Acknowledgments
The first author would like to thank Indonesia Endowment Fund for Education (LPDP) of Ministry of Finance, Republic of Indonesia, for funding his study at School of Informatics, the University of Edinburgh. Funds from Row Fogo Charitable Trust (MCVH) are also gratefully acknowledged. Data collection and sharing for this project was funded by the Alzheimer’s Disease Neuroimaging Initiative (ADNI) (National Institutes of Health Grant U01 AG024904) and DOD ADNI (Department of Defense award number W81XWH-12-2-0012). ADNI is funded by the National Institute on Aging, the National Institute of Biomedical Imaging and Bioengineering, and through generous contributions from the following: AbbVie, Alzheimer’s Association; Alzheimer’s Drug Discovery Foundation; Araclon Biotech; BioClinica, Inc.; Biogen; Bristol-Myers Squibb Company; CereSpir, Inc.; Cogstate; Eisai Inc.; Elan Pharmaceuticals, Inc.; Eli Lilly and Company; EuroImmun; F. Hoffmann-La Roche Ltd and its affiliated company Genentech, Inc.; Fujirebio; GE Healthcare; IXICO Ltd.; Janssen Alzheimer Immunotherapy Research and Development, LLC.; Johnson and Johnson Pharmaceutical Research and Development LLC.; Lumosity; Lundbeck; Merck and Co., Inc.; Meso Scale Diagnostics, LLC.; NeuroRx Research; Neurotrack Technologies; Novartis Pharmaceuticals Corporation; Pfizer Inc.; Piramal Imaging; Servier; Takeda Pharmaceutical Company; and Transition Therapeutics. The Canadian Institutes of Health Research is providing funds to support ADNI clinical sites in Canada. Private sector contributions are facilitated by the Foundation for the National Institutes of Health (
www.fnih.org). The grantee organization is the Northern California Institute for Research and Education, and the study is coordinated by the Alzheimer’s Therapeutic Research Institute at the University of Southern California. ADNI data are disseminated by the Laboratory for Neuro Imaging at the University of Southern California. Data used in preparation of this article were obtained from the Alzheimer’s Disease Neuroimaging Initiative (ADNI) database (
adni.loni.usc.edu). As such, the investigators within the ADNI contributed to the design and implementation of ADNI and/or provided data but did not participate in analysis or writing of this report. A complete listing of ADNI investigators can be found at:
http://adni.loni.usc.edu/wp-content/uploads/how_to_apply/ADNI_Acknowledgement_List.pdf.
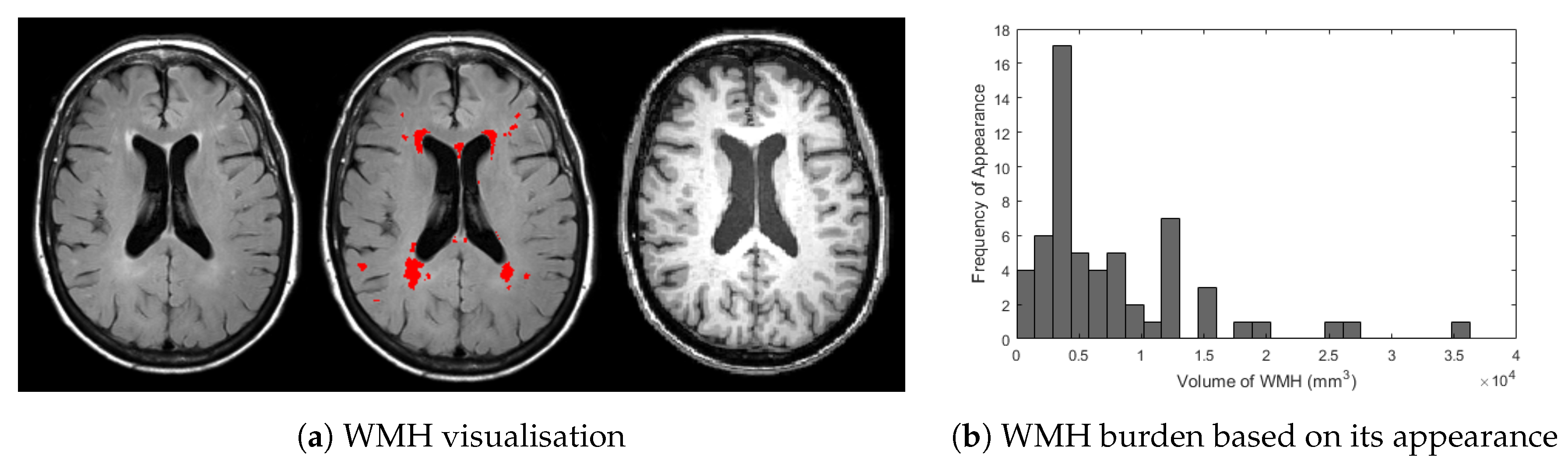
Figure 1.
(a) Visualisation of WMH in T2-FLAIR (left) and T1-weighted (right) of MRI and (b) histogram frequency of appearance based on WMH burden from ADNI dataset used in this study. In (a) above, bright regions of WMH are overlaid by red masks marked by clinical observer (centre). Whereas, histogram in (b) were produced by calculating WMH volume for all 60 MRI data from ADNI dataset used in this study.
Figure 1.
(a) Visualisation of WMH in T2-FLAIR (left) and T1-weighted (right) of MRI and (b) histogram frequency of appearance based on WMH burden from ADNI dataset used in this study. In (a) above, bright regions of WMH are overlaid by red masks marked by clinical observer (centre). Whereas, histogram in (b) were produced by calculating WMH volume for all 60 MRI data from ADNI dataset used in this study.
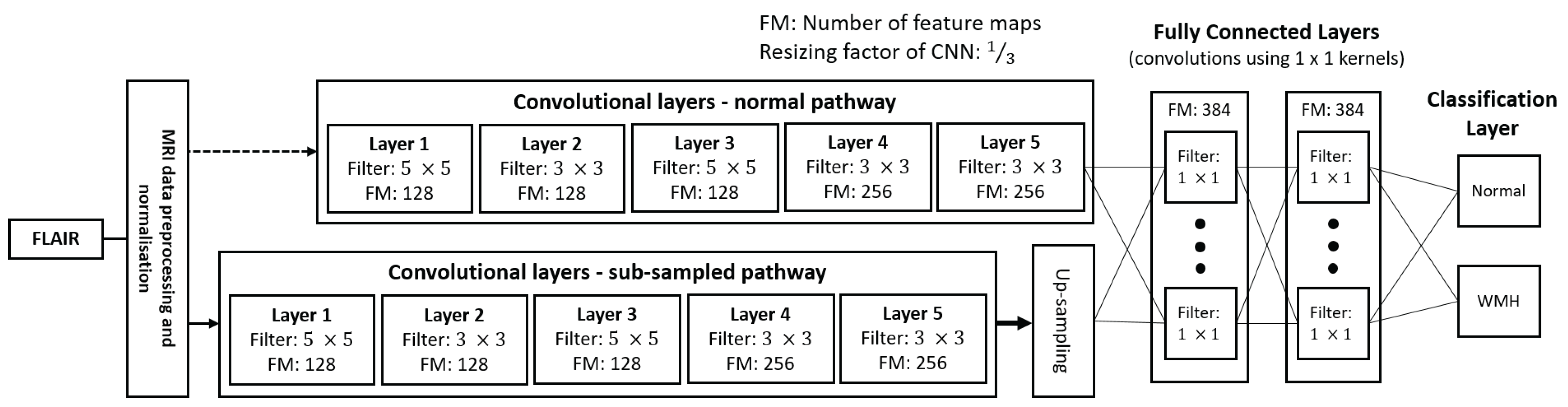
Figure 2.
Illustrations of (
a) DBM and (
b) convolutional encoder network (CEN) used in this study. In (
a), two RBMs are stacked together for pre-training (
left) to form a DBM (
right). In (
b), input image is encoded by using two convolutional layers and an average pooling layer and decoded to WMH segmentation using two de-convolutional layers and an un-pooling layer. This architecture is inspired from [
8,
9].
Figure 2.
Illustrations of (
a) DBM and (
b) convolutional encoder network (CEN) used in this study. In (
a), two RBMs are stacked together for pre-training (
left) to form a DBM (
right). In (
b), input image is encoded by using two convolutional layers and an average pooling layer and decoded to WMH segmentation using two de-convolutional layers and an un-pooling layer. This architecture is inspired from [
8,
9].
Figure 3.
Architecture patch-wise convolutional neural network (patch-CNN) used in this study which is created using DeepMedic. See DeepMedic’s paper [
7] for full explanation of the architecture.
Figure 3.
Architecture patch-wise convolutional neural network (patch-CNN) used in this study which is created using DeepMedic. See DeepMedic’s paper [
7] for full explanation of the architecture.
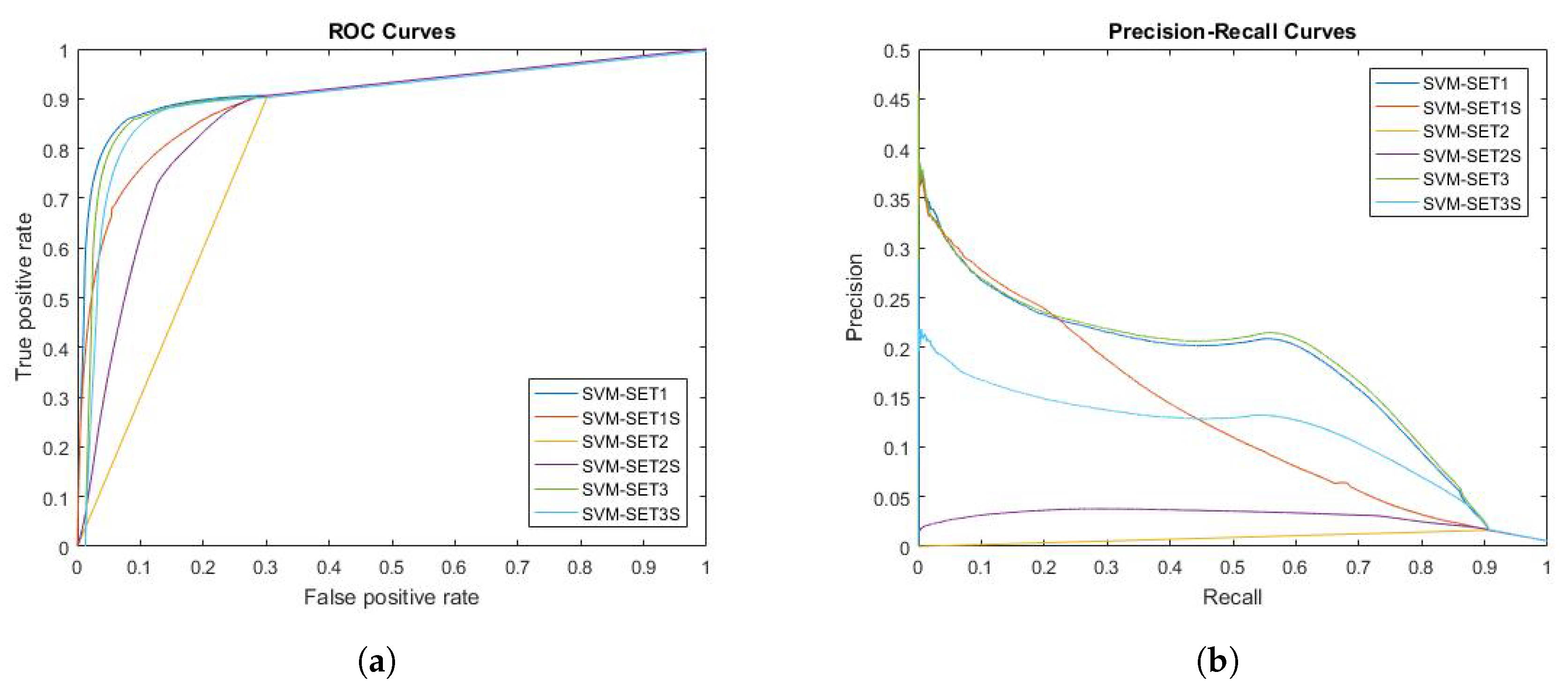
Figure 4.
Receiver operating characteristic (ROC) and precision-recall (PR) curves of SVM for all evaluated voxels. Six different ways of extracting features from MRI are tested and evaluated in this experiment. (a) ROC curve of SVM; (b) PR curve of SVM.
Figure 4.
Receiver operating characteristic (ROC) and precision-recall (PR) curves of SVM for all evaluated voxels. Six different ways of extracting features from MRI are tested and evaluated in this experiment. (a) ROC curve of SVM; (b) PR curve of SVM.
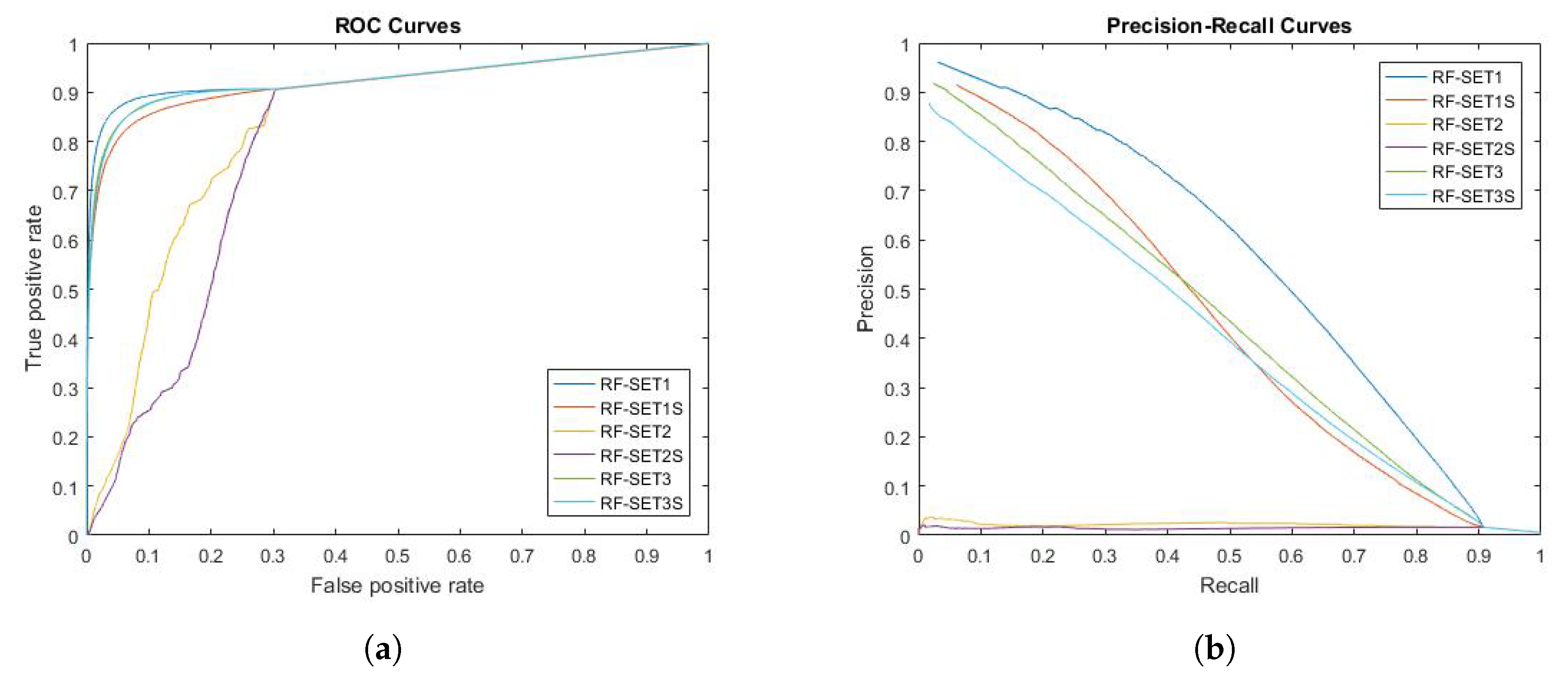
Figure 5.
Receiver operating characteristic (ROC) curve and precision-recall curve of RF for all evaluated voxels. Six different ways of extracting features from MRI are tested and evaluated in this experiment. (a) ROC curve of RF; (b) Precision-recall curve of RF.
Figure 5.
Receiver operating characteristic (ROC) curve and precision-recall curve of RF for all evaluated voxels. Six different ways of extracting features from MRI are tested and evaluated in this experiment. (a) ROC curve of RF; (b) Precision-recall curve of RF.
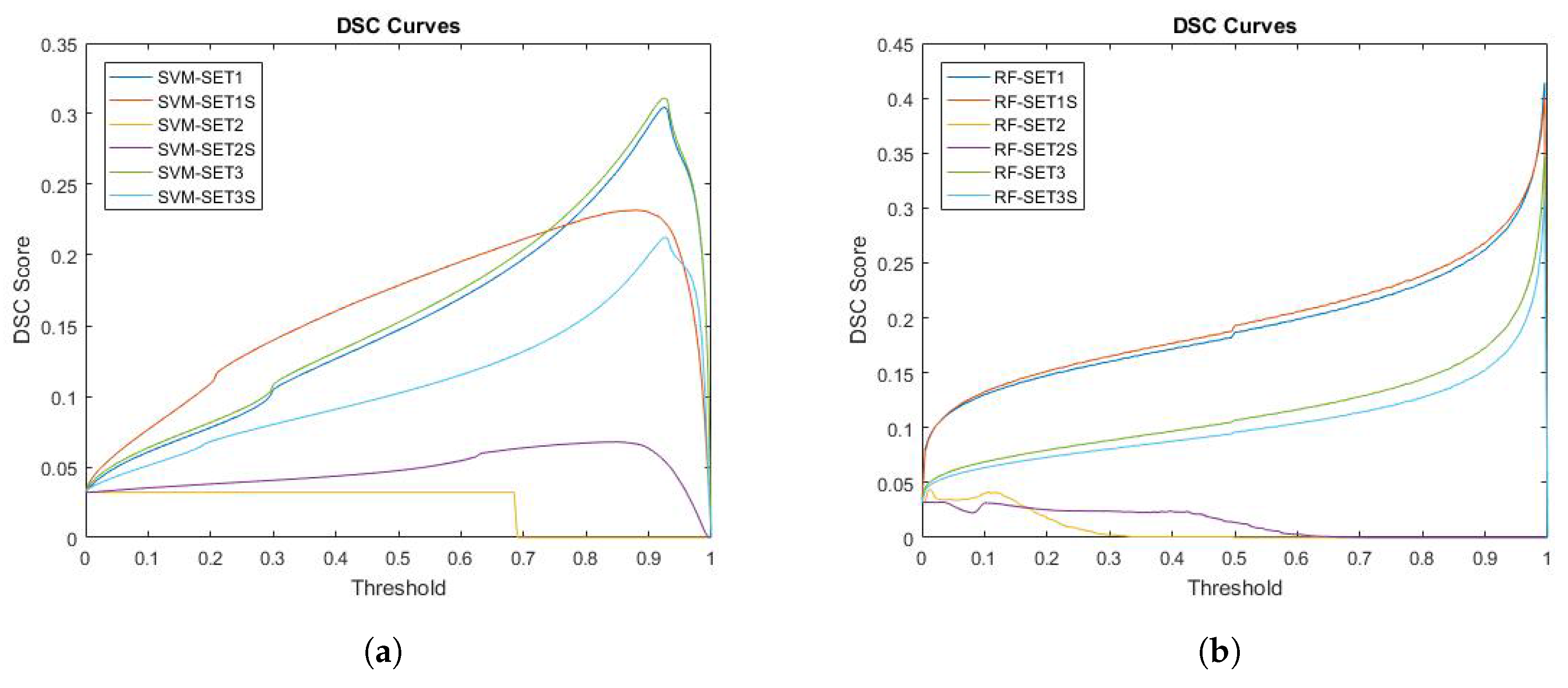
Figure 6.
DSC curves for both SVM and RF. Six different ways of extracting features from MRI are tested and evaluated in this experiment. (a) DSC curve of SVM; (b) DSC curve of RF.
Figure 6.
DSC curves for both SVM and RF. Six different ways of extracting features from MRI are tested and evaluated in this experiment. (a) DSC curve of SVM; (b) DSC curve of RF.
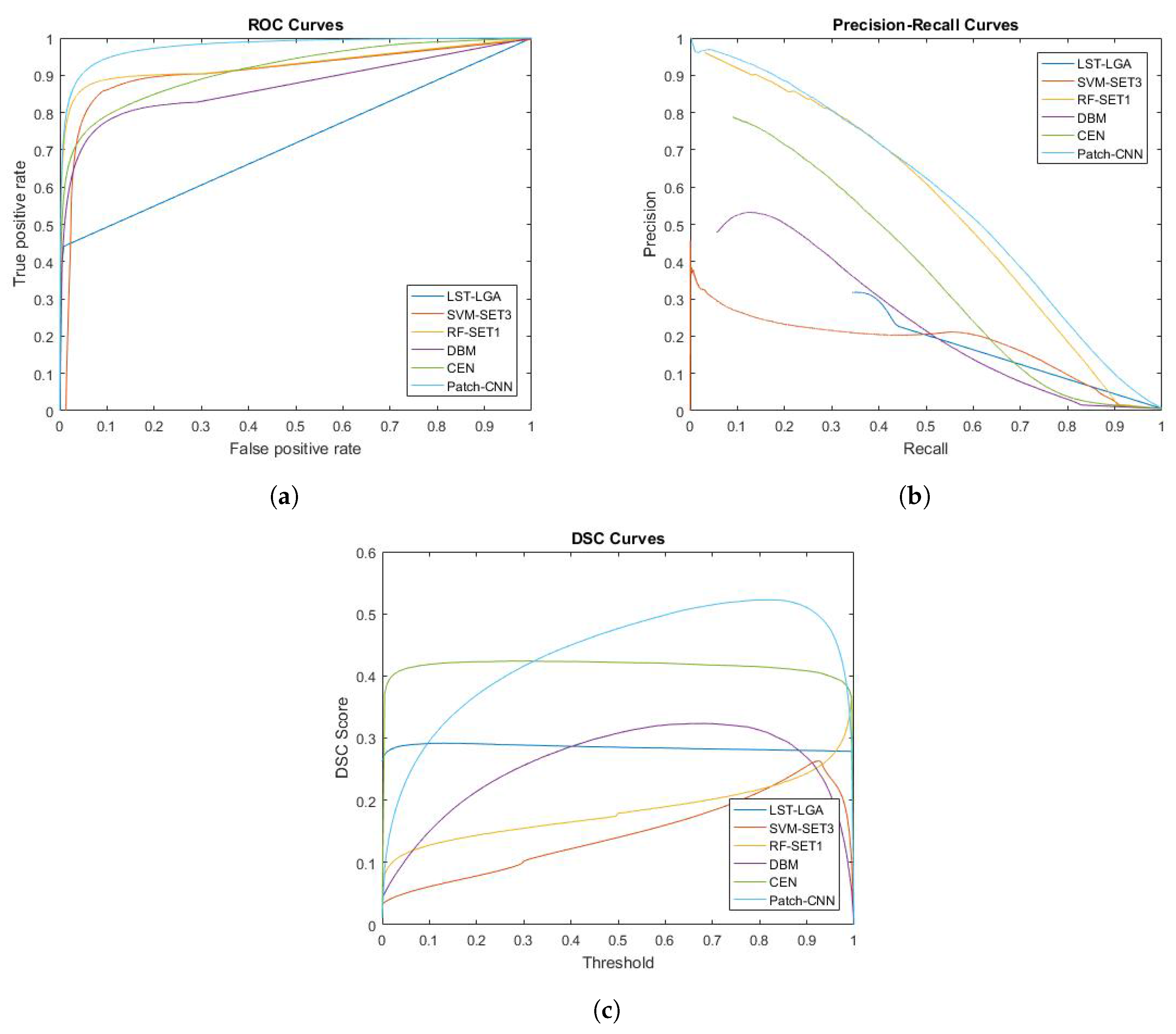
Figure 7.
Performance curves of ROC, PR and DSC for LST-LGA, SVM-SET3, RF-SET1, DBM, CEN and patch-CNN. SVM-SET3 and RF-SET1 represent conventional machine learning algorithm chosen from previous experiment while DBM, CEN and patch-CNN represent deep learning algorithm. On the other hand, LGA is unsupervised learning algorithm from LST toolbox. (a) ROC curve; (b) Precision-recall curve; (c) DSC curve.
Figure 7.
Performance curves of ROC, PR and DSC for LST-LGA, SVM-SET3, RF-SET1, DBM, CEN and patch-CNN. SVM-SET3 and RF-SET1 represent conventional machine learning algorithm chosen from previous experiment while DBM, CEN and patch-CNN represent deep learning algorithm. On the other hand, LGA is unsupervised learning algorithm from LST toolbox. (a) ROC curve; (b) Precision-recall curve; (c) DSC curve.
Figure 8.
Distribution of DSC scores for each group based on WMH volume burden. (1), (2), (3), (4), (5) and (6) represent methods listed in
Table 5, which are (1) LST-LGA, (2) SVM-SET3, (3) RF-SET1, (4) DBM, (5) CEN and (6) Patch-CNN.
Figure 8.
Distribution of DSC scores for each group based on WMH volume burden. (1), (2), (3), (4), (5) and (6) represent methods listed in
Table 5, which are (1) LST-LGA, (2) SVM-SET3, (3) RF-SET1, (4) DBM, (5) CEN and (6) Patch-CNN.
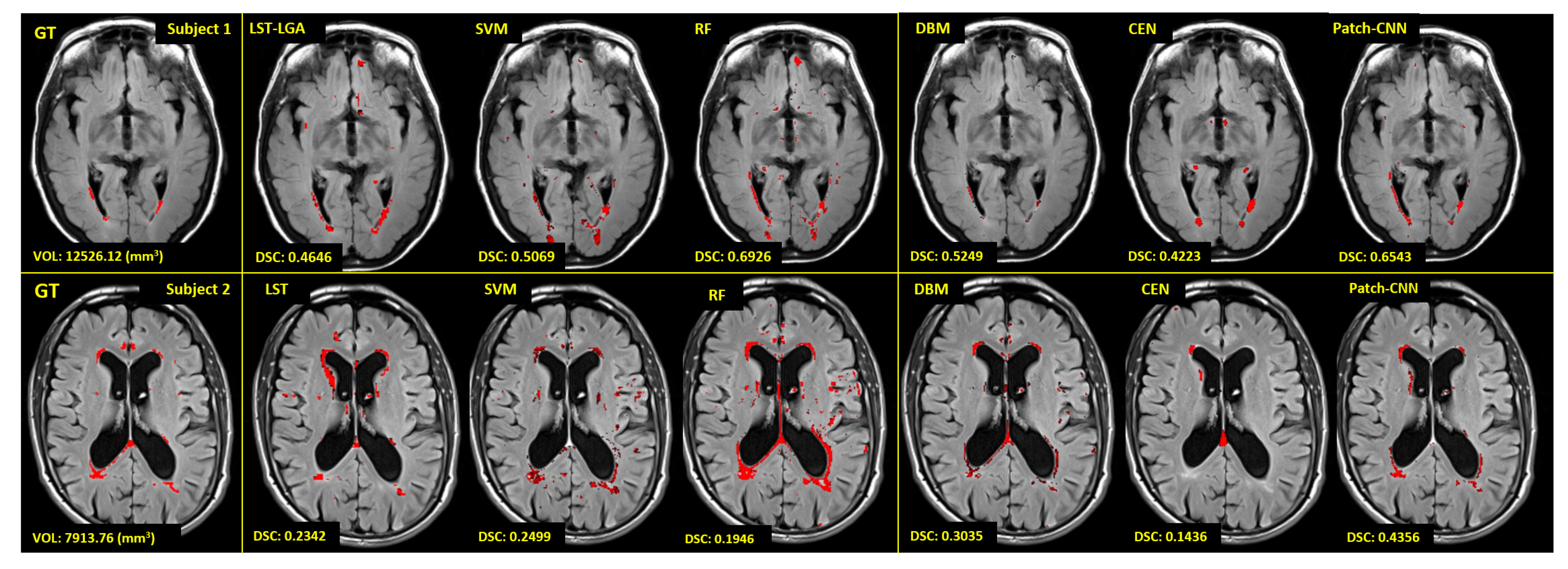
Figure 9.
Visualisation of automatic WMH segmentation results from LST-LGA, SVM-SET3, RF-SET1, DBM, CEN and patch-CNN. Red regions are WMH labelled by experts (GT) or conventional/deep learning algorithms. We visualise two different subjects with very different WMH burden to see how the WMH volume affects the performance of conventional/deep learning algorithms. Volume of WMH and value of the DSC metric for each algorithm are at the bottom left on each respective image.
Figure 9.
Visualisation of automatic WMH segmentation results from LST-LGA, SVM-SET3, RF-SET1, DBM, CEN and patch-CNN. Red regions are WMH labelled by experts (GT) or conventional/deep learning algorithms. We visualise two different subjects with very different WMH burden to see how the WMH volume affects the performance of conventional/deep learning algorithms. Volume of WMH and value of the DSC metric for each algorithm are at the bottom left on each respective image.
Table 1.
Data acquisition protocol parameters.
Table 1.
Data acquisition protocol parameters.
| Parameter | T1-Weighted | T2-FLAIR |
|---|
| In-plane matrix (pixels) | 256 × 256 | 256 × 256 |
| Number of Slices | 256 | 35 |
| Thickness (mm) | 1.2 | 5 |
| In-plane resolution (mm) | 1.0 × 1.0 | 0.8594 × 0.8594 |
| Repetition Time (TR) (ms) | 2300 | 9000 |
| Echo Time (TE) (ms) | 2.98 | 90 or 91 |
| Flip Angle | 9.0 | 90 or 150 |
| Pulse Sequence | GR/IR | SE/IR |
Table 2.
Summary of all machine learning algorithms used in this study and their configurations: SPV, DL and CML stand for “Supervised”, “Deep Learning” and “Conventional Machine Learning”.
Table 2.
Summary of all machine learning algorithms used in this study and their configurations: SPV, DL and CML stand for “Supervised”, “Deep Learning” and “Conventional Machine Learning”.
| No. | Method | SPV | DL/CML | Modality | Dimension of Input |
|---|
| 1 | LST-LGA | No | CML | FLAIR only | 1 MRI data () |
| 2 | SVM | Yes | CML | FLAIR & T1W | 3D patch () |
| 3 | RF | Yes | CML | FLAIR & T1W | 3D patch () |
| 4 | DBM | Yes | DL | FLAIR only | 3D patch () |
| 5 | CEN | Yes | DL | FLAIR only | 1 slice of MRI () |
| 6 | Patch-CNN | Yes | DL | FLAIR only | 2D patch () |
Table 3.
Parameters of patch-wise convolutional neural network (adopted from [
7]).
Table 3.
Parameters of patch-wise convolutional neural network (adopted from [
7]).
| Patch-Wise Convolutional Neural Network |
|---|
| Stage | Paramete | Value |
| Initialisation | weights | [39] |
| Regularisation | L1 | 0.000001 |
| L2 | 0.0001 |
| Dropout | p-2nd last layer | 0.5 |
| p-Last layer | 0.5 |
| Training | epochs | 35 |
| momentum | 0.5 |
| Initial learning rate | 0.001 |
Table 4.
Experiment results based on several metrics which are dice similarity coefficient (DSC), sensitivity (Sen.), specificity (Spe.) and precision (Pre.). Higher scores of DSC, sensitivity, specificity and precision are better. Values in bold are the best score for each evaluation column whereas values in italic are the second-best score.
Table 4.
Experiment results based on several metrics which are dice similarity coefficient (DSC), sensitivity (Sen.), specificity (Spe.) and precision (Pre.). Higher scores of DSC, sensitivity, specificity and precision are better. Values in bold are the best score for each evaluation column whereas values in italic are the second-best score.
| No. | Method | Threshold | DSC | Sen. | Spe. | Pre. |
|---|
| 1 | LST-LGA [12] | 0.13 | 0.2954 | 0.9955 | 0.3438 | 0.9966 |
| 2 | SVM-SET3 | 0.92 | 0.2790 | 0.9893 | 0.5371 | 0.9977 |
| 3 | RF-SET1 | 0.98 | 0.3285 | 0.9866 | 0.7362 | 0.9987 |
| 4 | DBM | 0.68 | 0.3359 | 0.9971 | 0.3583 | 0.9964 |
| 5 | CEN | 0.31 | 0.4243 | 0.9976 | 0.4567 | 0.9968 |
| 6 | Patch-CNN | 0.81 | 0.5376 | 0.9983 | 0.5385 | 0.9974 |
Table 5.
Average values of dice similarity coefficient (DSC) and volume difference ratio (VDR) for grouped MRI data based on its WMH burden. VS, S, M, L and VL stand for “Very Small”, “Small”, “Medium”, “Large” and “Very Large” which are names of the groups. Higher score of DSC is better whereas near-zero VDR score is better. Values in bold are the best score for each evaluation column whereas values in italic are the second-best score.
Table 5.
Average values of dice similarity coefficient (DSC) and volume difference ratio (VDR) for grouped MRI data based on its WMH burden. VS, S, M, L and VL stand for “Very Small”, “Small”, “Medium”, “Large” and “Very Large” which are names of the groups. Higher score of DSC is better whereas near-zero VDR score is better. Values in bold are the best score for each evaluation column whereas values in italic are the second-best score.
| Method | DSC | VDR |
|---|
| VS | S | M | L | VL | VS | S | M | L | VL |
|---|
| 1 | LST-LGA | 0.0671 | 0.2301 | 0.3518 | 0.3623 | 0.6130 | 4.3064 | 1.2886 | 0.2155 | 0.0174 | −0.3116 |
| 2 | SVM-SET3 | 0.0605 | 0.1888 | 0.3384 | 0.4861 | 0.5139 | 30.2538 | 4.1495 | 1.5375 | 0.3041 | 0.7383 |
| 3 | RF-SET1 | 0.0938 | 0.2230 | 0.3953 | 0.5862 | 0.5636 | 23.0259 | 5.7081 | 2.5821 | 0.4505 | 1.2762 |
| 4 | DBM | 0.2369 | 0.3000 | 0.3687 | 0.3355 | 0.5152 | 1.5353 | 0.5706 | 0.0795 | −0.7121 | −0.2331 |
| 5 | CEN | 0.2029 | 0.4200 | 0.4560 | 0.4075 | 0.5997 | 6.6595 | 0.4765 | −0.1408 | −0.5049 | −0.4751 |
| 6 | Patch-CNN | 0.2723 | 0.5160 | 0.5857 | 0.6048 | 0.6489 | 4.7211 | 0.6120 | −0.0641 | −0.2139 | −0.4382 |
Table 6.
Volume difference ratio (VDR) and volumetric disagreement (D) with observers’ measurements for LST-LGA, SVM-SET3, RF-SET1, DBM, CEN and patch-CNN. Near zero of VDR score is better. Whereas, lower score of D in Label. 1, Label. 2, Obs. 1 and Obs. 2 is better. Values in bold are the best score for D evaluation whereas values in italic are the second-best score.
Table 6.
Volume difference ratio (VDR) and volumetric disagreement (D) with observers’ measurements for LST-LGA, SVM-SET3, RF-SET1, DBM, CEN and patch-CNN. Near zero of VDR score is better. Whereas, lower score of D in Label. 1, Label. 2, Obs. 1 and Obs. 2 is better. Values in bold are the best score for D evaluation whereas values in italic are the second-best score.
| | Method | VDR | Intra-D (%) | Inter-D (%) |
|---|
| Label. 1 | SD | Label. 2 | SD | Obs. 1 | SD | Obs. 2 | SD |
|---|
| 1 | LST-LGA | 0.9249 | 70.40 | 34.28 | 81.12 | 48.35 | 60.59 | 41.58 | 49.89 | 42.37 |
| 2 | SVM-SET3 | 4.7891 | 99.50 | 50.29 | 111.24 | 55.31 | 118.93 | 48.48 | 111.26 | 47.58 |
| 3 | RF-SET1 | 5.2411 | 111.24 | 55.31 | 123.31 | 57.26 | 132.34 | 49.13 | 126.13 | 40.34 |
| 4 | DBM | 0.3074 | 63.31 | 42.51 | 80.29 | 50.47 | 75.63 | 38.19 | 65.11 | 48.66 |
| 5 | CEN | 0.6155 | 71.14 | 57.66 | 62.43 | 59.16 | 62.70 | 56.38 | 64.85 | 56.47 |
| 6 | Patch-CNN | 0.5626 | 48.02 | 44.81 | 70.06 | 64.25 | 46.30 | 53.87 | 48.69 | 42.17 |
Table 7.
Non-parametric correlation using Spearman’s correlation coefficient between WMH volume and Fazekas and Longstreth visual ratings. High r value with low p value are better. Underlined values are correlation values for manual WMH measurement. Whereas, values in bold and italic indicate the best and second-best schemes in this evaluation.
Table 7.
Non-parametric correlation using Spearman’s correlation coefficient between WMH volume and Fazekas and Longstreth visual ratings. High r value with low p value are better. Underlined values are correlation values for manual WMH measurement. Whereas, values in bold and italic indicate the best and second-best schemes in this evaluation.
| Visual Rating Scheme | Fazekas (Total) | Longstreth |
|---|
| | Method | Spearman’s Corr. Val. | Spearman’s Corr. Val. |
| r | p | r | p |
| 1 | Manual (Observer 1) | 0.7385 | | 0.7852 | |
| 2 | LST-LGA | 0.5743 | | 0.4834 | |
| 3 | SVM-SET3 | 0.4172 | 0.0012 | 0.3733 | 0.0042 |
| 4 | RF-SET1 | 0.2015 | 0.1328 | 0.1722 | 0.2003 |
| 5 | DBM | 0.2497 | 0.061 | 0.1729 | 0.1984 |
| 6 | CEN | 0.5933 | | 0.5008 | |
| 7 | Patch-CNN | 0.5852 | | 0.6976 | |

 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}