
Resources and Power Efficient FPGA Accelerators for Real-Time Image Classification


Abstract
:1. Introduction
2. Related Work
3. Background on Vessel Detection
4. CNN Design Approach
4.1. CNN Design Space Exploration
- Number of layers: the neural networks for the low-feature-space image-classification applications can achieve a high accuracy rating even with a relatively small number of convolution layers [8].
- Size of convolution kernels: considering the images that are relatively small, the recognized objects tend to occupy a large portion of the image and hence, large and medium-size convolution kernels suffice.
- Choosing the size of the pooling layers windows: the feature space is relatively limited and hence, the use of pooling layers will not affect the accuracy, though it will significantly improve the resources’ requirements of the succeeding layers.
- Padding avoidance: this is used throughout the CNN because: (a) it does not affect the accuracy and (b) given that the majority of the target applications have objects located at or close to the image center, we do not need to preserve the size of the feature maps.
- Divisibility: it refers to the divisibility of each convolution layer’s output size by the kernel size of the succeeding pooling layer. If it is applied, it will: (a) allow the omission of padding with no accuracy loss and (b) lead to an efficient pipeline for the contiguous layers.
4.2. Bit-Accurate Model Development
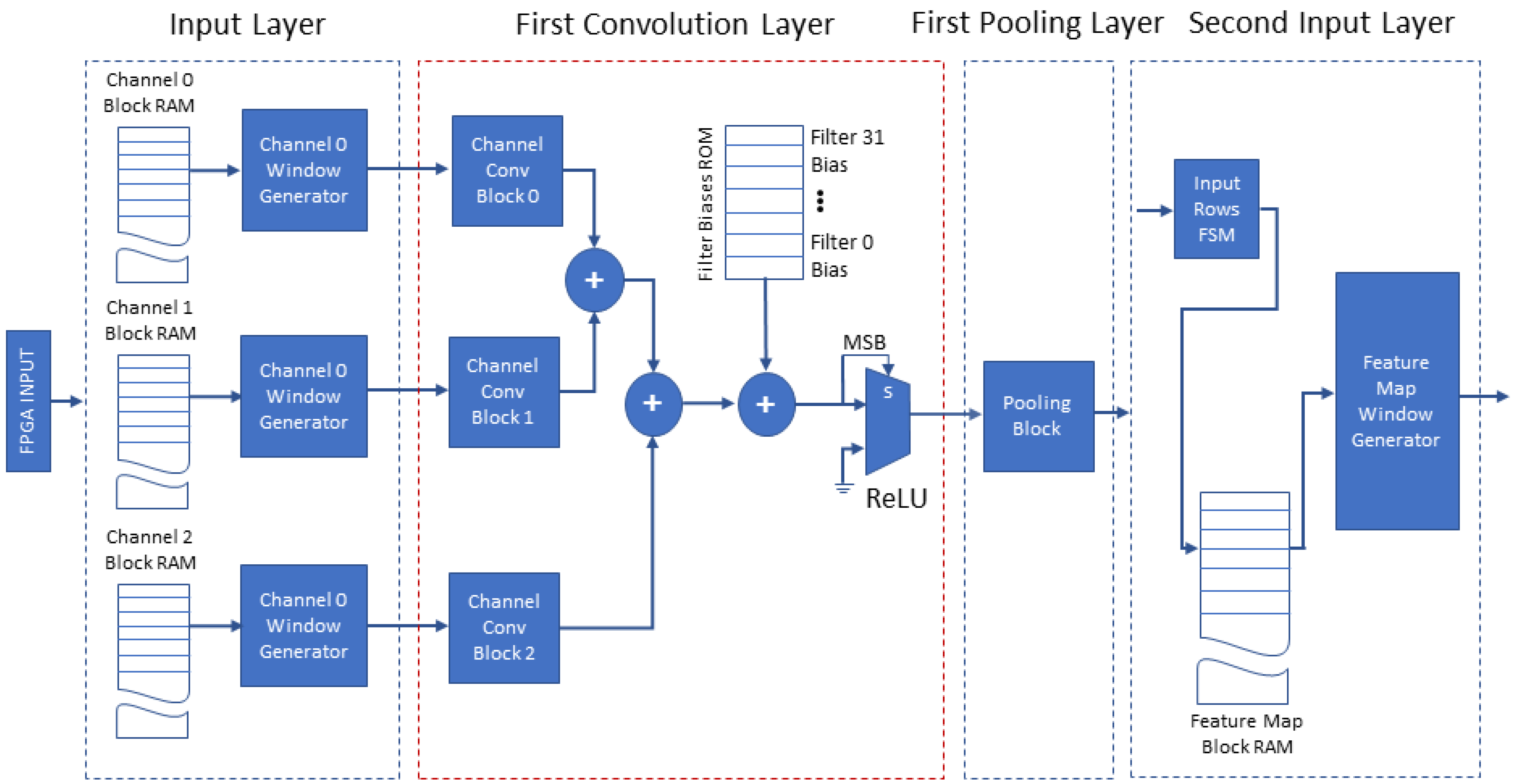
4.3. VHDL Blocks
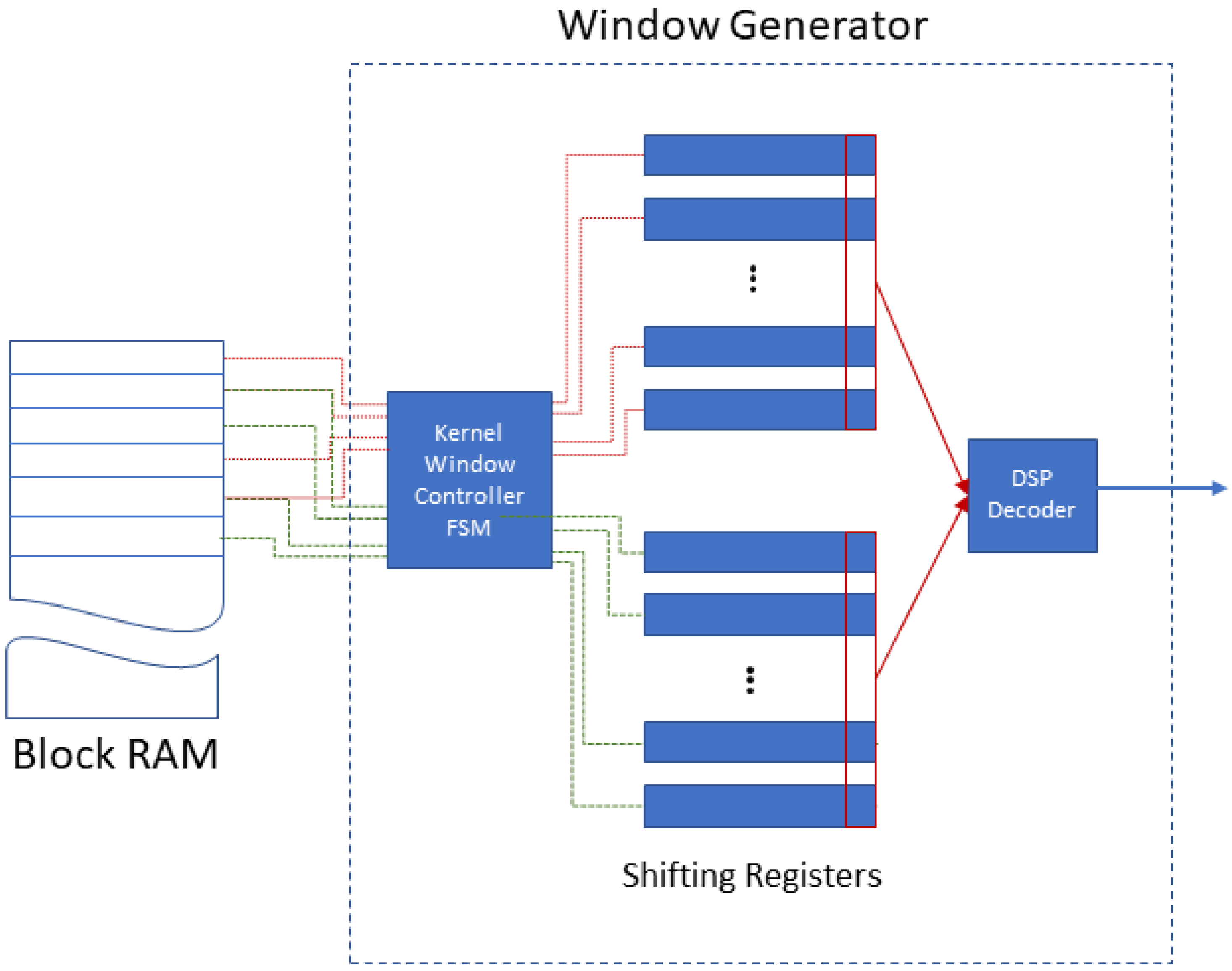
4.3.1. Input Block
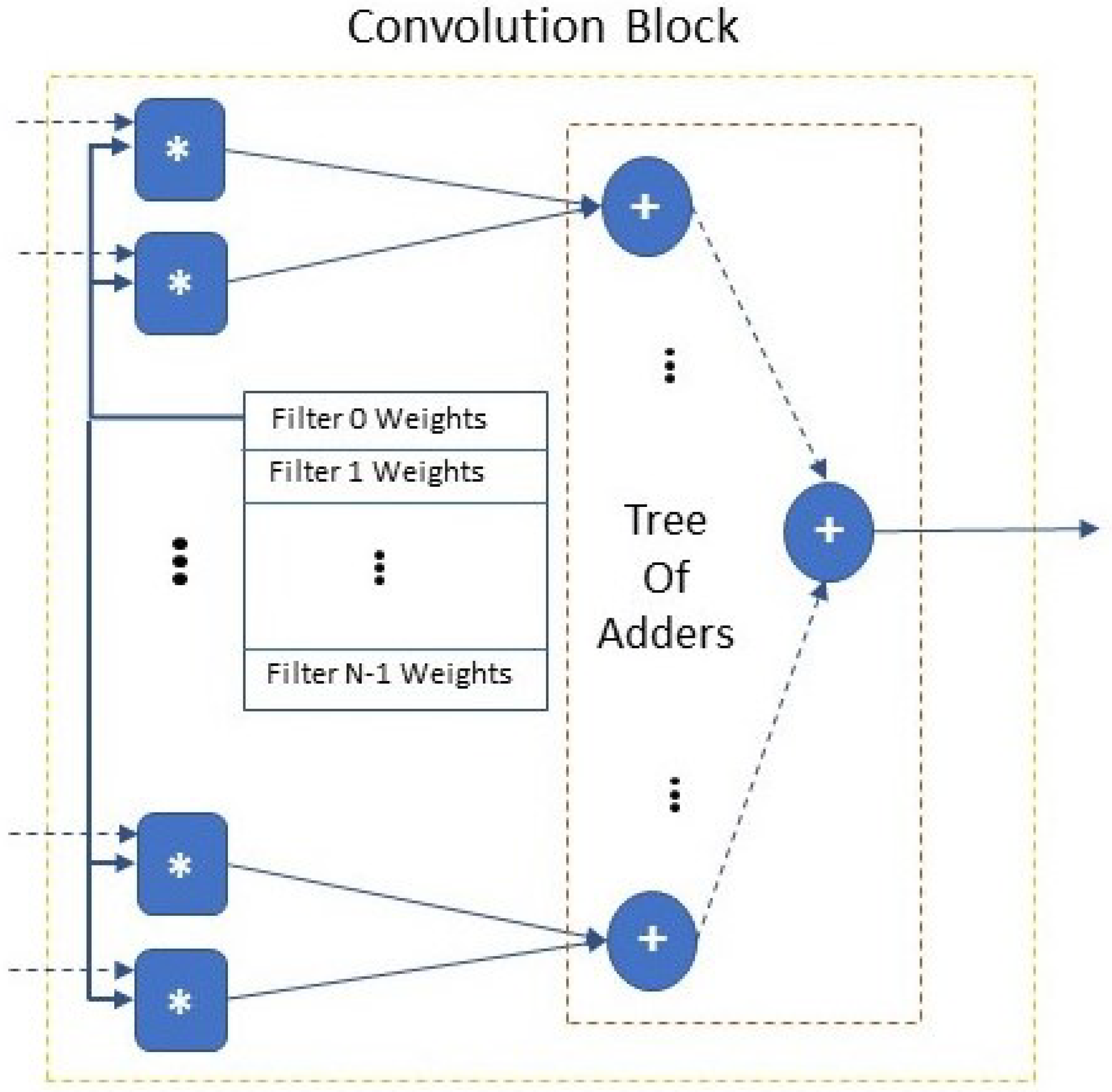
4.3.2. Convolution Block
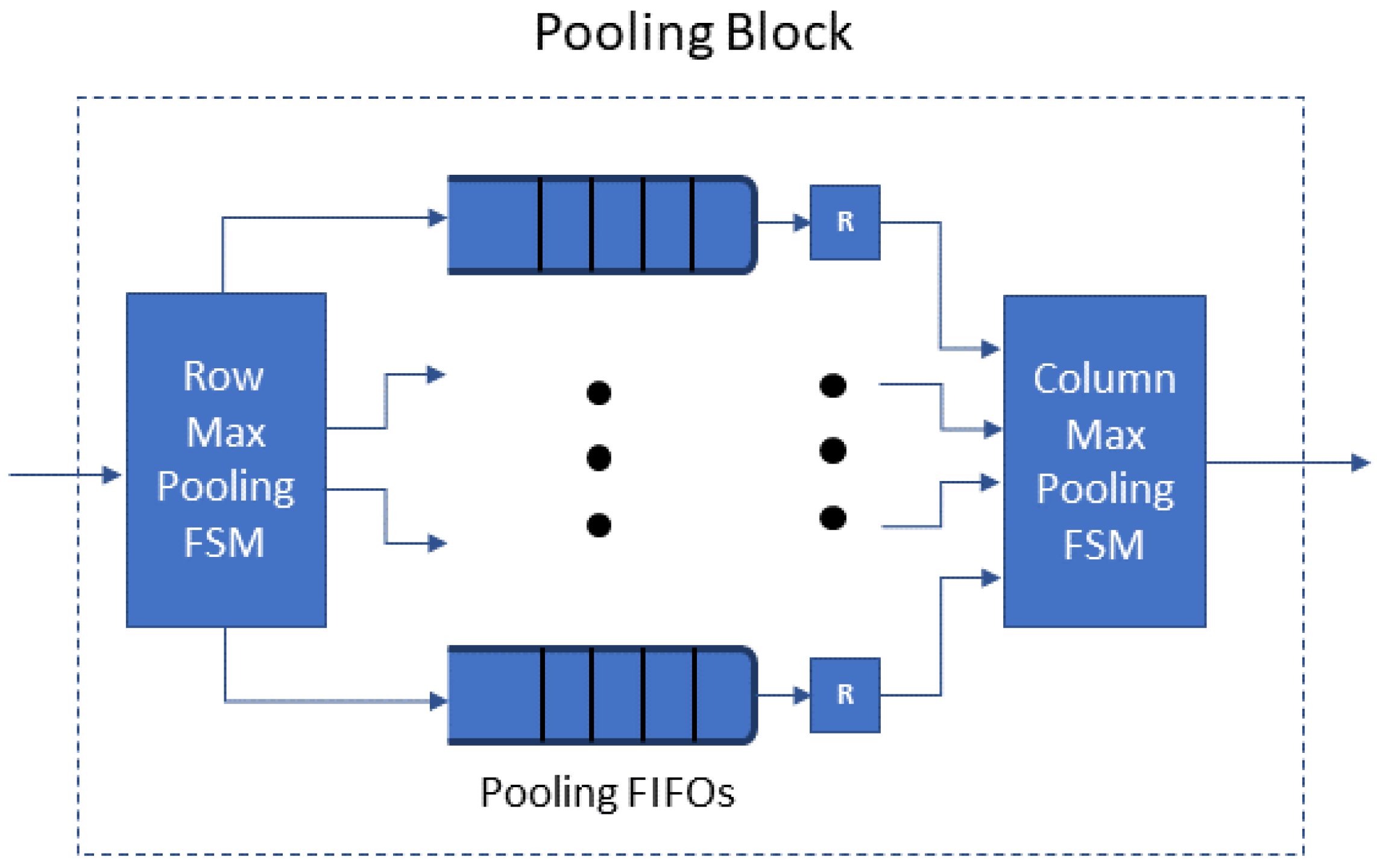
4.3.3. Pooling Block
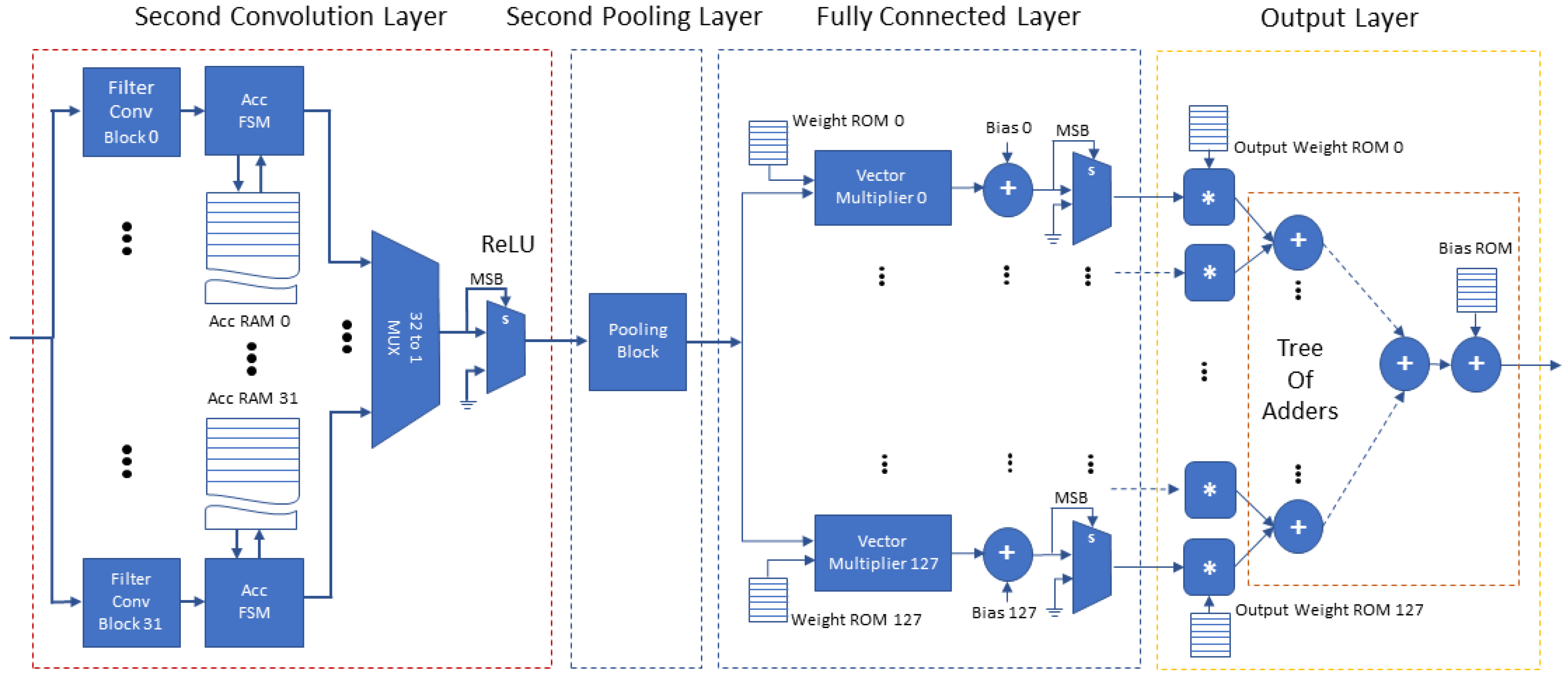
4.3.4. Vector Multiplier
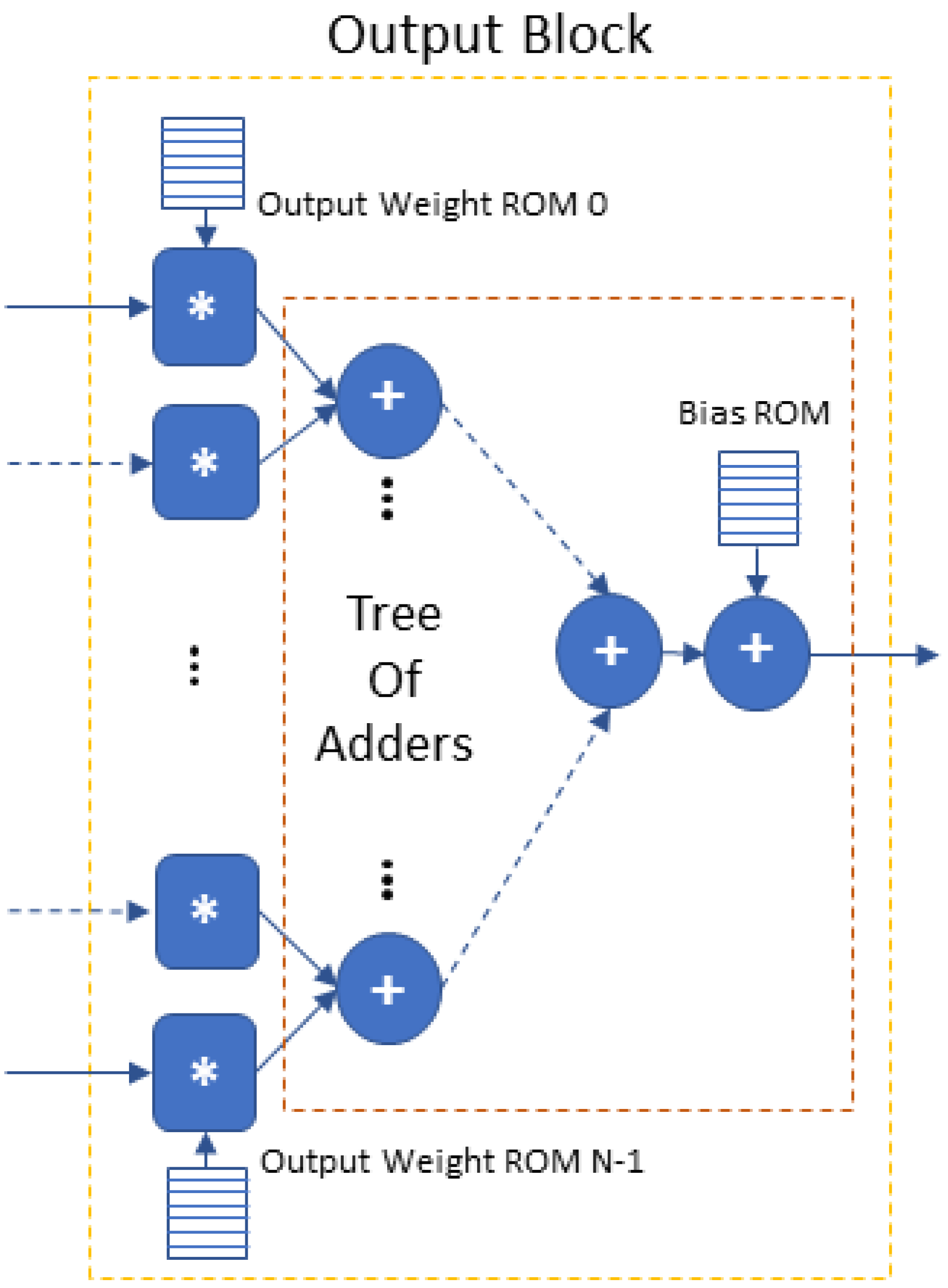
4.3.5. ReLU and Output Block
4.4. Methodology for Mapping the CNN on the FPGA
- (a)
- High efficiency in resource utilization and computing since all hardware is generated specifically for each CNN layer (module) and the layers are pipelined.
- (b)
- Significantly reduced memory requirements for the intermediate results and use of buffers only on the on-chip memory. The extensive pipeline of the proposed approach allows for succeeding layers (modules) to directly consume the data generated by the preceding ones and thus minimize the buffering of the intermediate results.
- (c)
- Reduced latency for shallow CNNs designed for the target limited feature space classification tasks. This is achieved by the parallelization strategy, the pipelining between the VHDL implemented layers (modules) and the use of only low-latency on-chip RAM.
- Buffers between layers and speed-up: The effort is given to parallelize the N filters in each convolution layer (except the first). Assuming that a convolution layer is designed with N filters, then the accelerator can have K parallel Convolution Blocks to complete the N convolution filters in steps. The accelerator design with is preferable because first, it maximizes the speed-up; second, it allows the pipelining of the input to every convolution block and avoids the buffer between this and its preceding layer.
- Reduce the memory of each layer: each convolution layer produces N feature maps and apart the first accumulates these in N memories. The size of each of these N memories depends on the size and the number of the preceding pooling layers. We denote by the dimensions of the th pooling layer. If the input image has size and there are p pooling layers of sizes each memory (of the N memories of the current layer) has size . Hence, higher-dimension pooling layers reduce the memory size and allow us to implement N parallel filters with their individual memories.
- The First Convolution Layer. The proposed parallelization technique for this layer leads to the balance of the speed-up against the available number of DSP blocks and block RAMs of the target FPGA device. The key computational role is realized by a parallel Structure consisting of one convolution block per channel; these blocks compute the convolution of all the input image’s channels (3 channels and 3 corresponding blocks in the case of RGB). Each block completes the convolution in real time and it forwards each result to the following pooling layer without a buffer, a design feature that significantly improves the memory requirements since the first convolution layer operates on the full-size input image (without any downsampling). The use of one (1) Structure to complete all the filters of the first convolution layer is resource efficient. It creates a parallel Structure by using first, 3 Convolution Blocks to compute the convolution of all the input image’s channels (3 in the case of RGB) and second, a tree of adders adding each channel’s convolution result in real time, forwarding it to the following pooling layer without a buffer. Avoiding this buffer is advantageous because it significantly improves the memory requirements considering that the first convolution layer operates on the input image without any downsampling. A single parallel Structure has to repeat this operation for every filter of the first convolution layer, but is the most resource efficient. If the following pooling layer has size , this layer will be slower by . Depending on the target FPGA’s resources, we can use k instances (, where the dimensions of the first pooling layer) of this Structure in parallel to improve the speed-up by k. We note here that each additional parallel Structure: adds a set of 3 convolution blocks, increasing the use of the FPGA DSP blocks; adds another memory buffer at the interface between the first pooling layer and the second input layer. However, the size of each additional input buffer is considerably reduced due to the high dimensions of the first pooling layer. Using k such Structures and the k buffers is limited by the available DSP blocks.
- Scalability. The aforementioned techniques lead to a scalable FPGA accelerator design. The architecture of the first convolution layer enables the engineer to opt for more performance or optimize the design for FPGA devices with limited resources. Moreover, the fully connected layers can use a Vector Multiplier per neuron: parallelizing the neurons is advantageous leading to a layer design irrespective of the size and the number of the feature maps produced by the preceding layer; more importantly, it is scalable.
5. Vessel Detection CNN FPGA Accelerator
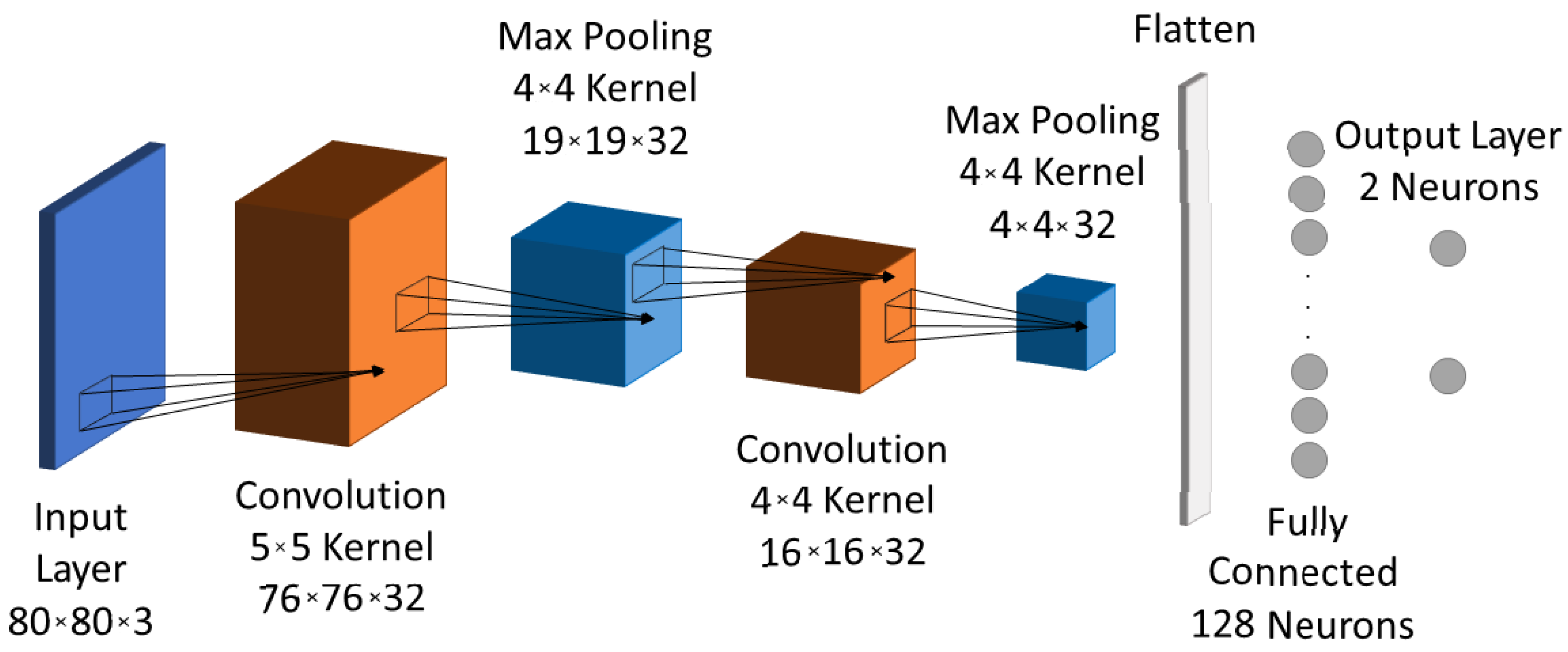
5.1. Model Architecture and Training
- Number of convolution layers: The proposed CNN with only two convolution layers achieves an accuracy of 97.6%, which is close to that of CNNs with more, e.g., a CNN with three convolution layers before any of the proposed optimizations achieved 98.5% accuracy.
- Ship orientation: The ship orientation is limited and, along with the proportion of the 80 × 80 image that the ship occupies, it leads to the use of 32 filters per convolution layer for achieving the best accuracy–computational cost trade-off.
- Max pooling layer: size achieved accuracy similar to that of size .
- The kernel’s size for each convolution layer: the first achieved improved accuracy with a kernel, while the choice for the second convolution layer is a kernel because its output has to be divisible by the following max pooling layer. As a result we did not use padding in the convolutions since this does not induce accuracy loss.
- Fully connected layer’s neurons: 128 neurons of the fully connected layer is the minimum number to use in order to avoid prediction accuracy loss.
5.2. Bit-Accurate Model (BAM)
5.3. FPGA Accelerator
6. Vessel Detection FPGA Accelerator Results and Comparison
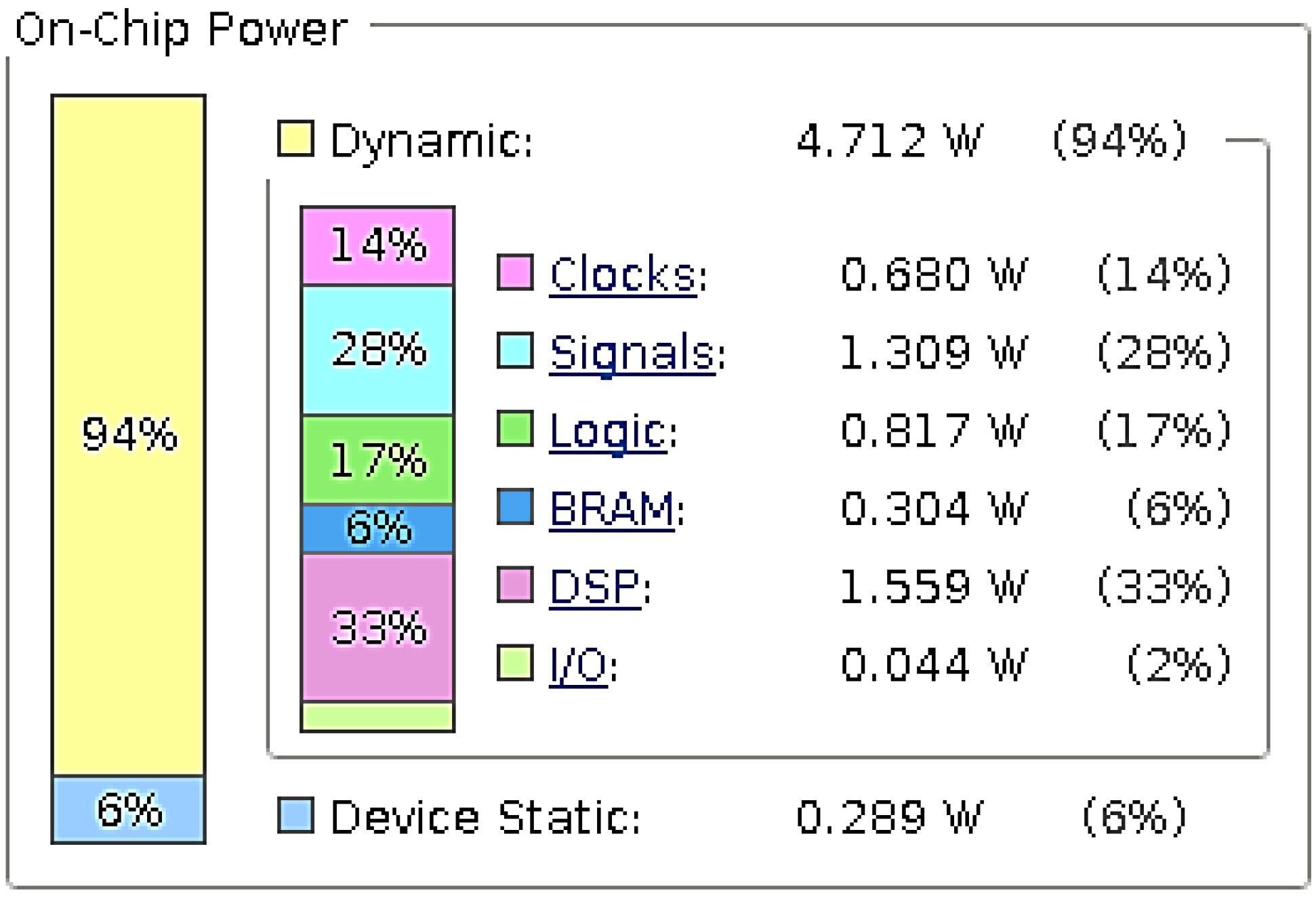
6.1. FPGA Implementation Results
6.2. Comparison to Edge Devices and Low Power Processors
6.3. Comparison to Other FPGA Accelerators
- (a)
- The same metrics between different FPGA accelerators may not be suitable for direct comparisons due to different FPGA platforms, benchmarking methodologies, etc.
- (b)
- While the majority of related works focus on accelerators for well-known CNN models, this work proposes a design approach that includes guidelines for designing CNN models from scratch, resulting in a custom model for vessel detection application.
- (c)
- This work focuses on accelerator designs for shallow CNNs suitable for binary and low feature space classification tasks while most works in the literature study complex and larger CNN models and result in substantially different architectures.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| API | Application Programming Interface |
| BAM | Bit-accurate Model |
| BRAM | Block Random Access Memory |
| CMX | Connection Matrix |
| CNN | Convolutional Neural Network |
| CPU | Central Processing Unit |
| CUDA | Compute Unified Device Architecture |
| DDR | Double Data Rate |
| DRAM | Dynamic Random Access Memory |
| DSP | Digital Signal Processor |
| FF | Flip-Flop |
| FIFO | First-In First-Out |
| FPGA | Field-programmable Gate Array |
| FSM | Finite-State Machine |
| GFLOPS | Giga Floating Point Operations Per Second |
| GOPS | Giga Operations Per Second |
| GPU | Graphics Processing Unit |
| GTX | Giga Texel Shader |
| HLS | High-level Synthesis |
| LUT | Lookup Table |
| LUTRAM | Lookup Table Random Access Memory |
| ML | Machine Learning |
| OBC | On-board Computing |
| PCIe | Peripheral Component Interconnect Express |
| RAM | Random Access Memory |
| R-CNN | Region-based CNN |
| ReLU | Rectified Linear Unit |
| RGB | Red Green Blue |
| ROM | Read-Only Memory |
| SHAVE | Streaming Hybrid Architecture Vector Engine |
| SSD | Single Shot MultiBox Detector |
| USB | Universal Serial Bus |
| VHDL | VHSIC Hardware Description Language |
| VHSIC | Very High Speed Integrated Circuit |
| YOLO | You Only Look Once |
References
- Mordvintsev, A.; Olah, C.; Tyka, M. Inceptionism: Going Deeper into Neural Networks. 2015. Available online: https://research.googleblog.com/2015/06/inceptionism-going-deeper-into-neural.html (accessed on 13 April 2022).
- Abdelouahab, K.; Pelcat, M.; Sérot, J.; Berry, F. Accelerating CNN inference on FPGAs: A Survey. arXiv 2018, arXiv:1806.01683. [Google Scholar]
- Lei, F.; Liu, X.; Dai, Q.; Ling, B. Shallow convolutional neural network for image classification. SN Appl. Sci. 2020, 2, 97. [Google Scholar] [CrossRef] [Green Version]
- Kyriakos, A.; Kitsakis, V.; Louropoulos, A.; Papatheofanous, E.A.; Patronas, G. High Performance Accelerator for CNN Applications. In Proceedings of the 2019 29th International Symposium on Power and Timing Modeling, Optimization and Simulation, Rhodes, Greece, 1–3 July 2019; pp. 135–140. [Google Scholar] [CrossRef]
- Li, H.; Lin, Z.; Shen, X.; Brandt, J. A convolutional neural network cascade for face detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, Boston, MA, USA, 7–12 June 2015; pp. 5325–5334. [Google Scholar] [CrossRef]
- Sermanet, P.; LeCun, Y. Traffic sign recognition with multi-scale Convolutional Networks. In Proceedings of the 2011 International Joint Conference on Neural Networks, San Jose, CA, USA, 31 July–5 August 2011; pp. 2809–2813. [Google Scholar] [CrossRef] [Green Version]
- Airbus Ship Detection Challenge. 2019. Available online: https://www.kaggle.com/c/airbus-ship-detection (accessed on 13 April 2022).
- Gorokhovatskyi, O.; Peredrii, O. Shallow Convolutional Neural Networks for Pattern Recognition Problems. In Proceedings of the 2018 IEEE Second International Conference on Data Stream Mining & Processing (DSMP), Lviv, Ukraine, 21–25 August 2018. [Google Scholar] [CrossRef]
- Planet: Ships-in-Satellite-Imagery. 2019. Available online: https://www.kaggle.com/rhammell/ships-in-satellite-imagery (accessed on 13 April 2022).
- Barry, B.; Brick, C.; Connor, F.; Donohoe, D.; Moloney, D.; Richmond, R.; O’Riordan, M.; Toma, V. Always-on Vision Processing Unit for Mobile Applications. IEEE Micro 2015, 35, 56–66. [Google Scholar] [CrossRef]
- España Navarro, J.; Samuelsson, A.; Gingsjö, H.; Barendt, J.; Dunne, A.; Buckley, L.; Reisis, D.; Kyriakos, A.; Papatheofanous, E.A.; Bezaitis, C.; et al. High-Performance Compute Board—A Fault-Tolerant Module for On-Boards Vision Processing. In Proceedings of the 2nd European Workshop on On-Board Data Processing (OBDP 2021), Online, 14–17 June 2021. [Google Scholar]
- Rapuano, E.; Meoni, G.; Pacini, T.; Dinelli, G.; Furano, G.; Giuffrida, G.; Fanucci, L. An FPGA-Based Hardware Accelerator for CNNs Inference on Board Satellites: Benchmarking with Myriad 2-Based Solution for the CloudScout Case Study. Remote Sens. 2021, 13, 1518. [Google Scholar] [CrossRef]
- Nvidia Jetson Nano. Available online: https://developer.nvidia.com/embedded/jetson-nano-developer-kit (accessed on 13 April 2022).
- Kim, J.H.; Grady, B.; Lian, R.; Brothers, J.; Anderson, J.H. FPGA-based CNN inference accelerator synthesized from multi-threaded C software. In Proceedings of the 2017 30th IEEE International System-on-Chip Conference (SOCC), Munich, Germany, 5–8 September 2017; pp. 268–273. [Google Scholar] [CrossRef] [Green Version]
- Solovyev, R.A.; Kalinin, A.A.; Kustov, A.G.; Telpukhov, D.V.; Ruhlov, V.S. FPGA Implementation of Convolutional Neural Networks with Fixed-Point Calculations. arXiv 2018, arXiv:1808.09945v1. Available online: https://arxiv.org/abs/1808.09945v1 (accessed on 13 April 2022).
- Zhang, C.; Li, P.; Sun, G.; Guan, Y.; Xiao, B.; Cong, J. Optimizing FPGA-based Accelerator Design for Deep Convolutional Neural Networks. In Proceedings of the 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2015; ACM: New York, NY, USA, 2015; pp. 161–170. [Google Scholar] [CrossRef]
- Sankaradas, M.; Jakkula, V.; Cadambi, S.; Chakradhar, S.; Durdanovic, I.; Cosatto, E.; Graf, H.P. A Massively Parallel Coprocessor for Convolutional Neural Networks. In Proceedings of the 2009 20th IEEE International Conference on Application-specific Systems, Architectures and Processors, Boston, MA, USA, 7–9 July 2009; pp. 53–60. [Google Scholar] [CrossRef]
- Peemen, M.; Setio, A.A.A.; Mesman, B.; Corporaal, H. Memory-centric accelerator design for Convolutional Neural Networks. In Proceedings of the 2013 IEEE 31st International Conference on Computer Design (ICCD), Asheville, NC, USA, 6–9 October 2013; pp. 13–19. [Google Scholar] [CrossRef] [Green Version]
- Liu, B.; Zou, D.; Feng, L.; Feng, S.; Fu, P.; Li, J. An FPGA-Based CNN Accelerator Integrating Depthwise Separable Convolution. Electronics 2019, 8, 281. [Google Scholar] [CrossRef] [Green Version]
- Pelcat, M.; Bourrasset, C.; Maggiani, L.; Berry, F. Design productivity of a high level synthesis compiler versus HDL. In Proceedings of the 2016 International Conference on Embedded Computer Systems: Architectures, Modeling and Simulation (SAMOS), Agios Konstantinos, Greece, 17–21 July 2016; pp. 140–147. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Y.; Gao, X.; Guo, X.; Liu, J.; Wang, E.; Mullins, R.; Cheung, P.Y.K.; Constantinides, G.; Xu, C.Z. Automatic Generation of Multi-Precision Multi-Arithmetic CNN Accelerators for FPGAs. In Proceedings of the 2019 International Conference on Field-Programmable Technology (ICFPT), Tianjin, China, 9–13 December 2019; pp. 45–53. [Google Scholar] [CrossRef] [Green Version]
- Sze, V.; Chen, Y.H.; Yang, T.J.; Emer, J.S. Efficient Processing of Deep Neural Networks: A Tutorial and Survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef] [Green Version]
- Lamoureux, J.; Luk, W. An Overview of Low-Power Techniques for Field-Programmable Gate Arrays. In Proceedings of the 2008 NASA/ESA Conference on Adaptive Hardware and Systems, Noordwijk, The Netherlands, 22–25 June 2008; pp. 338–345. [Google Scholar] [CrossRef] [Green Version]
- Dekker, R.; Bouma, H.; den Breejen, E.; van den Broek, B.; Hanckmann, P.; Hogervorst, M.; Mohamoud, A.; Schoemaker, R.; Sijs, J.; Tan, R.; et al. Maritime situation awareness capabilities from satellite and terrestrial sensor systems. In Proceedings of the MAST (Maritime Systems and Technology) Europe Conference 2013, Gdansk, Poland, 4–6 June 2013. [Google Scholar]
- Kanjir, U.; Greidanus, H.; Oštir, K. Vessel detection and classification from spaceborne optical images: A literature survey. Remote Sens. Environ. 2018, 207, 1–26. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. CoRR 2013, abs/1311.2524. Available online: https://arxiv.org/abs/1311.2524 (accessed on 14 April 2022).
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. CoRR 2015, abs/1506.01497. Available online: https://arxiv.org/abs/1506.01497 (accessed on 14 April 2022). [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. CoRR 2015, abs/1506.02640. Available online: https://arxiv.org/abs/1506.02640 (accessed on 14 April 2022).
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. CoRR 2015, abs/1512.02325. Available online: https://doi.org/10.1007/978-3-319-46448-0_2 (accessed on 14 April 2022). [CrossRef] [Green Version]
- Zhao, H.; Zhang, W.; Sun, H.; Xue, B. Embedded Deep Learning for Ship Detection and Recognition. Future Internet 2019, 11, 53. [Google Scholar] [CrossRef] [Green Version]
- Yu, J.-Y.; Huang, D.; Wang, L.-Y.; Guo, J.; Wang, Y.-H. A real-time on-board ship targets detection method for optical remote sensing satellite. In Proceedings of the 2016 IEEE 13th International Conference on Signal Processing (ICSP), Chengdu, China, 6–10 November 2016; pp. 204–208. [Google Scholar] [CrossRef]
- Giuffrida, G.; Fanucci, L.; Meoni, G.; Batič, M.; Buckley, L.; Dunne, A.; van Dijk, C.; Esposito, M.; Hefele, J.; Vercruyssen, N.; et al. The -Sat-1 Mission: The First On-Board Deep Neural Network Demonstrator for Satellite Earth Observation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5517414. [Google Scholar] [CrossRef]
- Furano, G.; Meoni, G.; Dunne, A.; Moloney, D.; Ferlet-Cavrois, V.; Tavoularis, A.; Byrne, J.; Buckley, L.; Psarakis, M.; Voss, K.O.; et al. Towards the Use of Artificial Intelligence on the Edge in Space Systems: Challenges and Opportunities. IEEE Aerosp. Electron. Syst. Mag. 2020, 35, 44–56. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Resource | Utilization | Utilization % |
|---|---|---|
| LUT | 50,743 | 16.71 |
| LUTRAM | 4228 | 3.23 |
| FF | 70,786 | 11.66 |
| BRAM | 96.5 | 9.37 |
| DSP | 843 | 30.11 |
| Execution Time (ms) | FPGA Speed-Up | |
|---|---|---|
| FPGA | 0.687 | - |
| CPU | 4.696 | 6.836 |
| GPU | 2.202 | 3.205 |
| Execution Time (ms) | Speed-Up | Power (W) | |
|---|---|---|---|
| Jetson Nano CPU | 440 | - | 10 |
| Jetson Nano GPU | 20.3 | 21.7 | 10 |
| Myriad2 1 SHAVE | 56.27 | 7.8 | 0.5 |
| Myriad2 12 SHAVE | 14.59 | 30.1 | 1 |
| FPGA Accelerator | 0.687 | 640.5 | 5 |
| [16] | [19] | [12] | Proposed Accelerator | |
|---|---|---|---|---|
| Precision | fl. point | fl. point | fixed-point | fixed-point |
| 32 bits | 32 bits | 16 bits | 17 bits | |
| Frequency (MHz) | 100 | 100 | 156 | 270 |
| FPGA | Xilinx Virtex | Xilinx Zynq | Xilinx Zynq | Xilinx Virtex |
| VC707 | 7100 | ZCU106 | VC707 | |
| CNN Size | 1.33 GFLOP | N/A | N/A | 18.122 MMAC |
| Performance (GOP/s) | 61.62 | 17.11 | N/A | 52.80 |
| Power (Watt) | 18.61 | 4.083 | 3.4 | 5.001 |
| Perf./Watt | 3.31 | 4.19 | N/A | 10.56 |
| (GOP/s/Watt) | ||||
| DSPs | 2240 | 1926 | 1175 | 843 |
| DSP Efficiency | 0.027 | 0.008 | N/A | 0.062 |
| (GOP/s/DSP) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kyriakos, A.; Papatheofanous, E.-A.; Bezaitis, C.; Reisis, D. Resources and Power Efficient FPGA Accelerators for Real-Time Image Classification. J. Imaging 2022, 8, 114. https://doi.org/10.3390/jimaging8040114
Kyriakos A, Papatheofanous E-A, Bezaitis C, Reisis D. Resources and Power Efficient FPGA Accelerators for Real-Time Image Classification. Journal of Imaging. 2022; 8(4):114. https://doi.org/10.3390/jimaging8040114
Chicago/Turabian StyleKyriakos, Angelos, Elissaios-Alexios Papatheofanous, Charalampos Bezaitis, and Dionysios Reisis. 2022. "Resources and Power Efficient FPGA Accelerators for Real-Time Image Classification" Journal of Imaging 8, no. 4: 114. https://doi.org/10.3390/jimaging8040114
APA StyleKyriakos, A., Papatheofanous, E. -A., Bezaitis, C., & Reisis, D. (2022). Resources and Power Efficient FPGA Accelerators for Real-Time Image Classification. Journal of Imaging, 8(4), 114. https://doi.org/10.3390/jimaging8040114