Network shifted-proper orthogonal decomposition: A machine learning approach for non-linear reduction of hyperbolic equations. Comput. Methods Appl. Mech. Eng. 2022, 392, 114687. [Google Scholar] [CrossRef]
- Riedel, M.; Sedona, R.; Barakat, C.; Einarsson, P.; Hassanian, R.; Cavallaro, G.; Book, M.; Neukirchen, H.; Lintermann, A. Practice and Experience in using Parallel and Scalable Machine Learning with Heterogenous Modular Supercomputing Architectures. In Proceedings of the 2021 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Portland, OR, USA, 17–21 June 2021; pp. 76–85. [Google Scholar] [CrossRef]
- Hassanian, R.; Riedel, M. Leading-Edge Erosion and Floating Particles: Stagnation Point Simulation in Particle-Laden Turbulent Flow via Lagrangian Particle Tracking. Machines 2023, 11, 566. [Google Scholar] [CrossRef]
- Cowen, E.A.; Monismith, S.G. A hybrid digital particle tracking velocimetry technique. Exp. Fluids 1997, 22, 199–211. [Google Scholar] [CrossRef]
- Hassanian, R. An Experimental Study of Inertial Particles in Deforming Turbulence Flow, in Context to Loitering of Blades in Wind Turbines. Master’s Thesis, Reykjavik University, Reykjavik, Iceland, 2020. [Google Scholar]
- Ouellette, N.T.; Xu, H.; Bodenschatz, E. A quantitative study of three-dimensional Lagrangian particle tracking algorithms. Exp. Fluids 2006, 40, 301–313. [Google Scholar] [CrossRef]
- Lee, C.M.; Gylfason, A.; Perlekar, P.; Toschi, F. Inertial particle acceleration in strained turbulence. J. Fluid Mech. 2015, 785, 31–53. [Google Scholar] [CrossRef]
- Ayyalasomayajula, S.; Warhaft, Z. Nonlinear interactions in strained axisymmetric high-Reynolds-number turbulence. J. Fluid Mech. 2006, 566, 273–307. [Google Scholar] [CrossRef]
- Cho, K.; van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder–Decoder Approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In 12th USENIX Symposium on Operating Systems Design and Implementation; USENIX Association: Berkeley, CA, USA, 2016. [Google Scholar]
- Kramer, O. Scikit-learn. Mach. Learn. Evol. Strateg. 2016, 20, 45–53. [Google Scholar]
- Alvarez, D. JUWELS Cluster and Booster: Exascale Pathfinder with Modular Supercomputing Architecture at Juelich Supercomputing Centre. J. Large-Scale Res. Facil. JLSRF 2021, 7, A183. [Google Scholar] [CrossRef]
- TensorFlow. TensorFlow Core Tutorials; TensorFlow: Mountain View, CA, USA, 2022. [Google Scholar]
- Hager, G.; Wellein, G. Introduction to High Performance Computing for Scientists and Engineers; Chapman & Hall/CRC Computational Science: London, UK, 2010. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Proportion | Performance | GRU-h | Transformer | LSTM | GRU |
|---|---|---|---|---|---|
| 80% | MAE | 0.001 | 0.002 | 0.001 | 0.002 |
| score | 0.99 | 0.98 | 0.98 | 0.98 | |
| Runtime (s) | 256 | 301 | 295 | 318 |
| Machine Module | Node | GPUs | Computing Time [s] | Speedup |
|---|---|---|---|---|
| JUWELS- | 1 | 1 | 5801.20 | 1 |
| BOOSTER | 1 | 2 | 3640.31 | 1.59 |
| 1 | 3 | 2719.36 | 2.13 | |
| 1 | 4 | 2252.52 | 2.57 | |
| DEEP-DAM | 1 | 1 | 5802.60 | 1 |
| Machine Module | GPUs | Batch Size per GPU | Computing Time [s] | MAE |
|---|---|---|---|---|
| JUWELS- | 4 | 8 | 14,723.30 | 0.0016698 |
| BOOSTER | 4 | 16 | 7499.96 | 0.0015822 |
| 4 | 32 | 3757.98 | 0.0015293 | |
| 4 | 64 | 1820.90 | 0.0014718 | |
| 4 | 128 | 963.49 | 0.0014551 | |
| 4 | 256 | 493.07 | 0.0013771 | |
| 4 | 512 | 255.93 | 0.0013613 | |
| 4 | 1024 | 147.70 | 0.0014453 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hassanian, R.; Aach, M.; Lintermann, A.; Helgadóttir, Á.; Riedel, M. Turbulent Flow Prediction-Simulation: Strained Flow with Initial Isotropic Condition Using a GRU Model Trained by an Experimental Lagrangian Framework, with Emphasis on Hyperparameter Optimization. Fluids 2024, 9, 84. https://doi.org/10.3390/fluids9040084
Hassanian R, Aach M, Lintermann A, Helgadóttir Á, Riedel M. Turbulent Flow Prediction-Simulation: Strained Flow with Initial Isotropic Condition Using a GRU Model Trained by an Experimental Lagrangian Framework, with Emphasis on Hyperparameter Optimization. Fluids. 2024; 9(4):84. https://doi.org/10.3390/fluids9040084
Chicago/Turabian StyleHassanian, Reza, Marcel Aach, Andreas Lintermann, Ásdís Helgadóttir, and Morris Riedel. 2024. "Turbulent Flow Prediction-Simulation: Strained Flow with Initial Isotropic Condition Using a GRU Model Trained by an Experimental Lagrangian Framework, with Emphasis on Hyperparameter Optimization" Fluids 9, no. 4: 84. https://doi.org/10.3390/fluids9040084
APA StyleHassanian, R., Aach, M., Lintermann, A., Helgadóttir, Á., & Riedel, M. (2024). Turbulent Flow Prediction-Simulation: Strained Flow with Initial Isotropic Condition Using a GRU Model Trained by an Experimental Lagrangian Framework, with Emphasis on Hyperparameter Optimization. Fluids, 9(4), 84. https://doi.org/10.3390/fluids9040084