
Mobile-Based 3D Modeling: An In-Depth Evaluation for the Application in Indoor Scenarios


Abstract
:1. Introduction
2. Related Work
3. Motivation and Contributions
- We provide additional benchmarks for the network proposed by Bian et al. in order to allow a better understanding of the network generalization performances.
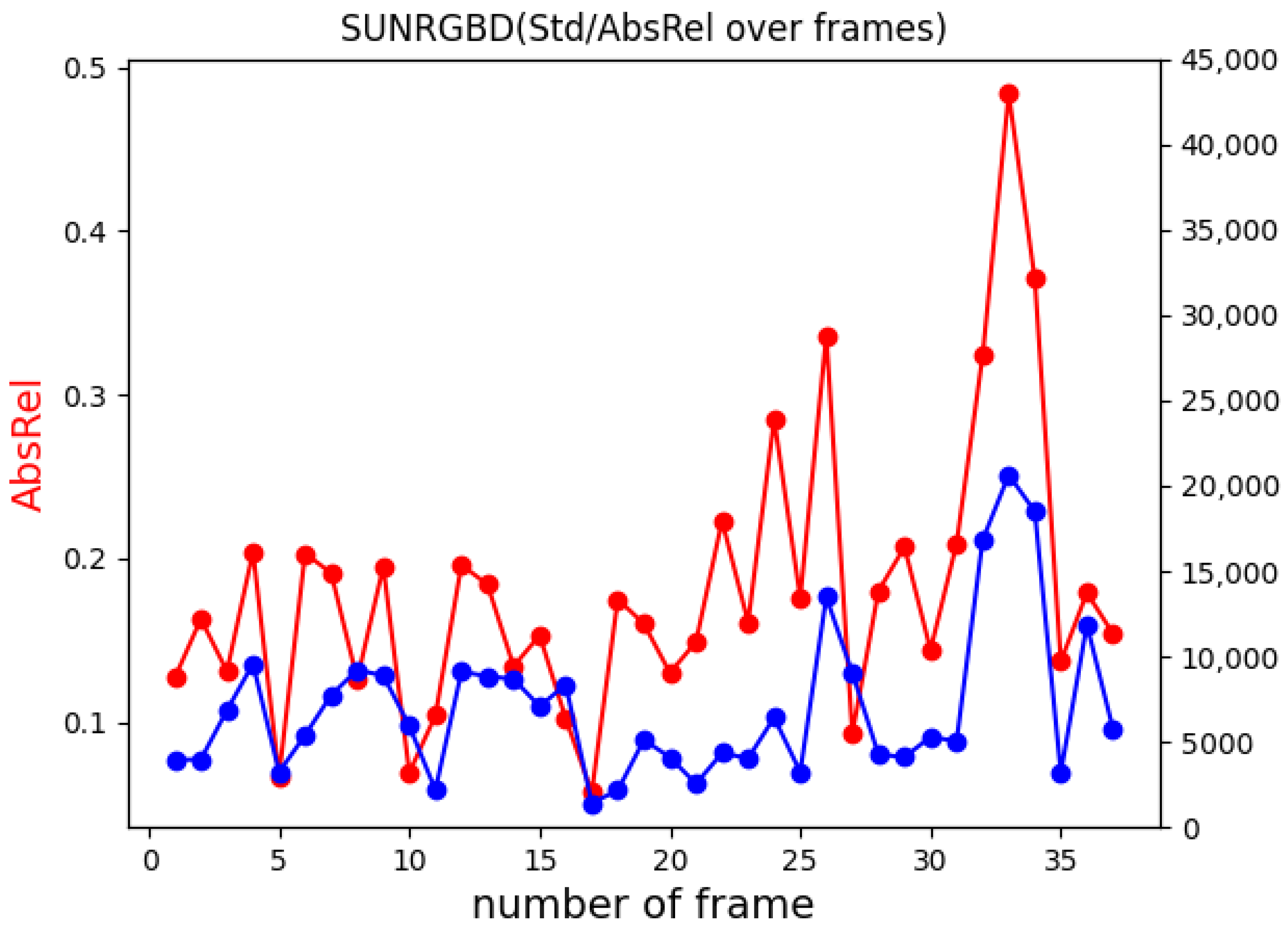
- We analyzed the network generalization capability in connection with the statistics of the scene, from which the depth was estimated. We computed the standard deviation of depth from depth ground truth to describe the amount of depth information that the network has to estimate, and then discuss how the generalization is related to this parameter.
4. Materials and Methods
Datasets
- RGB-D TUM Dataset: The sequence freiburg1_360 contains a 360 degree acquisition in a typical office environment; the freiburg_pioneer sequence shows a quite open indoor environment captured by a robot with depth sensor attached on top of it (Figure 4). The dataset is provided with depth ground truth acquired by the Kinect sensor, and camera pose ground truth as rotation and translation were acquired with an external motion capture system, which is typically used for SLAM systems. For additional details we refer the reader to the dataset website [36] and to the original paper [33]. Among the available sequences we decided to choose two of them (freiburg1_360 and freiburg_pioneer), since they represent distinct environments with interesting characteristics useful for testing the generalization of the network. In particular, in freiburg_360 there are many complex geometries due to the office furniture; freiburg_pioneer is instead characterized by wide spaces, usually implying more homogeneous depth maps but larger depth range.
- RGB-D Microsoft Dataset: This dataset [29,37] consists of sequences of tracked RGB-D frames of various indoor environments, and it is provided with the corresponding depth ground truth (Figure 5). This dataset is the one used by the authors in [26] to test the generalization capability of the network. Accordingly, we decided to re-run the tests as well, to ensure the replicability of the paper’s results.
- Washington RGB-D Object Dataset: The dataset [34] was created with the purpose of providing structure data of real objects. Aside from the isolated objects, the dataset provides 22 annotated sequences of various indoor environment with depth ground truth. Additionally, in this case, RGB-D data were collected using Micorsoft Kinect using aligned 640 × 480 RGB and depth images (Figure 6).
- SUN RGB-D Dataset: The dataset [35] is a collection of several common indoor environments from different datasets; it contains RGB-D images from NYUv2 [28], Berkeley B3DO [38] and SUN3D [39]. The dataset has in total 10,335 RGB-D images. In order to make the experiments comparable, we have selected only the samples acquired using Kinect (Figure 7).
5. Results
6. Conclusions
7. Future Works
- The adoption of other SoA architectures for richer comparisons;
- The adoption of a novel metric that considers the standard deviation of depth for performance evaluations and the training stage;
- The extension of the study to additional datasets, for which the ground truth has been collected with more up-to-date and accurate depth sensors.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| SoA | State-of-the-art |
| SfM | Structure from motion |
| SIFT | Scale invariant feature transform |
| BA | Bundle adjustment |
| CNN | Convolutional neural network |
| DispNet | Disparity network |
| RGB | Red, green, blue |
| RGB-D | Red, green, blue and depth |
| GT | Ground truth |
| AbsRel | Absolute relative error |
| StdDev | Standard deviation |
References
- Fazakas, T.; Fekete, R.T. 3D reconstruction system for autonomous robot navigation. In Proceedings of the 2010 11th International Symposium on Computational Intelligence and Informatics (CINTI), Budapest, Hungary, 18–20 November 2010. [Google Scholar]
- Gupta, S.K.; Shukla, D.P. Application of drone for landslide mapping, dimension estimation and its 3D reconstruction. J. Indian Soc. Remote Sens. 2018, 46, 903–914. [Google Scholar] [CrossRef]
- Alexiadis, D.S.; Zarpalas, D.; Daras, P. Real-time, realistic, full 3-D reconstruction of moving humans from multiple Kinect streams. IEEE Trans. Multimed. 2013, 15, 339–358. [Google Scholar] [CrossRef]
- Wu, C. Towards linear-time incremental structure from motion. In Proceedings of the 2013 International Conference on 3D Vision-3DV 2013, Seattle, WA, USA, 29 June–1 July 2013. [Google Scholar]
- Wu, C. VisualSFM: A Visual Structure from Motion System. Available online: http://ccwu.me/vsfm/ (accessed on 3 May 2021).
- Xie, J.; Ross, G.; Ali, F. Deep3d: Fully automatic 2d-to-3d video conversion with deep convolutional neural networks. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Vijayanarasimhan, S.; Ricco, S.; Schmid, C.; Sukthankar, R.; Fragkiadaki, K. Sfm-net: Learning of structure and motion from video. arXiv 2017, arXiv:1704.07804. [Google Scholar]
- Khilar, R.; Chitrakala, S.; SelvamParvathy, S. 3D image reconstruction: Techniques, applications and challenges. In Proceedings of the 2013 International Conference on Optical Imaging Sensor and Security (ICOSS), Coimbatore, India, 2–3 July 2013. [Google Scholar]
- Hosseinian, S.; Arefi, H. 3D Reconstruction from Multi-View Medical X-ray images–review and evaluation of existing methods. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, XL-1-W5, 319–326. [Google Scholar] [CrossRef] [Green Version]
- Bresnan, J.; Mchombo, S.A. The lexical integrity principle: Evidence from Bantu. Nat. Lang. Linguist. Theory 1995, 13, 181–254. [Google Scholar] [CrossRef]
- Szeliski, R. Computer Vision: Algorithms and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Corfu, Greece, 20–25 September 1999; Volume 2. [Google Scholar]
- Mayer, N.; Ilg, E.; Hausser, P.; Fischer, P.; Cremers, D.; Dosovitskiy, A.; Brox, T. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Flynn, J.; Snavely, K.; Neulander, I.; Philbin, J. Deepstereo: Learning to Predict New Views from Real World Imagery. U.S. Patent No. 9,916,679, 13 March 2018. [Google Scholar]
- Garg, R.; Vijay Kumar, B.G.; Gustavo, C.; Ian, R. Unsupervised cnn for single view depth estimation: Geometry to the rescue. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Agrawal, P.; Joao, C.; Jitendra, M. Learning to see by moving. In Proceedings of the IEEE International Conference on Computer Vision, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Jayaraman, D.; Kristen, G. Learning image representations equivariant to ego-motion. In Proceedings of the 2015 International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015. [Google Scholar]
- Goroshin, R.; Bruna, J.; Tompson, J. Unsupervised learning of spatiotemporally coherent metrics. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Misra, I.; Zitnick, C.L.; Hebert, M. Shuffle and learn: Unsupervised learning using temporal order verification. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Pathak, D.; Girshick, R.; Dollar, P.; Darrell, T.; Hariharan, B. Learning features by watching objects move. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, X.; Gupta, A. Unsupervised learning of visual representations using videos. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised learning of depth and ego-motion from video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
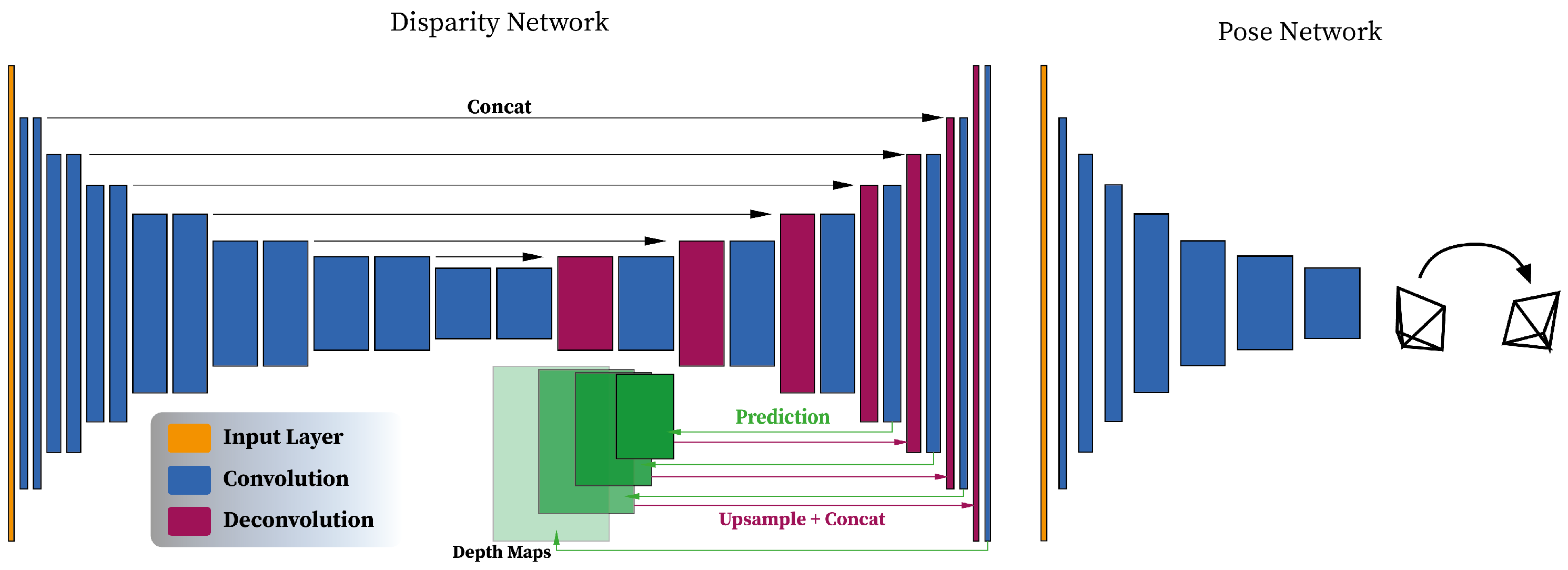
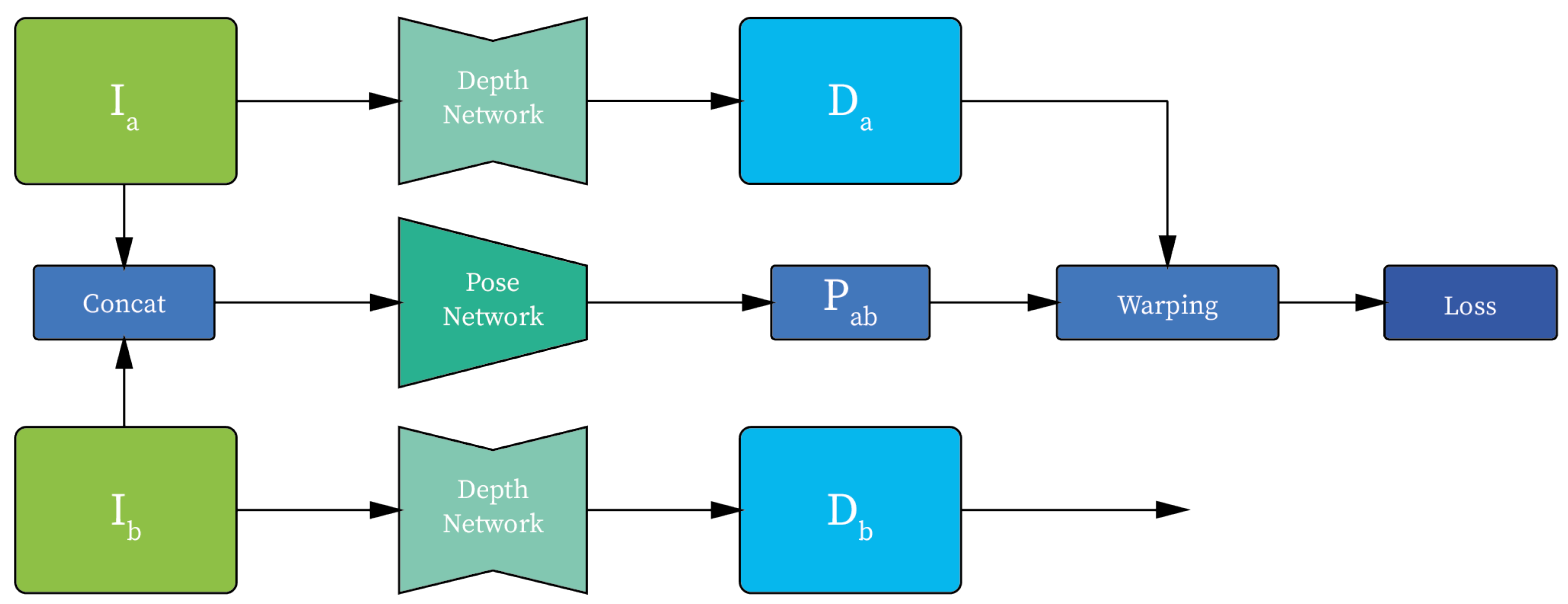
- Bian, J.-W.; Li, Z.; Wang, N.; Zhan, H.; Shen, C.; Cheng, M.; Reid, I. Unsupervised scale-consistent depth and ego-motion learning from monocular video. arXiv 2019, arXiv:1908.10553. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Cordts, M.; Omran, M.; Ramos, S. The cityscapes dataset. In Proceedings of the CVPR Workshop on the Future of Datasets in Vision, Boston, MA, USA, 11 June 2015; Volume 2. [Google Scholar]
- Bian, J.-W.; Zhan, H.; Wang, N.; Chin, T.-J.; Shen, C.; Reid, I. Unsupervised depth learning in challenging indoor video: Weak rectification to rescue. arXiv 2020, arXiv:2006.02708. [Google Scholar]
- NYU Depth Datadet Version 2. Available online: https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html (accessed on 5 May 2021).
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from rgbd images. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Glocker, B.; Izadi, S.; Shotton, J.; Criminisi, A. Real-time RGB-D camera relocalization. In Proceedings of the 2013 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Adelaide, SA, Australia, 1–4 October 2013. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016. [Google Scholar]
- Bian, J. Unsupervised-Indoor-Depth. Available online: https://github.com/JiawangBian/Unsupervised-Indoor-Depth (accessed on 3 May 2021).
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012. [Google Scholar]
- Lai, K.; Bo, L.; Ren, X.; Fox, D. A large-scale hierarchical multi-view rgb-d object dataset. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011. [Google Scholar]
- Shuran, S.; Lichtenberg, S.P.; Xiao, J. Sun rgb-d: A rgb-d scene understanding benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Computer Vision Group TUM Department of Informatics Technical University of Munich, RGB-D SLAM Dataset. Available online: https://vision.in.tum.de/data/datasets/rgbd-dataset/download (accessed on 5 May 2021).
- RGB-D Dataset 7-Scene. Available online: https://www.microsoft.com/en-us/research/project/rgb-d-dataset-7-scenes/ (accessed on 30 April 2021).
- Janoch, A.; Karayev, S.; Jia, Y.; Barron, J.T.; Fritz, M.; Saenko, K.; Darrell, T. A category-level 3d object dataset: Putting the kinect to work. In Consumer Depth Cameras for Computer Vision; Springer: London, UK, 2013; pp. 141–165. [Google Scholar]
- Xiao, J.; Andrew, O.; Antonio, T. Sun3d: A database of big spaces reconstructed using sfm and object labels. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Wasenmüller, O.; Didier, S. Comparison of kinect v1 and v2 depth images in terms of accuracy and precision. In Asian Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Godard, C.; Aodha, O.M.; Firman, M.; Brostow, G.J. Digging into self-supervised monocular depth estimation. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 3828–3838. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Method | Indoor | Dataset | Note |
|---|---|---|---|---|
| [7] | SfM Net | ✗ | KITTI [24] & Cityscapes [25] | O |
| [22] | SfM Learner | ✗ | KITTI [24] & Cityscapes [25] | O |
| [23] | SC-SfM Learner | ✗ | KITTI [24] & Cityscapes [25] | O |
| [26] | Indoor SC-SfM Learner | ✓ | NYUv2 [27,28] | R |
| Name | #Images | Img. Size | Ref. |
|---|---|---|---|
| 7Scene | 29,000 | 640 × 480 | [29] |
| freiburg_360 (TUM RGB-D) | 756 | 640 × 480 | [33] |
| freiburg_pioneer (TUM RGB-D) | 1225 | 640 × 480 | [33] |
| Washington | 11,440 | 640 × 480 | [34] |
| SUN | 10,335 | 640 × 480 | [35] |
| Scenes | AbsRel | StdDev () |
|---|---|---|
| Chess (7Scene) [29] | 0.19 | 5800.00 |
| Fire (7Scene) [29] | 0.15 | 4418.00 |
| Office (7Scene) [29] | 0.16 | 4438.00 |
| Pumpkin (7Scene) [29] | 0.13 | 3435.00 |
| RedKitchen (7Scene) [29] | 0.20 | 5700.00 |
| Stairs (7Scene) [29] | 0.17 | 5341.00 |
| freiburg_360 (TUM RGB-D) [33] | 0.16 | 5056.86 |
| freiburg_pioneer (TUM RGB-D) [33] | 0.28 | 11,370.31 |
| Washington [34] | 0.3 | 9656.00 |
| B3DO (SUN RGB-D) [35] | 0.18 | 6886.21 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
De Pellegrini, M.; Orlandi, L.; Sevegnani, D.; Conci, N. Mobile-Based 3D Modeling: An In-Depth Evaluation for the Application in Indoor Scenarios. J. Imaging 2021, 7, 167. https://doi.org/10.3390/jimaging7090167
De Pellegrini M, Orlandi L, Sevegnani D, Conci N. Mobile-Based 3D Modeling: An In-Depth Evaluation for the Application in Indoor Scenarios. Journal of Imaging. 2021; 7(9):167. https://doi.org/10.3390/jimaging7090167
Chicago/Turabian StyleDe Pellegrini, Martin, Lorenzo Orlandi, Daniele Sevegnani, and Nicola Conci. 2021. "Mobile-Based 3D Modeling: An In-Depth Evaluation for the Application in Indoor Scenarios" Journal of Imaging 7, no. 9: 167. https://doi.org/10.3390/jimaging7090167
APA StyleDe Pellegrini, M., Orlandi, L., Sevegnani, D., & Conci, N. (2021). Mobile-Based 3D Modeling: An In-Depth Evaluation for the Application in Indoor Scenarios. Journal of Imaging, 7(9), 167. https://doi.org/10.3390/jimaging7090167