
Weakly Supervised Polyp Segmentation in Colonoscopy Images Using Deep Neural Networks


Abstract
:1. Introduction
2. Materials and Methods
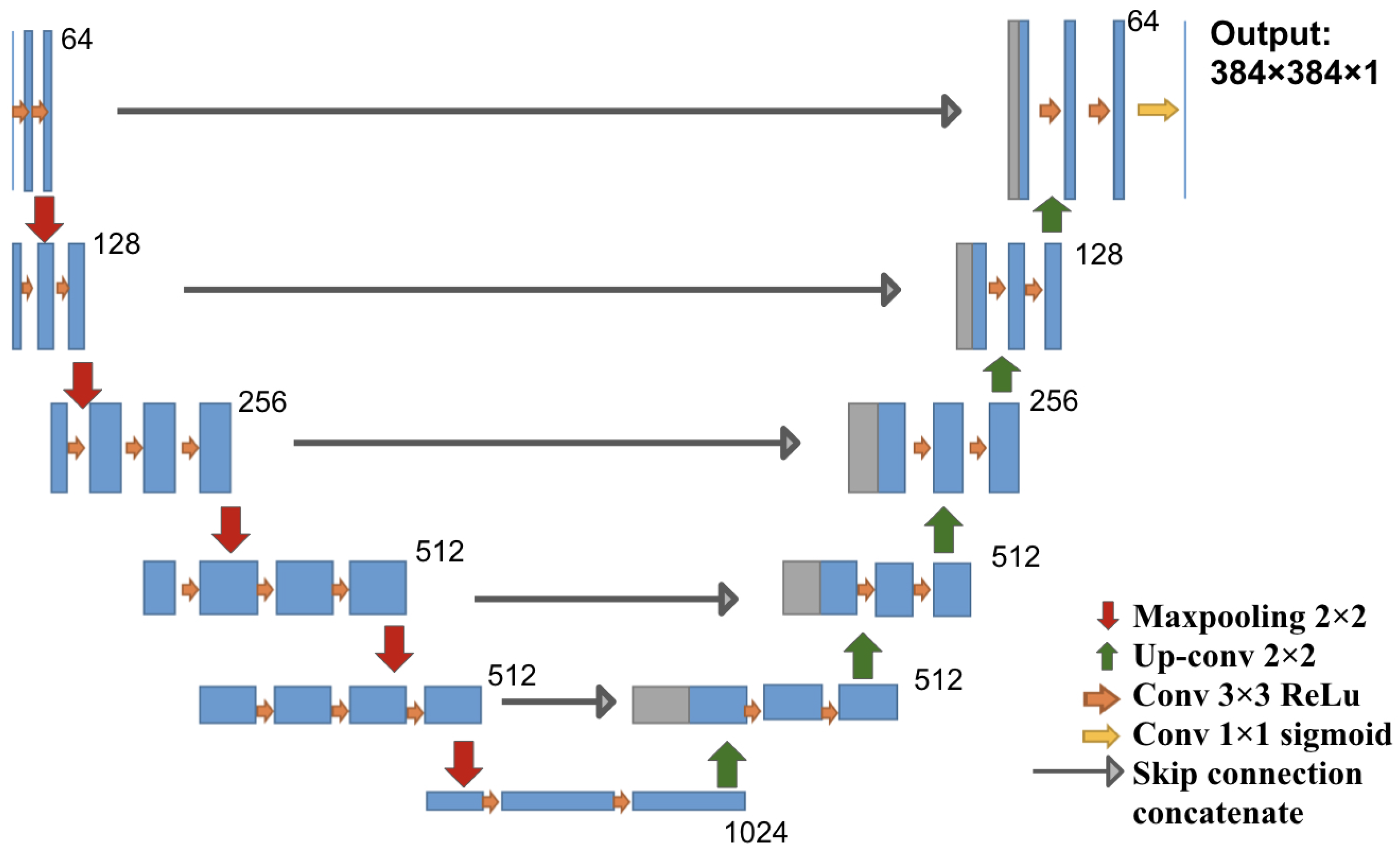
2.1. Deep Learning Architecture
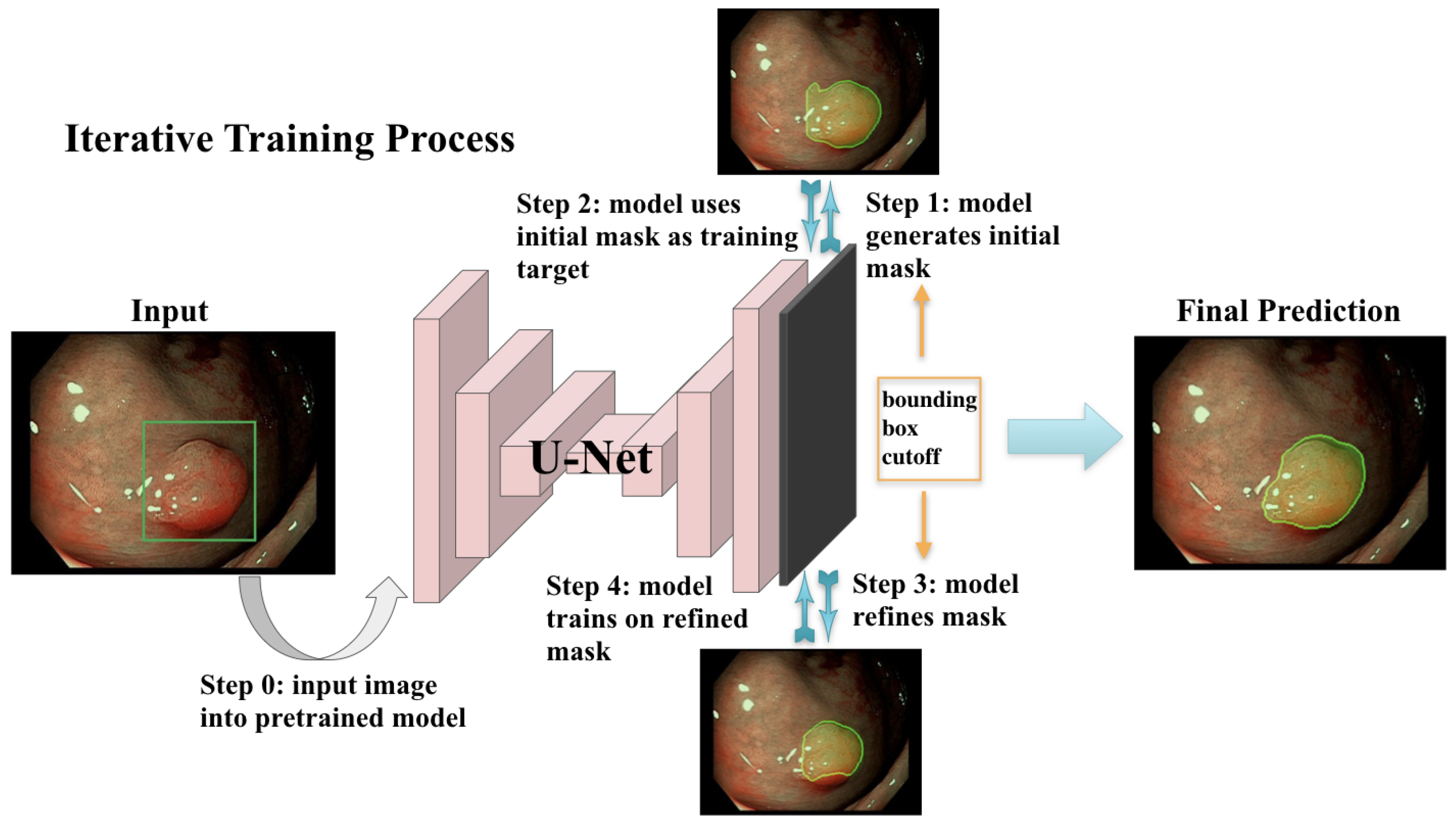
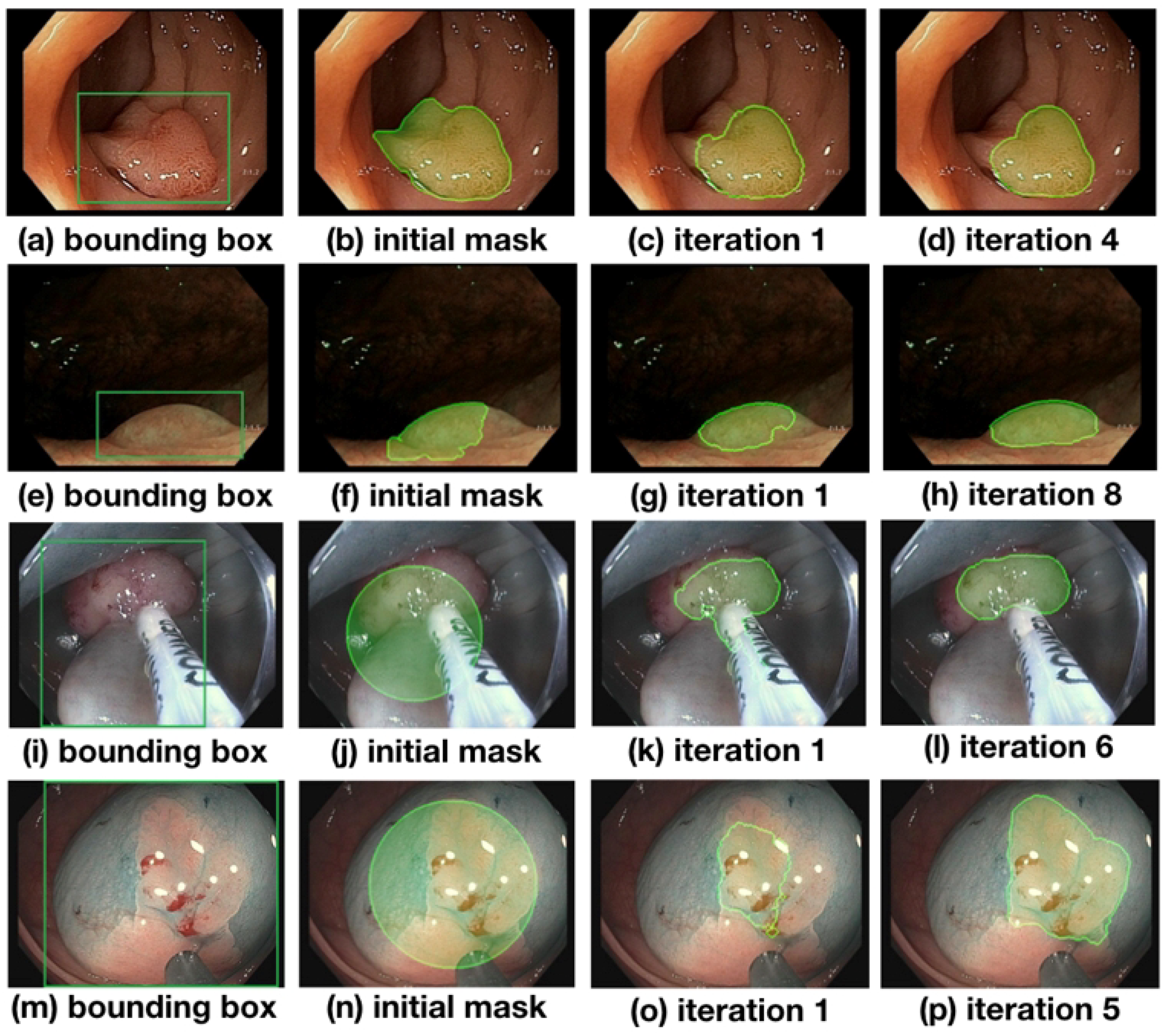
2.2. Iterative Weakly Supervised Training
2.3. Masked Loss Function
| Algorithm 1 Loss mask for semi-supervised training. |
| Require: bounding box width/height/coordinates: Require: image width/height: inner_radius outer_radius x_stretching y_stretching inv_mask ramp mask return |
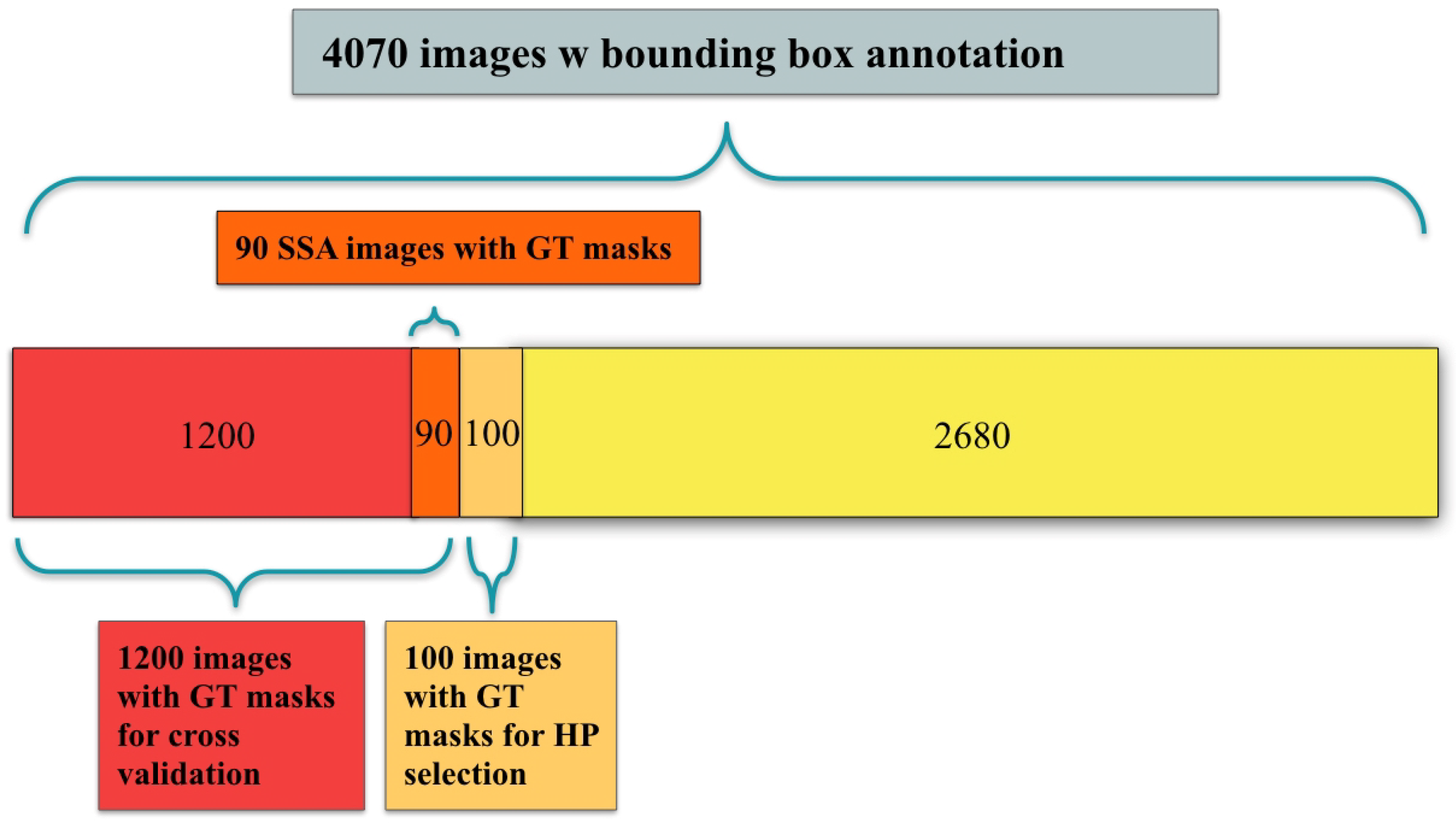
2.4. Dataset and Preprocessing
2.5. Model Training
- A fully supervised model was trained on the 612 polyp images and segmentation masks of the public CVC-ClinicDB dataset. The weights of this model were used as a starting point for further experiments. This model is denoted as Full-Sup-1-VGG.
- A fully supervised model was trained and evaluated via 10-fold cross-validation on the 1300 polyp images with segmentation masks from the Polyp-Box-Seg dataset. While the entire dataset contains 1300 images with segmentation masks, 100 of those were randomly selected and reserved for hyperparameter selection, with the 10-fold cross-validation being performed on the remaining 1200 images. A detailed breakdown of the data subsets used can be found in Figure 3. Weights pre-trained on the CVC-ClinicDB dataset were used as initial weights for this model. This model is denoted as Full-Sup-2. The cross-validation procedure trains 10 independent models and tests each on a different set of 120 images. This approach both significantly reduces the variance of the estimated (average) test score compared with a naïve single train-test data split and allows for an estimation of the variance of test accuracy estimates.
- A weakly supervised model was trained using the bounding box annotations on the 4070 polyp images from the Polyp-Box-Seg dataset in a 10-fold cross-validation, as described in Section 2.2. Three approaches to generating the initial segmentation targets were evaluated:
- a
- All initial training targets are set to be a solid circle in the center of the bounding boxes, with a diameter equal to 4/5 of the box’s shorter side (width or height). The area outside of the bounding boxes is thereby assumed to not contain any polyps and serves as “background” category. This model is referred to as Weak-Sup-Box-CI in the following (Circular Initialization).
- b
- Predictions of the model trained on the public CVC-ClinicDB dataset are used as initial targets. All pixels with a predicted probability over 0.5 that lie within a bounding box are assumed to show part of a polyp, while all other pixels are considered to be background pixels. Models trained on this initialization method will be denoted as Weak-Sup-Box-PI (Prediction Initialization).
- c
- The same initialization scheme as in b is used, but bad predictions are replaced with a solid circle as in a. Polyp predictions are considered bad if they occupy less than 30% of the bounding box area. Models trained using this initialization method are denoted as Weak-Sup-Box-HI (Hybrid Initialization). Weak-Sup-Box-HI is evaluated on the Kvasir-SEG dataset.
- A segmentation model was trained using the 1300 images with human segmentation labels together with the 2770 images with bounding boxes (a total of 4070 images) from the Polyp-Box-Seg dataset. Initial masks for the 2770 images with bounding boxes were generated in the hybrid manner, as described in c, and these masks were updated at the end of each training iteration, as described in Section 2.2. Segmentation mask labels were used for the 1300 images throughout training without being iteratively updated, as these labels are already accurate. In each iteration, the model trains on the mixture of 4070 images from both supervision sources, and at the end of the iteration, the model updates the masks for the 2770 images using model prediction. Models trained with a combination of weakly supervised bounding box targets and fully supervised segmentation mask targets are denoted as Weak-Sup-Mix.
- A Weak-Sup-Mix model was trained as described in 4 and evaluated on sessile serrated adenomas using 10-fold cross-validation.
- A Weak-Sup-Mix model was trained as described in 4 and evaluated on CVC-ClinicDB using 10-fold cross-validation. In each fold, the model was trained on all images from the Polyp-Box-Seg dataset plus 90% of the CVC-ClinicDB data and validated on the remaining 10% of the CVC-ClinicDB dataset. In the first two iterations, one extra training epoch on CVC-ClinicDB data was added at the end of three training epochs on all data, and in the remaining six iterations, two extra training epochs on CVC-ClinicDB data were added at the end of six training epochs on all data.
- A fully supervised segmentation model was trained and evaluated using 10-fold cross-validation on the CVC-ClinicDB dataset using initial weights pre-trained on the Weak-Sup-Mix model, as described in 4. This model is named Full-Sup-3. This pre-trained model essentially transfers knowledge of polyp shapes learned on the Polyp-Box-Seg dataset to the CVC-ClinicDB dataset, where it is fine-tuned to adjust to the differences between the datasets (such as different cameras and lighting conditions). The model was trained for 30 epochs with an initial learning rate of 1 × 10−4, learning rate decay of 5 × 10−4 after each epoch, and a batch size of 1.
2.6. Network Initialization
3. Results
3.1. Pre-Trained Weakly Supervised Models on Polyp-Box-Seg
3.2. Weakly Supervised Models Initialized with VGG16 Weights on Polyp-Box-Seg
3.3. Weakly Supervised Models Tested on Sessile Serrate Adenomas Alone
3.4. Weakly Supervised Models on CVC-ClinicDB
3.5. Weakly Supervised Models on Kvasir-SEG
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix B
References
- Colorectal Cancer Statistics|Center of Disease Control and Prevention. Available online: https://www.cdc.gov/cancer/colorectal/statistics/ (accessed on 18 April 2022).
- Shin, Y.; Qadir, H.A.; Aabakken, L.; Bergsland, J.; Balasingham, I. Automatic Colon Polyp Detection Using Region Based Deep CNN and Post Learning Approaches. IEEE Access 2018, 6, 40950–40962. [Google Scholar] [CrossRef]
- Anderson, J.C.; Butterly, L.F. Colonoscopy: Quality Indicators. Clin. Transl. Gastroenterol. 2015, 6, e77. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.; Park, S.W.; Kim, Y.S.; Lee, K.J.; Sung, H.; Song, P.H.; Yoon, W.J.; Moon, J.S. Risk factors of missed colorectal lesions after colonoscopy. Medicine 2017, 96, e7468. [Google Scholar] [CrossRef] [PubMed]
- Lee, Y.M.; Huh, K.C. Clinical and Biological Features of Interval Colorectal Cancer. Clin. Endosc. 2017, 50, 254–260. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Troelsen, F.S.; Sørensen, H.T.; Crockett, S.D.; Pedersen, L.; Erichsen, R. Characteristics and Survival of Patients with Inflammatory Bowel Disease and Postcolonoscopy Colorectal Cancers. Clin. Gastroenterol. Hepatol. 2021. [Google Scholar] [CrossRef]
- Le Clercq, C.M.C.; Bouwens, M.W.E.; Rondagh, E.J.A.; Bakker, C.M.; Keulen, E.T.P.; de Ridder, R.J.; Winkens, B.; Masclee, A.A.M.; Sanduleanu, S. Postcolonoscopy colorectal cancers are preventable: A population-based study. Gut 2014, 63, 957–963. [Google Scholar] [CrossRef]
- Forsberg, A.; Widman, L.; Bottai, M.; Ekbom, A.; Hultcrantz, R. Postcolonoscopy Colorectal Cancer in Sweden From 2003 to 2012: Survival, Tumor Characteristics, and Risk Factors. Clin. Gastroenterol. Hepatol. 2020, 18, 2724–2733.e3. [Google Scholar] [CrossRef]
- Macken, E.; Dongen, S.V.; Brabander, I.D.; Francque, S.; Driessen, A.; Hal, G.V. Post-colonoscopy colorectal cancer in Belgium: Characteristics and influencing factors. Endosc. Int. Open 2019. [Google Scholar] [CrossRef] [Green Version]
- Baldi, P. Deep Learning in Science; Cambridge University Press: Cambridge, UK, 2021. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Girshick, R.B. Fast R-CNN. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. arXiv 2014, arXiv:1411.4038. [Google Scholar]
- Urban, G.; Feil, N.; Csuka, E.; Hashemi, K.; Ekelem, C.; Choi, F.; Mesinkovska, N.A.; Baldi, P. Combining Deep Learning with Optical Coherence Tomography Imaging to Determine Scalp Hair and Follicle Counts. Lasers Surg. Med. 2021, 53, 171–178. [Google Scholar] [CrossRef] [PubMed]
- Chang, P.; Grinband, J.; Weinberg, B.; Bardis, M.; Khy, M.; Cadena, G.; Su, M.Y.; Cha, S.; Filippi, C.; Bota, D.; et al. Deep-Learning Convolutional Neural Networks Accurately Classify Genetic Mutations in Gliomas. AJNR Am. J. Neuroradiol. 2018, 39, 1201–1207. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Urban, G.; Bache, K.; Phan, D.T.; Sobrino, A.; Shmakov, A.K.; Hachey, S.J.; Hughes, C.C.; Baldi, P. Deep learning for drug discovery and cancer research: Automated analysis of vascularization images. IEEE/ACM Trans. Comput. Biol. Bioinform. 2018, 16, 1029–1035. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Ding, H.; Bidgoli, F.A.; Zhou, B.; Iribarren, C.; Molloi, S.; Baldi, P. Detecting Cardiovascular Disease from Mammograms with Deep Learning. EEE Trans. Med. Imaging 2017, 36, 1172–1181. [Google Scholar] [CrossRef]
- Wang, J.; Fang, Z.; Lang, N.; Yuan, H.; Su, M.Y.; Baldi, P. A multi-resolution approach for spinal metastasis detection using deep Siamese neural networks. Comput. Biol. Med. 2017, 84, 137–146. [Google Scholar] [CrossRef] [Green Version]
- Hassan, H.; Ren, Z.; Zhao, H.; Huang, S.; Li, D.; Xiang, S.; Kang, Y.; Chen, S.; Huang, B. Review and classification of AI-enabled COVID-19 CT imaging models based on computer vision tasks. Comput. Biol. Med. 2022, 141, 105123. [Google Scholar] [CrossRef]
- Li, R.; Xiao, C.; Huang, Y.; Hassan, H.; Huang, B. Deep Learning Applications in Computed Tomography Images for Pulmonary Nodule Detection and Diagnosis: A Review. Diagnostics 2022, 12, 298. [Google Scholar] [CrossRef]
- Urban, G.; Tripathi, P.; Alkayali, T.; Mittal, M.; Jalali, F.; Karnes, W.; Pierre, B. Deep Learning Localizes and Identifies Polyps in Real Time with 96% Accuracy in Screening Colonoscopy. Gastroenterology 2018, 155, P1069–P1078.E8. [Google Scholar] [CrossRef]
- Jin, E.H.; Lee, D.; Bae, J.H.; Kang, H.Y.; Kwak, M.S.; Seo, J.Y.; Yang, J.I.; Yang, S.Y.; Lim, S.H.; Yim, J.Y.; et al. Improved Accuracy in Optical Diagnosis of Colorectal Polyps Using Convolutional Neural Networks with Visual Explanations. Gastroenterology 2020, 158, 2169–2179.e8. [Google Scholar] [CrossRef]
- Ozawa, T.; Ishihara, S.; Fujishiro, M.; Kumagai, Y.; Shichijo, S.; Tada, T. Automated endoscopic detection and classification of colorectal polyps using convolutional neural networks. Ther. Adv. Gastroenterol. 2020, 13, 1756284820910659. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Riegler, M.; Pogorelov, K.; Eskeland, S.L.; Schmidt, P.T.; Albisser, Z.; Johansen, D.; Griwodz, C.; Halvorsen, P.; Lange, T.D. From Annotation to Computer-Aided Diagnosis: Detailed Evaluation of a Medical Multimedia System. ACM Trans. Multimed. Comput. Commun. Appl. 2017, 13, 1–26. [Google Scholar] [CrossRef]
- Tavanapong, W.; Oh, J.; Kijkul, G.; Pratt, J.; Wong, J.; de Groen, P. Real-Time Feedback for Colonoscopy in a Multicenter Clinical Trial. In Proceedings of the 2020 IEEE 33rd International Symposium on Computer-Based Medical Systems (CBMS), Rochester, MN, USA, 28–30 July 2020; pp. 13–18. [Google Scholar] [CrossRef]
- Wang, P.; Berzin, T.; Brown, J.; Bharadwaj, S.; Becq, A.; Xiao, X.; Liu, P.; Li, L.; Song, Y.; Zhang, D.; et al. Real-time automatic detection system increases colonoscopic polyp and adenoma detection rates: A prospective randomised controlled study. Gut 2019, 68, 1813–1819. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Su, J.R.; Li, Z.; Shao, X.J.; Ji, C.R.; Ji, R.; Zhou, R.C.; Li, G.C.; Liu, G.Q.; He, Y.S.; Zuo, X.L.; et al. Impact of real-time automatic quality control system on colorectal polyp and adenoma detection: A prospective randomized controlled study (with video). Gastrointest. Endosc. 2019, 91, 415–424. [Google Scholar] [CrossRef] [PubMed]
- Li, T.; Cohen, J.; Craig, M.; Tsourides, K.; Mahmud, N.; Berzin, T. Mo1979 The Next Endoscopic Frontier: A Novel Computer Vision Program Accurately Identifies Colonoscopic Colorectal Adenomas. Gastrointest. Endosc. 2016, 83, AB482. [Google Scholar] [CrossRef]
- Byrne, M.F.; Chapados, N.; Soudan, F.; Oertel, C.; Linares Pérez, M.L.; Kelly, R.; Iqbal, N.; Chandelier, F.; Rex, D.K. Su1614 Artificial Intelligence (AI) in Endoscopy–Deep Learning for Optical Biopsy of Colorectal Polyps in Real-Time on Unaltered Endoscopic Videos. Gastrointest. Endosc. 2017, 85, AB364–AB365. [Google Scholar] [CrossRef]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv 2013, arXiv:1311.2524. [Google Scholar]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2015, arXiv:1506.02640. [Google Scholar]
- Brandao, P.; Mazomenos, E.; Ciuti, G.; Caliò, R.; Bianchi, F.; Menciassi, A.; Dario, P.; Koulaouzidis, A.; Arezzo, A.; Stoyanov, D. Fully convolutional neural networks for polyp segmentation in colonoscopy. In Proceedings of the Medical Imaging 2017: Computer-Aided Diagnosis, Orlando, FL, USA, 11–16 February 2017; Volume 10134, pp. 101–107. [Google Scholar] [CrossRef]
- Vázquez, D.; Bernal, J.; Sánchez, F.J.; Fernández-Esparrach, G.; López, A.M.; Romero, A.; Drozdzal, M.; Courville, A.C. A Benchmark for Endoluminal Scene Segmentation of Colonoscopy Images. arXiv 2016, arXiv:1612.00799. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R.B. Mask R-CNN. arXiv 2017, arXiv:1703.06870. [Google Scholar]
- Meng, J.; Xue, L.; Chang, Y.; Zhang, J.; Chang, S.; Liu, K.; Liu, S.; Wang, B.; Yang, K. Automatic detection and segmentation of adenomatous colorectal polyps during colonoscopy using Mask R-CNN. Open Life Sci. 2020, 15, 588–596. [Google Scholar] [CrossRef] [PubMed]
- Bernal, J.; Sánchez, F.J.; Fernández-Esparrach, G.; Gil, D.; Rodríguez, C.; Vilariño, F. WM-DOVA maps for accurate polyp highlighting in colonoscopy: Validation vs. saliency maps from physicians. Comput. Med. Imaging Graph. 2015, 43, 99–111. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Bernal, J.; Matuszewski, B.J. Polyp Segmentation with Fully Convolutional Deep Neural Networks—Extended Evaluation Study. J. Imaging 2020, 6, 69. [Google Scholar] [CrossRef] [PubMed]
- Jha, D.; Smedsrud, P.H.; Riegler, M.A.; Johansen, D.; de Lange, T.; Halvorsen, P.; Johansen, H.D. ResUNet++: An Advanced Architecture for Medical Image Segmentation. In Proceedings of the 2019 IEEE International Symposium on Multimedia (ISM), San Diego, CA, USA, 9–11 December 2019. [Google Scholar]
- Nguyen, N.Q.; Vo, D.M.; Lee, S.W. Contour-Aware Polyp Segmentation in Colonoscopy Images Using Detailed Upsampling Encoder-Decoder Networks. IEEE Access 2020, 8, 99495–99508. [Google Scholar] [CrossRef]
- Jha, D.; Smedsrud, P.H.; Riegler, M.A.; Halvorsen, P.; de Lange, T.; Johansen, D.; Johansen, H.D. Kvasir-SEG: A Segmented Polyp Dataset. In Proceedings of the International Conference on Multimedia Modeling, Thessaloniki, Greece, 8–11 January 2019. [Google Scholar] [CrossRef]
- Mahmud, T.; Paul, B.; Fattah, S.A. PolypSegNet: A modified encoder-decoder architecture for automated polyp segmentation from colonoscopy images. Comput. Biol. Med. 2021, 128, 104119. [Google Scholar] [CrossRef]
- Tomar, N.K.; Jha, D.; Riegler, M.A.; Johansen, H.D.; Johansen, D.; Rittscher, J.; Halvorsen, P.; Ali, S. FANet: A Feedback Attention Network for Improved Biomedical Image Segmentation. arXiv 2021, arXiv:2103.17235. [Google Scholar] [CrossRef]
- Wu, H.; Chen, G.; Wen, Z.; Qin, J. Collaborative and Adversarial Learning of Focused and Dispersive Representations for Semi-supervised Polyp Segmentation. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 3469–3478. [Google Scholar] [CrossRef]
- Mylonaki, M.; Fritscher-Ravens, A.; Swain, P. Wireless capsule endoscopy: A comparison with push enteroscopy in patients with gastroscopy and colonoscopy negative gastrointestinal bleeding. Gut 2003, 52, 1122–1126. [Google Scholar] [CrossRef]
- Dai, J.; He, K.; Sun, J. BoxSup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentation. arXiv 2015, arXiv:1503.01640. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Baldi, P.; Brunak, S.; Chauvin, Y.; Andersen, C.A.F.; Nielsen, H. Assessing the accuracy of prediction algorithms for classification: An overview. Bioinformatics 2000, 16, 3412–3424. [Google Scholar] [CrossRef] [Green Version]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Han, X.; Laga, H.; Bennamoun, M. Image-based 3D Object Reconstruction: State-of-the-Art and Trends in the Deep Learning Era. arXiv 2019, arXiv:1906.06543. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Seitz, S.; Curless, B.; Diebel, J.; Scharstein, D.; Szeliski, R. A Comparison and Evaluation of Multi-View Stereo Reconstruction Algorithms. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 1, pp. 519–528. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Histology | Count |
|---|---|
| Tubular adenoma | 2102 |
| Hyperplastic | 909 |
| Sessile serrated adenoma | 349 |
| Non-serrated sessile | 446 |
| Tubulovillous adenoma | 64 |
| Inflammatory | 42 |
| Traditional serrated adenoma | 33 |
| Lymphoid nodule | 19 |
| CA adenocarcinoma | 14 |
| Hamartomatous | 11 |
| Juvenile polyp | 6 |
| CA lymphoma | 5 |
| Sessile serrated adenoma w dysplasia | 3 |
| Mucosal prolapse | 3 |
| CA squamous/epidermoid | 1 |
| Other | 63 |
| Full-Sup-2 | Weak-Sup-Box-CI | Weak-Sup-Box-PI | Weak-Sup-Box-HI | Weak-Sup-Mix | |
|---|---|---|---|---|---|
| Dice Coefficient | 81.52 ± 0.41% | 77.58 ± 0.66% | 77.78 ± 0.87% | 81.36 ± 0.43% | 85.53 ± 0.33% |
| Accuracy | 98.76 ± 0.09% | 98.42 ± 0.10% | 98.50 ± 0.11% | 98.67 ± 0.09% | 98.96 ± 0.07% |
| Weak-Sup-Box-CI | Weak-Sup-Box-PI | Weak-Sup-Box-HI | Weak-Sup-Mix | |
|---|---|---|---|---|
| TP | 5039.01 | 5947.08 | 6180.07 | 6333.31 |
| TN | 139,604.96 | 139,414.03 | 139,341.57 | 139,755.01 |
| FP | 512.68 | 703.62 | 776.07 | 362.63 |
| FN | 2299.32 | 1391.26 | 1158.26 | 1005.02 |
| Full-Sup-2-VGG | Weak-Sup-Box-CI-VGG | Weak-Sup-Mix-VGG | |
|---|---|---|---|
| Dice Coefficient | 79.11 ± 0.93% | 76.14 ± 0.67% | 85.08 ± 0.60% |
| Accuracy | 98.56 ± 0.14% | 98.31 ± 0.08% | 98.93 ± 0.09% |
| Weak-Sup-Mix on SSA | Weak-Sup-Mix-VGG on SSA | |
|---|---|---|
| Dice Coefficient | 84.56 ± 2.38% | 83.66 ± 1.95% |
| Accuracy | 98.23 ± 0.34% | 98.05 ± 0.39% |
| Weak-Sup-Mix-VGG on CVC | Full-Sup-3 on CVC | |
|---|---|---|
| Dice Coefficient | 90.43 ± 0.43% | 91.79 ± 0.43% |
| Accuracy | 98.87 ± 0.08% | 99.06 ± 0.07% |
| Weak-Sup-Box-HI on Kvasir-SEG | |
|---|---|
| Dice Coefficient | 82.81% |
| Accuracy | 95.41% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Urban, G.; Baldi, P. Weakly Supervised Polyp Segmentation in Colonoscopy Images Using Deep Neural Networks. J. Imaging 2022, 8, 121. https://doi.org/10.3390/jimaging8050121
Chen S, Urban G, Baldi P. Weakly Supervised Polyp Segmentation in Colonoscopy Images Using Deep Neural Networks. Journal of Imaging. 2022; 8(5):121. https://doi.org/10.3390/jimaging8050121
Chicago/Turabian StyleChen, Siwei, Gregor Urban, and Pierre Baldi. 2022. "Weakly Supervised Polyp Segmentation in Colonoscopy Images Using Deep Neural Networks" Journal of Imaging 8, no. 5: 121. https://doi.org/10.3390/jimaging8050121
APA StyleChen, S., Urban, G., & Baldi, P. (2022). Weakly Supervised Polyp Segmentation in Colonoscopy Images Using Deep Neural Networks. Journal of Imaging, 8(5), 121. https://doi.org/10.3390/jimaging8050121