
Breast Cancer Detection with an Ensemble of Deep Learning Networks Using a Consensus-Adaptive Weighting Method

 ,
,  , ,
, , 
Abstract
:1. Introduction
2. Materials and Methods
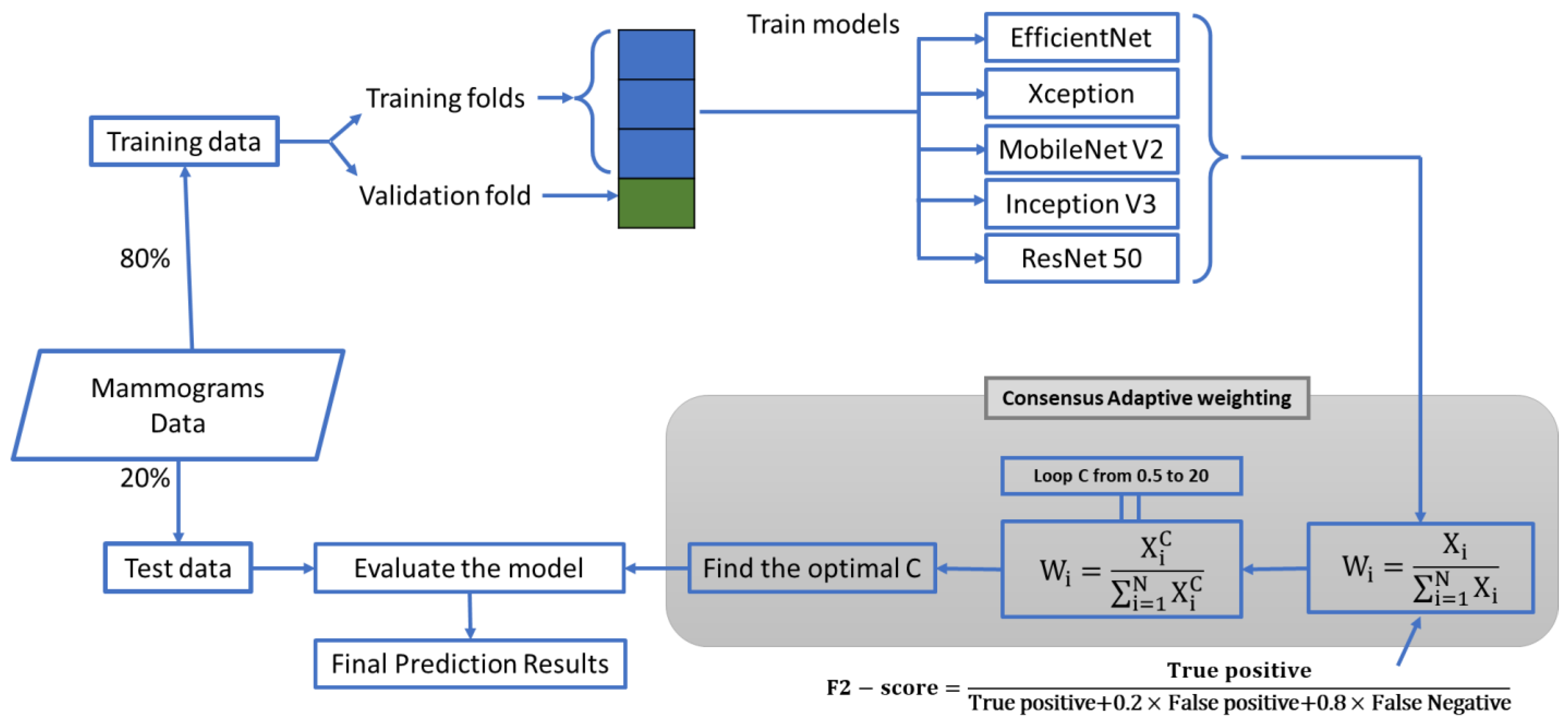
2.1. The Study Design
2.2. The First Proposed CAW System
2.3. The Second Proposed CAW System
2.4. Dataset and Experiment Setup
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- World Health Organization. Latest global cancer data: Cancer burden rises to 18.1 million new cases and 9.6 million cancer deaths in 2018. In International Agency for Research on Cancer; World Health Organization: Geneva, Switzerland, 2018; pp. 1–4. [Google Scholar]
- Moss, S.; Nyström, L.; Jonsson, H.; Paci, E.; Lynge, E.; Njor, S.; Broeders, M. The impact of mammographic screening on breast cancer mortality in Europe: A review of trend studies. J. Med. Screen. 2012, 19 (Suppl. S1), 26–32. [Google Scholar] [CrossRef] [PubMed]
- Welch, H.G.; Prorok, P.C.; O’Malley, A.J.; Kramer, B.S. Breast-cancer tumor size, overdiagnosis, and mammography screening effectiveness. N. Engl. J. Med. 2016, 375, 1438–1447. [Google Scholar] [CrossRef] [PubMed]
- Smith, R.A.; Duffy, S.W.; Gabe, R.; Tabar, L.; Yen, A.M.; Chen, T.H. The randomized trials of breast cancer screening: What have we learned? Radiol. Clin. 2004, 42, 793–806. [Google Scholar] [CrossRef] [PubMed]
- Ponti, A.; Anttila, A.; Ronco, G.; Senore, C. Cancer Screening in the European Union (2017); Report on the Implementation of the Council Recommendation on Cancer Screening; World Health Organization: Geneva, Switzerland, 2017. [Google Scholar]
- Choi, Y.J.; Shin, Y.D.; Kang, Y.H.; Lee, M.S.; Lee, M.K.; Cho, B.S.; Kang, Y.J.; Park, J.S. The effects of preoperative 18F-FDG PET/CT in breast cancer patients in comparison to the conventional imaging study. J. Breast Cancer 2012, 15, 441–448. [Google Scholar] [CrossRef] [PubMed]
- Griffeth, L.K. Use of PET/CT Scanning in Cancer Patients: Technical and Practical Considerations; Baylor University Medical Center Proceedings; Taylor & Francis: Abingdon, UK, 2005; pp. 321–330. [Google Scholar]
- Boyd, N.F.; Guo, H.; Martin, L.J.; Sun, L.; Stone, J.; Fishell, E.; Jong, R.A.; Hislop, G.; Chiarelli, A.; Minkin, S. Mammographic density and the risk and detection of breast cancer. N. Engl. J. Med. 2007, 356, 227–236. [Google Scholar] [CrossRef] [PubMed]
- Carney, P.A.; Miglioretti, D.L.; Yankaskas, B.C.; Kerlikowske, K.; Rosenberg, R.; Rutter, C.M.; Geller, B.M.; Abraham, L.A.; Taplin, S.H.; Dignan, M. Individual and combined effects of age, breast density, and hormone replacement therapy use on the accuracy of screening mammography. Ann. Intern. Med. 2003, 138, 168–175. [Google Scholar] [CrossRef] [PubMed]
- Hoff, S.R.; Abrahamsen, A.-L.; Samset, J.H.; Vigeland, E.; Klepp, O.; Hofvind, S. Breast cancer: Missed interval and screening-detected cancer at full-field digital mammography and screen-film mammography—Results from a retrospective review. Radiology 2012, 264, 378–386. [Google Scholar] [CrossRef]
- Kerlikowske, K.; Carney, P.A.; Geller, B.; Mandelson, M.T.; Taplin, S.H.; Malvin, K.; Ernster, V.; Urban, N.; Cutter, G.; Rosenberg, R. Performance of screening mammography among women with and without a first-degree relative with breast cancer. Ann. Intern. Med. 2000, 133, 855–863. [Google Scholar] [CrossRef]
- Berlin, L. Radiologic errors, past, present and future. Diagnosis 2014, 1, 79–84. [Google Scholar] [CrossRef]
- Sickles, E.A. Periodic mammographic follow-up of probably benign lesions: Results in 3,184 consecutive cases. Radiology 1991, 179, 463–468. [Google Scholar] [CrossRef]
- Doi, K. Computer-aided diagnosis in medical imaging: Historical review, current status and future potential. Comput. Med. Imaging Graph. 2007, 31, 198–211. [Google Scholar] [CrossRef]
- Birdwell, R.L.; Ikeda, D.M.; O’Shaughnessy, K.F.; Sickles, E.A. Mammographic characteristics of 115 missed cancers later detected with screening mammography and the potential utility of computer-aided detection. Radiology 2001, 219, 192–202. [Google Scholar] [CrossRef] [PubMed]
- Warren Burhenne, L.J.; Wood, S.A.; D’Orsi, C.J.; Feig, S.A.; Kopans, D.B.; O’Shaughnessy, K.F.; Sickles, E.A.; Tabar, L.; Vyborny, C.J.; Castellino, R.A. Potential contribution of computer-aided detection to the sensitivity of screening mammography. Radiology 2000, 215, 554–562. [Google Scholar] [CrossRef] [PubMed]
- Morton, M.J.; Whaley, D.H.; Brandt, K.R.; Amrami, K.K. Screening mammograms: Interpretation with computer-aided detection—Prospective evaluation. Radiology 2006, 239, 375–383. [Google Scholar] [CrossRef] [PubMed]
- Freer, T.W.; Ulissey, M.J. Screening mammography with computer-aided detection: Prospective study of 12,860 patients in a community breast center. Radiology 2001, 220, 781–786. [Google Scholar] [CrossRef] [PubMed]
- Gilbert, F.J.; Astley, S.M.; Gillan, M.G.; Agbaje, O.F.; Wallis, M.G.; James, J.; Boggis, C.R.; Duffy, S.W. Single reading with computer-aided detection for screening mammography. N. Engl. J. Med. 2008, 359, 1675–1684. [Google Scholar] [CrossRef] [PubMed]
- Gonzalo, R.B.; Corsetti, B.; Goicoechea-Telleria, I.; Husseis, A.; Liu-Jimenez, J.; Sanchez-Reillo, R.; Eglitis, T.; Ellavarason, E.; Guest, R.; Lunerti, C. Attacking a Smartphone Biometric Fingerprint System: A Novice’s Approach. In Proceedings of the 2018 International Carnahan Conference on Security Technology (ICCST), Montreal, QC, Canada, 22–25 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–5. [Google Scholar]
- Zohrevandi, P.; Jaryani, F. Proposing an effective framework for hybrid clustering on heterogeneous data in distributed systems. Int. J. Adv. Comput. Sci. Inf. Technol. 2018, 7, 71–81. [Google Scholar]
- Faraji, M.; Behnam, H.; Norizadeh Cherloo, M.; Shojaeifard, M. Novel approach for automatic mid-diastole frame detection in 2D echocardiography sequences for performing planimetry of the mitral valve orifice. IET Image Process. 2020, 14, 2890–2900. [Google Scholar] [CrossRef]
- Noroozi, R.; Arif, Z.U.; Taghvaei, H.; Khalid, M.Y.; Sahbafar, H.; Hadi, A.; Sadeghianmaryan, A.; Chen, X. 3D and 4D Bioprinting Technologies: A Game Changer for the Biomedical Sector? Ann. Biomed. Eng. 2023, 51, 1683–1712. [Google Scholar] [CrossRef]
- Eskandari, V.; Sahbafar, H.; Zeinalizad, L.; Hadi, A. A review of applications of surface-enhanced raman spectroscopy laser for detection of biomaterials and a quick glance into its advances for COVID-19 investigations. ISSS J. Micro Smart Syst. 2022, 11, 363–382. [Google Scholar] [CrossRef]
- Ciompi, F.; de Hoop, B.; van Riel, S.J.; Chung, K.; Scholten, E.T.; Oudkerk, M.; de Jong, P.A.; Prokop, M.; van Ginneken, B. Automatic classification of pulmonary peri-fissural nodules in computed tomography using an ensemble of 2D views and a convolutional neural network out-of-the-box. Med. Image Anal. 2015, 26, 195–202. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Ni, D.; Qin, J.; Li, S.; Yang, X.; Wang, T.; Heng, P.A. Standard plane localization in fetal ultrasound via domain transferred deep neural networks. IEEE J. Biomed. Health Inform. 2015, 19, 1627–1636. [Google Scholar] [CrossRef] [PubMed]
- Shin, H.-C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef] [PubMed]
- Mehraeen, E.; Dashti, M.; Ghasemzadeh, A.; Afsahi, A.M.; Shahidi, R.; Mirzapour, P.; Karimi, K.; Rouzi, M.D.; Bagheri, A.; Mohammadi, S. Virtual Reality in Medical Education during the COVID-19 Pandemic; A Systematic Review. JMIR Serious Games 2023, 10, e35000. [Google Scholar]
- Bagheri, A.B.; Rouzi, M.D.; Koohbanani, N.A.; Mahoor, M.H.; Finco, M.; Lee, M.; Najafi, B.; Chung, J. Potential Applications of Artificial Intelligence (AI) and Machine Learning (ML) on Diagnosis, Treatment, Outcome Prediction to Address Health Care Disparities of Chronic Limb-Threatening Ischemia (CLTI); Seminars in Vascular Surgery; Elsevier: Amsterdam, The Netherlands, 2023. [Google Scholar]
- Park, C.; Rouzi, M.D.; Atique, M.M.U.; Finco, M.; Mishra, R.K.; Barba-Villalobos, G.; Crossman, E.; Amushie, C.; Nguyen, J.; Calarge, C. Machine Learning-Based Aggression Detection in Children with ADHD Using Sensor-Based Physical Activity Monitoring. Sensors 2023, 23, 4949. [Google Scholar] [CrossRef] [PubMed]
- Jiao, Z.; Gao, X.; Wang, Y.; Li, J. A deep feature based framework for breast masses classification. Neurocomputing 2016, 197, 221–231. [Google Scholar] [CrossRef]
- Becker, A.S.; Marcon, M.; Ghafoor, S.; Wurnig, M.C.; Frauenfelder, T.; Boss, A. Deep learning in mammography: Diagnostic accuracy of a multipurpose image analysis software in the detection of breast cancer. Investig. Radiol. 2017, 52, 434–440. [Google Scholar] [CrossRef] [PubMed]
- Ribli, D.; Horváth, A.; Unger, Z.; Pollner, P.; Csabai, I. Detecting and classifying lesions in mammograms with deep learning. Sci. Rep. 2018, 8, 4165. [Google Scholar] [CrossRef]
- Ardila, D.; Kiraly, A.P.; Bharadwaj, S.; Choi, B.; Reicher, J.J.; Peng, L.; Tse, D.; Etemadi, M.; Ye, W.; Corrado, G. End-to-end lung cancer screening with three-dimensional deep learning on low-dose chest computed tomography. Nat. Med. 2019, 25, 954–961. [Google Scholar] [CrossRef]
- Coudray, N.; Ocampo, P.S.; Sakellaropoulos, T.; Narula, N.; Snuderl, M.; Fenyö, D.; Moreira, A.L.; Razavian, N.; Tsirigos, A. Classification and mutation prediction from non–small cell lung cancer histopathology images using deep learning. Nat. Med. 2018, 24, 1559–1567. [Google Scholar] [CrossRef]
- Liu, S.; Zheng, H.; Feng, Y.; Li, W. Prostate Cancer Diagnosis Using Deep Learning with 3D Multiparametric MRI; Medical Imaging 2017: Computer-Aided Diagnosis; SPIE: Bellingham, WA, USA, 2017; pp. 581–584. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Liggins II, M.; Hall, D.; Llinas, J. Handbook of Multisensor Data Fusion: Theory and Practice; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking Model Scaling for Convolutional Neural Networks; International Conference on Machine Learning; PMLR: Long beach, CA, USA, 2019; pp. 6105–6114. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part IV 14. Springer: Berlin/Heidelberg, Germany; pp. 630–645. [Google Scholar]
- Marques, G.; Agarwal, D.; De la Torre Díez, I. Automated medical diagnosis of COVID-19 through EfficientNet convolutional neural network. Appl. Soft Comput. 2020, 96, 106691. [Google Scholar] [CrossRef] [PubMed]
- Panthakkan, A.; Anzar, S.; Jamal, S.; Mansoor, W. Concatenated Xception-ResNet50—A novel hybrid approach for accurate skin cancer prediction. Comput. Biol. Med. 2022, 150, 106170. [Google Scholar] [CrossRef] [PubMed]
- Srinivasu, P.N.; SivaSai, J.G.; Ijaz, M.F.; Bhoi, A.K.; Kim, W.; Kang, J.J. Classification of skin disease using deep learning neural networks with MobileNet V2 and LSTM. Sensors 2021, 21, 2852. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Chen, D.; Hao, L.; Liu, X.; Zeng, Y.; Chen, J.; Zhang, G. Pulmonary image classification based on inception-v3 transfer learning model. IEEE Access 2019, 7, 146533–146541. [Google Scholar] [CrossRef]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- DDSM Mammography. Available online: https://www.kaggle.com/datasets/skooch/ddsm-mammography (accessed on 5 February 2021).
- The Complete Mini-DDSM. Available online: https://www.kaggle.com/cheddad/miniddsm2 (accessed on 18 March 2021).
- Moreira, I.C.; Amaral, I.; Domingues, I.; Cardoso, A.; Cardoso, M.J.; Cardoso, J.S. Inbreast: Toward a full-field digital mammographic database. Acad. Radiol. 2012, 19, 236–248. [Google Scholar] [CrossRef] [PubMed]
- Japkowicz, N.; Stephen, S. The class imbalance problem: A systematic study. Intell. Data Anal. 2002, 6, 429–449. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2019; pp. 248–255. [Google Scholar]
- Chen, X.; Wang, X.; Zhang, K.; Fung, K.-M.; Thai, T.C.; Moore, K.; Mannel, R.S.; Liu, H.; Zheng, B.; Qiu, Y. Recent advances and clinical applications of deep learning in medical image analysis. Med. Image Anal. 2022, 79, 102444. [Google Scholar] [CrossRef]
- Xu, Y.; Mo, T.; Feng, Q.; Zhong, P.; Lai, M.; Eric, I.; Chang, C. Deep learning of feature representation with multiple instance learning for medical image analysis. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1626–1630. [Google Scholar]
- Shen, L.; Margolies, L.R.; Rothstein, J.H.; Fluder, E.; McBride, R.; Sieh, W. Deep learning to improve breast cancer detection on screening mammography. Sci. Rep. 2019, 9, 12495. [Google Scholar] [CrossRef]
- Rampun, A.; Zheng, L.; Malcolm, P.; Tiddeman, B.; Zwiggelaar, R. Computer-aided detection of prostate cancer in T2-weighted MRI within the peripheral zone. Phys. Med. Biol. 2016, 61, 4796. [Google Scholar] [CrossRef]
- Hamidinekoo, A.; Suhail, Z.; Qaiser, T.; Zwiggelaar, R. Investigating the effect of various augmentations on the input data fed to a convolutional neural network for the task of mammographic mass classification. In Proceedings of the Medical Image Understanding and Analysis: 21st Annual Conference, MIUA 2017, Edinburgh, UK, 11–13 July 2017; Proceedings 21. Springer: Berlin/Heidelberg, Germany, 2017; pp. 398–409. [Google Scholar]
- Abunasser, B.S.; AL-Hiealy, M.R.J.; Zaqout, I.S.; Abu-Naser, S.S. Breast cancer detection and classification using deep learning Xception algorithm. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 223–228. [Google Scholar] [CrossRef]
- Ansar, W.; Shahid, A.R.; Raza, B.; Dar, A.H. Breast cancer detection and localization using mobilenet based transfer learning for mammograms. In Proceedings of the Intelligent Computing Systems: Third International Symposium, ISICS 2020, Sharjah, United Arab Emirates, 18–19 March 2020; Proceedings 3. Springer: Berlin/Heidelberg, Germany, 2020; pp. 11–21. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | F2-Score (%) | ||
|---|---|---|---|
| Cropped DDSM | DDSM | INbreast | |
| EfficientNet | 93.89 ± 0.09 | 81.03 ± 0.13 | 63.76 ± 0.11 |
| Xception | 92.03 ± 0.05 | 68.06 ± 0.12 | 66.75 ± 0.12 |
| MobileNetV2 | 92.43 ± 0.16 | 69.56 ± 0.28 | 60.58 ± 0.29 |
| InceptionV3 | 91.01 ± 0.17 | 76.74 ± 0.35 | 71.20 ± 0.15 |
| ResNet50 | 88.98 ± 0.16 | 67.93 ± 0.24 | 67.42 ± 0.38 |
| Majority Vote | 94.12 ± 0.12 | 81.32 ± 0.17 | 71.68 ± 0.16 |
| Initial proposed method: CAW V1 | 94.55 ± 0.10 | 81.66 ± 0.18 | 71.98 ± 0.15 |
| Final proposed method: CAW V2 | 95.48 ± 0.08 | 82.35 ± 0.17 | 72.31 ± 0.16 |
| C (CAW V2 Formula) | ||
|---|---|---|
| Cropped DDSM | DDSM | Inbreast |
| 2.6 | 3.4 | 3.1 |
| Dataset | |||
|---|---|---|---|
| Cropped DDSM | DDSM | INbreast | |
| Best and worst performance differences (%) | 4.906 | 13.105 | 10.62 |
| Model | Comparison of CAW V1 and V2 | |||||
|---|---|---|---|---|---|---|
| Cropped DDSM | DDSM | INbreast | ||||
| V1 Weights | V2 Weights | V1 Weights | V2 Weights | V1 Weights | V2 Weights | |
| EfficientNet B3 | 0.205 | 0.213 | 0.223 | 0.283 | 0.193 | 0.178 |
| Xception | 0.201 | 0.202 | 0.187 | 0.156 | 0.202 | 0.191 |
| MobileNetV2 | 0.202 | 0.204 | 0.191 | 0.148 | 0.184 | 0.135 |
| InceptionV3 | 0.199 | 0.196 | 0.211 | 0.186 | 0.216 | 0.202 |
| ResNet50 | 0.194 | 0.185 | 0.187 | 0.151 | 0.204 | 0.214 |
| CAW model (F2 score % Improvement) | 0.93 ± 0.18 | 0.69 ± 0.35 | 0.33 ± 0.31 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dehghan Rouzi, M.; Moshiri, B.; Khoshnevisan, M.; Akhaee, M.A.; Jaryani, F.; Salehi Nasab, S.; Lee, M. Breast Cancer Detection with an Ensemble of Deep Learning Networks Using a Consensus-Adaptive Weighting Method. J. Imaging 2023, 9, 247. https://doi.org/10.3390/jimaging9110247
Dehghan Rouzi M, Moshiri B, Khoshnevisan M, Akhaee MA, Jaryani F, Salehi Nasab S, Lee M. Breast Cancer Detection with an Ensemble of Deep Learning Networks Using a Consensus-Adaptive Weighting Method. Journal of Imaging. 2023; 9(11):247. https://doi.org/10.3390/jimaging9110247
Chicago/Turabian StyleDehghan Rouzi, Mohammad, Behzad Moshiri, Mohammad Khoshnevisan, Mohammad Ali Akhaee, Farhang Jaryani, Samaneh Salehi Nasab, and Myeounggon Lee. 2023. "Breast Cancer Detection with an Ensemble of Deep Learning Networks Using a Consensus-Adaptive Weighting Method" Journal of Imaging 9, no. 11: 247. https://doi.org/10.3390/jimaging9110247
APA StyleDehghan Rouzi, M., Moshiri, B., Khoshnevisan, M., Akhaee, M. A., Jaryani, F., Salehi Nasab, S., & Lee, M. (2023). Breast Cancer Detection with an Ensemble of Deep Learning Networks Using a Consensus-Adaptive Weighting Method. Journal of Imaging, 9(11), 247. https://doi.org/10.3390/jimaging9110247