
Lip Reading by Alternating between Spatiotemporal and Spatial Convolutions


Abstract
:1. Introduction
2. Related Work
3. Proposed Method
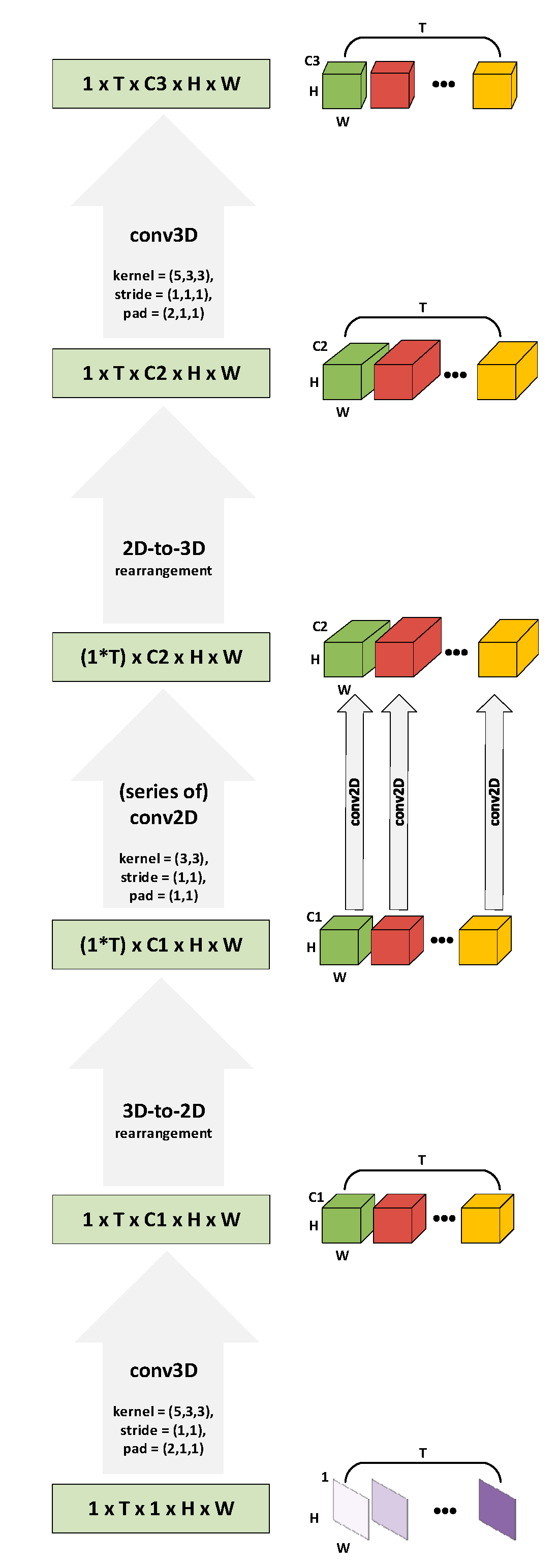
3.1. Alternating Spatiotemporal and Spatial Convolutions (ALSOS) Module
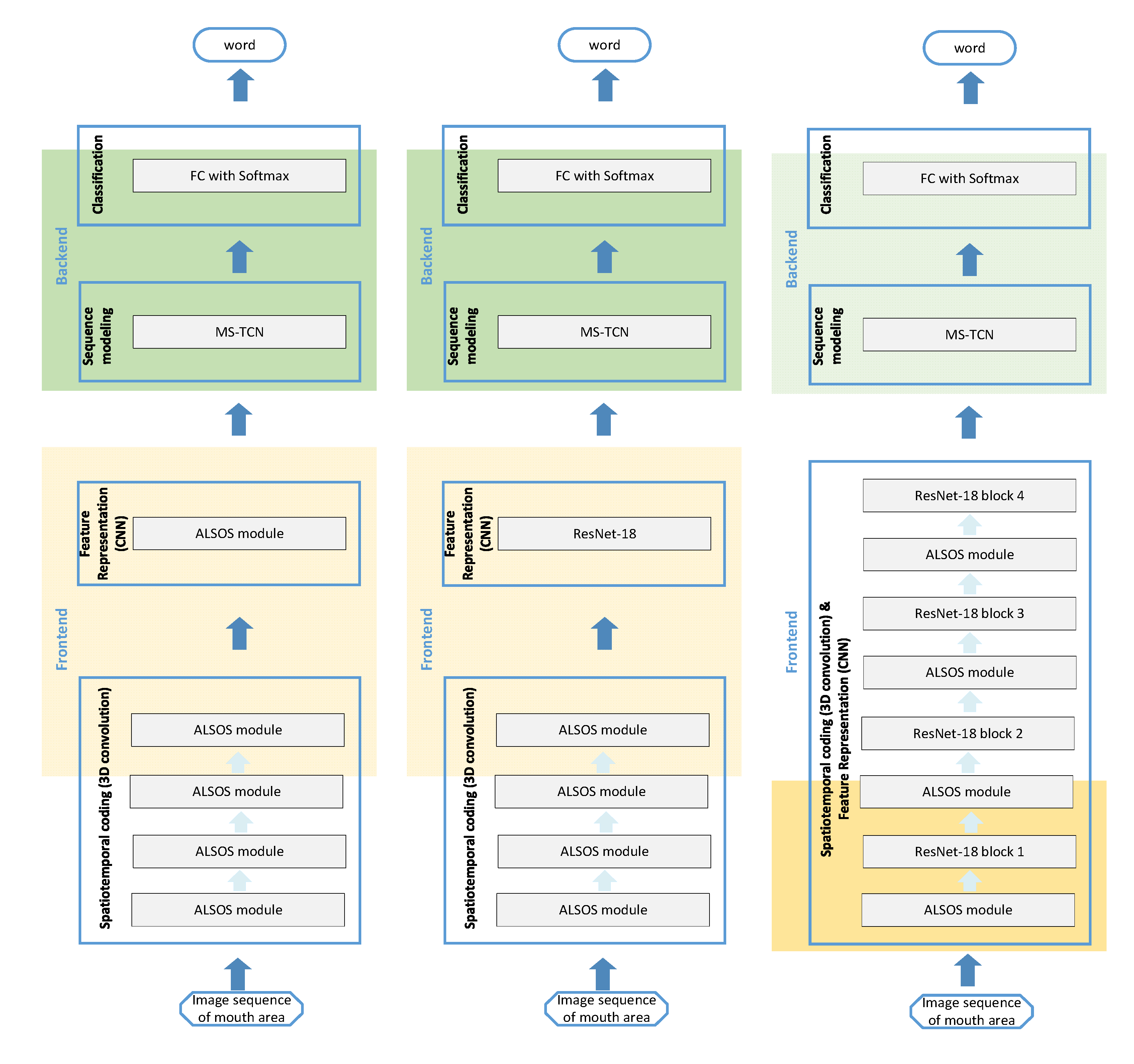
3.2. ALSOS and CNNs: Architecture for Image Sequence Mapping
4. Experimental Results
4.1. Materials and Methods
4.2. Datasets
4.3. Evaluation on Greek Words in a Biomedical Application Using the LRGW-10 Dataset
4.4. Evaluation on English Words in the Large Scale LRW-500 Dataset
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems—Volume 1, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. Available online: http://dl.acm.org/citation.cfm?id=2999134.2999257 (accessed on 19 May 2021).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the 28th International Conference on Neural Information Processing Systems—Volume 1, Cambridge, MA, USA, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Cham, Switzedland, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Lea, C.; Vidal, R.; Reiter, A.; Hager, G.D. Temporal Convolutional Networks: A Unified Approach to Action Segmentation. In Proceedings of the Computer Vision—ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–10 and 15–16 October 2016; pp. 47–54. [Google Scholar] [CrossRef] [Green Version]
- Lea, C.; Flynn, M.D.; Vidal, R.; Reiter, A.; Hager, G.D. Temporal Convolutional Networks for Action Segmentation and Detection. 2017, pp. 156–165. Available online: https://openaccess.thecvf.com/content_cvpr_2017/html/Lea_Temporal_Convolutional_Networks_CVPR_2017_paper.html (accessed on 14 September 2020).
- Chen, Y.; Kang, Y.; Chen, Y.; Wang, Z. Probabilistic forecasting with temporal convolutional neural network. Neurocomputing 2020, 399, 491–501. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.-X.; Ling, Z.-H.; Liu, L.-J.; Jiang, Y.; Dai, L.-R. Sequence-to-Sequence Acoustic Modeling for Voice Conversion. IEEE/ACM Trans. Audio. Speech. Lang. Process. 2019, 27, 631–644. [Google Scholar] [CrossRef] [Green Version]
- Otter, D.W.; Medina, J.R.; Kalita, J.K. A Survey of the Usages of Deep Learning for Natural Language Processing. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 604–624. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems—Volume 2, Cambridge, MA, USA, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, H.; Chen, H.; Brown, R. A sequence-to-sequence model-based deep learning approach for recognizing activity of daily living for senior care. J. Biomed. Inform. 2018, 84, 148–158. [Google Scholar] [CrossRef] [PubMed]
- Fernandez-Lopez, A.; Sukno, F.M. Survey on automatic lip-reading in the era of deep learning. Image Vis. Comput. 2018, 78, 53–72. [Google Scholar] [CrossRef]
- Agrawal, S.; Omprakash, V.R. Lip reading techniques: A survey. In Proceedings of the 2016 2nd International Conference on Applied and Theoretical Computing and Communication Technology (iCATccT), Bengaluru, Karnataka, India, 21–23 July 2016; pp. 753–757. [Google Scholar] [CrossRef]
- Zhou, Z.; Zhao, G.; Hong, X.; Pietikäinen, M. A review of recent advances in visual speech decoding. Image Vis. Comput. 2014, 32, 590–605. [Google Scholar] [CrossRef]
- Van den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. WaveNet: A Generative Model for Raw Audio. In Proceedings of the 9th ISCA Speech Synthesis Workshop, Sunnyvale, CA, USA, 13–15 September 2016; p. 125. Available online: http://www.isca-speech.org/archive/SSW_2016/abstracts/ssw9_DS-4_van_den_Oord.html (accessed on 19 May 2021).
- Zhang, Y.; Yang, S.; Xiao, J.; Shan, S.; Chen, X. Can We Read Speech Beyond the Lips? Rethinking RoI Selection for Deep Visual Speech Recognition. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 16–20 May 2020. [Google Scholar] [CrossRef]
- Feng, D.; Yang, S.; Shan, S.; Chen, X. Learn an Effective Lip Reading Model without Pains. arXiv 2020, arXiv:2011.07557. [Google Scholar]
- Stafylakis, T.; Tzimiropoulos, G. Combining Residual Networks with LSTMs for Lipreading. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 3652–3656. [Google Scholar] [CrossRef] [Green Version]
- Wang, C. Multi-Grained Spatio-temporal Modeling for Lip-reading. In Proceedings of the 30th British Machine Vision Conference 2019 (BMVC 2019), Cardiff, UK, 9–12 September 2019; p. 276. Available online: https://bmvc2019.org/wp-content/uploads/papers/1211-paper.pdf (accessed on 19 May 2021).
- Weng, X.; Kitani, K. Learning Spatio-Temporal Features with Two-Stream Deep 3D CNNs for Lipreading. In Proceedings of the 30th British Machine Vision Conference 2019 (BMVC 2019), Cardiff, UK, 9–12 September 2019; p. 269. Available online: https://bmvc2019.org/wp-content/uploads/papers/0016-paper.pdf (accessed on 19 May 2021).
- Kastaniotis, D.; Tsourounis, D.; Fotopoulos, S. Lip Reading modeling with Temporal Convolutional Networks for medical support applications. In Proceedings of the 2020 13th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Chengdu, China, 17–19 October 2020. [Google Scholar] [CrossRef]
- Martinez, B.; Ma, P.; Petridis, S.; Pantic, M. Lipreading Using Temporal Convolutional Networks. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6319–6323. [Google Scholar] [CrossRef] [Green Version]
- Dupont, S.; Luettin, J. Audio-visual speech modeling for continuous speech recognition. IEEE Trans. Multimed. 2000, 2, 141–151. [Google Scholar] [CrossRef]
- Chung, J.S.; Zisserman, A. Lip reading in the wild. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 87–103. [Google Scholar]
- Matthews, I.; Cootes, T.; Bangham, J.A.; Cox, S.; Harvey, R. Extraction of visual features for lipreading. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 198–213. [Google Scholar] [CrossRef]
- Messer, K. XM2VTSDB: The extended m2vts database. In Proceedings of the 1999 International Conference on Audio- and Video-Based Person Authentication, Washington, DC, USA, 22–24 March 1999; pp. 72–77. [Google Scholar]
- Patterson, E.; Gurbuz, S.; Tufekci, Z.; Gowdy, J. CUAVE: A new audio-visual database for multimodal human-computer interface research. In Proceedings of the IEEE International Conference on Acoustics Speech and Signal Processing, Orlando, FL, USA, 13–17 May 2002; Volume 2, p. II-2017. [Google Scholar]
- Chung, J.S.; Zisserman, A.P. Lip Reading in Profile. 2017. Available online: https://ora.ox.ac.uk/objects/uuid:9f06858c-349c-416f-8ace-87751cd401fc (accessed on 14 September 2020).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kastaniotis, D.; Tsourounis, D.; Koureleas, A.; Peev, B.; Theoharatos, C.; Fotopoulos, S. Lip Reading in Greek words at unconstrained driving scenario. In Proceedings of the 2019 10th International Conference on Information, Intelligence, Systems and Applications (IISA), Patras, Greece, 15–17 July 2019; pp. 1–6. [Google Scholar]
- Luo, M.; Yang, S.; Shan, S.; Chen, X. Pseudo-Convolutional Policy Gradient for Sequence-to-Sequence Lip-Reading. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 16–20 May 2020; pp. 273–280. [Google Scholar]
- Zhao, X.; Yang, S.; Shan, S.; Chen, X. Mutual Information Maximization for Effective Lip Reading. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 16–20 May 2020; pp. 420–427. [Google Scholar]
- Xiao, J.; Yang, S.; Zhang, Y.; Shan, S.; Chen, X. Deformation Flow Based Two-Stream Network for Lip Reading. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 16–20 May 2020; pp. 364–370. [Google Scholar]
- Cheng, S.; Ma, P.; Tzimiropoulos, G.; Petridis, S.; Bulat, A.; Shen, J.; Pantic, M. Towards Pose-Invariant Lip-Reading. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 4357–4361. [Google Scholar]
- Hara, K.; Kataoka, H.; Satoh, Y. Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet? In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6546–6555. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A Closer Look at Spatiotemporal Convolutions for Action Recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6450–6459. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4724–4733. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Piscataway, NJ, USA, 7–12 June 2015; pp. 1026–1034. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in pytorch. In Proceedings of the NeurIPS Workshop Autodiff, Long Beach, CA, USA, 9 December 2017. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for StochasticOptimizatio. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Courtney, L.; Sreenivas, R. Using Deep Convolutional LSTM Networks for Learning Spatiotemporal Features. In Proceedings of the ACPR 2019: Pattern Recognition, Auckland, New Zealand, 26–29 November 2019. [Google Scholar] [CrossRef]
- Chung, J.S.; Senior, A.; Vinyals, O.; Zisserman, A. Lip Reading Sentences in the Wild. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3444–3453. [Google Scholar]
- Petridis, S.; Stafylakis, T.; Ma, P.; Cai, F.; Tzimiropoulos, G.; Pantic, M. End-to-End Audiovisual Speech Recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 6548–6552. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| LR System | GMACS | Time (ms) | Parameters |
|---|---|---|---|
| ALSOS + MS-TCN | 72.37 | 56.9 | 28.22M |
| ALSOS & ResNet-18 + MS-TCN | 12.45 | 16.1 | 40.12M |
| 3D & ResNet-18 + MS-TCN [22] | 10.31 | 11.5 | 36.36M |
| Alternating ALSOS & ResNet-18 + MS-TCN | 14.49 | 13.8 | 41.23M |
| Method | Data | LRGW-10 | ||
|---|---|---|---|---|
| Authors’ Name (Year) | Frontend | Backend | Input Image Size | Classification Accuracy (%) |
| Kastaniotis et al. (2020) [21] | 3D & ResNet-18 (pretrained on ImageNet) | MS-TCN (He Normal initialization) | 112 × 112 | 41.1 |
| Kastaniotis et al. (2020) [21] | 3D & ResNet-18 (pretrained on subset of LRW) | MS-TCN (pretrained on subset of LRW) | 112 × 112 | 50.2 |
| Ours | ALSOS (He Normal initialization) | MS-TCN (pretrained on LRW) | 112 × 112 | 44.2 |
| Ours | ALSOS & ResNet-18 (pretrained on LRW) | MS-TCN (pretrained on LRW) | 112 × 112 | 51.6 |
| Ours | Alternating ALSOS (He Normal initialization) & ResNet-18 layers (pretrained on ImageNet) | MS-TCN (He Normal initialization) | 112 × 112 | 51.8 |
| Ours | Alternating ALSOS & ResNet-18 layers (pretrained on subset of LRW) | MS-TCN (pretrained on subset of LRW) | 112 × 112 | 54.3 |
| Ours | Alternating ALSOS & ResNet-18 layers (pretrained on LRW) | MS-TCN (pretrained on LRW) | 112 × 112 | 56.3 |
| Classification Accuracy (%) on the Validation Set of LRW-500 | ||||
|---|---|---|---|---|
| Mini-Batch Size | 8 | 16 | 32 | 40 |
| Alternating ALSOS & ResNet-18 blocks | 85.96% | 86.1% | 86.6% | 87.0% |
| Method | Data | LRW-500 | |||
|---|---|---|---|---|---|
| Authors’ Name (Year) | Frontend | Backend | Input Image Size | Input and Data Managing Policy | Classification Accuracy Top-1, WRR (%) |
| Chung et al. (2016) [24] | 3D & VGG M | - | 112 × 112 | Mouth | 61.10% |
| Chung et al. (2017) [42] | 3D & VGG M version | LSTM & Attention | 120 × 120 | Mouth | 76.20% |
| Petridis et al. (2018) [43] | 3D & ResNet-34 | Bi-GRU | 96 × 96 | Mouth | 82.00% |
| Stafylakis et al. (2017) [18] | 3D & ResNet-34 | Bi-LSTM | 112 × 112 | Mouth | 83.00% |
| Cheng et al. (2020) [34] | 3D & ResNet-18 | Bi-GRU | 88 × 88 | Mouth & 3D augmentations | 83.20% |
| Wang et al. (2019) [19] | 2-Stream ResNet-34 & DenseNet3D-52 | Bi-LSTM | 88 × 88 | Mouth | 83.34% |
| Courtney et al. (2020) [41] | alternating ResidualNet Bi-LSTM | alternating ResidualNet Bi-LSTM | 48 × 48, 56 × 56, 64 × 64 | Mouth | 83.40% |
| Luo et al. (2020) [31] | 3D & 2-Stream ResNet-18 | Bi-GRU | 88 × 88 | Mouth and gradient policy | 83.50% |
| Weng et al. (2019) [20] | deep 3D & 2-Stream ResNet-18 | Bi-LSTM | 112 × 112 | Mouth & optical flow | 84.07% |
| Xiao et al. (2020) [33] | 3D & 2-Stream ResNet-18 | Bi-GRU | 88 × 88 | Mouth & deformation flow | 84.13% |
| Zhao et al. (2020) [32] | 3D & ResNet-18 | Bi-GRU | 88 × 88 | Mouth and mutual information | 84.41% |
| Zhang et al. (2020) [16] | 3D & ResNet-18 | Bi-GRU | 112 × 112 | Mouth (Aligned) | 85.02% |
| Feng et al. (2020) [17] | 3D & SE ResNet-18 | Bi-GRU | 88 × 88 | Mouth (Aligned) & augmentations | 85.00% |
| Martinez et al. (2020) [22] | 3D & ResNet-18 | MS-TCN | 88 × 88 | Mouth (Aligned) | 85.30% |
| Ours | ALSOS (4 stacked) | MS-TCN | 88 × 88 | Mouth (Aligned) | 84.38% |
| Ours | ALSOS & ResNet-18 | MS-TCN | 88 × 88 | Mouth (Aligned) | 85.65% |
| Ours | Alternating ALSOS & ResNet-18 blocks | MS-TCN | 88 × 88 | Mouth (Aligned) | 87.01% |
| Classification Accuracy (%) on the LRW-500 (top-K) | |||
|---|---|---|---|
| LR System | Top-3 Accuracy | Top-5 Accuracy | Top-10 Accuracy |
| ALSOS (4 stacked) | 86.8% | 97.3% | 98.3% |
| ALSOS & ResNet-18 | 88.4% | 97.8% | 98.7% |
| Alternating ALSOS & ResNet-18 blocks | 88.7% | 98.0% | 99.3% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsourounis, D.; Kastaniotis, D.; Fotopoulos, S. Lip Reading by Alternating between Spatiotemporal and Spatial Convolutions. J. Imaging 2021, 7, 91. https://doi.org/10.3390/jimaging7050091
Tsourounis D, Kastaniotis D, Fotopoulos S. Lip Reading by Alternating between Spatiotemporal and Spatial Convolutions. Journal of Imaging. 2021; 7(5):91. https://doi.org/10.3390/jimaging7050091
Chicago/Turabian StyleTsourounis, Dimitrios, Dimitris Kastaniotis, and Spiros Fotopoulos. 2021. "Lip Reading by Alternating between Spatiotemporal and Spatial Convolutions" Journal of Imaging 7, no. 5: 91. https://doi.org/10.3390/jimaging7050091
APA StyleTsourounis, D., Kastaniotis, D., & Fotopoulos, S. (2021). Lip Reading by Alternating between Spatiotemporal and Spatial Convolutions. Journal of Imaging, 7(5), 91. https://doi.org/10.3390/jimaging7050091