1. Introduction
The length effect was first brought to light by Leonardo de Vinci, who said “Among cords of equal thickness the longest is the least strong” [
1]. In the context of levees, the length effect refers to the fact that as the length increases, there is a larger distance over which to encounter a weak spot in the levee, and thus a higher probability of failure. Typical reliability analyses of levees compute the probability of geotechnical failure over a small or infinitesimal length referred to as a cross section. However, risk analysis is often interested in the failure probability of long stretches (or reaches) of levees. Depending on the spatial variability of the soil parameters, and the length of the levee, the failure probability of a reach can be many times greater than that of a cross section. Incorrectly assigning it to the reach can lead to inaccuracies in failure and risk assessment of levees, in an unconservative direction.
Different approaches of accounting for the length effect in levees can be found in the literature. Vanmarcke proposed a method involving first crossings [
2,
3] to estimate the probability of failure over a longitudinal length. A crossing refers to the resistance being surpassing by the load, or equivalently the difference between them (also referred to as the limit state function) crossing zero and becoming negative. The method calculates the probability of such a crossing along a given length. It treats the limit state function as a random field, the parameterizing of which requires some assumptions. Li and Hicks [
4] compared a simple reliability method for long earthen slopes proposed by Vanmarcke [
5] with a fully three-dimensional model for slope stability and concluded that for large scales of fluctuation, the methods were in agreement, but for small scales of fluctuation, the Vanmarcke approach can produce unconservative reliability indices. The slope they considered was only 50 meters long, so the differences may have been due predominantly to the simplified modeling of slope instability in the Vanmarcke method, rather than the method of handling the spatial variability. More pragmatic methods are also found in the literature. Bowles et al. [
6] took the length effect into account in a risk analysis of the Herbert Hoover Dike in Florida. In that case, they broke up the levee into segments of about 500 m, and for all failure mechanisms besides ’piping through the foundation’, they assumed the segments were independent. For piping through the foundation, they judged that there was ‘some correlation’ between sections, and accounted for this by taking the average of failure probability assuming (1) full correlation and (2) complete independence. This approach does not clarify for which correlation such an average is valid, or how likely that correlation is to be the correct one. The risk methodology manual developed by the U.S. Bureau of Reclamation [
7] contains guidance for the length effect, proposed by the U.S. Army Corps of Engineers. Essentially they break up segments into ‘characteristic lengths’ which can be considered statistically independent. They do not specify how to estimate the characteristic length other than stating that it can be based on statistical analysis of spatial correlations, or via expert judgment.
In the Netherlands, a modified version of the standard outcrossing method is used to calculate the length effect, which we refer to in this paper as the modified outcrossing (MO) method. It is programmed into the flood defense reliability model Hydra-Ring (based on a previous model PC-Ring) [
8,
9] that is used in national flood risk studies [
10,
11,
12] and to support the assessment of flood defenses. Reliability calculations are often concerned with limit state functions, which are defined to be negative when geotechnical failure (such as piping or slope instability) occurs, and positive otherwise. The MO method approximates the limit state function as a one-dimensional Gaussian random field. This follows directly when first-order reliability method (FORM) is used at the cross section level, because FORM approximates the limit state function as a linear combination of Gaussian processes. However, it is not required to use FORM at the cross-section level; if, for example, Monte Carlo is used, the design point (the most probable set of variables leading to failure) can be estimated and used to approximate the limit state function as a linear combination of Gaussian processes. The MO method then uses the theory of outcrossing rates for Gaussian and ergodic random fields to determine the probability that the limit state becomes negative for at least one point along the levee segment. The MO method is similar to that of Vanmarcke [
2,
3], but is modified to handle the non-ergodicity of the limit state function. Information about the MO method can be found in [
8,
9,
13,
14], and we provide details in
Appendix A. Parallel research is looking into theoretical details of the MO method and its effect on design codes for flood defense systems [
15]. One of the issues we address in this paper is that although the MO method is an integral part of national flood risk analysis in the Netherlands, its accuracy has not been tested.
In this paper, we propose a method to compute the length effect by sampling from the (discretized) joint spatial distribution of the limit state function, using a copula approach. A similar approach has been proposed in other areas of engineering [
16], but has not been applied to levee reliability. We represent the joint distribution with a Bayesian network (BN), which allows us to visualize the correlation structure in the joint spatial distribution, and clarifies how the different parts of the reliability analysis fit together. Using the BN, we are able to update the joint distribution using observations. In this paper, we focus on updating the reliability estimate using survival observations. These are coupled observations of a (high) water level and survival of the levee, which we have in abundance. Researchers have looked at updating reliability estimates at a cross-section scale [
17]. In this paper, we expand upon this by using the BN to update the reliability of a (long) levee segment.
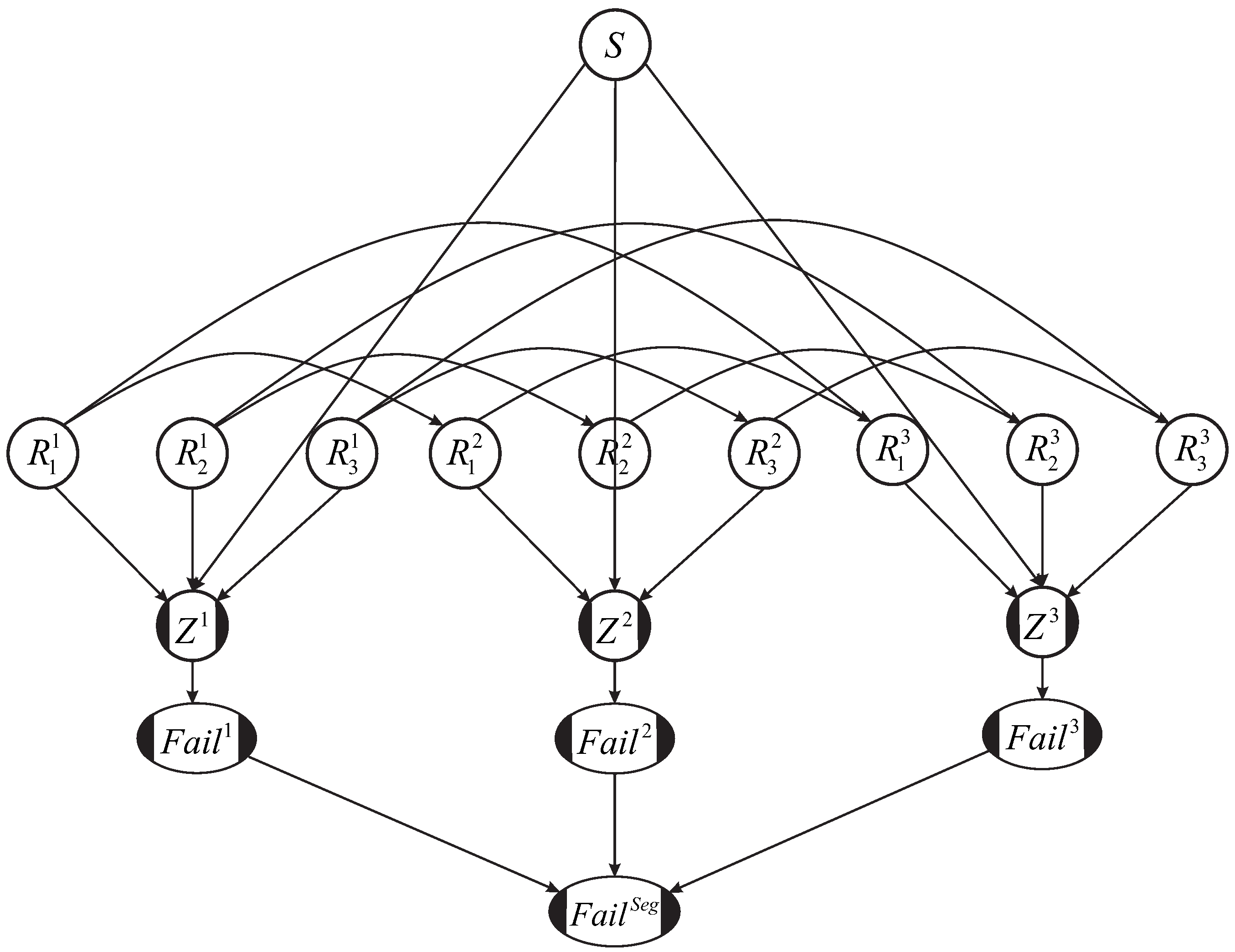
Traditional Bayesian networks, which work with inference algorithms designed for discrete distributions, become severely burdened computationally when the BN is densely connected (i.e., lots of correlations between variables). This is the case in levee reliability where the soil parameters are spatially correlated. When we slice up the levee into cross-sections (i.e., discretize the random field), the resistance variables in one cross section will be correlated with (connected to) the resistance variables in all other cross sections. Bensi et al. [
18] developed an approximate method to make discrete BNs tractable in these cases, but it remains difficult to know apriori how much error will be incurred for a particular application. Further, they require discrete conditional probability tables. In levee reliability applications, we generally have continuous marginal distributions of the random variables, where we are particularly interested in the tails of the distributions. The method we propose in this paper is particularly well-suited to levee reliability problems. It allows variables in the network to be described by continuous marginal distributions; correlations between variables are captured via autocorrelation coefficients. It assumes a Gaussian autocorrelation structure of resistance variables, but—in contrast to the MO method—does not approximate the limit state function as a Gaussian random field. Note that in general the limit state function is not a Gaussian random field because it is an (often non-linear) combination of resistance and load variables that are traditionally not Normally distributed (note that the terms “Normal” and “Gaussian” are used interchangeably throughout the paper).
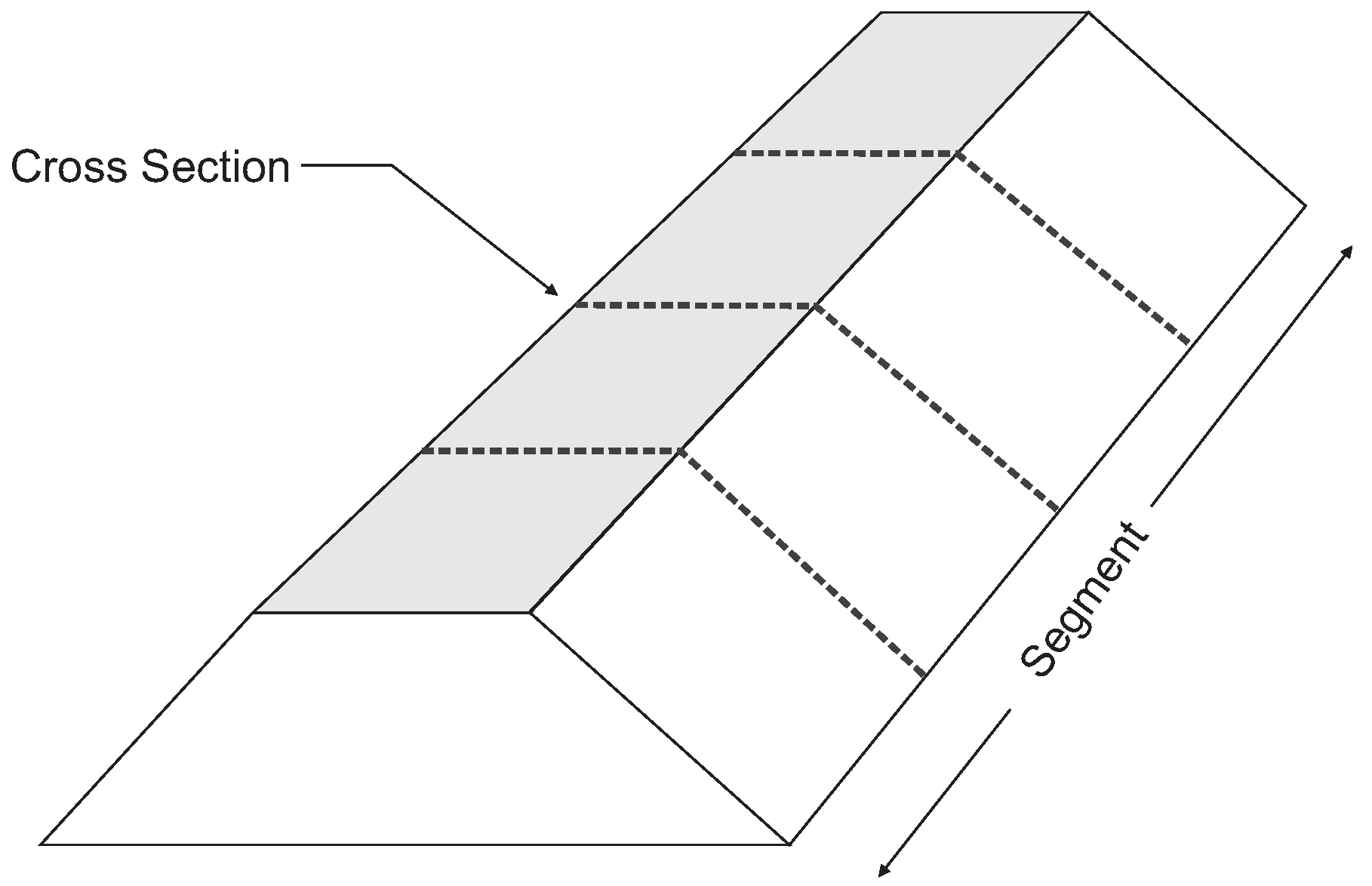
The spatial scales we consider in this paper are a cross section (typically in the order of meters) and a statistically homogeneous levee segment (order of kilometers).
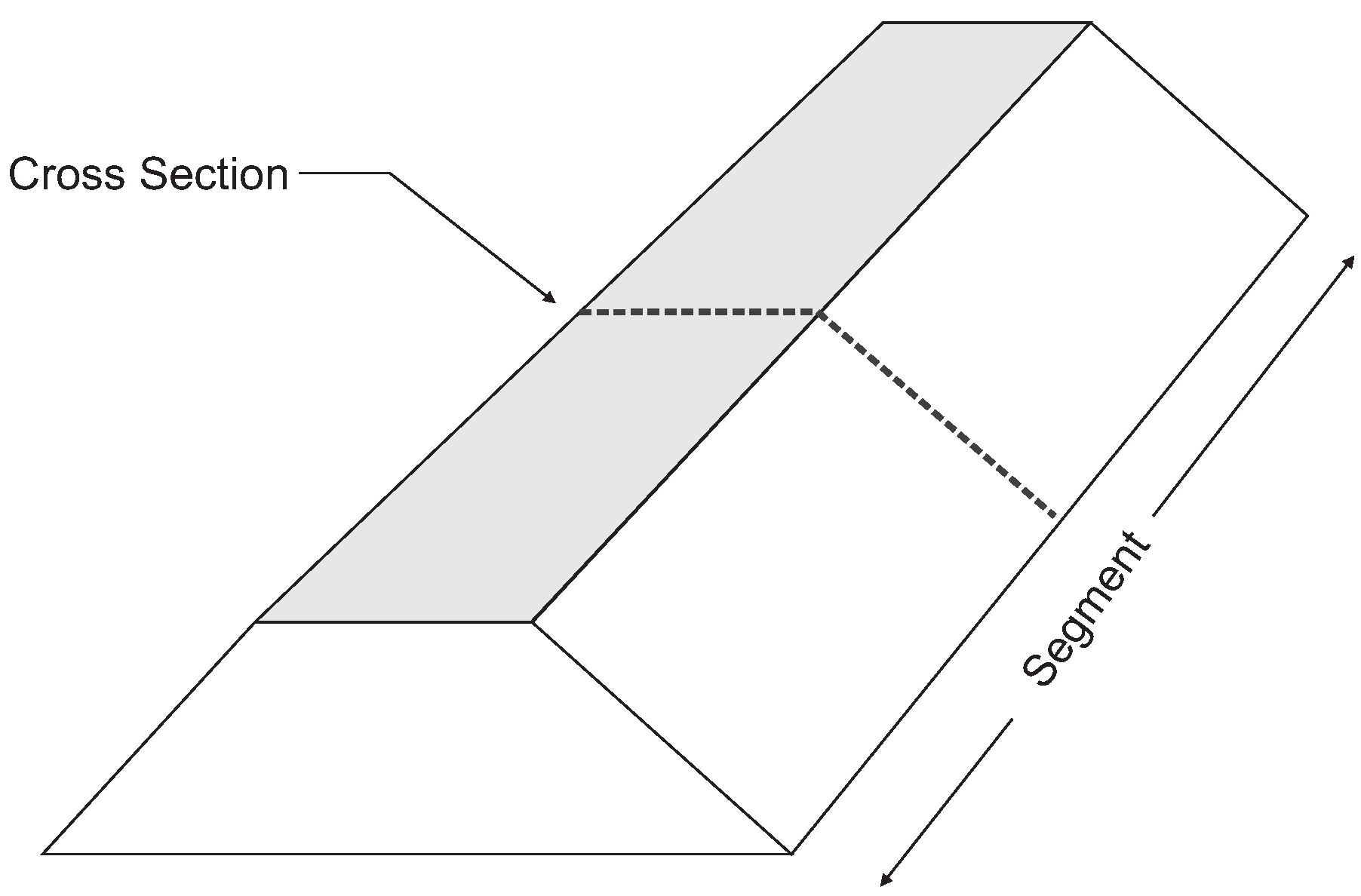
Figure 1 shows a schematic of a levee segment and a cross section. Computing levee reliability often relies on failure mechanism models, which calculate whether a particular failure mode—such as geotechnical stability or piping—will occur given specific soil properties and load conditions. The random variables in these models sometimes take into account some degree of spatial averaging over the vertical dimension of the levee (e.g., slope stability), but the reliability estimate is only valid for a relatively short length of the levee (i.e., a cross section). This is because the mechanism models generally look at point values of the soil parameters, while in reality these parameters are random fields over the length of the segment. Consider
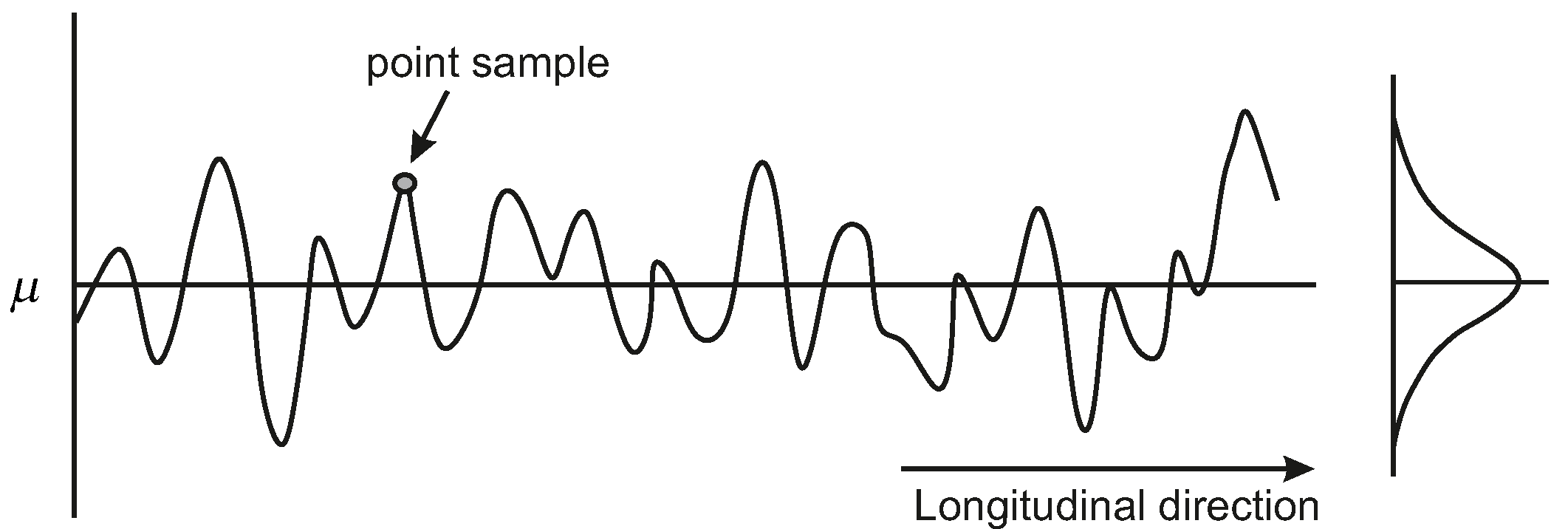
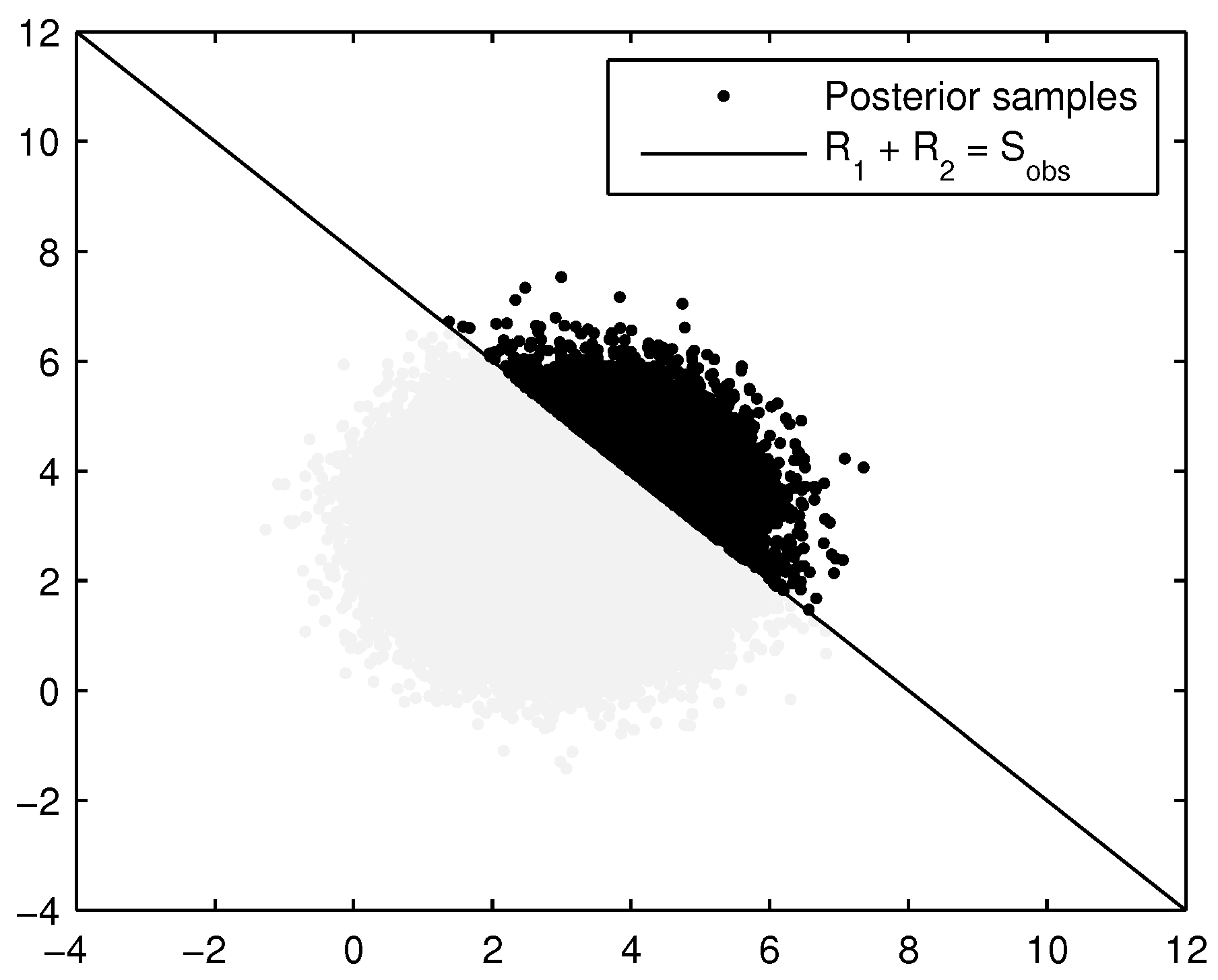
Figure 2; for a given point sample, there is the possibility of many other values of the soil parameter at other locations along the segment, even though they are all governed by the same probability distribution (see right side of
Figure 2). To estimate the failure probability of the segment, we need to account for the spatial variability of the soil parameters and the likelihood of finding a weak spot in the segment.
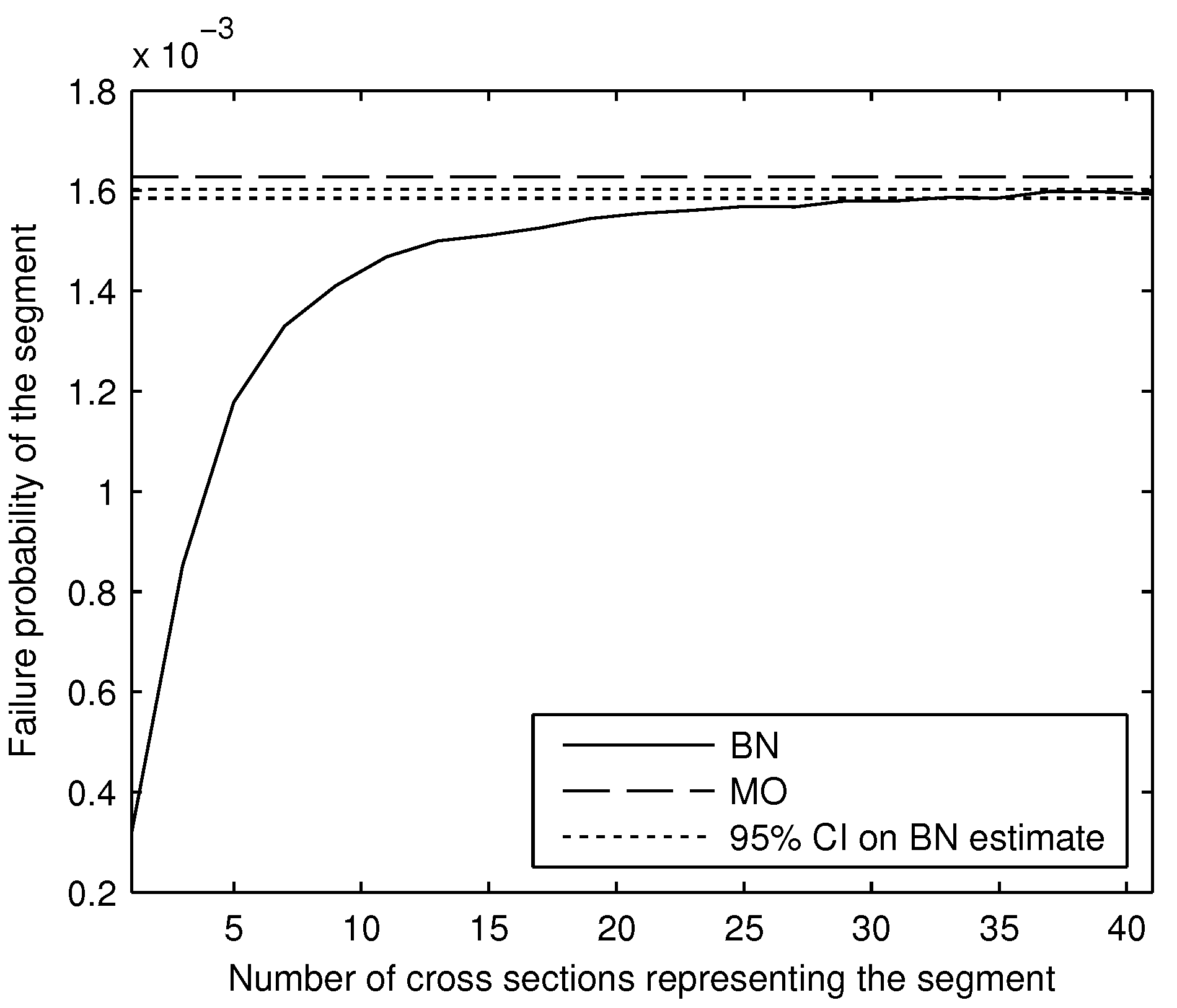
This paper has two main objectives: The first is to present the proposed BN method for computing the length effect in levee reliability, and the second is to use the BN method to address the accuracy/validity of the MO method, both with and without reliability updating using survival observations. The BN method is considered a more exact method (provided enough Monte Carlo samples are taken) because it does not require any assumptions about the distribution or correlation function of the limit state function (which the MO method does). We also devote attention to comparing the computational efficiency of the two methods, and exploring under which conditions survival observations are most informative.
Section 2 provides a brief background about the MO method (detailed information is provided in
Appendix A; in
Appendix B, we describe how we updated the segment failure probability—based on a survival observation—using the MO method).
Section 3 presents background about BNs, and introduces a new method for computing the reliability of a levee segment using a BN, as well as updating the reliability using a survival observation.
Section 4 presents a numerical example via which we compare the BN and MO methods, both prior to and following the incorporation of a survival observation.
Section 5 provides discussion about (1) the influence that the prior failure probability and the extremity of an observed load have on the impact of a survival observation, and (2) computational costs of both the BN and MO methods.
Section 6 presents general conclusions.
2. Modified Outcrossing Method
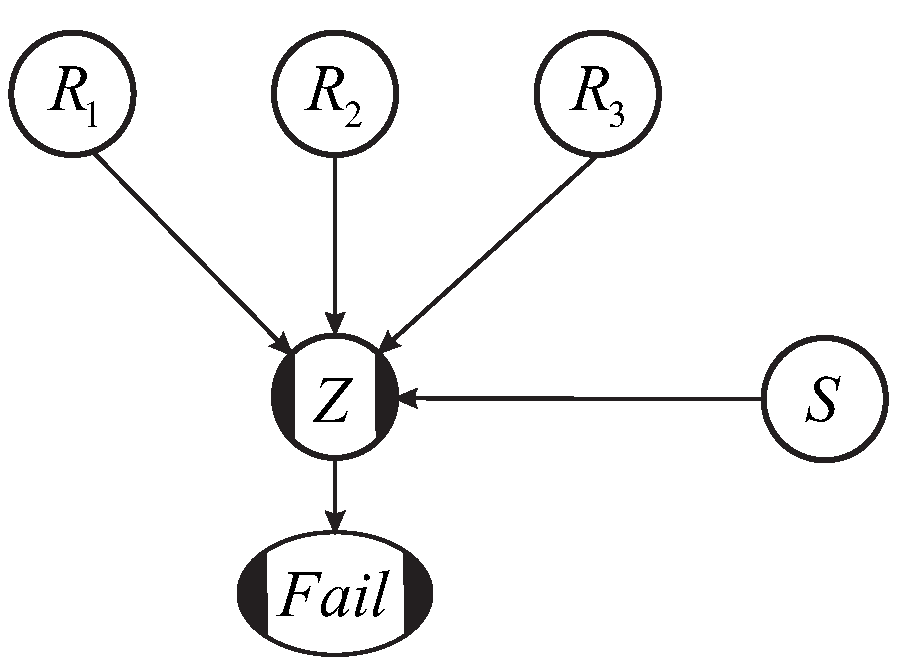
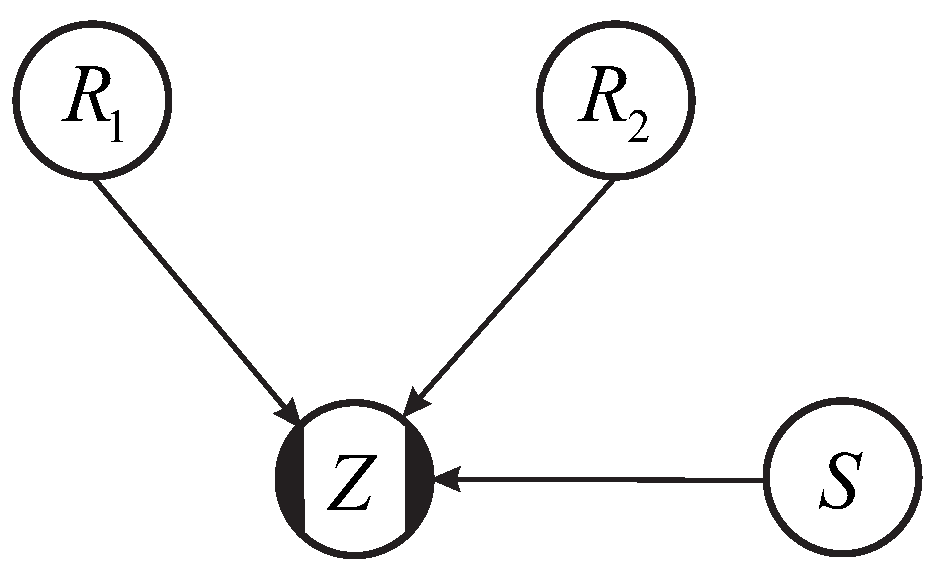
The modified outcrossing (MO) method to compute the failure probability of a homogeneous levee segment begins by computing the failure probability of a cross section,
. While not required, this cross-sectional failure probability is typically calculated using first order reliability method (FORM) because it returns influence coefficients of the random variables, which we will need (see below). The limit state function (
Z) depends on load and resistance variables (denoted later in the paper by
S and
R, respectively). In the MO method the loads and resistances are approximated as Gaussian processes, and the limit state as a linear combination of them (and thus itself also a Gaussian process). That is, the limit state function can be written as
, where
is the
i-th standard-Normally-distributed load or resistance variable, and
is its influence coefficient. The reliability index
is directly related to the failure probability:
, where
is the inverse standard Normal distribution.
Z can be written equivalently, but more compactly, in the form of Equation (
1), where
U is a standard Normally distributed variable. The spatial autocorrelation of
Z is modeled according to Equation (
2), where
is the longitudinal distance between two points,
is known as the correlation length, and dictates how quickly the correlation decreases in space, and
is the residual correlation at large distances. Note that in Equation (
2),
represents the non-ergodic part of the autocorrelation. Expressions for
and
, which depend on the autocorrelations and influence coefficients of the load and resistance variables, are available in the literature [
9,
13], and are provided in
Appendix A.
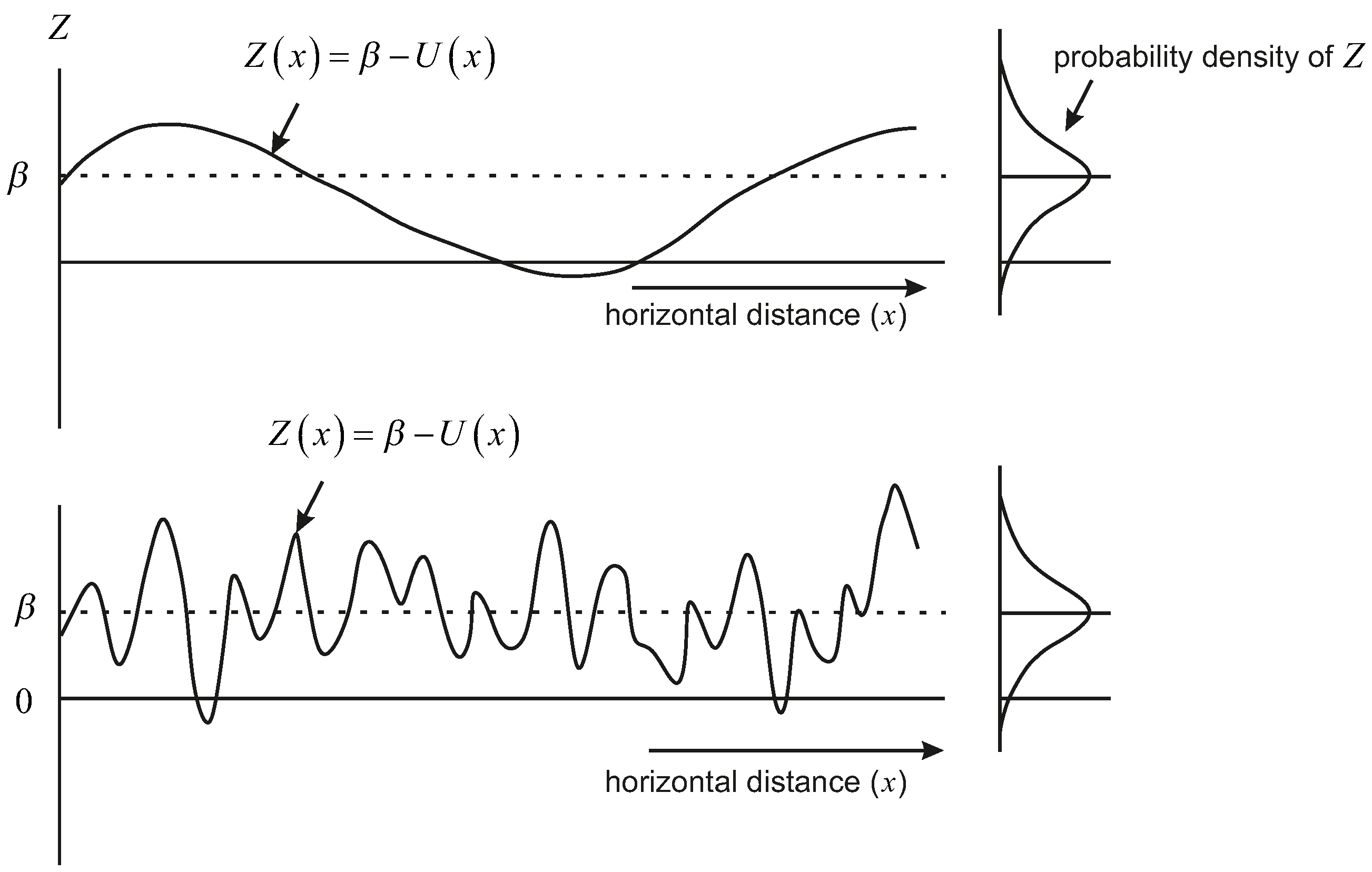
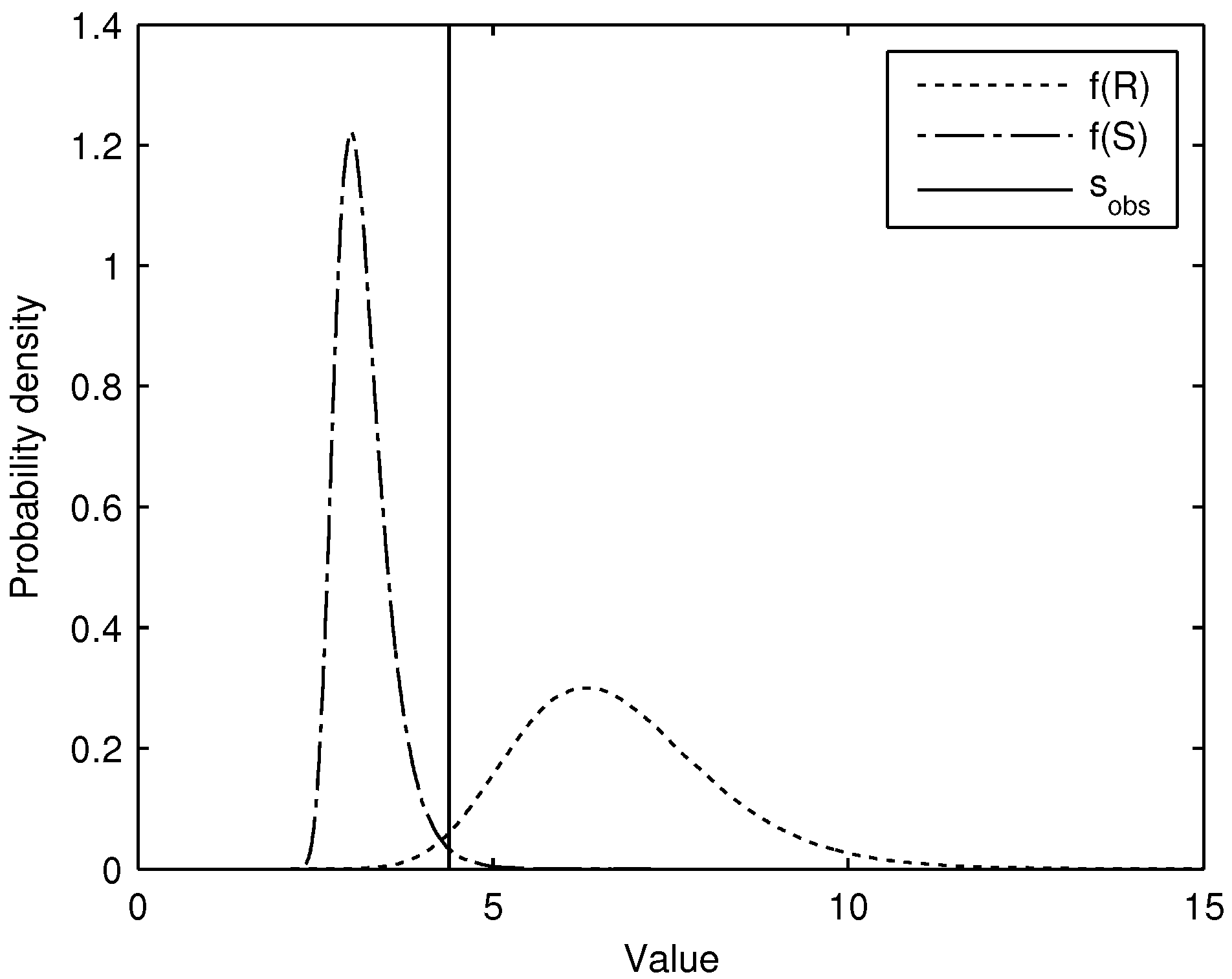
Figure 3 illustrates the limit state function
Z as a random field in one dimension (longitudinally). The probability of having a realization for which
increases as the length of the segment increases. The increase is dependent on both the length of the levee (
L), and how frequently
Z crosses 0. This latter quantity is referred to as an outcrossing rate, and is dependent on the spatial autocorrelation of
Z. For example, as seen in
Figure 3, a strongly-autocorrelated
Z function will change slowly in space, while a weakly-autocorrelated
Z function will show much more rapid change (allowing more opportunities for
Z to cross 0). The strength of the autocorrelation between two locations is dictated by the correlation length
in Equation (
2).
The outcrossing rate is calculated analytically based on theory for Gaussian ergodic random fields (see Van Marcke [
3]). However, the limit state function is not ergodic, due to the nearly fully-correlated nature of the load over a levee segment (other variables which are fully correlated over the length of the levee segment (such as model uncertainty) also contribute to the non-ergodicity of the limit state function). This is taken into account by calculating the segment failure probability conditional on the non-ergodic part of the limit state function, and then using the theorem of total probability to obtain the full segment failure probability.
Full details of the MO method are provided in
Appendix A.
Appendix B presents the details of how the MO method was applied in this paper when updating with survival observations (this has not been done in practice, and we were required to make some choices in our implementation for this paper).
In this paper, we are interested in verifying the MO method, which relies on the approximation of Z as a Gaussian random field. The marginal distribution of Z is modeled as a Normal distribution, and a Gaussian correlation structure is assumed. In general, the limit state function is not a Gaussian random field, because it is an (often) nonlinear combination of variables which are not necessarily Normally distributed. It is unclear how well the approximation works, both prior to and following incorporation of a survival observation. In the next section we describe a method to compute the failure probability of a levee segment in which the (discretized) spatial joint distribution of the resistance variables—and the limit state function—is represented by a BN, and sampled using a copula approach. Because the BN method does not require the limit state function to be approximated by a Gaussian random field, we can use the failure probability estimates from the BN to evaluate the accuracy of the prior and posterior failure probabilities computed by the MO method.
6. Conclusions
We have presented in this paper a method to calculate the length effect in levees by sampling the joint spatial distribution of the limit state function, represented by a BN, without having to approximate a parametric form of the spatial distribution. Using Monte Carlo rejection sampling for inference, the method can update failure probabilities of (long) levees using survival observations (e.g., high water levels and no levee failure). We compared results with the modified outcrossing (MO) method, currently in use in reliability modeling of flood defenses in the Netherlands, via a numerical example, for verification purposes. The primary difference between the two methods is that the BN method samples from the joint spatial distribution, whereas the MO method uses an approximative parametric form of the spatial distribution of the limit state, and solves the problem analytically.
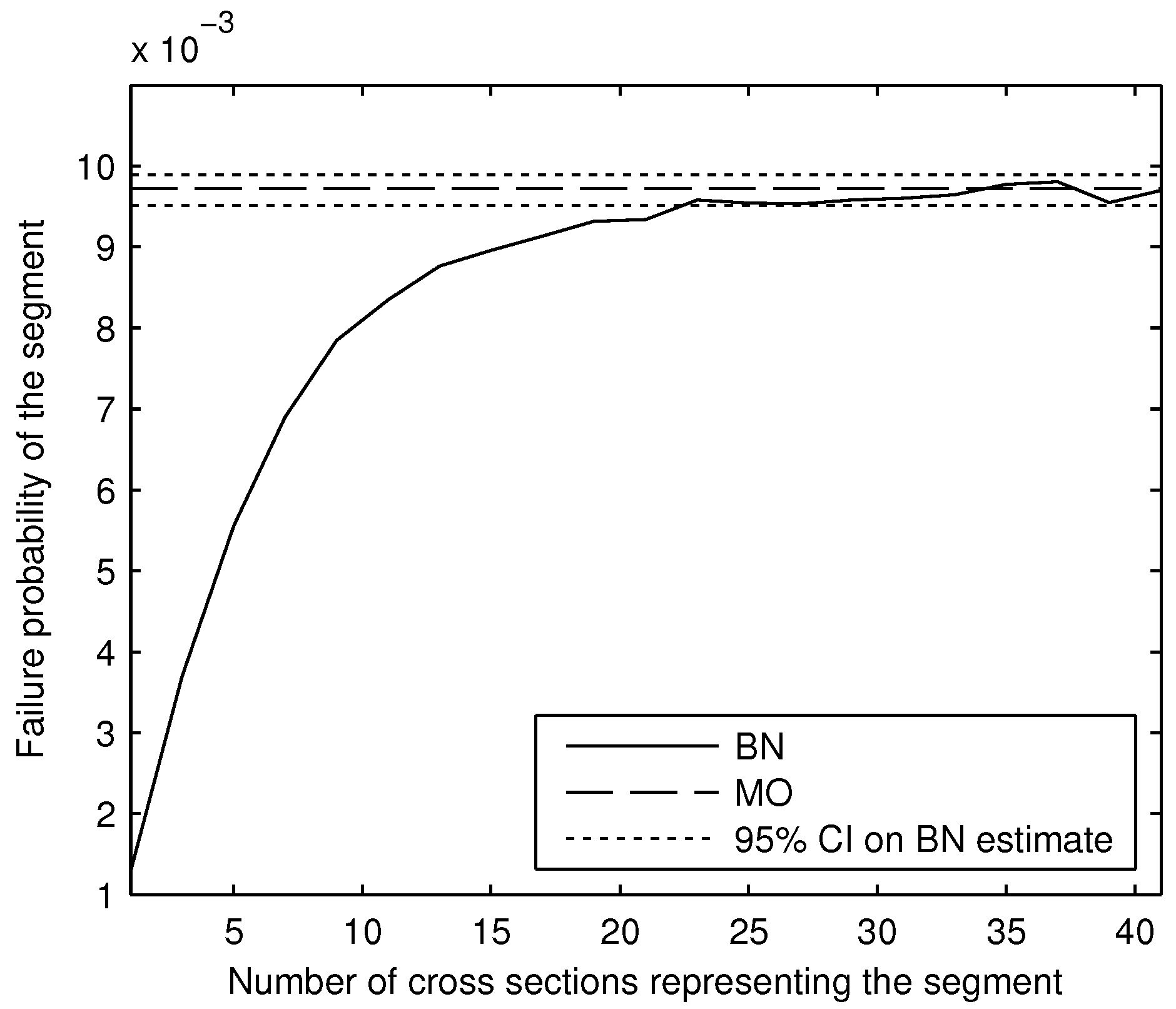
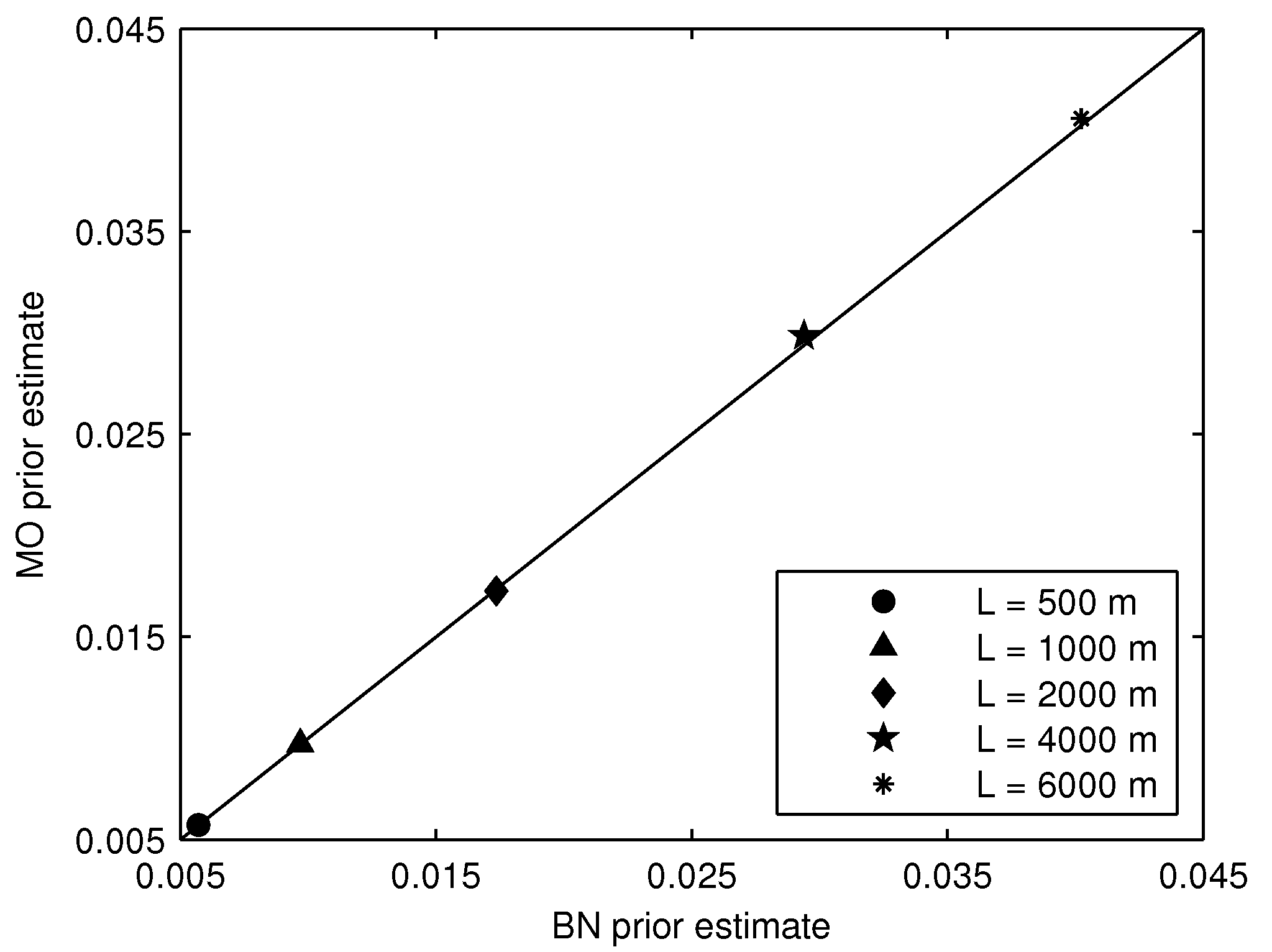
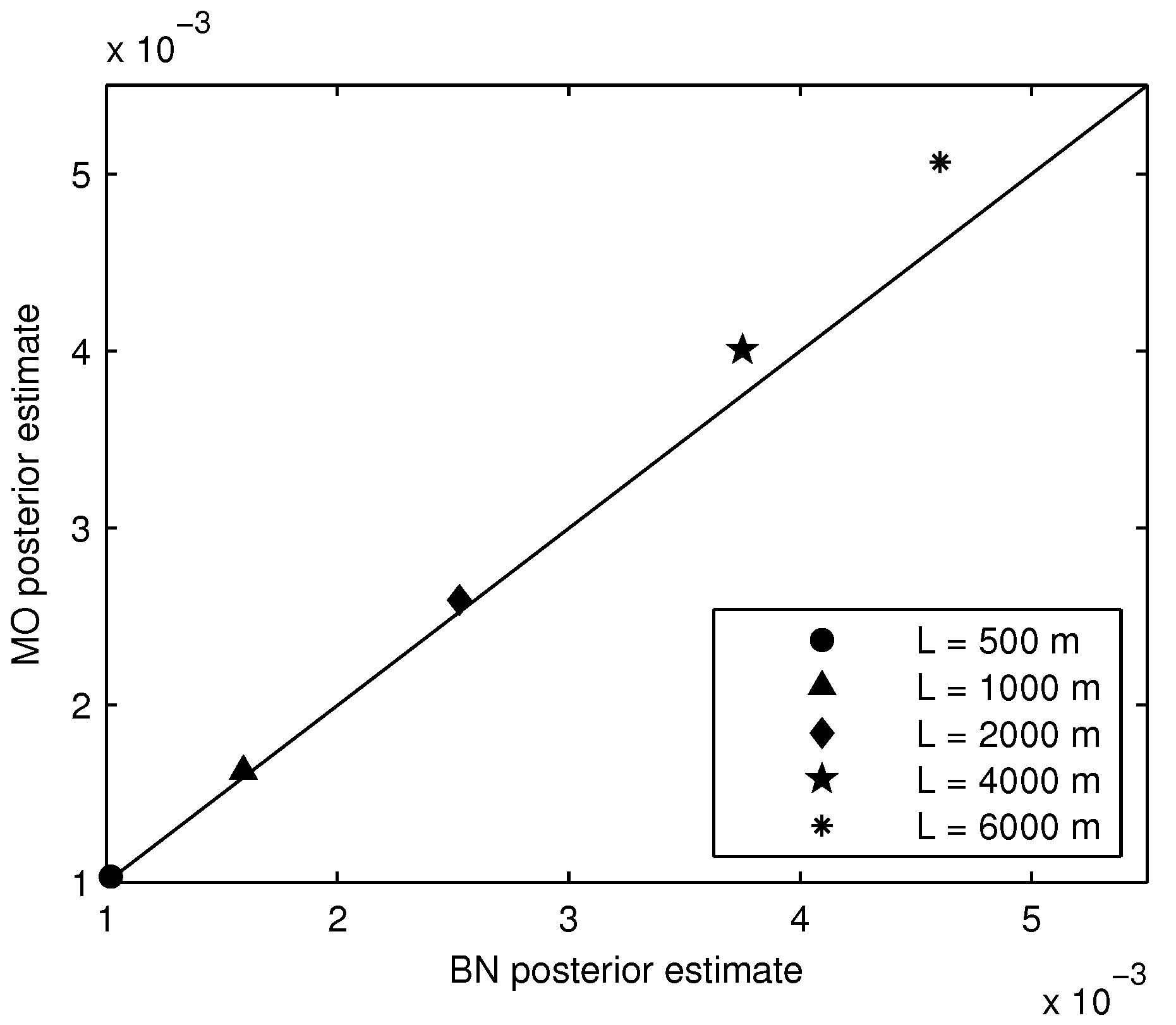
The prior and posterior segment failure probabilities calculated by the two methods are in strong agreement. Slight discrepancies were found for posterior segment failure probabilities for long segments (4000 and 6000 m), but these differences were less than 10%, and in terms of reliability index, less than 1%. These results provide a strong verification of the MO method for prior analysis, which is used in the levee reliability model Hydra-Ring. They also provide an important verification of the MO method for posterior analysis, which has a lot of potential. The speed of the MO method makes it possible to efficiently update failure probabilities of numerous levee segments with abundant survival observations.
Given the strong agreement between BN and MO results, and the relative efficiency of the MO method, we advocate use of the latter in practice. However, we must emphasize that the examples considered in this paper do not represent an exhaustive set of cases. For failure probability updating with survival observations, we advocate comparing the BN and MO output for each new type of application (e.g., new limit state function, new set of variable distribution types or correlation parameters). Once the results are verified, the MO method can be used with confidence for all examples of the same type.
Finally, we strongly advocate the use of either the BN or MO method to account for the length effect in reliability analysis over some of the more simplified approaches found in the literature.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}