
No Matter What Images You Share, You Can Probably Be Fingerprinted Anyway



Abstract
:1. Introduction
1.1. Problem Statement
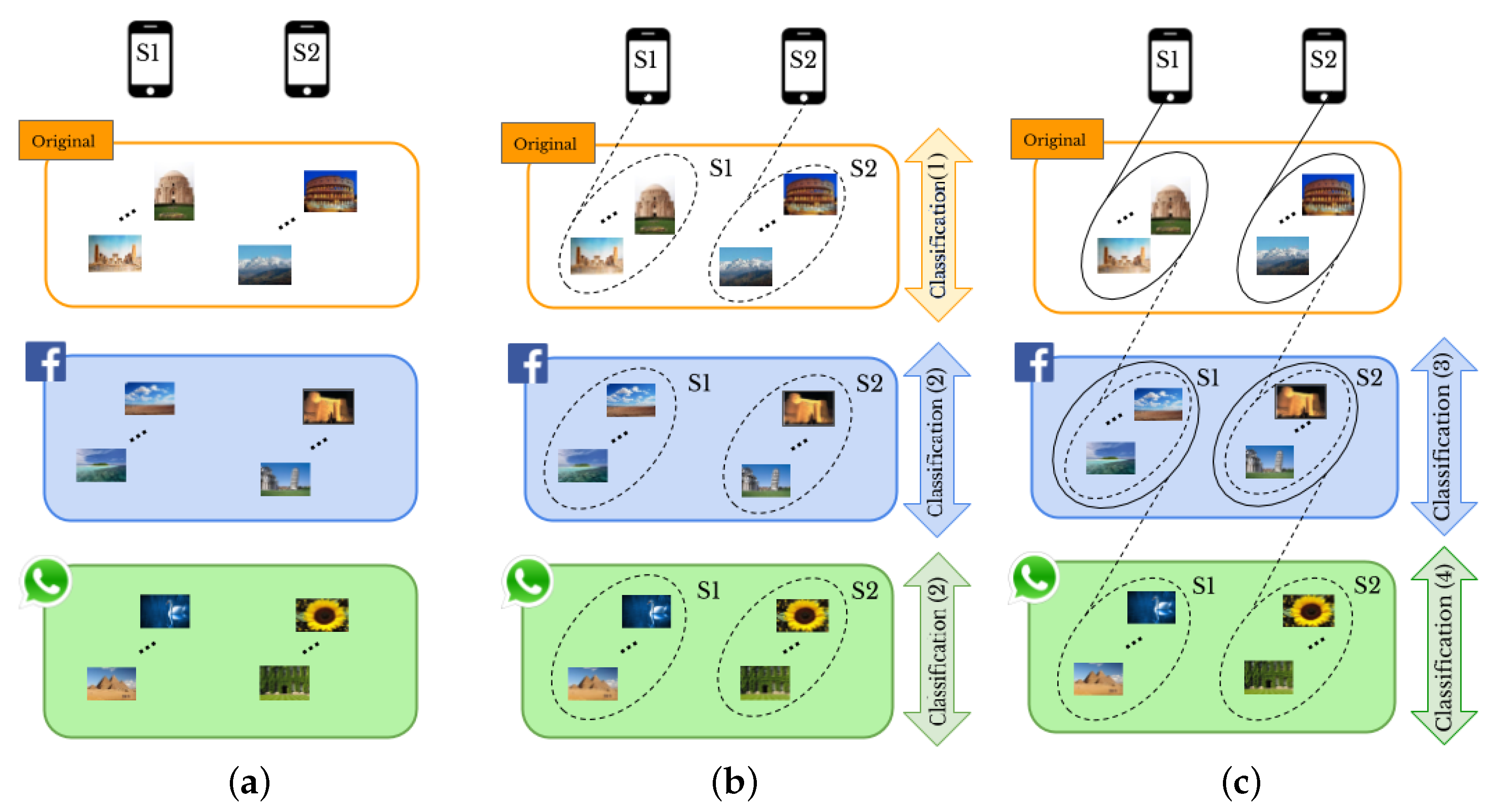
- 1.1
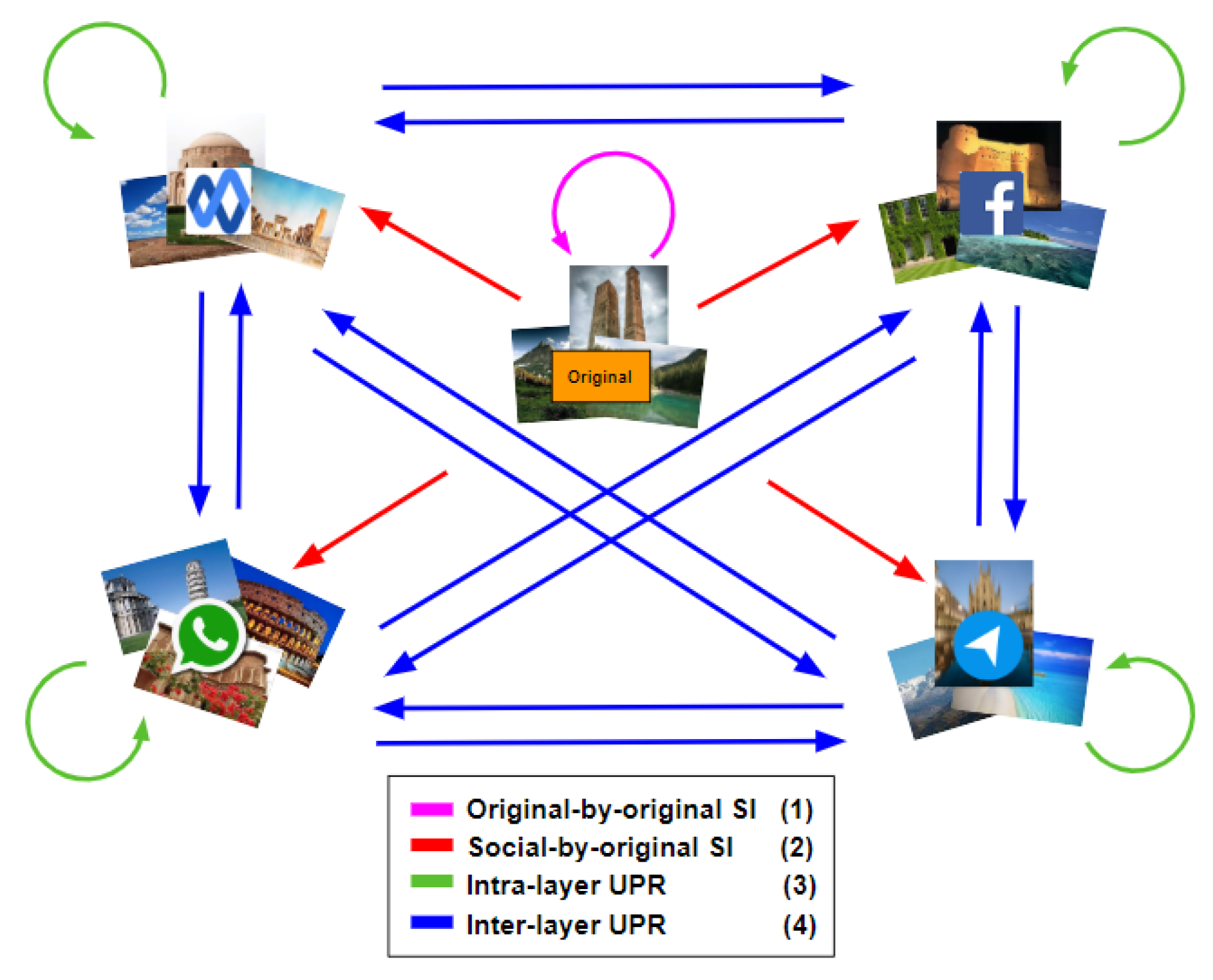
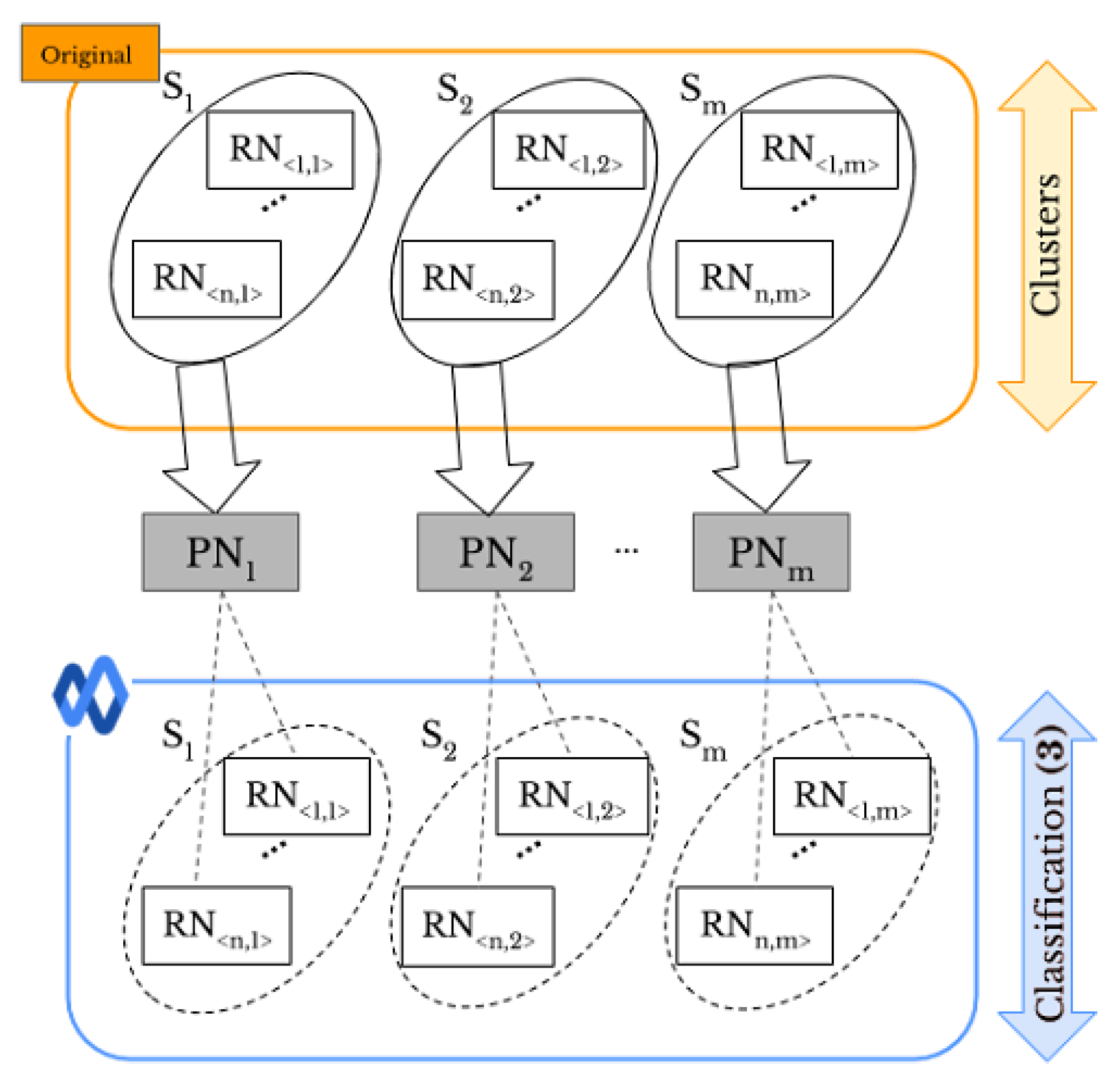
- Original-by-original SI is the task used to detect the source cameras from which a set of “original images” directly coming from smartphones have been taken, see the arrow labeled “Classification (1)” in Figure 1b.
- 1.2
- Social-by-original SI represents the task used to identify the source cameras of a given set of “shared images”, see the arrow labeled “Classification (3)” in Figure 1c. In this case, the “original images” are input data and allow one to define the smartphone camera fingerprints.
- 2.1
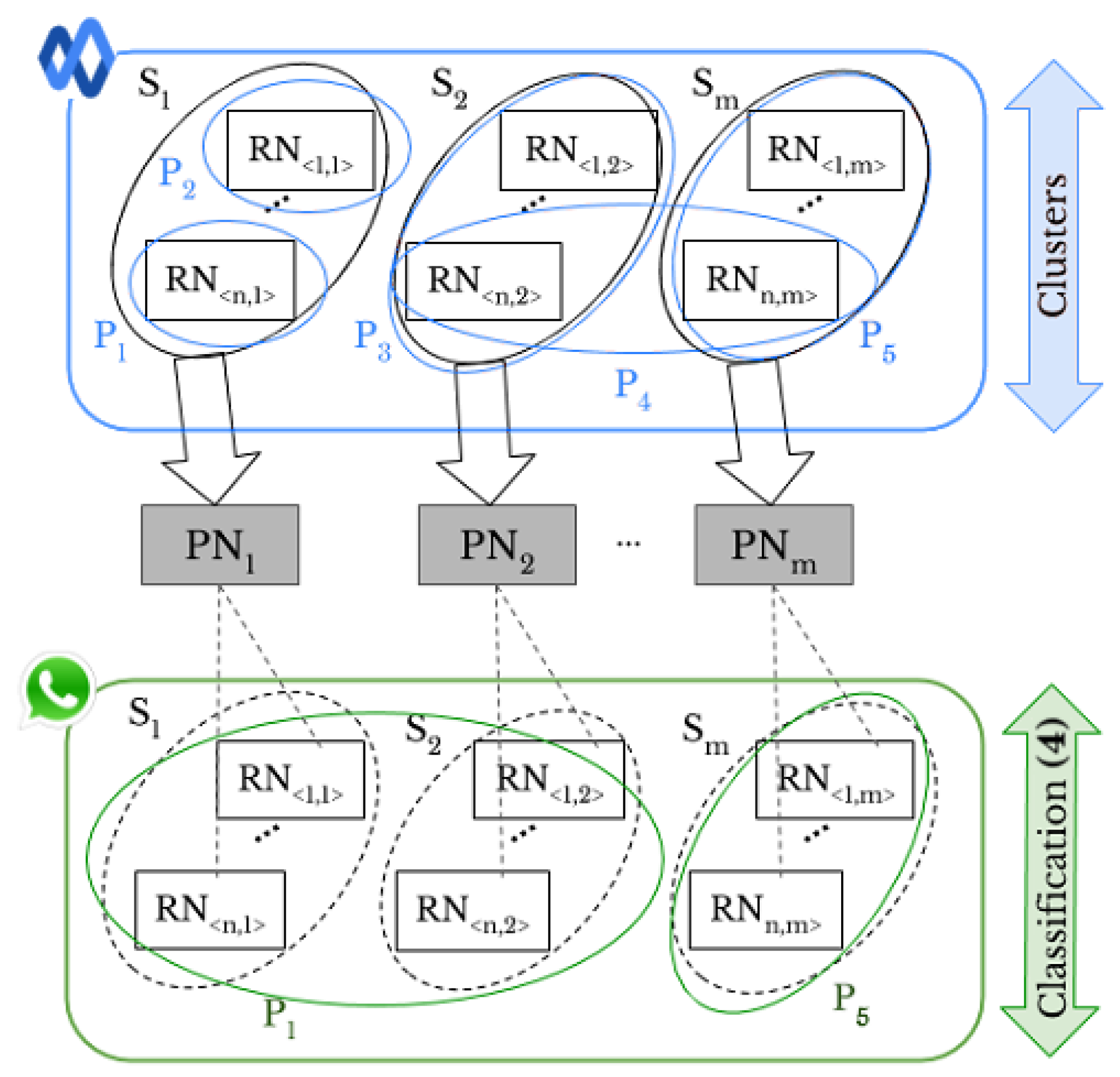
- Intra-layer UPL is the task used to link a given set of user profiles within the same SN using “shared images”, see the arrows labeled “Classification (2)” on Facebook and WhatsApp in Figure 1b. Through this task, the profiles that share images from the same source are linked within the same SNs.
- 2.2
- Inter-layer UPL represents the task used to link a set of user profiles across different SNs by using “shared images”, see the arrow labeled “Classification (4)” in Figure 1c. Through this task, the profiles from different SNs that share images from the same source are linked.
1.2. Contribution
2. Related Works
3. Methodology
3.1. Smartphone Fingerprinting
3.2. Pre-Processing
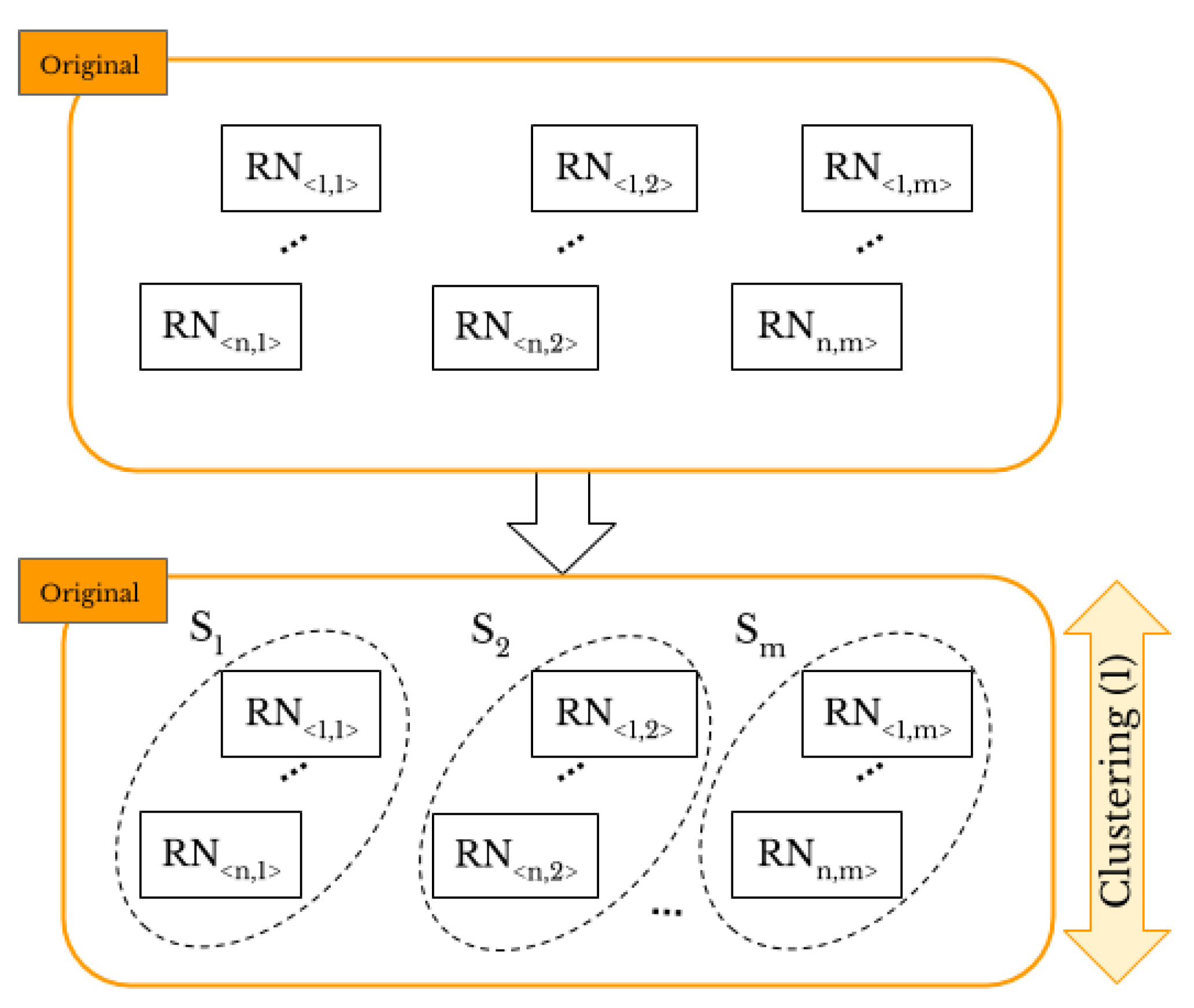
3.3. Original-By-Original Smartphone Identification and Intra-Layer User Profile Linking
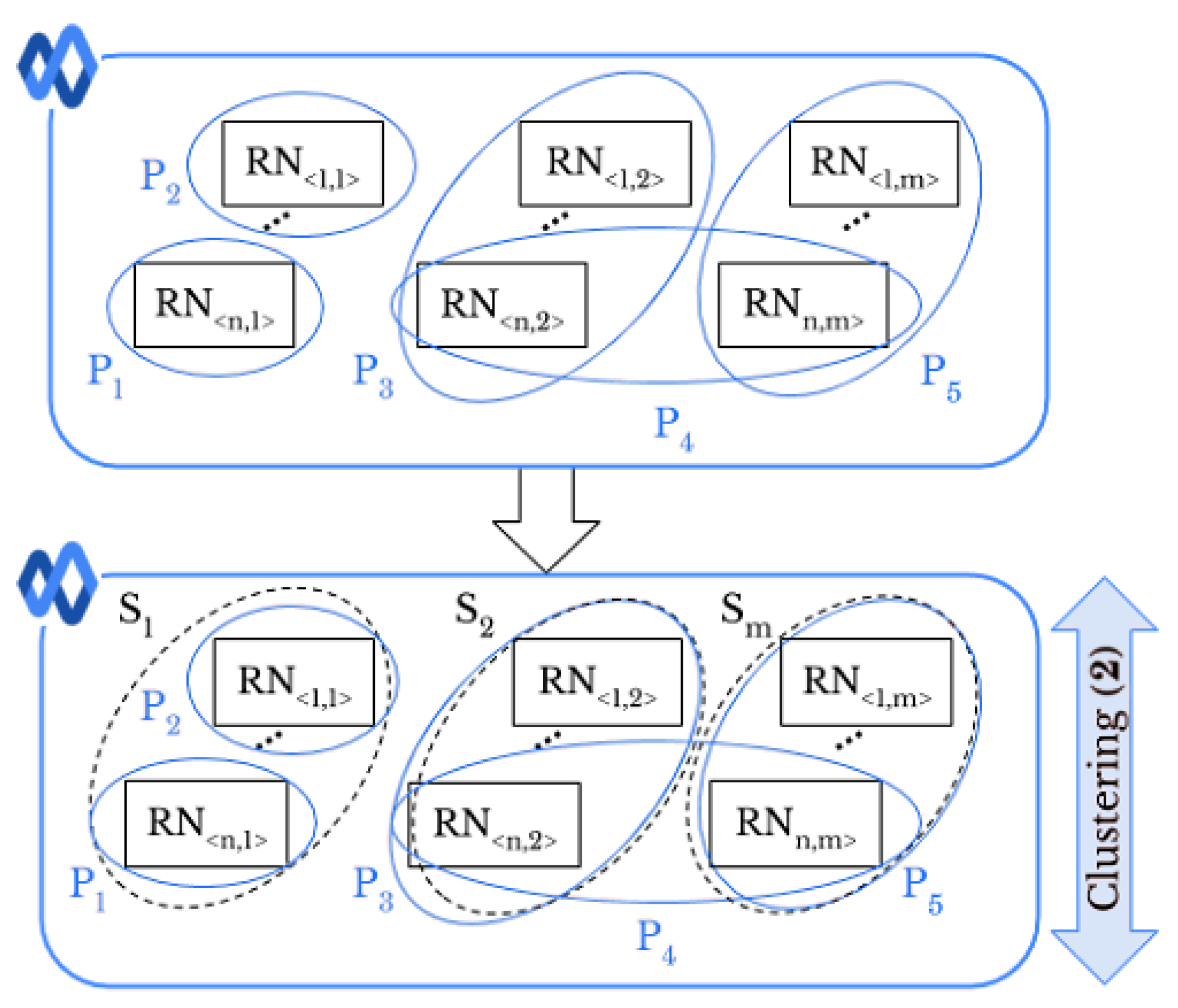
3.4. Social-By-Original Smartphone Identification and Inter-Layer User Profile Linking
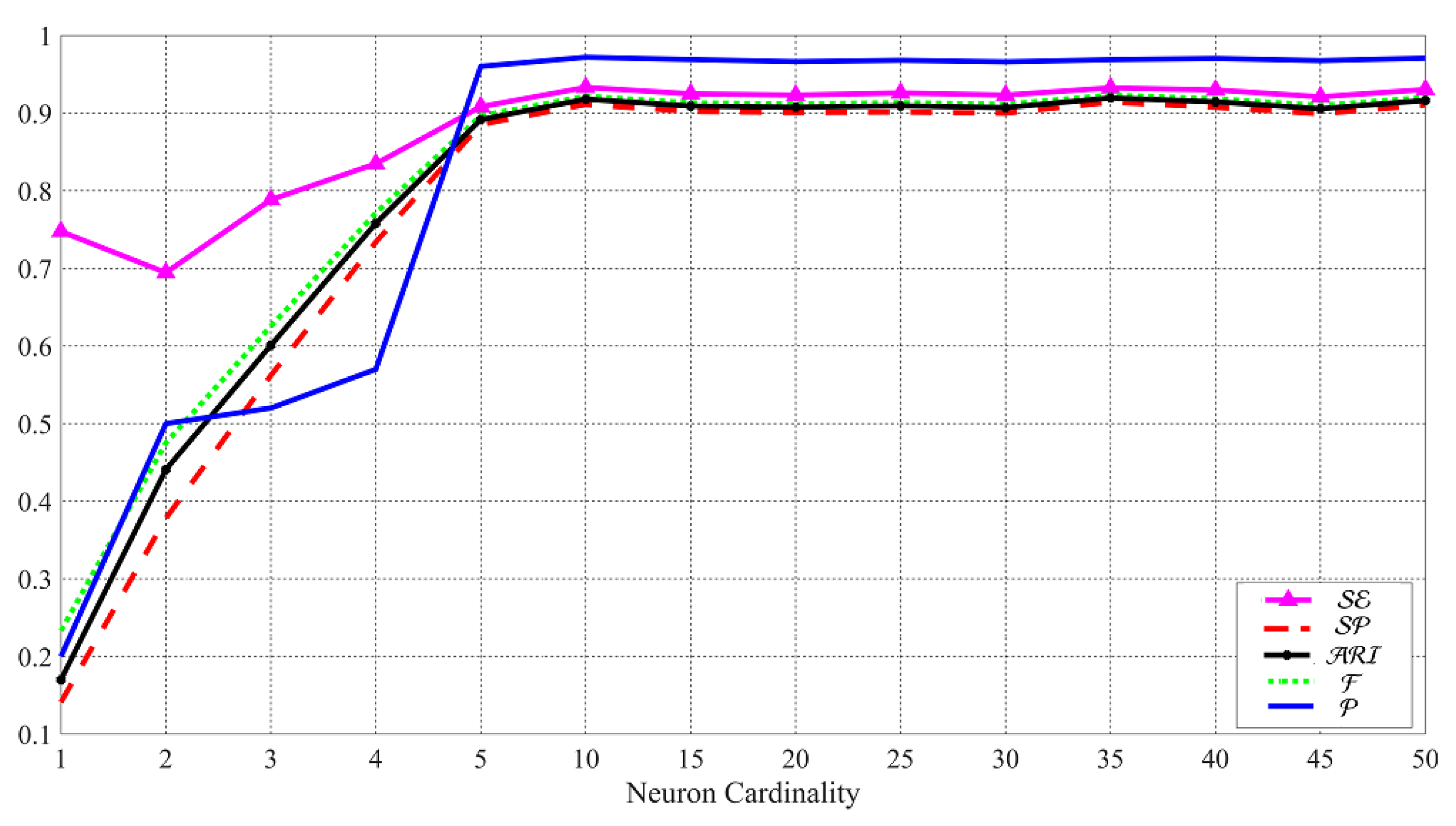
4. Experimental Results
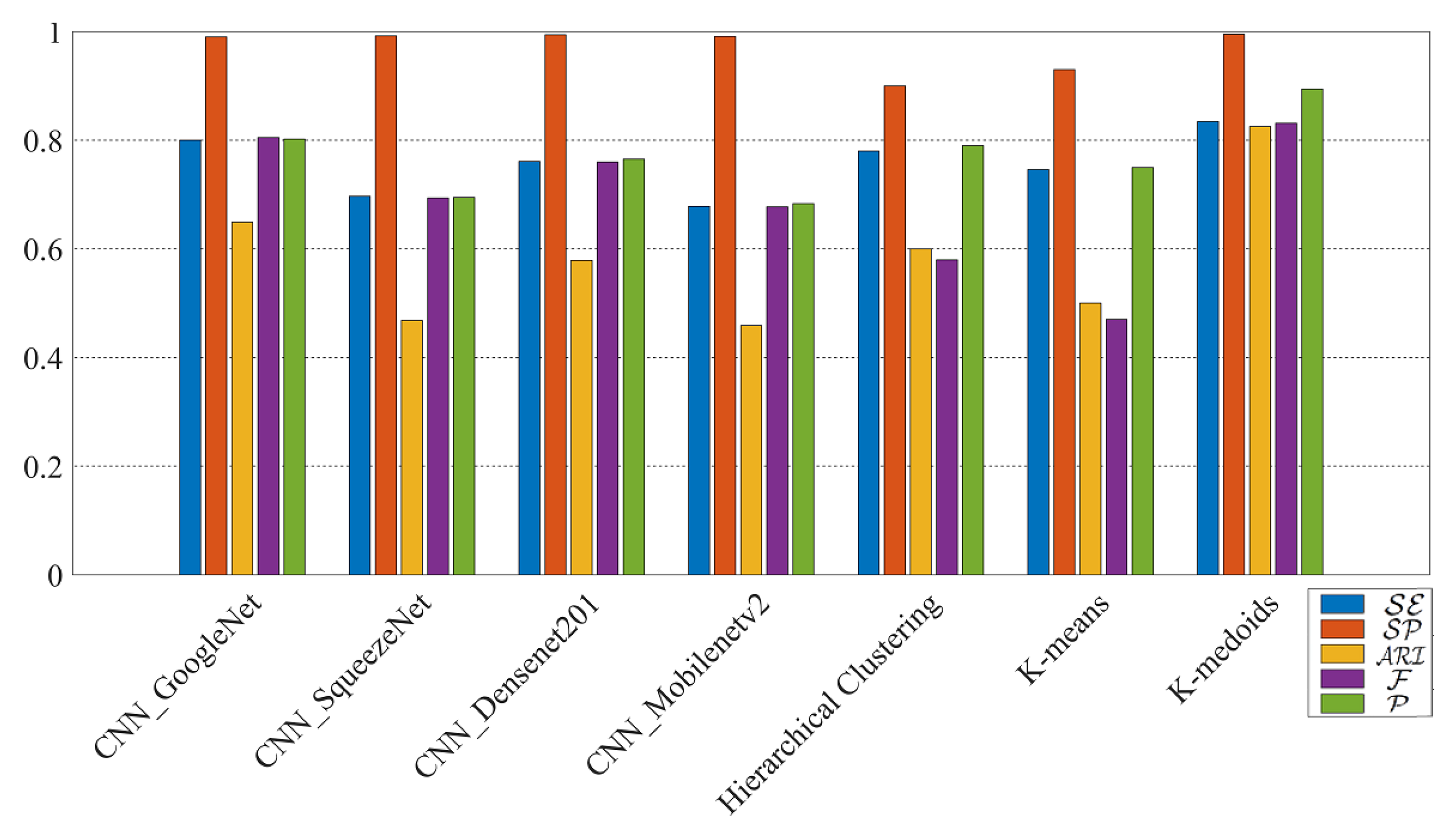
4.1. Original-By-Original Smartphone Identification Results
4.2. Social-By-Original Smartphone Identification Results
4.3. Intra-Layer User Profile Linking Results
4.4. Inter-Layer User Profile Linking Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mander, J. GWI Social Summary; GlobalWebIndex: London, UK, 2017. [Google Scholar]
- Norouzizadeh Dezfouli, F.; Dehghantanha, A.; Eterovic-Soric, B.; Choo, K.K.R. Investigating Social Networking applications on smartphones detecting Facebook, Twitter, LinkedIn and Google+ artefacts on Android and iOS platforms. Aust. J. Forensic Sci. 2016, 48, 469–488. [Google Scholar] [CrossRef]
- Liu, Q.; Li, X.; Chen, L.; Cho, H.; Cooper, P.; Chen, Z.; Qiao, M.; Sung, A. Identification of smartphone-image source and manipulation. Adv. Res. Appl. Artif. Intell. 2012, 7345, 262–271. [Google Scholar]
- Huang, N.; He, J.; Zhu, N.; Xuan, X.; Liu, G.; Chang, C. Identification of the source camera of images based on convolutional neural network. Digit. Investig. 2018, 26, 72–80. [Google Scholar] [CrossRef]
- Rouhi, R.; Bertini, F.; Montesi, D.; Lin, X.; Quan, Y.; Li, C.T. Hybrid clustering of shared images on social networks for digital forensics. IEEE Access 2019, 7, 87288–87302. [Google Scholar] [CrossRef]
- Van Lanh, T.; Chong, K.S.; Emmanuel, S.; Kankanhalli, M.S. A survey on digital camera image forensic methods. In Proceedings of the 2007 IEEE International Conference on Multimedia and Expo, Beijing, China, 2–5 July 2007; pp. 16–19. [Google Scholar]
- Lin, X.; Li, C.T. Preprocessing reference sensor pattern noise via spectrum equalization. IEEE Trans. Inf. Forensics Secur. 2016, 11, 126–140. [Google Scholar] [CrossRef] [Green Version]
- Taspinar, S.; Mohanty, M.; Memon, N. PRNU-Based Camera Attribution From Multiple Seam-Carved Images. IEEE Trans. Inf. Forensics Secur. 2017, 12, 3065–3080. [Google Scholar] [CrossRef]
- Lukáš, J.; Fridrich, J.; Goljan, M. Digital camera identification from sensor pattern noise. IEEE Trans. Inf. Forensics Secur. 2006, 1, 205–214. [Google Scholar] [CrossRef]
- Chen, Y.; Thing, V.L. A study on the photo response non-uniformity noise pattern based image forensics in real-world applications. In Proceedings of the International Conference on Image Processing, Computer Vision, and Pattern Recognition (IPCV). The Steering Committee of The World Congress in Computer Science, Computer Engineering and Applied Computing (WorldComp), Las Vegas, NV, USA, 16–19 July 2012; p. 1. [Google Scholar]
- Park, H.S.; Jun, C.H. A simple and fast algorithm for K-medoids clustering. Expert Syst. Appl. 2009, 36, 3336–3341. [Google Scholar] [CrossRef]
- Shullani, D.; Fontani, M.; Iuliani, M.; Al Shaya, O.; Piva, A. VISION: A video and image dataset for source identification. EURASIP J. Inf. Secur. 2017, 2017, 15. [Google Scholar] [CrossRef]
- Dey, S.; Roy, N.; Xu, W.; Choudhury, R.R.; Nelakuditi, S. AccelPrint: Imperfections of Accelerometers Make Smartphones Trackable; NDSS: San Diego, CA, USA, 2014. [Google Scholar]
- Willers, O.; Huth, C.; Guajardo, J.; Seidel, H. MEMS-based Gyroscopes as Physical Unclonable Functions. IACR Cryptol. Eprint Arch. 2016, 2016, 261. [Google Scholar]
- Jin, R.; Shi, L.; Zeng, K.; Pande, A.; Mohapatra, P. Magpairing: Pairing smartphones in close proximity using magnetometers. IEEE Trans. Inf. Forensics Secur. 2016, 11, 1306–1320. [Google Scholar] [CrossRef]
- Amerini, I.; Becarelli, R.; Caldelli, R.; Melani, A.; Niccolai, M. Smartphone Fingerprinting Combining Features of On-Board Sensors. IEEE Trans. Inf. Forensics Secur. 2017, 12, 2457–2466. [Google Scholar] [CrossRef]
- Alles, E.J.; Geradts, Z.J.; Veenman, C.J. Source camera identification for low resolution heavily compressed images. In Proceedings of the 2008 ICCSA’08, International Conference on Computational Sciences and Its Applications, Perugia, Italy, 30 June–3 July 2008; pp. 557–567. [Google Scholar]
- Das, A.; Borisov, N.; Caesar, M. Do you hear what i hear?: Fingerprinting smart devices through embedded acoustic components. In Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security, Scottsdale, AZ, USA, 3–7 November 2014; pp. 441–452. [Google Scholar]
- Cortiana, A.; Conotter, V.; Boato, G.; De Natale, F.G. Performance comparison of denoising filters for source camera identification. In Proceedings of the Media Forensics and Security, San Francisco Airport, CA, USA, 24–26 January 2011; p. 788007. [Google Scholar]
- Li, C.T.; Lin, X. A fast source-oriented image clustering method for digital forensics. EURASIP J. Image Video Process. 2017, 2017, 69. [Google Scholar] [CrossRef] [Green Version]
- Caldelli, R.; Amerini, I.; Picchioni, F.; Innocenti, M. Fast image clustering of unknown source images. In Proceedings of the 2010 IEEE International Workshop on Information Forensics and Security, Seattle, WA, USA, 12–15 December 2010; pp. 1–5. [Google Scholar]
- Villalba, L.J.G.; Orozco, A.L.S.; Corripio, J.R. Smartphone image clustering. Expert Syst. Appl. 2015, 42, 1927–1940. [Google Scholar] [CrossRef]
- Lin, X.; Li, C.T. Large-scale image clustering based on camera fingerprints. IEEE Trans. Inf. Forensics Secur. 2017, 12, 793–808. [Google Scholar] [CrossRef]
- Marra, F.; Poggi, G.; Sansone, C.; Verdoliva, L. Blind PRNU-based image clustering for source identification. IEEE Trans. Inf. Forensics Secur. 2017, 12, 2197–2211. [Google Scholar] [CrossRef]
- Amerini, I.; Caldelli, R.; Del Mastio, A.; Di Fuccia, A.; Molinari, C.; Rizzo, A.P. Dealing with video source identification in social networks. Signal Process. Image Commun. 2017, 57, 1–7. [Google Scholar] [CrossRef]
- Al Mutawa, N.; Baggili, I.; Marrington, A. Forensic analysis of social networking applications on mobile devices. Digit. Investig. 2012, 9, S24–S33. [Google Scholar] [CrossRef]
- Jamjuntra, L.; Chartsuwan, P.; Wonglimsamut, P.; Porkaew, K.; Supasitthimethee, U. Social network user identification. In Proceedings of the 2017 9th International Conference on Knowledge and Smart Technology (KST), Chonburi, Thailand, 1–4 February 2017; pp. 132–137. [Google Scholar]
- Winkler, W.E. String Comparator Metrics and Enhanced Decision Rules in the Fellegi-Sunter Model of Record Linkage; Education Resources Information Center-Institute of Education Sciences: Washington, DC, USA, 1990. [Google Scholar]
- Iofciu, T.; Fankhauser, P.; Abel, F.; Bischoff, K. Identifying users across social tagging systems. In Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media, Barcelona, Catalonia, Spain, 17–21 July 2011. [Google Scholar]
- Bartunov, S.; Korshunov, A.; Park, S.T.; Ryu, W.; Lee, H. Joint link-attribute user identity resolution in online social networks. In Proceedings of the 6th International Conference on Knowledge Discovery and Data Mining, Workshop on Social Network Mining and Analysis, Beijing, China, 12–16 August 2012. [Google Scholar]
- Raad, E.; Chbeir, R.; Dipanda, A. User profile matching in social networks. In Proceedings of the 2010 13th International Conference on Network-Based Information Systems, Takayama, Japan, 14–16 September 2010; pp. 297–304. [Google Scholar]
- Gupta, S.; Rogers, M. Using Computer Behavior Profiles to Differentiate between Users in a Digital Investigation; Annual ADFSL Conference on Digital Forensics, Security and Law: Daytona Beach, FL, USA, 2016; pp. 37–46. [Google Scholar]
- Zafarani, R.; Tang, L.; Liu, H. User identification across social media. ACM Trans. Knowl. Discov. Data TKDD 2015, 10, 16. [Google Scholar] [CrossRef]
- Naini, F.M.; Unnikrishnan, J.; Thiran, P.; Vetterli, M. Where You Are Is Who You Are: User Identification by Matching Statistics. IEEE Trans. Inf. Forensics Secur. 2016, 11, 358–372. [Google Scholar] [CrossRef] [Green Version]
- Agreste, S.; De Meo, P.; Ferrara, E.; Piccolo, S.; Provetti, A. Trust networks: Topology, dynamics, and measurements. IEEE Internet Comput. 2015, 19, 26–35. [Google Scholar] [CrossRef]
- Shu, K.; Wang, S.; Tang, J.; Zafarani, R.; Liu, H. User identity linkage across online social networks: A review. ACM Sigkdd Explor. Newsl. 2017, 18, 5–17. [Google Scholar] [CrossRef]
- Bertini, F.; Sharma, R.; Iannì, A.; Montesi, D. Smartphone Verification and User Profiles Linking Across Social Networks by Camera Fingerprinting. In Proceedings of the International Conference on Digital Forensics and Cyber Crime, Seoul, Republic of Korea, 6–8 October 2015; pp. 176–186. [Google Scholar]
- Rouhi, R.; Bertini, F.; Montesi, D. A Cluster-based Approach of Smartphone Camera Fingerprint for User Profiles Resolution within Social Network. In Proceedings of the 22nd International Database Engineering & Applications Symposium, Villa San Giovanni, Italy, 18–20 June 2018; pp. 287–291. [Google Scholar]
- Rouhi, R.; Bertini, F.; Montesi, D.; Li, C.T. Social Network Forensics through Smartphones and Shared Images. In Proceedings of the 2019 7th International Workshop on Biometrics and Forensics (IWBF), Cancun, Mexico, 2–3 May 2019; pp. 1–6. [Google Scholar]
- Bertini, F.; Sharma, R.; Iannì, A.; Montesi, D. Profile resolution across multilayer networks through smartphone camera fingerprint. In Proceedings of the 19th International Database Engineering & Applications Symposium, Yokohama, Japan, 13–15 July 2015; pp. 23–32. [Google Scholar]
- Lukáš, J.; Fridrich, J.; Goljan, M. Determining digital image origin using sensor imperfections. In Proceedings of the SPIE Electronic Imaging, Image and Video Communication and Processing, San Jose, CA, USA, 16–20 January 2005; Volume 5685, pp. 249–260. [Google Scholar]
- Bloy, G.J. Blind camera fingerprinting and image clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 532–534. [Google Scholar] [CrossRef]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Chierchia, G.; Parrilli, S.; Poggi, G.; Sansone, C.; Verdoliva, L. On the influence of denoising in PRNU based forgery detection. In Proceedings of the 2nd ACM workshop on Multimedia in Forensics, Security and Intelligence, Firenze, Italy, 29 October 2010; pp. 117–122. [Google Scholar]
- JEITA. Exchangeable Image File Format for Digital Still Cameras: Exif Version 2.2. 2002. Available online: http://www.exif.org/Exif2-2.PDF (accessed on 10 February 2021).
- Carlson, R.E.; Fritsch, F.N. An algorithm for monotone piecewise bicubic interpolation. SIAM J. Numer. Anal. 1989, 26, 230–238. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50× fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Fahad, A.; Alshatri, N.; Tari, Z.; Alamri, A.; Khalil, I.; Zomaya, A.Y.; Foufou, S.; Bouras, A. A survey of clustering algorithms for big data: Taxonomy and empirical analysis. IEEE Trans. Emerg. Top. Comput. 2014, 2, 267–279. [Google Scholar] [CrossRef]
- Shirkhorshidi, A.S.; Aghabozorgi, S.; Wah, T.Y.; Herawan, T. Big data clustering: A review. In Proceedings of the International Conference on Computational Science and Its Applications, Guimarães, Portugal, 30 June–3 July 2014; pp. 707–720. [Google Scholar]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the fifth Berkeley symposium on mathematical statistics and probability, Oakland, CA, USA, 21 June–18 July 1967; Volume 1, pp. 281–297. [Google Scholar]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: An Introduction to Cluster Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 344. [Google Scholar]
- Ertöz, L.; Steinbach, M.; Kumar, V. Finding clusters of different sizes, shapes, and densities in noisy, high dimensional data. In Proceedings of the 2003 SIAM International Conference on Data Mining, San Francisco, CA, USA, 1–3 May 2003; pp. 47–58. [Google Scholar]
- Chauhan, S.; Dhingra, S. Pattern recognition system using MLP neural networks. Pattern Recognit. 2012, 4, 43–46. [Google Scholar] [CrossRef]
- Abiodun, O.I.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Mohamed, N.A.; Arshad, H. State-of-the-art in artificial neural network applications: A survey. Heliyon 2018, 4, e00938. [Google Scholar] [CrossRef] [Green Version]
- Freeman, J.A.; Skapura, D.M. Algorithms, Applications, and Programming Techniques; Addison-Wesley Publishing Company: Boston, MA, USA, 1991. [Google Scholar]
- Haykin, S. Neural Networks: A Comprehensive Foundation; Prentice Hall PTR: New York, NY, USA, 1994. [Google Scholar]
- Yegnanarayana, B. Artificial Neural Networks; PHI Learning Pvt. Ltd.: Patparganj, India, 2009. [Google Scholar]
- Refaeilzadeh, P.; Tang, L.; Liu, H. Cross Validation, Encyclopedia of Database Systems (EDBS); Springer: New York, NY, USA, 2009; p. 6. [Google Scholar]
- Hubert, L.; Arabie, P. Comparing partitions. J. Classif. 1985, 2, 193–218. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Phone ID | Brand | Model | Resolution |
|---|---|---|---|
| S1 | LG | Nexus 4 | |
| S2 | Samsung | Galaxy S2 | |
| S3 | Apple | iPhone 6+ | |
| S4 | LG | Nexus 5 | |
| S5 | Huawei | Y550 | |
| S6 | Apple | iPhone 5 | |
| S7 | Motorola | Moto G | |
| S8 | Samsung | Galaxy S4 | |
| S9 | LG | G3 | |
| S10 | LG | Nexus 5 | |
| S11 | Sony | Xperia Z3 | |
| S12 | Samsung | Samsung S3 | |
| S13 | HTC | One S | |
| S14 | LG | Nexus 5 | |
| S15 | Apple | iPhone 6 | |
| S16 | Samsung | Galaxy S2 | |
| S17 | Nokia | Lumia 625 | |
| S18 | Apple | iPhone 5S |
| Dataset | Lowest Resolution | Highest Resolution |
|---|---|---|
| Type | Multi-Layer Perceptron (MLP) |
|---|---|
| Number of layers | 2 |
| Neurons in input layer | |
| Neurons in hidden layer | 50 |
| Neurons in output layer | |
| Learning rule | Back Propagation (BP) |
| Training function | trainscg |
| Activation function | logsig |
| Error | Mean Squared Error (MSE) |
| Resizing | Cropping * | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Size | 𝓢𝓔 | 𝓢𝓟 | 𝓐𝓡𝓘 | 𝓕 | 𝓟 | 𝓢𝓔 | 𝓢𝓟 | 𝓐𝓡𝓘 | 𝓕 | 𝓟 |
| 0.91 | 0.99 | 0.88 | 0.88 | 0.95 | —— | —— | —— | —— | —— | |
| 0.89 | 0.99 | 0.85 | 0.86 | 0.94 | —— | —— | —— | —— | —— | |
| 0.91 | 0.99 | 0.90 | 0.91 | 0.96 | —— | —— | —— | —— | —— | |
| 0.90 | 0.99 | 0.87 | 0.88 | 0.95 | 0.91 | 0.99 | 0.89 | 0.90 | 0.95 | |
| 0.90 | 0.99 | 0.87 | 0.88 | 0.94 | 0.85 | 0.98 | 0.81 | 0.82 | 0.89 | |
| 0.58 | 0.97 | 0.55 | 0.57 | 0.75 | 0.76 | 0.98 | 0.74 | 0.75 | 0.87 | |
| 0.18 | 0.94 | 0.12 | 0.17 | 0.37 | 0.43 | 0.96 | 0.39 | 0.42 | 0.66 | |
| Dataset | 𝓢𝓔 | 𝓢𝓟 | 𝓐𝓡𝓘 | 𝓕 | 𝓟 |
|---|---|---|---|---|---|
| 0.91 | 0.99 | 0.90 | 0.91 | 0.96 | |
| 0.84 | 0.99 | 0.84 | 0.85 | 0.894 |
| Dataset | 𝓢𝓔 | 𝓢𝓟 | 𝓐𝓡𝓘 | 𝓕 | 𝓟 |
|---|---|---|---|---|---|
| 0.92 | 0.99 | 0.91 | 0.91 | 0.97 | |
| 0.85 | 0.99 | 0.82 | 0.83 | 0.92 | |
| 0.85 | 0.99 | 0.82 | 0.83 | 0.92 | |
| 0.86 | 0.99 | 0.83 | 0.84 | 0.93 | |
| 0.81 | 0.99 | 0.79 | 0.80 | 0.91 | |
| 0.80 | 0.99 | 0.77 | 0.77 | 0.90 | |
| 0.78 | 0.99 | 0.75 | 0.75 | 0.89 |
| Dataset | 𝓓 | 𝓓 | 𝓓 | 𝓓 | 𝓓 | 𝓓 | 𝓓 |
|---|---|---|---|---|---|---|---|
| 0.91 | 0.87 | 0.88 | 0.87 | 0.75 | 0.73 | 0.43 | |
| 0.99 | 0.98 | 0.99 | 0.99 | 0.99 | 0.99 | 0.98 | |
| 0.88 | 0.84 | 0.86 | 0.86 | 0.74 | 0.71 | 0.40 | |
| 0.89 | 0.86 | 0.85 | 0.85 | 0.75 | 0.71 | 0.42 | |
| 0.96 | 0.94 | 0.93 | 0.92 | 0.84 | 0.80 | 0.58 |
| Dataset | 𝓢𝓔 | 𝓢𝓟 | 𝓐𝓡𝓘 | 𝓕 | 𝓟 |
|---|---|---|---|---|---|
| 0.90 | 0.99 | 0.87 | 0.88 | 0.96 | |
| 0.90 | 0.99 | 0.87 | 0.87 | 0.95 | |
| 0.92 | 0.99 | 0.90 | 0.91 | 0.96 | |
| 0.91 | 0.99 | 0.90 | 0.90 | 0.96 | |
| 0.86 | 0.99 | 0.83 | 0.83 | 0.94 | |
| 0.90 | 0.99 | 0.88 | 0.87 | 0.95 | |
| 0.90 | 0.99 | 0.88 | 0.88 | 0.95 | |
| 0.86 | 0.98 | 0.82 | 0.83 | 0.94 | |
| 0.87 | 0.99 | 0.84 | 0.85 | 0.93 | |
| 0.90 | 0.99 | 0.88 | 0.90 | 0.95 | |
| 0.87 | 0.98 | 0.85 | 0.85 | 0.94 | |
| 0.87 | 0.98 | 0.85 | 0.86 | 0.94 |
| Dataset | 𝓢𝓔 | 𝓢𝓟 | 𝓐𝓡𝓘 | 𝓕 | 𝓟 |
|---|---|---|---|---|---|
| 0.80 | 0.99 | 0.78 | 0.79 | 0.90 | |
| 0.80 | 0.99 | 0.78 | 0.78 | 0.88 | |
| 0.78 | 0.99 | 0.76 | 0.77 | 0.87 | |
| 0.77 | 0.99 | 0.76 | 0.76 | 0.87 | |
| 0.61 | 0.99 | 0.58 | 0.59 | 0.72 | |
| 0.61 | 0.99 | 0.59 | 0.60 | 0.73 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rouhi, R.; Bertini, F.; Montesi, D. No Matter What Images You Share, You Can Probably Be Fingerprinted Anyway. J. Imaging 2021, 7, 33. https://doi.org/10.3390/jimaging7020033
Rouhi R, Bertini F, Montesi D. No Matter What Images You Share, You Can Probably Be Fingerprinted Anyway. Journal of Imaging. 2021; 7(2):33. https://doi.org/10.3390/jimaging7020033
Chicago/Turabian StyleRouhi, Rahimeh, Flavio Bertini, and Danilo Montesi. 2021. "No Matter What Images You Share, You Can Probably Be Fingerprinted Anyway" Journal of Imaging 7, no. 2: 33. https://doi.org/10.3390/jimaging7020033
APA StyleRouhi, R., Bertini, F., & Montesi, D. (2021). No Matter What Images You Share, You Can Probably Be Fingerprinted Anyway. Journal of Imaging, 7(2), 33. https://doi.org/10.3390/jimaging7020033