
Developments in Image Processing Using Deep Learning and Reinforcement Learning



{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Methodology
2.1. Search Process and Sources of Information
2.2. Inclusion and Exclusion Criteria for Article Selection
3. Technical Background
3.1. Graphics Processing Units
3.2. Image Processing
3.3. Machine Learning Overview
- In supervised learning, we can determine predictive functions using labeled training datasets, meaning each data object instance must include an input for both the values and the expected labels or output values [21]. This class of algorithms tries to identify the relationships between input and output values and generate a predictive model able to determine the result based only on the corresponding input data [3,21]. Supervised learning methods are suitable for regression and data classification, being primarily used for a variety of algorithms like linear regression, artificial neural networks (ANNs), decision trees (DTs), support vector machines (SVMs), k-nearest neighbors (KNNs), random forest (RF), and others [3]. As an example, systems using RF and DT algorithms have developed a huge impact on areas such as computational biology and disease prediction, while SVM has also been used to study drug–target interactions and to predict several life-threatening diseases, such as cancer or diabetes [23].
- Unsupervised learning is typically used to solve several problems in pattern recognition based on unlabeled training datasets. Unsupervised learning algorithms are able to classify the training data into different categories according to their different characteristics [21,24], mainly based on clustering algorithms [24]. The number of categories is unknown, and the meaning of each category is unclear; therefore, unsupervised learning is usually used for classification problems and for association mining. Some commonly employed algorithms include K-means [3], SVM, or DT classifiers. Data processing tools like PCA, which is used for dimensionality reduction, are often necessary prerequisites before attempting to cluster a set of data.
3.3.1. Deep Learning Concepts
- Training a DNN implies the definition of a loss function, which is responsible for calculating the error made in the process given by the difference between the expected output value and that produced by the network. One of the most used loss functions in regression problems is the mean squared error (MSE) [30]. In the training phase, the weight vector that minimizes the loss function is adjusted, meaning it is not possible to obtain analytical solutions effectively. The loss function minimization method usually used is gradient descent [30].
- Activation functions are fundamental in the process of learning neural network models, as well as in the interpretation of complex nonlinear functions. The activation function adds nonlinear features to the model, allowing it to represent more than one linear function, which would not happen otherwise, no matter how many layers it had. The Sigmoid function is the most commonly used activation function in the early stages of studying neural networks [30].
- As their capacity to learn and adjust to data is greater than that of traditional ML models, it is more likely that overfitting situations will occur in DL models. For this reason, regularization represents a crucial and highly effective set of techniques used to reduce the generalization errors in ML. Some other techniques that can contribute to achieving this goal are increasing the size of the training dataset, stopping at an early point in the training phase, or randomly discarding a portion of the output of neurons during the training phase [30].
- In order to increase stability and reduce convergence times in DL algorithms, optimizers are used, with which greater efficiency in the hyperparameter adjustment process is also possible [30].
3.3.2. Reinforcement Learning Concepts
3.4. Current Challenges
4. Image Processing Developments
4.1. Domains
4.1.1. Research Using Deep Learning
- One of the first DL models used for video prediction, inspired by the sequence-to-sequence model usually used in natural language processing [97], uses a recurrent long and short term memory network (LSTM) to predict future images based on a sequence of images encoded during video data processing [97].
- In their research, Salahzadeh et al. [98] presented a novel mechatronics platform for static and real-time posture analysis, combining 3 complex components. The components included a mechanical structure with cameras, a software module for data collection and semi-automatic image analysis, and a network to provide the raw data to the DL server. The authors concluded that their device, in addition to being inexpensive and easy to use, is a method that allows postural assessment with great stability and in a non-invasive way, proving to be a useful tool in the rehabilitation of patients.
- Studies in graphical search engines and content-based image retrieval (CBIR) systems have also been successfully developed recently [11,82,99,100], with processing times that might be compatible with real-time applications. Most importantly, the corresponding results of these studies appeared to show adequate image retrieval capabilities, displaying an undisputed similarity between input and output, both on a semantic basis and a graphical basis [82]. In a review by Latif et al. [101], the authors concluded that image feature representation, as it is performed, is impossible to be represented by using a unique feature representation. Instead, it should be achieved by a combination of said low-level features, considering they represent the image in the form of patches and, as such, the performance is increased.
- In their publication, Rani et al. [102] reviewed the current literature found on this topic from the period from 1995 to 2021. The authors found that researchers in microbiology have employed ML techniques for the image recognition of four types of micro-organisms: bacteria, algae, protozoa, and fungi. In their research work, Kasinathan and Uyyala [17] apply computer vision and knowledge-based approaches to improve insect detection and classification in dense image scenarios. In this work, image processing techniques were applied to extract features, and classification models were built using ML algorithms. The proposed approach used different feature descriptors, such as texture, color, shape, histograms of oriented gradients (HOG) and global image descriptors (GIST). ML was used to analyze multivariety insect data to obtain the efficient utilization of resources and improved classification accuracy for field crop insects with a similar appearance.
4.1.2. Research Using Reinforcement Learning
5. Discussion and Future Directions
6. Conclusions
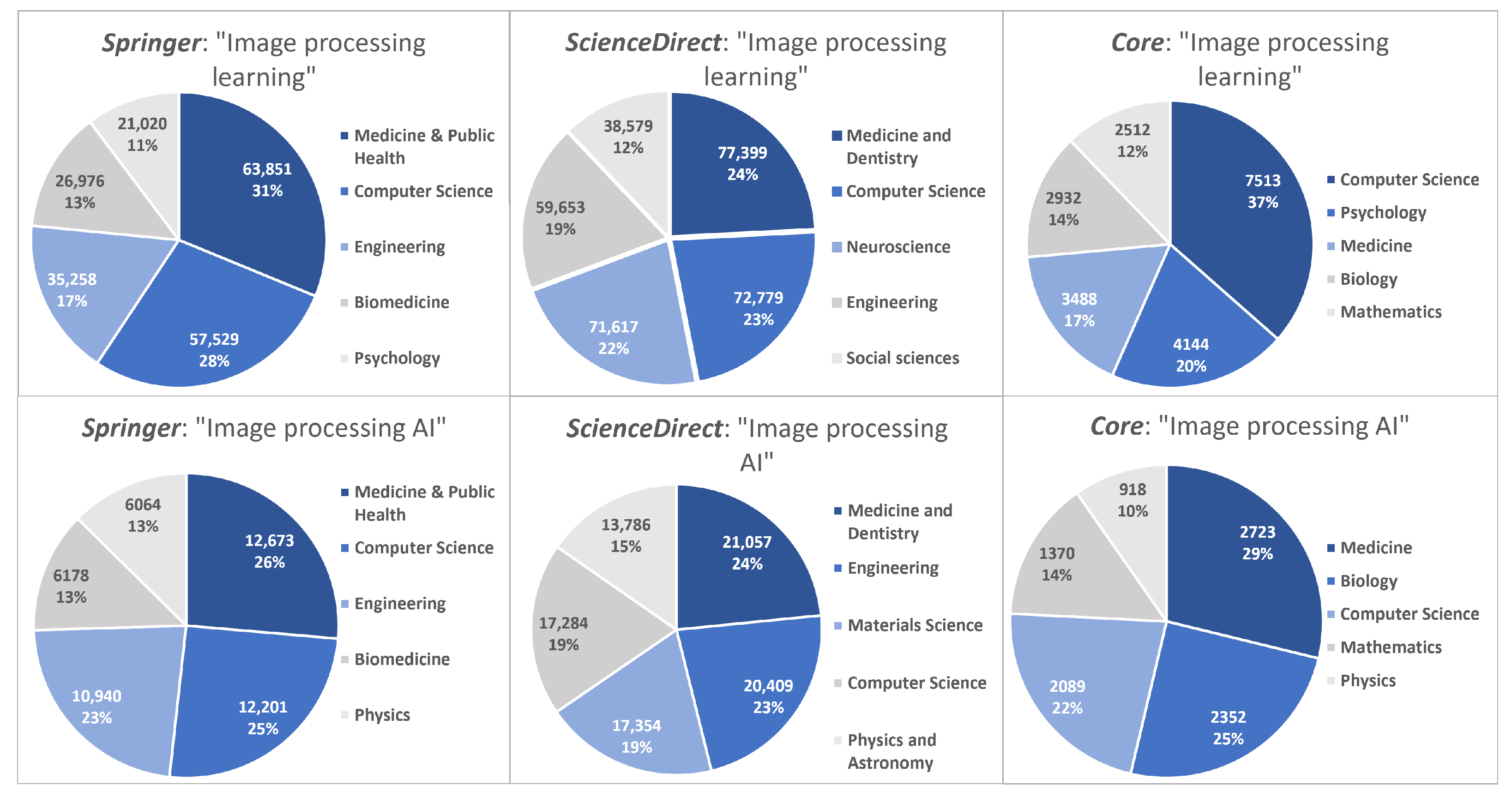
- Interest in image-processing systems using DL methods has exponentially increased over the last few years. The most common research disciplines for image processing and AI are medicine, computer science, and engineering.
- Traditional ML methods are still extremely relevant and are frequently used in fields such as computational biology and disease diagnosis and prediction or to assist in specific tasks when coupled with other more complex methods. DL methods have become of particular interest in many image-processing problems, particularly because of their ability to circumvent some of the challenges that more traditional approaches face.
- A lot of attention from researchers seems to focus on improving model performance, reducing computational resources and time, and expanding the application of ML models to solve concrete real-world problems.
- The medical field seems to have developed a particular interest in research using multiple classes and methods of learning algorithms. DL image processing has been useful in analyzing medical exams and other imaging applications. Some areas have also still found success using more traditional ML methods.
- Another area of interest appears to be autonomous driving and driver profiling, possibly powered by the increased access to information available both for the drivers and the vehicles alike. Indeed, modern driving assistance systems have already implemented features such as (a) road lane finding, (b) free driving space finding, (c) traffic sign detection and recognition, (d) traffic light detection and recognition, and (e) road-object detection and tracking. This research field will undoubtedly be responsible for many more studies in the near future.
- Graphical search engines and content-based image retrieval systems also present themselves as an interesting topic of research for image processing, with a diverse body of work and innovative approaches.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Inteligence |
| ML | Machine Learning |
| DL | Deep Learning |
| CBIR | Content Based Image Retrieval |
| CNN | Convolutional Neural Network |
| DNN | Deep Neural Network |
| DCNN | Deep Convolution Neural Network |
| RGB | Red, Green, and Blue |
References
- Raschka, S.; Patterson, J.; Nolet, C. Machine Learning in Python: Main Developments and Technology Trends in Data Science, Machine Learning, and Artificial Intelligence. Information 2020, 11, 193. [Google Scholar] [CrossRef]
- Barros, D.; Moura, J.; Freire, C.; Taleb, A.; Valentim, R.; Morais, P. Machine learning applied to retinal image processing for glaucoma detection: Review and perspective. BioMed. Eng. OnLine 2020, 19, 20. [Google Scholar] [CrossRef]
- Zhu, M.; Wang, J.; Yang, X.; Zhang, Y.; Zhang, L.; Ren, H.; Wu, B.; Ye, L. A review of the application of machine learning in water quality evaluation. Eco-Environ. Health 2022, 1, 107–116. [Google Scholar] [CrossRef]
- Singh, V.; Chen, S.S.; Singhania, M.; Nanavati, B.; kumar kar, A.; Gupta, A. How are reinforcement learning and deep learning algorithms used for big data based decision making in financial industries–A review and research agenda. Int. J. Inf. Manag. Data Insights 2022, 2, 100094. [Google Scholar] [CrossRef]
- Moscalu, M.; Moscalu, R.; Dascălu, C.G.; Țarcă, V.; Cojocaru, E.; Costin, I.M.; Țarcă, E.; Șerban, I.L. Histopathological Images Analysis and Predictive Modeling Implemented in Digital Pathology—Current Affairs and Perspectives. Diagnostics 2023, 13, 2379. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Yang, D.M.; Rong, R.; Zhan, X.; Fujimoto, J.; Liu, H.; Minna, J.; Wistuba, I.I.; Xie, Y.; Xiao, G. Artificial Intelligence in Lung Cancer Pathology Image Analysis. Cancers 2019, 11, 1673. [Google Scholar] [CrossRef]
- van der Velden, B.H.M.; Kuijf, H.J.; Gilhuijs, K.G.; Viergever, M.A. Explainable artificial intelligence (XAI) in deep learning-based medical image analysis. Med. Image Anal. 2022, 79, 102470. [Google Scholar] [CrossRef]
- Prevedello, L.M.; Halabi, S.S.; Shih, G.; Wu, C.C.; Kohli, M.D.; Chokshi, F.H.; Erickson, B.J.; Kalpathy-Cramer, J.; Andriole, K.P.; Flanders, A.E. Challenges related to artificial intelligence research in medical imaging and the importance of image analysis competitions. Radiol. Artif. Intell. 2019, 1, e180031. [Google Scholar] [CrossRef]
- Smith, K.P.; Kirby, J.E. Image analysis and artificial intelligence in infectious disease diagnostics. Clin. Microbiol. Infect. 2020, 26, 1318–1323. [Google Scholar] [CrossRef]
- Wu, Q. Research on deep learning image processing technology of second-order partial differential equations. Neural Comput. Appl. 2023, 35, 2183–2195. [Google Scholar] [CrossRef]
- Jardim, S.; António, J.; Mora, C. Graphical Image Region Extraction with K-Means Clustering and Watershed. J. Imaging 2022, 8, 163. [Google Scholar] [CrossRef]
- Ying, C.; Huang, Z.; Ying, C. Accelerating the image processing by the optimization strategy for deep learning algorithm DBN. EURASIP J. Wirel. Commun. Netw. 2018, 232, 232. [Google Scholar] [CrossRef]
- Protopapadakis, E.; Voulodimos, A.; Doulamis, A.; Doulamis, N.; Stathaki, T. Automatic crack detection for tunnel inspection using deep learning and heuristic image post-processing. Appl. Intell. 2019, 49, 2793–2806. [Google Scholar] [CrossRef]
- Yong, B.; Wang, C.; Shen, J.; Li, F.; Yin, H.; Zhou, R. Automatic ventricular nuclear magnetic resonance image processing with deep learning. Multimed. Tools Appl. 2021, 80, 34103–34119. [Google Scholar] [CrossRef]
- Freeman, W.; Jones, T.; Pasztor, E. Example-based super-resolution. IEEE Comput. Graph. Appl. 2002, 22, 56–65. [Google Scholar] [CrossRef]
- Rodellar, J.; Alférez, S.; Acevedo, A.; Molina, A.; Merino, A. Image processing and machine learning in the morphological analysis of blood cells. Int. J. Lab. Hematol. 2018, 40, 46–53. [Google Scholar] [CrossRef] [PubMed]
- Kasinathan, T.; Uyyala, S.R. Machine learning ensemble with image processing for pest identification and classification in field crops. Neural Comput. Appl. 2021, 33, 7491–7504. [Google Scholar] [CrossRef]
- Yadav, P.; Gupta, N.; Sharma, P.K. A comprehensive study towards high-level approaches for weapon detection using classical machine learning and deep learning methods. Expert Syst. Appl. 2023, 212, 118698. [Google Scholar] [CrossRef]
- Suganyadevi, S.; Seethalakshmi, V.; Balasamy, K. Reinforcement learning coupled with finite element modeling for facial motion learning. Int. J. Multimed. Inf. Retr. 2022, 11, 19–38. [Google Scholar] [CrossRef]
- Zeng, Y.; Guo, Y.; Li, J. Recognition and extraction of high-resolution satellite remote sensing image buildings based on deep learning. Neural Comput. Appl. 2022, 34, 2691–2706. [Google Scholar] [CrossRef]
- Pratap, A.; Sardana, N. Machine learning-based image processing in materials science and engineering: A review. Mater. Today Proc. 2022, 62, 7341–7347. [Google Scholar] [CrossRef]
- Mahesh, B. Machine Learning Algorithms—A Review. Int. J. Sci. Res. 2020, 9, 1–6. [Google Scholar] [CrossRef]
- Singh, D.P.; Kaushik, B. Machine learning concepts and its applications for prediction of diseases based on drug behaviour: An extensive review. Chemom. Intell. Lab. Syst. 2022, 229, 104637. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. In Proceedings of the 4th International Conference on Learning Representations 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar] [CrossRef]
- Dworschak, F.; Dietze, S.; Wittmann, M.; Schleich, B.; Wartzack, S. Reinforcement Learning for Engineering Design Automation. Adv. Eng. Inform. 2022, 52, 101612. [Google Scholar] [CrossRef]
- Khan, T.; Tian, W.; Zhou, G.; Ilager, S.; Gong, M.; Buyya, R. Machine learning (ML)-centric resource management in cloud computing: A review and future directions. J. Netw. Comput. Appl. 2022, 204, 103405. [Google Scholar] [CrossRef]
- Botvinick, M.; Ritter, S.; Wang, J.X.; Kurth-Nelson, Z.; Blundell, C.; Hassabis, D. Reinforcement Learning, Fast and Slow. Trends Cogn. Sci. 2019, 23, 408–422. [Google Scholar] [CrossRef]
- Moravčík, M.; Schmid, M.; Burch, N.; Lisý, V.; Morrill, D.; Bard, N.; Davis, T.; Waugh, K.; Johanson, M.; Bowling, M. DeepStack: Expert-level artificial intelligence in heads-up no-limit poker. Science 2017, 356, 508–513. [Google Scholar] [CrossRef]
- ElDahshan, K.A.; Farouk, H.; Mofreh, E. Deep Reinforcement Learning based Video Games: A Review. In Proceedings of the 2nd International Mobile, Intelligent, and Ubiquitous Computing Conference (MIUCC), Cairo, Egypt, 8–9 May 2022. [Google Scholar] [CrossRef]
- Huawei Technologies Co., Ltd. Overview of Deep Learning. In Artificial Intelligence Technology; Springer: Singapore, 2023; Chapter 1–4; pp. 87–122. [Google Scholar] [CrossRef]
- Le, N.; Rathour, V.S.; Yamazaki, K.; Luu, K.; Savvides, M. Deep reinforcement learning in computer vision: A comprehensive survey. Artif. Intell. Rev. 2022, 55, 2733–2819. [Google Scholar] [CrossRef]
- Melanthota, S.K.; Gopal, D.; Chakrabarti, S.; Kashyap, A.A.; Radhakrishnan, R.; Mazumder, N. Deep learning-based image processing in optical microscopy. Biophys. Rev. 2022, 14, 463–481. [Google Scholar] [CrossRef]
- Winovich, N.; Ramani, K.; Lin, G. ConvPDE-UQ: Convolutional neural networks with quantified uncertainty for heterogeneous elliptic partial differential equations on varied domains. J. Comput. Phys. 2019, 394, 263–279. [Google Scholar] [CrossRef]
- Pham, H.; Warin, X.; Germain, M. Neural networks-based backward scheme for fully nonlinear PDEs. SN Partial. Differ. Equ. Appl. 2021, 2, 16. [Google Scholar] [CrossRef]
- Wei, X.; Jiang, S.; Li, Y.; Li, C.; Jia, L.; Li, Y. Defect Detection of Pantograph Slide Based on Deep Learning and Image Processing Technology. IEEE Trans. Intell. Transp. Syst. 2020, 21, 947–958. [Google Scholar] [CrossRef]
- E, W.; Yu, B. The deep ritz method: A deep learning based numerical algorithm for solving variational problems. Commun. Math. Stat. 2018, 6, 1–12. [Google Scholar] [CrossRef]
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Imaging 2018, 9, 611–629. [Google Scholar] [CrossRef] [PubMed]
- Archarya, U.; Oh, S.; Hagiwara, Y.; Tan, J.; Adam, M.; Gertych, A.; Tan, R. A deep convolutional neural network model to classify heartbeats. Comput. Biol. Med. 2021, 89, 389–396. [Google Scholar] [CrossRef]
- Ha, V.K.; Ren, J.C.; Xu, X.Y.; Zhao, S.; Xie, G.; Masero, V.; Hussain, A. Deep Learning Based Single Image Super-resolution: A Survey. Int. J. Autom. Comput. 2019, 16, 413–426. [Google Scholar] [CrossRef]
- Jeong, C.Y.; Yang, H.S.; Moon, K. Fast horizon detection in maritime images using region-of-interest. Int. J. Distrib. Sens. Netw. 2018, 14, 1550147718790753. [Google Scholar] [CrossRef]
- Olmos, R.; Tabik, S.; Lamas, A.; Pérez-Hernández, F.; Herrera, F. A binocular image fusion approach for minimizing false positives in handgun detection with deep learning. Inf. Fusion 2019, 49, 271–280. [Google Scholar] [CrossRef]
- Zhao, X.; Wu, Y.; Tian, J.; Zhang, H. Single Image Super-Resolution via Blind Blurring Estimation and Dictionary Learning. Neurocomputing 2016, 212, 3–11. [Google Scholar] [CrossRef]
- Qi, C.; Song, C.; Xiao, F.; Song, S. Generalization ability of hybrid electric vehicle energy management strategy based on reinforcement learning method. Energy 2022, 250, 123826. [Google Scholar] [CrossRef]
- Ritto, T.; Beregi, S.; Barton, D. Reinforcement learning and approximate Bayesian computation for model selection and parameter calibration applied to a nonlinear dynamical system. Mech. Syst. Signal Process. 2022, 181, 109485. [Google Scholar] [CrossRef]
- Hwang, R.; Lee, H.; Hwang, H.J. Option compatible reward inverse reinforcement learning. Pattern Recognit. Lett. 2022, 154, 83–89. [Google Scholar] [CrossRef]
- Ladosz, P.; Weng, L.; Kim, M.; Oh, H. Exploration in deep reinforcement learning: A survey. Inf. Fusion 2022, 85, 1–22. [Google Scholar] [CrossRef]
- Khayyat, M.M.; Elrefaei, L.A. Deep reinforcement learning approach for manuscripts image classification and retrieval. Multimed. Tools Appl. 2022, 81, 15395–15417. [Google Scholar] [CrossRef]
- Nguyen, D.P.; Ho Ba Tho, M.C.; Dao, T.T. A review on deep learning in medical image analysis. Comput. Methods Programs Biomed. 2022, 221, 106904. [Google Scholar] [CrossRef]
- Laskin, M.; Lee, K.; Stooke, A.; Pinto, L.; Abbeel, P.; Srinivas, A. Reinforcement Learning with Augmented Data. In Proceedings of the 34th Conference on Neural Information Processing Systems 2020, Vancouver, BC, Canada, 6–12 December 2020; pp. 19884–19895. [Google Scholar]
- Li, H.; Xu, H. Deep reinforcement learning for robust emotional classification in facial expression recognition. Knowl.-Based Syst. 2020, 204, 106172. [Google Scholar] [CrossRef]
- Gomes, G.; Vidal, C.A.; Cavalcante-Neto, J.B.; Nogueira, Y.L. A modeling environment for reinforcement learning in games. Entertain. Comput. 2022, 43, 100516. [Google Scholar] [CrossRef]
- Georgeon, O.L.; Casado, R.C.; Matignon, L.A. Modeling Biological Agents beyond the Reinforcement-learning Paradigm. Procedia Comput. Sci. 2015, 71, 17–22. [Google Scholar] [CrossRef]
- Yin, S.; Liu, H. Wind power prediction based on outlier correction, ensemble reinforcement learning, and residual correction. Energy 2022, 250, 123857. [Google Scholar] [CrossRef]
- Badia, A.P.; Piot, B.; Kapturowski, S.; Sprechmann, P.; Vitvitskyi, A.; Guo, D.; Blundell, C. Agent57: Outperforming the Atari Human Benchmark. arXiv 2020, arXiv:2003.13350. [Google Scholar] [CrossRef]
- Zong, K.; Luo, C. Reinforcement learning based framework for COVID-19 resource allocation. Comput. Ind. Eng. 2022, 167, 107960. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Ren, J.; Guan, F.; Li, X.; Cao, J.; Li, X. Optimization for image stereo-matching using deep reinforcement learning in rule constraints and parallax estimation. Neural Comput. Appl. 2023, 1–11. [Google Scholar] [CrossRef]
- Morales, E.F.; Murrieta-Cid, R.; Becerra, I.; Esquivel-Basaldua, M.A. A survey on deep learning and deep reinforcement learning in robotics with a tutorial on deep reinforcement learning. Intell. Serv. Robot. 2021, 14, 773–805. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Krichen, M. Convolutional Neural Networks: A Survey. Computers 2023, 12, 151. [Google Scholar] [CrossRef]
- Song, D.; Kim, T.; Lee, Y.; Kim, J. Image-Based Artificial Intelligence Technology for Diagnosing Middle Ear Diseases: A Systematic Review. J. Clin. Med. 2023, 12, 5831. [Google Scholar] [CrossRef]
- Muñoz-Saavedra, L.; Escobar-Linero, E.; Civit-Masot, J.; Luna-Perejón, F.; Civit, A.; Domínguez-Morales, M. A Robust Ensemble of Convolutional Neural Networks for the Detection of Monkeypox Disease from Skin Images. Sensors 2023, 23, 7134. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Hargreaves, C.A. A Review Study of the Deep Learning Techniques used for the Classification of Chest Radiological Images for COVID-19 Diagnosis. Int. J. Inf. Manag. Data Insights 2022, 2, 100100. [Google Scholar] [CrossRef]
- Teng, Y.; Pan, D.; Zhao, W. Application of deep learning ultrasound imaging in monitoring bone healing after fracture surgery. J. Radiat. Res. Appl. Sci. 2023, 16, 100493. [Google Scholar] [CrossRef]
- Zaghari, N.; Fathy, M.; Jameii, S.M.; Sabokrou, M.; Shahverdy, M. Improving the learning of self-driving vehicles based on real driving behavior using deep neural network techniques. J. Supercomput. 2021, 77, 3752–3794. [Google Scholar] [CrossRef]
- Farag, W. Cloning Safe Driving Behavior for Self-Driving Cars using Convolutional Neural Networks. Recent Patents Comput. Sci. 2019, 11, 120–127. [Google Scholar] [CrossRef]
- Agyemang, I.; Zhang, X.; Acheampong, D.; Adjei-Mensah, I.; Kusi, G.; Mawuli, B.C.; Agbley, B.L. Autonomous health assessment of civil infrastructure using deep learning and smart devices. Autom. Constr. 2022, 141, 104396. [Google Scholar] [CrossRef]
- Zhou, S.; Canchila, C.; Song, W. Deep learning-based crack segmentation for civil infrastructure: Data types, architectures, and benchmarked performance. Autom. Constr. 2023, 146, 104678. [Google Scholar] [CrossRef]
- Guerrieri, M.; Parla, G. Flexible and stone pavements distress detection and measurement by deep learning and low-cost detection devices. Eng. Fail. Anal. 2022, 141, 106714. [Google Scholar] [CrossRef]
- Hoang, N.; Nguyen, Q. A novel method for asphalt pavement crack classification based on image processing and machine learning. Eng. Comput. 2019, 35, 487–498. [Google Scholar] [CrossRef]
- Tabrizi, S.E.; Xiao, K.; Van Griensven Thé, J.; Saad, M.; Farghaly, H.; Yang, S.X.; Gharabaghi, B. Hourly road pavement surface temperature forecasting using deep learning models. J. Hydrol. 2021, 603, 126877. [Google Scholar] [CrossRef]
- Jardim, S.V.B. Sparse and Robust Signal Reconstruction. Theory Appl. Math. Comput. Sci. 2015, 5, 1–19. [Google Scholar]
- Jackulin, C.; Murugavalli, S. A comprehensive review on detection of plant disease using machine learning and deep learning approaches. Meas. Sens. 2022, 24, 100441. [Google Scholar] [CrossRef]
- Keceli, A.S.; Kaya, A.; Catal, C.; Tekinerdogan, B. Deep learning-based multi-task prediction system for plant disease and species detection. Ecol. Inform. 2022, 69, 101679. [Google Scholar] [CrossRef]
- Kotwal, J.; Kashyap, D.; Pathan, D. Agricultural plant diseases identification: From traditional approach to deep learning. Mater. Today Proc. 2023, 80, 344–356. [Google Scholar] [CrossRef]
- Naik, A.; Thaker, H.; Vyas, D. A survey on various image processing techniques and machine learning models to detect, quantify and classify foliar plant disease. Proc. Indian Natl. Sci. Acad. 2021, 87, 191–198. [Google Scholar] [CrossRef]
- Thaiyalnayaki, K.; Joseph, C. Classification of plant disease using SVM and deep learning. Mater. Today Proc. 2021, 47, 468–470. [Google Scholar] [CrossRef]
- Carnegie, A.J.; Eslick, H.; Barber, P.; Nagel, M.; Stone, C. Airborne multispectral imagery and deep learning for biosecurity surveillance of invasive forest pests in urban landscapes. Urban For. Urban Green. 2023, 81, 127859. [Google Scholar] [CrossRef]
- Hadipour-Rokni, R.; Askari Asli-Ardeh, E.; Jahanbakhshi, A.; Esmaili paeen-Afrakoti, I.; Sabzi, S. Intelligent detection of citrus fruit pests using machine vision system and convolutional neural network through transfer learning technique. Comput. Biol. Med. 2023, 155, 106611. [Google Scholar] [CrossRef]
- Agrawal, P.; Chaudhary, D.; Madaan, V.; Zabrovskiy, A.; Prodan, R.; Kimovski1, D.; Timmerer, C. Automated bank cheque verification using image processing and deep learning methods. Multimed. Tools Appl. 2021, 80, 5319–5350. [Google Scholar] [CrossRef]
- Gordo, A.; Almazán, J.; Revaud, J.; Larlus, D. Deep Image Retrieval: Learning Global Representations for Image Search. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 241–257. [Google Scholar]
- Jardim, S.; António, J.; Mora, C.; Almeida, A. A Novel Trademark Image Retrieval System Based on Multi-Feature Extraction and Deep Networks. J. Imaging 2022, 8, 238. [Google Scholar] [CrossRef]
- Lin, K.; Yang, H.F.; Hsiao, J.H.; Chen, C.S. Deep learning of binary hash codes for fast image retrieval. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Boston, MA, USA, 7–12 June 2015; pp. 27–35. [Google Scholar] [CrossRef]
- Andriasyan, V.; Yakimovich, A.; Petkidis, A.; Georgi, F.; Georgi, R.; Puntener, D.; Greber, U. Microscopy deep learning predicts virus infections and reveals mechanics of lytic-infected cells. iScience 2021, 24, 102543. [Google Scholar] [CrossRef]
- Lüneburg, N.; Reiss, N.; Feldmann, C.; van der Meulen, P.; van de Steeg, M.; Schmidt, T.; Wendl, R.; Jansen, S. Photographic LVAD Driveline Wound Infection Recognition Using Deep Learning. In dHealth 2019—From eHealth to dHealth; IOS Press: Amsterdam, The Netherlands, 2019; pp. 192–199. [Google Scholar] [CrossRef]
- Fink, O.; Wang, Q.; Svensén, M.; Dersin, P.; Lee, W.J.; Ducoffe, M. Potential, challenges and future directions for deep learning in prognostics and health management applications. Eng. Appl. Artif. Intell. 2020, 92, 103678. [Google Scholar] [CrossRef]
- Ahmed, I.; Ahmad, M.; Jeon, G. Social distance monitoring framework using deep learning architecture to control infection transmission of COVID-19 pandemic. Sustain. Cities Soc. 2021, 69, 102777. [Google Scholar] [CrossRef]
- Hussain, S.; Yu, Y.; Ayoub, M.; Khan, A.; Rehman, R.; Wahid, J.A.; Hou, W. IoT and Deep Learning Based Approach for Rapid Screening and Face Mask Detection for Infection Spread Control of COVID-19. Appl. Sci. 2021, 11, 3495. [Google Scholar] [CrossRef]
- Kaur, J.; Kaur, P. Outbreak COVID-19 in Medical Image Processing Using Deep Learning: A State-of-the-Art Review. Arch. Comput. Methods Eng. 2022, 29, 2351–2382. [Google Scholar] [CrossRef] [PubMed]
- Groen, A.M.; Kraan, R.; Amirkhan, S.F.; Daams, J.G.; Maas, M. A systematic review on the use of explainability in deep learning systems for computer aided diagnosis in radiology: Limited use of explainable AI? Int. J. Autom. Comput. 2022, 157, 110592. [Google Scholar] [CrossRef] [PubMed]
- Hao, D.; Li, Q.; Feng, Q.X.; Qi, L.; Liu, X.S.; Arefan, D.; Zhang, Y.D.; Wu, S. SurvivalCNN: A deep learning-based method for gastric cancer survival prediction using radiological imaging data and clinicopathological variables. Artif. Intell. Med. 2022, 134, 102424. [Google Scholar] [CrossRef]
- Cui, X.; Zheng, S.; Heuvelmans, M.A.; Du, Y.; Sidorenkov, G.; Fan, S.; Li, Y.; Xie, Y.; Zhu, Z.; Dorrius, M.D.; et al. Performance of a deep learning-based lung nodule detection system as an alternative reader in a Chinese lung cancer screening program. Eur. J. Radiol. 2022, 146, 110068. [Google Scholar] [CrossRef]
- Liu, L.; Li, C. Comparative study of deep learning models on the images of biopsy specimens for diagnosis of lung cancer treatment. J. Radiat. Res. Appl. Sci. 2023, 16, 100555. [Google Scholar] [CrossRef]
- Muniz, F.B.; de Freitas Oliveira Baffa, M.; Garcia, S.B.; Bachmann, L.; Felipe, J.C. Histopathological diagnosis of colon cancer using micro-FTIR hyperspectral imaging and deep learning. Comput. Methods Programs Biomed. 2023, 231, 107388. [Google Scholar] [CrossRef]
- Gomes, S.L.; de S. Rebouças, E.; Neto, E.C.; Papa, J.P.; de Albuquerque, V.H.C.; Filho, P.P.R.; Tavares, J.M.R.S. Embedded real-time speed limit sign recognition using image processing and machine learning techniques. Neural Comput. Appl. 2017, 28, 573–584. [Google Scholar] [CrossRef]
- Monga, V.; Li, Y.; Eldar, Y.C. Algorithm Unrolling: Interpretable, Efficient Deep Learning for Signal and Image Processing. IEEE Signal Process. Mag. 2021, 38, 18–44. [Google Scholar] [CrossRef]
- Zhang, L.; Cheng, L.; Li, H.; Gao, J.; Yu, C.; Domel, R.; Yang, Y.; Tang, S.; Liu, W.K. Hierarchical deep-learning neural networks: Finite elements and beyond. Comput. Mech. 2021, 67, 207–230. [Google Scholar] [CrossRef]
- Salahzadeh, Z.; Rezaei-Hachesu, P.; Gheibi, Y.; Aghamali, A.; Pakzad, H.; Foladlou, S.; Samad-Soltani, T. A mechatronics data collection, image processing, and deep learning platform for clinical posture analysis: A technical note. Phys. Eng. Sci. Med. 2021, 44, 901–910. [Google Scholar] [CrossRef] [PubMed]
- Singh, P.; Hrisheekesha, P.; Singh, V.K. CBIR-CNN: Content-Based Image Retrieval on Celebrity Data Using Deep Convolution Neural Network. Recent Adv. Comput. Sci. Commun. 2021, 14, 257–272. [Google Scholar] [CrossRef]
- Varga, D.; Szirányi, T. Fast content-based image retrieval using convolutional neural network and hash function. In Proceedings of the 2016 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Budapest, Hungary, 9–12 October 2016; pp. 2636–2640. [Google Scholar] [CrossRef]
- Latif, A.; Rasheed, A.; Sajid, U.; Ahmed, J.; Ali, N.; Ratyal, N.I.; Zafar, B.; Dar, S.H.; Sajid, M.; Khalil, T. Content-Based Image Retrieval and Feature Extraction: A Comprehensive Review. Math. Probl. Eng. 2019, 2019, 9658350. [Google Scholar] [CrossRef]
- Rani, P.; Kotwal, S.; Manhas, J.; Sharma, V.; Sharma, S. Machine Learning and Deep Learning Based Computational Approaches in Automatic Microorganisms Image Recognition: Methodologies, Challenges, and Developments. Arch. Comput. Methods Eng. 2022, 29, 1801–1837. [Google Scholar] [CrossRef]
- Jardim, S.V.B.; Figueiredo, M.A.T. Automatic Analysis of Fetal Echographic Images. Proc. Port. Conf. Pattern Recognit. 2002, 1, 1–6. [Google Scholar]
- Jardim, S.V.B.; Figueiredo, M.A.T. Automatic contour estimation in fetal ultrasound images. In Proceedings of the 2003 International Conference on Image Processing 2003, Barcelona, Spain, 14–17 September 2003; Volum 1, pp. 1065–1068. [Google Scholar] [CrossRef]
- Devunooru, S.; Alsadoon, A.; Chandana, P.W.C.; Beg, A. Deep learning neural networks for medical image segmentation of brain tumours for diagnosis: A recent review and taxonomy. J. Ambient Intell. Humaniz. Comput. 2021, 12, 455–483. [Google Scholar] [CrossRef]
- Anaya-Isaza, A.; Mera-Jiménez, L.; Verdugo-Alejo, L.; Sarasti, L. Optimizing MRI-based brain tumor classification and detection using AI: A comparative analysis of neural networks, transfer learning, data augmentation, and the cross-transformer network. Eur. J. Radiol. Open 2023, 10, 100484. [Google Scholar] [CrossRef]
- Cao, Y.; Kunaprayoon, D.; Xu, J.; Ren, L. AI-assisted clinical decision making (CDM) for dose prescription in radiosurgery of brain metastases using three-path three-dimensional CNN. Clin. Transl. Radiat. Oncol. 2023, 39, 100565. [Google Scholar] [CrossRef]
- Chakrabarty, N.; Mahajan, A.; Patil, V.; Noronha, V.; Prabhash, K. Imaging of brain metastasis in non-small-cell lung cancer: Indications, protocols, diagnosis, post-therapy imaging, and implications regarding management. Clin. Radiol. 2023, 78, 175–186. [Google Scholar] [CrossRef]
- Mehrotra, R.; Ansari, M.; Agrawal, R.; Anand, R. A Transfer Learning approach for AI-based classification of brain tumors. Mach. Learn. Appl. 2020, 2, 100003. [Google Scholar] [CrossRef]
- Drai, M.; Testud, B.; Brun, G.; Hak, J.F.; Scavarda, D.; Girard, N.; Stellmann, J.P. Borrowing strength from adults: Transferability of AI algorithms for paediatric brain and tumour segmentation. Eur. J. Radiol. 2022, 151, 110291. [Google Scholar] [CrossRef] [PubMed]
- Ranjbarzadeh, R.; Caputo, A.; Tirkolaee, E.B.; Jafarzadeh Ghoushchi, S.; Bendechache, M. Brain tumor segmentation of MRI images: A comprehensive review on the application of artificial intelligence tools. Comput. Biol. Med. 2023, 152, 106405. [Google Scholar] [CrossRef] [PubMed]
- Yedder, H.B.; Cardoen, B.; Hamarneh, G. Deep learning for biomedical image reconstruction: A survey. Artif. Intell. Rev. 2021, 54, 215–251. [Google Scholar] [CrossRef]
- Manuel Davila Delgado, J.; Oyedele, L. Robotics in construction: A critical review of the reinforcement learning and imitation learning paradigms. Adv. Eng. Inform. 2022, 54, 101787. [Google Scholar] [CrossRef]
- Íñigo Elguea-Aguinaco; Serrano-Muñoz, A.; Chrysostomou, D.; Inziarte-Hidalgo, I.; Bøgh, S.; Arana-Arexolaleiba, N. A review on reinforcement learning for contact-rich robotic manipulation tasks. Robot. Comput.-Integr. Manuf. 2023, 81, 102517. [Google Scholar] [CrossRef]
- Ahn, K.H.; Na, M.; Song, J.B. Robotic assembly strategy via reinforcement learning based on force and visual information. Robot. Auton. Syst. 2023, 164, 104399. [Google Scholar] [CrossRef]
- Jafari, M.; Xu, H.; Carrillo, L.R.G. A biologically-inspired reinforcement learning based intelligent distributed flocking control for Multi-Agent Systems in presence of uncertain system and dynamic environment. IFAC J. Syst. Control 2020, 13, 100096. [Google Scholar] [CrossRef]
- Wang, X.; Liu, S.; Yu, Y.; Yue, S.; Liu, Y.; Zhang, F.; Lin, Y. Modeling collective motion for fish schooling via multi-agent reinforcement learning. Ecol. Model. 2023, 477, 110259. [Google Scholar] [CrossRef]
- Jain, D.K.; Dutta, A.K.; Verdú, E.; Alsubai, S.; Sait, A.R.W. An automated hyperparameter tuned deep learning model enabled facial emotion recognition for autonomous vehicle drivers. Image Vis. Comput. 2023, 133, 104659. [Google Scholar] [CrossRef]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science 2018, 362, 1140–1144. [Google Scholar] [CrossRef]
- Ueda, M. Memory-two strategies forming symmetric mutual reinforcement learning equilibrium in repeated prisoners’ dilemma game. Appl. Math. Comput. 2023, 444, 127819. [Google Scholar] [CrossRef]
- Wang, X.; Liu, F.; Ma, X. Mixed distortion image enhancement method based on joint of deep residuals learning and reinforcement learning. Signal Image Video Process. 2021, 15, 995–1002. [Google Scholar] [CrossRef]
- Dai, Y.; Wang, G.; Muhammad, K.; Liu, S. A closed-loop healthcare processing approach based on deep reinforcement learning. Multimed. Tools Appl. 2022, 81, 3107–3129. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Valente, J.; António, J.; Mora, C.; Jardim, S. Developments in Image Processing Using Deep Learning and Reinforcement Learning. J. Imaging 2023, 9, 207. https://doi.org/10.3390/jimaging9100207
Valente J, António J, Mora C, Jardim S. Developments in Image Processing Using Deep Learning and Reinforcement Learning. Journal of Imaging. 2023; 9(10):207. https://doi.org/10.3390/jimaging9100207
Chicago/Turabian StyleValente, Jorge, João António, Carlos Mora, and Sandra Jardim. 2023. "Developments in Image Processing Using Deep Learning and Reinforcement Learning" Journal of Imaging 9, no. 10: 207. https://doi.org/10.3390/jimaging9100207
APA StyleValente, J., António, J., Mora, C., & Jardim, S. (2023). Developments in Image Processing Using Deep Learning and Reinforcement Learning. Journal of Imaging, 9(10), 207. https://doi.org/10.3390/jimaging9100207