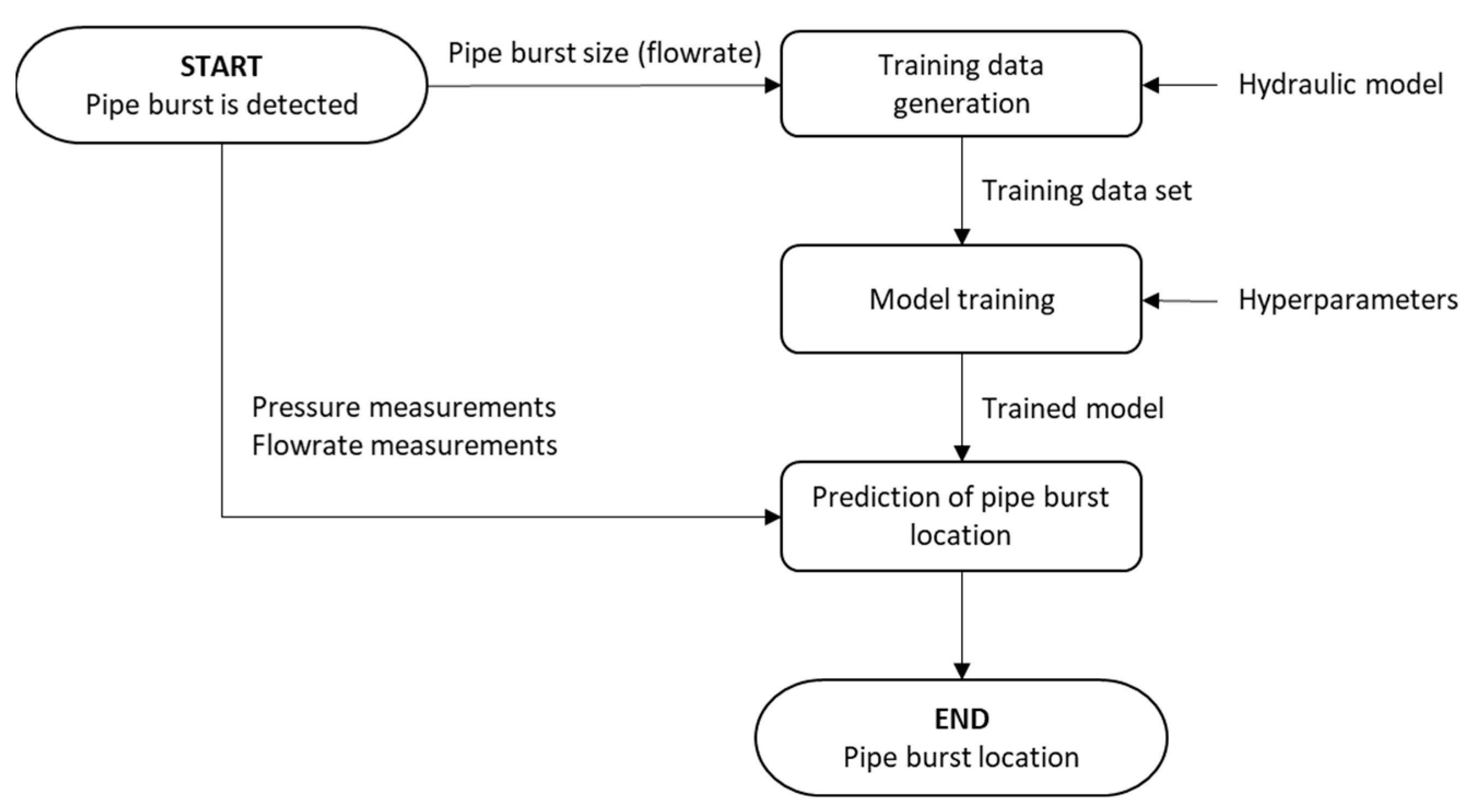
A computational application was developed for this research, using Python 3.8.2 as the programming language. The TensorFlow 2.9.1 (TF) package was used to develop the neural network, and the TensorBoard 2.9.1 plugin was used for assessment and visualization of training results [
29]. Hydraulic simulations are carried out in EPANET [
30], which is a water distribution system modeling software package developed by the United States Environmental Protection Agency, using the Water Network Tool for Resilience 0.4.2 (WNTR) Python package [
31].
3.2. Hyperparametrization
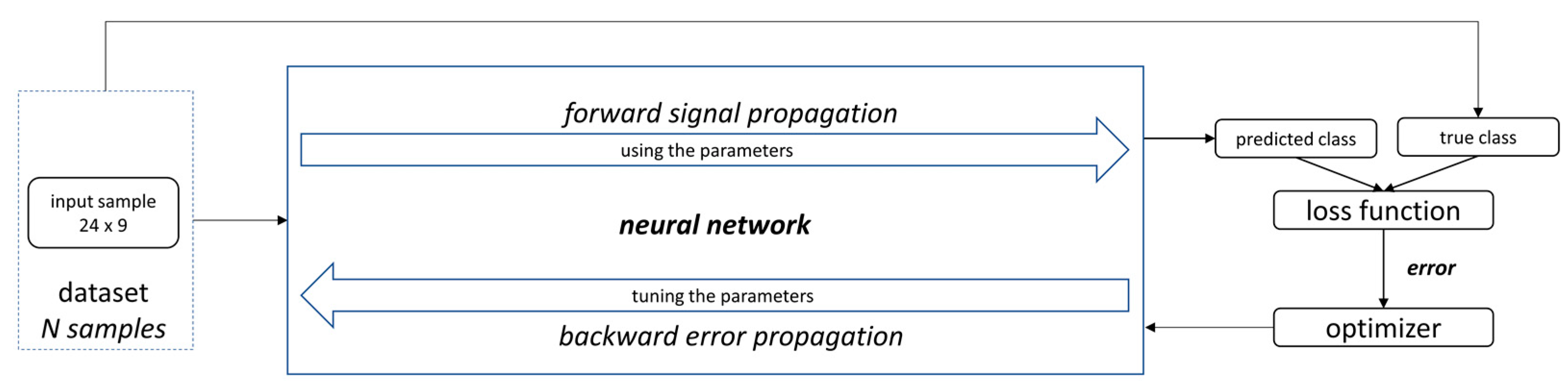
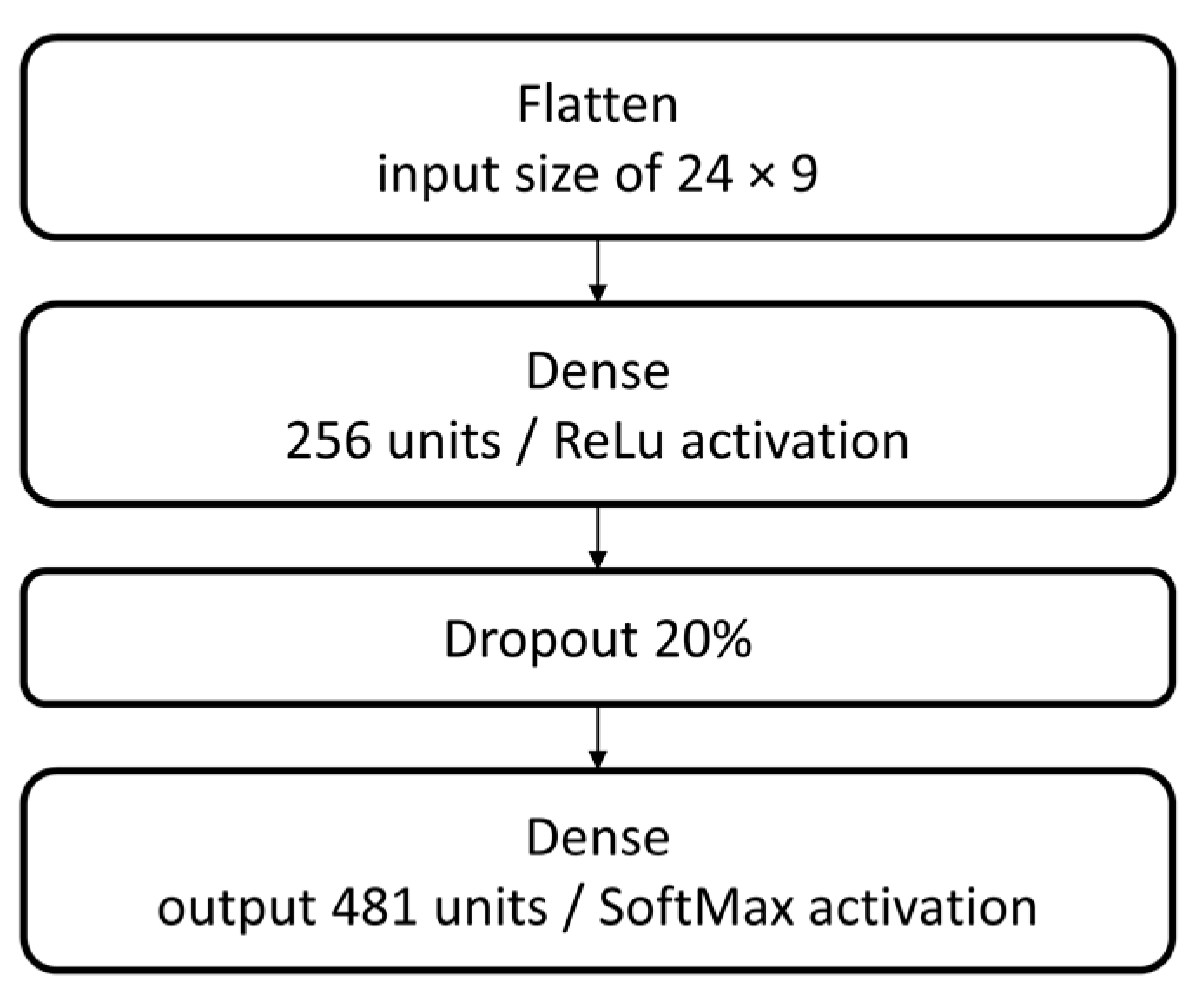
A simple neural network structure is implemented as a baseline for starting the tests procedure. This structure consists of a group of sequential layers: flatten input with a shape of 24 rows by 9 columns, dense with 256 units and rectified linear unit (ReLu) activation, a 20% dropout, and dense output with 481 units and SoftMax activation, as displayed in
Figure 6.
An initial set of estimated parameters is chosen as the baseline for training the neural network (See
Table 1). The burst size considered for training data generation and prediction is 20% of the total inlet flow rate. The hydraulic simulation consists of 24 hourly time steps. No network clustering is used, but an initial search space reduction for removing valve nodes is carried out; thus, 481 relevant WDN nodes are considered.
Training data are generated by simulating a burst at every each WDN node during 24 hourly timesteps. The measurement noise used when generating the training dataset is considered equal to 0.0001% (practically zero or no noise). The effect of measurement noise level on the model’s performance is later assessed in
Section 3.3. A dataset split of 70% is used for training, and the remaining 30% samples are used for validation.
The model optimizer is Adam, with learning rate regularization. Adam uses a computational efficient method with low memory requirements, and is adequate for big data problems with lots of parameters [
33].
The metrics to use when assessing loss and accuracy are directly dependent on the neural network structure. In this study, since SoftMax is used as activation of the output layer, sparse categorical cross entropy and sparse categorical accuracy metrics are used for monitoring loss and accuracy, respectively (the sparse categorical variants of the metrics are used due to integer conversion of categories before training the model).
The categorical cross entropy can be calculated as follows:
where
is the number of classes,
is the truth value of the real class, and
is the probability of the inferred class.
The categorical accuracy can be calculated as follows:
where
is the number of observations,
is the number of true positives, and
is the number of true negatives.
3.2.1. Effect of Termination Criteria
The early stopping (ES) functionality in training can be useful for preventing excessive training and possible overfitting of models, but if misconfigured can stop training at a local minimum and prevent the model from further learning. A test was performed to determine if ES should be considered to stop training based on some predefined criteria (e.g., loss or accuracy). ES was configured to stop after 20 epochs without metric progression. Using ES with a patience setting of 20 epochs and monitoring for validation loss, the model stopped training at epoch 335, achieving a final validation loss and accuracy of 1.796 and 41.5%, respectively (
Table 2, C1). Using the same setting but monitoring for validation accuracy, the model stopped the training at epoch 98, achieving a final value for the validation loss and accuracy of 2.071 and 35.5%, respectively (
Table 2, C2). Training for the full 5000 epochs without ES achieved a final validation loss and accuracy of 1.591 and 46.63%, respectively (
Table 2, C3).
The full training (5000 epochs) allowed the detection of the inflection of the validation loss and accuracy curves, showing that the best values were achieved just before epoch 2500, as can be seen in
Figure 7. ES criteria with a patience setting of 20 epochs were too low to achieve the optimal values. Taking in account the minor difference between the optimal value and the final value at 5000 epochs, and that, in this specific case, the fine tuning of the other parameters demonstrates that the early stopping parameter stops being useful, a decision was made to stick to training until 5000 epochs were reached. This decision will also allow full assessment of the validation loss curve progression.
3.2.2. Effect of Training Dataset Size
The number of datasets available for neural network training is a relevant factor. Three distinct sizes for dataset generation were devised: 50, 250, and 500. Each dataset consists of the sensor measurements after placing a simulated burst in each of the relevant network nodes throughout the 24 hourly timesteps. So, for the current case study (a network with 481 relevant nodes after SSR and 9 sensors), 50 datasets consist of 24,050 samples, 250 datasets consist of 120,250 samples, and 500 datasets consist of 240,500 samples.
Training the model with 50 datasets achieved a validation loss and accuracy of 1.992 and 36.0%, respectively, in 1 h and 34 min (
Table 3, C4); using 250 datasets for training achieved a validation loss and accuracy of 1.667 and 41.1%, respectively, in 8 h (C5), and training with 500 datasets achieved a validation loss and accuracy of 1.591 and 46.6%, respectively, in 17 h (C6). The best result was achieved with the training using 500 datasets, but the extra amount of time needed is relevant, considering that it might limit the method’s usability in near real-time applications and there was only a little gain achieved in validation accuracy. Thus, 250 datasets are used for the remaining tests.
3.2.3. Effect of Dataset Normalization
Two distinct sets of training data consisting of 250 datasets were generated. The first set was normalized between 0 and 1. The second set was not normalized. Training with 250 normalized datasets achieved a validation loss and accuracy of 1.667 and 41.1%, respectively (
Table 4, C7), whilst training with non-normalized datasets resulted in a validation loss and accuracy of 6.176 and 1.5%, respectively (
Table 4, C8). These results demonstrate the relevance of and need for normalization.
3.2.4. Effect of Training Batch Size
The batch size determines the number of samples used to calculate one step in the training process. Several steps are performed during one epoch, and the number of steps is calculated as the amount of training samples divided by the batch size. Using a batch size of 20 achieved a validation loss and accuracy of 5.16 and 1.4%, respectively; this was interrupted at epoch 1000 after lasting for around 8 h, thus making the training too long (
Table 5, C9). Training with a batch size of 100 achieved a validation loss and accuracy of 1.584 and 46.1%, respectively; this lasted around 8 h for 5000 epochs (
Table 5, C10). A batch size of 500 samples achieved a validation loss and accuracy of 1.15 and 61.1%, respectively, with a duration of around 2 h for 5000 epochs (
Table 5, C11). A batch size of 1000 achieved a validation loss and accuracy of 1.463 and 55.2%, respectively, for 1000 epochs, thus performing worst and being interrupted after 19 min (
Table 5, C12). In sum, a greater batch size can reduce the training duration, but the performance depends on the available system memory. Thus, the best result was found using a training batch size of 500 samples.
3.2.5. Effect of Optimizer Learning Rate Regularization
Configuring the optimizer with learning rate regularization (using inverse time decay with a decay rate of epoch steps multiplied by 1000) achieved a validation loss and accuracy of 1.021 and 75.4%, respectively (
Table 6, C13). The same training without learning rate regularization achieved a validation loss and accuracy of 1.15 and 61.1%, respectively (
Table 6, C14). Therefore, the best result was achieved using optimizer learning rate regularization.
3.2.6. Effect of Neural Network Structure
The neural network topology and structure are very relevant parameters for obtaining good results. The optimal structure is usually obtained after experimentation, and there is no known formula as it depends mostly on the specific problem. This study uses dense layers and convolutional layers as building blocks for a neural network. A simple network structure was devised as a baseline for all previous tests, using a dense layer with 256 units, followed by a 20% dropout layer, both of which achieve a validation loss and accuracy of 1.021 and 75.4%, respectively (
Table 7, C15). Distinct structure variations were tested to find the best solution. Using a dense layer with 512 units followed by a 20% dropout layer achieved a validation loss and accuracy of 0.872 and 79.9%, respectively (
Table 7, C16). A structure with a dense layer with 256 units and a 50% dropout layer achieved a validation loss and accuracy of 1.567 and 66.8%, respectively (
Table 7, C17), whilst a dense layer with 512 units and a 50% dropout layer achieved a validation loss and accuracy of 1.194 and 77.2%, respectively (
Table 7, C18). The best structure was found with C16, since this combination presented both the best validation accuracy and loss.
Sometimes multiple layers can be combined to achieve better results. Thus, we trialed adding an extra dense and dropout layer to the previous test’s best configuration (C16). A dense layer with 512 units and 20% dropout layer followed by another dense layer with 256 units and 20% dropout layer achieved a validation loss and accuracy of 3.771 and 35.6%, respectively (
Table 8, C19). A dense layer with 512 units and 20% dropout layer followed by another dense layer with 512 units and 20% dropout layer achieved a validation loss and accuracy of 5.871 and 19.6%, respectively, being interrupted after 1000 epochs (
Table 8, C20). Based on these results, it was concluded that adding these extra layers did not provide better results, and therefore the configuration from C16 was kept as the basis of the subsequent tests.
A neural network structure configuration using a convolutional layer was tested. This configuration consists of the best previous dense configuration (C16), this time preceded by a convolutional 1D layer followed by a global max pooling layer, which is then connected to dense layer with the number of units equal to the relevant 481 network nodes and a SoftMax activation, building a final model with five hidden layers. So, using a convolutional layer with 32 filters, a kernel size of 3 and strides equal to 2 achieved a validation loss and accuracy of 0.401 and 88.1%, respectively (
Table 9, C21). A configuration using the same parameters but with strides equal to 1 achieved a validation loss and accuracy of 0.3274 and 90.3%, respectively (
Table 9, C22). Based on these results, it is concluded that the best configuration is C22, with strides equal to 1.
In sum, the first tuning consisted of establishing the layer size and dropout value. The second tuning consisted of adding extra dense layers to the base configuration. Adding these extra layers did not provide better results, and therefore the configuration from C16 was kept as the basis of the next tests. As a third tuning of this hyperparameter, an explicit convolutional layer was added before the classification stage (CNN with the better dense classifier model). This convolutional layer extracts relevant features from the input data. This configuration provided better results than using a simple classifier. The fine tuning of the strides parameter in the convolution can provide an attenuation in the data. Using a higher value for strides seemed to discard relevant information, providing worst results.
The C22 configuration, which provided optimal results and was thus selected as the final model configuration, can be visualized in
Figure 8. It consists of training a model configuration based on a CNN with a convolutional 1D layer (using 32 filters, a kernel size of 3 and strides equal to 1) for a maximum of 5000 epochs, using a total of 250 datasets (using a [0, 1] data normalization with tolerance equal to max noise) and a batch size of 500 samples per epoch step, and optimized with Adam using learning rate regularization.
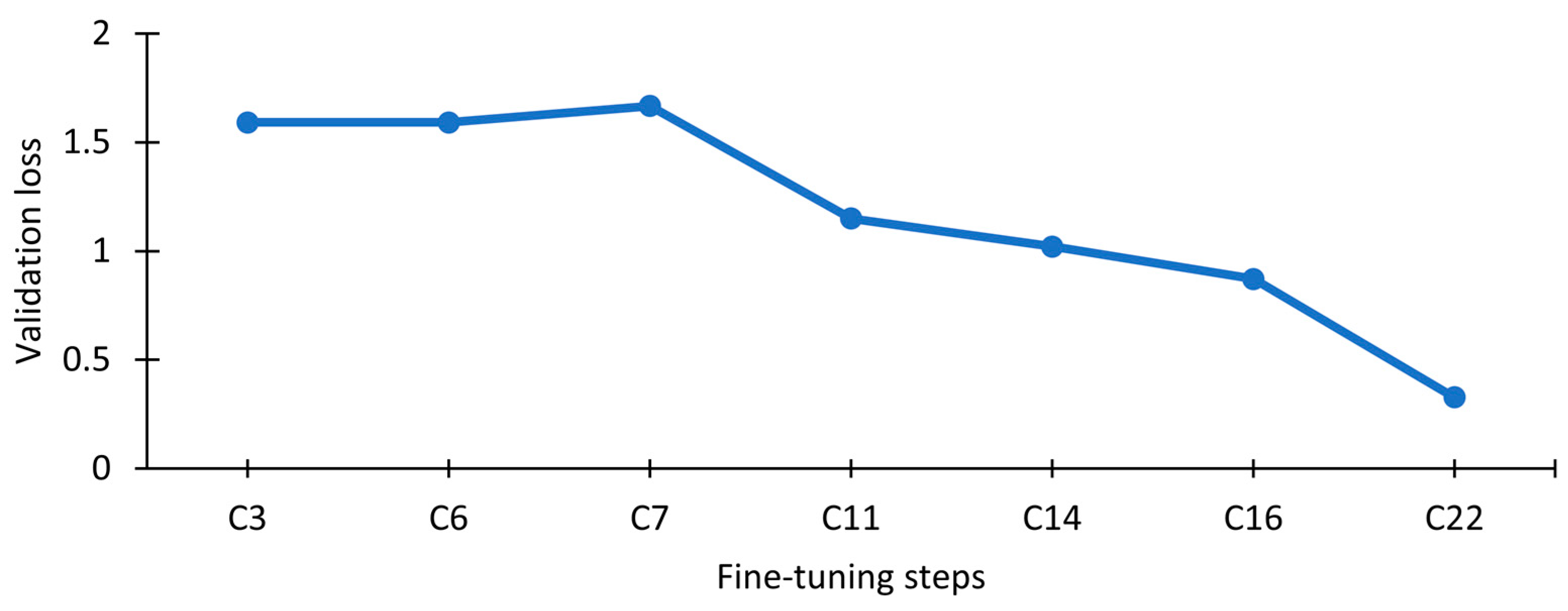
The evolution of the validation loss during the overall hyperparameter fine-tuning process can be visualized in
Figure 9.
3.2.7. Inference Test
After the model is trained, it can be used for inference of pipe burst locations. To assess the model’s inference consistency, a test was carried out by simulating a pipe burst in four network nodes located in distinct places throughout the WDN (i.e., by generating pressure and flow rate measurements associated with a pipe burst in four distinct locations). The result of each inference is the probability of the burst being located in each node. Based on these results, two metrics are used: the predicted distance and the weighted distance. The predicted distance consists of the Euclidean distance between the real pipe burst location and the node with the highest probability (herein referred as the inferred node). The weighted distance is the weighted average between each node’s probability and the Euclidian distance to the real pipe burst location. The mean values after ten location predictions for a pipe burst in the four nodes are displayed in
Table 10.
3.3. Study on the Effect of Measurement Noise in Pipe Burst Location
To study the effect of measurement noise on pipe burst location, in order to take into account the uncertainty of real measurements, two additional training sets of 250 datasets were created, the first one using a noise value of 1% and the second using a noise value of 3%. Training the model with the 0% noise dataset provided a validation accuracy and loss of 90.3% and 0.3274, respectively (
Table 11, C23). Training the model using the 1% noise dataset achieved a validation loss and accuracy of 2.092 and 33.7%, respectively (
Table 11, C24). The use of a measurement noise level of 3% in the training dataset achieved a validation loss and accuracy of 3.015 and 19.2%, respectively (
Table 11, C25).
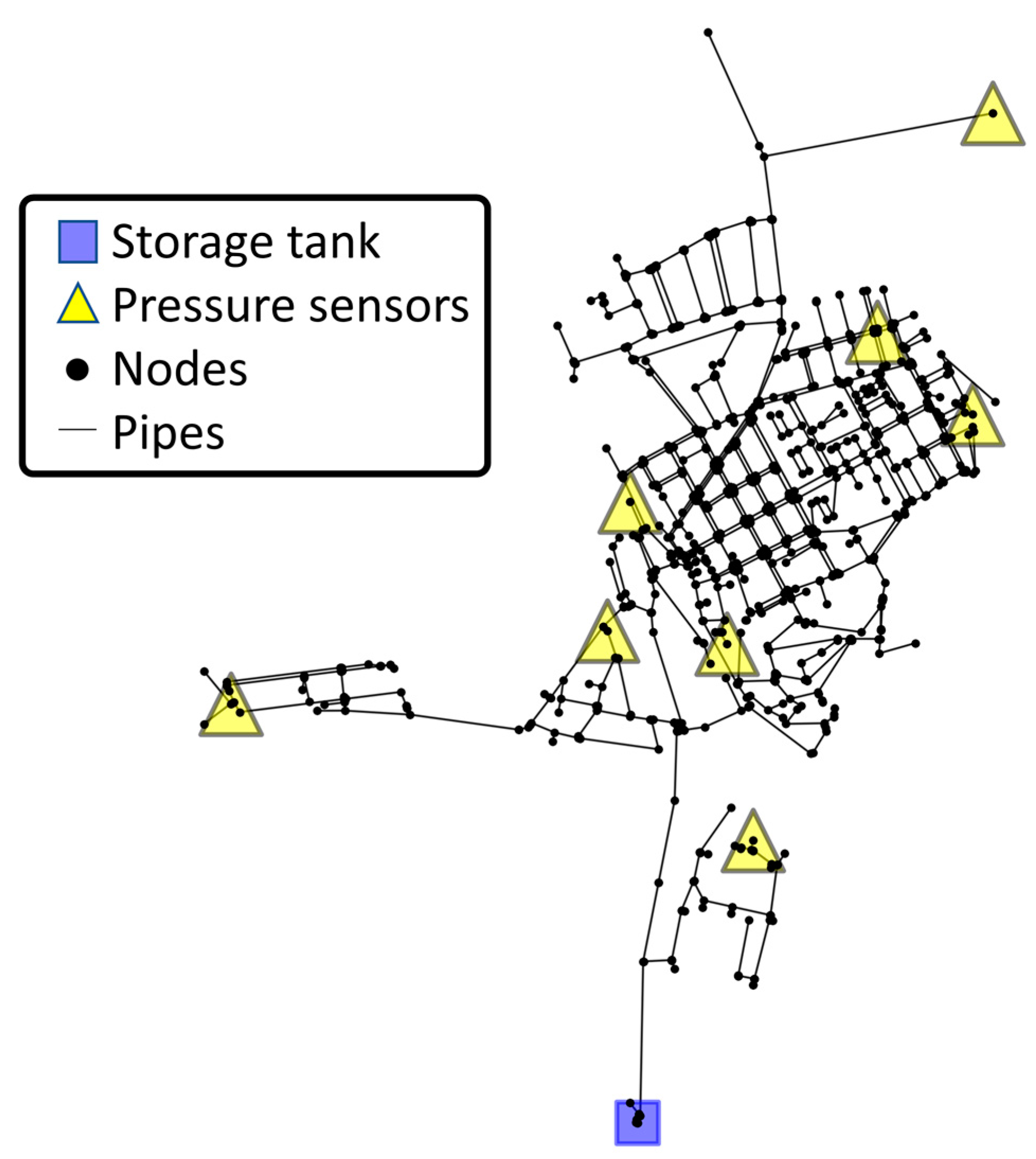
As expected, the increase in measurement noise level leads to a decrease in the validation accuracy and increase in validation loss. Nonetheless, note that the WDN topology is important when assessing the method results. Although this is a classification problem in that it can be either correct or wrong, in practice, selecting an incorrect location a few meters away from the real target (in a network with dozens of km) cannot be deemed wrong. The accuracy of 19.22% (with 3% noise) can seem rather small from a classification point of view, but as is further demonstrated in this chapter, it can be concluded that the most probable nodes are near the true location. This is the reason that the maps provided with each inference are so important. In practice, water utilities aim to estimate the approximate location at a street level using these computational methods. Based on this approximate location, more precise methods can be used, such as acoustic equipment or valve-step testing.
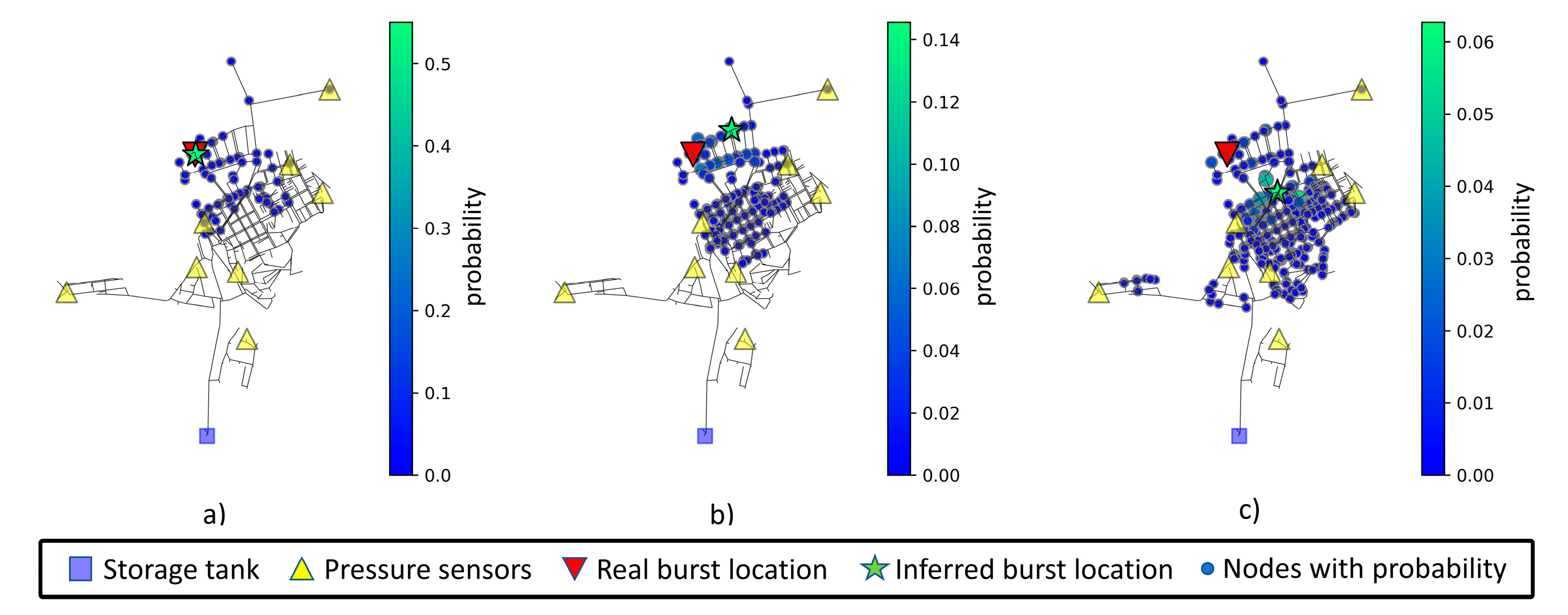
To assess model inference consistency using noisy datasets, measurements were made for inferences using 0%, 1%, and 3% noise. Each inference is made with a newly generated sample not available in training or validation datasets. The mean values after ten location predictions of a pipe burst located at node 20 are displayed in
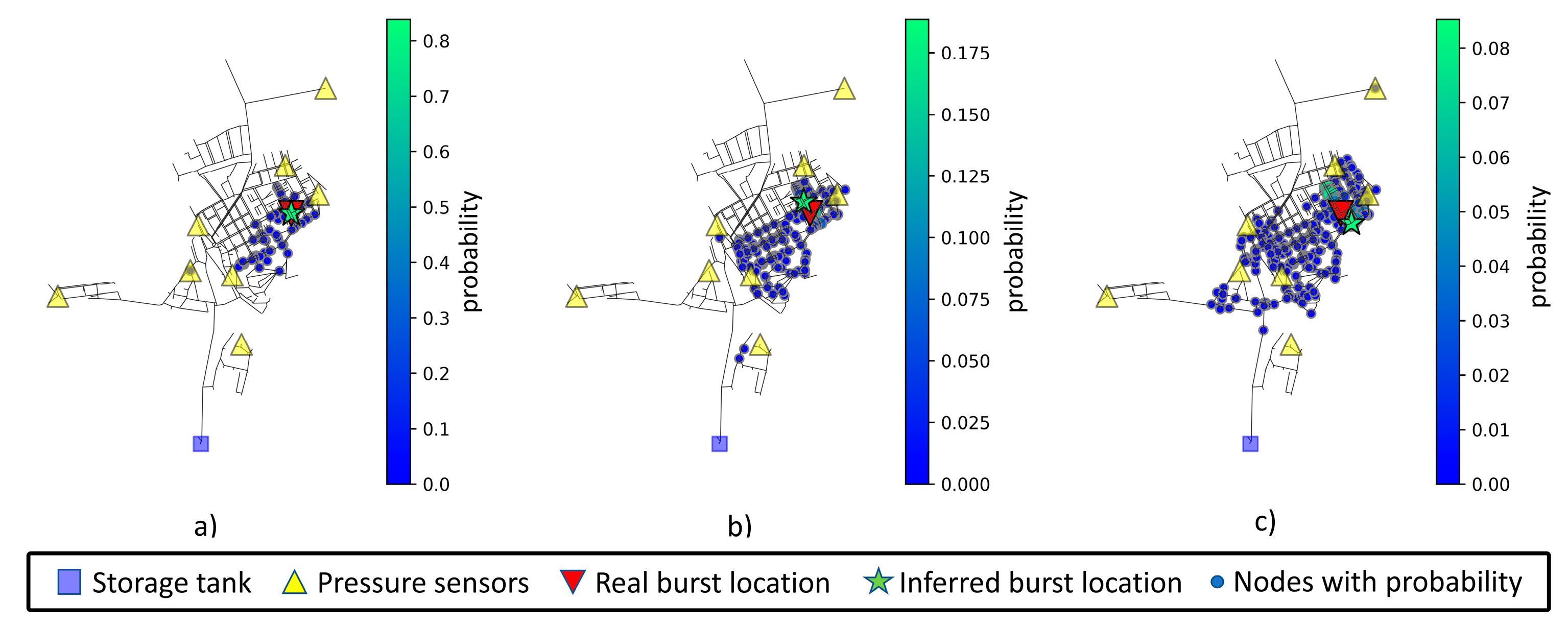
Table 12. The increase in measurement noise level leads to an increase in both mean weighted and predicted distances. Note that node 20 is in the upper left section of the network and is far from any sensor. The inferred node and associated area of interest for node 20 can be viewed in
Figure 10. The visualization depicts the possible burst areas (nodes where there is a probability greater than zero). The most relevant nodes in these areas are displayed with a larger size and a greener color, following the scale presented to the right of each chart.
The increase in measurement noise level leads to an increase in nodes with assigned probability (a greater blue area) and nodes with higher probability (a higher number of green nodes).
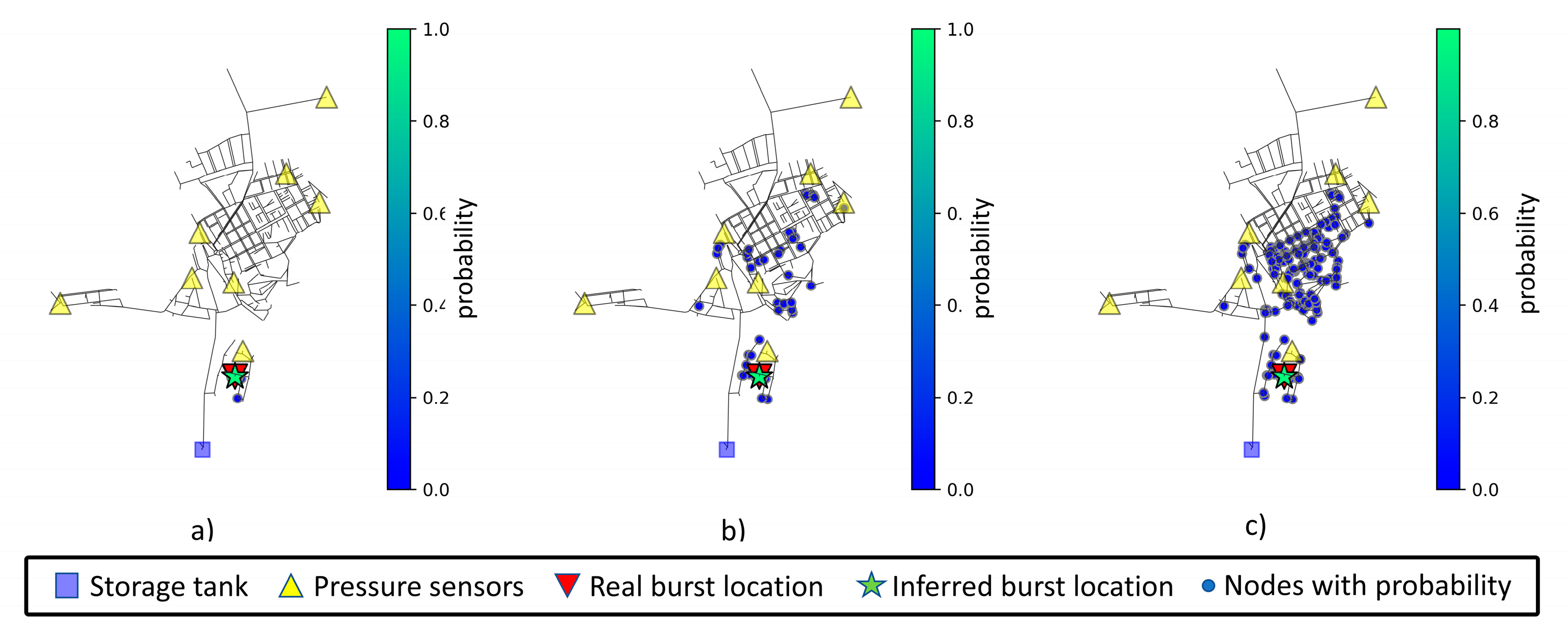
The mean values after ten location predictions for a pipe burst located at node 40 are displayed in
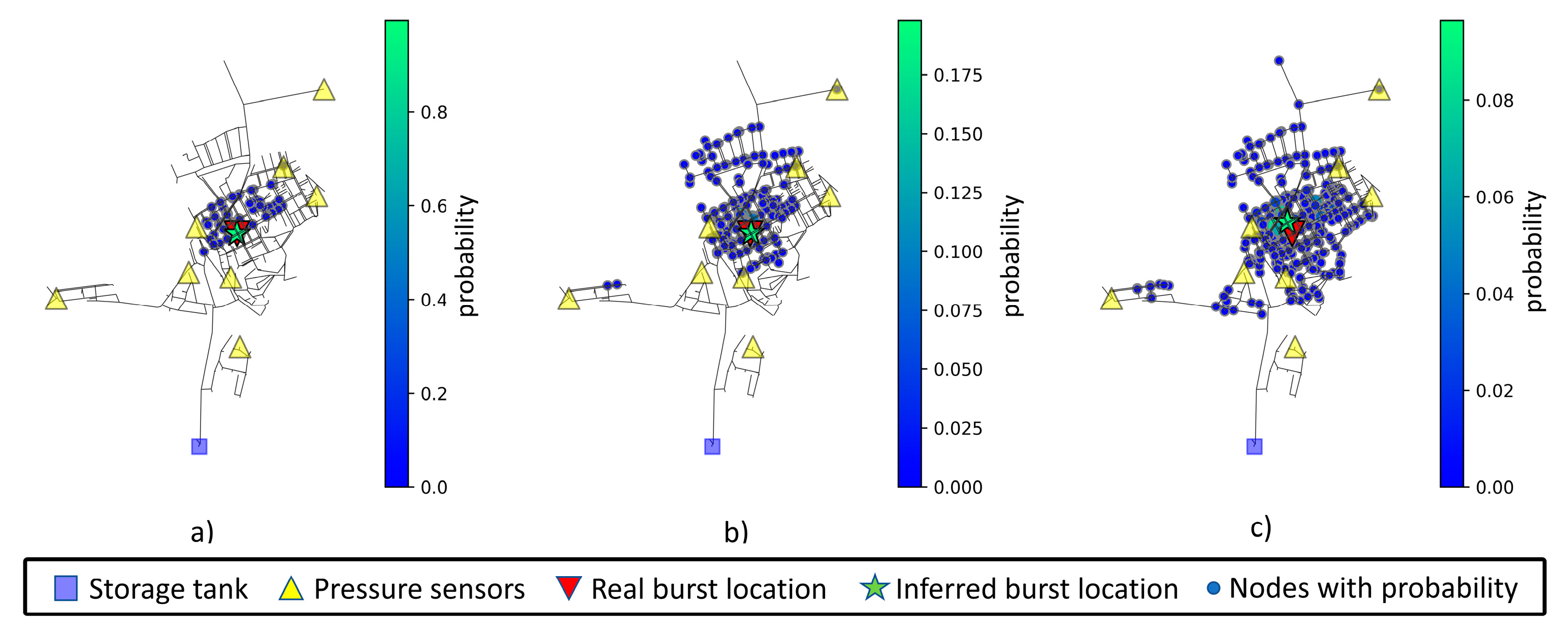
Table 13. Interestingly, the increase in measurement noise level does not increase the weighted or predicted distances. Node 40 is in the bottom right section of the network and in a very specific and isolated area with a nearby sensor. The inferred node and associated area of interest for node 40 can be viewed in
Figure 11.
The mean values after ten location predictions for a pipe burst located at node 235 are displayed in
Table 14. The increase in measurement noise level leads to an increase in both mean weighted and predicted distances. Note that node 235 is in the middle right section of the network, with no nearby sensor. The inferred node and associated area of interest for node 235 can be viewed in
Figure 12.
Finally, the mean values after ten location predictions for a pipe burst located at node 285 are displayed in
Table 15. Once again, the increase in measurement noise level leads to an increase in both mean weighted and predicted distances. Node 285 is in the middle of the network, with no nearby pressure or flow rate sensors. The inferred node and associated area of interest for node 285 can be viewed in
Figure 13.
In sum, the model starts to have difficulty in accurately predicting the burst location as higher measurement noise levels are considered. Whilst without uncertainty, the model is almost always accurate, with predictions in a distance range between 0 and 5 m, the added noise level makes the model more prone to a certain degree of inaccuracy. Nevertheless, it is still capable of making a valuable prediction, and provides an area of interest which can be further reduced using hardware-based techniques.
With 1% noise added, the area of interest (composed by nodes that have a probability greater than zero) starts to become more dispersed and, depending on the proximity of the burst node to a sensor, the model can still be accurate. Even if the model is inaccurate, the set of relevant nodes (with highest probability) highlight the possible area in which the burst occurs. The distance range for prediction of the analyzed nodes is between 0 and 200 m.
With 3% noise added, the area of interest tends to grow and spread, with the probabilities being much lower in magnitude, as can be observed in
Figure 10,
Figure 11,
Figure 12 and
Figure 13. The weighted distance and prediction distance grow, with the distance range for prediction of the analyzed nodes falling between 7 and 202 m.
Compared to existing classification methods, which often cluster the WDN into zones prior to the classification problem, the proposed method considers each possible burst location individually and, as such, the region of interest is composed of nodes with a given assigned probability. This ensures that the inference result is not affected by the clustering procedure.
Furthermore, many of the existing model-based methods for pipe burst location fail to consider the uncertainty in model parameters and the errors in measurement readings. As such, when the uncertainty is significant, those methods can pinpoint to completely wrong locations. Ferreira et al. [
34] compared three distinct model-based techniques for this same case study and concluded that given high uncertainty levels (e.g., noise level of 3%), the unique inferred location is often quite distant from the true location (e.g., between 200 and 300 m). This unique location is not an ideal result since, if wrongly inferred, the water utility may be looking for a pipe burst where there is not one. On the other hand, the proposed method provides a region of interest which varies in size according to the expected uncertainty level. For a water utility, this region of interest is a much more reliable result, since this region can be further reduced in the field, for instance, by operating valves (e.g., step testing), and by assessing if the inlet flow rate increases.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}