
Effectiveness of Learning Systems from Common Image File Types to Detect Osteosarcoma Based on Convolutional Neural Networks (CNNs) Models

 ,
,  , ,
, ,
Abstract
:1. Introduction
2. Methods
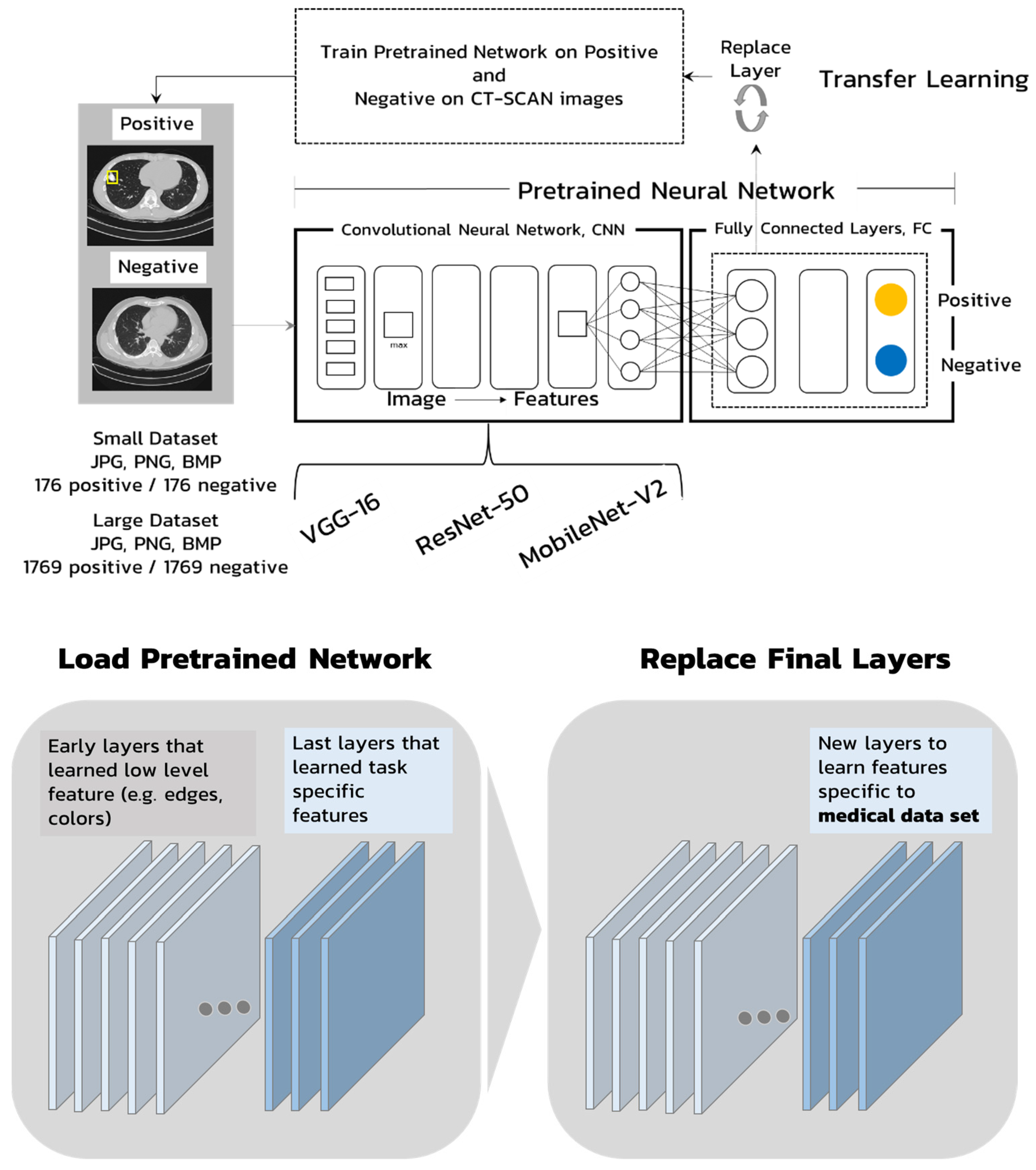
2.1. Dataset Preparation
2.1.1. Data Acquisition
2.1.2. Ground Truth
2.1.3. Datasets
2.2. Pretrained Neural Networks
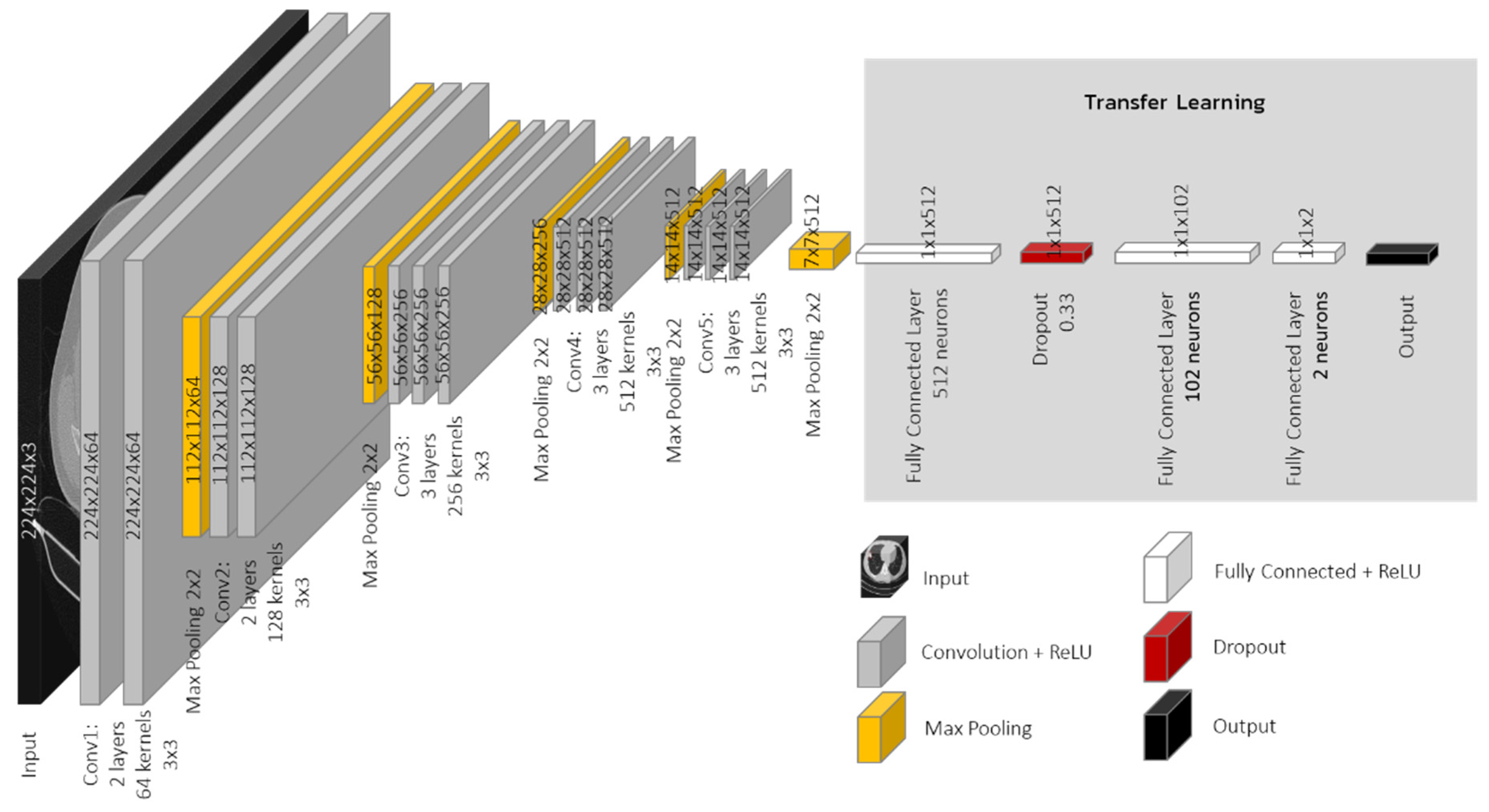
2.2.1. VGG Model
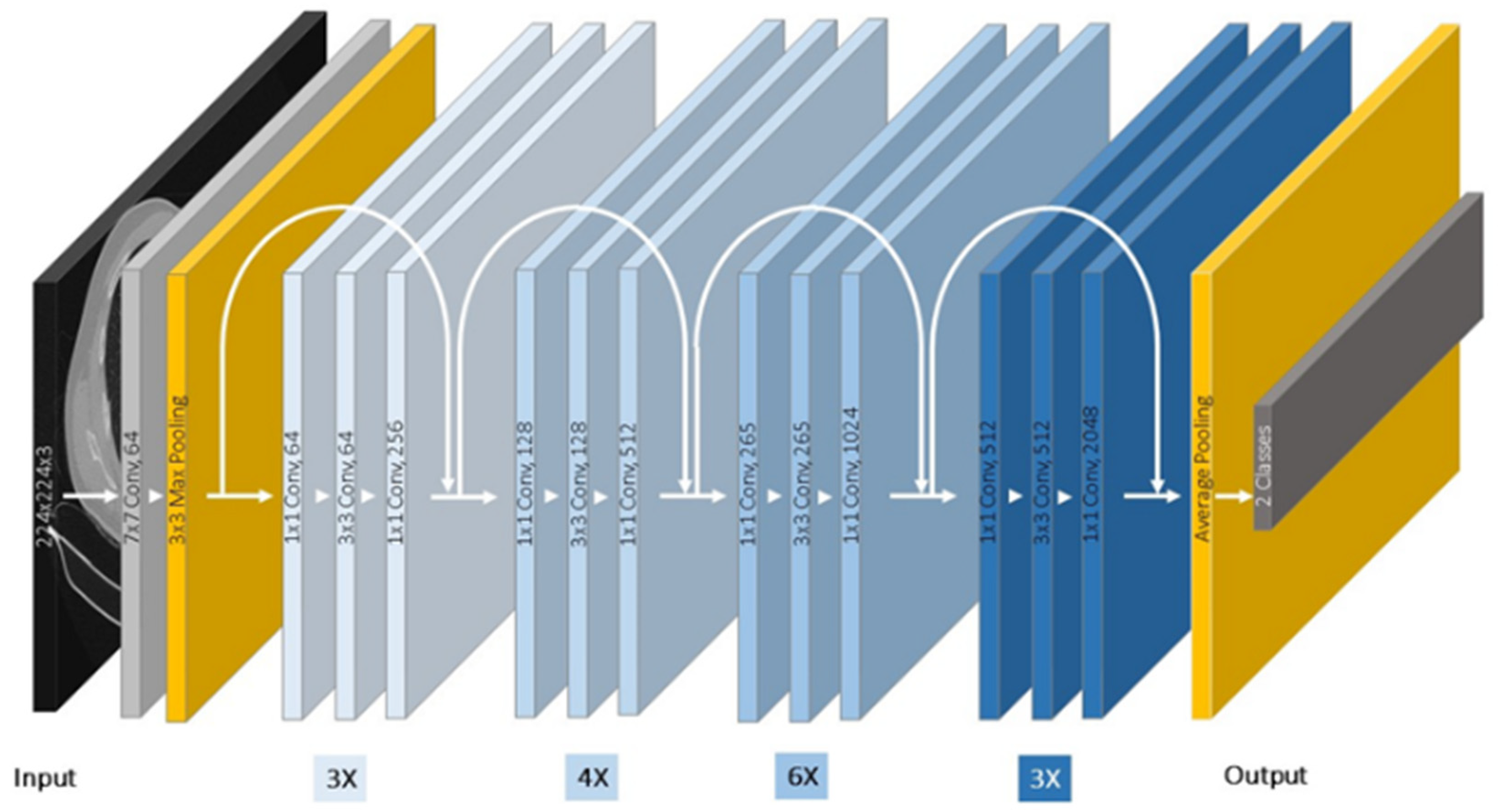
2.2.2. Residual Networks Model
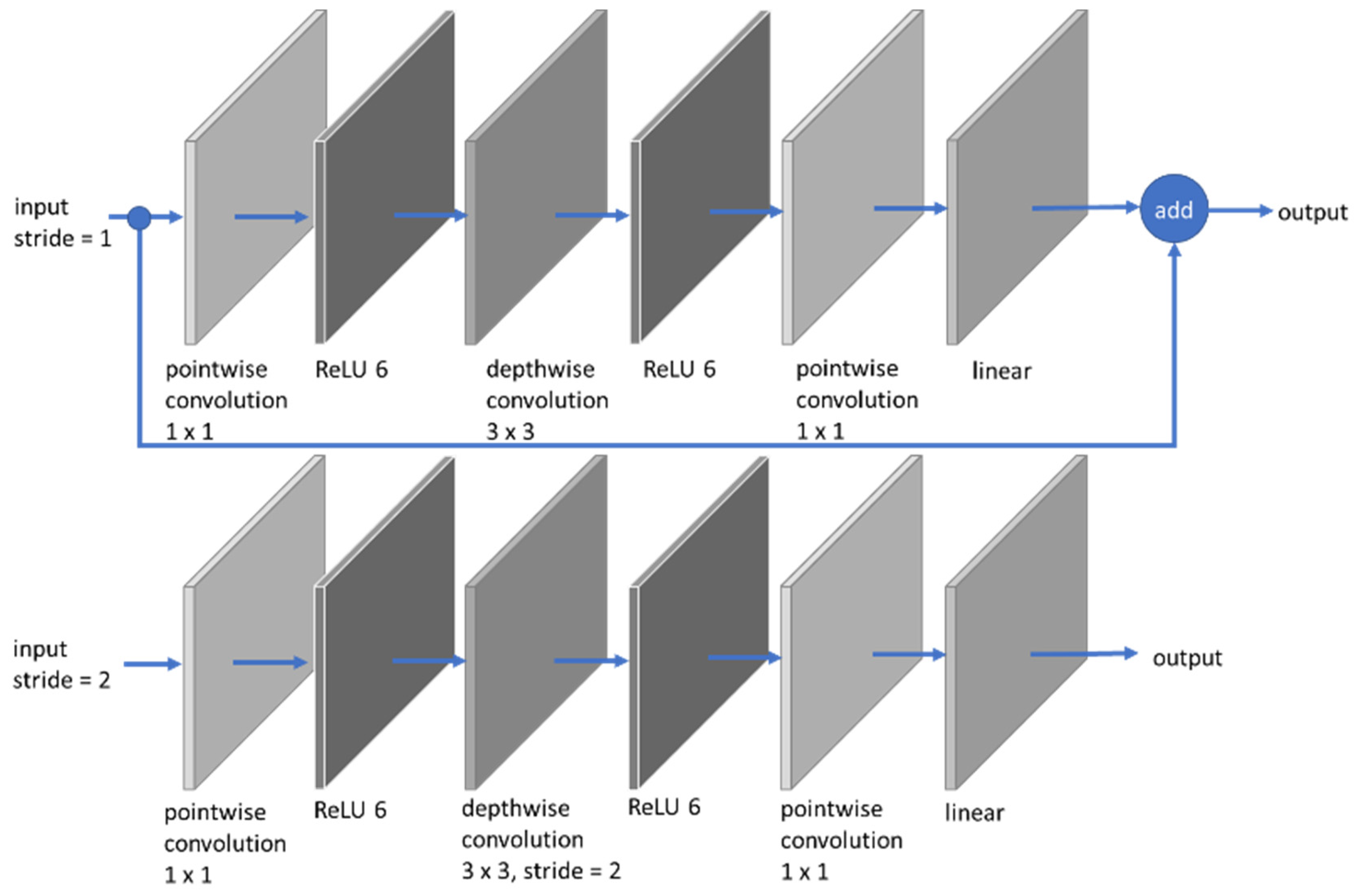
2.2.3. MobileNet Model
2.3. Train and Validate the CNNs Networks
2.4. Loss Function
- number of training examples
- predicted value
- expected value
2.5. Performance Benchmark Scores
3. Results
4. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Siegel, R.L. Cancer Statistics 2020. CA Cancer J. Clin. 2020, 70, 7–30. [Google Scholar] [CrossRef] [PubMed]
- Cancer.Net Doctor-Approved Patient Information from ASCO Publications, Bone Cancer (Sarcoma of Bone): Statistics, Approved by the Cancer.Net Editorial Board, 01/2021. Available online: https://www.cancer.net/cancer-types/bone-cancer-sarcoma-bone/statistics (accessed on 2 October 2021).
- Martin, J.W.; Squire, J.; Zielenska, M. The Genetics of Osteosarcoma. Sarcoma 2012, 2012, 627254. [Google Scholar] [CrossRef] [Green Version]
- Matsubara, E.; Mori, T.; Koga, T.; Shibata, H.; Ikeda, K.; Shiraishi, K.; Suzuki, M. Metastasectomy of Pulmonary Metastases from Osteosarcoma: Prognostic Factors and Indication for Repeat Metastasectomy. J. Respir. Med. 2015, 2015, 570314. [Google Scholar] [CrossRef] [Green Version]
- Su, W.T.; Chewning, J.; Abramson, S.; Rosen, N.; Gholizadeh, M.; Healey, J.; Meyers, P.; La Quaglia, M.P. Surgical management and outcome of osteosarcoma patients with unilateral pulmonary metastases. J. Pediatr. Surg. 2004, 39, 418–423. [Google Scholar] [CrossRef] [PubMed]
- Bramwell, V. Metastatic Osteosarcoma: A Review of Current Issues in Systemic Treatment. Sarcoma 1997, 1, 123–130. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liang, X.; Yu, J.; Liao, J.; Chen, Z. Convolutional Neural Network for Breast and Thyroid Nodules Diagnosis in Ultrasound Imaging. BioMed Res. Int. 2020, 2020, 1763803. [Google Scholar] [CrossRef] [PubMed]
- Lin, Z.; Ye, H.; Zhan, B.; Huang, X. An Efficient Network for Surface Defect Detection. Appl. Sci. 2020, 10, 6085. [Google Scholar] [CrossRef]
- Narin, A.; Kaya, C.; Pamuk, Z. Automatic detection of coronavirus disease (COVID-19) using X-ray images and deep convolutional neural networks. Pattern Anal. Appl. 2021, 24, 1207–1220. [Google Scholar] [CrossRef]
- Sethy, P.K.; Behera, S.K.; Ratha, P.K.; Biswas, P. Detection of coronavirus Disease (COVID-19) based on Deep Features and Support Vector Machine. Int. J. Math. Eng. Manag. Sci. 2020, 5, 643–651. [Google Scholar] [CrossRef]
- Zhang, J.; Xie, Y.; Pang, G.; Liao, Z.; Verjans, J.; Li, W.; Sun, Z.; He, J.; Li, Y.; Shen, C.; et al. Viral Pneumonia Screening on Chest X-rays Using Confidence-Aware Anomaly Detection. IEEE Trans. Med. Imaging 2021, 40, 879–890. [Google Scholar] [CrossRef]
- Hemdan, E.E.-D.; Shouman, M.A.; Karar, M.E. COVIDX-Net: A Framework of Deep Learning Classifiers to Diagnose COVID-19 in X-ray Images. Cornell University. Available online: https://arxiv.org/abs/2003.11055 (accessed on 18 October 2021).
- Sakshica, D.; Gupta, K. Various Raster and Vector Image File Formats. Int. J. Adv. Res. Comput. Commun. Eng. 2015, 4, 268–271. [Google Scholar] [CrossRef]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 3rd ed.; Pearson Education: Upper Saddle River, NJ, USA, 2008; pp. 526–538. [Google Scholar]
- Tan, L.K. Image file formats. Biomed. Imaging Interv. J. 2006, 2, e6. [Google Scholar] [CrossRef] [PubMed]
- Naseer, A.; Yasir, T.; Azhar, A.; Shakeel, T.; Zafar, K. Computer-Aided Brain Tumor Diagnosis: Performance Evaluation of Deep Learner CNN Using Augmented Brain MRI. Int. J. Biomed. Imaging 2021, 2021, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Signoroni, A.; Savardi, M.; Baronio, A.; Benini, S. Deep Learning Meets Hyperspectral Image Analysis: A Multidisciplinary Review. J. Imaging 2019, 5, 52. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef] [Green Version]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. Available online: https://arxiv.org/pdf/1704.04861.pdf (accessed on 24 October 2021).
- Elgendi, M.; Fletcher, R.; Howard, N.; Menon, C.; Ward, R. The Evaluation of Deep Neural Networks and X-Ray as a Practical Alternative for Diagnosis and Management of COVID-19. medRxiv 2020. [Google Scholar] [CrossRef]
- Zulkifley, M.A.; Abdani, S.R.; Zulkifley, N.H. Automated Bone Age Assessment with Image Registration Using Hand X-ray Images. Appl. Sci. 2020, 10, 7233. [Google Scholar] [CrossRef]
- Peng, J.; Kang, S.; Ning, Z.; Deng, H.; Shen, J.; Xu, Y.; Zhang, J.; Zhao, W.; Li, X.; Gong, W.; et al. Residual convolutional neural network for predicting response of transarterial chemoembolization in hepatocellular carcinoma from CT imaging. Eur. Radiol. 2020, 30, 413–424. [Google Scholar] [CrossRef] [Green Version]
- Tsochatzidis, L.; Costaridou, L.; Pratikakis, I. Deep Learning for Breast Cancer Diagnosis from Mammograms—A Comparative Study. J. Imaging 2019, 5, 37. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- ElGhany, S.A.; Ibraheem, M.R.; Alruwaili, M.; Elmogy, M. Diagnosis of Various Skin Cancer Lesions Based on Fine-Tuned ResNet50 Deep Network. Comput. Mater. Contin. 2021, 68, 117–135. [Google Scholar] [CrossRef]
- Google AI Blog The latest from Google Research, Mark Sandler, Andrew Howard, MobileNetV2: The Next Generation of On-Device Computer Vision Networks. 2018. Available online: https://ai.googleblog.com/2018/04/mobilenetv2-next-generation-of-on.html#1 (accessed on 24 October 2021).
- Šimundić, A.-M. Bias in research. Biochem. Med. 2013, 23, 12–15. [Google Scholar] [CrossRef]
- Ho, Y.; Wookey, S. The Real-World-Weight Cross-Entropy Loss Function: Modeling the Costs of Mislabeling. IEEE Access 2020, 8, 4806–4813. [Google Scholar] [CrossRef]
- Dufourq, E.; Bassett, B.A. Automated Problem Identification: Regression vs. Classification via Evolutionary Deep Networks. In Proceedings of the South African Institute of Computer Scientists and Information Technologists, Thaba Nchu, South Africa, 26–28 September 2017; pp. 1–9. [Google Scholar]
- Zhang, Z.; Sabuncu, M.R. Generalized Cross Entropy Loss for Training Deep Neural Networks with Noisy Labels. In Proceedings of the 32nd Conference on Neural Information Processing Systems, NeurIPS, Montreal, QC, Canada, 3–8 December 2018; pp. 1–11. [Google Scholar]
- Sasaki, Y. The Truth of the F-Measure. 2007. Available online: https://www.toyota-ti.ac.jp/Lab/Denshi/COIN/people/yutaka.sasaki/F-measure-YS-26Oct07.pdf (accessed on 25 October 2021).
- Chen, H.-C.; Sunardi; Liau, B.-Y.; Lin, C.-Y.; Akbari, V.B.H.; Lung, C.-W.; Jan, Y.-K. Estimation of Various Walking Intensities Based on Wearable Plantar Pressure Sensors Using Artificial Neural Networks. Sensors 2021, 21, 6513. [Google Scholar] [CrossRef]
- Serj, M.F.; Lavi, B.; Hoff, G.; Valls, D.P. A Deep Convolutional Neural Network for Lung Cancer Diagnostic. arXiv 2018, arXiv:1804.08170. [Google Scholar]
- Sriramakrishnan, P.; Kalaiselvi, T.; Padmapriya, S.T.; Shanthi, N.; Ramkumar, S.; Kalaichelvi, N. An Medical Image File Formats and Digital Image Conversion. Int. J. Eng. Adv. Technol. 2019, 9, 74–78. [Google Scholar]
- Ujgare, N.S.; Baviskar, S.P. Conversion of DICOM Image in to JPEG, BMP and PNG Image Format. Int. J. Comput. Appl. 2013, 62, 22–26. [Google Scholar] [CrossRef]
- Oladiran, O.; Gichoya, J.; Purkayastha, S. Conversion of JPG Image into DICOM Image Format with One Click Tagging. In Proceedings of the Lecture Notes in Computer Science; Springer: Singapore, 2017; pp. 61–70. [Google Scholar]
- Wiggins, R.H.; Davidson, H.C.; Harnsberger, H.R.; Lauman, J.R.; Goede, P.A. Image File Formats: Past, Present, and Future1. RadioGraphics 2001, 21, 789–798. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
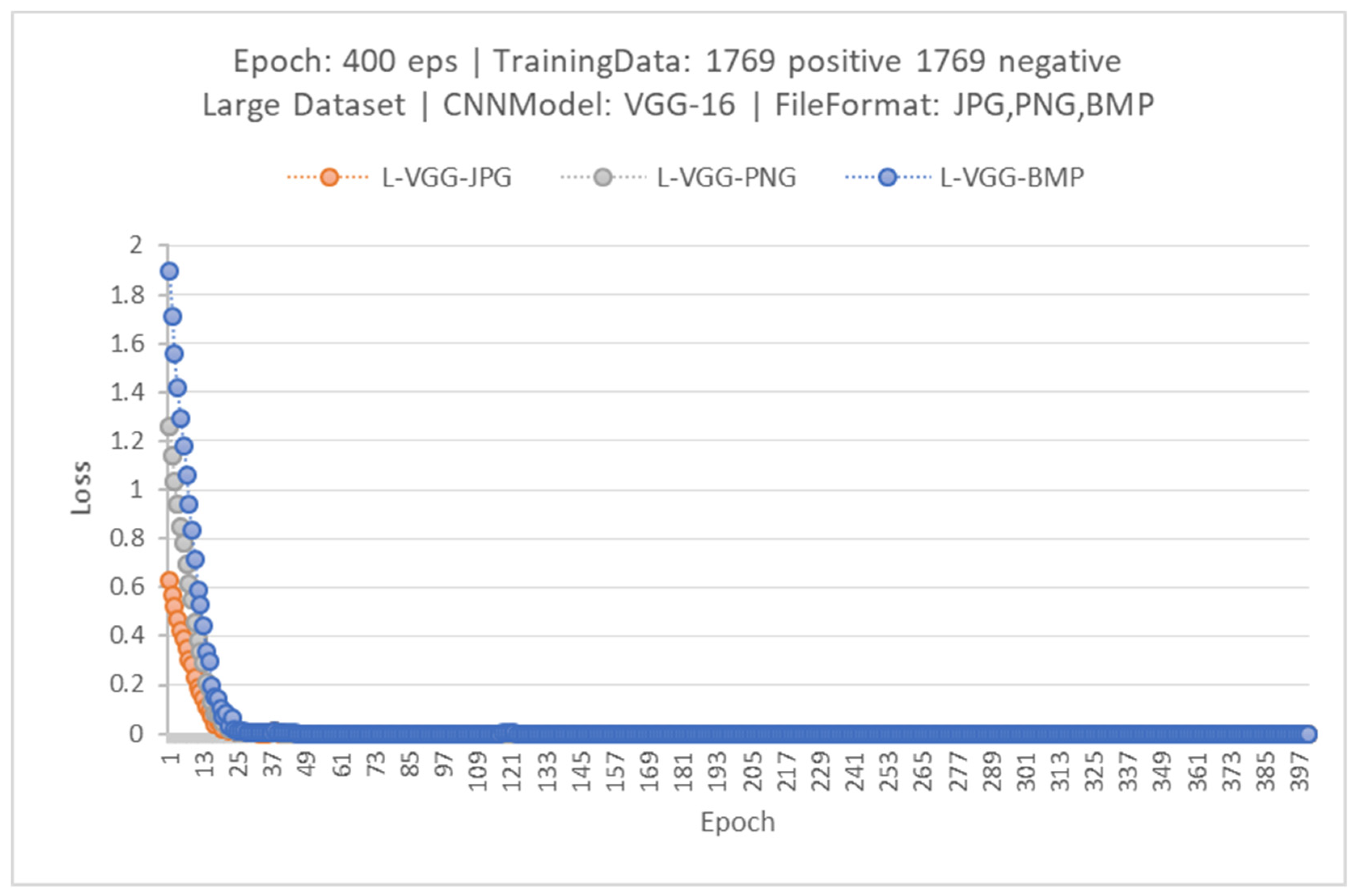{kind=link}
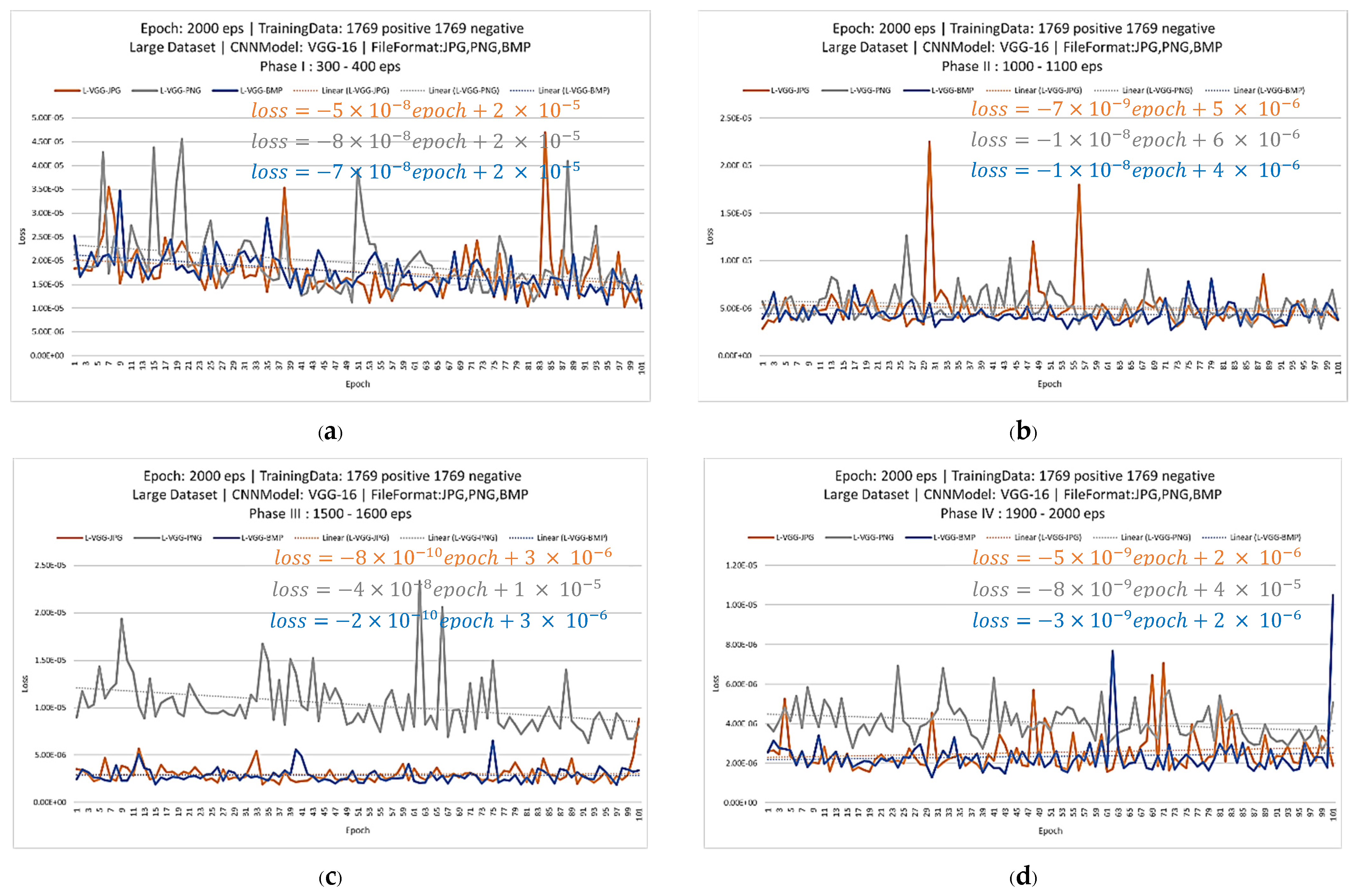{kind=link}
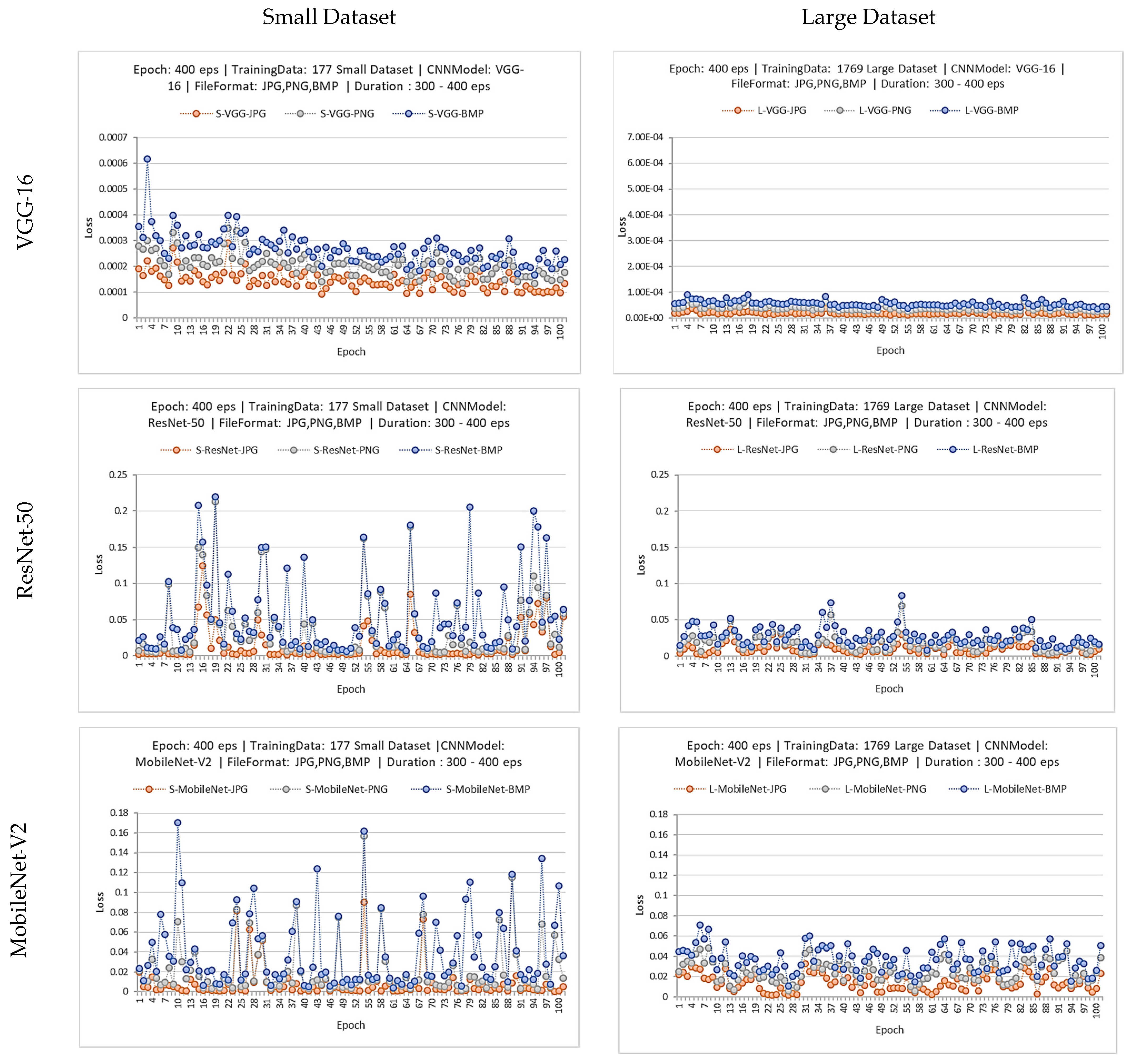{kind=link}
{kind=link}
| Codes | Details | Positive (No. of Image) | Negative (No. of Image) | Total (No. of Image) | |
|---|---|---|---|---|---|
| Small Dataset | B1_VGG16JPG | VGG16 trained on JPG | 177 | 177 | 354 |
| B2_VGG16PNG | VGG16 trained on PNG | 177 | 177 | 354 | |
| B3_VGG16BMP | VGG16 trained on BMP | 177 | 177 | 354 | |
| B4_ResNetJPG | ResNet50 trained on JPG | 177 | 177 | 354 | |
| B5_ResNetPNG | ResNet50 trained on PNG | 177 | 177 | 354 | |
| B6_ResNetBMP | ResNet50 trained on BMP | 177 | 177 | 354 | |
| B7_MobileNetJPG | MobileNetV2 trained on JPG | 177 | 177 | 354 | |
| B8_MobileNetPNG | MobileNetV2 trained on PNG | 177 | 177 | 354 | |
| B9_MobileNetBMP | MobileNetV2 trained on BMP | 177 | 177 | 354 | |
| Large Dataset | B10_VGG16JPG | VGG16 trained on JPG | 1769 | 1769 | 3565 |
| B11_VGG16PNG | VGG16 trained on PNG | 1769 | 1769 | 3565 | |
| B12_VGG16BMP | VGG16 trained on BMP | 1769 | 1769 | 3565 | |
| B13_ResNetJPG | ResNet50 trained on JPG | 1769 | 1769 | 3565 | |
| B14_ResNetPNG | ResNet50 trained on PNG | 1769 | 1769 | 3565 | |
| B15_ResNetBMP | ResNet50 trained on BMP | 1769 | 1769 | 3565 | |
| B16_MobileNetJPG | MobileNetV2 trained on JPG | 1769 | 1769 | 3565 | |
| B17_MobileNetPNG | MobileNetV2 trained on PNG | 1769 | 1769 | 3565 | |
| B18_MobileNetBMP | MobileNetV2 trained on BMP | 1769 | 1769 | 3565 | |
| Total | 17,514 | 17,514 | 35,055 |
| Disease Present | Disease Absent | Total | |
|---|---|---|---|
| Index Test Positive | True Positive (TP) | False Positive (FP) | TP + FP |
| Index Test Negative | False Negative (FN) | True Negative (TN) | FN + TN |
| Total | TP + FN | FP + TN |
| Period | Trendline Slopes | ||
|---|---|---|---|
| JPG | PNG | BMP | |
| 300–400 | |||
| 1000–1100 | |||
| 1500–1600 | |||
| 1900–2000 | |||
| Format | Format | TP | TN | FP | FN | Accuracy | Precision | Recall | F1 Score | |
|---|---|---|---|---|---|---|---|---|---|---|
| Trained | Tested | |||||||||
| VGG-16 | BMP | BMP | 162 | 355 | 88 | 281 | 0.583 | 0.648 | 0.366 | 0.467 |
| JPG | 161 | 357 | 86 | 282 | 0.584 | 0.652 | 0.363 | 0.467 | ||
| PNG | 162 | 355 | 88 | 281 | 0.583 | 0.648 | 0.366 | 0.467 | ||
| JPG | BMP | 179 | 349 | 94 | 264 | 0.596 | 0.656 | 0.404 | 0.500 | |
| JPG | 174 | 348 | 95 | 269 | 0.589 | 0.647 | 0.393 | 0.489 | ||
| PNG | 179 | 349 | 94 | 264 | 0.596 | 0.656 | 0.404 | 0.500 | ||
| PNG | BMP | 161 | 352 | 91 | 282 | 0.579 | 0.639 | 0.363 | 0.463 | |
| JPG | 154 | 354 | 89 | 289 | 0.573 | 0.634 | 0.348 | 0.449 | ||
| PNG | 161 | 352 | 91 | 282 | 0.579 | 0.639 | 0.363 | 0.463 | ||
| ResNet-50 | BMP | BMP | 99 | 394 | 49 | 344 | 0.556 | 0.669 | 0.223 | 0.335 |
| JPG | 100 | 398 | 45 | 343 | 0.562 | 0.690 | 0.225 | 0.340 | ||
| PNG | 99 | 394 | 49 | 344 | 0.556 | 0.669 | 0.223 | 0.335 | ||
| JPG | BMP | 83 | 408 | 35 | 360 | 0.554 | 0.703 | 0.187 | 0.296 | |
| JPG | 81 | 409 | 34 | 362 | 0.553 | 0.704 | 0.183 | 0.290 | ||
| PNG | 83 | 408 | 35 | 360 | 0.554 | 0.703 | 0.187 | 0.296 | ||
| PNG | BMP | 87 | 385 | 58 | 356 | 0.533 | 0.600 | 0.196 | 0.296 | |
| JPG | 83 | 388 | 55 | 360 | 0.532 | 0.601 | 0.187 | 0.286 | ||
| PNG | 87 | 385 | 58 | 356 | 0.533 | 0.600 | 0.196 | 0.296 | ||
| MobileNet-V2 | BMP | BMP | 86 | 418 | 25 | 357 | 0.569 | 0.775 | 0.194 | 0.310 |
| JPG | 83 | 419 | 24 | 360 | 0.566 | 0.776 | 0.187 | 0.301 | ||
| PNG | 86 | 418 | 25 | 357 | 0.569 | 0.775 | 0.194 | 0.310 | ||
| JPG | BMP | 93 | 428 | 15 | 350 | 0.588 | 0.861 | 0.210 | 0.337 | |
| JPG | 84 | 425 | 18 | 359 | 0.574 | 0.823 | 0.190 | 0.308 | ||
| PNG | 93 | 428 | 15 | 350 | 0.588 | 0.861 | 0.210 | 0.337 | ||
| PNG | BMP | 88 | 423 | 20 | 355 | 0.577 | 0.815 | 0.199 | 0.319 | |
| JPG | 95 | 424 | 19 | 348 | 0.586 | 0.833 | 0.214 | 0.341 | ||
| PNG | 88 | 423 | 20 | 355 | 0.577 | 0.815 | 0.199 | 0.319 |
| Format | Format | TP | TN | FP | FN | Accuracy | Precision | Recall | F1 Score | |
|---|---|---|---|---|---|---|---|---|---|---|
| Trained | Tested | |||||||||
| VGG-16 | BMP | BMP | 117 | 270 | 173 | 326 | 0.437 | 0.403 | 0.264 | 0.319 |
| JPG | 118 | 269 | 174 | 325 | 0.437 | 0.404 | 0.266 | 0.321 | ||
| PNG | 117 | 270 | 173 | 326 | 0.437 | 0.403 | 0.264 | 0.319 | ||
| JPG | BMP | 116 | 275 | 168 | 327 | 0.441 | 0.408 | 0.262 | 0.319 | |
| JPG | 116 | 274 | 169 | 327 | 0.440 | 0.407 | 0.262 | 0.319 | ||
| PNG | 116 | 275 | 168 | 327 | 0.441 | 0.408 | 0.262 | 0.319 | ||
| PNG | BMP | 115 | 272 | 171 | 328 | 0.437 | 0.402 | 0.259 | 0.315 | |
| JPG | 115 | 273 | 170 | 328 | 0.438 | 0.403 | 0.259 | 0.315 | ||
| PNG | 115 | 272 | 171 | 328 | 0.437 | 0.402 | 0.259 | 0.315 | ||
| ResNet-50 | BMP | BMP | 160 | 190 | 253 | 283 | 0.395 | 0.387 | 0.361 | 0.374 |
| JPG | 154 | 193 | 250 | 289 | 0.392 | 0.381 | 0.348 | 0.364 | ||
| PNG | 160 | 190 | 253 | 283 | 0.395 | 0.387 | 0.361 | 0.374 | ||
| JPG | BMP | 171 | 184 | 259 | 272 | 0.401 | 0.398 | 0.386 | 0.392 | |
| JPG | 161 | 193 | 250 | 282 | 0.399 | 0.392 | 0.363 | 0.377 | ||
| PNG | 171 | 184 | 259 | 272 | 0.401 | 0.398 | 0.386 | 0.392 | ||
| PNG | BMP | 140 | 250 | 193 | 303 | 0.440 | 0.420 | 0.316 | 0.361 | |
| JPG | 130 | 221 | 222 | 313 | 0.396 | 0.369 | 0.293 | 0.327 | ||
| PNG | 140 | 250 | 193 | 303 | 0.440 | 0.420 | 0.316 | 0.361 | ||
| MobileNet-V2 | BMP | BMP | 176 | 201 | 242 | 267 | 0.425 | 0.421 | 0.397 | 0.409 |
| JPG | 187 | 198 | 245 | 256 | 0.434 | 0.433 | 0.422 | 0.427 | ||
| PNG | 176 | 201 | 242 | 267 | 0.425 | 0.421 | 0.397 | 0.409 | ||
| JPG | BMP | 130 | 223 | 220 | 313 | 0.398 | 0.371 | 0.293 | 0.328 | |
| JPG | 127 | 227 | 216 | 316 | 0.399 | 0.370 | 0.287 | 0.323 | ||
| PNG | 130 | 223 | 220 | 313 | 0.398 | 0.371 | 0.293 | 0.328 | ||
| PNG | BMP | 140 | 250 | 193 | 303 | 0.440 | 0.420 | 0.316 | 0.361 | |
| JPG | 152 | 244 | 199 | 291 | 0.447 | 0.433 | 0.343 | 0.383 | ||
| PNG | 140 | 250 | 193 | 303 | 0.440 | 0.420 | 0.316 | 0.361 |
| Format | Format | TP | TN | FP | FN | Accuracy | Precision | Recall | F1 Score | |
|---|---|---|---|---|---|---|---|---|---|---|
| Trained | Tested | |||||||||
| VGG-16 | BMP | BMP | 111 | 292 | 151 | 332 | 0.455 | 0.424 | 0.250 | 0.315 |
| JPG | 113 | 288 | 155 | 330 | 0.453 | 0.422 | 0.255 | 0.318 | ||
| PNG | 111 | 292 | 151 | 332 | 0.455 | 0.424 | 0.250 | 0.315 | ||
| JPG | BMP | 115 | 267 | 176 | 328 | 0.431 | 0.395 | 0.259 | 0.313 | |
| JPG | 114 | 273 | 170 | 329 | 0.437 | 0.401 | 0.257 | 0.314 | ||
| PNG | 115 | 267 | 176 | 328 | 0.431 | 0.395 | 0.259 | 0.313 | ||
| PNG | BMP | 112 | 264 | 179 | 331 | 0.424 | 0.385 | 0.253 | 0.305 | |
| JPG | 117 | 265 | 178 | 326 | 0.431 | 0.397 | 0.264 | 0.317 | ||
| PNG | 112 | 264 | 179 | 331 | 0.424 | 0.385 | 0.253 | 0.305 | ||
| ResNet-50 | BMP | BMP | 69 | 289 | 154 | 374 | 0.404 | 0.309 | 0.156 | 0.207 |
| JPG | 64 | 300 | 143 | 379 | 0.411 | 0.309 | 0.144 | 0.197 | ||
| PNG | 69 | 289 | 154 | 374 | 0.404 | 0.309 | 0.156 | 0.207 | ||
| JPG | BMP | 180 | 184 | 259 | 263 | 0.411 | 0.410 | 0.406 | 0.408 | |
| JPG | 179 | 184 | 259 | 264 | 0.410 | 0.409 | 0.404 | 0.406 | ||
| PNG | 180 | 184 | 259 | 263 | 0.411 | 0.410 | 0.406 | 0.408 | ||
| PNG | BMP | 106 | 245 | 198 | 337 | 0.396 | 0.349 | 0.239 | 0.283 | |
| JPG | 101 | 246 | 197 | 342 | 0.392 | 0.339 | 0.228 | 0.272 | ||
| PNG | 106 | 245 | 198 | 337 | 0.396 | 0.349 | 0.239 | 0.283 | ||
| MobileNet-V2 | BMP | BMP | 140 | 209 | 234 | 303 | 0.394 | 0.374 | 0.316 | 0.343 |
| JPG | 131 | 223 | 220 | 312 | 0.399 | 0.373 | 0.296 | 0.330 | ||
| PNG | 140 | 209 | 234 | 303 | 0.394 | 0.374 | 0.316 | 0.343 | ||
| JPG | BMP | 164 | 225 | 218 | 279 | 0.439 | 0.429 | 0.370 | 0.397 | |
| JPG | 164 | 224 | 219 | 279 | 0.438 | 0.428 | 0.370 | 0.397 | ||
| PNG | 164 | 225 | 218 | 279 | 0.439 | 0.429 | 0.370 | 0.397 | ||
| PNG | BMP | 223 | 201 | 242 | 220 | 0.478 | 0.479 | 0.503 | 0.491 | |
| JPG | 225 | 205 | 238 | 218 | 0.485 | 0.486 | 0.508 | 0.497 | ||
| PNG | 223 | 201 | 242 | 220 | 0.478 | 0.479 | 0.503 | 0.491 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Loraksa, C.; Mongkolsomlit, S.; Nimsuk, N.; Uscharapong, M.; Kiatisevi, P. Effectiveness of Learning Systems from Common Image File Types to Detect Osteosarcoma Based on Convolutional Neural Networks (CNNs) Models. J. Imaging 2022, 8, 2. https://doi.org/10.3390/jimaging8010002
Loraksa C, Mongkolsomlit S, Nimsuk N, Uscharapong M, Kiatisevi P. Effectiveness of Learning Systems from Common Image File Types to Detect Osteosarcoma Based on Convolutional Neural Networks (CNNs) Models. Journal of Imaging. 2022; 8(1):2. https://doi.org/10.3390/jimaging8010002
Chicago/Turabian StyleLoraksa, Chanunya, Sirima Mongkolsomlit, Nitikarn Nimsuk, Meenut Uscharapong, and Piya Kiatisevi. 2022. "Effectiveness of Learning Systems from Common Image File Types to Detect Osteosarcoma Based on Convolutional Neural Networks (CNNs) Models" Journal of Imaging 8, no. 1: 2. https://doi.org/10.3390/jimaging8010002
APA StyleLoraksa, C., Mongkolsomlit, S., Nimsuk, N., Uscharapong, M., & Kiatisevi, P. (2022). Effectiveness of Learning Systems from Common Image File Types to Detect Osteosarcoma Based on Convolutional Neural Networks (CNNs) Models. Journal of Imaging, 8(1), 2. https://doi.org/10.3390/jimaging8010002