
Discriminative Shape Feature Pooling in Deep Neural Networks



Abstract
:1. Introduction
- Due to the intervention of the injected discriminative shape features, the model with DSF-Pooling obtains reliable performance improvement, especially for the natural scenes and living beings categories;
- Guided by the handcrafted features, the proposed deep network model reduces the learning curve, i.e., fast convergence;
- The proposed framework is generic and suitable for various handcrafted features and network architectures;
- The proposed pooling method has comparable performance to the other state-of-the-art methods.
2. Related Work
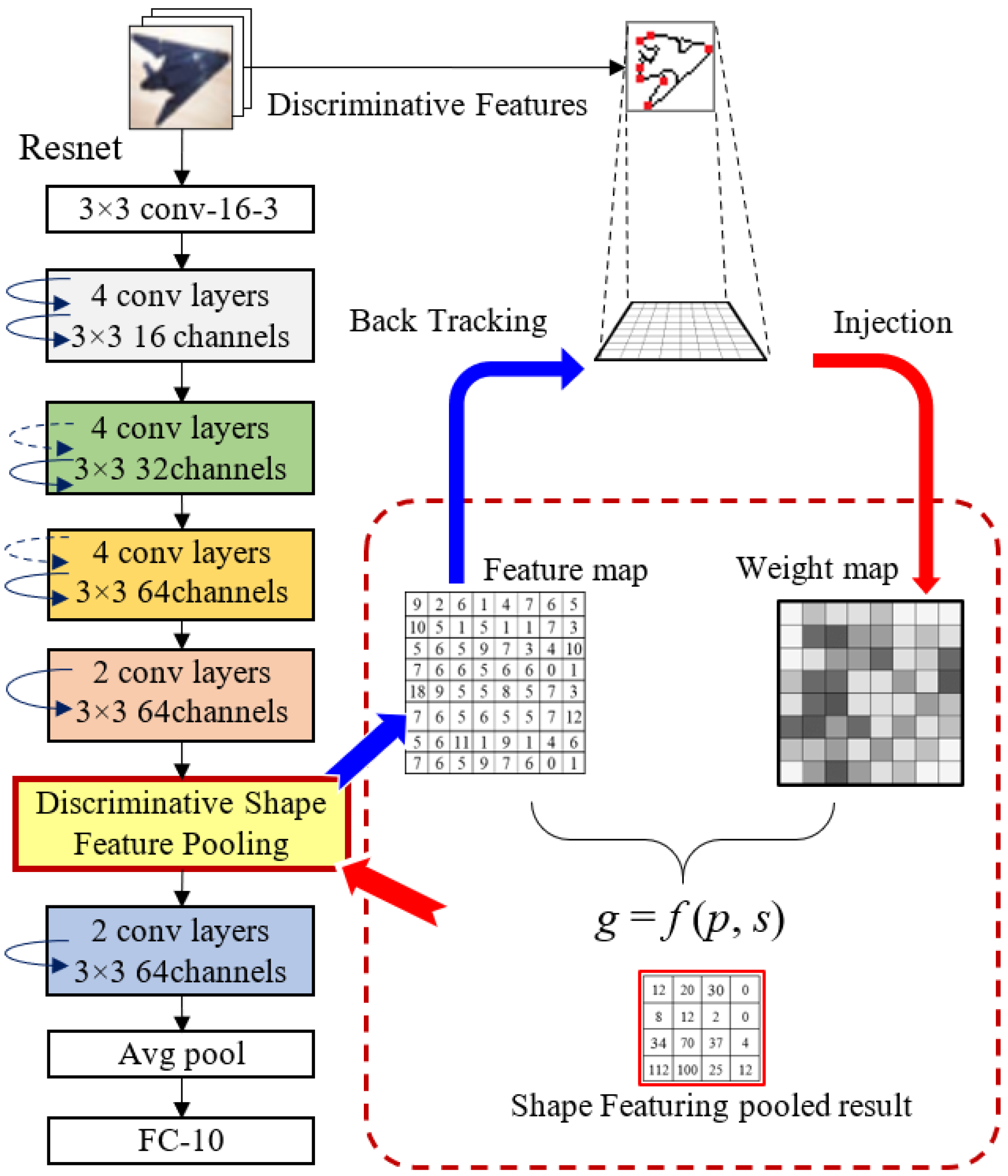
3. Proposed Method
3.1. Handcrafted Discriminative Shape Features
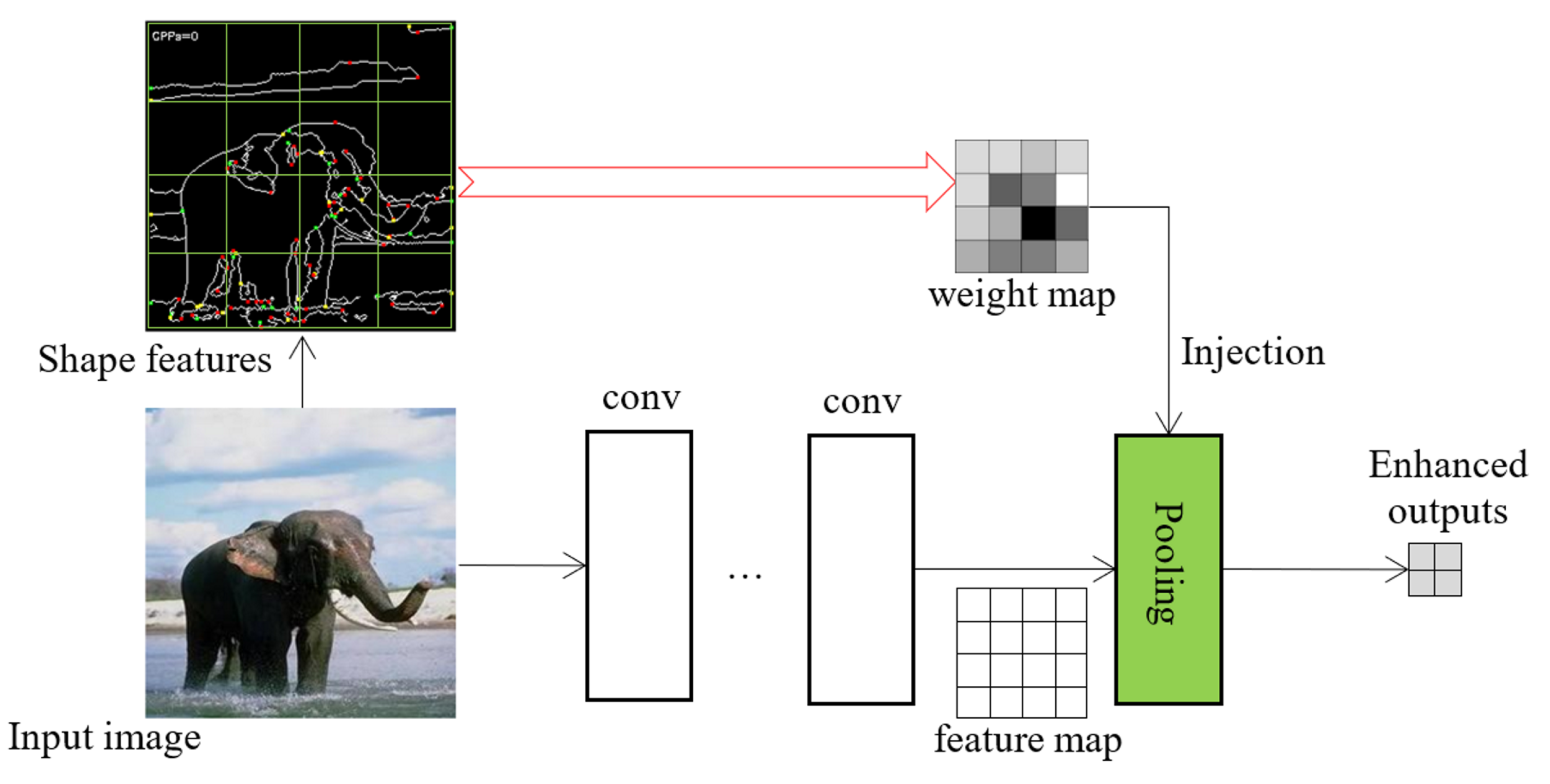
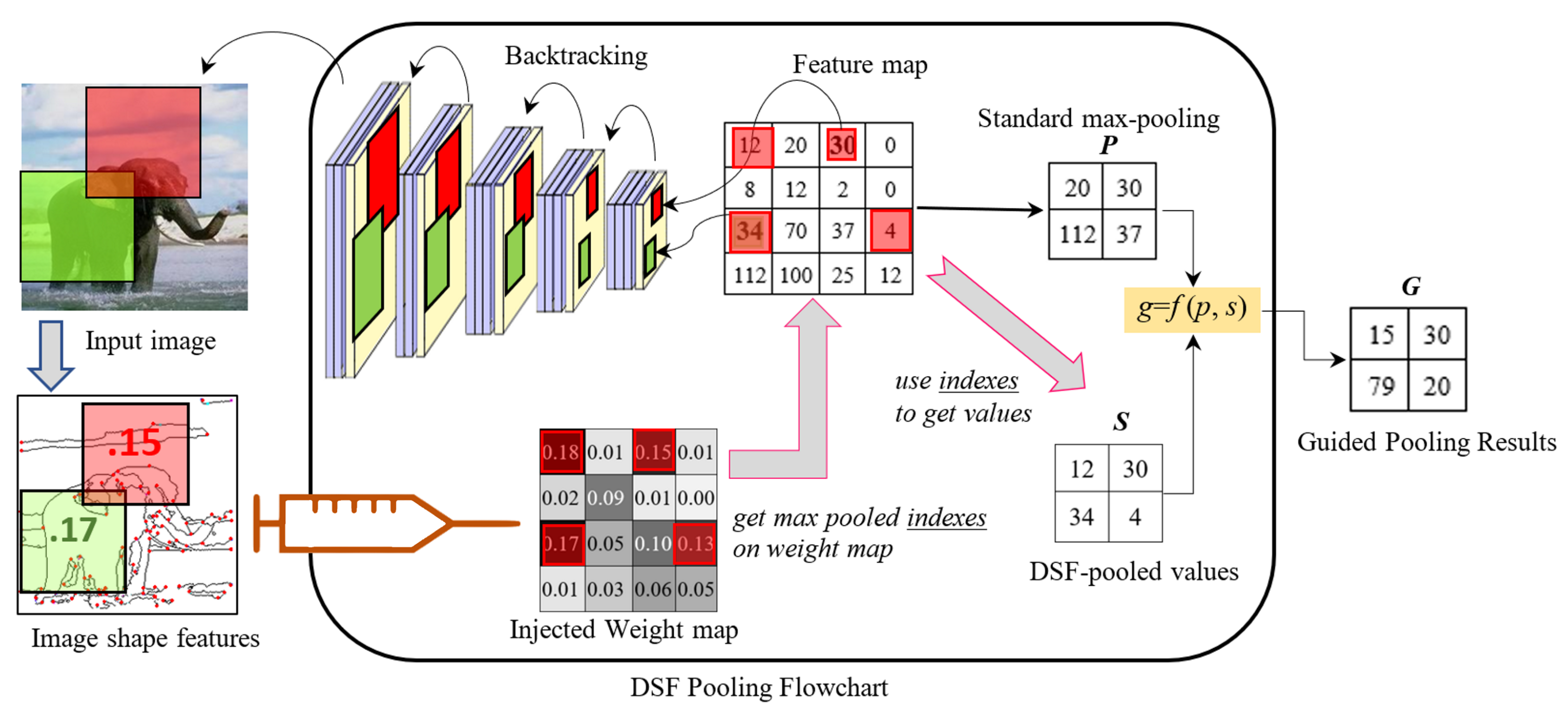
3.2. Discriminative Shape Feature Pooling
3.3. Case Study
3.4. Algorithms
Algorithm 1: Backtracking and feature extraction. |
Input: Input image , preprocessed handcrafted features For each location , is the mapped region Compute according to in this mapped region using Equation (1) Output: feature-based weight map |
Algorithm 2: Discriminative shape feature pooling. |
Input: convoluted feature map , weight map For each pooling window in Output: New pooled values |
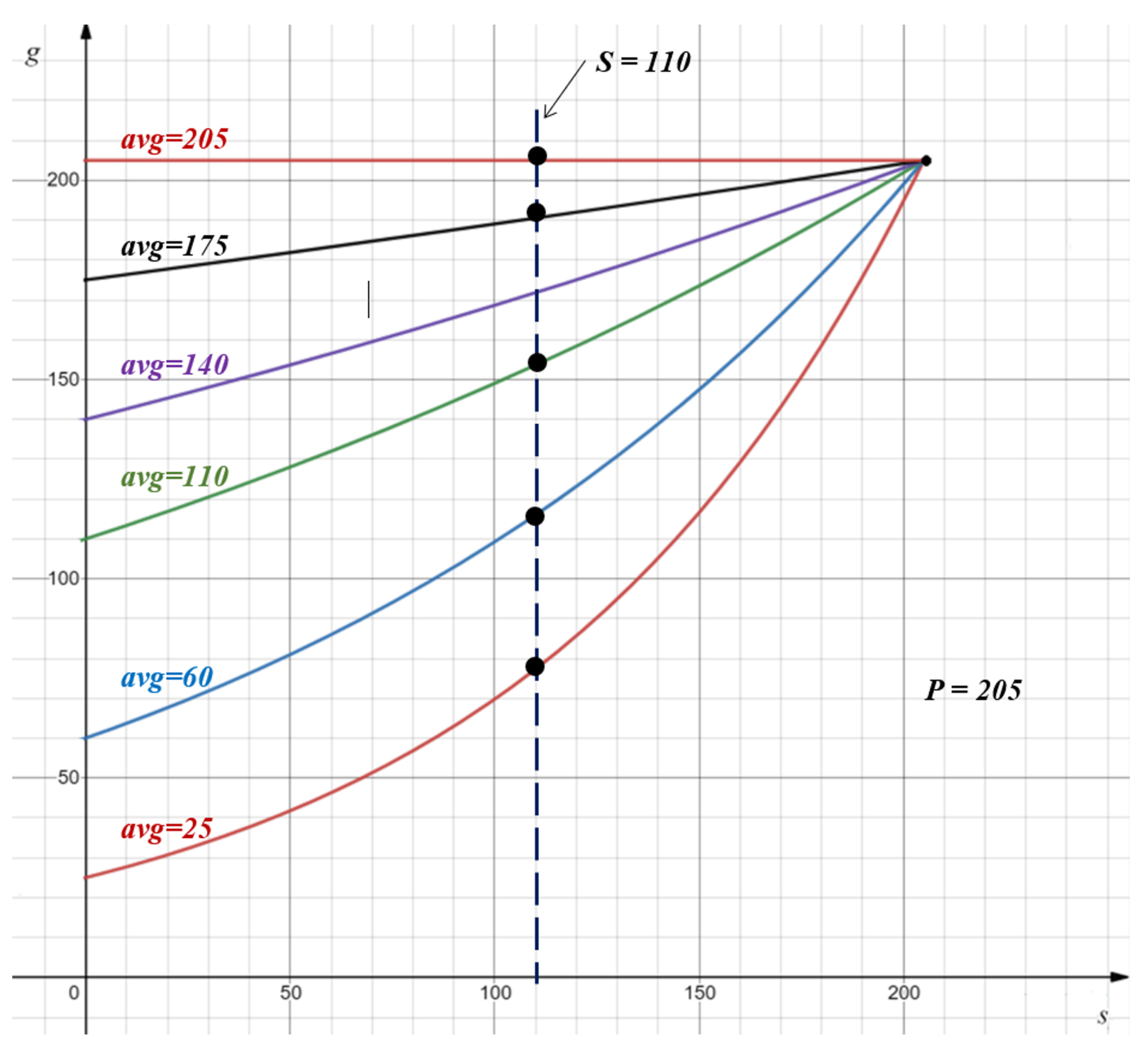
3.5. Back-Propagation
4. Experiments and Discussion
4.1. Ablation Studies
4.2. Alexnet with Pretrained Model
4.3. Pooling Method Comparisons on ImageNet 1K
4.4. Learning Efforts
4.5. Visualization of the DSF-Pooling Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Zhu, Z.; Yin, H.; Chai, Y.; Li, Y.; Qi, G. A novel multi-modality image fusion method based on image decomposition and sparse representation. Inf. Sci. 2018, 432, 516–529. [Google Scholar] [CrossRef]
- Zhu, Z.; Wei, H.; Hu, G.; Li, Y.; Qi, G.; Mazur, N. A Novel Fast Single Image Dehazing Algorithm Based on Artificial Multiexposure Image Fusion. IEEE Trans. Instrum. Meas. 2021, 70, 1–23. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional. Neural Netw. 2017, 60, 84–90. [Google Scholar]
- Zhu, Z.; Luo, Y.; Qi, G.; Meng, J.; Li, Y.; Mazur, N. Remote Sensing Image Defogging Networks Based on Dual Self-Attention Boost Residual Octave Convolution. Remote Sens. 2021, 13, 3104. [Google Scholar] [CrossRef]
- Qi, G.; Zhang, Y.; Wang, K.; Mazur, N.; Liu, Y.; Malaviya, D. Small Object Detection Method Based on Adaptive Spatial Parallel Convolution and Fast Multi-Scale Fusion. Remote Sens. 2022, 14, 420. [Google Scholar] [CrossRef]
- Jin, L.; Gao, S.; Li, Z.; Tang, J. Hand-crafted features or machine learnt features? Together they improve RGB-D object recognition. In Proceedings of the 2014 IEEE International Symposium on Multimedia, Taichung, Taiwan, 10–12 December 2014; pp. 311–319. [Google Scholar]
- Wu, S.; Chen, Y.C.; Li, X.; Wu, A.C.; You, J.J.; Zheng, W.S. An enhanced deep feature representation for person re-identification. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–8. [Google Scholar]
- Hu, G.; Gao, Q. A non-parametric statistics based method for generic curve partition and classification. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 3041–3044. [Google Scholar]
- Duda, R.O.; Hart, P.E. Use of the Hough transformation to detect lines and curves in pictures. Commun. ACM 1972, 15, 11–15. [Google Scholar] [CrossRef]
- Tahmasbi, A.; Saki, F.; Shokouhi, S.B. Classification of benign and malignant masses based on Zernike moments. Comput. Biol. Med. 2011, 41, 726–735. [Google Scholar] [CrossRef] [PubMed]
- Novak, C.L.; Shafer, S.A. Anatomy of a color histogram. In Proceedings of the CVPR, Champaign, IL, USA, 15–18 June 1992; Volume 92, pp. 599–605. [Google Scholar]
- Jian, M.; Liu, L. Texture image classification using visual perceptual texture features and gabor wavelet. J. Comput. 2009, 4, 763. [Google Scholar] [CrossRef]
- Liu, G.H.; Yang, J.Y. Content-based image retrieval using color difference histogram. Pattern Recognit. 2013, 46, 188–198. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Gool, L.V. Surf: Speeded up robust features. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 404–417. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary robust invariant scalable keypoints. In Proceedings of the2011 IEEE International Conference on Computer Vision (ICCV 2011), Barcelona, Spain, 6–13 November 2011; pp. 2548–2555. [Google Scholar]
- Csurka, G.; Dance, C.; Fan, L.; Willamowski, J.; Bray, C. Visual categorization with bags of keypoints. In Proceedings of the Workshop on Statistical Learning in Computer Vision, Washington, DC, USA, 27 June–2 July 2004; Volume 1, pp. 1–2. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Zheng, Z.; Li, Z.; Nagar, A. Compact Deep Neural Networks for Device-Based Image Classification. In Mobile Cloud Visual Media Computing; Springer: Berlin/Heidelberg, Germany, 2015; pp. 201–217. [Google Scholar]
- Wang, H.; Cruz-Roa, A.; Basavanhally, A.; Gilmore, H.; Shih, N.; Feldman, M.; Tomaszewski, J.; Gonzalez, F.; Madabhushi, A. Mitosis detection in breast cancer pathology images by combining handcrafted and convolutional neural network features. J. Med. Imaging 2014, 1, 034003. [Google Scholar] [CrossRef] [PubMed]
- Kashif, M.N.; Raza, S.E.A.; Sirinukunwattana, K.; Arif, M.; Rajpoot, N. Handcrafted features with convolutional neural networks for detection of tumor cells in histology images. In Proceedings of the 2016 IEEE 13th International Symposium on Biomedical Imaging (ISBI), Prague, Czech Republic, 13–16 April 2016; pp. 1029–1032. [Google Scholar]
- Sirinukunwattana, K.; Ahmed Raza, S.E.; Tsang, Y.W.; Snead, D.; Cree, I.; Rajpoot, N. A spatially constrained deep learning framework for detection of epithelial tumor nuclei in cancer histology images. In Proceedings of the International Workshop on Patch-Based Techniques in Medical Imaging, Munich, Germany, 9 October 2015; pp. 154–162. [Google Scholar]
- Gao, S.; Duan, L.; Tsang, I.W. DEFEATnet-A deep conventional image representation for image classification. IEEE Trans. Circuits Syst. Video Technol. 2015, 26, 494–505. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhu, Z.; Luo, Y.; Chen, S.; Qi, G.; Mazur, N.; Zhong, C.; Li, Q. Camera style transformation with preserved self-similarity and domain-dissimilarity in unsupervised person re-identification. J. Vis. Commun. Image Represent. 2021, 80, 103303. [Google Scholar] [CrossRef]
- Huang, X.; Qi, G.; Mazur, N.; Chai, Y. Deep residual networks-based intelligent fault diagnosis method of planetary gearboxes in cloud environments. Simul. Model. Pract. Theory 2022, 116, 102469. [Google Scholar] [CrossRef]
- Hubel, D.H.; Wiesel, T.N. Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex. J. Physiol. 1962, 160, 106–154. [Google Scholar] [CrossRef]
- Grauman, K.; Darrell, T. The Pyramid Match Kernels: Discriminative Classification with Sets of Image Features. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–21 October 2005; Volume 1, pp. 1458–1465. [Google Scholar]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the Computer Vision and Pattern Recognition, 2006 IEEE Computer Society, New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2169–2178. [Google Scholar]
- Xie, G.S.; Zhang, X.Y.; Shu, X.; Yan, S.; Liu, C.L. Task-driven feature pooling for image classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1179–1187. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Stochastic pooling for regularization of deep convolutional neural networks. arXiv 2013, arXiv:1301.3557. [Google Scholar]
- Zhai, S.; Wu, H.; Kumar, A.; Cheng, Y.; Lu, Y.; Zhang, Z.; Feris, R. S3pool: Pooling with stochastic spatial sampling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4970–4978. [Google Scholar]
- Graham, B. Fractional max pooling. arXiv 2014, arXiv:1412.6071. [Google Scholar]
- Jia, Y.; Huang, C.; Darrell, T. Beyond spatial pyramids: Receptive field learning for pooled image features. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3370–3377. [Google Scholar]
- Goodfellow, I.J.; Warde-Farley, D.; Mirza, M.; Courville, A.; Bengio, Y. Maxout networks. arXiv 2013, arXiv:1302.4389. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Gong, Y.; Wang, L.; Guo, R.; Lazebnik, S. Multi-scale orderless pooling of deep convolutional activation features. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 392–407. [Google Scholar]
- Saeedan, F.; Weber, N.; Goesele, M.; Roth, S. Detail-Preserving Pooling in Deep Networks. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9108–9116. [Google Scholar]
- Gao, Z.; Wang, L.; Wu, G. Lip: Local importance-based pooling. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3355–3364. [Google Scholar]
- Stergiou, A.; Poppe, R.; Kalliatakis, G. Refining activation downsampling with SoftPool. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10357–10366. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2007 (VOC2007) Results; 2007. Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.230.2543 (accessed on 5 January 2022).
- Griffin, G.; Holub, A.; Perona, P. Caltech-256 Object Category Dataset. 2007. CaltechAUTHORS. Available online: https://authors.library.caltech.edu/7694/ (accessed on 5 January 2022).
- Sohn, K.; Jung, D.Y.; Lee, H.; Hero, A.O. Efficient learning of sparse, distributed, convolutional feature representations for object recognition. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2643–2650. [Google Scholar]
- Huang, Y.; Wu, Z.; Wang, L.; Tan, T. Feature coding in image classification: A comprehensive study. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 493–506. [Google Scholar] [CrossRef]
- Bo, L.; Ren, X.; Fox, D. Multipath sparse coding using hierarchical matching pursuit. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 660–667. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the devil in the details: Delving deep into convolutional nets. arXiv 2014, arXiv:1405.3531. [Google Scholar]
- Van De Sande, K.; Gevers, T.; Snoek, C. Evaluating color descriptors for object and scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1582–1596. [Google Scholar] [CrossRef]
- Sharif Razavian, A.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN features off-the-shelf: An astounding baseline for recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Washington, DC, USA, 23–28 June 2014; pp. 806–813. [Google Scholar]
- Oquab, M.; Bottou, L.; Laptev, I.; Sivic, J. Learning and transferring mid-level image representations using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1717–1724. [Google Scholar]
- Afkham, H.M.; Targhi, A.T.; Eklundh, J.O.; Pronobis, A. Joint visual vocabulary for animal classification. In Proceedings of the 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Test Error (%) |
|---|---|
| ResNet-18 | 8.05 |
| ResNet-18 Max pooling | 9.12 |
| ResNet-18 SIFT pooling | 7.69 |
| ResNet-18 DSF-Pooling | 7.56 |
| Network | Original | DSF-Pooling |
|---|---|---|
| ResNet-18 | 30.24 | 28.65 |
| ResNet-34 | 26.71 | 25.42 |
| ResNet-50 | 24.23 | 23.28 |
| ResNet-101 | 22.31 | 21.88 |
| ResNet-152 | 22.16 | 21.55 |
| Methods | Accuracy (%) |
|---|---|
| Sohn et al.’s convolutional RBMs, SIFT [47] | 47.94 |
| Huang et al.’s SIFT, improved Fisher kernel [48] | 52.0 |
| Bo et al.’s multipath HMP [49] | 55.2 |
| Zeiler and Fergus’ ZF-net [50] | 74.2 |
| Chatfield et al.’ 8-layer CNN [51] | 77.6 |
| Gao et al.’ DEFEATnet [25] | 48.52 |
| Baseline Alexnet model [20] | 74.47 |
| Proposed model | 76.13 |
| Butterfly | Cormorant | Elephant | Gorilla | Ostrich | Owl | Penguin | Hibiscus | Hawksbill | Christ | Swan | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Alex | 67.65 | 78.57 | 77.36 | 76.87 | 87.10 | 69.05 | 70.42 | 90.11 | 90.91 | 66.47 | 78.38 |
| Ours | 82.35 | 92.86 | 83.02 | 77.61 | 87.10 | 64.29 | 74.65 | 90.11 | 93.45 | 68.14 | 81.08 |
| Methods | mAP (%) |
|---|---|
| Huang et al.—SIFT, improved Fisher kernel [48] | 58.05 |
| Sande et al.—SIFT, C-SIFT, OpponentSIFT, RGB-SIFT, rg-SIFT [52] | 60.05 |
| Razavian et al.—Overfeat [53] | 77.2 |
| Oquab et al.—transfer of mid-level CNN [54] | 77.7 |
| He et al.—SPP-net [39] | 80.1 |
| Chatfield et al.—8-layer CNN [51] | 82.4 |
| Alexnet | 80.21 |
| Ours | 81.45 |
| Aero | Bike | Bird | Boat | Bottle | Bus | Car | Cat | Chair | Cow | Table | Dog | Horse | Bike | PPL | Plant | Sheep | Sofa | Train | Tv | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Alex | 90.7 | 88.6 | 76.3 | 76.5 | 71.2 | 75.9 | 86.7 | 85.6 | 74.1 | 62.5 | 73.6 | 81.1 | 82.2 | 82.4 | 90.3 | 85.3 | 79.1 | 66.3 | 88.8 | 86.6 |
| Ours | 88.8 | 91.1 | 83.7 | 72.3 | 75.5 | 74.6 | 86.9 | 88.5 | 73.8 | 68.2 | 76.3 | 86.5 | 85.3 | 81.1 | 91.1 | 90.3 | 74.8 | 65.7 | 87.9 | 86.5 |
| Method | Pooling No. | ResNet18 | ResNet34 | ResNet50 | ResNet101 | ResNet152 |
|---|---|---|---|---|---|---|
| Original | - | 69.76 | 73.3 | 76.15 | 77.37 | 78.31 |
| Stochastic [34] | 1 | 70.13 | 73.34 | 76.11 | - | - |
| S3Pool [35] | 1 | 70.15 | 73.56 | 76.24 | - | - |
| DPP [41] | 3 | 70.86 | 74.25 | 77.09 | 78.30 | - |
| LIP [42] | 7 | 70.83 | 73.95 | 77.13 | 79.33 | - |
| SoftPool [43] | 1 | 71.27 | 74.67 | 77.35 | 77.74 | 78.73 |
| DSF Pool | 1 | 71.35 | 74.58 | 76.72 | 78.12 | 78.45 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, G.; Dixit, C.; Qi, G. Discriminative Shape Feature Pooling in Deep Neural Networks. J. Imaging 2022, 8, 118. https://doi.org/10.3390/jimaging8050118
Hu G, Dixit C, Qi G. Discriminative Shape Feature Pooling in Deep Neural Networks. Journal of Imaging. 2022; 8(5):118. https://doi.org/10.3390/jimaging8050118
Chicago/Turabian StyleHu, Gang, Chahna Dixit, and Guanqiu Qi. 2022. "Discriminative Shape Feature Pooling in Deep Neural Networks" Journal of Imaging 8, no. 5: 118. https://doi.org/10.3390/jimaging8050118
APA StyleHu, G., Dixit, C., & Qi, G. (2022). Discriminative Shape Feature Pooling in Deep Neural Networks. Journal of Imaging, 8(5), 118. https://doi.org/10.3390/jimaging8050118