1. Introduction
In fire safety engineering, risks for occupants are of high concern and continuously investigated in risk analyses. In a risk analysis, risks are quantified with the consequences and frequencies of many scenarios subjected to uncertainty [
1] (pp. 1, 5) with the frequency and the consequences of many scenarios with random parameter settings [
1] (pp. 1, 5). Risks can be expressed as the individual risk, namely the ‘measure of fire risk limited to consequences experienced by an individual and based on the individual’s pattern of life’ and the societal risk as a ‘measure of fire risk combining consequences experienced by every affected individual’, often represented with a risk curve [
2] (p. 3f).
The risk-related research in fire safety engineering comprises diverse methodologies for the analysis of consequences in many scenarios. In the methodology proposed by Albrecht [
3] with reference to Albrecht and Hosser [
4], life safety in a community assembly building was quantified with the probability for safe evacuation. De Sanctis et al. [
5] expressed the Live Quality Index based consequences of small fires in single family houses based on statistical data, and the consequences of large fires were considered with a probabilistic decision analytical approach. The methodology published by De Sanctis and Fontana [
6] was applied on the risk- and Life Quality Index-based optimisation of the widths of doors in a retail building. Van Weyenberge et al. [
7] analysed the risks for humans in assembly compartments with reference to Van Weyenberge et al. [
8]. Di Nardo et al. [
9] used system dynamics to include time-dependent variables for the qualitative and quantitative analysis of risks caused by LPG cylinders in houses. Coping with more complex structures, Schröder [
10] evaluated the safe evacuation of underground metro stations in many different scenarios. Anderson and Ezekoye [
11] carried out an analysis of the community-averaged extent of damages caused by fires in residential buildings of the United States and Yamamoto et al. [
12] investigated the fire safety of road tunnel users. In particular, the risks of road tunnel users have been widely under research, e.g., by Schubert et al. [
13], and culminated in several European methodologies for risk analysis, such as for Germany [
14] and Austria [
15].
Whereas De Sanctis et al. [
5] and Schubert et al. [
13] applied probabilistic and empirical models to compute the consequences of fire and evacuation scenarios, the other methodologies combined a fire model and an evacuation model. The fire models are mostly computational fluid dynamics models [
3,
7,
10,
12,
14,
15] and the evacuation models are most often one-dimensional models [
3,
6,
7,
14,
15], except for Yamamoto et al. [
12], who used a cellular automaton and Schröder [
10], who employed a microscopic evacuation model. Thus, in several methodologies, complex models were used, causing high computational costs to evaluate the consequences for occupants in evacuation scenarios under the effects of smoke spread from fire scenarios.
Because of the high computational costs of complex models, several authors apply metamodels to determine consequences, for example Albrecht and Hosser [
4], De Sanctis and Fontana [
6], Van Weyenberge et al. [
7] and ILF Consulting Engineers [
15], together with a zone model. A metamodel comprises three integral parts, summarised in Queipo et al. [
16] (p. 3): the experimental design, the database and the response surface model (RSM). The experimental design specifies the parameters of discrete scenarios to be computed with the complex model. The result of interest of these simulations is most often a measure of the consequences in the scenarios. The database comprises these results for all data points of the experimental design. From these results of the database, the RSM approximates the result for any random scenario represented by a point on the domain of the variables. Thus, the RSM simplifies the complex model and, therefore, is quick in the determination of results but causes ‘metamodel uncertainties’ [
17] (p. 9). Since the ‘inaccuracy of the metamodels can be interpreted as the metamodel uncertainty where the true response is unknown except at the sample points’ [
18] (p. 1) and since adding additional data points could reduce the ‘inaccuracy’, the metamodel uncertainty can, in our case, mostly be characterised as an ‘epistemic uncertainty’ also acknowledging minor ‘aleatory uncertainties’ [
19]. Summing up, the metamodel has low computational costs and, for this reason, can be helpful with regard to the global objective of the risk analysis. Namely, the global objective is directed at the consequences of many random scenarios on the entire domain of the variables.
A scenario is typically specified with ‘control variables’ [
20] (p. 15), briefly named variables, such as the maximum heat release rate (HRR) or the number of occupants. Next to these variables, ‘environmental variables’ [
20] (p. 15) cause an ‘intrinsic’ randomness [
21,
22,
23] in the fire and the evacuation scenario, for example in the gas turbulence or the individual characteristics of the occupants. Whereas the environmental variables are, in common practice, of minor concern in the fire scenarios, they have a large effect in the evacuation scenarios. For this reason, they are considered in the evacuation models of several methodologies [
4,
6,
7,
15]. Thus, the stochastic result of the evacuation scenario is subjected to an uncertainty, named the inherent uncertainty. Obviously, the inherent uncertainty can be reduced by a detailed modelling of, for example, the individual characteristics and for this reason it is also ‘epistemic’ [
19]. However, since this precise description is uncommon in evacuation modelling, the inherent uncertainty is treated as mainly an ‘aleatory uncertainty’ with the ‘intrinsic randomness of a phenomenon’ [
19]. Hence, replications of one scenario lead to an observed random sample (ORS) of the results, which represents the true but unknown inherent uncertainty of the evacuation model. A general approach in evacuation modelling exemplified by Ronchi et al. [
22] is to run several replications of a specific evacuation scenario and then evaluate the ORS characterised by the two discrete measures, mean and deviation.
Besides fire safety engineering, several publications, such as Marrel et al. [
24] and Moutoussamy et al. [
25], address metamodels for the stochastic simulation results of complex models. Marrel et al. [
24] describe a joint metamodel for the mean and the dispersion of stochastic model results without replications. This metamodel is based on a Gaussian process model with additional nugget effects to not directly interpolate to the data points. The nugget effect is different for each data point, which allows to consider spatially different dispersions. The dispersion is modelled with a multidimensional differential exponential function. Moutoussamy et al. [
25] present a metamodel to directly determine the probability density functions of the results of the complex model at any arbitrary point. Their method relies on replications at the data points and does not require the assumption of a specific distribution type. They first discuss the classical kernel regression, where all data points are considered with a weight depending on the distance to the arbitrary point. Next, they propose a metamodel based on functional decomposition, which is similar to kernel regression but the results are derived from a reduced database. The problem that the model of the probability density function also produces negative values is coped with adapted methods, such as the alternate quadratic minimisation.
Although several methodologies in fire safety engineering using metamodels analyse the metamodel uncertainty, e.g., Albrecht [
3], Van Weyenberge et al. [
8], or consider environmental variables, e.g., Albrecht [
3], De Sanctis and Fontana [
6], and LF Consulting Engineers [
15], neither the metamodel uncertainty nor the inherent uncertainty have been transferred to the results of the metamodel. At least, Van Weyenberge et al. [
7] discuss the integration of the inherent uncertainty. However, the authors of the present publication think that it is important to take into account the metamodel uncertainty and the inherent uncertainty in the final result of the metamodel to represent the result of the complex model at an arbitrary point.
For this reason, a metamodel for fire safety engineering is presented, which includes both uncertainties, and it is used in an exemplary case study for a fire risk analysis of a road tunnel. This metamodel is based on the results of a computational fluid dynamics model and a microscopic evacuation model. It considers temporal aspects within the scenarios and has therewith another focus as the approach of Di Nardo et al. [
9], who model the evolution of risks. However, the metamodel can be also used within their approach. Despite the available approaches for stochastic results, such as those of Marrel et al. [
24] or Moutoussamy et al. [
25], the RSM is based on the deterministic results of the complex model, namely the mean of each ORS, and also produces deterministic results. One reason for this deterministic RSM is to allow to separate the deterministic result of the RSM from the inherent uncertainty at any arbitrary point in order to comply with the general approach for evacuation scenarios [
22], that is, characterising the ORS by its mean and deviation. Regarding the inherent uncertainty in the results of the complex model, the authors propose an original approach called the sampled uncertainty approach. This approach is suitable for the requirements of the microscopic evacuation models, namely, a limited number of replications and different unspecific frequency distributions in the ORSs. In conclusion, our metamodel, which includes the metamodel uncertainty and the inherent uncertainty, is different from the other metamodels in fire safety engineering outlined above and, for this reason, can contribute to the scientific basis.
2. Materials and Methods
Basically, the metamodel consists of the three parts of RSM, metamodel uncertainty and inherent uncertainty. The symbols used to describe these three parts are shown in
Table 1. Firstly, the RSM is based on the projection array-based design method of Loeppky et al. [
26] for the experimental design and on the moving least squares method by Lancaster and Salkauskas [
27], both further detailed in
Section 2.1 and
Section 2.2.1. The experimental design establishes the database of data points simulated with the complex model. Secondly, the metamodel uncertainty is the mainly epistemic uncertainty of the RSM and is determined with the prediction interval method by Kim and Choi [
18] outlined in
Section 2.2.2. Thirdly, the original sampled uncertainty approach is used to reproduce the ORS as described in
Section 2.3.
To sum up, the result of the metamodel
at a point
(or
for multiple points) in Equation (
1) combines the result of the RSM
, the metamodel uncertainty
and the relative inherent uncertainty
.
It therewith should reproduce the result of the complex model. The result of the metamodel only considering the metamodel uncertainty and not the inherent uncertainty is denoted with , and vice versa, it is denoted with .
The metamodel is used for a risk analysis in a case study described in
Section 3.1. The risk analysis requires the results of a high number of different points. These points are drawn in a Monte-Carlo simulation and their results are determined with the metamodel. The metamodel, therefore, uses the database earlier simulated with the complex model.
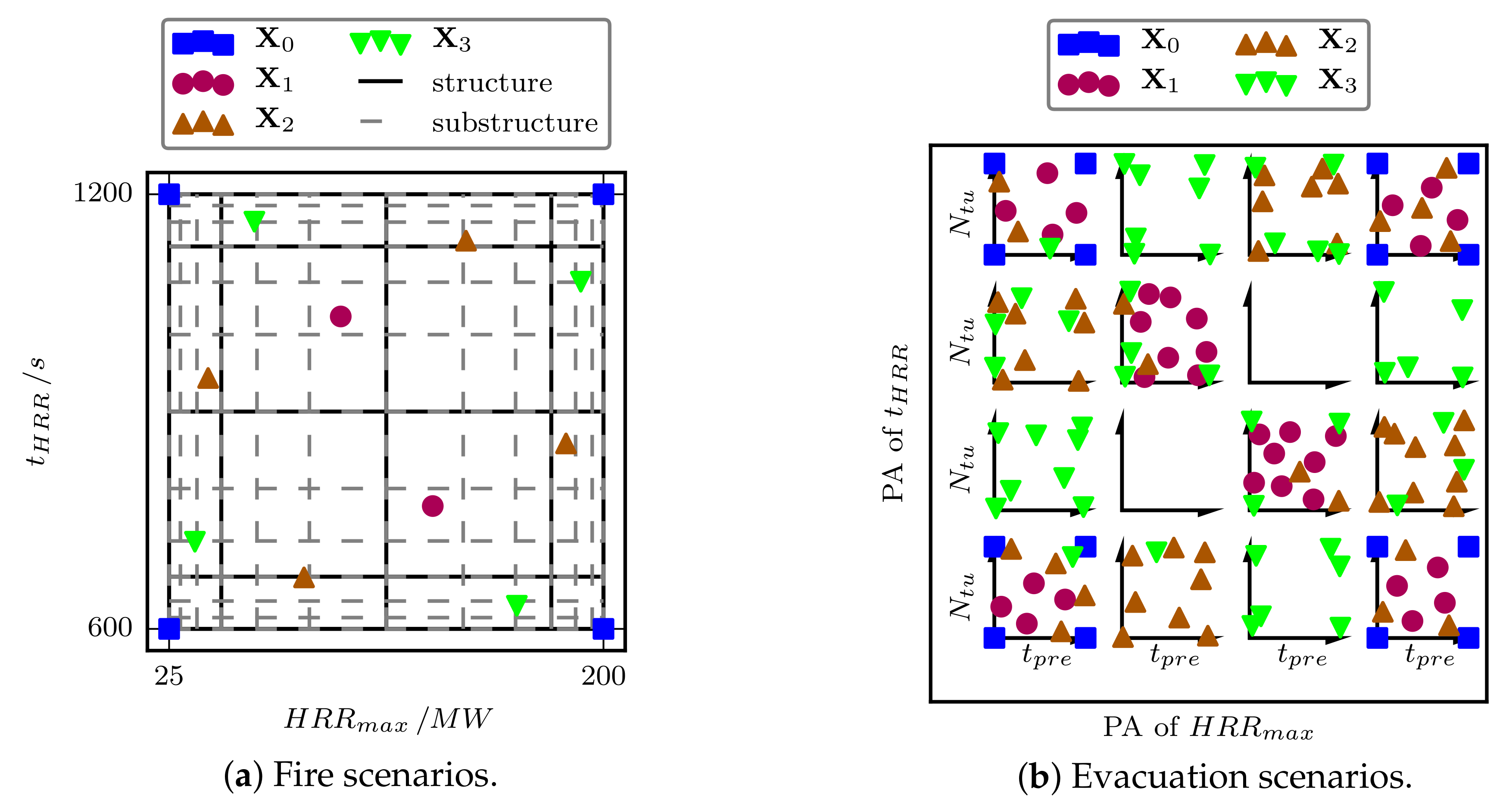
2.1. Experimental Design
Due to the global objective of the risk analysis, the results have to be computed on the entire domain of the variables. According to Santner et al. [
20] (p. 124), ‘computer experiments’ often share the same global objective; hence, their ‘space-filling’ experimental design should ‘spread the [data] points at which we observe the response evenly throughout the region’. Latin hypercube designs [
28] meet this requirement and are, therefore, commonly used in computer experiments [
20] (p. 125), for example by Van Weyenberge et al. [
7].
The projection array-based design method by Loeppky et al. [
26] extends the Latin hypercube design in order to further improve its space-filling properties. In detail, the projection array-based design is based on the substructure consisting of substrata from Latin hypercube designs as well as on an additional structure of projection arrays formed by strata, which are, for example, rectangles in a two-dimensional case. Each projection array in a projection array-based design may contain at maximum one data point, and each substrata of a variable contains exactly one data point, following Latin hypercube designs. Loeppky et al. [
26] further present a sequential refinement for the projection array-based design, in other words adding subsequently new data points to an existing experimental design.
The projection array-based design method is employed here because of its space-filling properties and its sequential refinement. During its setup, data points are added randomly to the available strata and projection arrays. To improve the space-filling properties, each projection array-based design is chosen from a large set of different designs with regard to a maximin and minimax optimisation.
2.2. Response Surface Model and Metamodel Uncertainty
The methodologies of Anderson and Ezekoye [
11] and Bundesanstalt für Straßenwesen (BASt) [
14] use event trees for the risk analysis and, therefore, directly use discrete scenarios simulated with the complex model for the single events. This approach corresponds to a ‘nearest neighbour interpolation (NNI)’, which virtually adopts the result for an arbitrary point directly from the data point of a discrete scenario with the smallest Euclidean distance. Several computer codes are readily available to realise the NNI method.
2.2.1. Moving Least Squares
The methodologies of Albrecht [
3] and Van Weyenberge et al. [
7] employ the moving least squares method (MLS) [
27] for their RSMs. MLS conducts a local weighted least squares regression of a linear or quadratic polynomial at a point
. It therefore extends the global least squares regression by weighting the data points as shown in Equation (
2) [
29] (p. 18ff).
Here, are the approximation errors, are the regression coefficients and are the deterministic results, i.e., the means of the ORSs, of the complex model at the data points of the experimental design with data points .
The local weighting matrix
is a diagonal matrix which weights the data points depending on their Euclidean distance to the point
with a weighting function. The least squares estimators
of the regression coefficients can be calculated with Equation (
3).
Consequently, the local least squares estimators are only valid for one point, and Equation (
4) leads to a local result
.
Three weighing functions are adopted from Kim and Choi [
18] (Equation (4a)) as well as Most and Bucher [
30] (Equations (12) and (16)). The weighting function and its weighting parameter are calibrated with a straightforward algorithm to fit to the results of the data points. This algorithm reduces the prediction variance determined at arbitrary points on the entire domain, similar to Kim and Choi [
18] (p. 4), who use the prediction variance for the ‘design optimisation’.
The results
of Equation (
4) for every point are deterministic if the probabilistic properties of the regression coefficients are neglected. The regression causes residuals, namely the difference between the result of a data point and the approximated result of the RSM.
2.2.2. Metamodel Uncertainty
Kim and Choi [
18] introduce a method to calculate the metamodel uncertainty of MLS in the following, called the prediction interval method. In detail, the metamodel uncertainty
is the difference between the result of the RSM and the unknown result of the complex model
. It is normally distributed with a mean of zero and the variance
.
The prediction interval
is defined with Equation (
5).
It depends on the Student distribution with the statistic
for the two-sided confidence level
and the degree of freedom
, where
is the number of terms in the regression model. Further, the prediction variance
is given in Equation (
6) [
18] (Equation (21)) for the variance of the metamodel uncertainty
.
The prediction variance depends on the variance estimator
in Equation (
7), also known as the leave-one-out cross-validation error, where
denotes the result of the RSM at the data point
with a database excluding this specific data point.
The metamodel uncertainty is derived from the prediction interval method with Equation (
8), where
is a random number subjected to the Student distribution.
In conclusion, the metamodel uncertainty
is a random value for a single point. The metamodel uncertainty is integrated into the metamodel with Equation (
1), similar to Nannapaneni and Mahadevan [
17] (Equation (
7)) and Kim and Choi [
18] (Equation (25)).
2.3. Inherent Uncertainty
Salemi et al. [
31] present a metamodel, using MLS with a database that comprises a high number of data points with many replications. The variance at a point is quantified with the equally weighted averaged variance of the ORSs at its neighbours, meaning the spatially close data points. In their approach to quantify the aleatory uncertainty, it is clearly distinguished between the deterministic results of the ORSs, i.e., their mean, for the RSM and the variances of the ORSs. In this respect, their approach differs to other approaches, such as that of Moutoussamy et al. [
25], but it suits the general approach for evacuation scenarios exemplified by Ronchi et al. [
22].
However, evacuation scenarios are often analysed only in a limited number of data points
and replications
. For this reason the databases common for evacuation scenarios differ clearly to the database used by Salemi et al. [
31]. Furthermore, the ORSs of evacuation scenarios often have a variety of different, unspecific frequency distributions unequal to normal or lognormal distributions. For this reason, the approach of Salemi et al. [
31] or Gaussian processes [
24] are less suitable for the databases of microscopic evacuation models. Hence, the authors introduce an original approach, called the ‘sampled uncertainty approach’, to determine the inherent uncertainty.
The sampled uncertainty approach comprises three principal steps to derive the inherent uncertainty at a point
. To begin, each ORS
in the database is divided by its mean to get the relative ORS
. Next, the relative ORSs of all
neighbours of the point
are merged in the combined relative sample
. This combined relative sample is specific for each point. It contains
replications and has the local discrete distribution
in Equation (
9).
Here,
is the uniform distribution of the ORS
in which each replication is subjected to the probability
. Additionally, each of these uniform distributions is weighted with a combination factor
that sums up to
over all
neighbours and is
for the other data points. The number of neighbours, therefore, defines the region around an point where the ORSs are considered. At last, the relative inherent uncertainty
is directly drawn in Equation (
10) from the combined relative sample.
The combined relative sample should correspond to the true ORS of the complex model at a specific point
. Notably, this ORS is unknown since the results were not simulated. Obviously, the required combination factors are unknown; hence, three basic modes for the combination are discussed. Firstly, the combined relative sample can contain only the closest ORS with
and
. This mode leads to a discontinuous transition in the centre between two data points, which is not reasonable. Next,
ORSs can be weighted with equal combination factors
such as in the approach of Salemi et al. [
31]. However, this uniform combination does not represent the true ORS if the point
is equal to a data point. So third, in the linear combination,
data points are linearly weighted with the weights
depending on their Euclidean distance
d to the point
. Since the combined relative sample should represent the true ORS directly at a data point, it further yields
. For this reason, the initial parameter
has to be adapted for each point
as a consequence of
, e.g., a point
equal to a data point leads to the adapted number of neighbours
. In conclusion, the linear combination represents the true ORS at a point
with regard to the following: firstly, no discontinuous transitions in the results for the inherent uncertainty; secondly, the unbiased combination of ORSs in the case of equal Euclidean distances between two neighbouring data points; and thirdly, the direct adoption of an ORS at a data point. In this respect, its results are most realistic among the three basic modes and is based only on the little available information of the ORSs.
A relative ORS may lead to unrealistic results of the inherent uncertainty if its mean results are close to zero. Hence, a limit for the mean results of ORSs is defined with regard to the evacuation scenarios but can be different in the case of other applications. This limit prevents unrealistically high results in the metamodel because each relative ORS with is manipulated to and arbitrary points linked to these ORSs always result in the relative inherent uncertainty .
In conclusion, the sampled uncertainty approach is suitable for a limited number of data points and replications and, therefore, meets the requirements of microscopic evacuation models. It derives the inherent uncertainty from the neighbours and separates the inherent uncertainty from the deterministic results of the RSM, and therewith it is similar to the approach of Salemi et al. [
31]. However, there are also clear differences because the ORSs are directly used without the quantification of additional parameters for the variance or the fitting of a specific distribution type to the ORSs. Moreover, the sampled uncertainty approach flexibly adapts to the variety of different frequency distributions of the ORS.
4. Conclusions
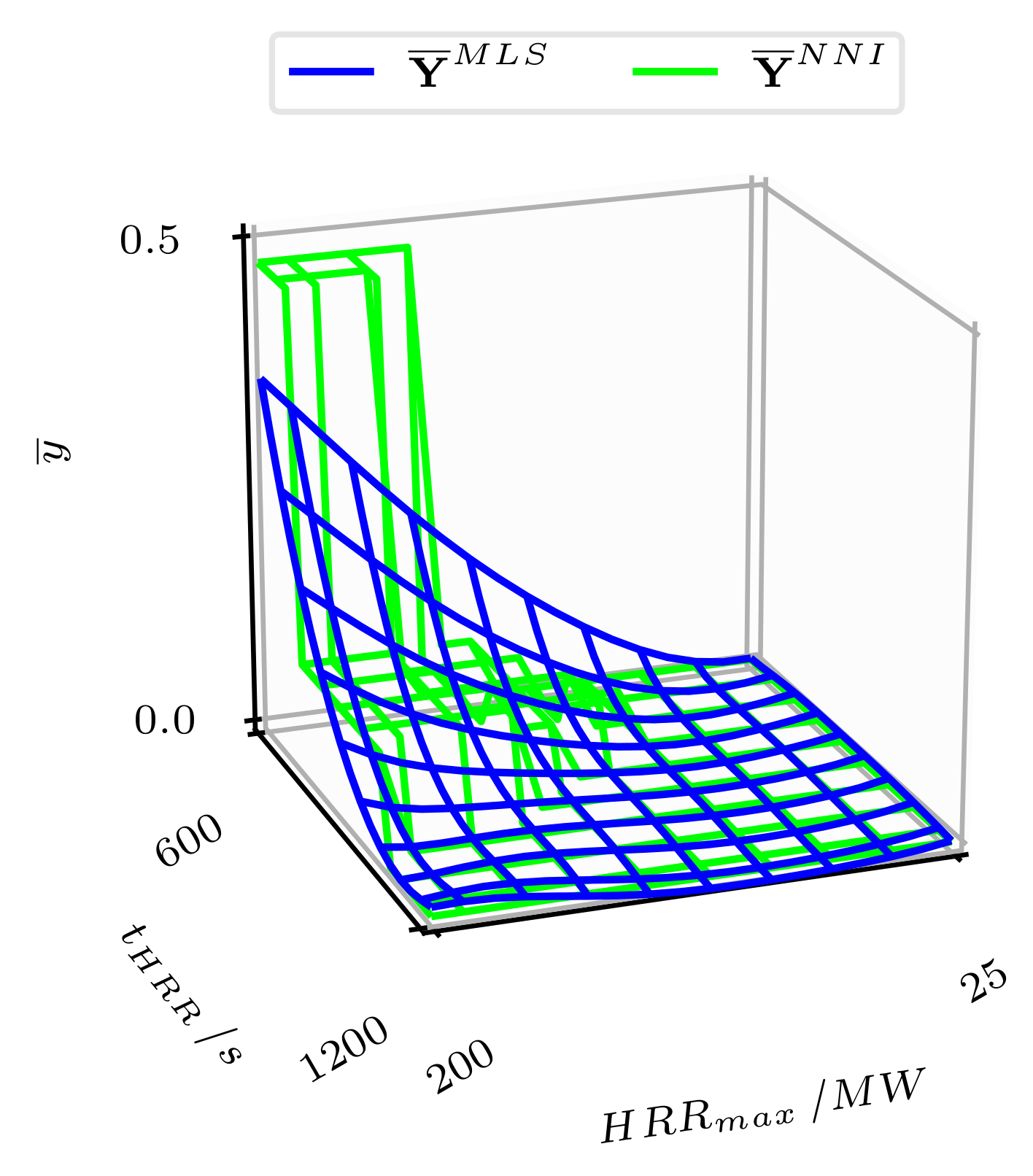
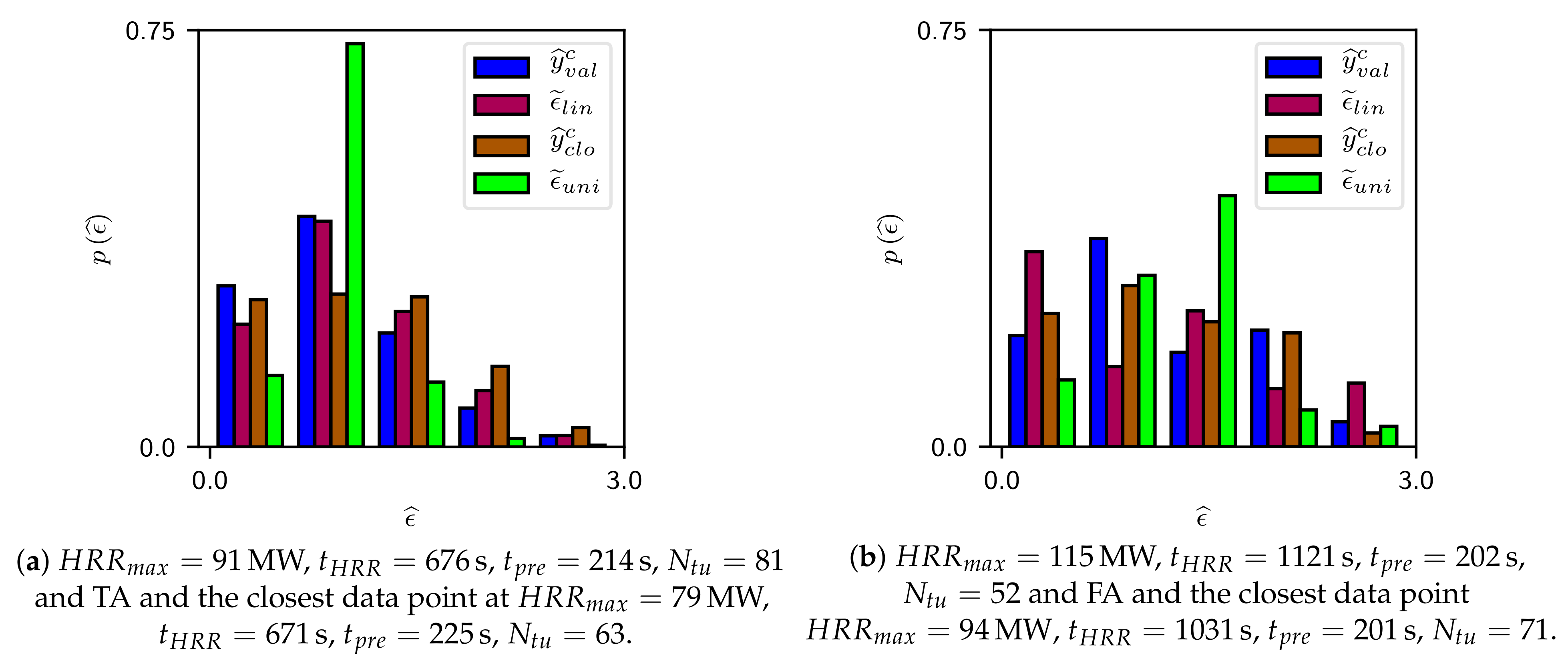
In this publication, a metamodel on the basis of complex simulation models was developed, validated and applied for a risk analysis of a road tunnel. The metamodel consists of three parts: the response surface model based on the projection array-based design method and moving least squares, the metamodel uncertainty and the inherent uncertainty of the complex model. Its validation reveals accordance with the results of the complex models. As a result, the moving least squares model shows a high accuracy on the entire complex response surfaces, which is, in particular, confirmed with the comparison to the nearest neighbour interpolation. Accordingly, the use of moving least squares instead of the nearest neighbour interpolation can improve the accuracy of a risk analysis. The metamodel uncertainty and the inherent uncertainty have clear effects on the results of the risk analysis and are especially important where the database is small or where the complex model has large aleatory uncertainties.
The original sampled uncertainty approach uses all simulated scenario replications and describes the aleatory uncertainty without the assumption of parameters or specific types of probability distributions. For this reason, it is explicitly suitable for a low number of replications and varying frequency distributions among the results of the different scenarios.
The methods of the generic metamodel are suitable for the evaluation of a wide parameter domain of complex response surfaces. The separation of the deterministic response surface model and the aleatory uncertainty of the complex model makes the metamodel applicable on deterministic and stochastic complex models as well as experiments in engineering. Thus, it is useful for expensive simulations or experiments where the results are required on a wide domain of parameters.
The methodology and the results presented in this publication are subjected to limitations. The results of the risk analysis are limited to the specific scenario described in the case study. Furthermore, response surface methods other than moving least squares, such as the first- and second-order regression methods, may be more efficient when the focus is on a small range of parameters as it often is in optimisation problems. Moreover, the accuracy of the metamodel uncertainty may be limited due to the use of the prediction interval method. Improving this issue by adding additional points or by applying other response surface methods, such as the Gaussian process model, still constitutes an open point for future research.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}