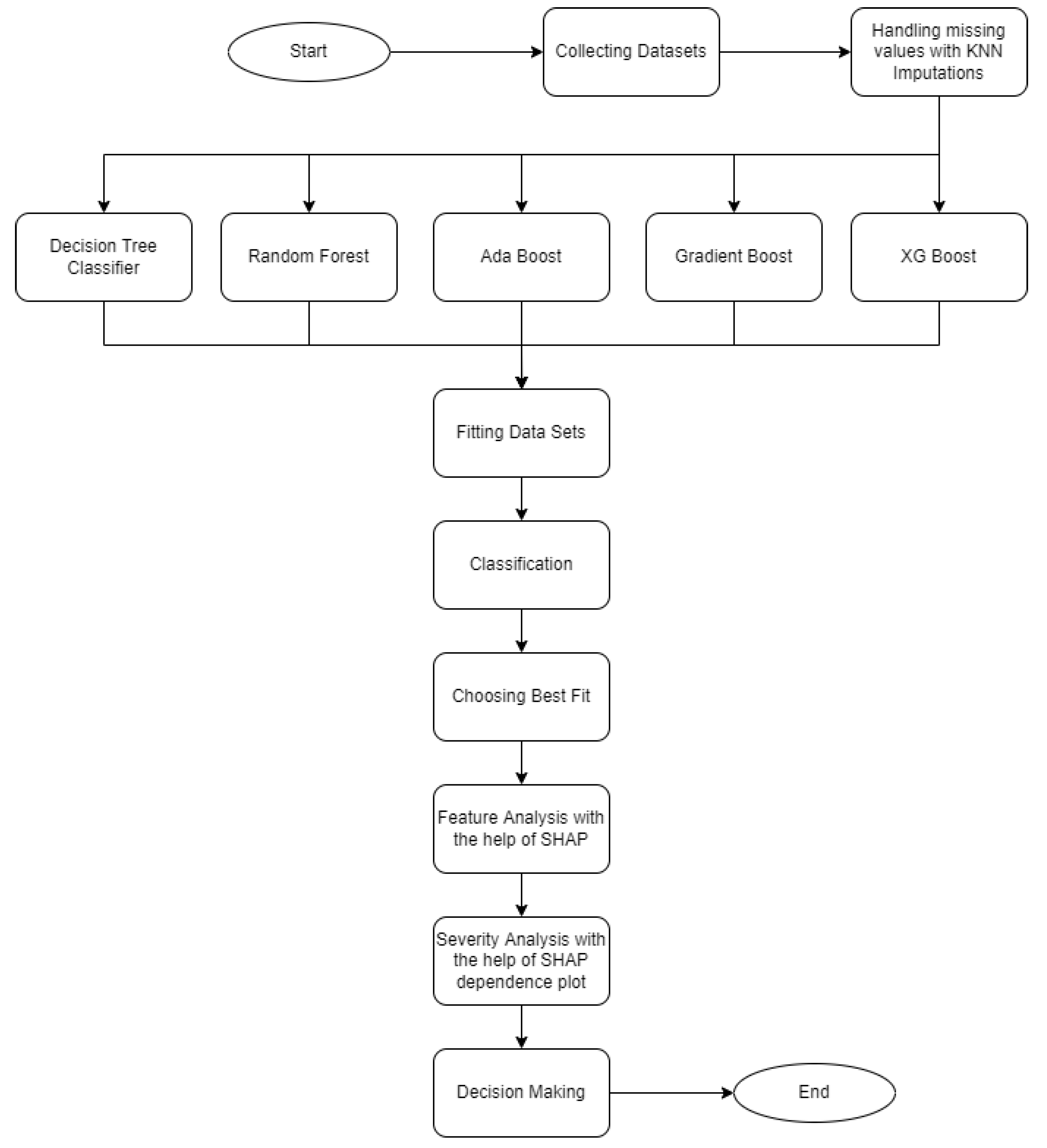
7.1. Analysis on the VDengue Dataset
As we mentioned earlier, among the supervised learning we applied, the XGBoost classifier was found to be best performing on our dataset. It is also reflected in
Table 4 and
Table 5. For the XGBoost model, the hyper parameters were tuned, such as objective = binary logistic, colsample_bytree = 0.3, learning rate = 1, max_depth= 9, alpha = 10, and n_estimators = 10, to achieve a better performance.
The size of the epochs was taken as equal to the length of the evaluation set.
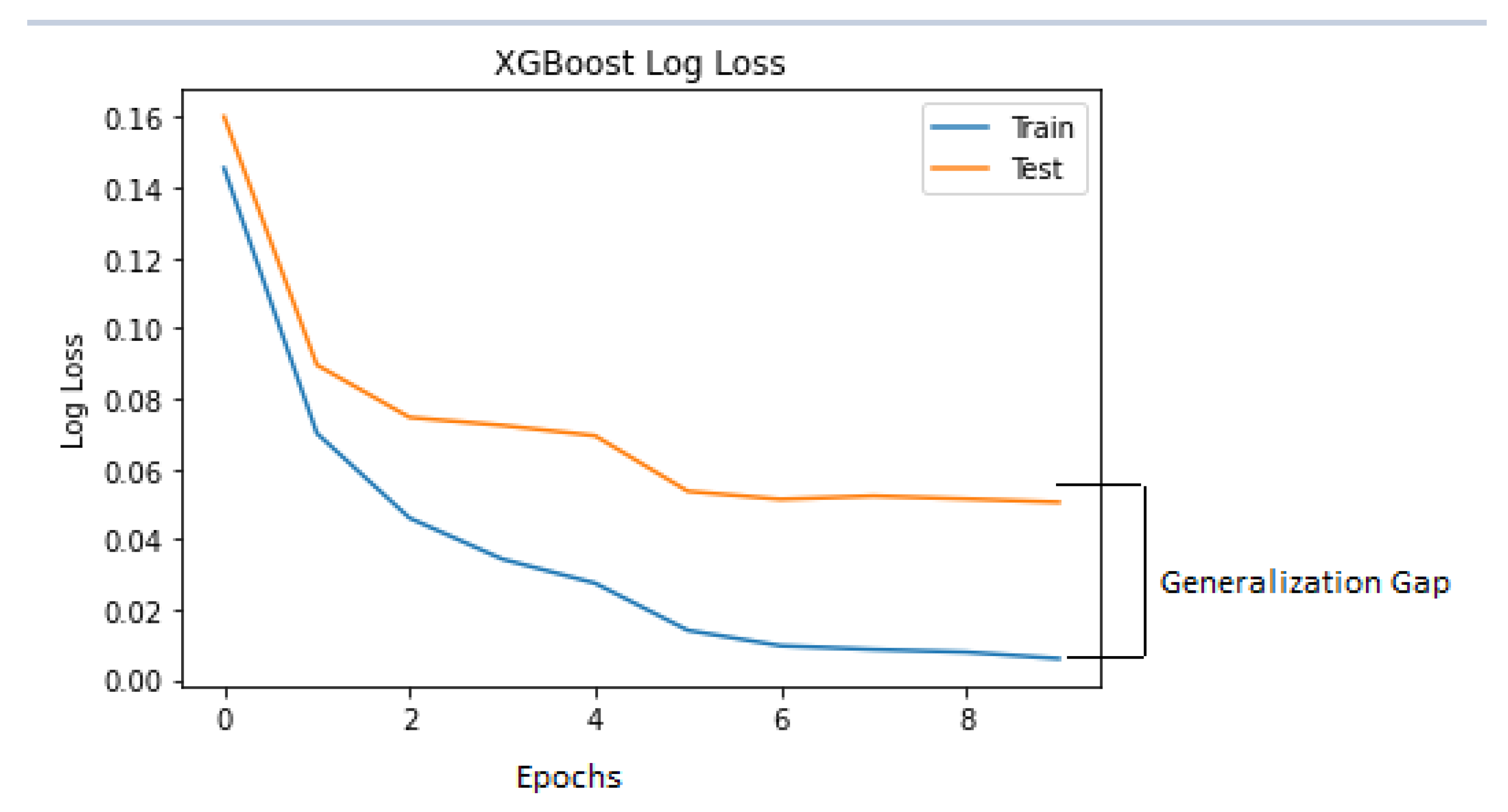
Figure 8 is the log loss which indicates the model behaviour on the train and test dataset over the training epochs. As the generalisation gap was small between the training and testing log-loss curve, it could be said that the XGBoost classifier model had a good fit on the VDengue dataset in predicting the dengue severity.
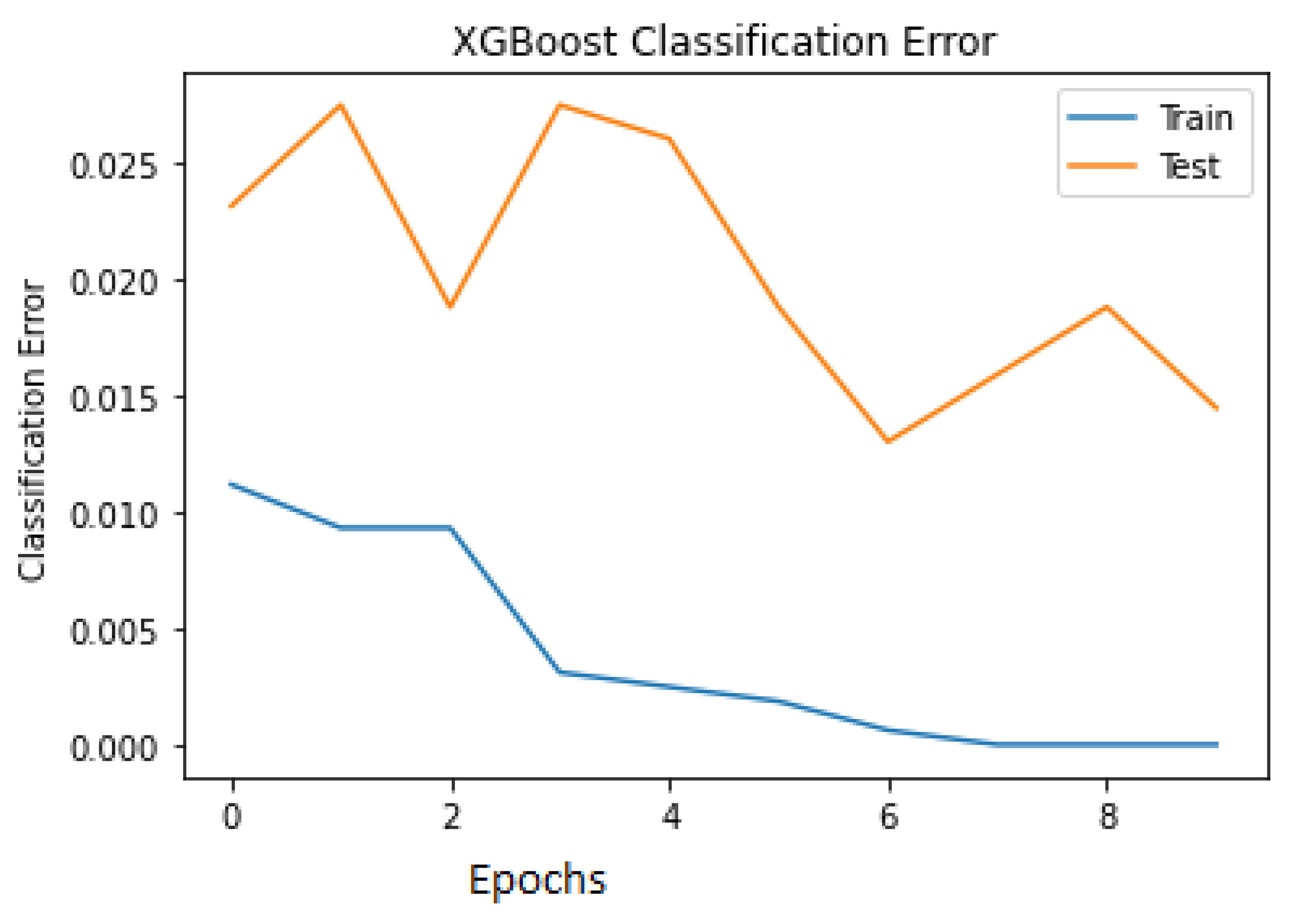
The classification errors for both the train and test are plotted in
Figure 9 to visualise the misclassification among the data points. It is seen in the last epoch that the number of misclassified samples during training is close to 0, and during testing, it is close to 0.05.
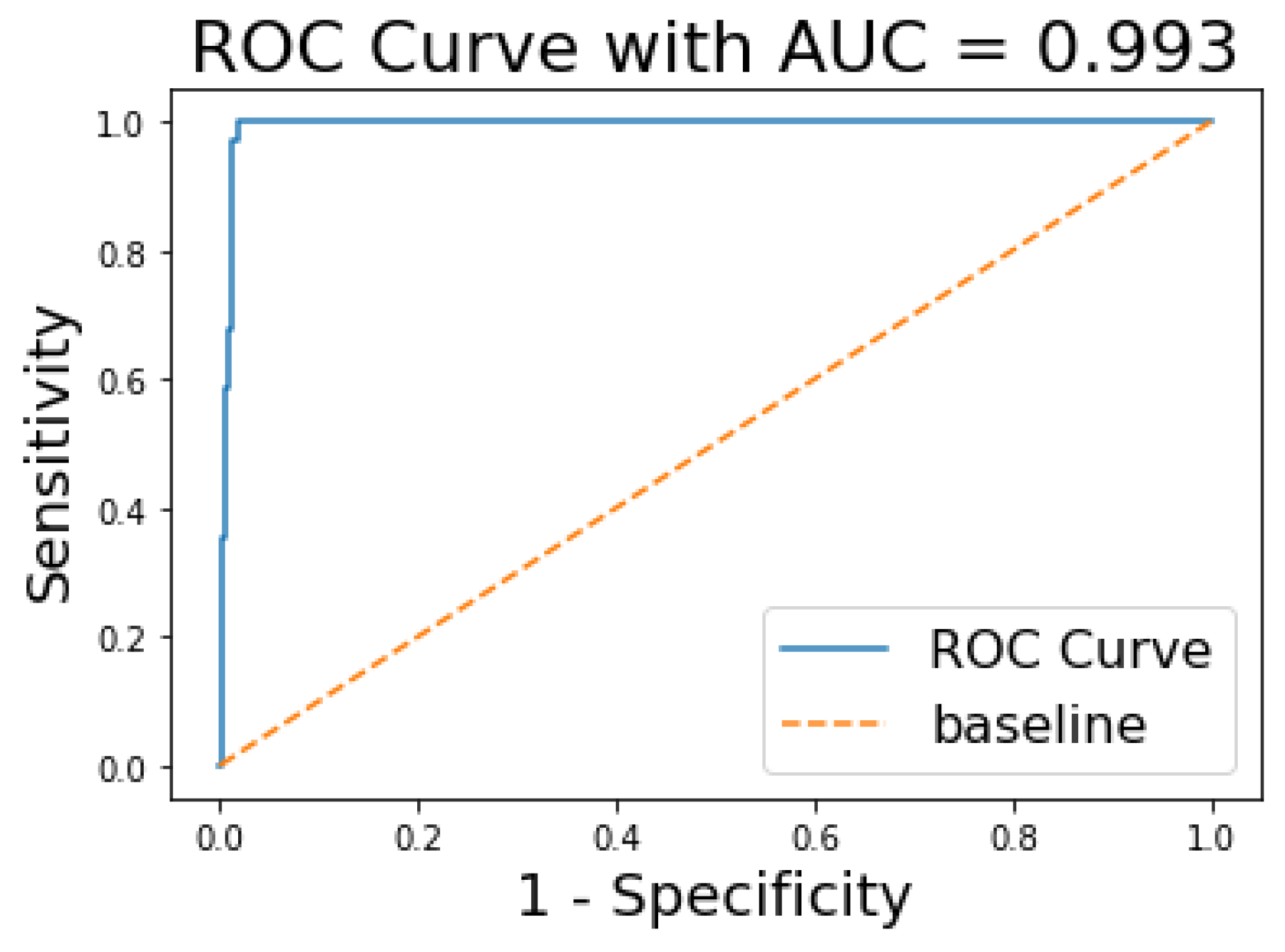
The ROC and AUC curves were further assessed to see the performance of our model. The AUC curve summarises the performance and gives a metric that lies between 0 and 1. The value tends to 1 for a high performing classifier and 0 for a low performing classifier. From
Figure 10, we can see that the AUC for the XGBoost model is 0.993.
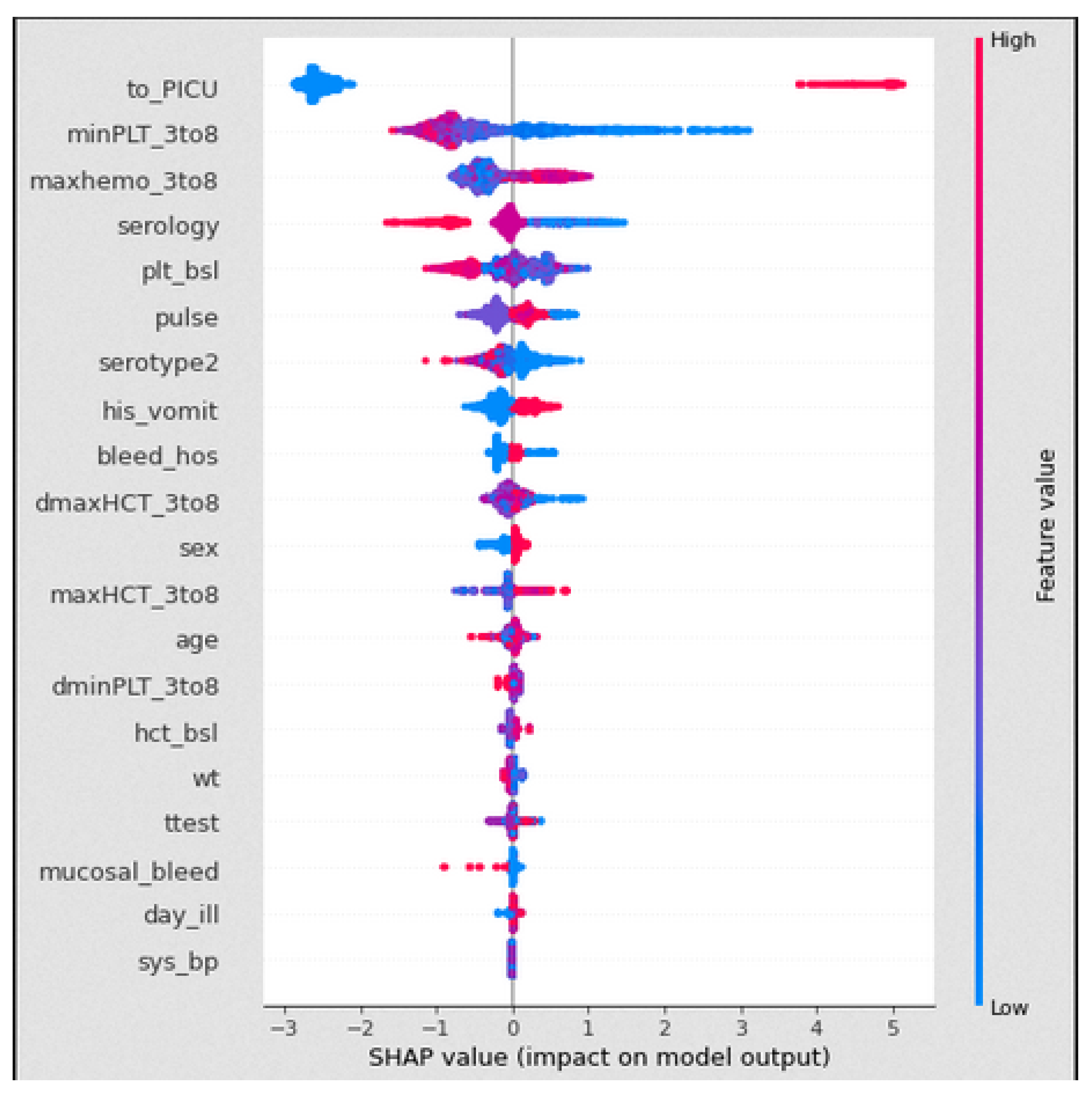
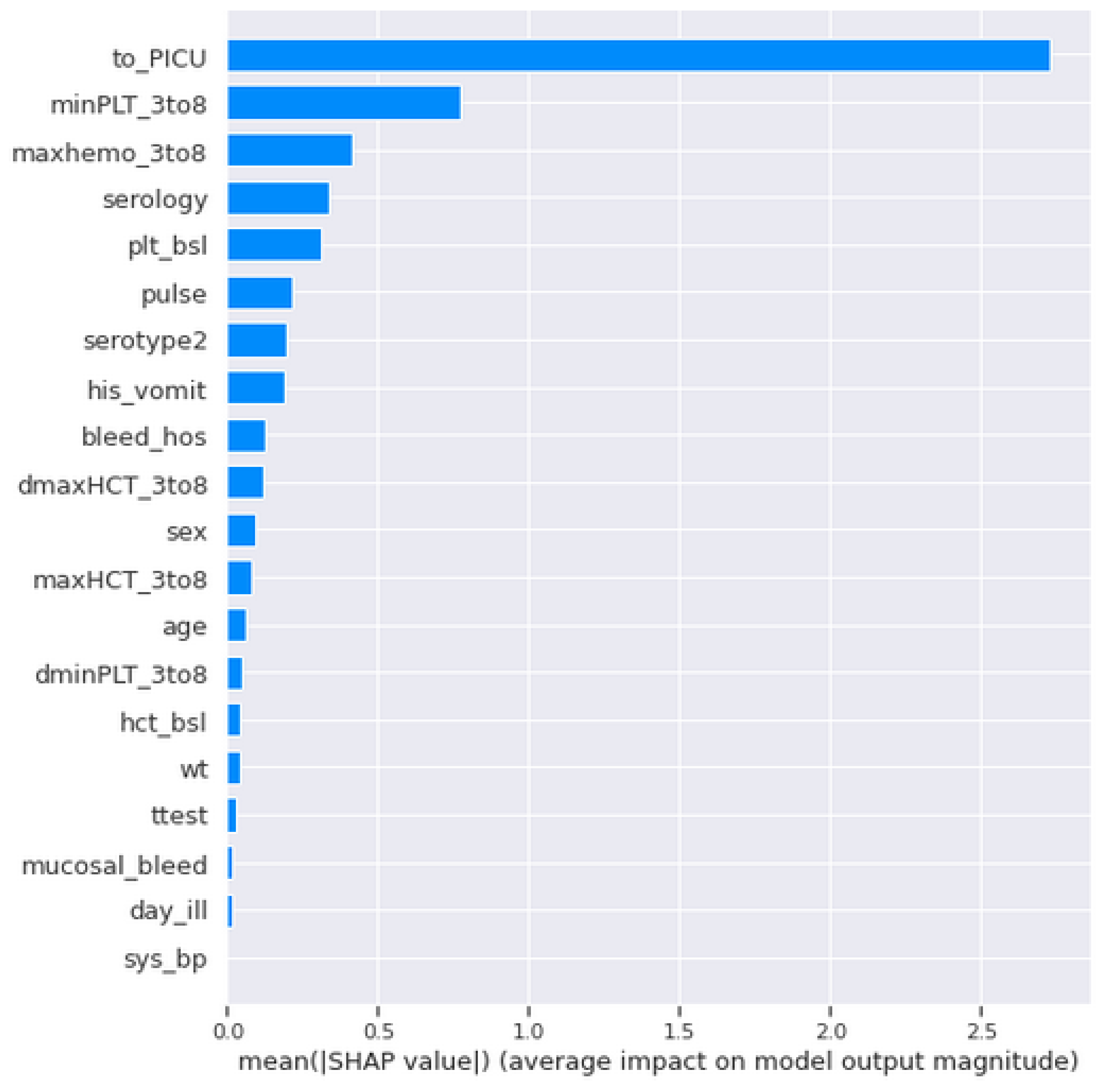
In the VDengue dataset, among all the features, the to_PICU, maxHCT_3to8, minPLT_3to8, maxhemo_3to8, and serotype2 are considered to be the most important features as described in
Section 3, and the analysis was done by taking all these features under consideration. The influence of the aforementioned variables on the predictions given by the XGBoost classifier, which was the best fitted model for the VDengue dataset, was depicted using a SHAP dependency plot. This plot assisted us in analysing the factors that have a higher chance of causing shock, i.e., severity. A SHAP value greater than zero shows that the prediction result is positive, indicating that the patient has gone into shock, whereas a value less than zero suggests that the patient has not yet reached to shock level or acquired DSS [
15].
The term haemoconcentration refers to a drop in plasma volume that is accompanied by an increase in red blood cell concentration. With the increase in haemoconcentration, the blood viscosity is also increased and causes fever. The DHF and DSS are characterised by plasma leakage which can result from severe dengue fever.
The haematocrit concentration (%) of children on the day of enrolment was recorded and saved in the hct_bsl column of the VDengue dataset. A daily haematocrit concentration count was evaluated between the third and eighth days of enrolment, and the maximum counts within those five days were noted and kept in the maxHCT_3to8 column of the dataset. On the same way, the overall haemoconcentration (%) was recorded in the maxhemo_3to8 column of the dataset. The data of patients who were admitted to the paediatric intensive care unit were stored in the to_PICU column (PICU).
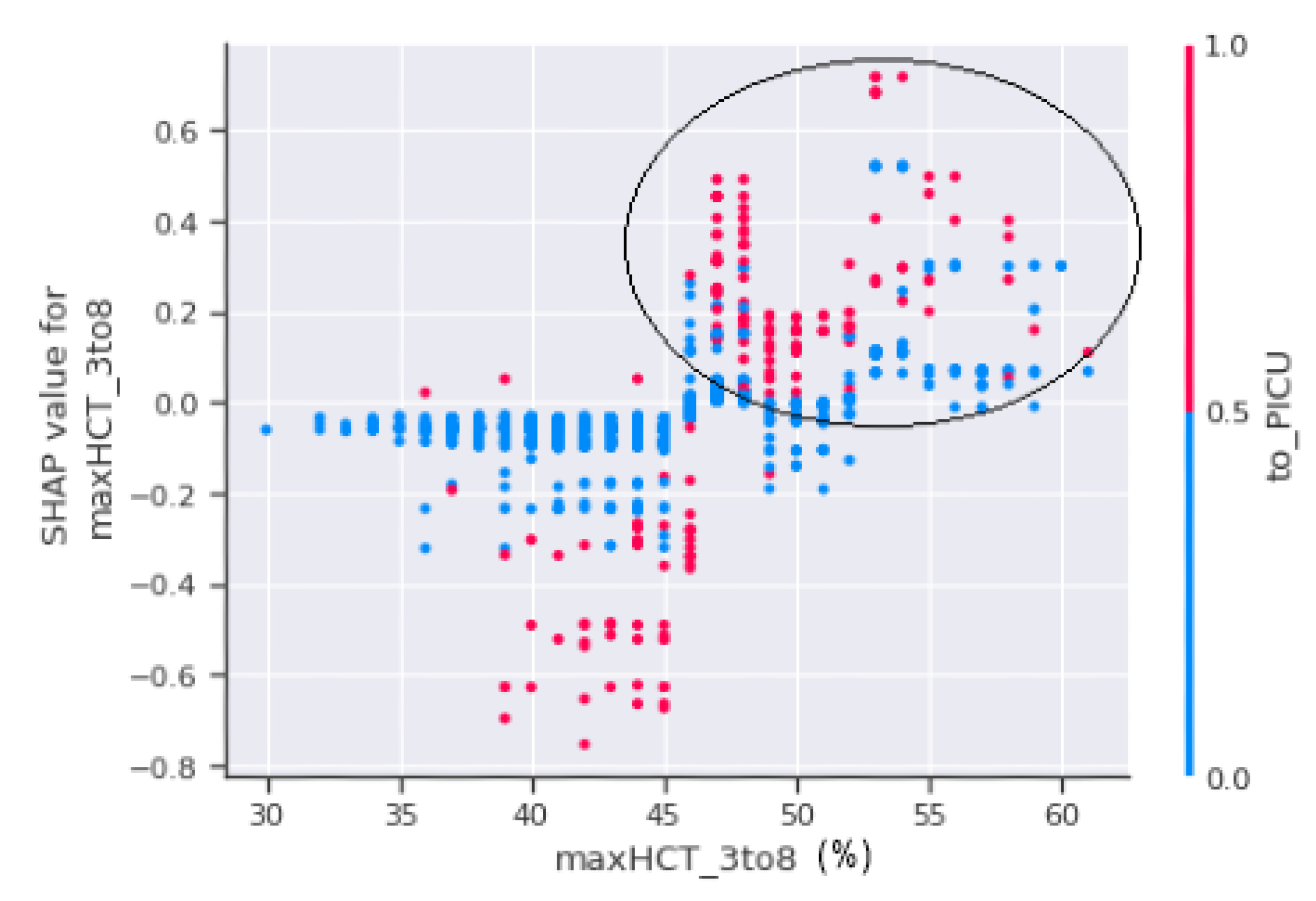
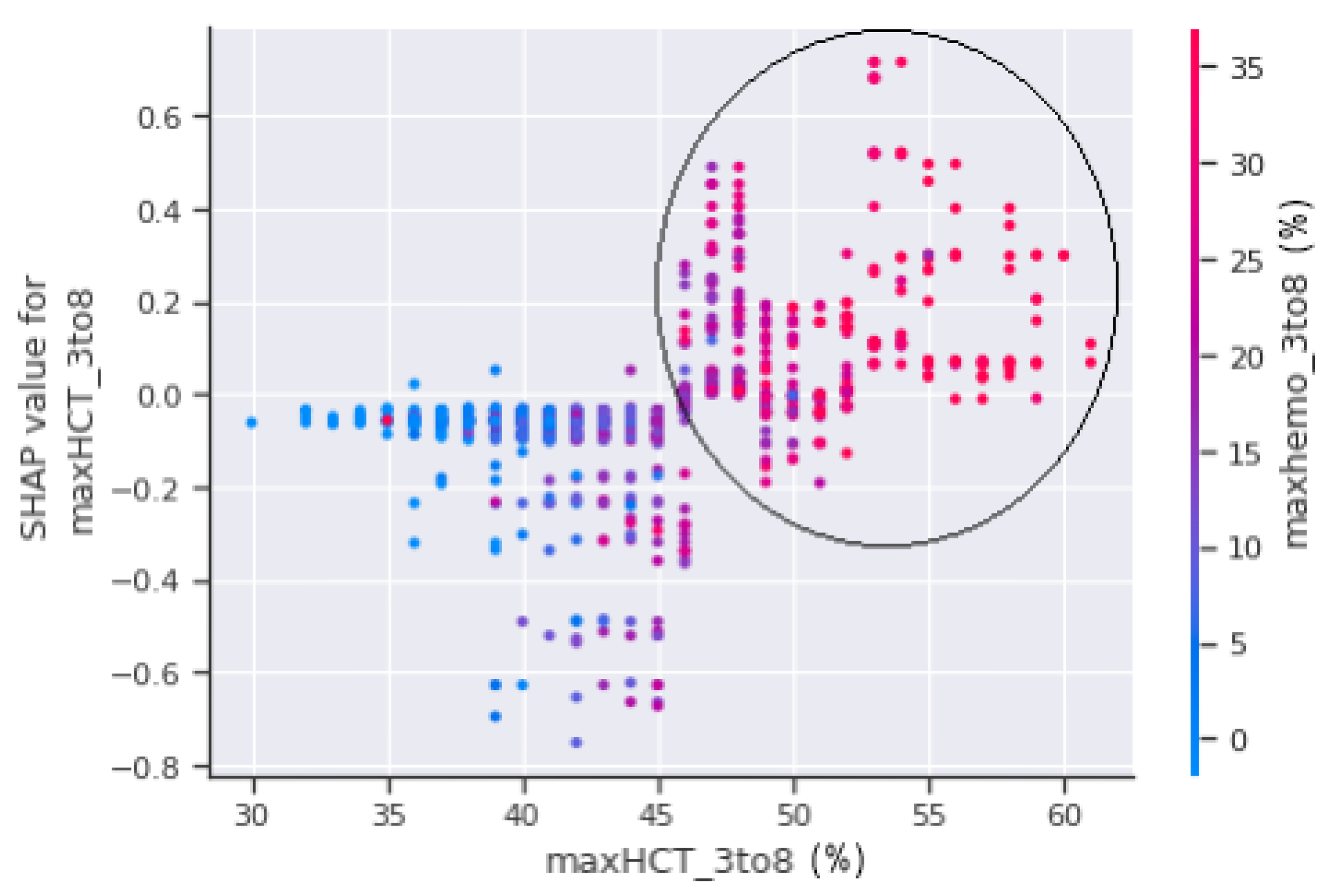
The horizontal axis, maxHCT_3to8, is depicted in
Figure 11 and represents the actual value of the maximum haematocrit count between the third and eighth days of the patient’s enrolment, whereas the vertical axis represents a value that has an impact on the prediction, i.e., severity, to confirm shock or non-shock. Patients with a haematocrit concentration of more than 45% are more prone to fall into shock and develop DSS, as seen in the circled part of
Figure 11. The circled region has a higher concentration of red dots which indicate that the patients in those areas were sent to the PICU.
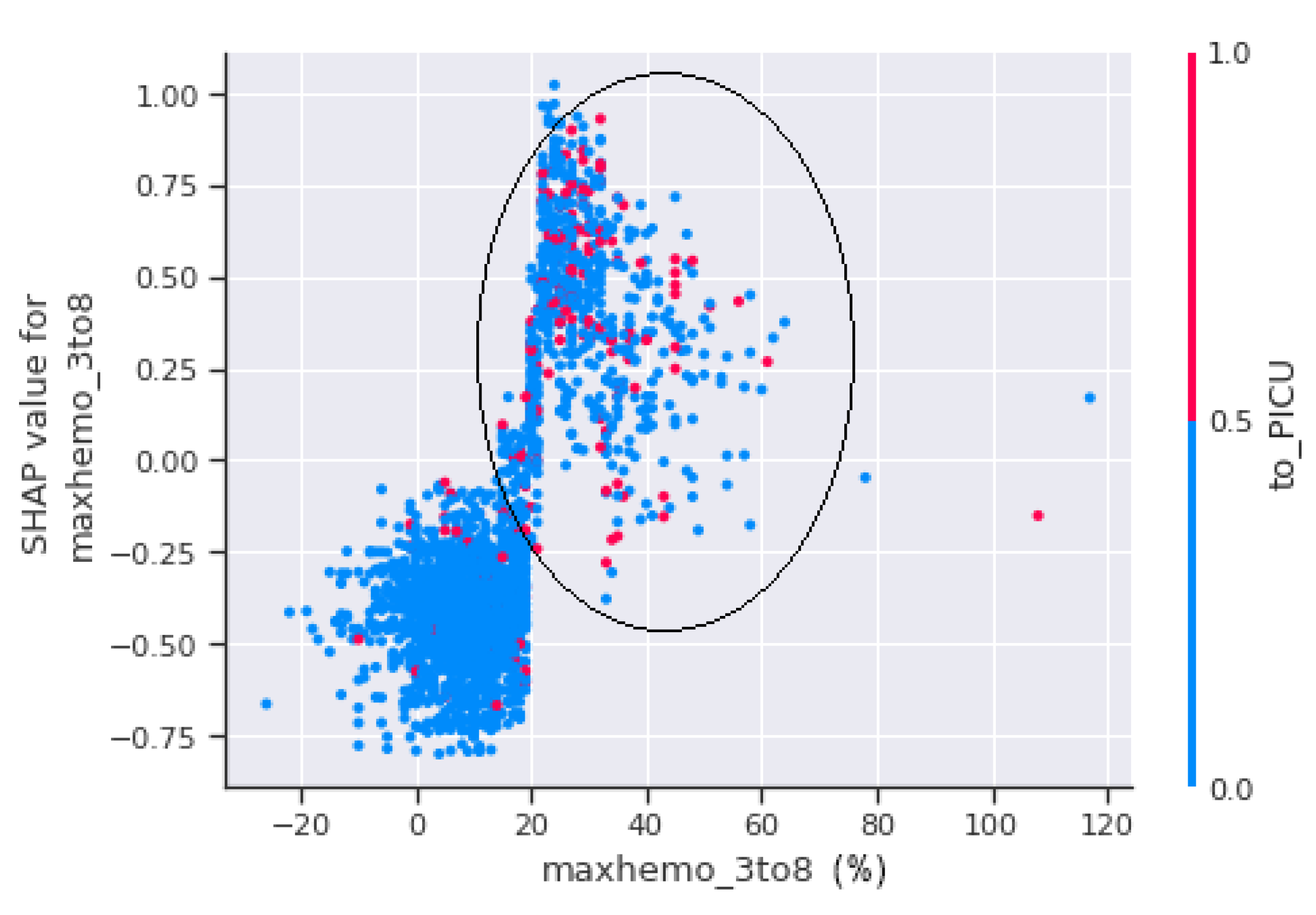
A scatter plot between maxhemo_3to8 and to_PICU is seen in
Figure 12.
Figure 12 shows that the patients with a haemoconcentration of more than 20% have the highest risk of suffering shock, regardless of whether they are admitted to PICU or not.
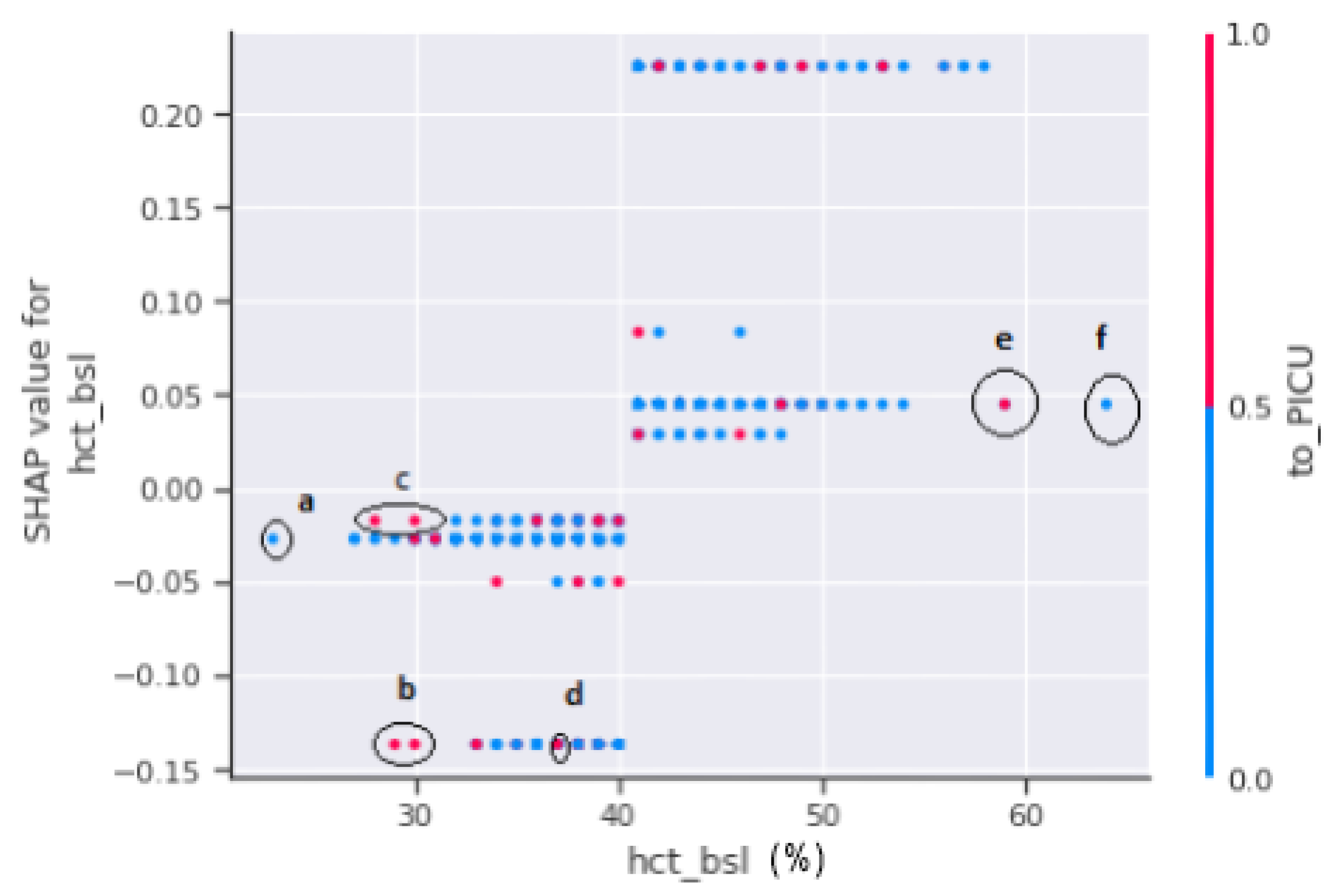
A SHAP dependency scatter plot between hct_bsl and to_PICU is shown in
Figure 13. Haematocrit (HCT) testing was performed to determine the extent of plasma leakages. The SHAP-dependent plot in
Figure 13 does not offer a clear picture. As a result, no decision can be made on the severity of the patients since, if marked regions “b”, “c”, and “d” are observed, any patient in the range of 25% to 45% of the hct concentration is either referred to PICU or has a minimal chance of progressing to shock. On the other hand, if marked regions “e” and “f” are considered, patients with hct levels exceeding 45% have a higher risk of developing dengue shock syndrome.
Figure 14 shows a relation between the maximum haematocrit count and the haemoconcentration on the third and eighth days of enrolment of the patients. The circle portion indicates, if the haemoconcentration is above 20% with respect to a 45% maximum haematocrit count, the patient is going to suffer from hazardous health issues, which may lead to either DHF or DSS.
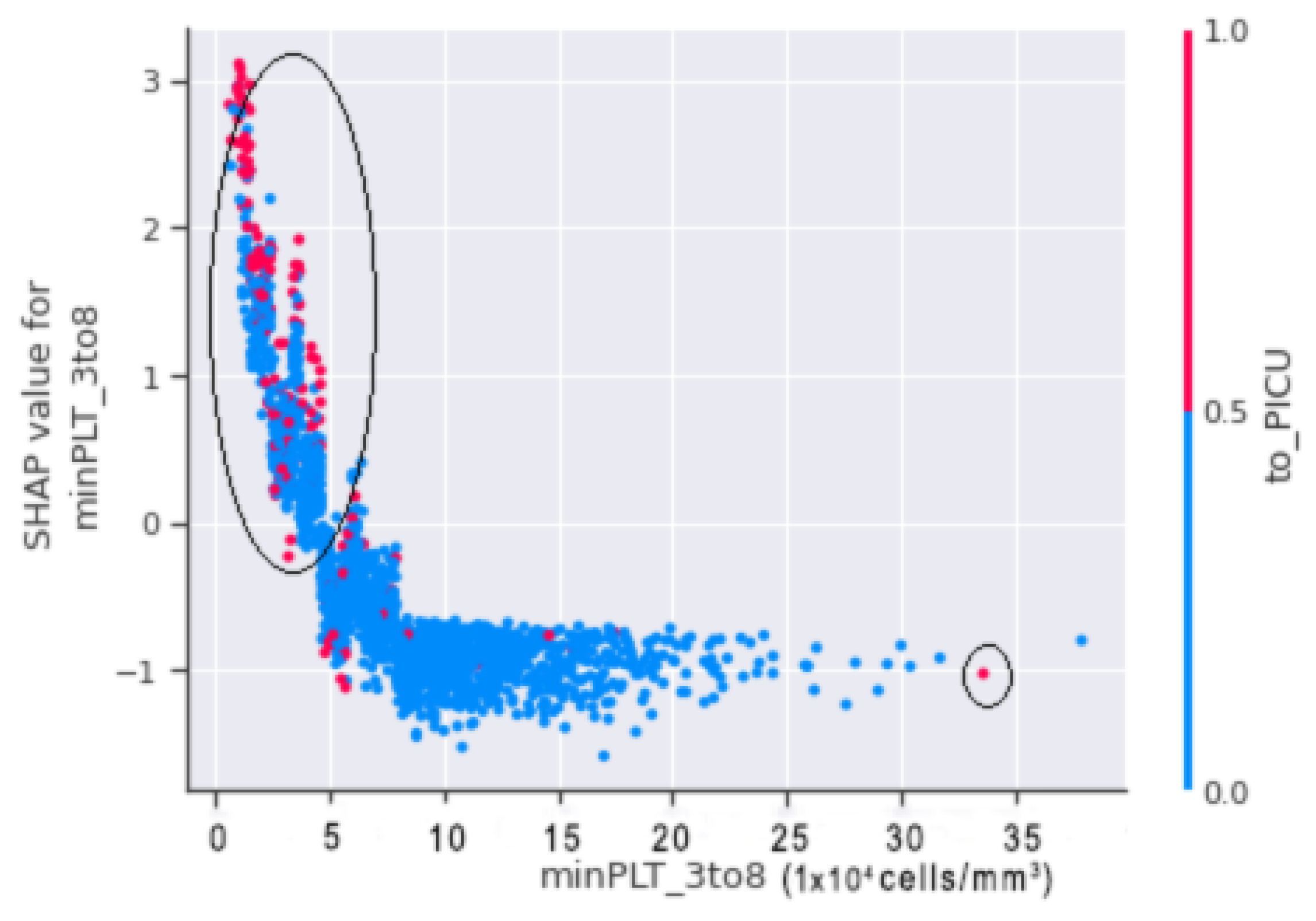
In the
Figure 15, the horizontal axis contains to_PICU which shows the actual value from the datasets, and the vertical axis indicates the value of minPLT_3to8 that has an impact on the prediction. The increasing slope reflects the value of to_PICU, which is 1 (positive), indicating that the model is more likely to predict that the patient would go into shock.
In
Figure 16, horizontal axis minPLT_3to8 refers to the actual value from the dataset, and the vertical axis shows the value that has an impact on the prediction. The upward slope shows that, when the value of to_PICU is 1 (positive), there is a higher chance for the patient to go into shock.
Thus, by merging both scatter plots of
Figure 15 and
Figure 16, it is shown that, when minPLT 3to8, i.e., patients with a minimal platelet count between the third and eighth days of admission to the hospital, have low values, there is a higher chance that the patient will go into shock. Furthermore, the majority of the children in the VDengue dataset who were on the verge of DSS or were in susceptible situations were admitted to the PICU. In the circled region of
Figure 16, we can observe that the patients brought to the PICU had platelet counts ranging from 15,000 to 50,000 (cells/mm
), resulting in a positive SHAP score, indicating DSS. If we look at the right bottom corner, we can observe that the patient has taken to_PICU, however, since the platelet count is approximately 300,000 cells/mm
and the patient has a negative SHAP value, it is unlikely that the patient would go into shock.
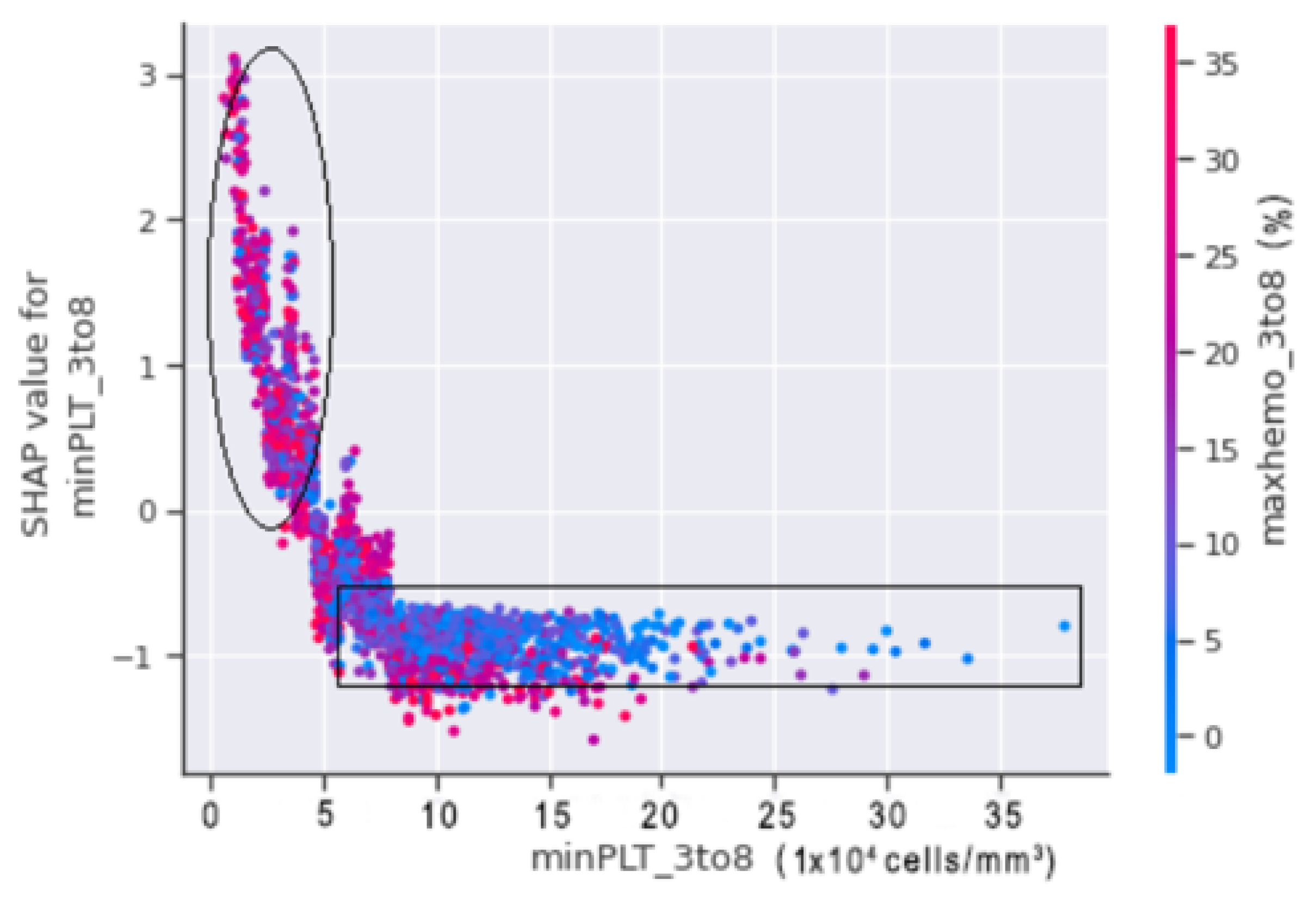
A SHAP dependence plot was plotted between minPLT_3to8 and maxhemo_3to8 to show the relation between the minimum platelets count and the maximum haemoconcentration from our datasets.
In
Figure 17, the circled region indicates that the patients in that region are more likely to fall into shock. Patients with a minimum platelet count ranges between 20,000 (cells/mm
) and 50,000 (cells/mm
) with a haemoconcentration of more than 20% are at risk of shock. A minimum platelet count of more than 50,000 (cells/mm
) and haemoconcentration of less than 20%, on the other hand, indicate that the patient is less prone to suffer DSS.
The serotype is the recognisable variation in bacteria or viruses or immune cells of different individuals within a species [
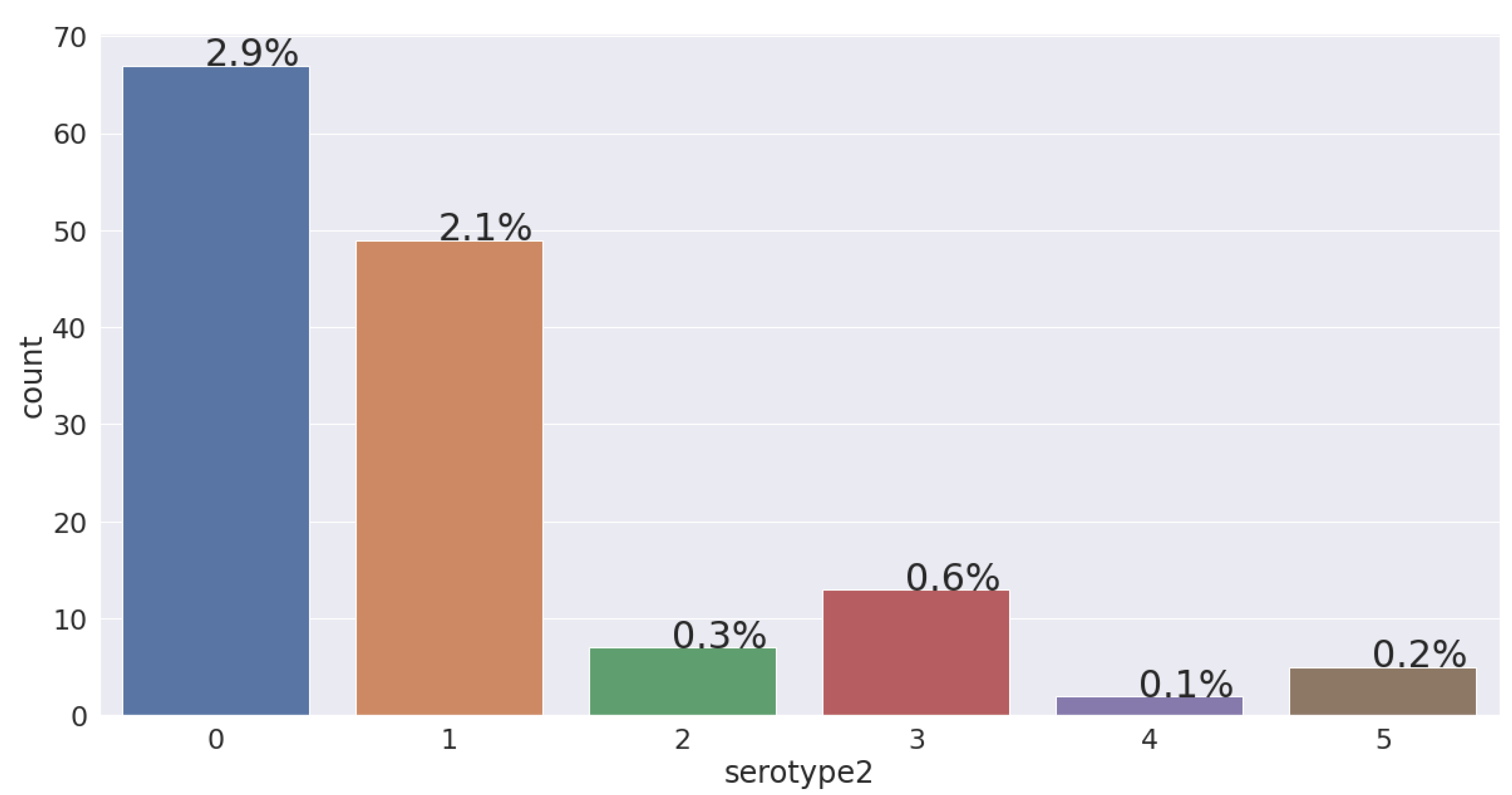
28]. Considering the VDengue dataset, 6.21% of patients have reached to shock and have a tendency to develop dengue shock syndrome. If we look into
Figure 18, we can see the percentage of the patients who have suffered from different serotypes. Among the 143 (6.21%) patients that reached to shock in the VDengue dataset, 67 (2.9%) had DENV1, 49 (2.1%) had DENV2, 7 (0.3%) had DENV3, 13 (0.6%) had DENV4, 2 (0.1%) had mixed serotypes, and 5 (0.2%) had no serotype. A bar diagram is also plotted based on the VDengue dataset, which shows that patients with DENV1 and DENV2 are most likely to associate with shock, where the patients have a high chance to develop DSS.
Taking into consideration the minimum platelets, the maximum haematocrit, and the haemoconcentration monitored for 3 to 8 days after admission into the hospital, the mean value for all the three features with respect to the serotype was calculated. After the calculation, it was found that the patients fell into the category of the DENV-1 serotype, and having a mean value of 30,942 (cells/mm) platelets, 48% hematocrit, and 25% hemoconcentration is very much likely to lead to developing DSS.
0 = DENV1;
1 = DENV2;
2 = DENV3;
3 = DENV4;
4 = MIXED;
5 = NEGATIVE.
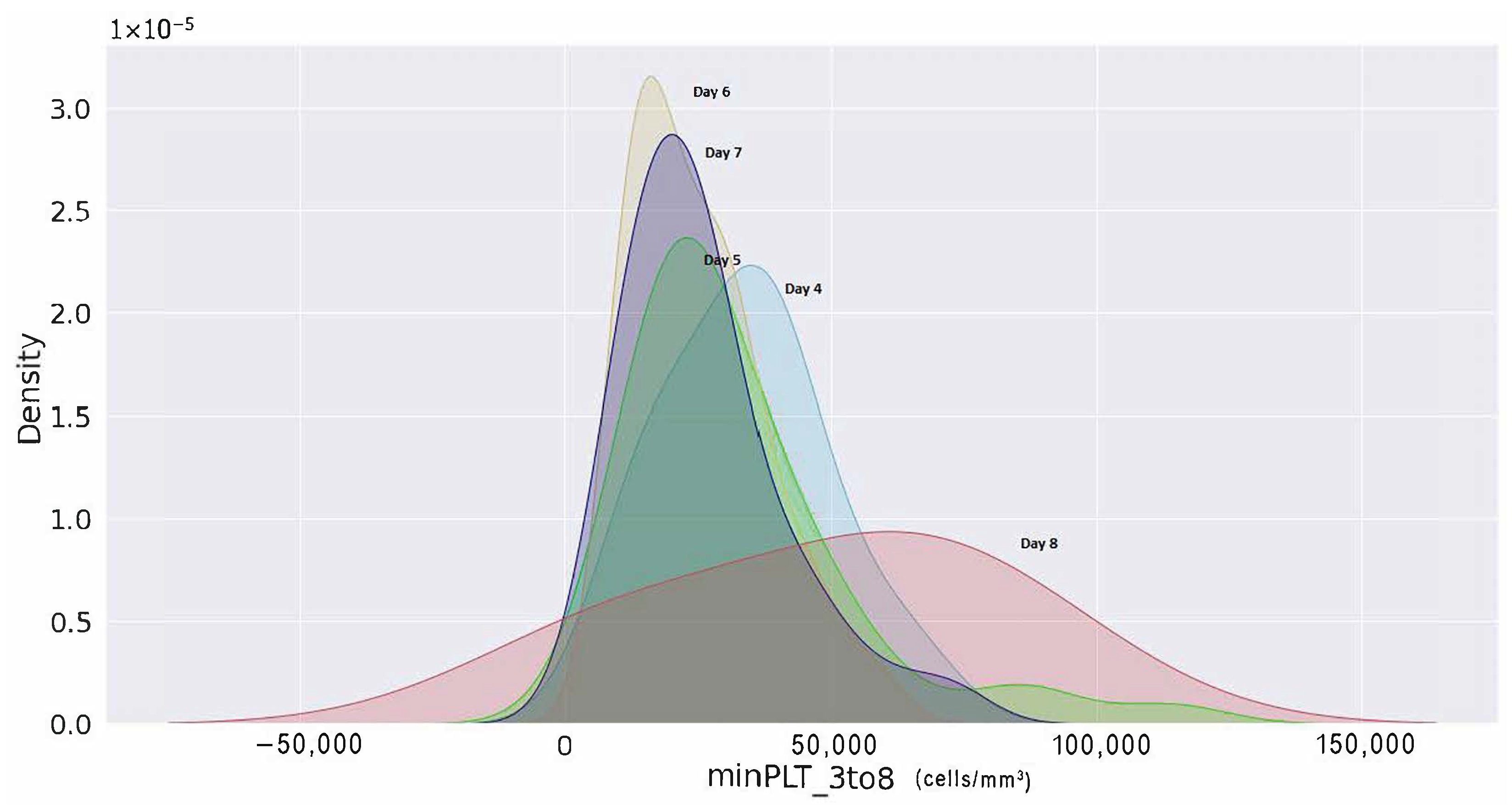
Furthermore, a kernel density estimation graph was generated to assess the probability of minimum platelets and a maximum haematocrit count from day 3 to day 8 of their enrolment. The probability density of minimal platelets and highest haematocrit concentration of patients with shock are displayed in
Figure 19 from day 3 of hospital admission to day 8. According to the density curve in
Figure 19, patients with platelets fewer than 50,000 (cells/mm
) on day 6 counted from the day of patient registration had the highest density probability. Similarly, it can be shown in
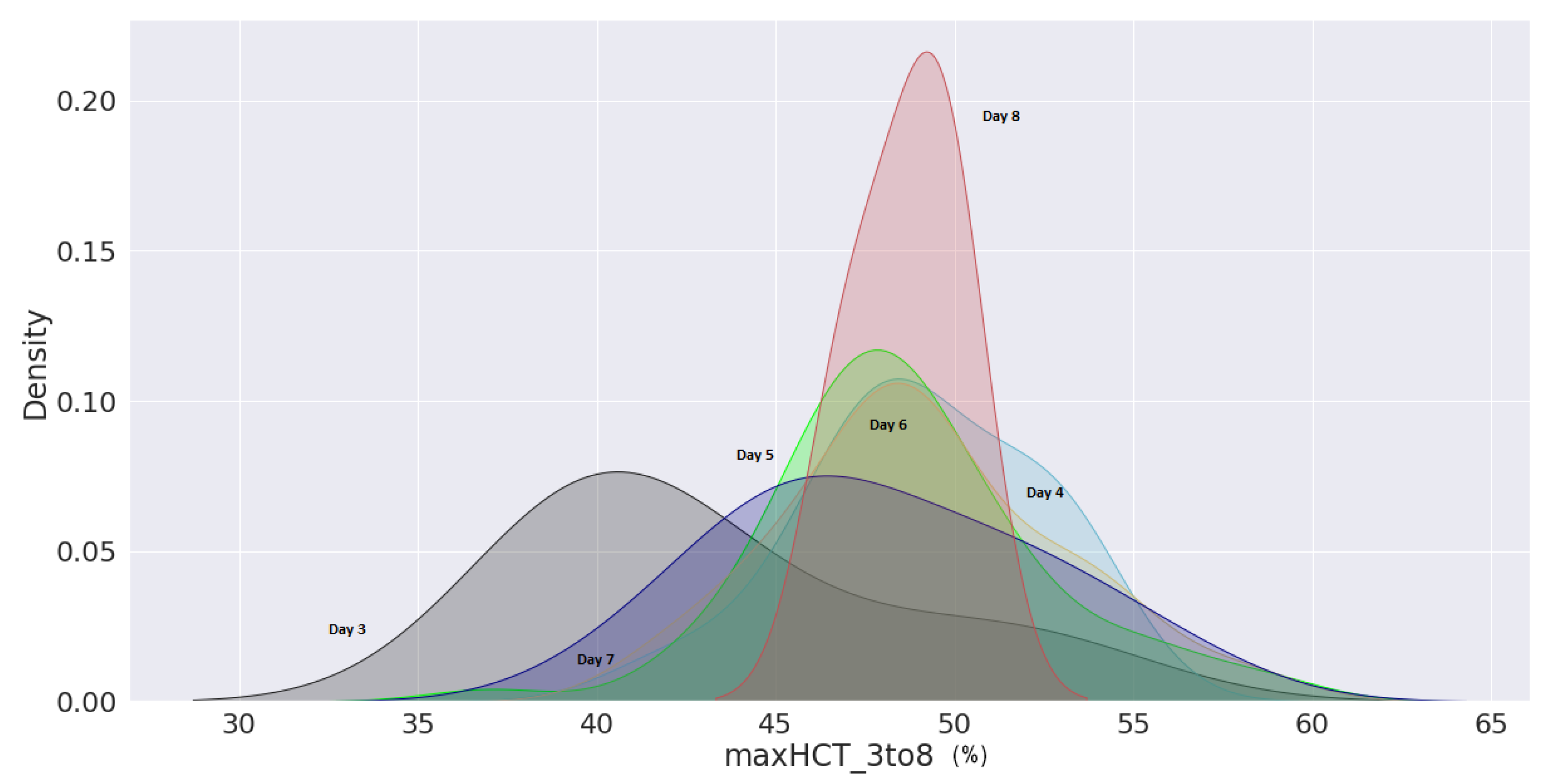
Figure 20 that an individual with haematocrit concentrations greater than 45% on day 8 had the highest density probability.
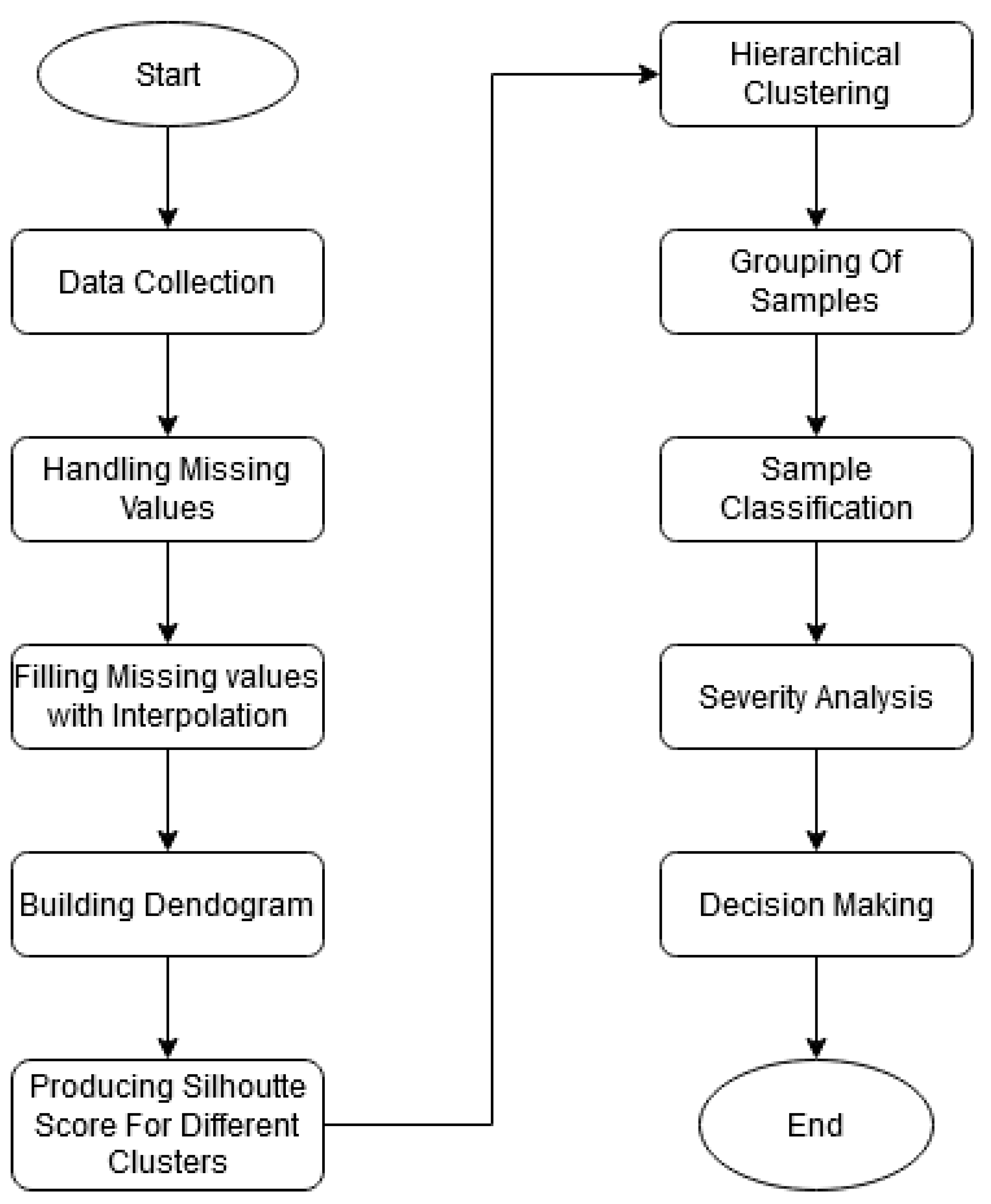
7.2. Analysis on the BDengue Dataset
The BDengue dataset was used with the agglomerative hierarchical clustering to determine different clusters of the patients. After fitting the dataset with the model, it starts to process by finding all of the dissimilarities between the data points. Two clusters could be formed after applying hierarchical clustering. The mean and standard deviation values of all features for both the clusters are shown in
Table 6 and
Table 7 after fitting the dataset with hierarchical clustering. Later, the two clusters were examined further to see whether or not patients from either cluster had progressed to severity [
29]. Individual pair plots of two clusters were plotted to obtain insight into the patients displaying severity. The severity determination was made in accordance with WHO guidelines. Thus, after examining both clusters, 106 patients from a total of 169 patients belonged to cluster 0, and none of the patients from cluster 0 achieved severity since their platelet count was greater than 200,000 (cells/mm
).
Cluster 1 includes the remaining 63 cases. In the instance of Cluster 1, some individuals experience typical dengue fever whereas others are at risk of developing DHF. It was shown that 44% of cluster 1 patients have a very high likelihood of progressing to severity since their platelet count was less than 100,000 (cells/mm), indicating that the patients may develop thrombocytopenia. In contrast, 55% of patients in cluster 1 have normal DF because their platelet count is greater than 100,000 (cells/mm).
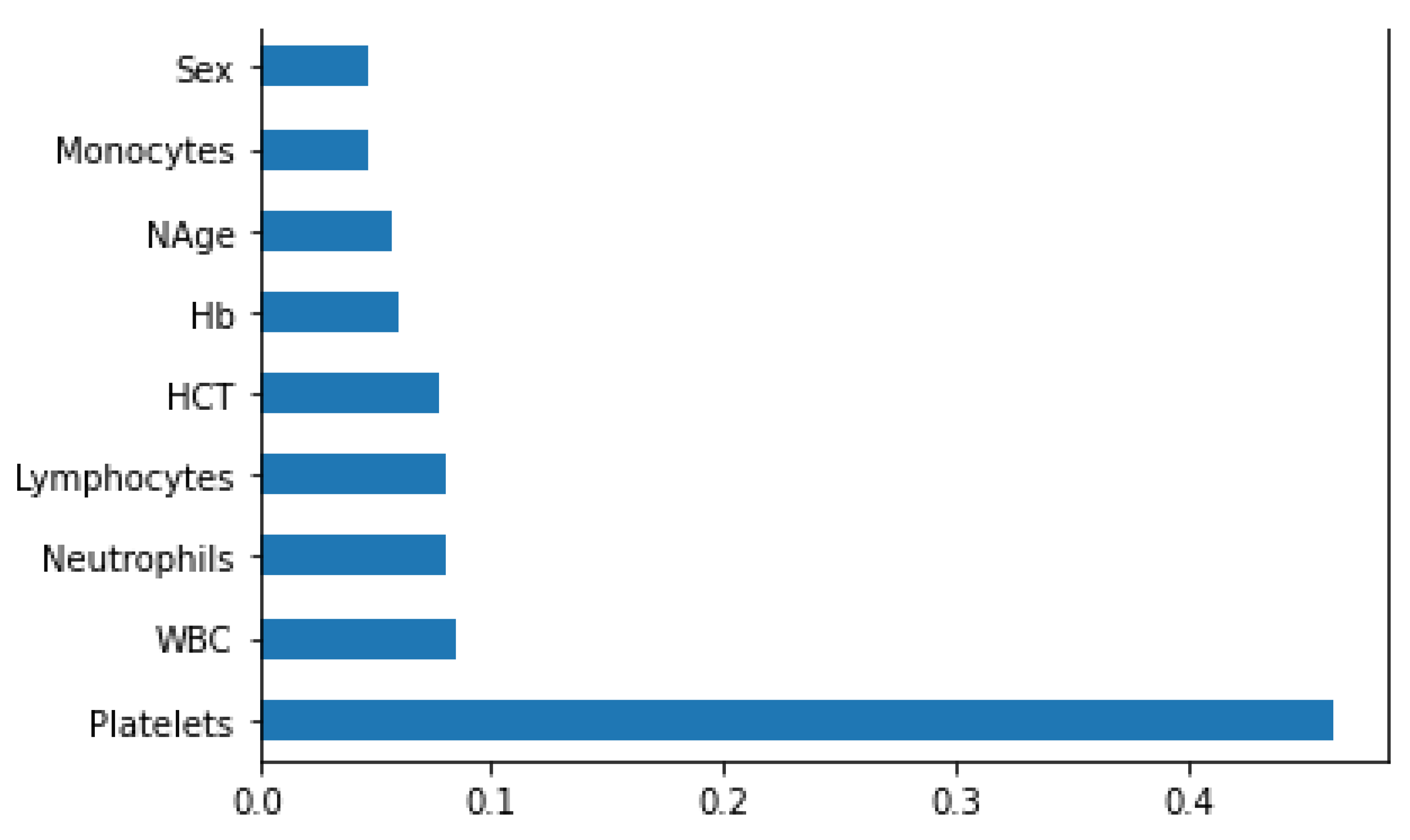
Moreover we can observe that the patients in cluster 0 have a mean neutrophils count of 65% and patients in cluster 1 have a mean neutrophils count of 52%. Neutrophils are the part of white blood cells that help the body to fight against any foreign body or any sort of infection and help the injured tissues to heal faster. However, individuals in cluster 1 are more likely to develop neutropenia, which is characterised by low levels of neutrophils, which increases the higher risk of getting infected by different types of infections [
8]. In addition to that, the mean HCT percentage in cluster 1 patients is slightly higher than the cluster 0 patients. Despite having a higher risk of DHF or DSS, cluster 1 patients had a higher mean proportion of lymphocytes than cluster 0 patients. Cluster 0 has a mean percentage of lymphocytes count of 28.5%, whereas cluster 1 has a mean percentage of 40%. If the number of lymphocytes decreases further in cluster 0 individuals, lymphocytopenia may ensue. Furthermore, the mean percentage count of Hb and monocytes for both clusters was the same.


 ,
, 























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}