1. Introduction
The last few decades have seen considerable growth in the use of image processing techniques to solve various problems in agriculture and the life sciences because of their wide variety of applications [
1]. This growth is mainly due to the fact that computer vision techniques have been combined with deep learning techniques. The latter has offered promising results in various application fields, such as haematology [
2], biology [
3,
4], or botany [
5,
6]. Deep learning algorithms differ from traditional machine learning (ML) methods in that they require little or no preprocessing of images and can infer an optimal representation of data from raw images without the need for prior feature selection, resulting in a more objective and less biased process. Moreover, the ability to investigate the structural details of biological components, such as organisms and their parts, can significantly influence biological research. According to Kamilaris et al. [
7], image analysis is a significant field of research in agriculture for seeds, crops or leaves classification, anomaly or disease detection, and other related activities.
In the agricultural area, the cultivation of crops is based on seeds, mainly for food production. In particular, in this study, we focus on the field of plant science carpology, which examines seeds and fruits from a morphological and structural point of view. It generally has two main challenges: reconstructing the evolution of a particular plant species and recreating what the landscape was and, therefore, what its flora and fauna appeared. Professionals employed in this field typically capture images of seeds using a digital camera or flatbed scanner. Especially the latter provides quality and speed of workflow due to the constant illumination condition and the defined image size [
8,
9,
10,
11,
12]. In this context, the seed image classification can play a fundamental role for manifold reasons, from crops, fruits and vegetables to disease recognition, or even to obtain specific feature information for archaeobotanical reasons, and so forth. One of the most-used tools by biologists is ImageJ [
13,
14,
15]. It is defined as one of the standard types of image analysis software, as it is freely available, platform-independent, and easily applicable for biological researchers to quantify laboratory tests.
A traditional image analysis procedure uses a pipeline of four steps: preprocessing, segmentation, feature extraction, and classification, although deep learning workflows have emerged since the proposal of the convolutional neural network (CNN) AlexNet in 2012 [
16]. CNNs do not follow the typical image analysis workflow because they can extract features independently without the need for feature descriptors or specific feature extraction techniques. In the traditional pipeline, image preprocessing techniques are used to prepare the image before analysing it to eliminate possible distortions or unnecessary data or highlight and enhance distinctive features for further processing. Next, the segmentation step divides the significant regions into sets of pixels with shared characteristics such as colour, intensity, or texture. The purpose of segmentation is to simplify and change the image representation into something more meaningful and easier to analyse. Extracting features from the regions of interest identified by segmentation is the next step. In particular, features can be based on shape, structure or colour [
17,
18]. The last step is classification, assigning a label to the objects using supervised or unsupervised machine learning approaches. Compared to manual analysis, the use of seed image analysis techniques brings several advantages to the process:
- (i)
It speeds up the analysis process;
- (ii)
It minimises distortions created by natural light and microscopes;
- (iii)
It automatically identifies specific features;
- (iv)
It automatically classifies families or genera.
In this work, we address the problem of multiclass classification of seed images from two different perspectives. First, we study possible optimisations of five traditional machine learning classifiers as adopted in our previous work [
6], trained with seven different categories of handcrafted (HC) features extracted from seed images with our proposed ImageJ tool [
19]. Second, we train several well-known convolutional neural networks and a new CNN, namely SeedNet, recently proposed in our previous work [
6], in order to determine whether and to what extent a feature extraction performed from them may be advantageous over handcrafted features for training the same traditional machine learning methods depicted before. In particular,
Table 1 depicts the study, contributions, and tools provided by our previous works and the one presented here.
The overall aim of the work is to propose a comprehensive comparison of seed classification systems, both based on handcrafted and deep features, to produce an accurate and efficient classification of heterogeneous seeds. It is important, for example, to obtain archaeobotanical information of seeds and to effectively recognise their types. More specifically, the classification addressed in this work is fine-grained, oriented to single seeds, rather than sets of seeds, as it is in [
20]. In detail, our contribution is threefold:
- (i)
We exploit handcrafted, a combination of handcrafted, and CNN-extracted features;
- (ii)
We compare the classification results of five different models, trained with HC and CNN-extracted features;
- (iii)
We evaluate the classification results from a multiclass perspective to assess which type of descriptor may be most suitable for this task.
This research aims to classify individual seeds belonging to the same family or species from two different and heterogeneous seed data sets, where differences in colour, shape, and structure can be challenging to detect. We also want to highlight how traditional classification techniques trained with handcrafted features can outperform CNNs in training speed and achieve accuracy close to CNNs in this task.
The rest of the article is organised as follows.
Section 2 presents state of the art in plant science work, with a focus on seed image analysis.
Section 3 presents the data sets used and the classification experiments. The experimental evaluation is discussed in
Section 4, and finally, in
Section 5 we give the conclusions of the work.
4. Results and Discussion
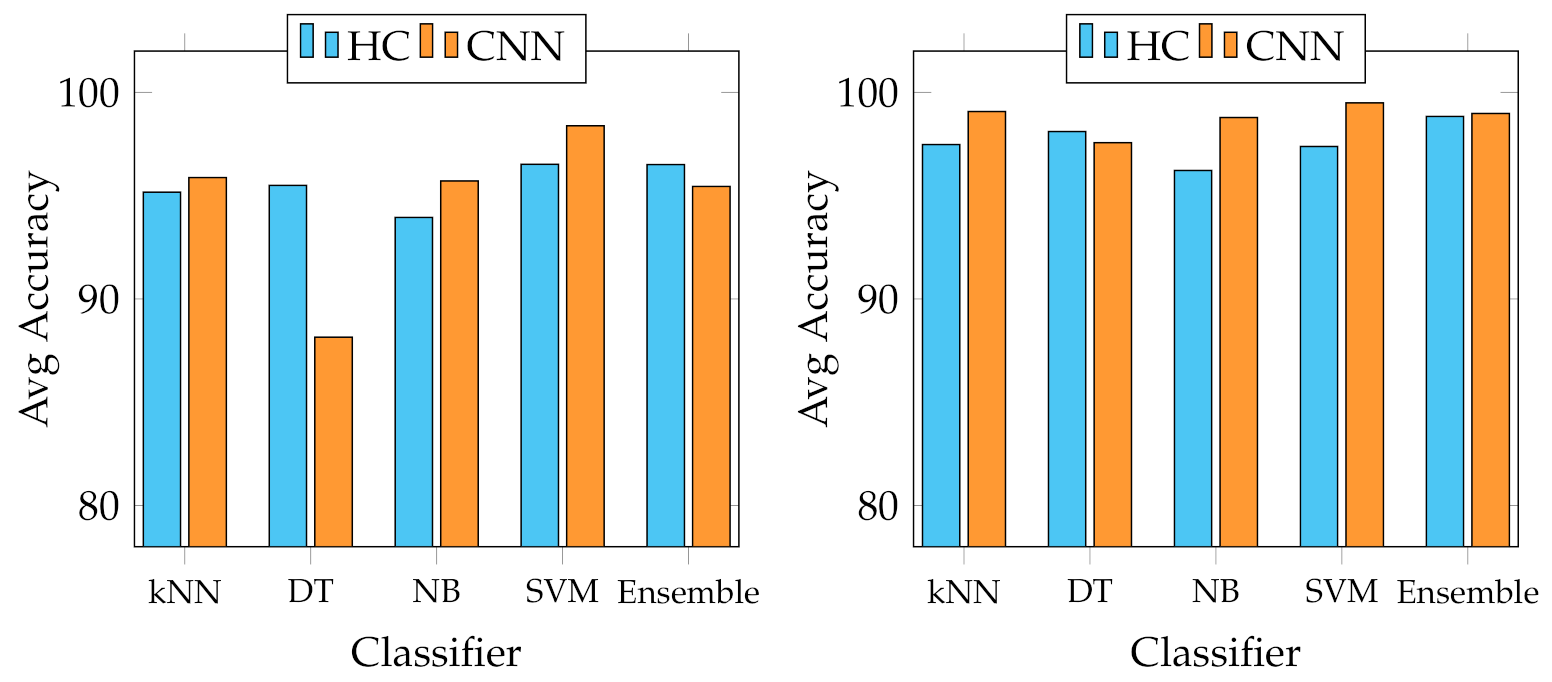
We report several results obtained from the experiments. First of all, four graphs are presented to show the general behaviour of the two sets of descriptors from two points of view. In fact, we report the best and average accuracies for both sets, as shown in
Figure 3 and
Figure 4. It works as a general indicator of the effectiveness of the features used for the task. In addition, we pinpoint their performance in the multiclass scenario. In particular,
Figure 5 and
Figure 6 show the behaviour of the MFM computed for the different classifiers. Secondly, in the
Appendix A, we report
Table A1–
Table A5, in which the individual descriptor categories results obtained with each classifier are detailed.
The graphs in
Figure 3 and
Figure 4 show that each of the employed classifiers can achieve excellent classification accuracy on both data sets. However, from the results of the Canada data set, the Decision Tree classifier seems the least suitable for the task, especially when trained with CNNs descriptors, being the only one below 90% on average in that case. Although the other four strategies can achieve an accuracy above 90% in practically all cases, the Support Vector Machine seems the most appropriate in every experimental condition. It outperforms the others, averaging 98.38% and 99.49% on the Canada and Cagliari data sets, respectively, and a best of 99.58% and 99.73% with the features extracted from SeedNet on the Canada and Cagliari data sets, respectively. In general, and looking only at the accuracy, there seem to be no distinct performance differences in the two categories of descriptors to justify one over the other.
However, the scenario considerably changes when observing the results of the multiclass classification performance that we evaluated using the F-measure computed for all the classes, as indicated in Equation (
6). In particular,
Figure 5 shows that the best MFMs are generally lower than the accuracy on both data sets, even though the SVM reaches more than 99% of MFM on the Canada data set with ResNet50 and SeedNet descriptors and 96.07% with SeedNet-extracted features on Cagliari data set. In the last graph shown in
Figure 6, the average performance obtained with the MFM again indicates the SVM trained with CNN descriptors as the most suitable choice for the task. Indeed, the SVM trained with CNN-extracted descriptors obtains 96.11% and 92.86% on Canada and Cagliari data sets, respectively.
As a general rule, on the one hand, the results provided with the extensive experiments conducted seem to show that the SVM trained with CNN-extracted features can accomplish the multiclass seeds classification task with performance that outperforms every other combination of descriptors and classifier analysed. Moreover, this solution seems to be robust, achieving the highest results in each comparative test. Those extracted from SeedNet performed excellently in all categories among the deep features, establishing themselves very well suited to the task. On the other hand, the results produced using the HC descriptors are satisfactory since they generally bring results comparable to the CNNs ones, even slightly lower than the best CNN descriptors case of the SVM. In general, the Ensemble strategy turns out to be the most appropriate when using HC descriptors, being able to reach 98.76% and 99.42% as the best accuracy and 95.24% and 90.93% as best the MFM on Canada and Cagliari data sets, respectively, and 96.50% 98.84% as the average accuracy and 84.88% and 81.59% as the MFM. Nevertheless, the different number of features that the two different categories have should also be considered. In particular, the handcrafted ones are 64 if combined, while the deep features are 4096 in the worst cases of AlexNet, Vgg16, and Vgg19, and 1000 in all the remaining CNNs. SeedNet is an exception because it has 23 features. Therefore, if we consider the number of discriminative features, the results obtained with the HC features are even more satisfactory and pave the way for possible combinations of heterogeneous features.
Since our investigation is the first attempt to study the problems of classifying fine-grained seed types with a large variety of different seed classes (up to 23), we leveraged known existing classification strategies that have been commonly used in other works closer to this [
22,
24,
26,
43,
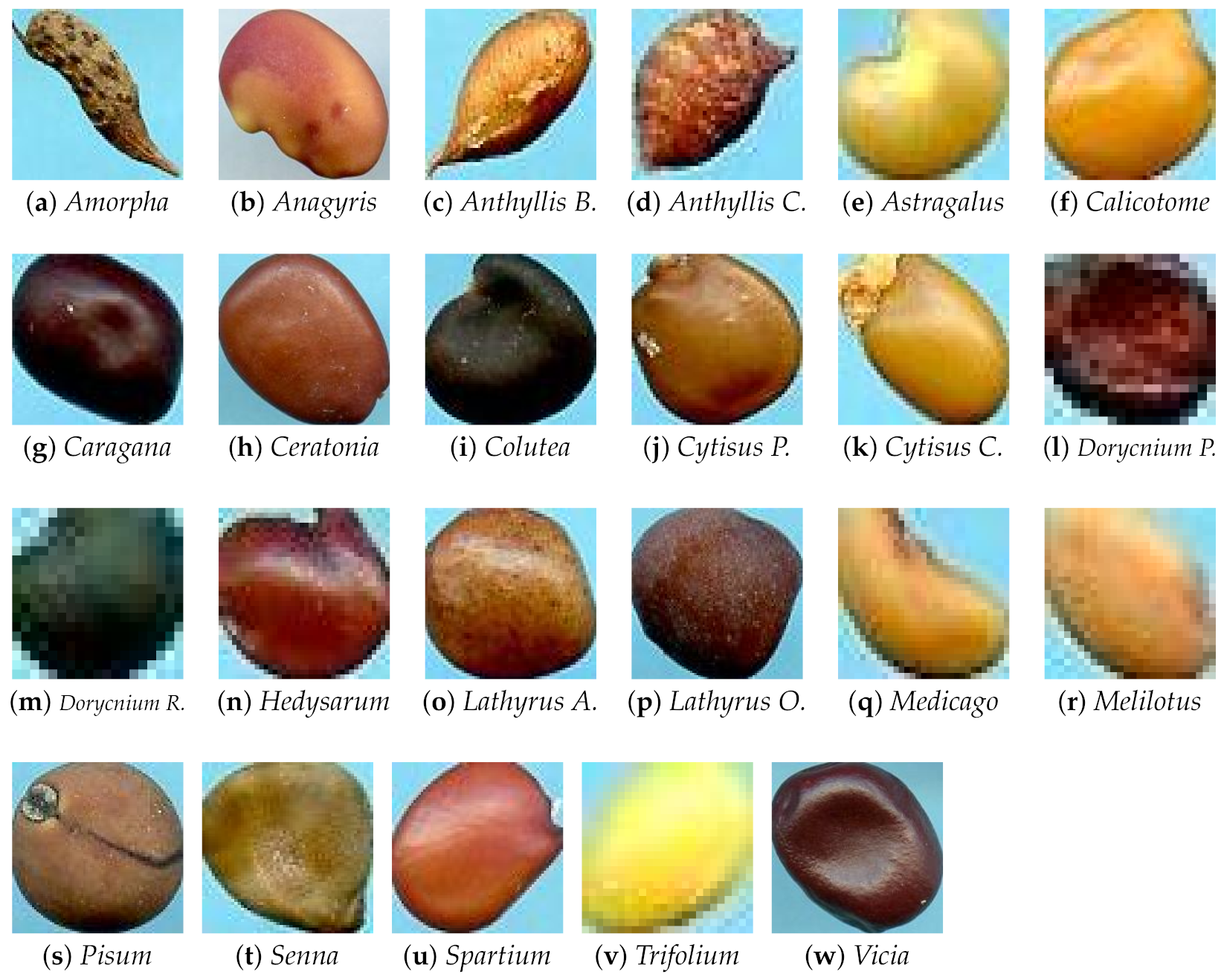
44]. Specifically, we employed kNN, Decision Tree, Naive Bayes, Ensemble classifier with AdaBoost method, and SVM. SVM is the most suitable for this task, probably due to its excellent capacity in distinguishing classes with closely related elements. This condition is evident in the Canada data set, containing seeds with heterogeneous shapes, colours, and textures. In contrast, the Cagliari data set is composed of similar classes, making the process more complex (see
Astragalus,
Medicago, and
Melitotus as examples from
Figure 2). For the same reasons, Decision Trees showed the most unsatisfactory results in this context because, with high probabilities, the features produced are insufficient to adequately represent all possible conditions of the internal nodes and realise an appropriate number of splits. Furthermore, as
Figure 3 and
Figure 4 show, the overall performance of the system in terms of accuracy indicates that the HC and CNN features are comparable, and in some cases, the first ones are better than the last ones. This behaviour is because, in general, both categories have high representational power for fine-grained seeds classification [
6], both in this context and on the same data sets. However, the accuracy metric does not represent the detail of the multiclass issue faced in this work. For this reason, we adopted the mean F-measure in order to have a more unambiguous indication of the most suitable features for the task, keeping in mind the multiclass scenario.
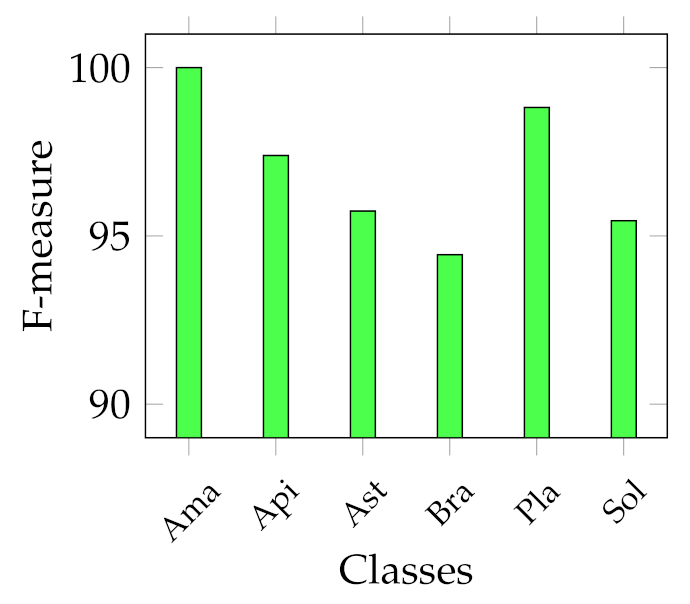
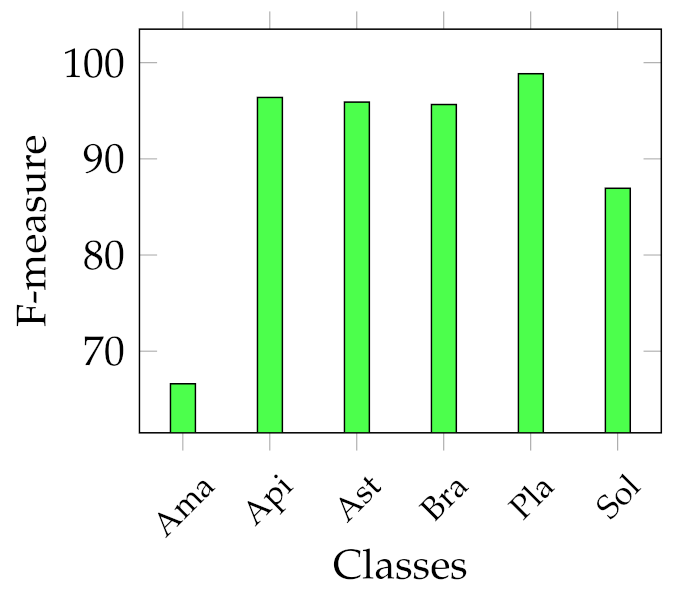
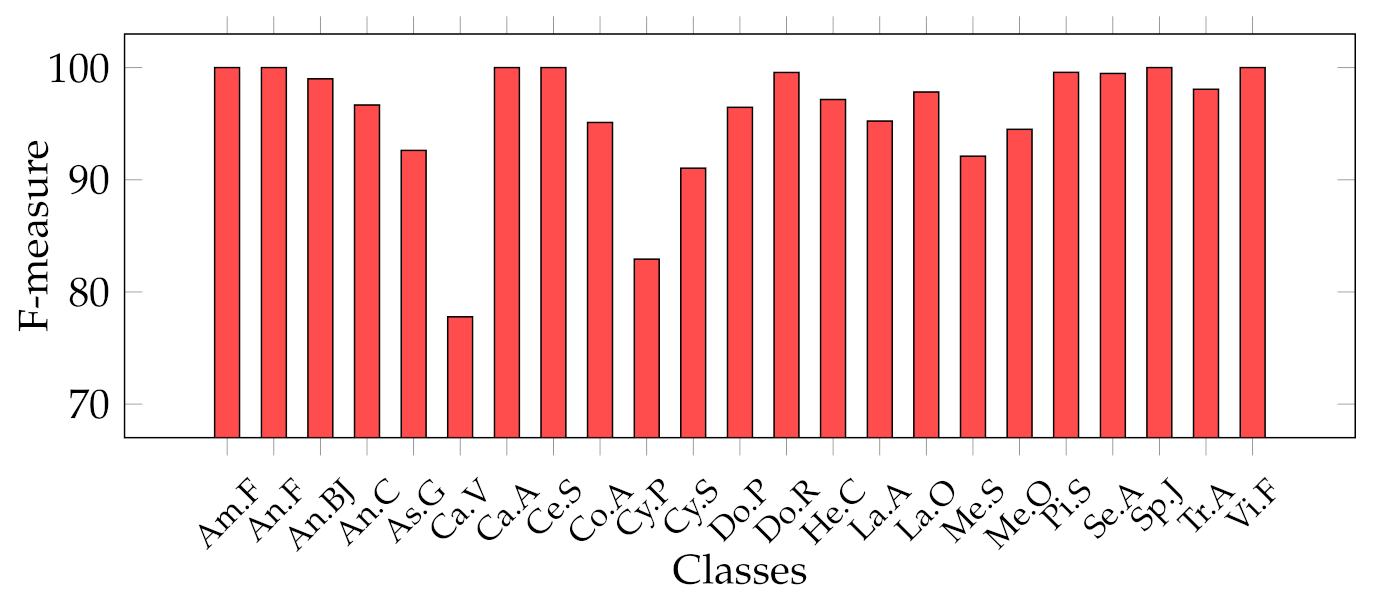
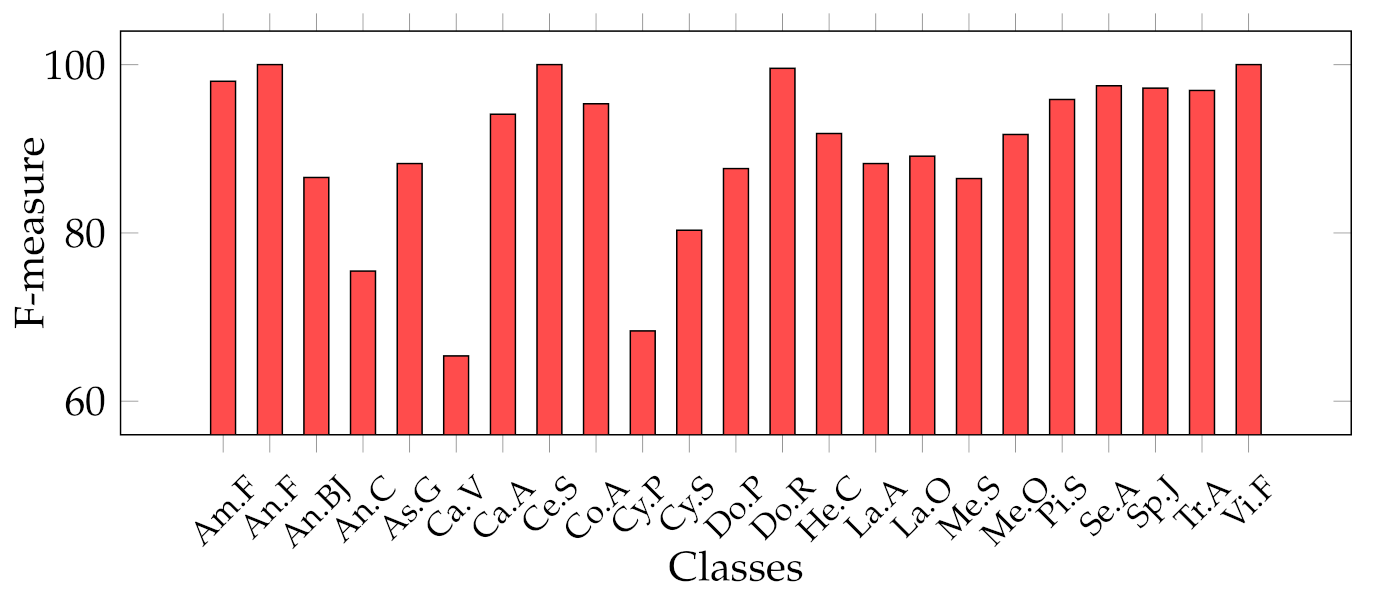
Considering that we addressed a a multiclass classification problem, we provide
Figure 7,
Figure 8,
Figure 9 and
Figure 10, which represent the classwise MFM for each class of both features categories. In detail, regarding the Cagliari data set,
Figure 9 and
Figure 10 show that the most difficult classes are
Calicotome villosa (with F-measures of 77.78% with the SeedNet features and 65.38% with all the HC features) and
Cystus purgans (with F-measures of 82.93% with the SeedNet features and 68.35% with all the HC features), in both cases far below 90%. They are mostly misclassified with
Hedysarum coronarium and
Cystus scoparius, respectively. In both cases, this is certainly due to their similar shapes, and in the latter, certain seeds also have similar colours. As regards the Canada data set,
Figure 8 shows that the
Amaranthaceae (F-measure of 66%) class is mainly misclassified with
Solanaceae, and vice versa, although to a lesser extent (F-measure of 86.95%). Even in this case, this is probably due to the similar shapes, but it is necessary to remark that the
Amaranthaceae class contains only ten samples. The remaining four classes obtained an F-measure highly above 95%. On the other hand,
Figure 7 represents the excellent representational power of the ResNet50-extracted features, considering that the F-measure of all the classes is above 95%, and, above all, the
Amaranthaceae obtained 100%, overcoming the issues of the handcrafted features in discriminating it.
A final remark should be devoted to the execution time. We did not indicate the training time of the different CNNs employed because it is out of the scope of the work. However, we note that the training time was never less than 22 min on the Canada data set (AlexNet) and 21 min on the Cagliari data set (GoogLeNet) for the known architectures, while the SeedNet training lasted 4 and 12 min, respectively. Regarding the training time of the traditional classifiers, it was never above 1 min (the worst was Naive Bayes).
To sum up, the classification strategy based on the optimised SVM trained with SeedNet-extracted features is suitable for the seed-classification task, even in a multiclass scenario. This work shows how SeedNet is not only a robust solution for classification [
6] but is also an outstanding feature extractor if coupled with the SVM classifier. The solution here obtained could also be more feasible than using SeedNet alone, considering the quicker training time of the SVM once provided with the selected features, in contrast to SeedNet alone.
While interesting results have been shown, our work suffers from some limitations. First, the best-performing solution relies entirely on one combination of descriptor and classifier, even though other categories of descriptors produced satisfactory results. Considering the properties of handcrafted features, combining them with deep features could improve the results, particularly in distinguishing the different classes of seeds more specifically. Second, every experimental condition assumed a preprocessing step before it, which needs to be tuned according to the data set employed. As a result, the trained classifier could have issues if applied to other data sets with different image conditions. Third, the training time of the best classification system strictly depends on the training time of the CNN adopted for the feature extraction. Efforts should be made in this sense in order to make a real-time system for the task addressed. Fourth, the dimensionality of the different feature vectors slightly changes if we compare handcrafted and deep descriptors. The first ones have a maximum of 64 features, while the second ones can have up to 4096. In this context, SeedNet is an excellent solution with only 23 features. A reasonable combination of heterogeneous descriptors could be made to investigate possible improvements, even followed by a feature reduction/selection. Fifth, as represented by the classwise performance, some classes are harder to distinguish because of their similar shapes and colours. In the case of Cagliari data sets, not even the deep features have overcome this issue. For this reason, the combination of heterogeneous descriptors could help recognise the most challenging classes.
5. Conclusions
In this work, we mainly focused on the problem of seed image classification. In this context, we specifically addressed an unbalanced multiclass task with two heterogeneous seed data sets, using both handcrafted and deep features. Based on shape, texture, and colour, the handcrafted features are general and dependent on the problem addressed, generating a feature vector with a maximum size of 64. Deep features were extracted from several known CNNs capable of performing different visual recognition tasks, generating a feature vector whose size is 1000 or 4096, except for SeedNet, which has 23. The features were then used to train five different classification algorithms, kNN, Decision Tree, Naive Bayes, SVM, and Ensemble. The experimental results show that the different feature categories perform best and comparably using SVM or Ensemble models for the Canada data set, with average accuracy values above 96.5%. The best model for the Cagliari data set is Ensemble for HC features and SVM for deep features. In both cases, the average accuracy values are above 99.4%. The MFM metric values give us essential information about how well the considered features can solve the unbalanced multiclass task. For both types of features, the Ensemble model achieves the best and comparable performance, with average values higher than 95.2% and 91%, respectively, for the data sets of Canada and Cagliari. When comparing HC- and CNN-based features, especially when considering the size of the feature vector, HC descriptors outperformed deep descriptors in some cases, as they achieved similar performance but with significant computational savings. In general, the results provided by the extensive experiments indicate that the SVM trained with the features extracted from the CNN can perform the task of multiclass seed classification with a performance that outperforms any other combination of descriptors and classifiers analysed. Moreover, this solution seems to be robust, obtaining the highest results in each comparative test. Among the deep features, those extracted by SeedNet performed excellently in all categories, establishing themselves as very well suited to the task and expressing SeedNet as a powerful tool for seed classification and feature extraction. It is also important to remark that the classwise performance highlighted that some classes are harder to distinguish because of their similar shapes and colours. For this reason, the combination of HC and deep descriptors could help recognise the most challenging classes.
In conclusion, SeedNet and CNNs, in general, have demonstrated their ability to offer convenient features for this task, achieving outstanding performance results with both data sets. However, if we consider the size of the feature vectors as a computational term, and the training time involved in the initial process, the HC feature performed satisfactorily, which is particularly desired for a real-time framework.
As a future direction, we aim to further improve the results obtained by investigating the possibility of combining the HC and CNN features, particularly to overcome the difficulties in recognising some seed classes and a feature selection step to reduce the dimensionality of the features. Finally, we also plan to realise a complete framework that can manage all the steps involved in this task, from image acquisition to seed classification, broadening our approach to distinguishing between seeds’ genera and species.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









