1. Introduction
The fast consumption of information from social media and news websites has become a daily routine for millions of users. Many readers neither have the time nor the interest (and/or skills) to fact-check every announced event. This opens up a wide range of opportunities to manipulate the opinions of citizens, one of which is fake news, which contains information about events that never happened in real life (or representations of real events in extremely narrow and biased ways). Fake news can be as simple as damaging the reputation of a person, organization, or country, or as serious as inciting immediate emotional reactions that lead to destructive actions in the physical world.
Since the exploitation of Facebook to influence public opinion during the 2016 U.S. presidential election [
1], there has been significant interest in fake news. However, the dissemination of false information not only misinforms readers but can also result in much more serious consequences. For instance, the spreading of a baseless rumor alleging that Hillary Clinton was involved in child sex trafficking led to a dangerous situation at a Washington D.C. pizzeria [
2]. The global pandemic in 2020 has led to the rise of an infodemic [
3], which could have even more severe consequences by exacerbating the epidemiological situation and endangering people’s health. Furthermore, The recent events of 2022 also showed how politics and global events could be dramatically influenced by the spread of fake news. The Russia–Ukraine conflict was accompanied by an intense information war [
4] featuring an enormous amount of fake stories. In addition to the political world, the World Cup 2022 was surrounded by rumors from both organizers and visitors that had an impact on security during the competition [
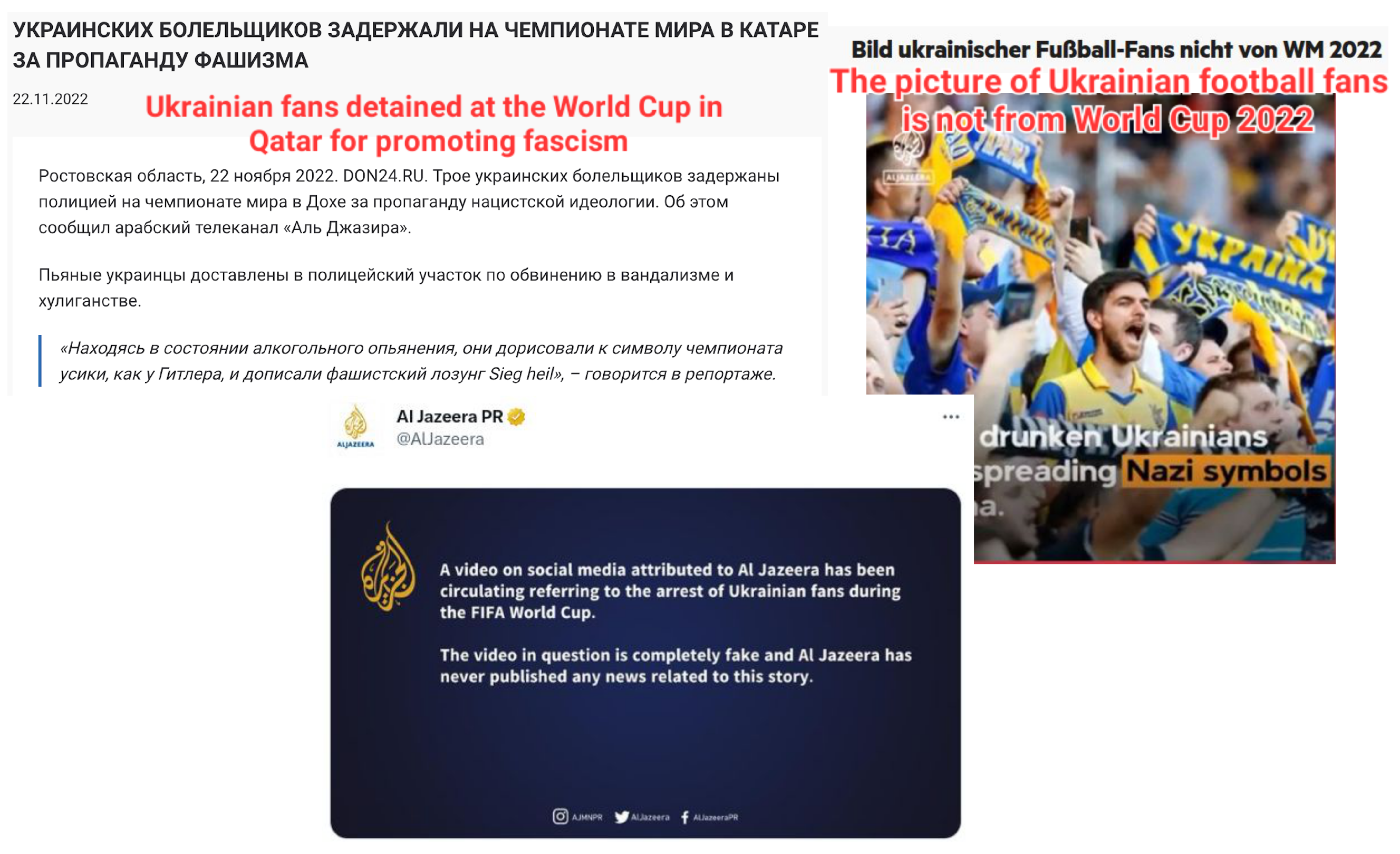
5]. A fake news story illustrated in
Figure 1 is one artifact of this recent information warfare. Given these circumstances, it is more urgent than ever to develop technologies for reliable, open, and available-to-everyone fact-checking and news verification technologies.
The issue of fake news has garnered significant public attention and has also become a subject of growing interest in academic circles. With the proliferation of online content, there is a great deal of optimism about the potential of automated methods for detecting fake news. Numerous studies have been conducted on fake news detection, utilizing a variety of information from diverse sources. While the misinformation mitigation field is represented in the artificial intelligence field via different tasks (i.e., stance detection, fact-checking, source credibility classification, inter alia), we focus on the supervised fake news classification task.
For the fake news classification task, given a news
n and its feature representation
F, we aim to find a classifier
that predicts class
. Discovering a suitable classifier entails searching and refining the classification model
f, as well as extracting an appropriate set of feature representations
F. Multiple supervised fake news detection models have been proposed based on linguistic features [
6,
7]; deep learning models [
8,
9,
10,
11]; or signals from social networks [
12,
13]. One direction of a supervised approach involves using additional information from the web [
14,
15,
16]. In addition to text features, multimodal fake news detection has also been explored [
17,
18]. However, in these works only monolingual text signals were taken into account.
In our work, we propose a new way of how news feature representation F can be defined. We assume that viral spreading of (fake) information may naturally hit the “language barrier”; cross-checking of facts across media in various languages and cultures (that are supposed to be strongly independent) could yield additional signals. We aim to close the gap of monolingual textual feature usage; we explored cross-lingual web features for fake news detection.
The contributions of our work are as follows:
We propose the ’Multiverse’: the new cross-lingual evidence feature for fake news detection based on multilingual news comparison. We explored several strategies for cross-lingual similarity estimations based on pre-trained neural language models.
We conduct extensive experiments with the proposed feature showing its usefulness. First, a human judgment study is used for misinformation identification. Second, we integrate the feature into several fake news detection systems demonstrating that it consistently improves results and helps to improve performance.
We demonstrate how our approach can be used to explain fake news detection to users by showing examples of how extracted cross-lingual information can be used for evidence generation.
We demonstrate how the proposed technique can leverage image similarity by exploring two example news stories using image-based features.
2. Related Work
For practical importance, fake news detection has become an active research topic in the field of natural language processing. A substantial amount of work has been conducted, including the creation of datasets and methods for automatic fake news identification. In this section, we perform a comprehensive analysis of prior art related to the subject of this article, structured into three parts: (1) the analysis of user behavior when attempting to fact check information, (2) fake news detection datasets, and (3) fake news detection methods.
2.1. User Behavior for Fake News Detection
Firstly, before the discussion of automatic machine fake news detection methods, we analyze how real-life users react to fake information and in which way they check the veracity of information.
In [
19], a very broad analysis of users’ behavior was obtained. The authors discovered that when people attempt to check information credibility, they rely on a limited set of features, such as:
Is this information compatible with other things that I believe to be true?
Is this information internally coherent? Do the pieces form a plausible story?
Does it come from a credible source?
Do other people believe it?
Thus, people can rely on the news text, its source, and their judgment. However, if they receive enough internal motivation, they can also refer to some external sources for evidence. These external sources can be knowledgeable sources or other people.
The conclusions from [
20] repeat the previous results: individuals rely on both their judgment of the source and the message. When these factors do not adequately provide a definitive answer, people turn to external resources to authenticate the news. The intentional and institutional reactions sought confirmation from institutional sources, with some respondents answering simply “Google”.
Moreover, several works have been conducted to explore the methods to combat fake information received by users and convince them with facts. In [
21], it was shown that explicitly emphasizing the myth and even its repetition with refutation can help users pay attention and remember the truth. Additionally, participants who received messages across different media platforms [
22] and different perspectives on the information [
23] showed greater awareness of news evidence. Consequently, information obtained from external searches is an important feature for evaluating news authenticity and seeking evidence. Furthermore, obtaining different perspectives from different media sources adds more confidence decision-making process.
In our approach, we explore the use of this kind of evidence in the form of monolingual and cross-lingual news similarity scores.
2.2. Fake News Detection Datasets
To leverage the task of automatic fake news detection there have been created several news datasets focused on misinformation, each with a different strategy of labeling. The comparison of all discussed datasets is presented in
Table 1.
The Fake News Challenge (
http://www.fakenewschallenge.org, accessed on 14 December 2022) launched in 2016 was a big step in identifying fake news. The objective of FNC-1 was a stance detection task [
24]. The dataset includes 300 topics, with 5–20 news articles each. In general, it consists of 50,000 labeled claim-article pairs. The dataset was derived from the Emergent project [
25].
Another publicly available dataset is LIAR [
26]. In this dataset 12,800 manually labeled short statements in various contexts from
PolitiFact.com (
https://www.politifact.com, accessed on 14 December 2022) were collected. They covered such topics as news releases, TV or radio interviews, campaign speeches, etc. The labels for news truthfulness are fine-grained in multiple classes: pants-fire, false, barely-true, half-true, mostly true, and true.
Claim verification is also related to the Fact Extraction and VERification dataset (FEVER) [
27]; 185,445 claims were manually verified against the introductory sections of Wikipedia pages and classified as SUPPORTED, REFUTED, or NOTENOUGHINFO. For the first two classes, the annotators also recorded the sentences forming the necessary evidence for their judgments.
FakeNewsNet [
28] contains two comprehensive datasets that include news content, social context, and dynamic information. Moreover, as opposed to all of the datasets described above, in addition to all of the textual information, there is also a visual component saved in this dataset. All news was collected via PolitiFact and GossipCop (
https://www.gossipcop.com, accessed on 31 August 2021) crawlers. In general, 187,014 fake and 415,645 real news items were crawled.
Another dataset collected for supervised learning is the FakeNewsDataset [
6]. The authors conducted a lot of manual work to collect and verify the data. As a result, they managed to collect 240 fake and 240 legit news items on 6 different domains—sports, business, entertainment, politics, technology, and education. All of the news articles in the dataset are from the year 2018.
One large dataset is NELA-GT-2018 [
29]. In this dataset, the authors attempted to overcome some limitations that could be observed in previous works: (1) Engagement-driven—the majority of the datasets, for news articles and claims, contained only data that were highly engaged with on social media or received attention from fact-checking organizations; (2) lack of ground truth labels—all current large-scale news article datasets do not have any form of labeling for misinformation research. To overcome these limitations, they gathered a wide variety of news sources from varying levels of veracity and scraped article data from the gathered sources’ RSS feeds twice a day for 10 months in 2018. As a result, a new dataset was created consisting of 713,534 articles from 194 news and media producers.
Table 1.
The datasets covered in related work. The majority of datasets for fake news detection tasks are in English.
Table 1.
The datasets covered in related work. The majority of datasets for fake news detection tasks are in English.
| Dataset | Task | Language |
|---|
| FNC-1 [24] | Stance Detection | English |
| Arabic Claims Dataset [30] | Arabic |
| FEVER [27] | Fact-Checking | English |
| DanFEVER [31] | Danish |
| LIAR [26] | Fake News Classification | English |
| FakeNewsNET [6] |
| FakeNewsDataset [6] |
| NELA-GT-2018 [29] |
| ReCOVery [32] |
| GermanFakeNC [33] | German |
| The Spanish Fake News Corpus [34] | Spanish |
Due to the events of 2020, there has been ongoing work toward creating a COVID-19 fake news detection dataset. The COVID-19 Fake News [
7] is based on information from public fact-verification websites and social media. It consists of 10,700 tweets (5600 real and 5100 fake posts) connected to the COVID-19 topic. In addition, the ReCOVery [
32] multimodal dataset was created. It also incorporates 140,820 labeled tweets and 2029 news articles on coronavirus collected from reliable and unreliable resources.
However, all of the above datasets have one main limitation—they are monolingual and dedicated only to the English language. Regarding languages other than English, such datasets can be mentioned:
the French satiric dataset [
35],
GermanFakeNC [
33],
The Spanish Fake News Corpus [
34], and
Arabic Claims Dataset [
30]. These datasets do not fully cover the multilingualism gap in fake news detection. The mentioned datasets are monolingual as well and mostly cover fake news classification tasks, missing, for instance, fact verification and evidence generation problems.
In our work, we relied on English datasets for testing as they are the most commonly used and widespread for experiments. We studied how signals from other languages can improve the quality of monolingual fake news detection.
2.3. Fake News Classification Methods
Based on previously described datasets, multiple methods have been developed to tackle the problem of obtaining such a classifier. The feature sets used in all existing methods can be divided into two categories: (1) internal features that can be obtained from different preprocessing strategies and a linguistic analysis of the input text; (2) external features that are extracted from a knowledge base, the internet, or social networks, and give additional information about the facts from the news, its propagation in social media, and users’ reactions. In other words, internal methods rely on the text itself while external methods rely on meta-information from the text.
2.3.1. Methods Based on Internal Features
Linguistic and psycholinguistic features are helpful in fake news classification tasks. In [
6], a strong baseline model based on such a feature set was created based on the FakeNewsDataset. The set of features used in this work is as follows:
Ngrams: tf–idf values of unigrams and bigrams from a bag-of-words representation of the input text.
Punctuation such as periods, commas, dashes, question marks, and exclamation marks.
Psycholinguistic features extracted with LIWC lexicon. Alongside some statistical information, LIWC also provides emotional and psychological analysis.
Readability that estimates the complexity of a text. The authors use content features such as the number of characters, complex words, long words, the number of syllables, word types, and others. In addition, they used several readability metrics, including the Flesch–Kincaid, Flesch Reading Ease, Gunning Fog, and Automatic Readability Index.
Syntax is a set of features derived from production rules based on context-free grammar (CFG) trees.
Using this feature set, the system yields strong results. That is why in our work we rely on it as a baseline, further extending this set with our newly developed features.
Based on such features, different statistical machine learning models can be trained. In [
6], the authors trained the SVM classifier according to the set of characteristics presented. Naïve Bayes, Random Forest, KNN, and AdaBoost were also frequently used as fake news classification models [
36,
37,
38].
In [
39], the authors explore the potential of using emotional signals extracted from text to detect fake news. The authors analyzed the set of emotions present in true and fake news to test the hypothesis that trusted news sources do not use emotions to affect the reader’s opinion while fake news does. They discovered that emotions, such as
negative emotions,
disgust, and
surprise tend to appear in fake news and can give a strong signal for fake news classification.
In addition to linguistic features, feature extraction strategies based on deep learning architectures were also explored. In [
40], the classical architecture for the text classification task based on CNN was successfully applied to the fake news detection task. Given the recent surge in the use of Transformer architectures in natural language processing, models like BERT [
10,
41] and RoBERTa [
9] have achieved high results in classifying general-topic fake news, as well as in detecting COVID-19-related fake news.
In addition to text features, images mentioned in news articles can serve as strong indicators for veracity identification. Visual content can be manipulated, for instance, via deepfakes [
42] or by combining images from different contexts in a misleading format [
43]. While multimodal fake news detection is a developing field, several approaches were already presented in [
44,
45].
It is evident that models based on internal feature sets have a significant advantage in their ease of use, as they do not require extensive additional time for feature extraction. Furthermore, such models can be highly efficient in terms of inference time and memory usage, as they solely rely on internal information from input news. However, if we take into account the aspect of explainability for end users, the evidence generated from such internal features is unlikely to be sufficient to persuade the user of the model’s accuracy and to justify the label assigned to the news.
2.3.2. Methods Based on External Features
Although internal feature-based models can achieve high classification scores in the fake news classification task, the decisions of such are hard to interpret. As a result, additional signals from external sources can add more confidence to model decision reasoning.
If the news appears on a social network, information about the users who liked or reposted the item and the resulting propagation can serve as valuable features for fake news classification. It was shown in [
46] that fake news tends to spread more quickly over social networks than true news. As a result, to combat fake news in the early stages of its appearance, several methods have been created to detect the anomaly behaviors in reposts or retweets [
47,
48]. In [
49], different data about specific users were explored. The author extracted locations, profile images, and political biases to create a feature set.
User comments related to a news article can also serve as a valuable source of information for detecting fake news, and this approach was explored in [
13]. The dEFEND system was created to explain fake news detection. The information from users’ comments was used to find related evidence and validate the facts from the original news. The Factual News Graph (FANG) system from [
12] was presented to connect the content of news, news sources, and user interactions to create a fulfilled social picture of the inspected news.
To extract more information from the users who interact with news pieces, several approaches based on different word embeddings and transformer-based architectures can be applied. For instance, the SoulMate method [
50] is specifically designed to measure short-text similarities, taking into account information about the authors. Moreover, we can take into account the personalities of the authors and predict their probability of spreading fake news, adapting the idea described in [
51].
A simple source for obtaining evidence to verify the accuracy of information is the web. In several works, such as [
14,
15,
16,
52], the authors used web search engines, such as Google or Bing, to collect relevant articles; they also used scraped information, such as an external feature to build a fake news classifier. As discussed in
Section 2.1, this web-based feature is motivated by the behaviors of real-life users. Consequently, the generated evidence based on scraped information can be more persuasive for users, as it automates the steps they typically take to verify the veracity of news articles.
However, in the discussed methods, we can also see the usage of only one language for evidence granting. The systems that used web search for evidence extraction turned to English search results only. In our work, we wanted to fill this gap to explore cross-lingual web-based evidence for the fake news classification task.
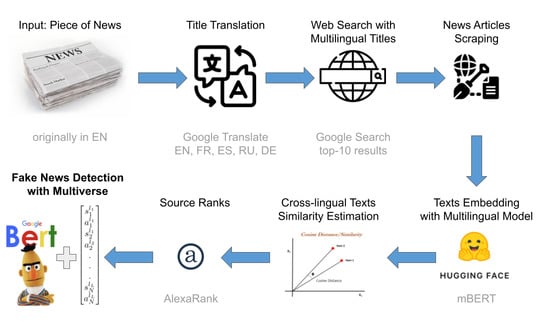
3. Multiverse: A New Feature for Fake News Classification
In this section, we present the general schema of our approach. We describe technical details of its implementation in two following sections. The Multiverse stands for
Multilingual E
videnc
e fo
r Fake New
s D
etection and is based on information extraction from a web search combined with cross-lingual text similarity and text categorization techniques. The idea of the approach is motivated by the user experience illustrated in
Section 2.1 and the lack of multilingualism in automatic fake news detection methods, as discussed in
Section 2.3. Users quite often refer to the web search to check news items seen in some news feeds. In order to overcome the limitations of a monolingual perspective and gain access to diverse viewpoints and supplementary information, conducting cross-lingual verification of news can be highly effective. Such an approach enables a broader scope for rational evaluation of information.
Our proposed approach is based on the following hypothesis:
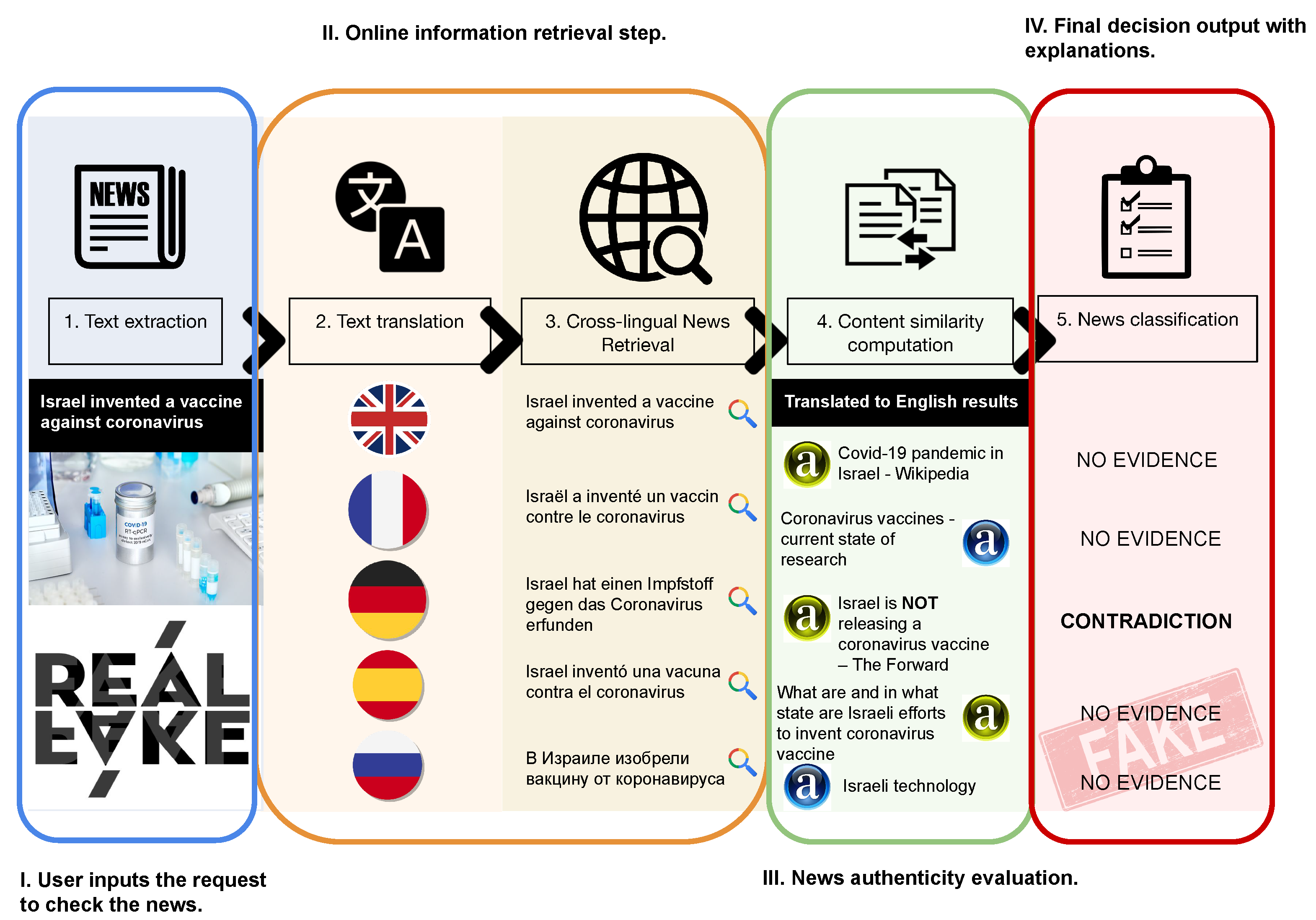
Hypothesis 1 (H1) If the news is true, then it will be widespread in the press, published in various languages, and published across media with different biases; the facts mentioned should also be identical. On the contrary, if the news is fake, it is likely to receive a lower response and be less widespread than a true news article, especially in foreign media. (Another reason that a true news article may not spread in foreign media is the fact that the mentioned event is just “too local” to be of interest to an international audience. To compensate for this obvious limitation, we take into account the ranks of the named entities mentioned in the news as described in Section 5.1.3). The step-by-step pipeline of the approach, schematically represented in
Figure 2, is as follows:
Step 1. Text extraction: As a new article arrives, the title and content are extracted from it. For instance, a user can generate such a request to check a piece of news.
Step 2. Text translation: The title is translated into target languages and new search requests are generated. This is the preparatory step for multilingual news retrieval.
Step 3. Cross-lingual news retrieval: Based on generated cross-lingual requests—translated titles—the search (via a web search engine) is executed. We suppose that this step should be accomplished with an online search available via a search engine.
Step 4. Cross-lingual evidence impacts computation: Top-N articles from search results are extracted to assess the authenticity of the initial news. This step involves comparing the information presented in the news with that of the multilingual articles retrieved from a search query. The credibility and ranking of the news sources are also factored into the analysis. The objective is to estimate the number of articles that confirm or contradict the initial news.
Step 5. News classification: Based on the information from the previous step, a decision is made about the authenticity of the news. If the majority of results support the original news, then it is more likely to be true; if there are contradictions—it is a signal to consider the news as fake.
As a result, a piece of news is represented with a feature set , where N stands for the number of news items extracted for each language, L is the number of languages used for cross-lingual news retrieval; s corresponds to the similarity score between two peace of news calculated with similarity metrics ; a stands for the news source credibility score. The number of languages, scrapped news, as well as cross-lingual news similarity functions are hyperparameters of the proposed approach. In our work, we provide descriptions of how we define these features for our experiments.
From the example illustrated in
Figure 2, we can see that for the news
“Israel invented a vaccine against coronavirus", the majority of the scraped articles provide no evidence that supported incoming news. Moreover, there was an article (originally, in German) with high reliability that provided an explicit refutation of the original information. As there is no supporting information and contradictions with the scraped information, the probability that we should believe in the veracity of the requested news is quite low.
The proposed method based on cross-lingual evidence extraction can work properly with important worldwide news. Indeed, if there is some local event about locally famous parties, in the majority of cases such news will doubtfully be widespread on the Internet. As a result, in our future assumptions and experiments, we will take into consideration datasets and news that cover worldwide events.
To confirm the hypothesis above, we conducted several experiments. For all experiments, we chose the top 5 European languages spoken in Europe (
https://www.justlearn.com/blog/languages-spoken-in-europe, accessed on 20 March 2023) and used on the internet (
https://www.statista.com/statistics/262946/share-of-the-most-common-languages-on-the-internet, accessed on 14 December 2022)—English, French, German, Spanish, and Russian—to obtain cross-lingual evidence. For the search engine, we stopped at Google Search (
https://www.google.com, accessed on 14 December 2022) as it is the top search engine used in the world (
https://www.oberlo.com/blog/top-search-engines-world, accessed on 14 December 2022) and was widely used by users during the fake news experiments mentioned in
Section 2.1.
More specifically, we present the results of three experiments. The first experiment described in
Section 4 is a manual small-scale study describing the methodology and experimental setup for manual news verification using Multiverse. In
Section 5, we propose the methodology to automate the proposed pipeline. We describe how similarity functions can be estimated, source credibility rank can be extracted, and, finally, how the Multiverse feature set can be automatically constructed. Automated fake news detection systems were tested on several fake news classification datasets. We implemented our cross-lingual evidence feature and compared it with several baselines. The main difference between the first and the second experiment is the implementation of stages 4 and 5. In the manual setup, the estimation of cross-lingual news similarity and news categorization was done by human judges; in the automatic setup, we performed the similarity computations and categorization by automatically using machine learning models. The first three stages were conducted in both experiments similarly. In addition to two text-based experiments forming the core of our research, in
Section 6, we deliver the third experiment by investigating the possibility of further extending the idea to the similarity of images retrieved using cross-lingual search.
4. Experiment 1: Manual Similarity Computation and Classification
To incorporate the proposed feature into an automatic fake news detection pipeline, firstly, we wanted to rely on the user experience; we checked the following hypothesis:
Hypothesis 2 (H2) A person can detect fake news using the cross-lingual evidence feature as computed using the pipeline presented in Figure 2. To confirm Hypothesis 1 and 2, we experimented with manual markups where the annotators were asked to classify fake news based on cross-lingual evidence.
4.1. Dataset
For fake news examples, we used the top 50 fake news list from 2018, according to BuzzFeed (
https://github.com/BuzzFeedNews/2018-12-fake-news-top-50, accessed on 14 December 2022). For true news, we used the NELA-GT-2018 dataset [
29]. We manually selected 10 fake and true news items. We attempted to cover several topics in this dataset: celebrities, science, politics, culture, and the world. The full dataset featuring 20 news used for the manual markup is provided in
Table 2.
4.2. Experimental Setup
As Google provides personalized search results (
http://googlepress.blogspot.com/2004/03/google-introduces-personalized-search.html, accessed on 14 December 2022), we precomputed
Step 2 and
Step 3 for convenience and reproducibility. We generated cross-lingual requests in five languages—English, French, German, Spanish, and Russian. To translate from English, the Google Translation service was used. As the news items were from 2018, the time range of each search was limited to this year. For the cross-lingual search, the translated titles were used. From the search results, we used the first page of the search, which was composed of 10 news. As a result, for 20 news items for each language, we obtained 1000 pairs of “original news ↔ scraped news” to the markup.
We asked six annotators to take part in the experiment, to manually conduct
Step 4: cross-lingual evidence impact computation. For this, we created an interface for the markup presented in
Figure 3 (a link to the original annotation table layout is available at
https://github.com/s-nlp/multilingual-fake-news, accessed on 14 December 2022). For each news piece, we provide information about its title, content, and link to the source. As a result, every annotator could evaluate the quality of the text, the credibility of the source, and cross-lingual evidence for each sample from the dataset.
Every annotator received 10 randomly selected news items; as a result, each piece of news was cross-checked by 3 annotators. All non-English pieces of news were translated into English. For each pair, “original news ↔ scraped news”, the annotator provided one of three answers: (1) support: the information in the scraped news supports the original news; (2) refute: the information is opposite or differs from the original news or there is an explicit refutation; (3) not enough info: the information is not relevant or not sufficient enough to support/refute the original news. Finally, at the end of the annotation of a news item, the annotator was asked to proceed with Step 5 of the pipeline and classify the news as fake or true.
4.3. Discussion of Results
Based on the collected annotations, for each news item, we chose the final label based on the majority vote. We estimated the confidence in the annotator’s agreement with Krippendorff’s alpha (
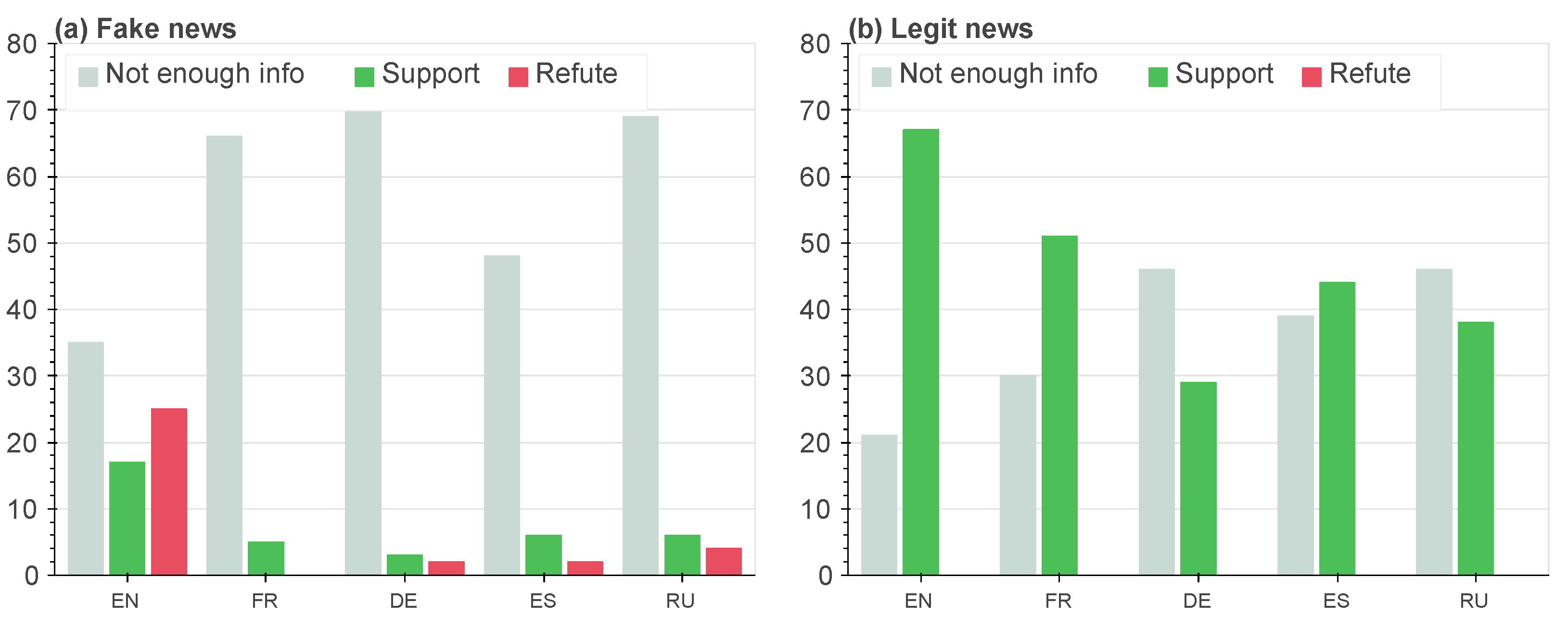
). After that, we separately calculated the distribution of each answer for the top 10 search results by languages for fake and true news. The results are provided in
Figure 4.
As we can see, the distribution of labels for true news significantly differs from the distribution for fake ones. The supporting articles are enough for almost every language. At the same time, we observed that for fake news, there were more signals refuting the English language version compared to supporting it. Furthermore, there was little to no evidence or relevant information dissemination in other languages. The obtained results can be used for the confirmation of Hypothesis 1. The fake news received less of a spread over different languages, while for true news, we can see supportive information from multilingual sources. Finally, the average accuracy of the annotator’s classification was . This confirms Hypothesis 2: a person can distinguish fake news based on cross-lingual evidence.
5. Experiment 2: Automatic Similarity Computation and Classification
In this section, we explore the possibilities to automate fake news classification using the cross-lingual evidence feature. Namely, we consider the following hypothesis:
Hypothesis 3 (H3) The proposed cross-lingual evidence feature computed using the pipeline presented in Figure 2 can improve automatic fake news detection. We conducted chain experiments to validate this hypothesis by automating all of the steps of the pipeline presented in
Section 3. We experimented with several approaches for cross-lingual evidence feature computation and compared the implementations with the annotator’s markup obtained in
Section 4. After that, we incorporated our feature into an automated fake news detection pipeline by comparing it with baseline methods.
5.1. Automatic Cross-Lingual Evidence Feature
We implemented the cross-lingual evidence feature according to the steps of the pipeline described in
Section 3. Firstly, we implemented Algorithms 1 and 2 to estimate cross-lingual texts similarity. Then, we implemented Algorithm 3, which automatically extracts cross-lingual evidence features for input news.
| Algorithm 1 News similarity evaluation using cosine distance. |
Input: news information n, web scraping result w, language of the search l. Output: similarity estimation for the news pair. - 1:
function cosine_distance_news_similarity() - 2:
if then - 3:
= 0 - 4:
end if - 5:
if then - 6:
= 0 - 7:
end if - 8:
- 9:
return - 10:
end function
|
| Algorithm 2 News similarity evaluation using NLI. |
Input: news information n, web scraping result w, language of the search l. Output: similarity estimation for the news pair. - 1:
function nli_news_similarity() - 2:
- 3:
return - 4:
end function
|
| Algorithm 3 Multilingual evidence for fake news detection: feature extraction. |
Input: news information n, languages to use for comparison the maximum amount N of news from the web search to compare with. Output: cross-lingual evidence feature set of similarity with the original news and source credibility rank for each news item from a multilingual web search.
- 1:
function Multiverse(n, L, N) - 2:
- 3:
for do - 4:
- 5:
- 6:
for do - 7:
- 8:
# For similarity score cosine- or NLI-based function can be chosen - 9:
- 10:
- 11:
end for - 12:
end for - 13:
return - 14:
end function
|
5.1.1. Cross-Lingual Evidence Retrieval
To automate
Step 2:
Text translation, we used the Googletrans (
https://pypi.org/project/googletrans, accessed on 20 March 2023) library. For the translation, we used five languages: English, French, German, Spanish, and Russian. To execute
Step 3:
Cross-lingual News Retrieval, the Google Search API (
https://pypi.org/project/Google-Search-API, accessed on 20 March 2023) was used. As in the manual experiment, we generated queries by translating the titles of the original news and extracted only the first page of the search results, which gave us 10 articles for each language.
5.1.2. Content Similarity Computation
The goal of Step 4: Cross-lingual evidence impact computation is to figure out if the information in scraped articles supports or refutes the information from the original news. To estimate the cross-lingual news similarity measurement , we tested two strategies: (1) similarity computation based on the cosine distance between text embeddings (Algorithm 1); (2) scores based on the NLI model (Algorithm 2).
Cosine Similarity
Firstly, we evaluated the similarity between two news items based on their text embeddings. As the similarity between text embeddings can be interpreted as the similarity between the text content, we assumed that such a strategy for content similarity computation can correlate with whether one news item supports information from another. However, there can be cases when the content of the news can be very close or even duplicated, but special remarks, such as “Fake”, “Rumor”, etc., indicate the refutation of the original facts. We took into account such situations. As a result, the algorithm for this content similarity computation approach is as follows:
If the link from the search leads to the file and not to the HTML page, then the news at this link is automatically considered dissimilar to the original one;
If there are signs of the disproof of news, such as the words “fake”, “false”, “rumor”, “lie” (and their translations to the corresponding language), negation, or rebuttal, then the news is automatically considered dissimilar to the original one;
Finally, we calculate the similarity between the news title and the translated original one. For the similarity measure, we choose the cosine similarity between sentence embeddings. To obtain the sentence vector representation, we average the sentence’s token embeddings extracted from multilingual Bert (mBERT) released by [
53] (
https://github.com/imgarylai/bert-embedding, accessed on 14 December 2022). If the similarity measure overcomes the threshold
, then the data described in scraped news and original news are considered the same.
Natural Language Inference (NLI)
On the other hand, estimating the similarities between news items can be reformulated as the natural language inference task. NLI is the problem of determining whether a natural language hypothesis
h can reasonably be inferred from a natural language premise
p [
54]. The relations between the hypothesis and premise can be
entailment,
contradiction, and
neutral. The release of the large NLI dataset [
55] and later multilingual XNLI dataset [
56] makes the development of different deep learning systems to solve this task possible.
The number of classes and their meanings in the NLI task are very similar to the labels “Support”, “Refute”, and “Not enough info”, which are used for the stance detection task in the fake news detection pipeline and the manual markup. Moreover, in [
57], the usage of NLI features for stance detection tasks was tested. The best model based on NLI features showed a 10% improvement in accuracy over baselines in the FNC-1 dataset. An example of the usage of the NLI model on news titles is presented in
Table 3.
We used the XLM-RoBERTa-large model pre-trained on the multilingual XNLI dataset (
https://huggingface.co/joeddav/xlm-roberta-large-xnli, accessed on 14 December 2022) to obtain NLI scores for the pairs “original news as premise
p↔ scraped news as hypothesis
h”. Moreover, we generated input in a special format: (1) the premise was formulated as “The news “<news title + first
N symbols of content>” is legit”; (2) the hypothesis was only “<news title + first
N symbols of content>”. The size
N of the used content was a hyperparameter of this NLI-based approach for the news content similarity computation.
5.1.3. Additional Features
Source Credibility
As discussed in
Section 2.1, users often consider the credibility of the news source (
a) when verifying the authenticity of a news piece. In addition, such a feature is widely used in the methods described in
Section 2.3. In the Multiverse feature set
F, we also take into account the credibility of the source from where the news comes from. Following [
58], we used Alexa Rank for source assessment. More recent works, such as [
59], further confirm the usefulness of Alexa-based metrics news media profiling.
Named Entity Frequency
During the manual experiment, it was discovered that a cross-lingual check is more relevant for news about worldwide important events, people, or organizations, and not the local ones. As a result, to evaluate the worthiness of the news to be checked in a cross-lingual manner, we (1) extracted NEs from the title and the content of the news with mBert fine-tuned for NER (
https://huggingface.co/Babelscape/wikineural-multilingual-ner, accessed on 14 December 2022); (2) found the most relevant page on Wikipedia; (3) evaluated the Alexa Rank of the corresponding Wikipedia page to estimate the popularity of the NE. For our experiments, we assumed that all of the news items were about worldwide events. However, this additional feature should be included in the live fake news detection pipeline.
5.2. Comparison with Manual Markup
To assess the effectiveness of our chosen approaches for computing content similarity between news items, we conducted a small case study on a manually marked-up dataset. For each approach of news similarity estimation, we calculated the accuracy of such an experimental setup: the classification task if the scraped news supported the original news. The manually annotated dataset consisted of 1000 pairs of “original news ↔ scraped news”, each labeled by three annotators; the final label for each pair was determined by majority voting.
Taking this setup, we fine-tuned hyperparameters for both approaches. Specifically, we fine-tuned the threshold for the embedding-based similarity approach. We conducted a hyperparameter search on the segment with . The best result was achieved with a value of 0.5 for decision-making on whether the scraped news supports the original news or not. For the NLI-based approach, we fine-tuned the length of the news text that was passed as input to the NLI model. We found that the optimal hyperparameters for this approach were a news text length of 500 symbols, which corresponds to the news title plus the first two paragraphs of the content. Additionally, we unified the “neutral” and “contradiction” classes in the NLI model to have a similar setup as the embeddings-based approach.
Finally, for the cosine distance approach, we achieved accuracy, while for the NLI approach, we achieved accuracy in the 1000-pairs dataset. Although the models are not ideal, we believe that they can be used as baseline approximations of human judgments.
5.3. Automatic Fake News Detection
Finally, we conducted a set of experiments to validate Hypothesis 3, i.e., if the presented cross-lingual evidence feature could improve automatic fake news detection systems. We integrated the automated cross-lingual evidence feature into the fake news classification pipeline tested on three datasets.
5.3.1. Datasets
In the tested datasets for our automated experiment, we attempted to cover several worldwide topics—politics, famous people, events, entertainment, as well as the most recent events connected to COVID-19. Firstly, we evaluated the systems on a multi-domain dataset by [
6], which consists of two parts: the
FakeNewsAMT dataset (240 fake and 240 legit articles) and the
CelebrityDataset dataset (250 fake and 250 legit articles). The
FakeNewsAMT dataset consists of news from six topics: sports, business, entertainment, politics, technology, and education.
CelebrityDataset is dedicated to rumors, hoaxes, and fake reports about famous actors, singers, socialites, and politicians. Secondly, we ran experiments on the COVID-19 fake news dataset
ReCOVery [
32]. It consists of 2029 (665 fake and 1364 true news). The full statistics about all used datasets is presented in
Table 4. All datasets were originally in English.
We used the 70/20/10 proportion for the train/test/dev validation split.
5.3.2. Baselines
We compared our approach with several baselines. For the baseline, we chose the fake news systems based on internal features computed either via linguistic analysis or neural networks.
Linguistic Features: In [
6], a baseline fake news classification model was trained based on Ngrams, punctuation, psycholinguistic features extracted with LIWC, readability, and syntax. In [
32], LIWC features were used as some of the proposed baselines. We tested these features separately, grouped them all, and in combination with our proposed feature. We experimented with SVM, RandomForest, LogRegression, and LightGBM. We used standard hyperparameters set for the models. The results of the best models based on LightGBM are presented. We refer to the model that combines all of the linguistic features mentioned above as the
All linguistic model.
Text-CNN, LSTM: Following [
32], we tested the classical model for text categorization of TextCNN and LSTM on all datasets.
Only monolingual evidence (ME): In addition, we compared our feature with a baseline approach that only uses monolingual English evidence. In this case, we also utilized the LightGBM model.
5.3.3. Results
To evaluate the performance of fake news classification models, we used three standard metrics:
,
, and
. The formulas are provided below:
We experimented with both types of content similarity measurements—either cosine similarity between embeddings (Emb.) or NLI scores—concatenated with the source credibility rank (Rank) of the scraped news. Both Emb. and NLI features are presented as vectors of similarity scores for the pairs “original news ↔ scraped news”.
Table 5 compares the results of our model based on cross-lingual evidence (CE) with the baselines of three datasets. To prove the statistical significance of the results, we used the paired
t-test on the five-fold cross-validation. All improvements presented in the results are statistically important. Additionally, we provide a histogram view of the
score comparison for all three datasets: FakeNewsAMT (
Figure 5), Celebrity (
Figure 6), and ReCOVery (
Figure 7).
The CE features exhibit slightly better performance than the baselines, or they perform comparably to the linguistic features. As such, a baseline fake news detection system can be built using only the CE feature, which offers greater explainability compared to other models. As expected, using only ME-based features for fake news detection yields worse results compared to using CE features. The NLI-based CE features generally exhibit worse results compared to the embeddings-based approach. To further improve performance, the NLI model can be specifically trained for the task of detecting confirmation or refutation in news content.
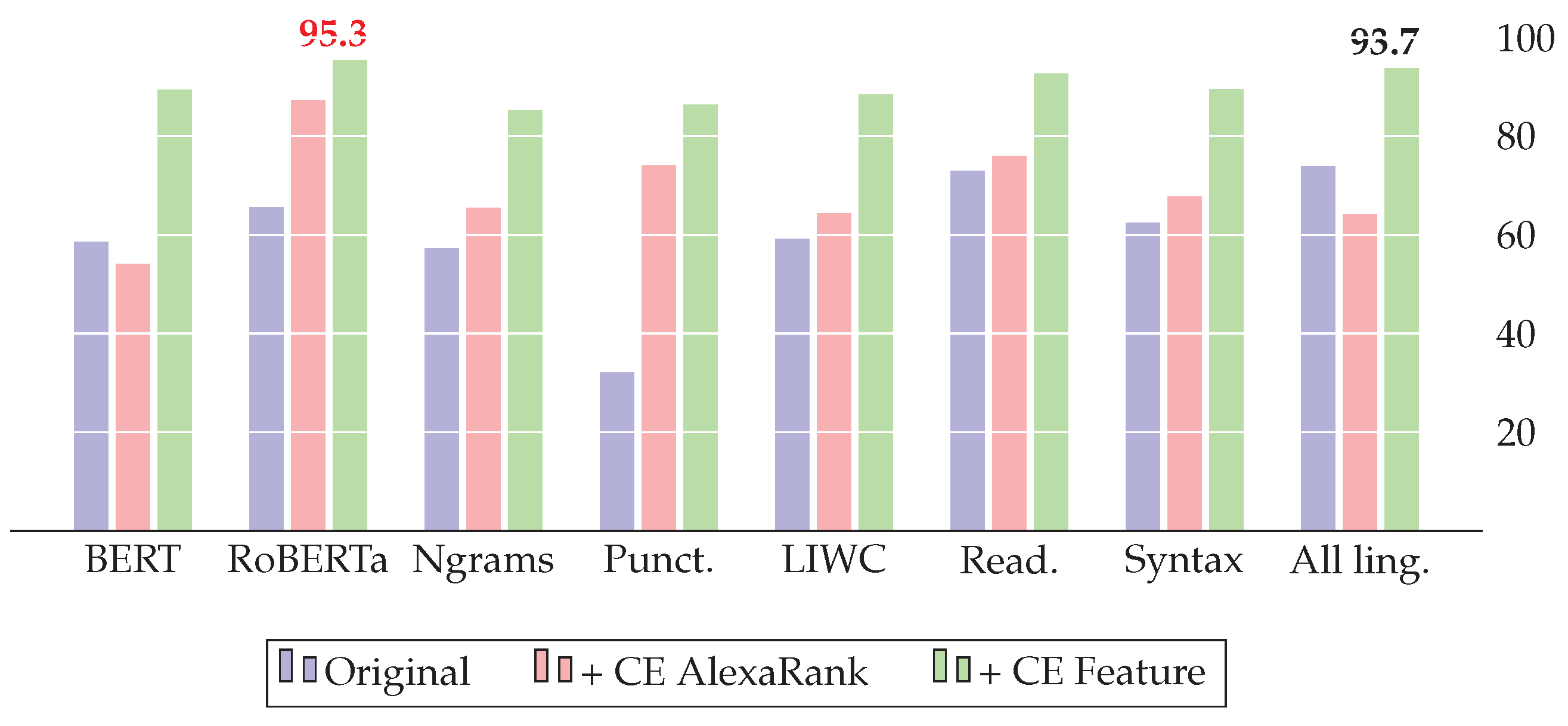
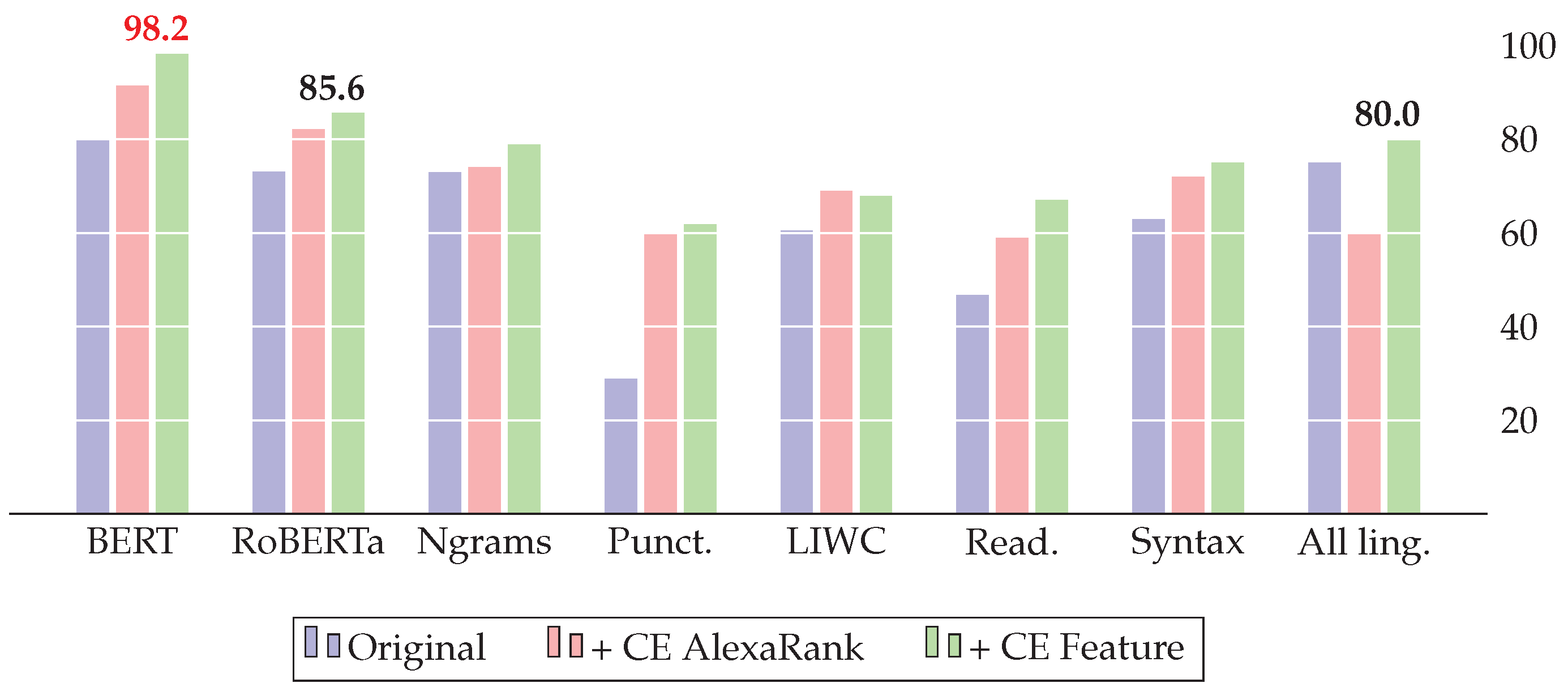
The addition of CE features improves all baseline models. For FakeNewsAMT, the best score is achieved with BERT embeddings in combination with CE features. For the Celebrity dataset, BERT with CE features shows the best results, achieving the best result. Despite RoBERTa showing the highest score for ReCOVery, the combination of all linguistic and CE features and specifically Ngrams with CE features shows competitive results, achieving and , respectively.
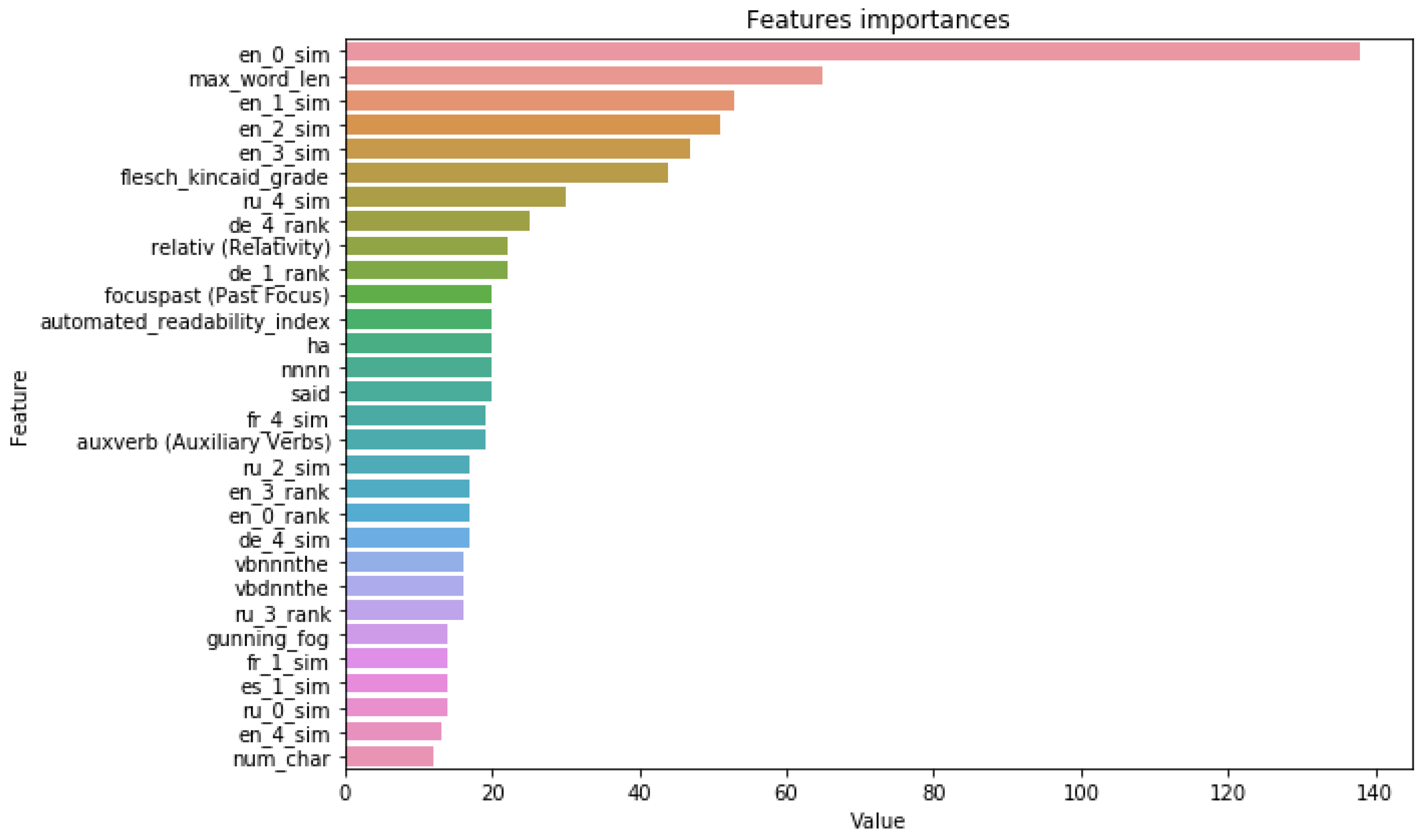
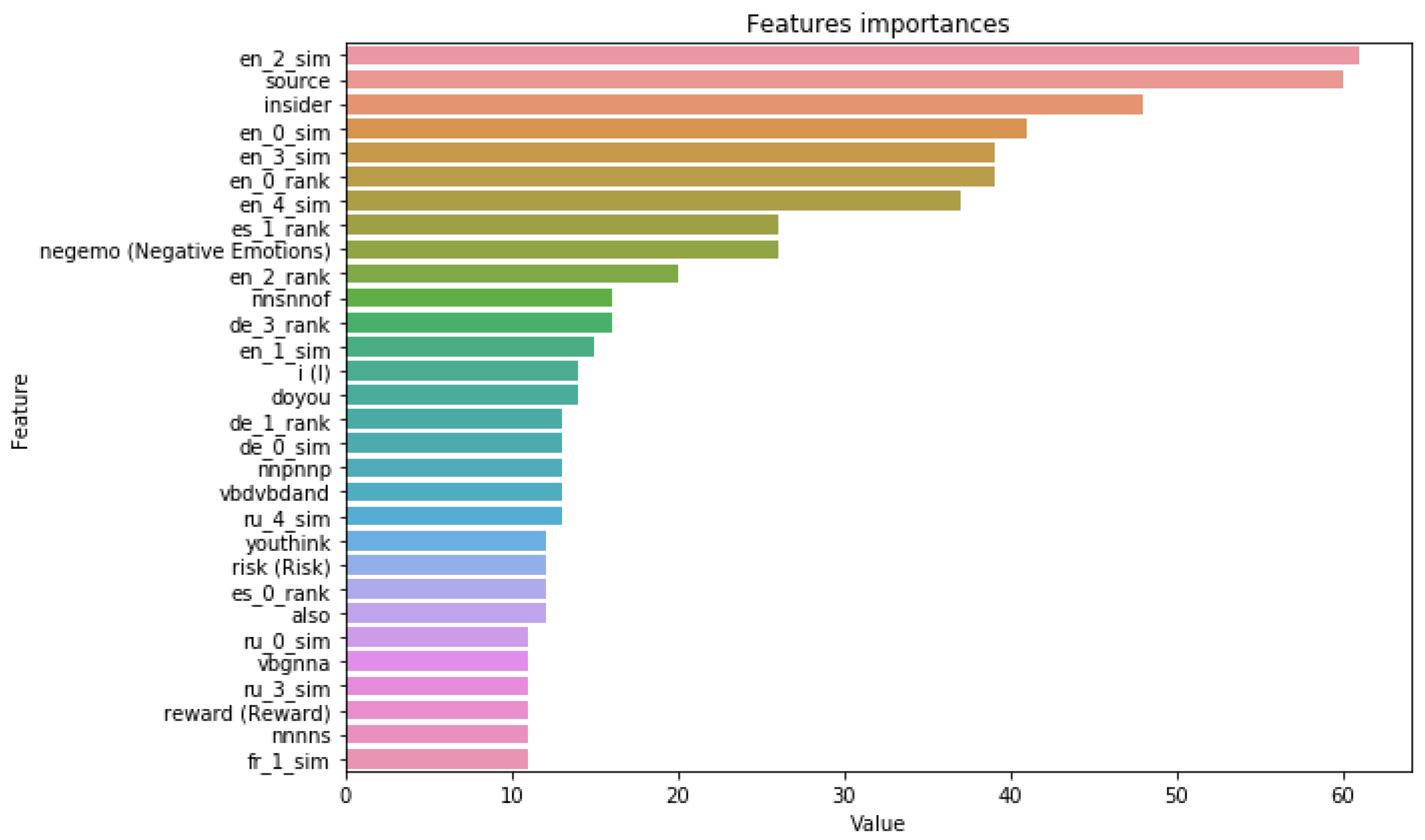
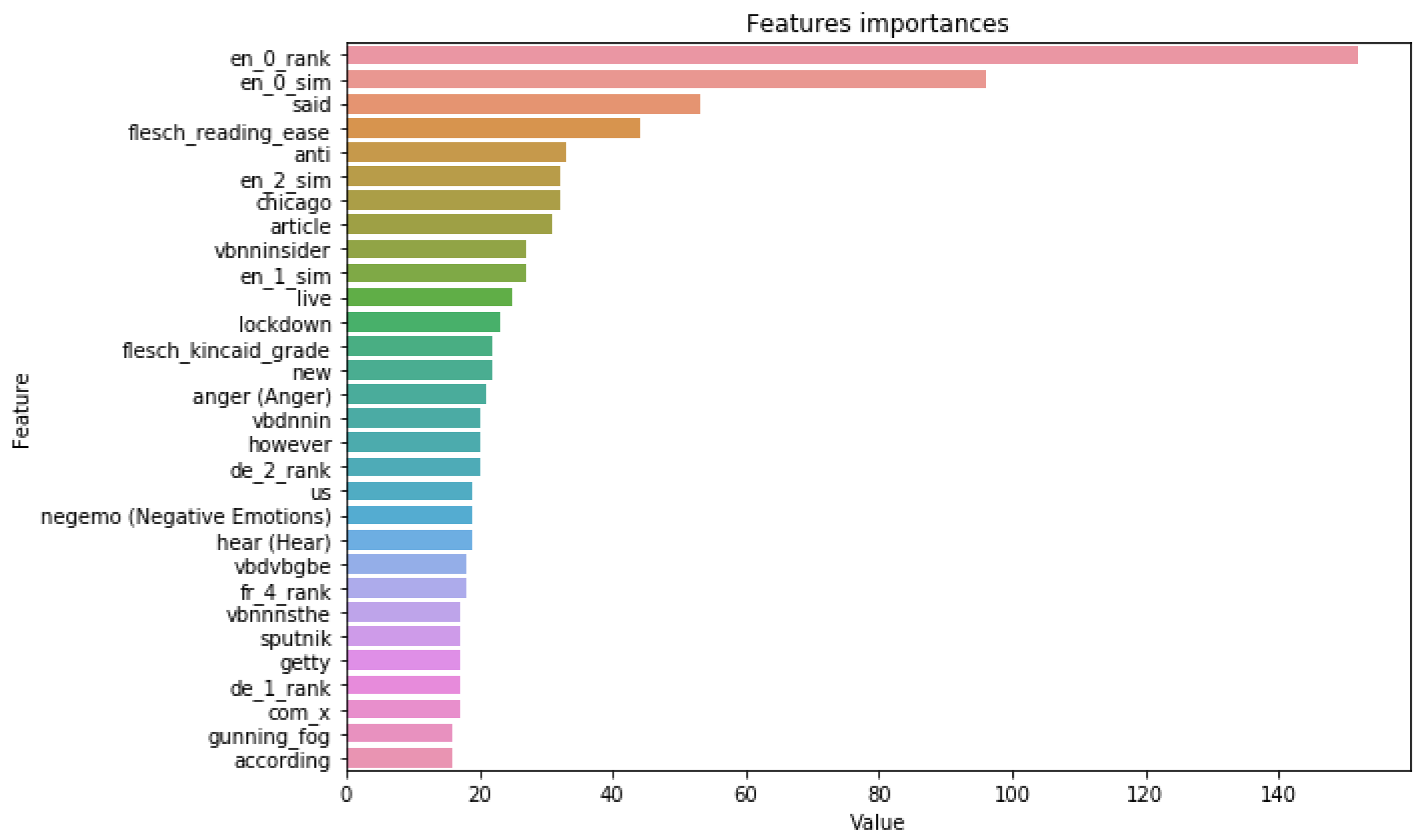
The importance of the proposed features in the model’s decision-making is also confirmed by the feature’s importance. The top 30 most important features for the best models for all datasets based on embeddings similarities are reported in
Figure 8 and in
Appendix A. For the
FakeNewsAMT,
Celebrity, and
ReCOVery datasets, we can see the presence not only in English but in cross-lingual evidence features in the most important features. Although the English evidence features had the highest importance for the top three news from the search results, the similarity scores and rank of the source from other languages (such as French, German, Spanish, and Russian) also contributed to the overall performance.
5.4. Ablation Study
In order to verify which part of the presented cross-lingual evidence features impacted the results the most, we conducted an ablation study.
We compared the best results of the combinations of the linguistic features and CE evidence features. We tested the usage of monolingual English evidence (ME) and only source ranks (Rank) in combination with linguistic features. The results are presented in
Table 6.
We can see that the rank of cross-lingual evidence sources compared to the combination of content similarity and ranks resulted in worse performance. This trend is also observed for the combinations of linguistic features with ME Rank (rank of only English sources), ME Emb. + Rank (content similarity comparison based on embeddings between the original news and only English search results in combination with English sources’ ranks), and CE Rank (the sources’ ranks of all scraped cross-lingual articles). For statistically significant proof for all comparisons with the best model, we used the paired t-test on the five-fold cross-validation. All of the obtained results are statistically significant. Consequently, we can claim that the use of proposed cross-lingual evidence features is justified.
5.5. Usage and Explainability
Our proposed feature can be easily utilized to explain the model’s decision and provide evidence from various sources confirming or refuting the verifiable news. For example, full-text evidence can be generated based on the obtained news to provide the user with at least the source of a critical attitude towards the original news. As the first step of such an explanation, we can report the scraped news, the rank of the source, and an approximation of the similarity to the original news. The examples of such a report are illustrated in
Appendix B,
Table A1 and
Table A2. Finally, the proposed Multiverse feature can be framed into a platform for fake news detection. There, users can input the piece of news as a request and receive a cross-lingual news comparison. An example of such a demonstration can be found in
Appendix C.
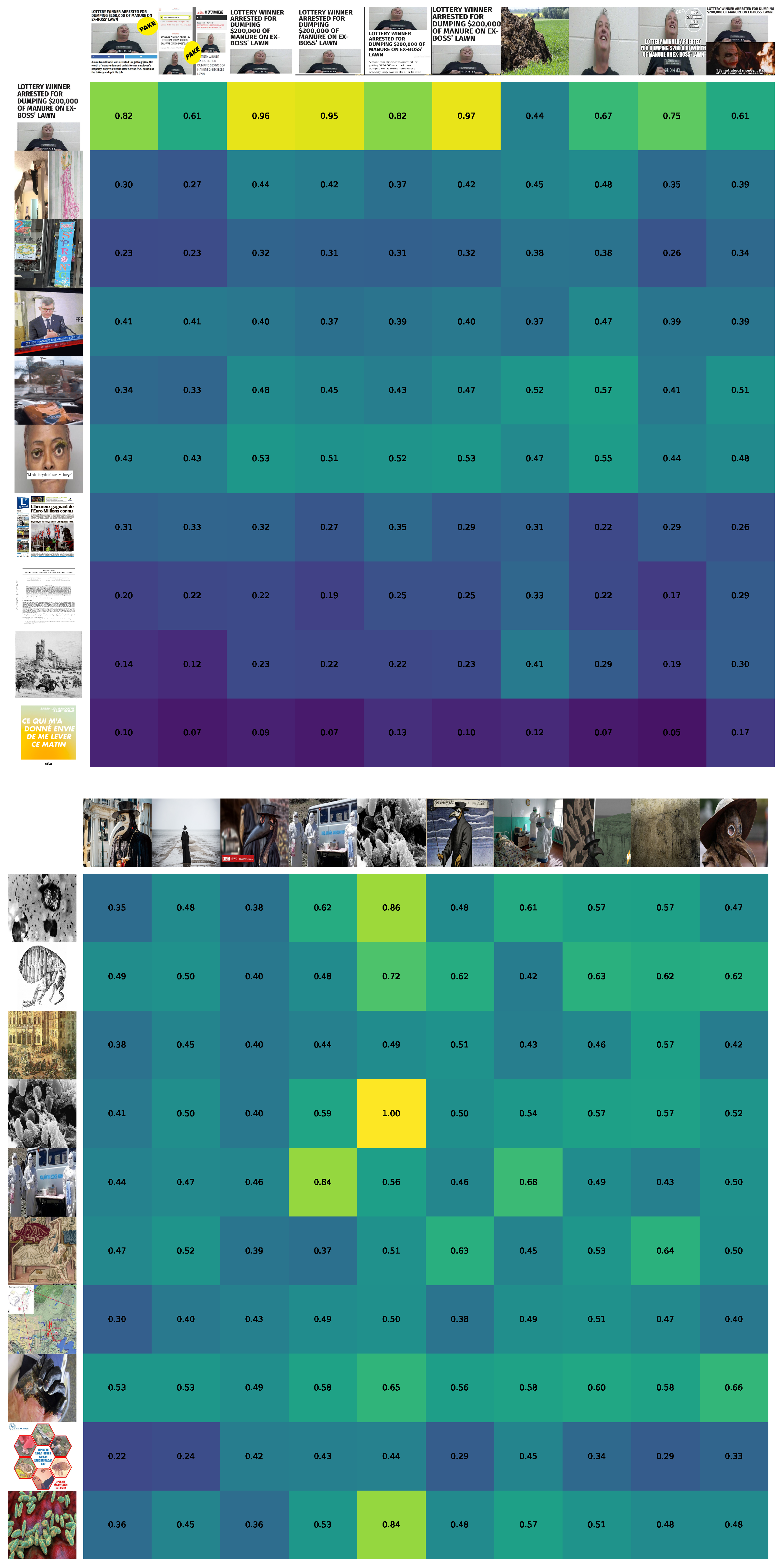
As can be seen from the examples, the hypothesis is confirmed by real pieces of news. For instance, in the case of the fake news example “Lottery winner arrested for dumping $200,000 of manure on ex-boss’ lawn”, we can see different scraped information. Some of the articles explicitly refute the news and name it as fake, e.g., the information from PolitiFact: “Viral post that lottery winner was arrested for dumping manure on former boss’ lawn reeks of falsity” and the Spanish list of fake news, i.e., “Estas son las 50 noticias falsas que tuvieron mayor éxito en Facebook en 2018”. However, some of the scraped news really copied the original title in different languages (“Un gagnant de loterie arrêté pour avoir déversé 200,000$ de fumier sur la pelouse de son ex-patron”, ПОБЕДИТЕЛЬ ЛОТЕРЕИ АРЕСТОВАН ЗА ТО, ЧТО ПОТРАТИЛ $200,000, ЧТОБЫ СВАЛИТЬ ГОРУ НАВОЗА НА ГАЗОН). However, we can see from the source ranks that these articles come from unreliable sources and the user should think critically about the information. The other titles either correlate the topic but give different information that does not support the original one (“Lotto-Gewinner holt Mega-Jackpot und lässt 291 Millionen Dollar sausen & Lottery winner takes MegaJackpot and drops”) or do not correlate in any way with the input article (“Histoire de Suresnes—Wikipedia & History of Suresnes—Wikipedia”). As a result, the user should be critical of the information since the confirmation number is quite small and there are even claims that the news is fake.
Contrary to the fake news, the legit news “Bubonic plague outbreak in Mongolia” received a large amount of support from all target languages. We can see the information about the bubonic plague is presented in the first cross-lingual results: “Bubonic plague: Case found in China’s Inner Mongolia”, “Epidémie : des cas de peste détectés en Chine et en Mongolie & Epidemic”, “Mongolei: 15-Jähriger an Beulenpest gestorben-DER SPIEGEL”, “BROTE DE PESTE BUBÓNICA EN MONGOLIA”, “В Мoнгoлии прoизoшла вспышка бубoннoй чумы”. Most importantly, the similarity between cross-lingual news content reinforces the fact that it comes from reliable sources. Thus, as we can see substantial cross-lingual support from trustworthy sources for the original news, the probability of believing in this information is quite high.
6. Experiment 3: Exploring the Use of Image Similarity Computation in the Multiverse
In this section, we present a preliminary study on further developing our method for the image domain. The idea in the following way:
The original headline is translated into 4 languages: English, French, German, Russian, and Spanish.
Requests via Google are made for each translated headline as well as the original one.
The top k relevant images are collected from the search results, where k is a hyperparameter of the approach.
Each image collected for each evidence language can be compared to each image collected from the search results for the headline in the original language to obtain pairwise image similarities.
Pairwise similarities are averaged to obtain the overall similarity of collected images.
First, we need to note that this additional experiment was done to explore the overall possibility to transpose the idea to images. To illustrate our idea for future work, we picked two news examples from the appendix: one fake news item about the “lottery” and one legitimate news item about the “plague”. The examples are the same as those discussed in
Section 5.5. Parameter
k was set to 10. The top 5 collected images for each language are provided in
Appendix B,
Figure A3 and
Figure A4. In order to compare images, the CLIP [
60] model (we used the ViT-B/32 version of the model) was used for encoding. The resulting feature vectors were compared with the cosine similarity. Text for the model input was formed as “This is a picture for newsbreak ‘<news title>’”.
Results
The results of the image comparison for each language pair as well as the overall similarity are provided in
Table 7. Moreover, we provide examples of the pairwise image comparison in
Figure 9.
From
Table 7, it can be assumed that for legit news the average similarity of images is higher than for fake news. However, such results could be the consequence of the fact that the selected legit piece of news is more general. More research is required for the hypothesis to be confirmed. Namely, a run on datasets used in Experiment 2 will be a reasonable setup.
7. Limitations and Future Work
The proposed cross-lingual evidence feature implemented using the described pipeline in
Section 5.1 can have several limitations.
The main limitation is that our approach works best with globally important and widely spread events. Unfortunately, it is less applicable to local news related to specific regions or individuals. Nonetheless, even if the news concerns a well-known local figure, it is likely to be covered in news sources from neighboring countries. Consequently, a cross-lingual check with neighboring countries’ languages can also be useful.
Secondly, employing Google services for search and translation stages can introduce biases from personalized systems. To mitigate personalization in the search, we conducted experiments in incognito mode to conceal the search history and location parameters. However, Google Search can employ meta-information and tailor the resulting feed. On the one hand, using Google services is motivated by the user search experience. On the other hand, replicating such experiments can be challenging. To address this issue, one may use pre-saved snapshots of internet searches for a precise time period or use more anonymized search engines.
As we used automated translation to obtain the queries for cross-lingual search, there can be another side of such an automated translation application—some internet media can use automated translation to obtain the duplication of the news in the target language. Moreover, the methods for machine translation are becoming more advanced every year. As a result, we can obtain the repetition of the news in search results over the different languages. However, we believe that our proposed pipeline can handle such cases as we incorporated in our feature the source rank of the news. We believe that reliable media still self-process text material in their language. In future work, the addition of the detection of machine-generated text can be considered.
Another part that can be added to the proposed cross-lingual feature is the cross-checking of the information, not only with the original news but also between scraped multilingual evidence. That can add additional signals to the information verification process and reveal new details. Moreover, in this work, we used linguistic features calculated only for the original news. Such features can also be added to the all-scraped news in different languages when the appropriate methods are implemented.
In the presented experiments, the original news was presented only in English. Moreover, the datasets and information noise on the internet generally exist in larger amounts in English compared to any other language. In future work, it will make sense to test the proposed feature for the news originally presented in different languages other than English. Moreover, the amount of scraped evidence for language should be somehow normalized according to the overall amount of news that appears in the language.
8. Conclusions
We presented Multiverse—an approach for detecting fake news that utilizes cross-lingual evidence (CE). This approach is based on Hypothesis 1, which posits that news can propagate across languages, and is motivated by user behavior. The aim of the Multiverse is to overcome the constraints of previous work, which relied on only monolingual external features.
Firstly, we conducted a manual study on 20 news items to test Hypothesis 2, on whether the real-life user can use cross-lingual evidence to detect fake news. The annotators successfully passed the task of such news verification, providing the markup of 100 pairs “original news ↔ scraped news”. The annotators could detect fake news based on our proposed pipeline with an accuracy of , which confirms Hypothesis 2.
Then, we proposed Multiverse for automatic fake news detection to verify Hypothesis 3. To define the similarity measurement between cross-lingual news, we experimented with two strategies: (i) based on cosine distance between news text embeddings; (ii) based on natural language inference (NLI) scores, where the original news was used as the premise p and scraped news as the hypothesis h. We compared the proposed strategies with human assessments of 1000 pairs of marked news items, showing that these methods can be used for news similarity estimations. Finally, we integrated the proposed cross-lingual feature into the automated fake news detection pipeline. The cross-lingual feature itself showed the performance at the baseline level, proving a zero-shot usage of Multiverse to be a strong baseline fake news detection system. Moreover, the combination of our proposed feature with linguistic features based on the original news text yields significant classification results, outperforming both statistical and deep learning fake news classification systems. These results confirm Hypothesis 3: fake news detection systems benefit from Multiverse usage in both performance and explainability sides.
Additionally, we provided an ablation study, where the necessity of the usage of cross-lingual evidence with source rank, compared to only monolingual features was proven. We showed how our feature can be extended to visual content usage. Finally, to explore the explainability possibilities of Multiverse, we showed how the obtained cross-lingual information can be used for further evidence generation for the end users.
Finally, we presented a preliminary study on the integration of the similarity of visual illustrations of news with the proposed methodology, obtaining promising results worth further investigation.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}














