Genesis of Non-Coding RNA Genes in Human Chromosome 22—A Sequence Connection with Protein Genes Separated by Evolutionary Time


Abstract
:1. Introduction
2. Background on Conserved Linked Sequences
3. lincRNA Gene Families
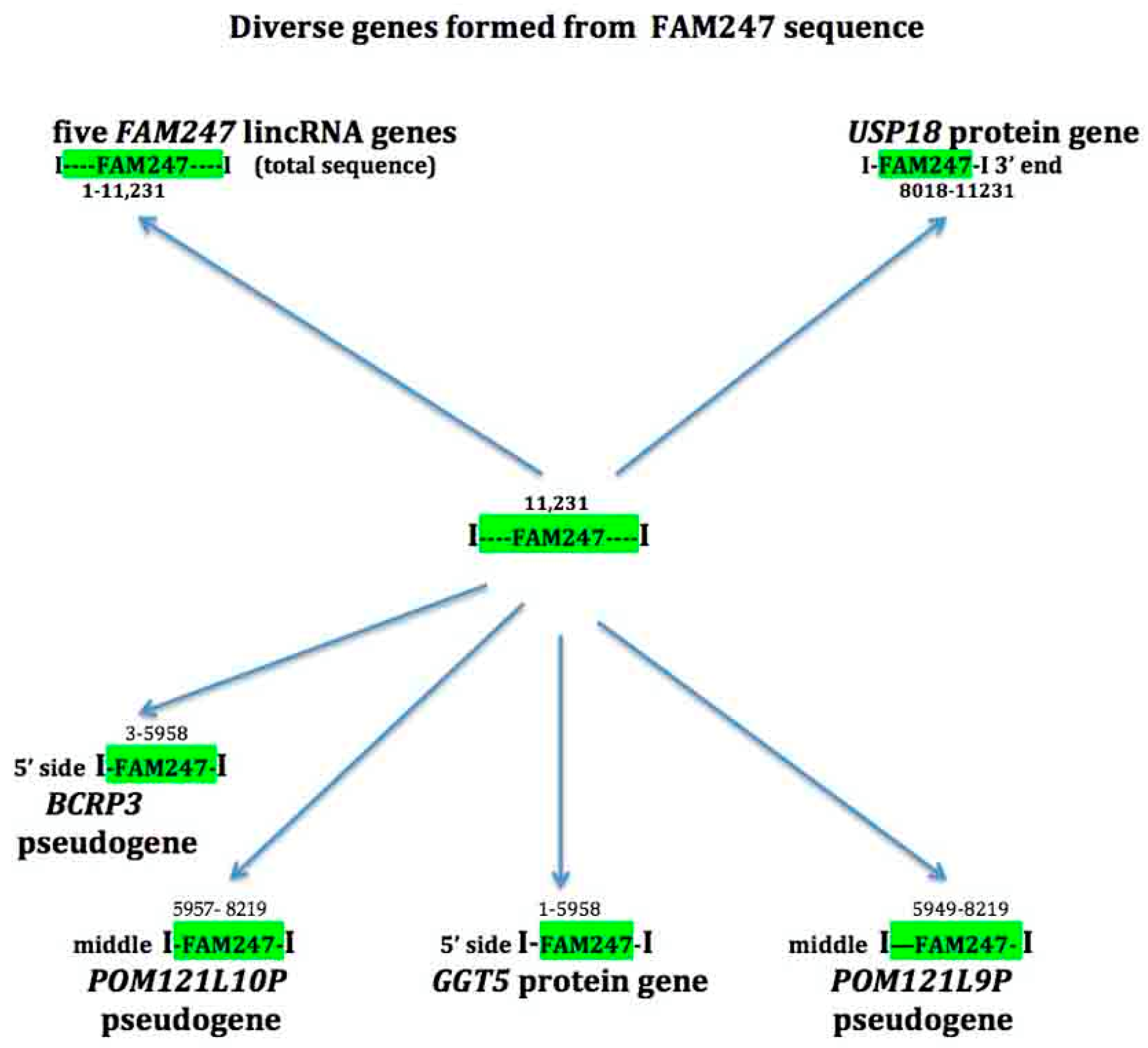
4. The FAM247 Sequence is Present in Diverse Genes
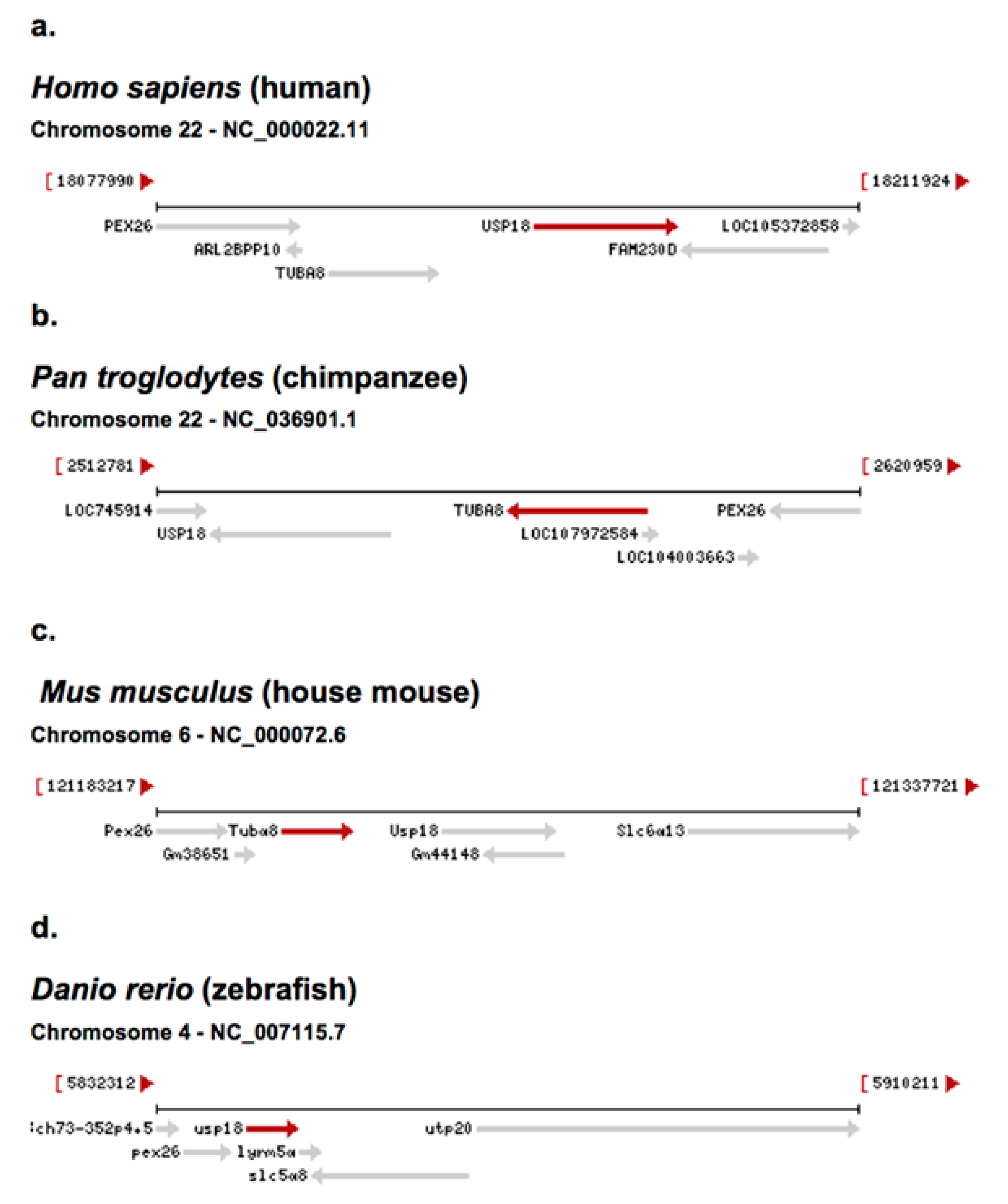
4.1. USP18
4.2. USP18 Exon 11
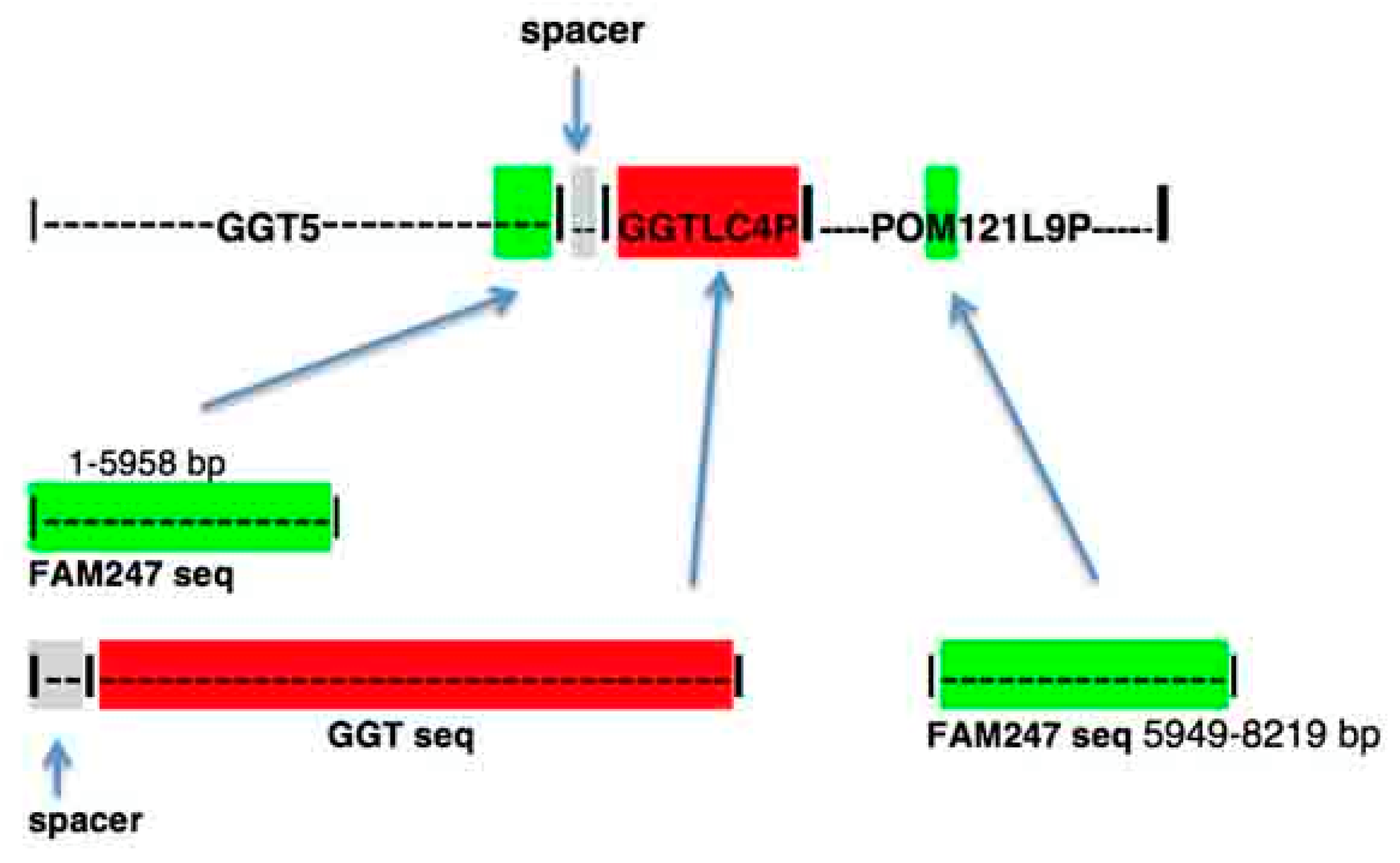
4.3. GGT5
4.4. Pseudogene POM121L9P
4.5. Pseudogenes BCRP3 and POM121L10P
5. Conclusions
Funding
Conflicts of Interest
References
- Ohno, S. Gene duplication and the uniqueness of vertebrate genomes circa 1970–1999. Semin. Cell Dev. Biol. 1999, 10, 517–522. [Google Scholar] [CrossRef]
- Jacob, F. Evolution and tinkering. Science 1977, 196, 1161–1166. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, W.; Yu, H.; Long, M. Duplication-degeneration as a mechanism of gene fission and the origin of new genes in Drosophila species. Nat. Genet. 2004, 36, 523–527. [Google Scholar] [CrossRef]
- Carvunis, A.R.; Rolland, T.; Wapinski, I.; Calderwood, M.A.; Yildirim, M.A.; Simonis, N.; Charloteaux, B.; Hidalgo, C.A.; Barbette, J.; Santhanam, B.; et al. Proto-genes and de novo gene birth. Nature 2012, 487, 370–374. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McLysaght, A.; Guerzoni, D. New genes from non-coding sequence: The role of de novo protein-coding genes in eukaryotic evolutionary innovation. Philos. Trans. R. Soc. B Biol. Sci. 2015, 370, 20140332. [Google Scholar] [CrossRef] [Green Version]
- Schlotterer, C. Genes from scratch—The evolutionary fate of de novo genes. Trends Genet. 2015, 31, 215–219. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van Oss, S.B.; Carvunis, A.R. De novo gene birth. PLoS Genet. 2019, 15, e1008160. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ulitsky, I.; Bartel, D.P. lincRNAs: Genomics, evolution, and mechanisms. Cell 2013, 154, 26–46. [Google Scholar] [CrossRef] [Green Version]
- Delihas, N. Formation of human long intergenic non-coding RNA genes, pseudogenes, and protein genes: Ancestral sequences are key players. PLoS ONE 2020, 15, e0230236. [Google Scholar] [CrossRef] [Green Version]
- Nowell, P.; Hungerford, D. A minute chromosome in human chronic granulocytic leukemia. Science 1960, 132, 1497. [Google Scholar]
- De Klein, A.; van Kessel, A.G.; Grosveld, G.; Bartram, C.R.; Hagemeijer, A.; Bootsma, D.; Spurr, N.K.; Heisterkamp, N.; Groffen, J.; Stephenson, J.R. A cellular oncogene is translocated to the Philadelphia chromosome in chronic myelocytic leukaemia. Nature 1982, 300, 765–767. [Google Scholar] [CrossRef] [PubMed]
- Arimoto, K.I.; Löchte, S.; Stoner, S.A.; Burkart, C.; Zhang, Y.; Miyauchi, S.; Wilmes, S.; Fan, J.B.; Heinisch, J.J.; Li, Z.; et al. STAT2 is an essential adaptor in USP18-mediated suppression of type I interferon signaling. Nat. Struct. Mol. Biol. 2017, 24, 279–289. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Honke, N.; Shaabani, N.; Zhang, D.E.; Hardt, C.; Lang, K.S. Multiple functions of USP18. Cell Death Dis. 2016, 7, e2444. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bruford, E.A.; Braschi, B.; Denny, P.; Jones, T.E.M.; Seal, R.L.; Tweedie, S. Guidelines for human gene nomenclature. Nat. Genet. 2020, 52, 754–758. [Google Scholar] [CrossRef] [PubMed]
- Szabo, L.; Morey, R.; Palpant, N.J.; Wang, P.L.; Afari, N.; Jiang, C.; Parast, M.M.; Murry, C.; Laurent, L.C.; Salzman, J. Statistically based splicing detection reveals neural enrichment and tissue-specific induction of circular RNA during human fetal development. Genome Biol. 2015, 16, 126. [Google Scholar] [CrossRef] [Green Version]
- Fagerberg, L.; Hallström, B.M.; Oksvold, P.; Kampf, C.; Djureinovic, D.; Odeberg, J.; Habuka, M.; Tahmasebpoor, S.; Danielsson, A.; Edlund, K.; et al. Analysis of the human tissue-specific expression by genome-wide integration of transcriptomics and antibody based proteomics. Mol. Cell. Proteom. 2014, 13, 397–406. [Google Scholar] [CrossRef] [Green Version]
- O’Leary, N.A.; Wright, M.W.; Brister, J.R.; Ciufo, S.; Haddad, D.; McVeigh, R.; Rajput, B.; Robbertse, B.; Smith-White, B.; Ako-Adjei, D.; et al. Reference sequence (RefSeq) database at NCBI: Current status, taxonomic expansion, and functional annotation. Nucleic Acids Res. 2016, 44, D733–D745. [Google Scholar] [CrossRef] [Green Version]
- Siepel, A. Phylogenomics of primates and their ancestral populations. Genome Res. 2009, 19, 1929–1941. [Google Scholar] [CrossRef] [Green Version]
- Madeira, F.; Park, Y.M.; Lee, J.; Buso, N.; Gur, T.; Madhusoodanan, N.; Basutkar, P.; Tivey, A.R.N.; Potter, S.C.; Finn, R.D.; et al. The EMBL-EBI Search and Sequence Analysis Tools APIs in 2019. Nucleic Acids Res. 2019, 47, W636–W641. [Google Scholar] [CrossRef] [Green Version]
- Malakhov, M.P.; Malakhova, O.A.; Kim, K.I.; Ritchie, K.J.; Zhang, D.E. Protein ISGylation Modulates the JAK-STAT Signaling Pathway. J. Biol. Chem. 2002, 277, 9976–9981. [Google Scholar] [CrossRef] [Green Version]
- Dauphinee, S.M.; Richer, E.; Eva, M.M.; McIntosh, F.; Paquet, M.; Dangoor, D.; Burkart, C.; Zhang, D.E.; Gruenheid, S.; Gros, P. Contribution of increased ISG15, ISGylation and deregulated type I IFN signaling in Usp18 mutant mice during the course of bacterial infections. Genes Immun. 2014, 15, 282–292. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redaelli, S.; Maitz, S.; Crosti, F.; Sala, E.; Villa, N.; Spaccini, L.; Selicorni, A.; Rigoldi, M.; Conconi, D.; Dalprà, L.; et al. Refining the phenotype of recurrent rearrangements of chromosome 16. Int. J. Mol. Sci. 2019, 20, 1095. [Google Scholar] [CrossRef] [PubMed] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gene/Gene Family | Type | Locus Origin |
|---|---|---|
| * FAM230A-J | lincRNA | FAM230 |
| FAM247A-D | lincRNA | FAM247 |
| POM121L9P, POM121L10P | pseudogene | FAM247 |
| BCRP3 | pesudogene | FAM247 |
| GGT1, GGT2 | protein | GGT |
| GGTLC2 | protein | GGT |
| GGTLC3 | protein | GGT |
| GGT3P | pseudogene | GGT |
| GGT4P | pseudogene | GGT |
| GGTLC4P | pseudogene | GGT |
| GGTLC5P | pseudogene | GGT |
| GGT5 | protein | FAM247 |
| USP18 | protein | FAM247 |
| Species | USP18 Gene nt Sequence %Identity | USP18 aa Sequence %Identity | Evolutionary Age (MYA) * |
|---|---|---|---|
| human | 100% | 100% | 0 MYA |
| chimpanzee | 99% | 99% | 6 MYA |
| Rhesus monkey | 92% | 94% | 25 MYA |
| Philippine tarsier | 66% | 80% | 50 MYA |
| mouse | 51% | 71% | 90 MYA |
| zebrafish | 39% | 31% | 350 MYA |
| Source of nt Sequence | % Identity Relative to FAM247 3′ End |
|---|---|
| FAM247A 3′ end nt 10,653–11,231 | 100 |
| USP18 3′UTR human | 99.8 |
| USP18 3′UTR chimp | 98.6 |
| USP18 3′UTR Rhesus monkey | 90.2 |
| USP18 3′UTR Philippine tarsier | 71.9 |
| USP18 3′UTR mouse | 49.5 |
| USP18 3′UTR zebrafish | 53.1 |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Delihas, N. Genesis of Non-Coding RNA Genes in Human Chromosome 22—A Sequence Connection with Protein Genes Separated by Evolutionary Time. Non-Coding RNA 2020, 6, 36. https://doi.org/10.3390/ncrna6030036
Delihas N. Genesis of Non-Coding RNA Genes in Human Chromosome 22—A Sequence Connection with Protein Genes Separated by Evolutionary Time. Non-Coding RNA. 2020; 6(3):36. https://doi.org/10.3390/ncrna6030036
Chicago/Turabian StyleDelihas, Nicholas. 2020. "Genesis of Non-Coding RNA Genes in Human Chromosome 22—A Sequence Connection with Protein Genes Separated by Evolutionary Time" Non-Coding RNA 6, no. 3: 36. https://doi.org/10.3390/ncrna6030036
APA StyleDelihas, N. (2020). Genesis of Non-Coding RNA Genes in Human Chromosome 22—A Sequence Connection with Protein Genes Separated by Evolutionary Time. Non-Coding RNA, 6(3), 36. https://doi.org/10.3390/ncrna6030036