
Spline-Based Dense Medial Descriptors for Lossy Image Compression



Abstract
:1. Introduction
- Novelty: Our method is, to our knowledge, the first approach to encode color images with B-spline-based MATs;
- Generality: SDMD can directly handle any raster image of any resolution;
- Scalability: End-to-end, our method can encode (and decode) megapixel images in a few seconds on a commodity PC featuring a modern graphics processing unit (GPU);
- Evaluation: We show that SDMD has good performance (compression ratio and quality) on a wide set of natural and synthetic color images of different sizes;
- Applications: We show that SDMD enables additional applications besides compression, such as generating super-resolution images and compression that preserves salient features.
2. Related Work
2.1. CDMD Method
2.2. SMAT Method
2.3. Image Compression Methods
- We do not aim quality wise or compression ratio wise to compete with the compression effect of DNN techniques.
- We reduce significantly the blocking and banding artifacts of transform domain coding methods.
- We do not need any training data or expensive training procedures.
- We offer full control on how the compression works by the exposed free parameter of our method.
- Conceptually, we show that spline-based MATs are an efficient and effective tool for color image compression, which is, to our knowledge, the first result in this area.
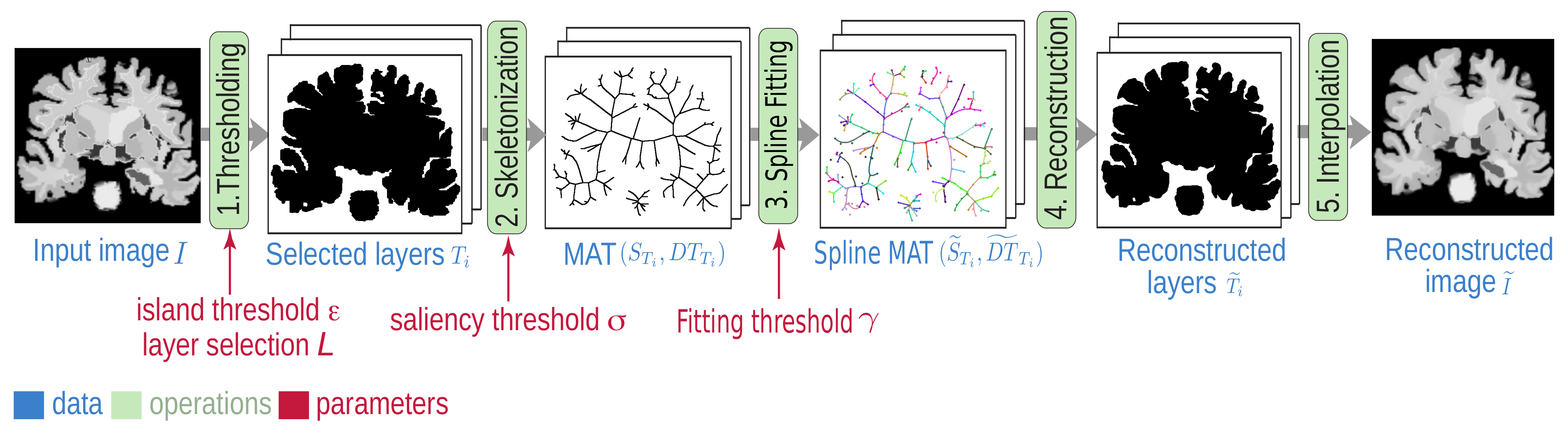
3. SDMD Method
3.1. Adaptive Layer Encoding
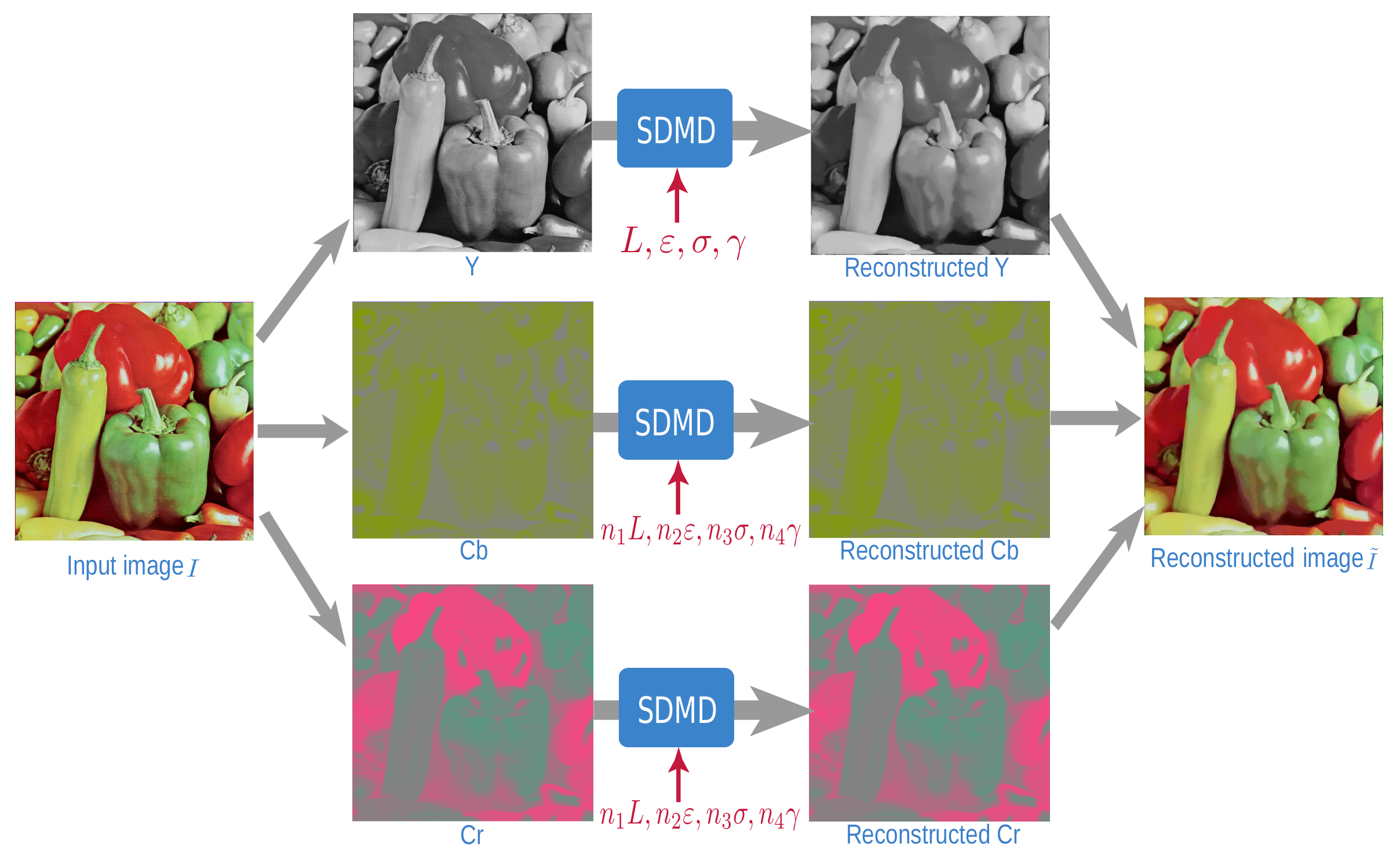
3.2. Per-Channel Encoding
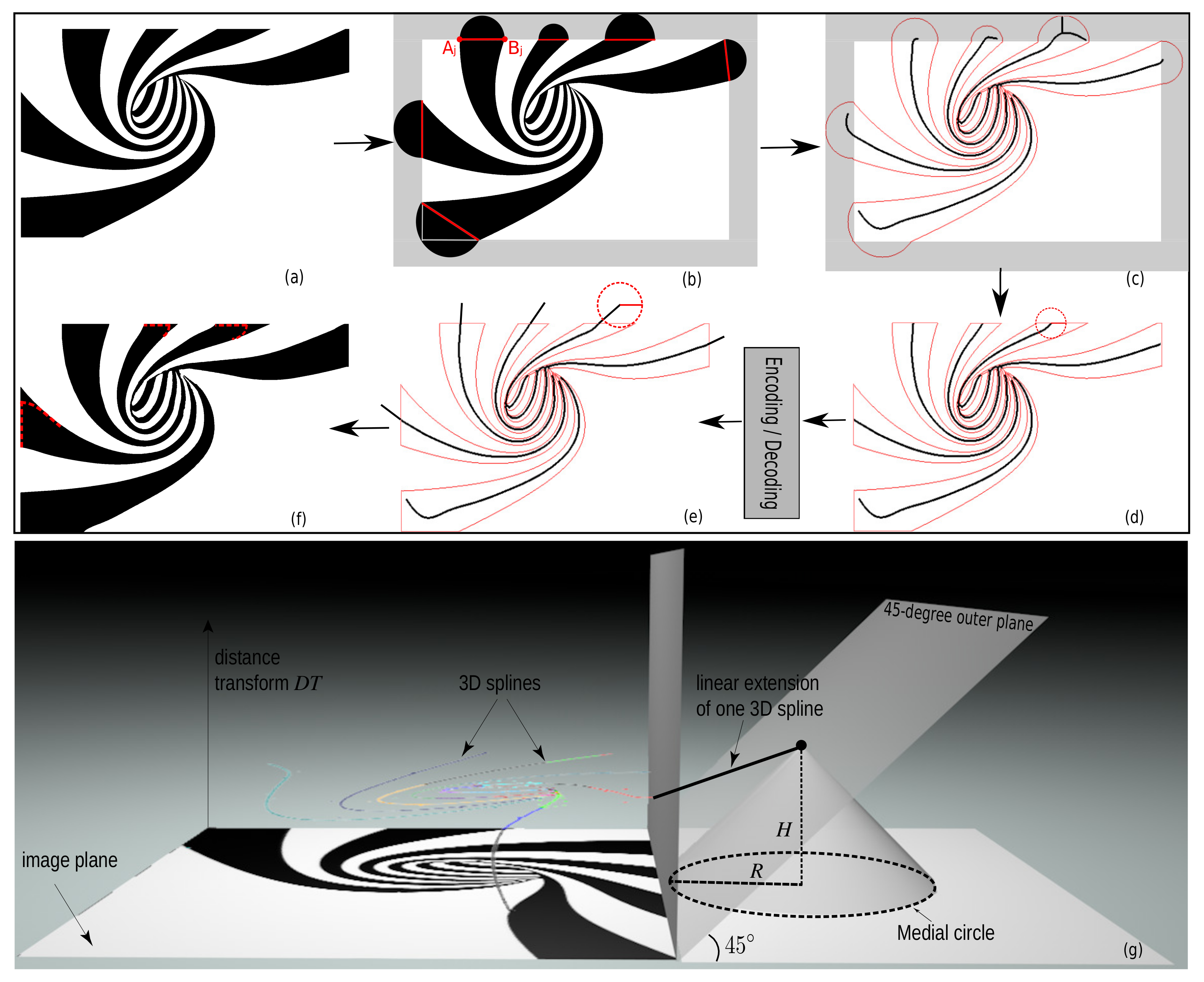
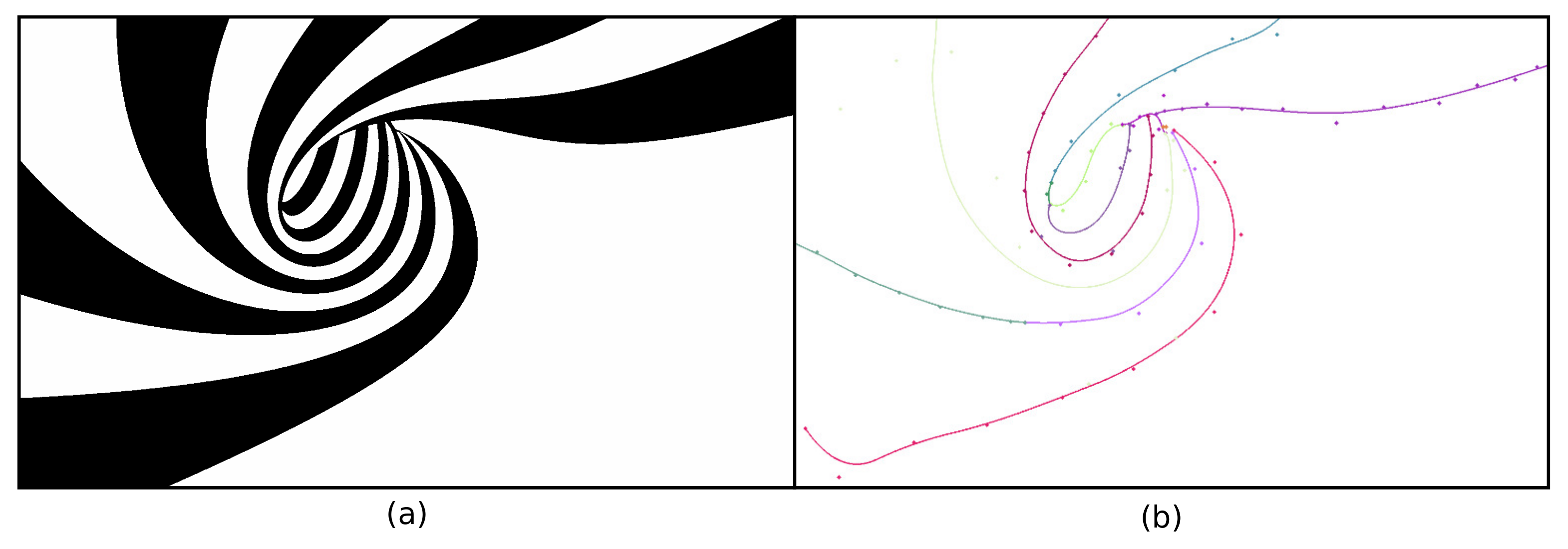
3.3. Boundary Y-Structure Elimination
| Algorithm 1: Semi-disc extension algorithm |
| Input: Threshold-set Output: Extended to be skeletonized 1 Scan the pixel border of to detect the boundary segments . 2 Enlarge by a band of thickness in all four directions. 3 Draw a semi-disc atop each segment with diameter and centered at . |
4. Results
- First, we build an evaluation benchmark (Section 4.1);
- We study how SDMD depends on its free parameters (Section 4.2);
- We quantitatively assess the adaptive layer and per-channel encoding extensions proposed earlier (Section 4.3);
- We compare our method with the original CDMD method, the well-known JPEG technique, and the recently developed JPEG 2000 and BPG. (Section 4.4);
- Finally, we show how SDMD performs on images of different resolutions (Section 4.5).
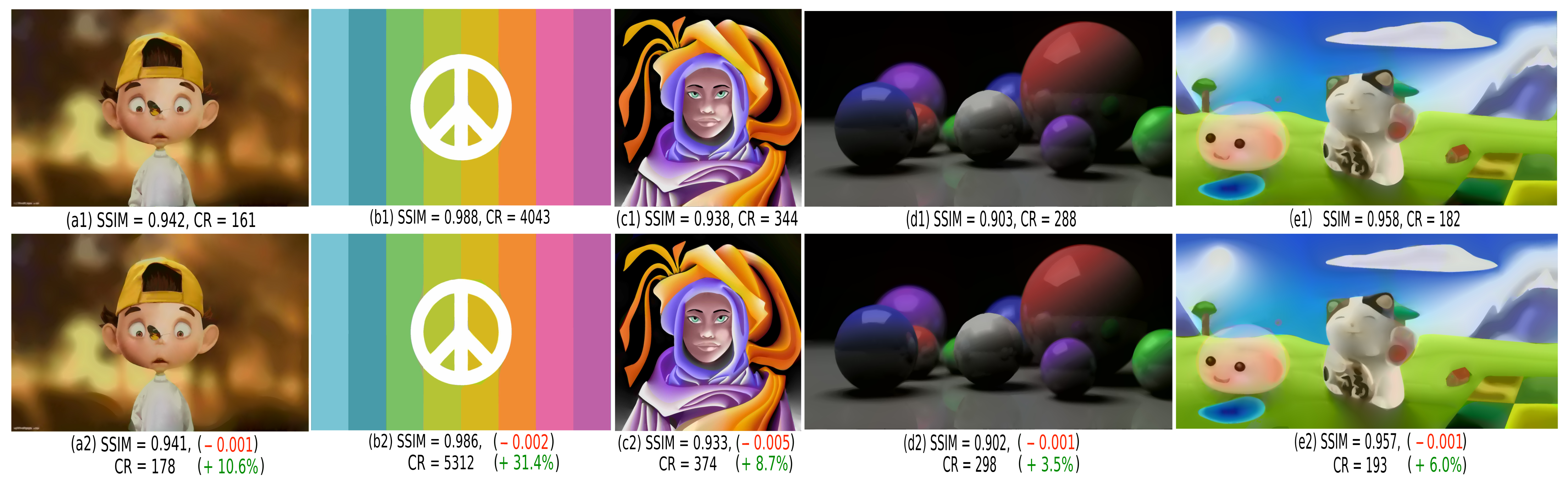
4.1. Benchmark
4.2. Parameters Effect
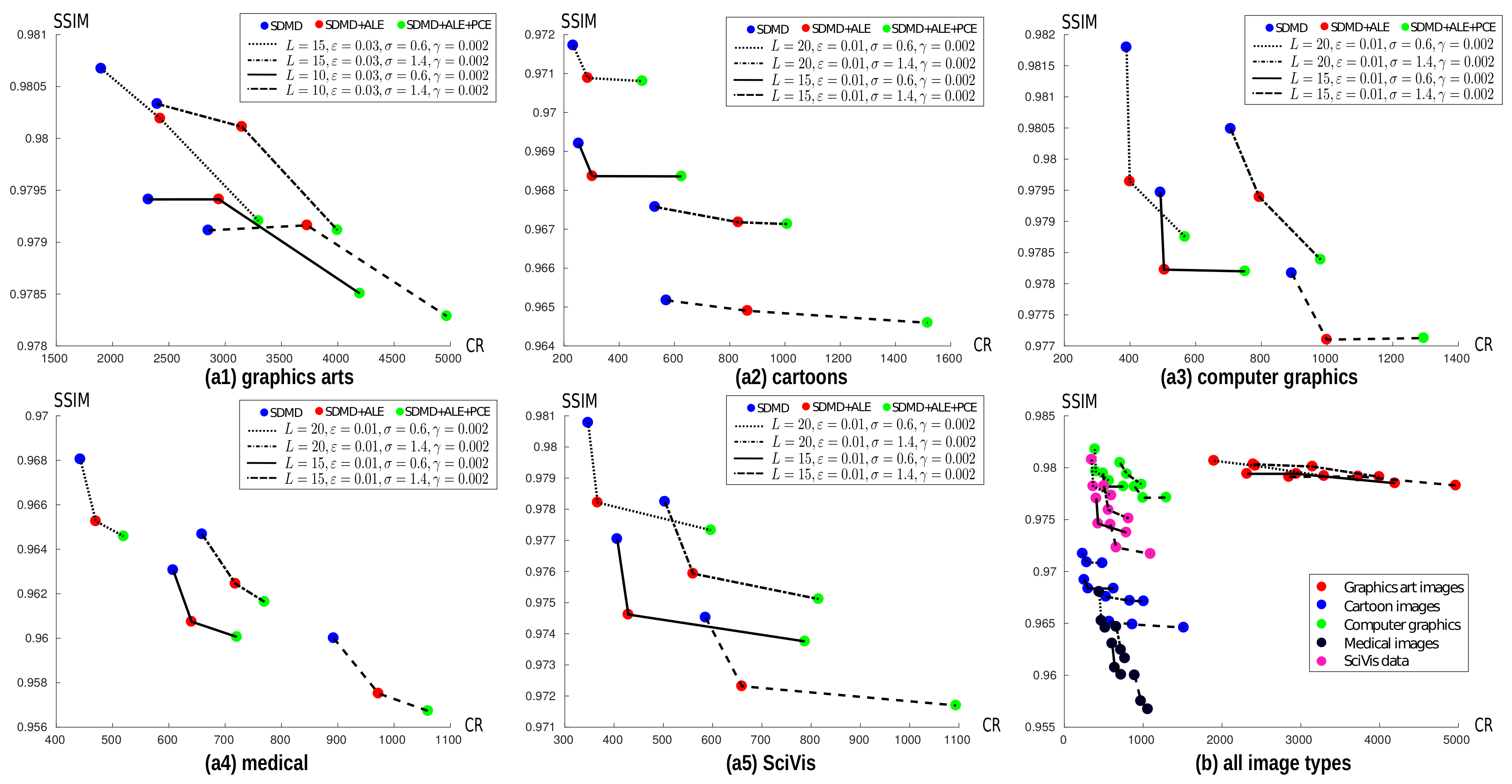
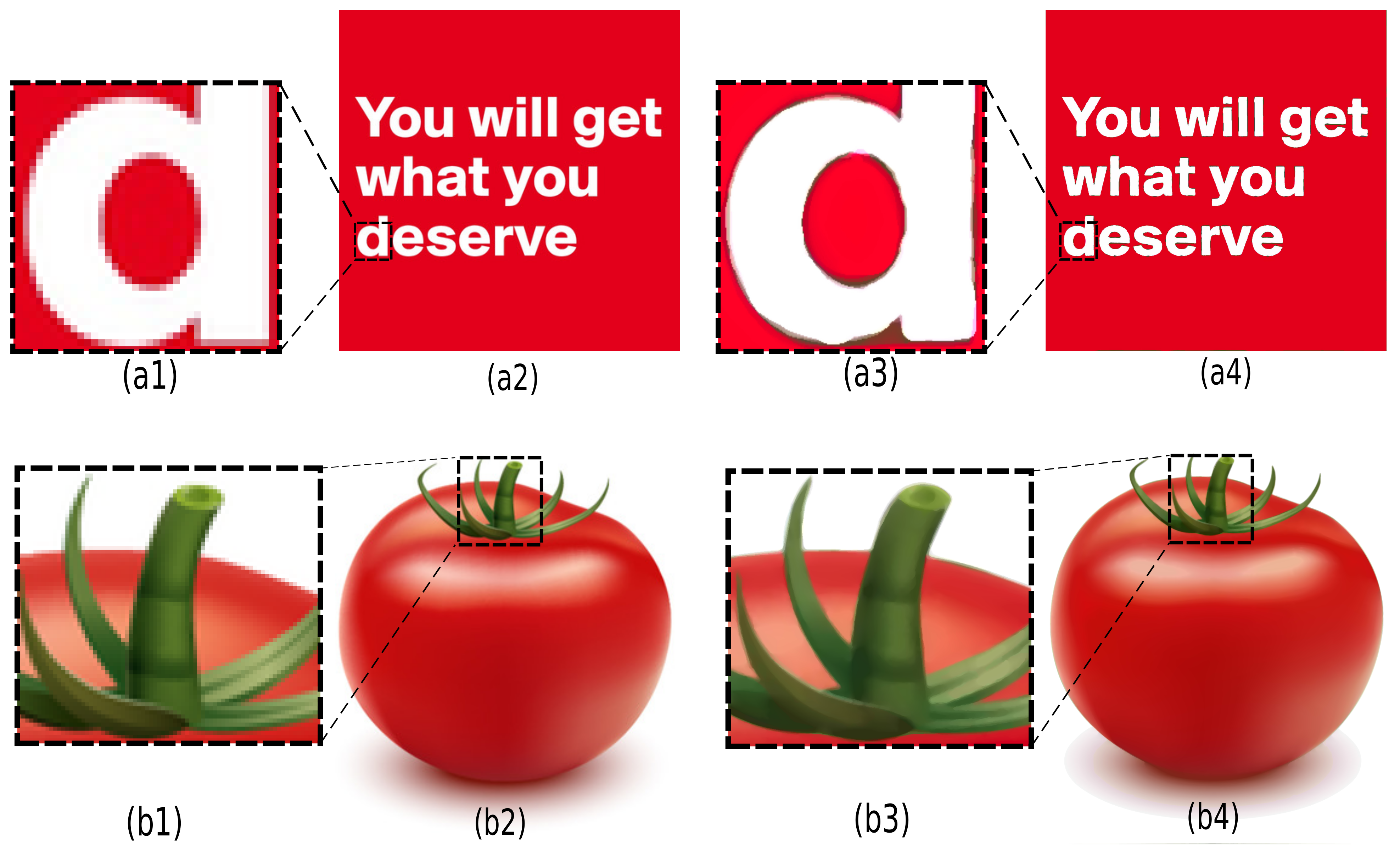
4.3. Quantitative Evaluation of Adaptive Layer and Per-Channel Encoding
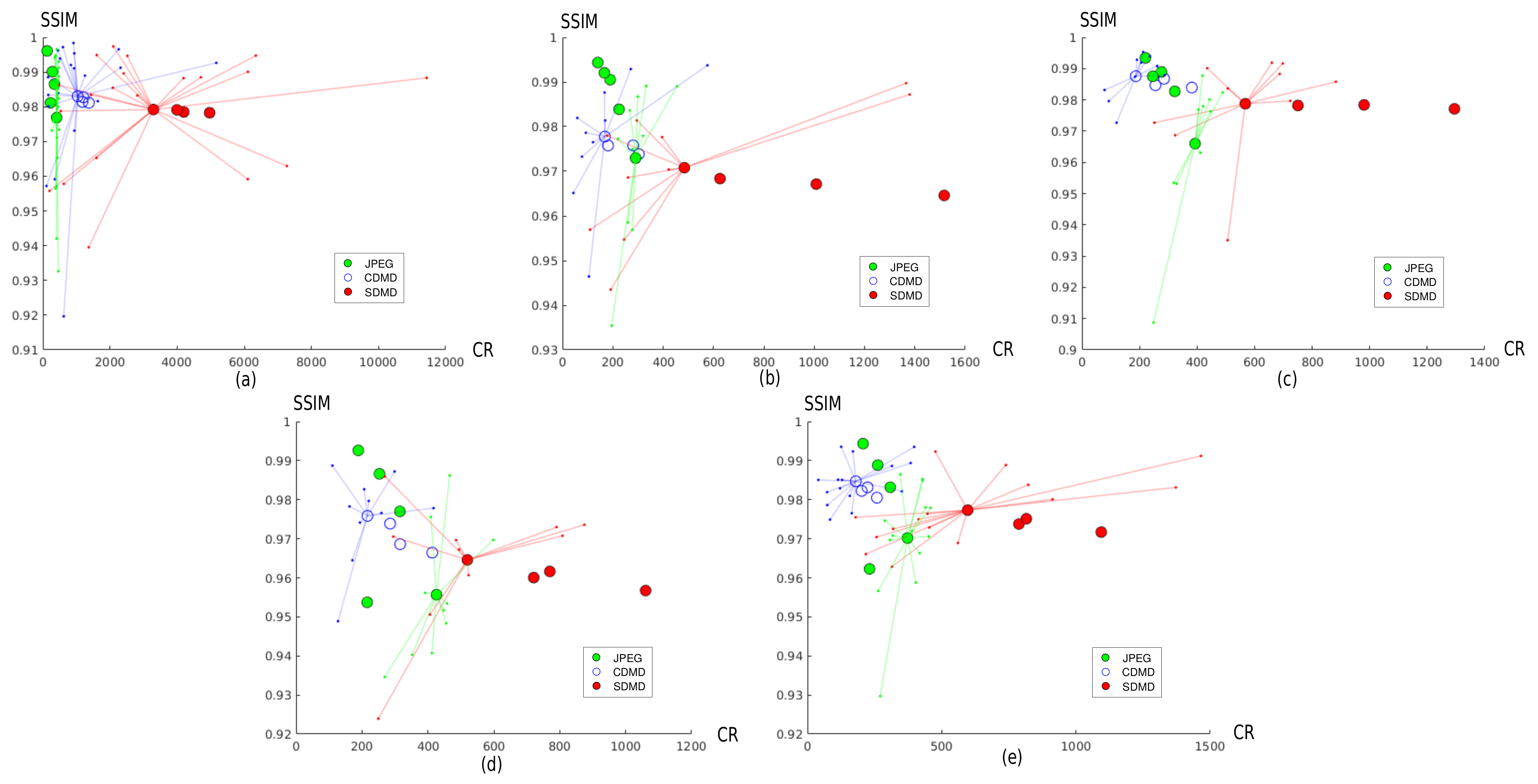
4.4. Comparison with CDMD and JPEG
4.4.1. Comparison with the Original CDMD Method
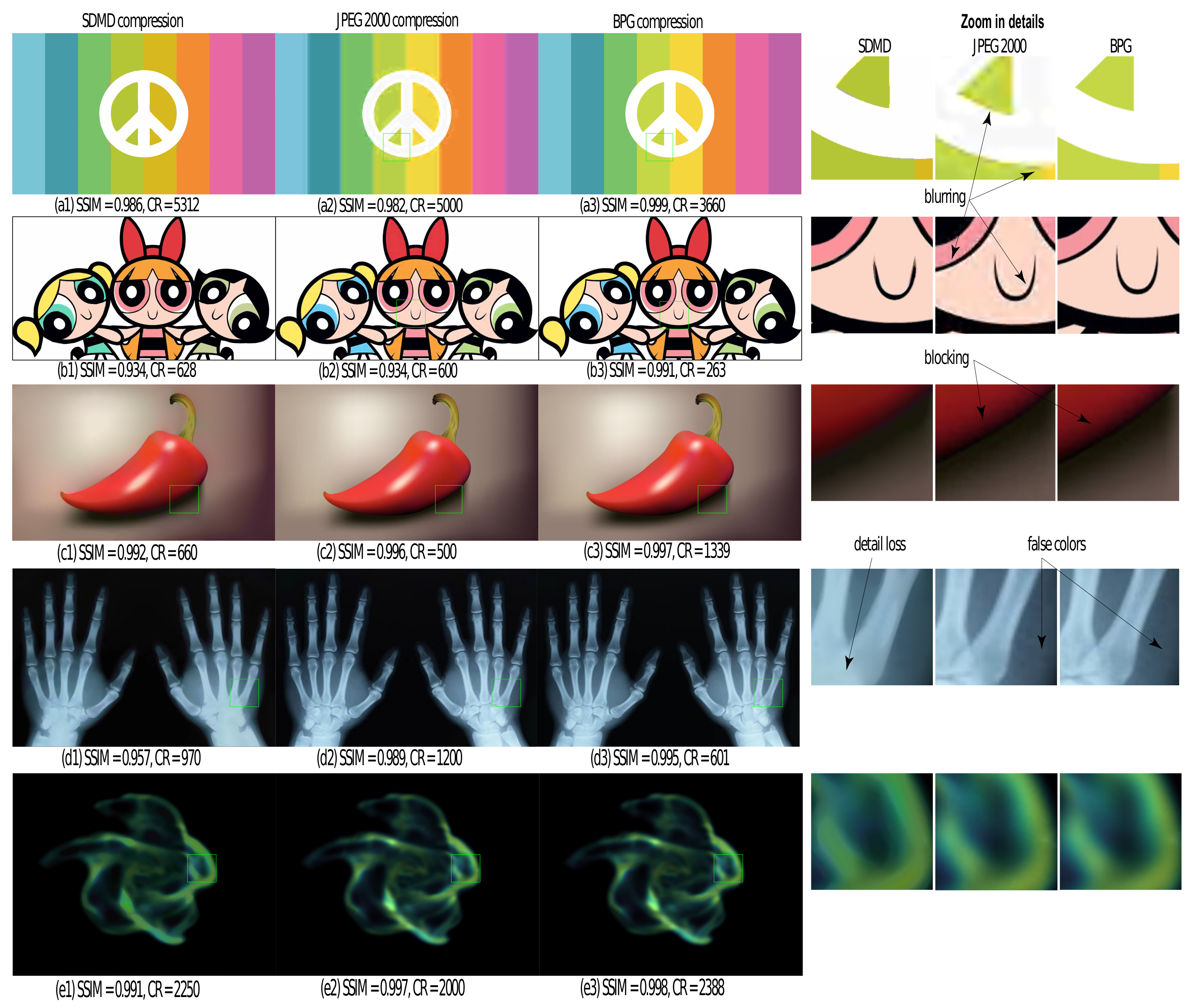
4.4.2. Comparison with JPEG
4.4.3. Additional Comparisons
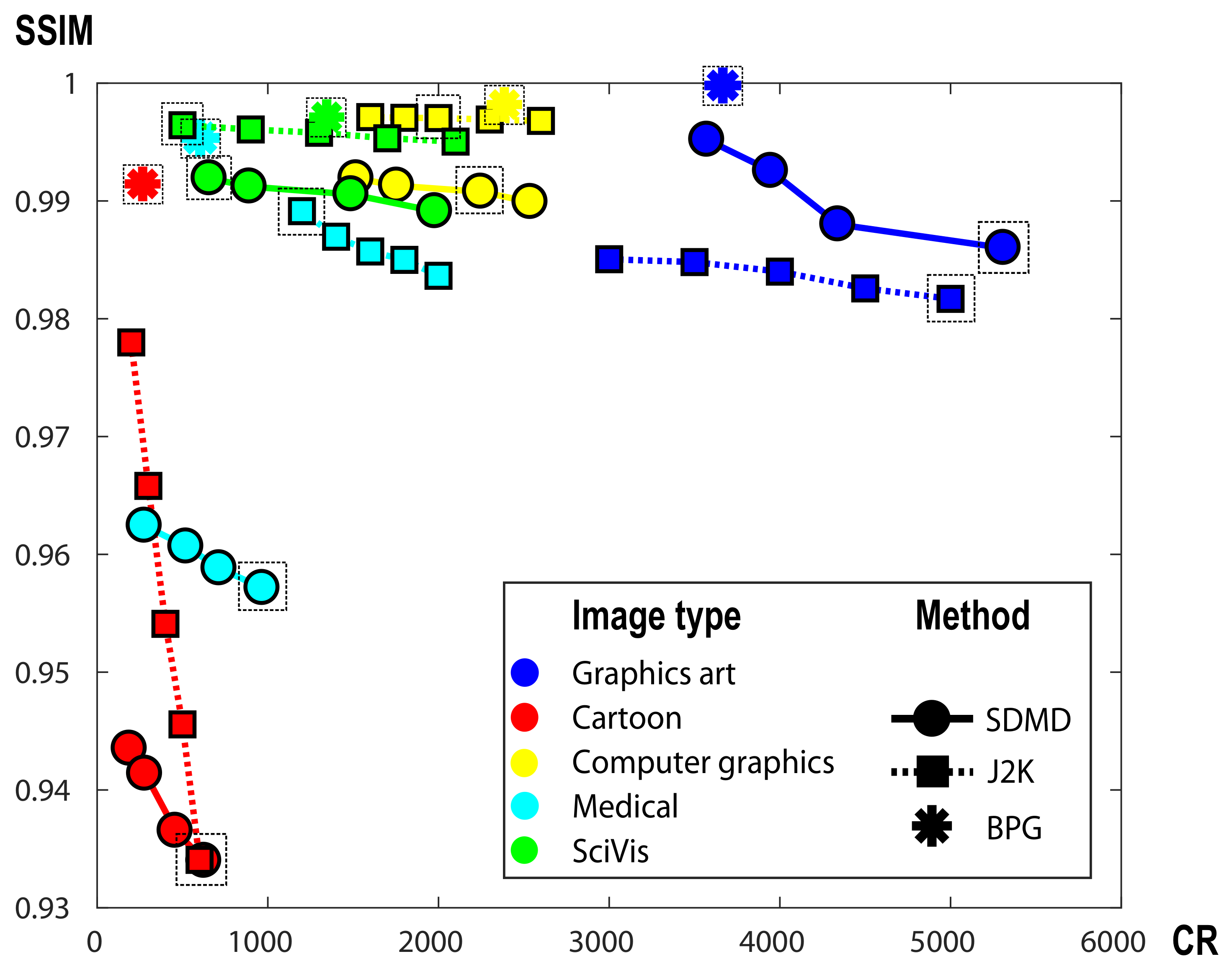
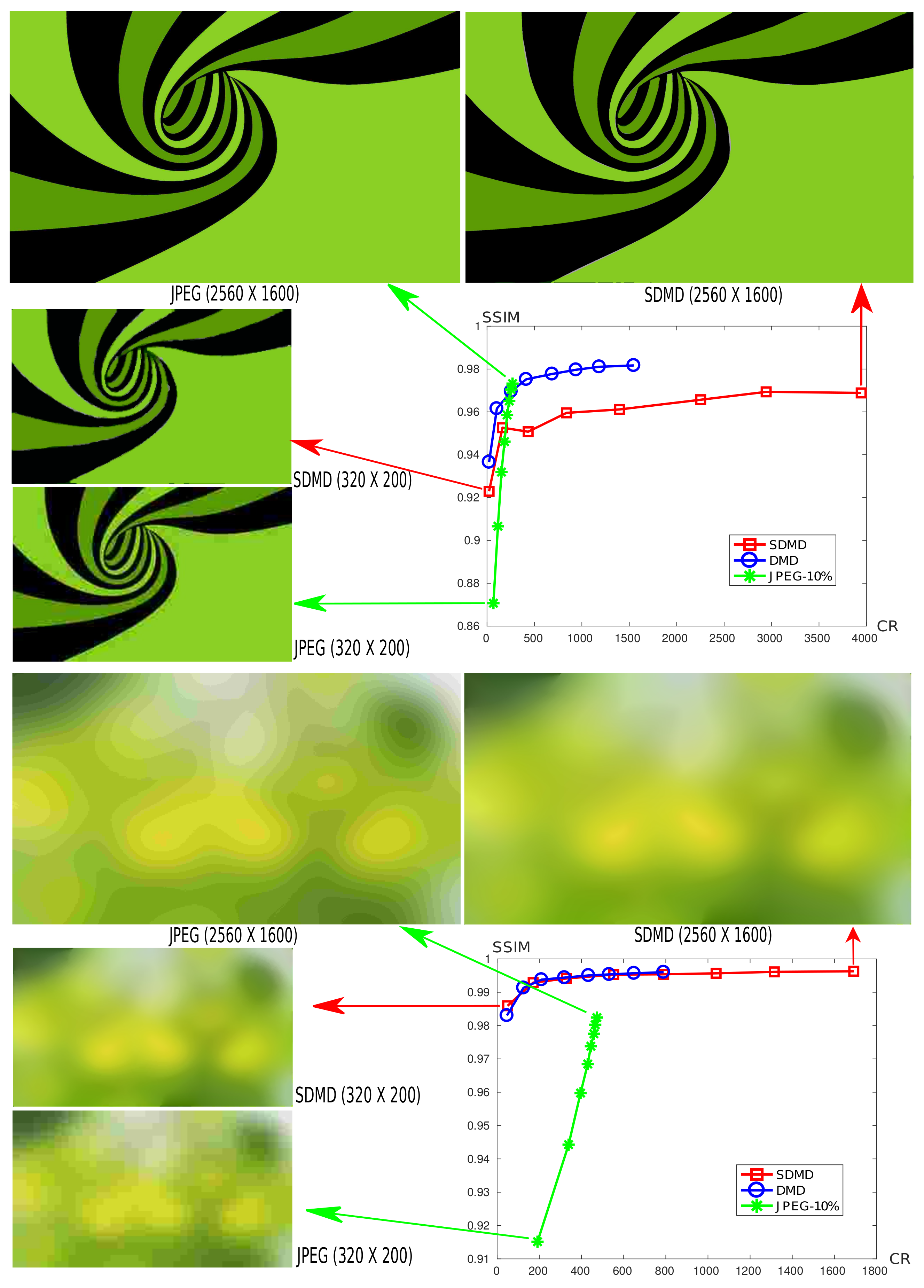
4.5. SDMD Performance on Images of Different Resolutions
5. Applications
5.1. Super-Resolution Images
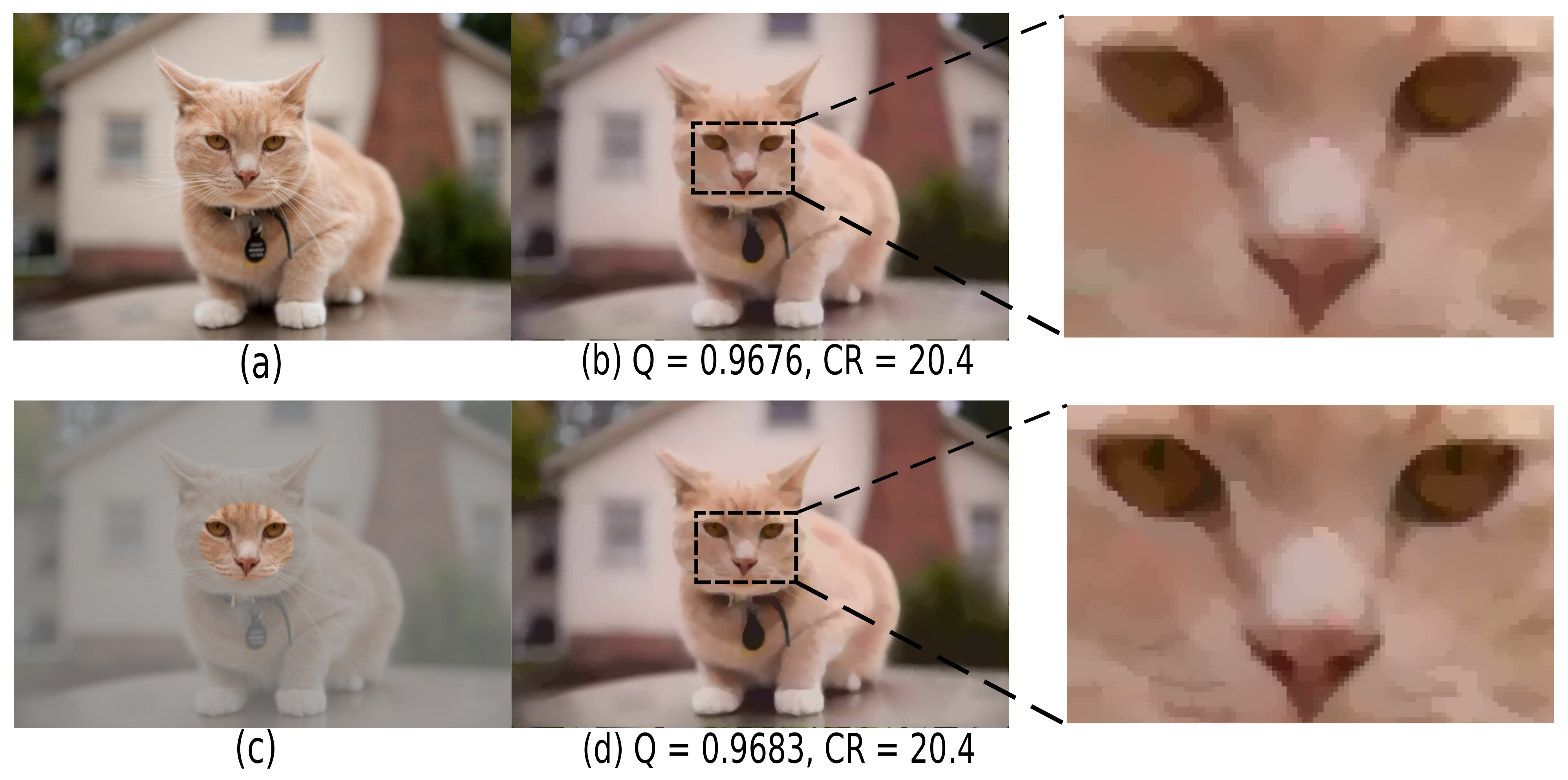
5.2. Salient Detail Encoding
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zwan, M.V.D.; Meiburg, Y.; Telea, A. A dense medial descriptor for image analysis. In Proceedings of the International Conference on Computer Vision Theory and Applications, Barcelona, Spain, 21–24 February 2013; pp. 285–293. [Google Scholar]
- Davies, E. Machine Vision: Theory, Algorithms, Practicalities; Academic Press: Cambridge, MA, USA, 2004. [Google Scholar]
- Wang, J.; Terpstra, M.; Kosinka, J.; Telea, A. Quantitative evaluation of dense skeletons for image compression. Information 2020, 11, 274. [Google Scholar] [CrossRef]
- Wang, J.; Kosinka, J.; Telea, A. Spline-based medial axis transform representation of binary images. Comput. Graph. 2021, 98, 165–176. [Google Scholar] [CrossRef]
- Fabbri, R.; Costa, L.D.F.; Torelli, J.C.; Bruno, O.M. 2D Euclidean distance transform algorithms: A comparative survey. ACM Comput. Surv. 2008, 40, 1–44. [Google Scholar] [CrossRef]
- Pizer, S.; Siddiqi, K.; Székely, G.; Damon, J.; Zucker, S. Multiscale medial loci and their properties. Int. J. Comput. Vis. 2003, 55, 155–179. [Google Scholar] [CrossRef]
- Siddiqi, K.; Pizer, S. Medial Representations: Mathematics, Algorithms and Applications, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Saha, P.K.; Borgefors, G.; Sanniti di Baja, G. A survey on skeletonization algorithms and their applications. Pattern Recognit. Lett. 2016, 76, 3–12. [Google Scholar] [CrossRef]
- Lam, L.; Lee, S.; Suen, C.Y. Thinning methodologies-a comprehensive survey. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 869–885. [Google Scholar] [CrossRef] [Green Version]
- Ogniewicz, R.; Kübler, O. Hierarchic Voronoi skeletons. Pattern Recognit. 1995, 28, 343–359. [Google Scholar] [CrossRef]
- Kimmel, R.; Shaked, D.; Kiryati, N.; Bruckstein, A.M. Skeletonization via distance maps and level sets. Comput. Vis. Image Underst. 1995, 62, 382–391. [Google Scholar] [CrossRef]
- Cao, T.T.; Tang, K.; Mohamed, A.; Tan, T.S. Parallel banding algorithm to compute exact distance transform with the GPU. In Proceedings of the ACM SIGGRAPH Symposium on Interactive 3D Graphics and Games, Washington, DC, USA, 19–21 February 2010; pp. 83–90. [Google Scholar]
- Meijster, A.; Roerdink, J.; Hesselink, W.A. A general algorithm for computing distance transforms in linear time. In Mathematical Morphology and its Applications to Image and Signal Processing; Springer: Berlin/Heidelberg, Germany, 2002; pp. 331–340. [Google Scholar]
- Hesselink, W.H.; Roerdink, J.B.T.M. Euclidean skeletons of digital image and volume data in linear time by the integer medial axis transform. IEEE TPAMI 2008, 30, 2204–2217. [Google Scholar] [CrossRef] [Green Version]
- Telea, A. Feature preserving smoothing of shapes using saliency skeletons. In Visualization in Medicine and Life Sciences II; Springer: Berlin/Heidelberg, Germany, 2012; pp. 153–170. [Google Scholar]
- Telea, A.; van Wijk, J. An augmented fast marching method for computing skeletons and centerlines. In Proceedings of the Symposium on Data Visualization, Eurographics, Barcelona, Spain, 27–29 May 2002; pp. 251–259. [Google Scholar]
- Yushkevich, P.; Thomas Fletcher, P.; Joshi, S.; Thall, A.; Pizer, S.M. Continuous medial representations for geometric object modeling in 2D and 3D. Image Vis. Comput. 2003, 21, 17–27. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Y.; Sun, F.; Choi, Y.K.; Jüttler, B.; Wang, W. Computing a compact spline representation of the medial axis transform of a 2D shape. Graph. Models 2014, 76, 252–262. [Google Scholar] [CrossRef] [Green Version]
- Attali, D.; Montanvert, A. Computing and simplifying 2D and 3D continuous skeletons. Comput. Vis. Image Underst. 1997, 67, 261–273. [Google Scholar] [CrossRef]
- Eberly, D. Least-Squares Fitting of Data with B-Spline Curves. 2014. Geometric Tools. Available online: www.geometrictools.com/Documentation/BSplineCurveLeastSquaresFit.pdf (accessed on 20 May 2020).
- Piegl, L.; Tiller, W. The NURBS Book, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 1997. [Google Scholar]
- Wallace, G.K. The JPEG still picture compression standard. IEEE TCE 1992, 38, xviii–xxxiv. [Google Scholar] [CrossRef]
- Taubman, D.S.; Marcellin, M.W. JPEG 2000: Image Compression Fundamentals, Standards and Practice; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Siddeq, M.M.; Al-Khafaji, G. Applied minimized matrix size algorithm on the transformed images by DCT and DWT used for image compression. Int. J. Comput. Appl. 2013, 70. [Google Scholar]
- Sun, C.; Yang, E.H. An efficient DCT-based image compression system based on Laplacian transparent composite model. IEEE Trans. Image Process. 2015, 24, 886–900. [Google Scholar] [PubMed]
- Toderici, G.; O’Malley, S.M.; Hwang, S.J.; Vincent, D.; Minnen, D.; Baluja, S.; Covell, M.; Sukthankar, R. Variable rate image compression with recurrent neural networks. arXiv 2016, arXiv:1511.06085. [Google Scholar]
- Toderici, G.; Vincent, D.; Johnston, N.; Hwang, S.J.; Minnen, D.; Shor, J.; Covell, M. Full resolution image compression with recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5435–5443. [Google Scholar]
- Johnston, N.; Vincent, D.; Minnen, D.; Covell, M.; Singh, S.; Chinen, T.; Jin Hwang, S.; Shor, J.; Toderici, G. Improved lossy image compression with priming and spatially adaptive bit rates for recurrent networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4385–4393. [Google Scholar]
- Choi, Y.; El-Khamy, M.; Lee, J. Variable rate deep image compression with a conditional autoencoder. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3146–3154. [Google Scholar]
- Theis, L.; Shi, W.; Cunningham, A.; Huszár, F. Lossy image compression with compressive autoencoders. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Agustsson, E.; Tschannen, M.; Mentzer, F.; Timofte, R.; Van Gool, L. Generative adversarial networks for extreme learned image compression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 221–231. [Google Scholar]
- Mentzer, F.; Toderici, G.D.; Tschannen, M.; Agustsson, E. High-fidelity generative image compression. arXiv 2020, arXiv:2006.09965. [Google Scholar]
- Van Wijk, J.; Van de Wetering, H. Cushion treemaps: Visualization of hierarchical information. In Proceedings of the 1999 IEEE Symposium on Information Visualization (InfoVis’ 99), San Francisco, CA, USA, 24–29 October 1999; pp. 73–78. [Google Scholar]
- Silva, D.J.; Alves, W.A.L.; Morimitsu, A.; Hashimoto, R.F. Efficient incremental computation of attributes based on locally countable patterns in component trees. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3738–3742. [Google Scholar]
- Wang., J.; Joao., L.; Falcão., A.; Kosinka., J.; Telea., A. Focus-and-context skeleton-based image simplification using saliency maps. In Proceedings of the 16th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Vienna, Austria, 8–10 February 2021; Volume 4, pp. 45–55. [Google Scholar]
- Podpora, M. Yuv vs. RGB–A comparison of lossy compressions for human-oriented man-machine interfaces. Zesz. Nauk. Elektr. 2009, 55–56. [Google Scholar]
- Podpora, M.; Korbaś, G.; Kawala-Janik, A. YUV vs. RGB—Choosing a color space for human-machine interaction. Ann. Comput. Sci. Inf. Syst. 2014, 3. [Google Scholar]
- Nobuhara, H.; Hirota, K. Color image compression/reconstruction by YUV fuzzy wavelets. In Proceedings of the IEEE Annual Meeting of the Fuzzy Information, Banff, AB, Canada, 27–30 June 2004; Volume 2, pp. 774–779. [Google Scholar]
- Lambrecht, C.J.V.d.B. Vision Models and Applications to Image and Video Processing; Kluwer Academic Publishers: London, UK, 2001; p. 209. [Google Scholar]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image quality assessment: From error visibility to structural similarity. IEEE TIP 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Wang, J. SDMD Supplementary Material. 2021. Available online: https://github.com/WangJieying/SDMD-resources (accessed on 21 June 2021).
- Orzan, A.; Bousseau, A.; Barla, P.; Winnemöller, H.; Thollot, J.; Salesin, D. Diffusion curves: A vector representation for smooth-shaded images. Commun. ACM 2013, 56, 101–108. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Ballard, F. Better Portable Graphics. 2018. Available online: https://bellard.org/bpg (accessed on 15 August 2021).
- Thyssen, A. ImageMagick v6 Examples—Resize or Scaling. 2012. Available online: https://legacy.imagemagick.org/Usage/resize/ (accessed on 20 May 2021).
- Robert, V.; Talbot, H. Does super-resolution improve ocr performance in the real world? A case study on images of receipts. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 548–552. [Google Scholar]
- Wang, X.; Yu, K.; Wu, S.; Gu, J.; Liu, Y.; Dong, C.; Qiao, Y.; Loy, C.C. ESRGAN: Enhanced super-resolution generative adversarial networks. In Proceedings of the Computer Vision—ECCV 2018 Workshops, Munich, Germany, 8–14 September 2018; pp. 63–79. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Köhler, T.; Bätz, M.; Naderi, F.; Kaup, A.; Maier, A.; Riess, C. Toward bridging the simulated-to-real gap: Benchmarking super-resolution on real data. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2944–2959. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Maalouf, A.; Larabi, M.C. Colour image super-resolution using geometric grouplets. IET Image Process. 2012, 6, 168–180. [Google Scholar] [CrossRef]
- Borji, A.; Cheng, M.; Jiang, H.; Li, J. Salient object detection: A benchmark. IEEE TIP 2015, 24, 5706–5722. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, J.; Fang, S.; Ehinger, K.A.; Wei, H.; Yang, W.; Zhang, K.; Yang, J. Hypergraph optimization for salient region detection based on foreground and background queries. IEEE Access 2018, 6, 26729–26741. [Google Scholar] [CrossRef]
- Peng, H.; Li, B.; Ling, H.; Hu, W.; Xiong, W.; Maybank, S.J. Salient object detection via structured matrix decomposition. IEEE TPAMI 2016, 39, 818–832. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Lu, H.; Zhang, L.; Ruan, X.; Yang, M. Saliency detection via dense and sparse reconstruction. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2976–2983. [Google Scholar]
- Telea, A. CUDASkel: Real-Time Computation of Exact Euclidean Multiscale Skeletons on CUDA. 2019. Available online: webspace.science.uu.nl/~telea001/Shapes/CUDASkel (accessed on 21 June 2020).





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Description | Quantity |
|---|---|---|
| SciVis data | Scientific visualizations (scalar and vector fields) | 15 |
| Medical images | Images generated by CT, X-ray and MRI scans | 10 |
| Computer graphics | Images generated by rendering and vectorization | 10 |
| Graphics art images | Simple shapes such as clip art, logos, and graphics design | 20 |
| Cartoon images | Animated cartoons and comic strips | 10 |
| Type | SDMD + ALE | SDMD + ALE + PCE |
|---|---|---|
| (a1) Graphics art images | 0.0002↓ / 29%↑ | 0.0010↓ / 74%↑ |
| (a2) Cartoon images | 0.0006↓ / 38%↑ | 0.0007↓ / 128%↑ |
| (a3) Computer graphics | 0.0015↓ / 7%↑ | 0.0019↓ / 45%↑ |
| (a4) Medical images | 0.0025↓ / 7%↑ | 0.0032↓ / 18%↑ |
| (a5) SciVis data | 0.0024↓ / 9%↑ | 0.0032↓ / 79%↑ |
| Operation | 320 × 200 | 640 × 400 | 960 × 600 | 1280 × 800 | 1600 × 1000 | 1920 × 1200 | 2240 × 1400 | 2560 × 2000 |
|---|---|---|---|---|---|---|---|---|
| Skeletonization | 48 | 182 | 294 | 729 | 1119 | 1559 | 3501 | 4168 |
| Spline fitting | 1648 | 1236 | 2136 | 2098 | 2812 | 3849 | 4650 | 5592 |
| Reconstruction | 62 | 118 | 292 | 561 | 951 | 1583 | 2502 | 3618 |
| Interpolation | 28 | 260 | 345 | 1004 | 1479 | 2105 | 3904 | 4960 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Kosinka, J.; Telea, A. Spline-Based Dense Medial Descriptors for Lossy Image Compression. J. Imaging 2021, 7, 153. https://doi.org/10.3390/jimaging7080153
Wang J, Kosinka J, Telea A. Spline-Based Dense Medial Descriptors for Lossy Image Compression. Journal of Imaging. 2021; 7(8):153. https://doi.org/10.3390/jimaging7080153
Chicago/Turabian StyleWang, Jieying, Jiří Kosinka, and Alexandru Telea. 2021. "Spline-Based Dense Medial Descriptors for Lossy Image Compression" Journal of Imaging 7, no. 8: 153. https://doi.org/10.3390/jimaging7080153
APA StyleWang, J., Kosinka, J., & Telea, A. (2021). Spline-Based Dense Medial Descriptors for Lossy Image Compression. Journal of Imaging, 7(8), 153. https://doi.org/10.3390/jimaging7080153