
Addressing Motion Blurs in Brain MRI Scans Using Conditional Adversarial Networks and Simulated Curvilinear Motions


Abstract
:1. Introduction
2. Related Work
3. Methods
3.1. Generative Adversarial Network
3.2. Our Approach
3.3. MC-GAN Generator
3.4. MC-GAN Discriminator
3.5. Loss Function
4. Data and Preprocessing
4.1. Real-World Datasets
4.2. Synthetic Datasets
4.2.1. Generating Synthetic Artifact-Free Data
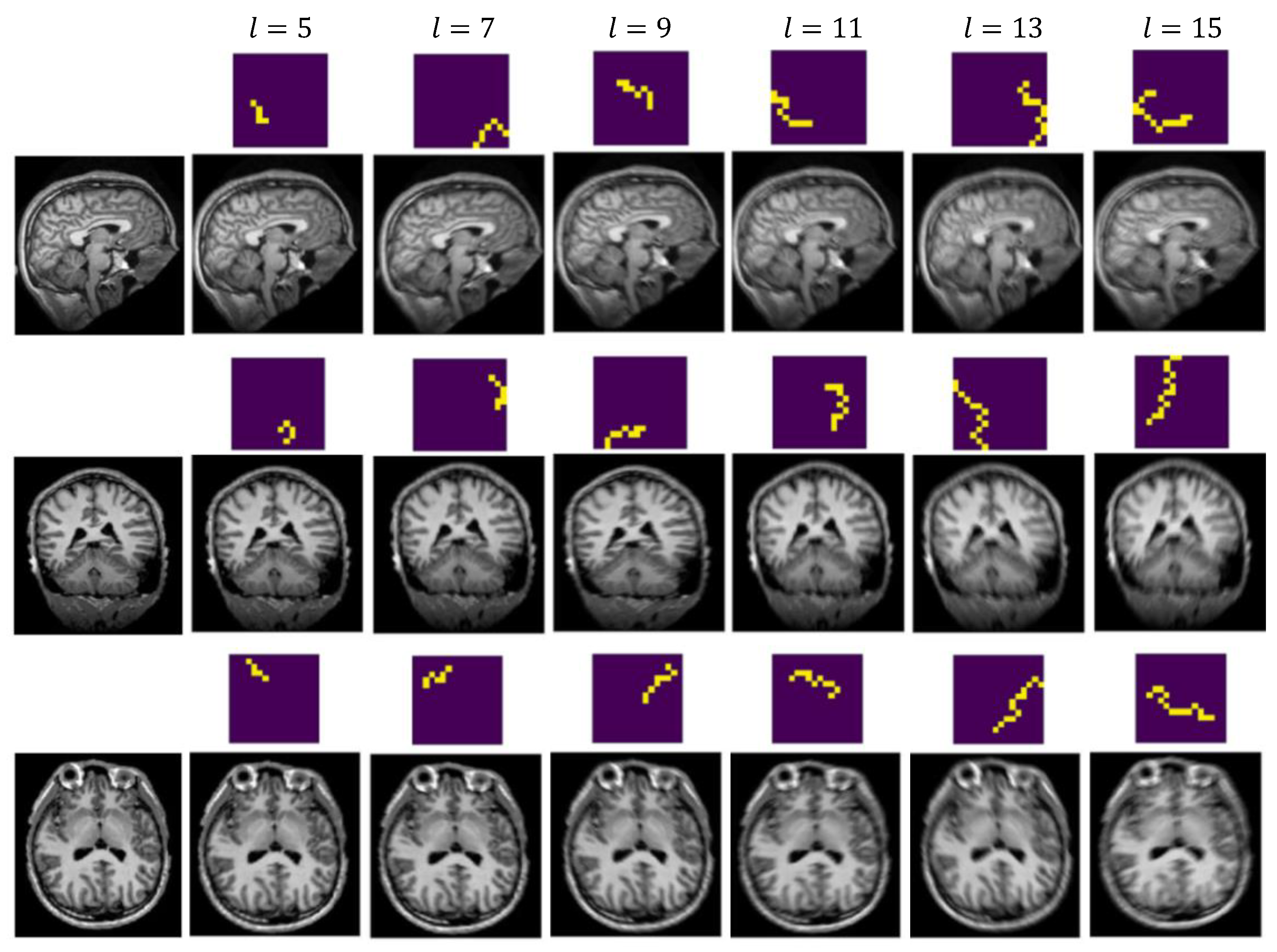
4.2.2. Generate Synthetic Artifact-Affected Data
5. Results
5.1. Quantitative Evaluation Metrics
- Root Mean Square Error (RMSE): RMSE measures pixel-wise root mean square error between a pair of images. A smaller RMSE indicates a higher similarity between the images. We compare the RMSEs of the original blurred image and corrected model output against the ground-truth motion-free image.
- Peak Signal to Noise Ratio (PSNR) [42]: PSNR is the ratio between the maximum possible power of a signal and the power of corrupting noise that affects the fidelity of its representation. Thus, a higher PSNR indicates a higher quality of an image. We calculated the PSNRs after scaling pixel intensities of the images to the interval [0, 255].
- Perception-based Image Quality Evaluator (PIQE) [43]: PIQE evaluates the image quality using two psychovisually-based fidelity estimates: block-wise distortion and similarity. The two estimates are combined into a single PIQE score to assess quality. The smaller the value of PIQE, the better the image quality.
5.2. Model Performance
Evaluation on Synthetic Images
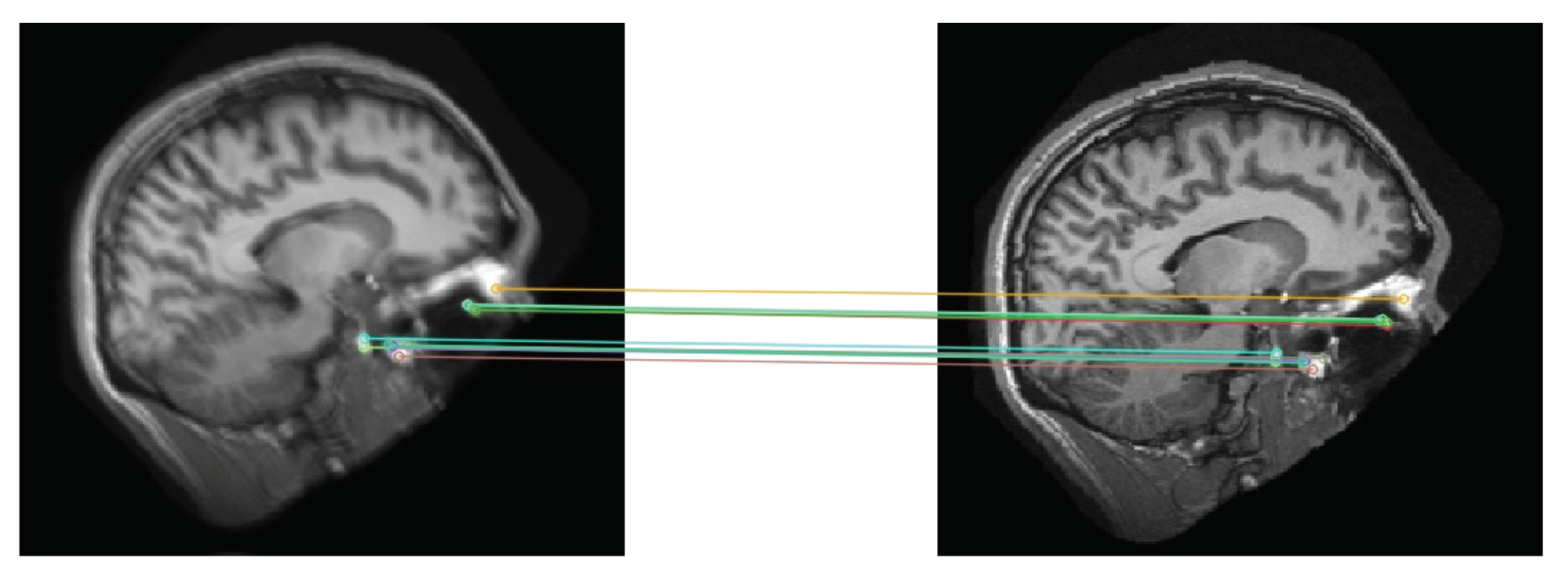
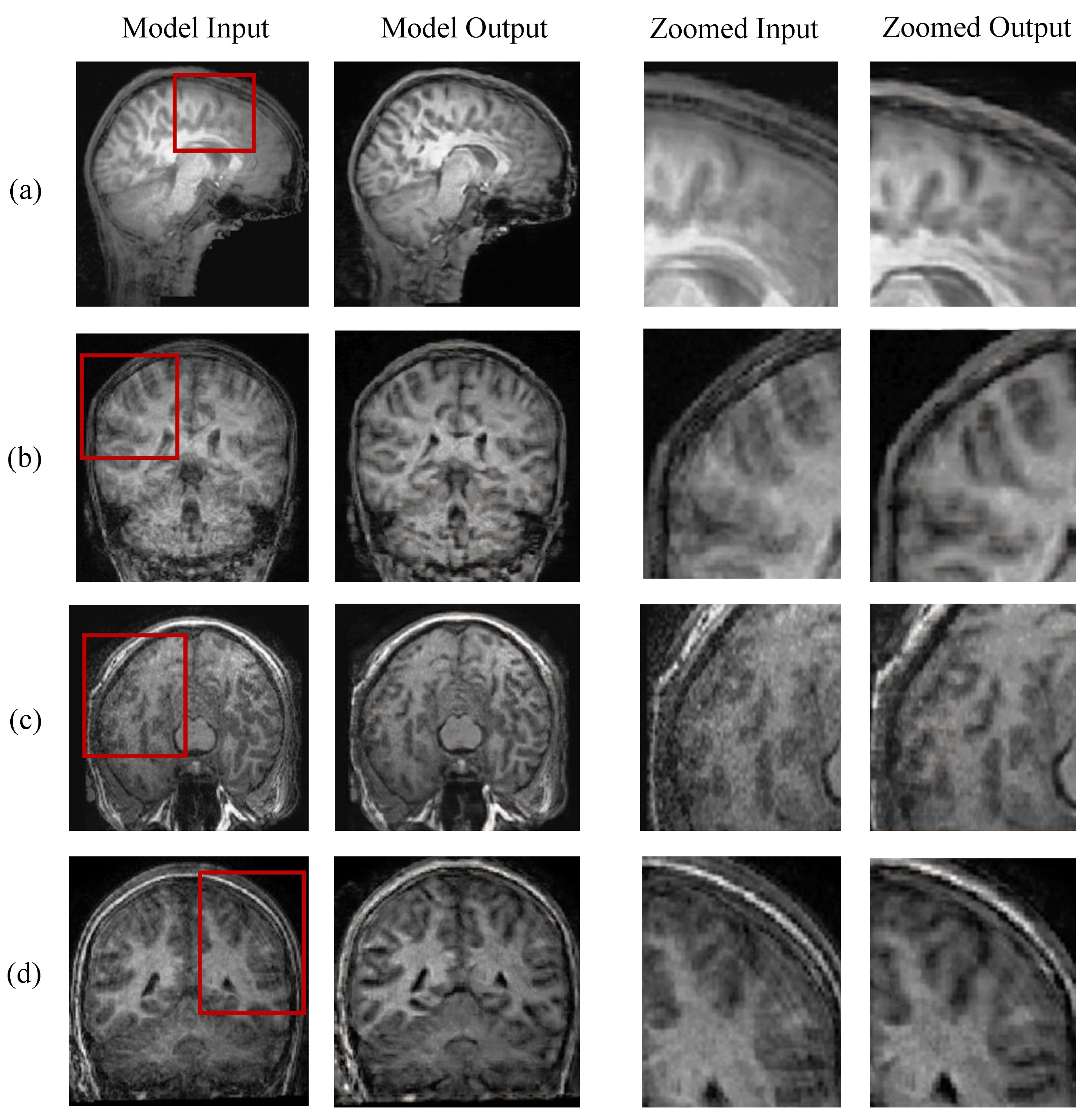
5.3. Evaluation on Real-World Scans
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Twieg, D.B. The k-trajectory formulation of the NMR imaging process with applications in analysis and synthesis of imaging methods. Med. Phys. 1983, 10, 610–621. [Google Scholar] [CrossRef] [PubMed]
- Wood, M.L.; Henkelman, R.M. MR image artifacts from periodic motion. Med. Phys. 1985, 12, 143–151. [Google Scholar] [CrossRef] [PubMed]
- Van de Walle, R.; Lemahieu, I.; Achten, E. Magnetic resonance imaging and the reduction of motion artifacts: Review of the principles. Technol. Health Care 1997, 5, 419–435. [Google Scholar] [CrossRef] [PubMed]
- Power, J.D.; Barnes, K.A.; Snyder, A.Z.; Schlaggar, B.L.; Petersen, S.E. Spurious but systematic correlations in functional connectivity MRI networks arise from subject motion. Neuroimage 2012, 59, 2142–2154. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- He, M.; Wang, X.; Zhao, Y. A calibrated deep learning ensemble for abnormality detection in musculoskeletal radiographs. Sci. Rep. 2021, 11, 9097. [Google Scholar] [CrossRef] [PubMed]
- Jones, R.M.; Sharma, A.; Hotchkiss, R.; Sperling, J.W.; Hamburger, J.; Ledig, C.; O’Toole, R.; Gardner, M.; Venkatesh, S.; Roberts, M.M.; et al. Assessment of a deep-learning system for fracture detection in musculoskeletal radiographs. NPJ Digit. Med. 2020, 3, 144. [Google Scholar] [CrossRef]
- Ozkaya, U.; Melgani, F.; Bejiga, M.B.; Seyfi, L.; Donelli, M. GPR B scan image analysis with deep learning methods. Measurement 2020, 165, 107770. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, Q.; Yang, K.; Yu, T.; Yao, J.; Liu, Y.; Wang, P.; He, Q. Deep Learning for the Detection and Recognition of Rail Defects in Ultrasound B-Scan Images. Transp. Res. Rec. 2021, 2675, 888–901. [Google Scholar] [CrossRef]
- Chea, P.; Mandell, J.C. Current applications and future directions of deep learning in musculoskeletal radiology. Skelet. Radiol. 2020, 49, 183–197. [Google Scholar] [CrossRef]
- Zhao, Y.; Ossowski, J.; Wang, X.; Li, S.; Devinsky, O.; Martin, S.P.; Pardoe, H.R. Localized motion artifact reduction on brain MRI using deep learning with effective data augmentation techniques. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–9. [Google Scholar]
- Sui, Y.; Afacan, O.; Gholipour, A.; Warfield, S.K. MRI Super-Resolution Through Generative Degradation Learning. In International Conference on Medical Image Computing and Computer-Assisted Intervention, Proceedings of the 24th International Conference, Strasbourg, France, 27 September–1 October 2021; Springer: Cham, Switzerland, 2021; pp. 430–440. [Google Scholar]
- Kocanaogullari, D.; Eksioglu, E.M. Deep Learning For Mri Reconstruction Using A Novel Projection Based Cascaded Network. In Proceedings of the 2019 IEEE 29th International Workshop on Machine Learning for Signal Processing (MLSP), Pittsburgh, PA, USA, 13–16 October 2019; pp. 1–6. [Google Scholar]
- Almansour, H.; Gassenmaier, S.; Nickel, D.; Kannengiesser, S.; Afat, S.; Weiss, J.; Hoffmann, R.; Othman, A.E. Deep learning-based superresolution reconstruction for upper abdominal magnetic resonance imaging: An analysis of image quality, diagnostic confidence, and lesion conspicuity. Investig. Radiol. 2021, 56, 509–516. [Google Scholar] [CrossRef] [PubMed]
- Foldiak, P.; Endres, D. Sparse coding. Scholarpedia 2008, 3, 2984. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Marcus, D.S.; Wang, T.H.; Parker, J.; Csernansky, J.G.; Morris, J.C.; Buckner, R.L. Open Access Series of Imaging Studies (OASIS): Cross-sectional MRI data in young, middle aged, nondemented, and demented older adults. J. Cogn. Neurosci. 2007, 19, 1498–1507. [Google Scholar] [CrossRef] [Green Version]
- Di Martino, A.; Yan, C.G.; Li, Q.; Denio, E.; Castellanos, F.X.; Alaerts, K.; Anderson, J.S.; Assaf, M.; Bookheimer, S.Y.; Dapretto, M.; et al. The autism brain imaging data exchange: Towards a large-scale evaluation of the intrinsic brain architecture in autism. Mol. Psychiatry 2014, 19, 659–667. [Google Scholar] [CrossRef]
- Richardson, W.H. Bayesian-based iterative method of image restoration. J. Opt. Soc. Am. 1972, 62, 55–59. [Google Scholar] [CrossRef]
- Murli, A.; D’Amore, L.; De Simone, V. The wiener filter and regularization methods for image restoration problems. In Proceedings of the 10th International Conference on Image Analysis and Processing, Venice, Italy, 27–29 September 1999; pp. 394–399. [Google Scholar]
- Khetkeeree, S.; Liangrocapart, S. Image Restoration Using Optimized Weiner Filtering Based on Modified Tikhonov Regularization. In Proceedings of the 2019 IEEE 4th International Conference on Signal and Image Processing (ICSIP), Wuxi, China, 19–21 July 2019; pp. 1015–1020. [Google Scholar]
- Hussien, M.N.; Saripan, M.I. Computed tomography soft tissue restoration using Wiener filter. In Proceedings of the 2010 IEEE Student Conference on Research and Development (SCOReD), Kuala Lumpur, Malaysia, 13–14 December 2010; pp. 415–420. [Google Scholar]
- Aguena, M.L.; Mascarenha, N.D.; Anacleto, J.C.; Fels, S.S. MRI iterative super resolution with Wiener filter regularization. In Proceedings of the 2013 XXVI Conference on Graphics, Patterns and Images, Arequipa, Peru, 5–8 August 2013; pp. 155–162. [Google Scholar]
- Abdulmunem, A.A.; Hassan, A.K. Deblurring X-Ray Digital Image Using LRA Algorithm. J. Phys. Conf. Ser. 2019, 1294, 042002. [Google Scholar] [CrossRef]
- Fergus, R.; Singh, B.; Hertzmann, A.; Roweis, S.T.; Freeman, W.T. Removing camera shake from a single photograph. In ACM SIGGRAPH 2006 Papers; Association for Computing Machinery: New York, NY, USA, 2006; pp. 787–794. [Google Scholar]
- Xu, L.; Zheng, S.; Jia, J. Unnatural l0 sparse representation for natural image deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 July 2013; pp. 1107–1114. [Google Scholar]
- Babacan, S.D.; Molina, R.; Do, M.N.; Katsaggelos, A.K. Bayesian blind deconvolution with general sparse image priors. In European Conference on Computer Vision, Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 341–355. [Google Scholar]
- Sun, J.; Cao, W.; Xu, Z.; Ponce, J. Learning a convolutional neural network for non-uniform motion blur removal. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 769–777. [Google Scholar]
- Noroozi, M.; Chandramouli, P.; Favaro, P. Motion deblurring in the wild. In German Conference on Pattern Recognition, Proceedings of the 39th German Conference, GCPR 2017, Basel, Switzerland, 12–15 September 2017; Springer: Cham, Switzerland, 2017; pp. 65–77. [Google Scholar]
- Gong, D.; Yang, J.; Liu, L.; Zhang, Y.; Reid, I.; Shen, C.; Van Den Hengel, A.; Shi, Q. From motion blur to motion flow: A deep learning solution for removing heterogeneous motion blur. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2319–2328. [Google Scholar]
- Eaton-Rosen, Z.; Bragman, F.; Ourselin, S.; Cardoso, M.J. Improving Data Augmentation for Medical Image Segmentation. 2018. Available online: https://openreview.net/forum?id=rkBBChjiG (accessed on 20 June 2021).
- Duffy, B.A.; Zhang, W.; Tang, H.; Zhao, L.; Law, M.; Toga, A.W.; Kim, H. Retrospective Correction of Motion Artifact Affected Structural MRI Images Using Deep Learning of Simulated Motion. 2018. Available online: https://openreview.net/forum?id=H1hWfZnjM (accessed on 20 June 2021).
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. Deblurgan: Blind motion deblurring using conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8183–8192. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2016; pp. 770–778. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In European Conference on Computer Vision, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 694–711. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved Techniques for Training Gans. Adv. Neural Inf. Process. Syst. 2016, 29. Available online: https://proceedings.neurips.cc/paper/2016/hash/8a3363abe792db2d8761d6403605aeb7-Abstract.html (accessed on 10 November 2021).
- Pardoe, H.R.; Hiess, R.K.; Kuzniecky, R. Motion and morphometry in clinical and nonclinical populations. Neuroimage 2016, 135, 177–185. [Google Scholar] [CrossRef] [PubMed]
- Ossowski, J. Modeling Inter-subject Brain Morphological Variability (Animation). Available online: https://storm.cis.fordham.edu/yzhao/100_distortions_BW.mp4 (accessed on 22 September 2021).
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Salomon, D. Data Compression: The Complete Reference; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Chan, R.W.; Goldsmith, P.B. A psychovisually-based image quality evaluator for JPEG images. In Proceedings of the Smc 2000 IEEE International Conference on Systems, Man and Cybernetics, ‘Cybernetics Evolving to Systems, Humans, Organizations, and Their Complex Interactions’, Nashville, TN, USA, 8–11 October 2000; Volume 2, pp. 1541–1546. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PSNR Level | Model | Pixel-Wise RMSE | PSNR (dB) | ||||
|---|---|---|---|---|---|---|---|
| Degraded vs. Target | Corrected vs. Target | Reduction (%) | Degraded vs. Target | Corrected vs. Target | Gain | ||
| <17 | MC-GAN (x) | 0.162 (0.022) | 0.115 (0.034) | 29.45% | 15.85 (1.04) | 19.18 (2.50) | 3.33 |
| MC-GAN (y) | 0.161 (0.025) | 0.097 (0.035) | 40.03% | 15.93 (1.06) | 20.82 (2.95) | 4.89 | |
| MC-GAN (z) | 0.167 (0.028) | 0.101 (0.045) | 39.45% | 15.66 (1.22) | 20.60 (3.30) | 4.94 | |
| MC-GAN (xyz) | 0.163 (0.024) | 0.110 (0.035) | 32.65% | 15.81 (1.10) | 19.56 (2.59) | 3.76 | |
| x-direction | 0.162 (0.022) | 0.120 (0.032) | 26.43% | 15.85 (1.04) | 18.75 (2.26) | 2.90 | |
| y-direction | 0.161 (0.025) | 0.097 (0.031) | 39.58% | 15.93 (1.06) | 20.61 (2.47) | 4.67 | |
| z-direction | 0.167 (0.028) | 0.102 (0.039) | 38.97% | 15.66 (1.22) | 20.33 (2.73) | 4.67 | |
| MC-GAN (x) | 0.133 (0.004) | 0.097 (0.023) | 27.31% | 17.53 (0.27) | 20.53 (2.02) | 3.00 | |
| MC-GAN (y) | 0.132 (0.005) | 0.086 (0.025) | 35.37% | 17.57 (0.30) | 21.72 (2.50) | 4.15 | |
| MC-GAN (z) | 0.132 (0.004) | 0.090 (0.028) | 30.79% | 17.56 (0.29) | 21.17 (2.68) | 3.60 | |
| MC-GAN (xyz) | 0.133 (0.004) | 0.095 (0.021) | 28.39% | 17.55 (0.28) | 20.67 (1.96) | 3.12 | |
| x-direction | 0.133 (0.004) | 0.100 (0.021) | 24.45% | 17.53 (0.27) | 20.14 (1.74) | 2.61 | |
| y-direction | 0.132 (0.005) | 0.089 (0.021) | 32.37% | 17.57 (0.30) | 21.20 (2.01) | 3.62 | |
| z-direction | 0.132 (0.004) | 0.090 (0.022) | 30.74% | 17.56 (0.29) | 21.12 (2.05) | 3.55 | |
| MC-GAN (x) | 0.120 (0.004) | 0.085 (0.019) | 28.50% | 18.45 (0.28) | 21.57 (1.89) | 3.12 | |
| MC-GAN (y) | 0.118 (0.004) | 0.08 (0.022) | 32.81% | 18.54 (0.28) | 22.3 (2.34) | 3.77 | |
| MC-GAN (z) | 0.119 (0.004) | 0.079 (0.023) | 33.15% | 18.52 (0.28) | 22.36 (2.45) | 3.84 | |
| MC-GAN (xyz) | 0.119 (0.004) | 0.085 (0.019) | 28.34% | 18.50 (0.29) | 21.60 (1.92) | 3.10 | |
| x-direction | 0.120 (0.004) | 0.090 (0.017) | 24.77% | 18.45 (0.28) | 21.07 (1.62) | 2.62 | |
| y-direction | 0.118 (0.004) | 0.084 (0.019) | 29.04% | 18.54 (0.28) | 21.73 (1.96) | 3.20 | |
| z-direction | 0.119 (0.004) | 0.082 (0.020) | 31.30% | 18.52 (0.29) | 22.02 (2.04) | 3.50 | |
| MC-GAN (x) | 0.107 (0.003) | 0.077 (0.016) | 27.97% | 19.43 (0.28) | 22.45 (1.71) | 3.02 | |
| MC-GAN (y) | 0.106 (0.004) | 0.071 (0.018) | 33.31% | 19.48 (0.29) | 23.26 (2.14) | 3.79 | |
| MC-GAN (z) | 0.106 (0.004) | 0.071 (0.019) | 33.50% | 19.48 (0.29) | 23.31 (2.26) | 3.84 | |
| MC-GAN (xyz) | 0.106 (0.004) | 0.076 (0.016) | 28.60% | 19.47 (0.29) | 22.57 (1.76) | 3.10 | |
| x-direction | 0.107 (0.003) | 0.083 (0.015) | 22.79% | 19.43 (0.28) | 21.80 (1.49) | 2.37 | |
| y-direction | 0.106 (0.004) | 0.075 (0.016) | 29.66% | 19.48 (0.29) | 22.72 (1.80) | 3.24 | |
| z-direction | 0.106 (0.004) | 0.073 (0.015) | 31.05% | 19.48 (0.29) | 22.88 (1.73) | 3.40 | |
| >20 | MC-GAN (x) | 0.089 (0.009) | 0.067 (0.012) | 24.49% | 21.09 (0.97) | 23.61 (1.53) | 2.53 |
| MC-GAN (y) | 0.088 (0.010) | 0.061 (0.014) | 30.59% | 21.19 (1.13) | 24.50 (1.90) | 3.32 | |
| MC-GAN (z) | 0.089 (0.010) | 0.064 (0.015) | 27.60% | 21.11 (1.06) | 24.06 (1.89) | 2.96 | |
| MC-GAN (xyz) | 0.088 (0.010) | 0.066 (0.013) | 25.12% | 21.14 (1.08) | 23.76 (1.69) | 2.62 | |
| x-direction | 0.089 (0.009) | 0.071 (0.012) | 20.44% | 21.09 (0.97) | 23.14 (1.42) | 2.05 | |
| y-direction | 0.088 (0.010) | 0.064 (0.013) | 27.33% | 21.19 (1.13) | 24.06 (1.69) | 2.87 | |
| z-direction | 0.089 (0.010) | 0.067 (0.014) | 24.22% | 21.11 (1.06) | 23.62 (1.71) | 2.52 | |
| Models | PIQE | ||
|---|---|---|---|
| Degraded | Corrected | Reduction (%) | |
| MC-GAN (x) | 9.09 (3.77) | 7.98 (5.23) | 12.26% |
| MC-GAN (y) | 12.17 (6.62) | 9.01 (7.52) | 26.01% |
| MC-GAN (z) | 12.45 (10.65) | 6.86 (5.05) | 44.88% |
| MC-GAN (xyz) | 11.24 (7.71) | 9.11 (7.00) | 18.97% |
| x-direction | 9.09 (3.77) | 8.38 (5.65) | 7.84% |
| y-direction | 12.17 (6.62) | 9.75 (7.13) | 19.92% |
| z-direction | 12.45 (10.65) | 9.19 (7.14) | 26.18% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Zhao, Y. Addressing Motion Blurs in Brain MRI Scans Using Conditional Adversarial Networks and Simulated Curvilinear Motions. J. Imaging 2022, 8, 84. https://doi.org/10.3390/jimaging8040084
Li S, Zhao Y. Addressing Motion Blurs in Brain MRI Scans Using Conditional Adversarial Networks and Simulated Curvilinear Motions. Journal of Imaging. 2022; 8(4):84. https://doi.org/10.3390/jimaging8040084
Chicago/Turabian StyleLi, Shangjin, and Yijun Zhao. 2022. "Addressing Motion Blurs in Brain MRI Scans Using Conditional Adversarial Networks and Simulated Curvilinear Motions" Journal of Imaging 8, no. 4: 84. https://doi.org/10.3390/jimaging8040084
APA StyleLi, S., & Zhao, Y. (2022). Addressing Motion Blurs in Brain MRI Scans Using Conditional Adversarial Networks and Simulated Curvilinear Motions. Journal of Imaging, 8(4), 84. https://doi.org/10.3390/jimaging8040084