ECRU: An Encoder-Decoder Based Convolution Neural Network (CNN) for Road-Scene Understanding


Abstract
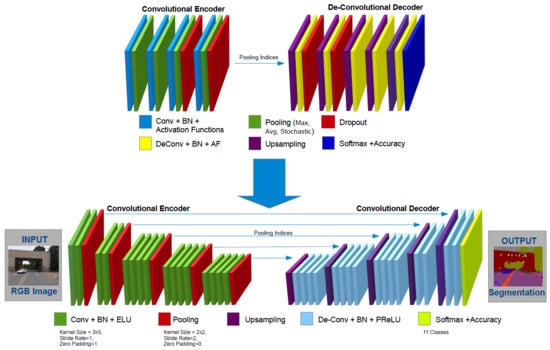
:
1. Introduction
2. Related Work
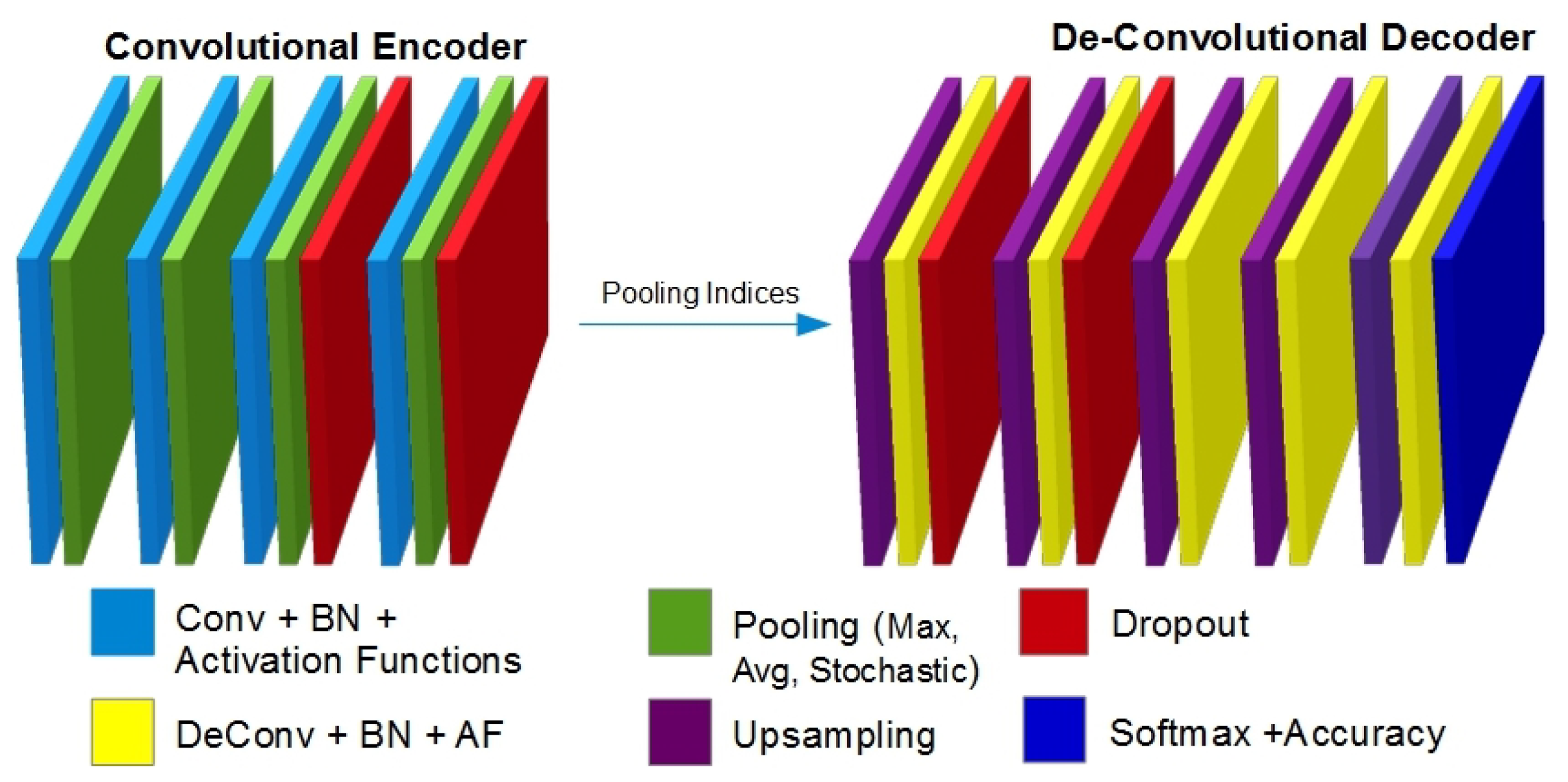
3. Algorithm Overview
| Algorithm 1 CNN encoder training: Training starts with . Additional parameters required in training are F spatial extent, K number of filters, P zero padding and S stride rate. The network outputs an image of . |
1.1. Generating feature-maps:
|
| Algorithm 2 CNN decoder training: Input pooling mask size of . The out volume is . |
2.1. De-Conv.and upsampling:
|
| Algorithm 3 Batch normalization [51]: In the algorithm, let the normalized values be and their linear transformations be . The transformation is stated as: . This algorithmic procedure states that is a constant incorporated for numerical stability. |
|
- A novel VGG-19 network-based encoder-decoder network for semantic segmentation.
- Simplified training of encoder and decoder networks simultaneously.
- An enhanced encoder-decoder model that improves the overall segmentation performance.
- The encoder architecture feeds the feature map(s) to the decoder to upsample. The proposed core segmentation engine has reduced the amount of the encoder (∼30 M) and decoder (∼0.5 M) parameters. In this way, the overall network size is reduced.
- Implemented the latest enhanced activation function (PReLU, ELU) to increase network efficiency.
- Flexible CNN network to adapt to any size of input.
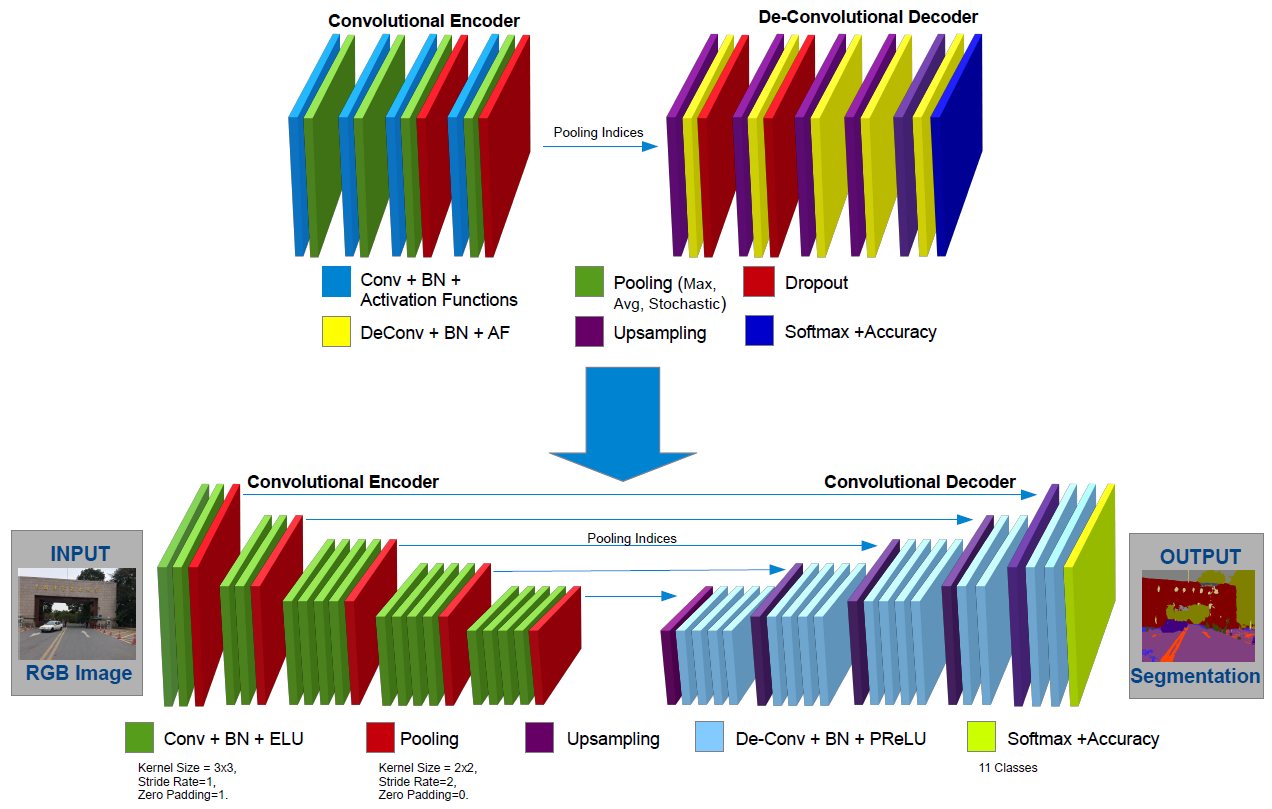
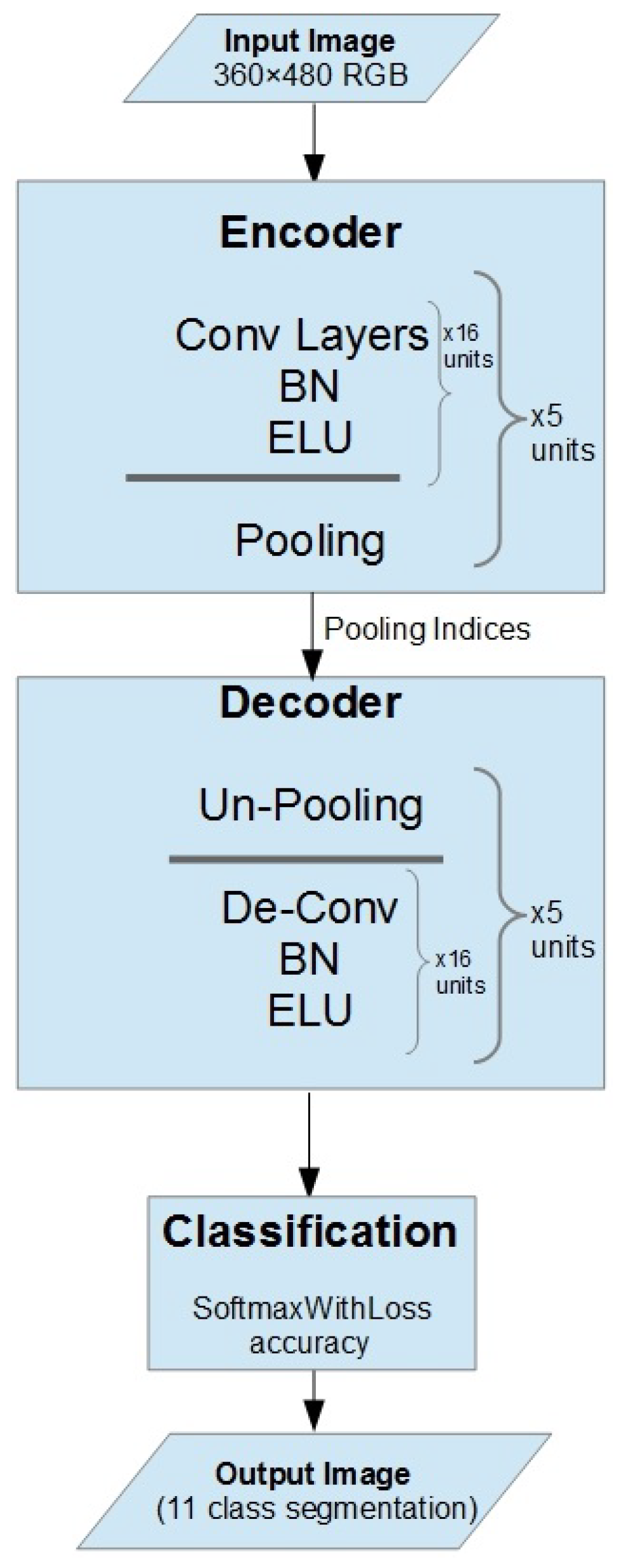
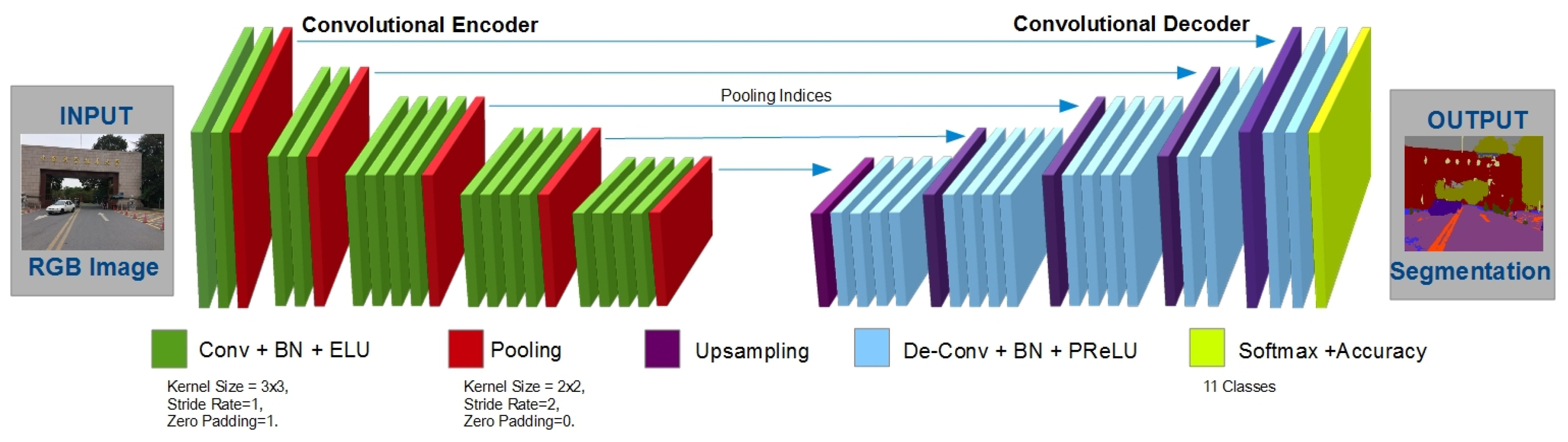
4. ECRU Architecture
5. Training and Experiments
5.1. Training
5.2. Experiments
5.2.1. Implementation Details: BMSS (Base Model)
5.2.2. Implementation Details: ECRU
5.2.3. Dataset
5.2.4. Hardware Implementation
6. Results and Analysis
7. Conclusions
Funding
Conflicts of Interest
References
- Kirillov, A.; He, K.; Girshick, R.; Rother, C.; Dollár, P. Panoptic Segmentation. arXiv, 2018; arXiv:1801.00868. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv, 2017; arXiv:1706.05587. [Google Scholar]
- Everingham, M.; Winn, J. The PASCAL Visual Object Classes Challenge 2011 (VOC2011) Development Kit. In Pattern Analysis, Statistical Modelling and Computational Learning; Tech. Report; European Commission: Brussels, Belgium, 2011. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Li, S.; Chan, A.B. 3d human pose estimation from monocular images with deep convolutional neural network. In Asian Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 332–347. [Google Scholar]
- Giusti, A.; Cireşan, D.C.; Masci, J.; Gambardella, L.M.; Schmidhuber, J. Fast image scanning with deep max-pooling convolutional neural networks. arXiv, 2013; arXiv:1302.1700. [Google Scholar]
- Arbelaez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour detection and hierarchical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 898–916. [Google Scholar] [CrossRef] [PubMed]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Shotton, J.; Sharp, T.; Kipman, A.; Fitzgibbon, A.; Finocchio, M.; Blake, A.; Cook, M.; Moore, R. Real-time human pose recognition in parts from single depth images. Commun. ACM 2013, 56, 116–124. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Couprie, C.; Farabet, C.; Najman, L.; LeCun, Y. Indoor semantic segmentation using depth information. arXiv, 2013; arXiv:1301.3572. [Google Scholar]
- Farabet, C.; Couprie, C.; Najman, L.; LeCun, Y. Learning hierarchical features for scene labelling. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1915–1929. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Höft, N.; Schulz, H.; Behnke, S. Fast semantic segmentation of RGB-D scenes with GPU-accelerated deep neural networks. In Joint German/Austrian Conference on Artificial Intelligence (Künstliche Intelligenz); Springer: Cham, Switzerland, 2014; pp. 80–85. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv, 2014; arXiv:1412.7062. [Google Scholar]
- Badrinarayanan, V.; Handa, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for robust semantic pixel-wise labelling. arXiv, 2015; arXiv:1505.07293. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Koltun, V. Efficient inference in fully connected crfs with gaussian edge potentials. Advances in Neural Information Processing Systems. In Proceedings of the Twenty-Fifth Conference on Neural Information Processing Systems (NIPS 2011), Granada, Spain, 14 December 2011. [Google Scholar]
- Jung, H.; Choi, M.K.; Soon, K.; Jung, W.Y. End-to-End Pedestrian Collision Warning System based on a Convolutional Neural Network with Semantic Segmentation. arXiv, 2016; arXiv:1612.06558. [Google Scholar]
- Xie, K.; Ge, S.; Ye, Q.; Luo, Z. Traffic Sign Recognition Based on Attribute-Refinement Cascaded Convolutional Neural Networks. In Pacific Rim Conference on Multimedia; Springe: Cham, Switzerland, 2016; pp. 201–210. [Google Scholar]
- Huval, B.; Wang, T.; Tandon, S.; Kiske, J.; Song, W.; Pazhayampallil, J.; Andriluka, M.; Rajpurkar, P.; Migimatsu, T.; Cheng-Yue, R.; et al. An empirical evaluation of deep learning on highway driving. arXiv, 2015; arXiv:1504.01716. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Tompson, J.J.; Jain, A.; LeCun, Y.; Bregler, C. Joint training of a convolutional network and a graphical model for human pose estimation. Advances in Neural Information Processing Systems. In Proceedings of the Advances in Neural Information Processing Systems (NIPS 2014), Montréal, QC, Canada, 8–13 December 2014; pp. 1799–1807. [Google Scholar]
- Zbontar, J.; LeCun, Y. Computing the stereo matching cost with a convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1592–1599. [Google Scholar]
- Gupta, S.; Girshick, R.; Arbeláez, P.; Malik, J. Learning rich features from RGB-D images for object detection and segmentation. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 345–360. [Google Scholar]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Wolf, R.; Platt, J.C. Postal address block location using a convolutional locator network. In Advances in Neural Information Processing Systems; Advances in Neural Information Processing Systems: Denver, CO, USA, 1994; p. 745. [Google Scholar]
- Ning, F.; Delhomme, D.; LeCun, Y.; Piano, F.; Bottou, L.; Barbano, P.E. Toward automatic phenotyping of developing embryos from videos. IEEE Trans. Image Process. 2005, 14, 1360–1371. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shotton, J.; Johnson, M.; Cipolla, R. Semantic texton forests for image categorization and segmentation. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Sturgess, P.; Alahari, K.; Ladicky, L.; Torr, P.H. Combining appearance and structure from motion features for road scene understanding. In Proceedings of the 23rd British Machine Vision Conference (BMVC 2012), London, UK, 3–7 September 2009. [Google Scholar]
- Brostow, G.J.; Fauqueur, J.; Cipolla, R. Semantic object classes in video: A high-definition ground truth database. Pattern Recognit. Lett. 2009, 30, 88–97. [Google Scholar] [CrossRef]
- Ladickỳ, L.; Sturgess, P.; Alahari, K.; Russell, C.; Torr, P.H. What, where and how many? Combining object detectors and crfs. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2010; pp. 424–437. [Google Scholar]
- Kang, F.; Han, S.; Salgado, R.; Li, J. System probabilistic stability analysis of soil slopes using Gaussian process regression with Latin hypercube sampling. Comput. Geotech. 2015, 63, 13–25. [Google Scholar] [CrossRef]
- Kang, F.; Xu, Q.; Li, J. Slope reliability analysis using surrogate models via new support vector machines with swarm intelligence. Appl. Math. Model. 2016, 40, 6105–6120. [Google Scholar] [CrossRef]
- Huang, F.J.; Boureau, Y.L.; LeCun, Y. Unsupervised learning of invariant feature hierarchies with applications to object recognition. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, IEEE, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Kendall, A.; Badrinarayanan, V.; Cipolla, R. Bayesian segnet: Model uncertainty in deep convolutional encoder-decoder architectures for scene understanding. arXiv, 2015; arXiv:1511.02680. [Google Scholar]
- Yasrab, R.; Gu, N.; Zhang, X. An Encoder-Decoder Based Convolution Neural Network (CNN) for Future Advanced Driver Assistance System (ADAS). Appl. Sci. 2017, 7, 312. [Google Scholar] [CrossRef]
- Yasrab, R.; Gu, N.; Xiaoci, Z.; Asad-Khan. DCSeg: Decoupled CNN for Classification and Semantic Segmentation. In Proceedings of the 2017 IEEE Conference on Knowledge and Smart Technologies (KST), Pattaya, Thailand, 1–4 February 2017; pp. 1–6. [Google Scholar]
- Yasrab, R.; Gu, N.; Xiaoci, Z. SCNet: A Simplified Encoder-Decoder CNN for Semantic Segmentation. In Proceedings of the 2016 5th International Conference on Computer Science and Network Technology (ICCSNT), Changchun, China, 10–11 December 2016; pp. 1–6. [Google Scholar]
- Zolock, J.; Senatore, C.; Yee, R.; Larson, R.; Curry, B. The Use of Stationary Object Radar Sensor Data from Advanced Driver Assistance Systems (ADAS) in Accident Reconstruction; Technical Report, SAE Technical Paper; SAE: Warrendale, PA, USA, 2016. [Google Scholar]
- Kedzia, J.C.; de Souza, P.; Gruyer, D. Advanced RADAR sensors modeling for driving assistance systems testing. In Proceedings of the 2016 10th European Conference on Antennas and Propagation (EuCAP), Davos, Switzerland, 10–15 April 2016; pp. 1–2. [Google Scholar]
- Deng, L.; Yang, M.; Li, H.; Li, T.; Hu, B.; Wang, C. Restricted Deformable Convolution based Road Scene Semantic Segmentation Using Surround View Cameras. arXiv, 2018; arXiv:1801.00708. [Google Scholar]
- Laugraud, B.; Piérard, S.; Van Droogenbroeck, M. LaBGen-P-Semantic: A First Step for Leveraging Semantic Segmentation in Background Generation. J. Imaging 2018, 4, 86. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, Z.; Wu, Q.J.; Cai, L.; Lu, D.; Li, X. Fast Semantic Segmentation for Scene Perception. IEEE Trans. Ind. Inform. 2018. [Google Scholar] [CrossRef]
- Kalith, A.S.; Mohanapriya, D.; Mahesh, K. Video Scene Segmentation: A Novel Method to Determine Objects. Int. J. Sci. Res. Sci. Technol. 2018, 4, 90–94. [Google Scholar]
- Darwich, A.; Hébert, P.A.; Bigand, A.; Mohanna, Y. Background Subtraction Based on a New Fuzzy Mixture of Gaussians for Moving Object Detection. J. Imaging 2018, 4, 92. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In AAAI; Google Inc.: Mountain View, CA, USA, 2017; Volume 4, p. 12. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv, 2015; arXiv:1502.03167. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Clevert, D.A.; Unterthiner, T.; Hochreiter, S. Fast and accurate deep network learning by exponential linear units (elus). arXiv, 2015; arXiv:1511.07289. [Google Scholar]
- Srivastava, N.; Hinton, G.E.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; ACM: New York, NY, USA, 2014; pp. 675–678. [Google Scholar]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Drucker, H.; Le Cun, Y. Improving generalization performance in character recognition. In Proceedings of the 1991 IEEE Workshop on Neural Networks for Signal Processing, Princeton, NJ, USA, 30 September–1 October 1991; pp. 198–207. [Google Scholar]
- Goodfellow, I.J.; Warde-Farley, D.; Mirza, M.; Courville, A.C.; Bengio, Y. Maxout networks. ICML 2013, 28, 1319–1327. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Stochastic pooling for regularization of deep convolutional neural networks. arXiv, 2013; arXiv:1301.3557. [Google Scholar]
- Jarrett, K.; Kavukcuoglu, K.; Lecun, Y. What is the best multi-stage architecture for object recognition? In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2146–2153. [Google Scholar]
- Brostow, G.J.; Shotton, J.; Fauqueur, J.; Cipolla, R. Segmentation and recognition using structure from motion point clouds. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2008; pp. 44–57. [Google Scholar]
- Zhang, C.; Wang, L.; Yang, R. Semantic segmentation of urban scenes using dense depth maps. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2010; pp. 708–721. [Google Scholar]
- Kontschieder, P.; Bulo, S.R.; Bischof, H.; Pelillo, M. Structured class-labels in random forests for semantic image labelling. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2190–2197. [Google Scholar]
- Rota Bulo, S.; Kontschieder, P. Neural decision forests for semantic image labelling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 23–28 June 2014; pp. 81–88. [Google Scholar]
- Yang, Y.; Li, Z.; Zhang, L.; Murphy, C.; Ver Hoeve, J.; Jiang, H. Local label descriptor for example based semantic image labelling. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2012; pp. 361–375. [Google Scholar]
- Tighe, J.; Lazebnik, S. Superparsing. Int. J. Comput. Vis. 2013, 101, 329–349. [Google Scholar] [CrossRef]
- Wang, Q.; Gao, J.; Yuan, Y. Embedding structured contour and location prior in siamesed fully convolutional networks for road detection. IEEE Trans. Intell. Transp. Syst. 2018, 19, 230–241. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Block | Input 360 × 480 + Norm |
|---|---|
| Encoder Block | 7 × 7Conv.64+ BN + 2 × 2 Pooling (max) + |
| ReLU/ELU/MaxOut/PReLU+ Dropout | |
| 7 × 7Conv.64 + BN + 2 × 2 Pooling (max) + | |
| ReLU/ELU/MaxOut/PReLU + Dropout | |
| 7 × 7Conv.64 + BN + 2 × 2 Pooling (max) + | |
| ReLU/ELU/MaxOut/PReLU + Dropout | |
| 7 × 7Conv.64 + BN + 2 × 2 Pooling (max) + | |
| ReLU/ELU/MaxOut/PReLU + Dropout | |
| Decoder Block | Upsample + 7 × 7 De-Conv.64 + BN |
| Upsample + 7 × 7 De-Conv.64 + BN | |
| Upsample + 7 × 7 De-Conv.64 + BN | |
| Upsample + 7 × 7 De-Conv.64 + BN | |
| Classification Block | Convolution Classifier 11 |
| Output Block | SoftmaxWithLoss |
| Accuracy |
| Encoder CNN | Decoder CNN | ||||
|---|---|---|---|---|---|
| Input 360 × 480 + Norm | Output, softmax with Loss + Accuracy | ||||
| Conv 1 | 3 × 3, 64 | B-N, ELU, Pool | DeConv 1 | 3 × 3, 64 | Upsample, B-N, ELU |
| 3 × 3, 64 | 3 × 3, 64 | ||||
| Conv 2 | 3 × 3, 128 | B-N, ELU, Pool | DeConv 2 | 3 × 3, 128 | Upsample, B-N, ELU |
| 3 × 3, 128 | 3 × 3, 128 | ||||
| Conv 3 | 3 × 3, 256 | B-N, ELU, Pool, Dropout | DeConv 3 | 3 × 3, 256 | Upsample, B-N, ELU, Dropout |
| 3 × 3, 256 | 3 × 3, 256 | ||||
| 3 × 3, 256 | 3 × 3, 256 | ||||
| 3 × 3, 256 | 3 × 3, 256 | ||||
| Conv 4 | 3 × 3, 512 | B-N, ELU, Pool, Dropout | DeConv 4 | 3 × 3, 512 | Upsample, B-N, ELU, Dropout |
| 3 × 3, 512 | 3 × 3, 512 | ||||
| 3 × 3, 512 | 3 × 3, 512 | ||||
| 3 × 3, 512 | 3 × 3, 512 | ||||
| Conv 5 | 3 × 3, 512 | B-N, ELU, Pool, Dropout | DeConv 5 | 3 × 3, 512 | Upsample, B-N, ELU, Dropout |
| 3 × 3, 512 | 3 × 3, 512 | ||||
| 3 × 3, 512 | 3 × 3, 512 | ||||
| 3 × 3, 512 | 3 × 3, 512 | ||||
| Encoder transfer pooling indices to decoder-CNN | |||||
| Network/Model | Building | Tree | Sky | Car | Sign/Symbol | Road | Pedestrian | Fence | Column-Pole | Side-Walk | Bicyclist | CAA. | GA. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Brostow et al. [61] | 46.2 | 61.9 | 89.7 | 68.6 | 42.9 | 89.5 | 53.6 | 46.6 | 0.7 | 60.5 | 22.5 | 53.0 | 69.1 |
| Sturgess et al. [33] | 61.9 | 67.3 | 91.1 | 71.1 | 58.5 | 92.9 | 49.5 | 37.6 | 25.8 | 77.8 | 24.7 | 59.8 | 76.4 |
| Zhang et al. [62] | 85.3 | 57.3 | 95.4 | 69.2 | 46.5 | 98.5 | 23.8 | 44.3 | 22.0 | 38.1 | 28.7 | 55.4 | 82.1 |
| Kontschieder et al. [63] | - | 51.4 | 72.5 | ||||||||||
| Bulo et al. [64] | - | 56.1 | 82.1 | ||||||||||
| Yang et al. [65] | 80.7 | 61.5 | 88.8 | 16.4 | - | 98.0 | 1.09 | 0.05 | 4.13 | 12.4 | 0.07 | 36.3 | 73.6 |
| Tighe et al. [66] | 87.0 | 67.1 | 96.9 | 62.7 | 30.1 | 95.9 | 14.7 | 17.9 | 1.7 | 70.0 | 19.4 | 51.2 | 83.3 |
| Sturgess et al. [33] | 70.7 | 70.8 | 94.7 | 74.4 | 55.9 | 94.1 | 45.7 | 37.2 | 13.0 | 79.3 | 23.1 | 59.9 | 79.8 |
| Sturgess et al. [33] | 84.5 | 72.6 | 97.5 | 72.7 | 34.1 | 95.3 | 34.2 | 45.7 | 8.1 | 77.6 | 28.5 | 59.2 | 83.8 |
| Ladicky et al. [35] | 81.5 | 76.6 | 96.2 | 78.7 | 40.2 | 93.9 | 43.0 | 47.6 | 14.3 | 81.5 | 33.9 | 62.5 | 83.8 |
| Kendall et al. [39] | 75.0 | 84.6 | 91.2 | 82.7 | 36.9 | 93.3 | 55.0 | 37.5 | 44.8 | 74.1 | 16.0 | 62.9 | 84.3 |
| Badrinarayanan et al. [17] | 80.6 | 72.0 | 93.0 | 78.5 | 21.0 | 94.0 | 62.5 | 31.4 | 36.6 | 74.0 | 42.5 | 62.3 | 82.8 |
| Seg-Net [17] | 88.0 | 87.3 | 92.3 | 80.0 | 29.5 | 97.6 | 57.2 | 49.4 | 27.8 | 84.8 | 30.7 | 65.9 | 88.6 |
| Bayesian-SegNet-Basic [39] | 75.1 | 68.8 | 91.4 | 77.7 | 52.0 | 92.5 | 71.5 | 44.9 | 52.9 | 79.1 | 69.6 | 70.5 | 81.6 |
| Bayesian-Full-Segnet [39] | 80.4 | 85.5 | 90.1 | 86.4 | 67.9 | 93.8 | 73.8 | 64.5 | 50.8 | 91.7 | 54.6 | 76.3 | 86.9 |
| ECRU | 95.1 | 84.0 | 84.5 | 94.9 | 93.3 | 87.4 | 97.3 | 88.3 | 93.3 | 94.1 | 90.2 | 88.4 | 91.1 |
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yasrab, R. ECRU: An Encoder-Decoder Based Convolution Neural Network (CNN) for Road-Scene Understanding. J. Imaging 2018, 4, 116. https://doi.org/10.3390/jimaging4100116
Yasrab R. ECRU: An Encoder-Decoder Based Convolution Neural Network (CNN) for Road-Scene Understanding. Journal of Imaging. 2018; 4(10):116. https://doi.org/10.3390/jimaging4100116
Chicago/Turabian StyleYasrab, Robail. 2018. "ECRU: An Encoder-Decoder Based Convolution Neural Network (CNN) for Road-Scene Understanding" Journal of Imaging 4, no. 10: 116. https://doi.org/10.3390/jimaging4100116
APA StyleYasrab, R. (2018). ECRU: An Encoder-Decoder Based Convolution Neural Network (CNN) for Road-Scene Understanding. Journal of Imaging, 4(10), 116. https://doi.org/10.3390/jimaging4100116