A New Binarization Algorithm for Historical Documents

 , ,
, ,
Abstract
:1. Introduction
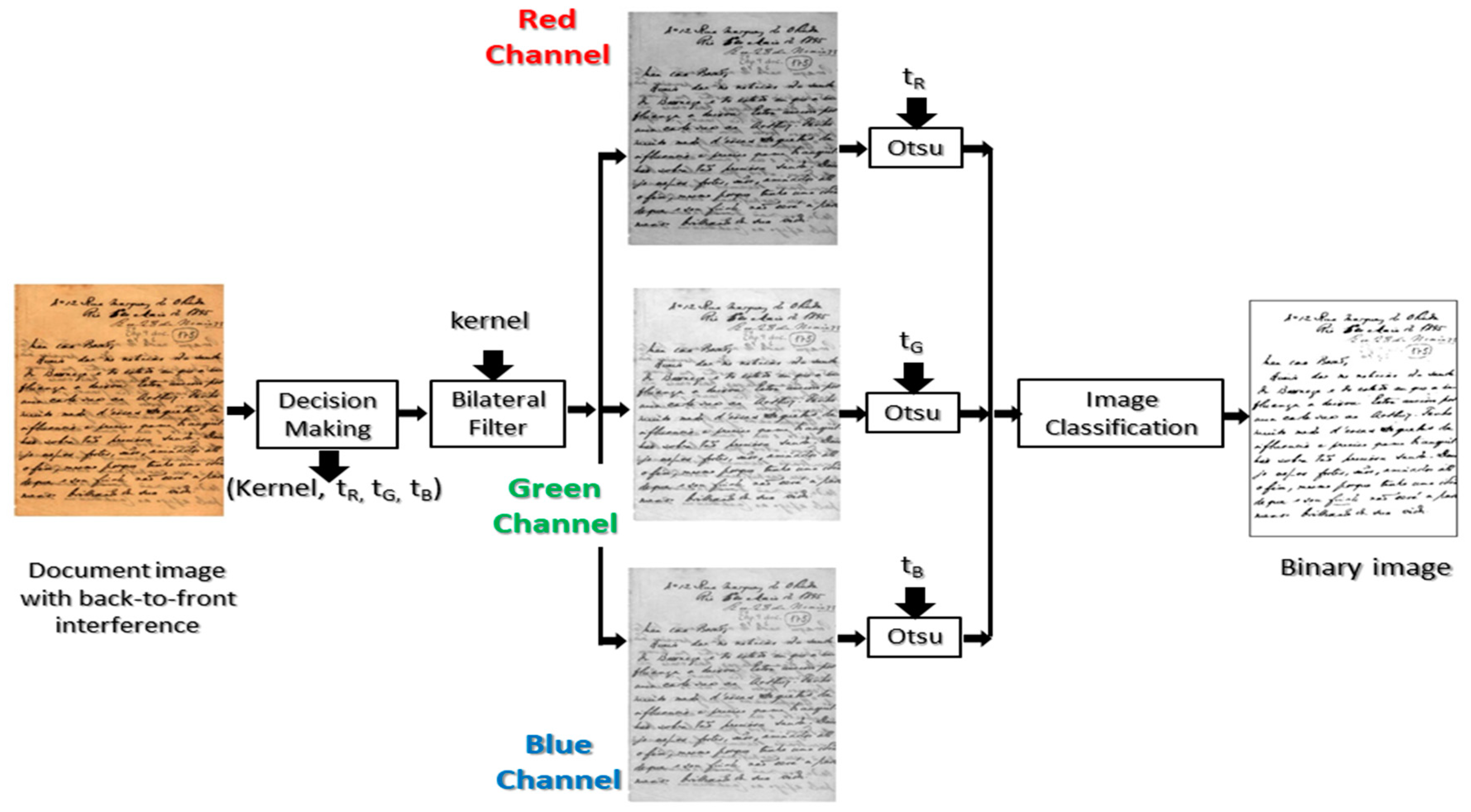
2. The New Algorithm
2.1. The Decision Making Block
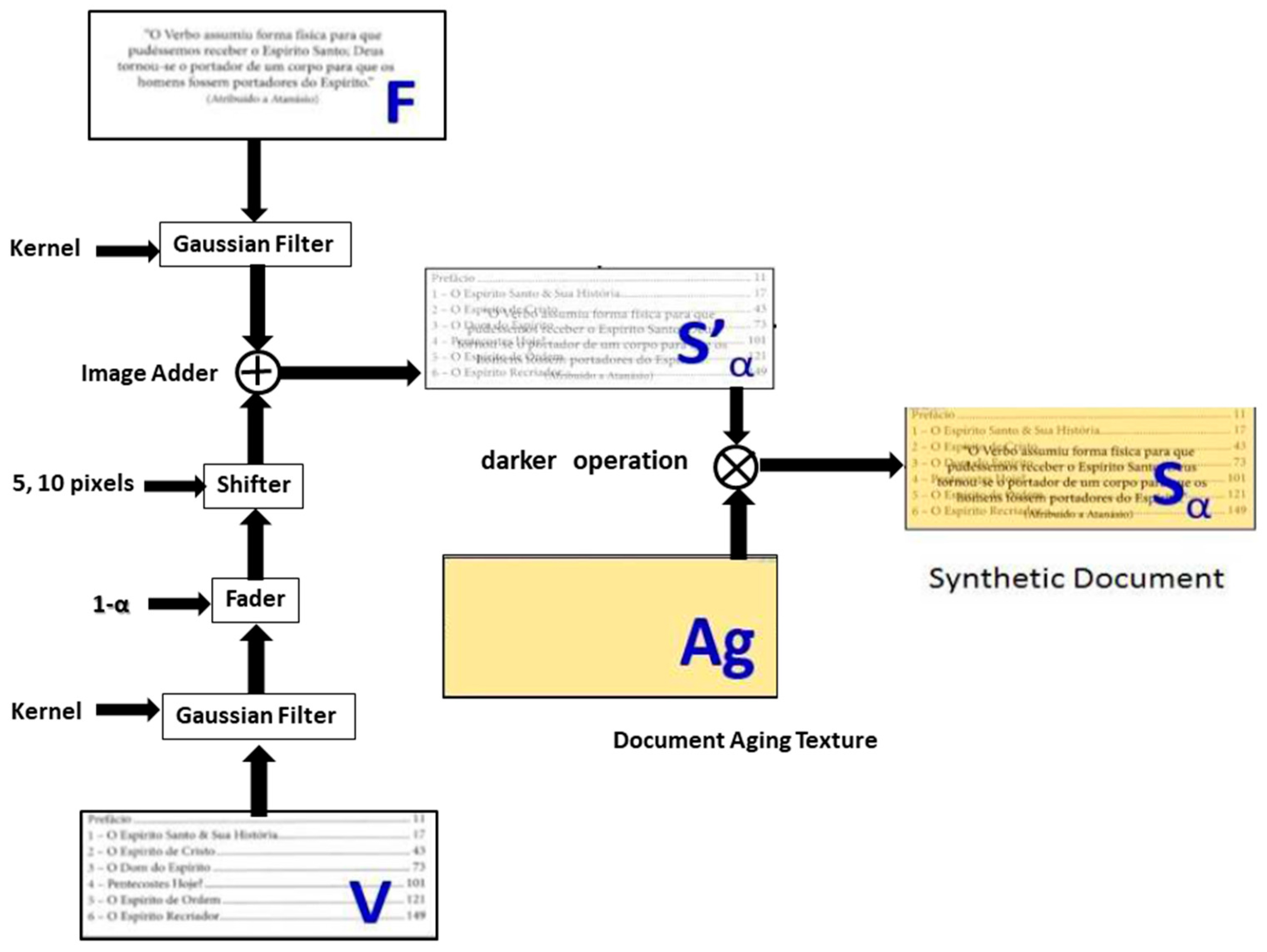
2.2. Generating Synthetic Images
2.3. The Bilateral Filter
2.4. Otsu Filtering
2.5. Image Classification
3. Experiments and Results
- Mello-Lins [5]
- DaSilva-Lins-Rocha [6]
- Otsu [16]
- Johannsen-Bille [17]
- Kapur-Sahoo-Wong [18]
- RenyEntropy (variation of [18])
- Li-Tam [19]
- Mean [20]
- MinError [21]
- Mixture-Modeling [22]
- Moments [23]
- IsoData [24]
- Percentile [25]
- Pun [26]
- Shanbhag [27]
- Triangle [28]
- Wu-Lu [29]
- Yean-Chang-Chang [30]
- Intermodes [31]
- Minimum (variation of [31])
- Ergina-Local [32]
- Sauvola [33]
- Niblack [34]
3.1. The Nabuco Dataset
3.2. The LiveMemory Dataset
3.3. The DIBCO Dataset
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Chaki, N.; Shaikh, S.H.; Saeed, K. Exploring Image Binarization Techniques; Springer: New Delhi, India, 2014. [Google Scholar]
- Lins, R.D. A Taxonomy for Noise in Images of Paper Documents-The Physical Noises. In Proceedings of the International Conference Image Analysis and Recognition, Halifax, NS, Canada, 6–8 July 2009; Volume 5627, pp. 844–854. [Google Scholar]
- Lins, R.D. An Environment for Processing Images of Historical Documents. Microprocess. Microprogr. 1995, 40, 939–942. [Google Scholar] [CrossRef]
- Sharma, G. Show-through cancellation in scans of duplex printed documents. IEEE Trans. Image Process. 2001, 10, 736–754. [Google Scholar] [CrossRef] [PubMed]
- Mello, C.A.B.; Lins, R.D. Generation of Images of Historical Documents by Composition. In Proceedings of the 2002 ACM Symposium on Document Engineering, New York, NY, USA, 8–9 November 2002; pp. 127–133. [Google Scholar]
- Silva, M.M.; Lins, R.D.; Rocha, V.C. Binarizing and Filtering Historical Documents with Back-to-Front Interference. In Proceedings of the 2006 ACM Symposium on Applied Computing, New York, NY, USA, 23–27 April 2006; pp. 853–858. [Google Scholar]
- Lins, R.D. Nabuco—Two Decades of Processing Historical Documents in Latin America. J. Univers. Comput. Sci. 2011, 17, 151–161. [Google Scholar]
- Roe, E.; Mello, C.A.B. Binarization of Color Historical Document Images Using Local Image Equalization and XDoG. In Proceedings of the 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 205–209. [Google Scholar]
- Lins, R.D.; Almeida, M.A.M.; Bernardino, R.B.; Jesus, D.; Oliveira, J.M. Assessing Binarization Techniques for Document Images. In Proceedings of the ACM Symposium on Document Engineering, Valletta, Malta, 4–7 September 2017. [Google Scholar]
- Pratikakis, I.; Zagoris, K.; Barlas, G.; Gatos, B. ICDAR 2017 Competition on Document Image Binarization (DIBCO 2017). In Proceedings of the 14th IAPR International Conference on Document Analysis and Recognition, Kyoto, Japan, 13–15 November 2017; pp. 2140–2379. [Google Scholar]
- Efros, A.A.; Freeman, W.T. Image quilting for texture synthesis and transfer. In Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques (SIGGRAPH ’01), New York, NY, USA, 12–17 August 2001; pp. 341–346. [Google Scholar]
- Aurich, V.; Weule, J.B. Non-Linear Gaussian Filters Performing Edge Preserving Diffusion. In Proceedings of the DAGM Symposium, London, UK, 13–15 September 1995; pp. 538–545. [Google Scholar]
- Tomasi, C.; Manduchi, R. Bilateral Filtering for Gray and Color Images. In Proceedings of the 6th International Conference on Computer Vision, Washington, DC, USA, 4–7 January 1998; pp. 836–846. [Google Scholar]
- Paris, P.; Kornprobst, P.; Tumblim, J.; Durand, F. Bilateral Filtering: Theory and Applications. Found. Trends Comput. Graph. Vis. 2008, 4, 1–73. [Google Scholar] [CrossRef]
- Shyam Anand, C.; Sahambi, J.S. Pixel Dependent Automatic Parameter Selection for Image Denoising with Bilateral Filter. Int. J. Comput. Appl. 2012, 45, 41–46. [Google Scholar]
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Johannsen, G.; Bille, J.A. A Threshold Selection Method Using Information Measure. In Proceedings of the 6th International Conference on Pattern Recognition (ICPR’82), Munich, Germany, 19–22 October 1982; pp. 140–143. [Google Scholar]
- Kapur, N.; Sahoo, P.K.; Wong, A.K.C. A New Method for Gray-Level Picture Thresholding Using the Entropy of the Histogram. Comput. Vis. Graph. Image Process. 1985, 29, 273–285. [Google Scholar] [CrossRef]
- Li, C.H.; Tam, P.K.S. An iterative algorithm for minimum cross entropy thresholding. Pattern Recognit. Lett. 1998, 19, 771–776. [Google Scholar] [CrossRef]
- Glasbey, C.A. An analysis of histogram-based thresholding algorithms. Graph. Models Image Process. 1993, 55, 532–537. [Google Scholar] [CrossRef]
- Kittler, J.; Illingworth, J. Minimum error thresholding. Pattern Recognit. 1986, 19, 41–47. [Google Scholar] [CrossRef]
- Mixture Modeling. ImageJ. Available online: http://imagej.nih.gov/ij/plugins/mixture-modeling.html (accessed on 20 January 2018).
- Tsai, W.H. Moment-preserving thresholding: A new approach. Comput. Vis. Graph. Image Process. 1985, 29, 377–393. [Google Scholar] [CrossRef]
- Doyle, W. Operation useful for similarity-invariant pattern recognition. J. Assoc. Comput. Mach. 1962, 9, 259–267. [Google Scholar] [CrossRef]
- Pun, T. Entropic Thresholding, A New Approach. Comput. Vis. Graph. Image Process. 1981, 16, 210–239. [Google Scholar] [CrossRef]
- Shanbhag, A.G.G. Utilization of Information Measure as a Means of Image Thresholding. Comput. Vis. Graph. Image Process. 1994, 56, 414–419. [Google Scholar] [CrossRef]
- Zack, G.W.; Rogers, W.E.; Latt, S.A. Automatic measurement of sister chromatid exchange frequency. J. Histochem. Cytochem. 1977, 25, 741–753. [Google Scholar] [CrossRef] [PubMed]
- Wu, U.L.; Songde, A.; Haqing, L.U.A. An Effective Entropic Thresholding for Ultrasonic Imaging. In Proceedings of the International Conference Pattern Recognition, Brisbane, Australia, 16–20 August 1998; pp. 1522–1524. [Google Scholar]
- Yen, J.C.; Chang, F.J.; Chang, S. A New Criterion for Automatic Multilevel Thresholding. IEEE Trans. Image Process. 1995, 4, 370–378. [Google Scholar] [PubMed]
- Ridler, T.W.; Calvard, S. Picture Thresholding Using an Iterative Selection Method. IEEE Trans. Syst. Man Cybern. 1978, 8, 630–632. [Google Scholar]
- Prewitt, M.S.; Mendelsohn, M.L. The Analysis of Cell Images. Ann. N. Y. Acad. Sci. 1996, 128, 836–846. [Google Scholar] [CrossRef]
- Kavallieratou, E.; Stamatatos, S. Adaptive binarization of historical document images. In Proceedings of the 18th International Conference on Pattern ICPR 2006, Hong Kong, China, 20–24 August 2006; Volume 3. [Google Scholar]
- Sauvola, J.; Pietikainen, M. Adaptive document image binarization. Pattern Recognit. 2000, 33, 225–236. [Google Scholar] [CrossRef]
- Niblack, W. An introduction to Digital Image Processing; Prentice-Hall: Upper Saddle River, NJ, USA, 1986. [Google Scholar]
- Ntirogiannis, K.; Gatos, B.; Pratikakis, I. Performance Evaluation Methodology for Historical Document Image Binarization. IEEE Trans. Image Process. 2013, 22, 595–609. [Google Scholar] [CrossRef] [PubMed]
- Lins, R.D.; Silva, G.F.P.; Torreão, G.; Alves, N.F. Efficiently Generating Digital Libraries of Proceedings with the LiveMemory Platform. In IEEE International Telecommunications Symposium; IEEE Press: Rio de Janeiro, Brazil, 2010; pp. 119–125. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AlgName | P(f/f) | P(b/b) | Time (s) |
|---|---|---|---|
| IsoData | 98.08 ± 3.39 | 99.38 ± 0.60 | 0.0171 |
| Otsu | 98.08 ± 3.39 | 99.36 ± 0.63 | 0.0159 |
| Bilateral | 99.57 ± 1.23 | 99.29 ± 0.93 | 1.0790 |
| Huang | 99.40 ± 2.14 | 98.69 ± 0.88 | 0.0200 |
| Moments | 99.39 ± 1.34 | 98.40 ± 1.70 | 0.0160 |
| Ergina-Local | 99.99 ± 0.03 | 98.13 ± 0.64 | 0.3412 |
| RenyEntropy | 100.00 | 97.56 ± 1.17 | 0.0188 |
| Kapoo-Sahoo-Wong | 100.00 | 97.51 ± 1.07 | 0.0172 |
| Yean-Chang-Chang | 100.00 | 97.38 ± 1.26 | 0.0161 |
| Triangle | 100.00 | 95.94 ± 1.46 | 0.0160 |
| Mello-Lins | 98.61 ± 5.14 | 89.63 ± 24.43 | 0.0160 |
| Mean | 100.00 | 81.77 ± 5.99 | 0.0168 |
| Johannsen-Bille | 98.87 ± 2.97 | 59.77 ± 48.80 | 0.0164 |
| Pun | 100.00 | 55.44 ± 2.57 | 0.0185 |
| Percentile | 100.00 | 53.21 ± 1.33 | 0.0185 |
| Sauvola | 85.51 ± 12.93 | 99.95 ± 0.11 | 1.2977 |
| Niblack | 99.75 ± 0.34 | 77.06 ± 5.63 | 0.2135 |
| AlgName | P(f/f) | P(b/b) | Time (s) |
|---|---|---|---|
| Bilateral | 100.00 | 98.90 ± 1.07 | 3.3325 |
| IsoData-ORIG | 99.56 ± 0.69 | 98.61 ± 1.99 | 0.0734 |
| Otsu | 99.60 ± 0.68 | 98.57 ± 2.08 | 0.0735 |
| Moments | 99.99 ± 0.03 | 97.91 ± 1.87 | 0.0716 |
| Ergina-Local | 98.98 ± 2.82 | 97.62 ± 1.04 | 0.9917 |
| Huang | 99.93 ± 0.27 | 96.42 ± 4.20 | 0.0865 |
| Triangle | 100.00 | 94.24 ± 2.15 | 0.0728 |
| Mean | 100.00 | 83.58 ± 5.59 | 0.0747 |
| Niblack | 99.76 ± 0.76 | 78.31 ± 2.97 | 0.6710 |
| Pun | 100.00 | 55.28 ± 3.60 | 0.0800 |
| Percentile | 100.00 | 53.91 ± 1.96 | 0.0795 |
| Kapur-Sahoo-Wong | 98.62 ± 4.92 | 97.15 ± 1.44 | 0.0729 |
| AlgName | P(f/f) | P(b/b) | Time (s) |
|---|---|---|---|
| Ergina-local | 91.37 ± 6.25 | 99.88 ± 1.89 | 0.1844 |
| RenyEntropy | 90.13 ± 14.19 | 96.77 ± 3.50 | 0.0125 |
| Yean-Chang-Chang | 90.61 ± 14.44 | 96.16 ± 4.35 | 0.0112 |
| Moments | 90.75 ± 9.91 | 95.80 ± 5.19 | 0.0112 |
| Bilateral | 92.99 ± 9.06 | 90.78 ± 16.01 | 0.6099 |
| Huang | 95.62 ± 6.37 | 84.22 ± 18.36 | 0.0147 |
| Triangle | 96.40 ± 5.72 | 80.80 ± 23.32 | 0.0113 |
| Mean | 99.35 ± 1.14 | 78.99 ± 9.35 | 0.0115 |
| MinError | 92.79 ± 23.46 | 74.29 ± 19.36 | 0.0115 |
| Pun | 99.68 ± 0.82 | 56.20 ± 6.18 | 0.0122 |
| Percentile | 99.71 ± 0.72 | 55.06 ± 3.58 | 0.0121 |
| Sauvola | 59.75 ± 30.06 | 99.58 ± 079 | 0.6933 |
| Niblack | 95.91 ± 2.31 | 78.61 ± 5.69 | 0.1241 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almeida, M.; Lins, R.D.; Bernardino, R.; Jesus, D.; Lima, B. A New Binarization Algorithm for Historical Documents. J. Imaging 2018, 4, 27. https://doi.org/10.3390/jimaging4020027
Almeida M, Lins RD, Bernardino R, Jesus D, Lima B. A New Binarization Algorithm for Historical Documents. Journal of Imaging. 2018; 4(2):27. https://doi.org/10.3390/jimaging4020027
Chicago/Turabian StyleAlmeida, Marcos, Rafael Dueire Lins, Rodrigo Bernardino, Darlisson Jesus, and Bruno Lima. 2018. "A New Binarization Algorithm for Historical Documents" Journal of Imaging 4, no. 2: 27. https://doi.org/10.3390/jimaging4020027
APA StyleAlmeida, M., Lins, R. D., Bernardino, R., Jesus, D., & Lima, B. (2018). A New Binarization Algorithm for Historical Documents. Journal of Imaging, 4(2), 27. https://doi.org/10.3390/jimaging4020027