
Building an Effective Classifier for Phishing Web Pages Detection: A Quantum-Inspired Biomimetic Paradigm Suitable for Big Data Analytics of Cyber Attacks



Abstract
:1. Introduction
1.1. Problem Statement and Research Motivation
1.2. Contribution and Methodology
- -
- This work contributes by demonstrating that the improvements obtained by utilizing a specialized learner are outweighed by the advantages made by extracting more meaningful features from the URL data, allowing for improved classification. As a result, GA is adapted into a bio-inspired feature reduction approach to focus on the most pertinent features (optimal URL data features) for constructing a powerful and effective learning model.
- -
- A two-step quantum artificial bee colony (2-step QABC) technique is adapted for effective malicious URL clustering. The K-means method is used to determine the starting locations of food sources in the modified 2-step QABC algorithm, rather than utilizing randomization. In addition, a refined solution search equation inspired by particle social behavior was utilized to focus on the most successful places to look.
- -
- Real-world DNS traffic may be much higher than that in published datasets. So, malicious website detection methods must be scalable. Further, certain methods need big data for detection algorithm training and fine-tuning. The proposed strategy takes advantage of the Apache Hadoop distributed computing technology to solve this issue.
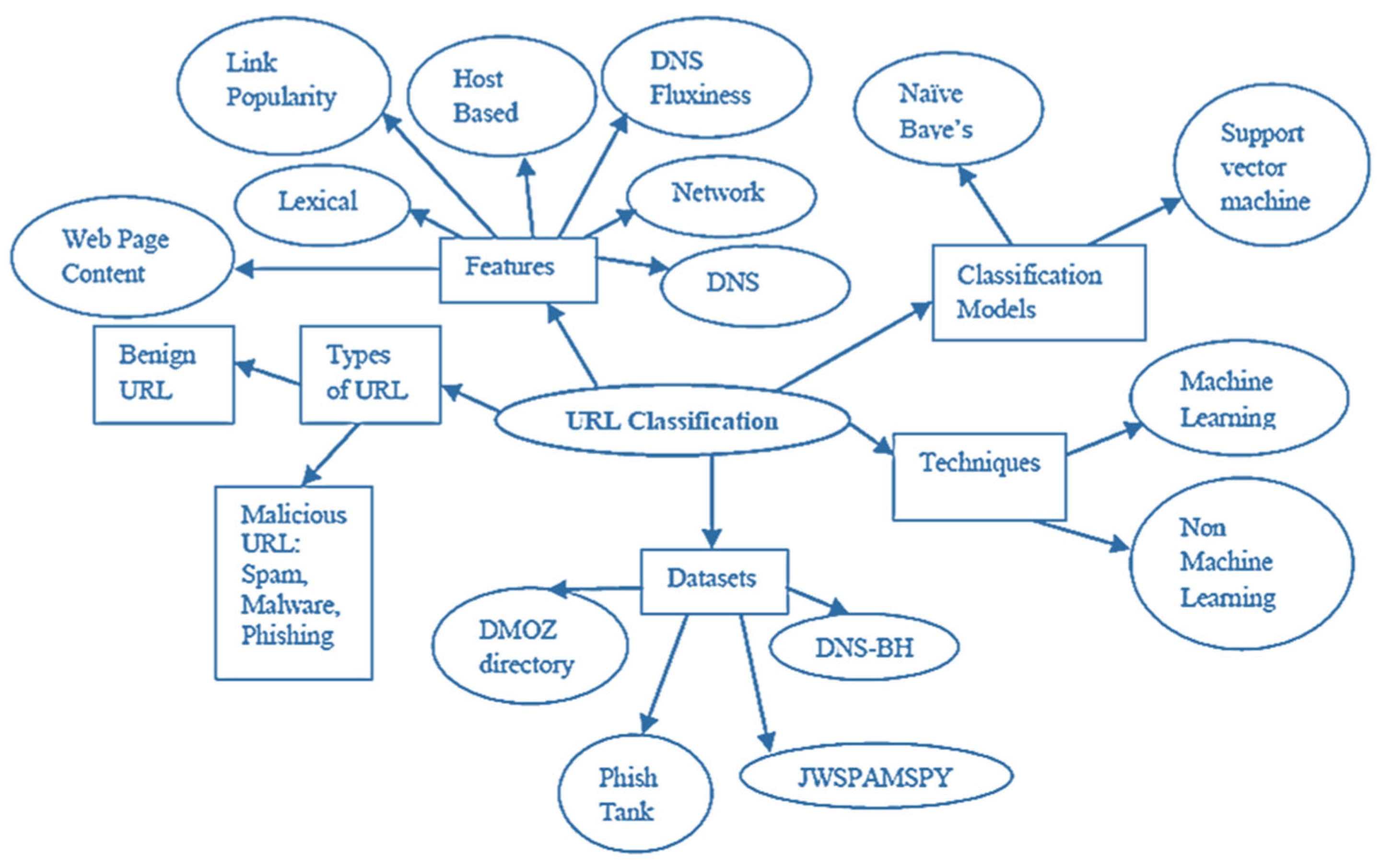
2. State of the Art
3. Proposed Malicious URL Detection Model
3.1. Problem Formulation
- -
- Feature representation: Determine the best feature representation to extract, in which the URL is represented by the d-dimensional feature vector .
- -
- Machine learning: Learning a prediction function f, that correctly predicts the class assignment for every instance of a URL based on the presentation of its features.
3.2. Methodology
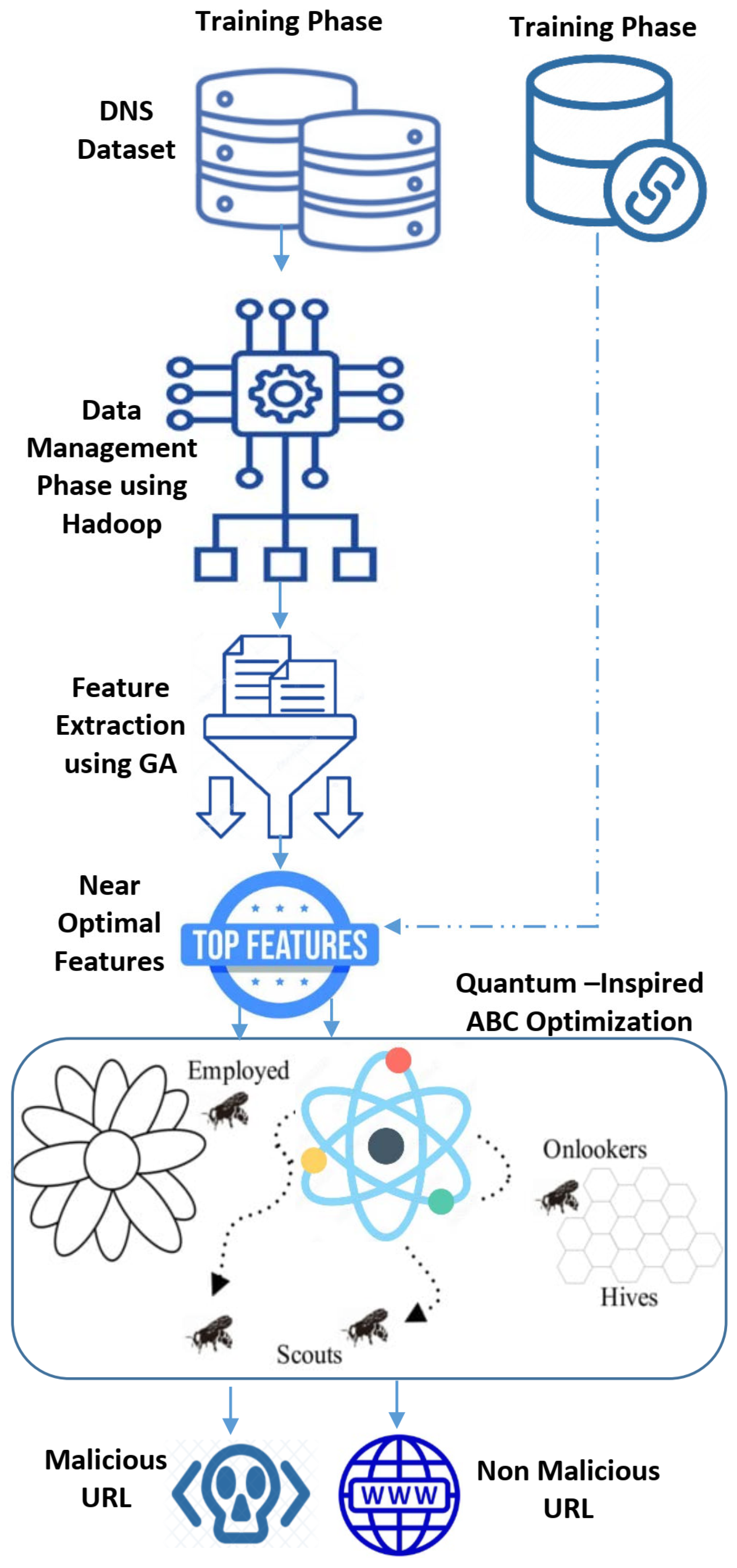
3.2.1. Training Phase
Step 1: Passive DNS Dataset
Step 2: Data Preprocessing and Management
Step 3: Feature Extraction
- -
- Type 1: DNS answer-based features: A domain’s DNS answer consists of DNS records.
- -
- Type 2: TTL value-based features: Every DNS record has a TTL that indicates how long a domain’s answer should be cached. Both DNS clients and name servers may profit from DNS caching if the TTL is between 1 and 5 days. High-availability systems reduce hostname TTL and employ round-robin DNS.
- -
- Type 3: DNS domain name-based features: DNS provides human-readable names to people who cannot remember server IP addresses. Good internet services pick easy-to-remember domain names. Malicious individuals do not care about easy-to-remember domain names. This feature represents QNAME query name in which the target domain-name is presented as a sequence of labels, each label consisting of a length octet followed by that number of octets. The domain name ends with the zero-length octet for the null label of the root. This DNS server looks for resource records (RRs) that match the specified Qtype and Qclass. If it does not have a match, this server can point to a DNS server that may have a match instead. QTYPE is a two-octet code which specifies the type of the query, e.g., host addresses. QCLASS is a two-octet code that specifies the class of the query, e.g., internet addresses. Table 1 shows a record for the used dataset (17 feature vector per URL) [36,37,38,39,40,41,42,43,44,45].
Step 4: Feature Selection Using Genetic Algorithm
| Algorithm 1: Feature Selection Algorithm |
| Input: —Data sample with features —Evaluation measure to be maximized —Successor generation operator Output: Solution Begin: Solution: = (weighted) feature subset Solution: = Repeat: Until Stop (J, L). |
- -
- R is the solution space; each chromosome contains 17 feature vector per URL (see Table 1). R is n matrix, where n is the number of URL samples. Each bit is a gene representing the vector’s feature.
- -
- Q is the feasibility predicate (different operators: selection, crossover, and mutation). Crossover refers to the process by which genes from one parent are swapped with those from another parent in order to create a hybrid child. Simple single-point crossovers are used here. A uniform mutation is used to avoid slipping into a locally optimal solution. The selection operator keeps the best-fitting chromosome from one generation and chooses specified numbers of parent chromosomes. Tournament selection is popular in genetic algorithms because of its efficiency and simplicity [61].
- -
- represents the collection of viable options (new-generation populations). Following these iterations, the most optimal chromosome will be used to symbolize the URL feature vector by including a selection of key components. According to the identification success rate, this vector will explicitly indicate the best possible feature combination [62].
- -
- f is the fitness function. The fittest individual will become the operator’s companion. The fitness function is based on the difference between the actual URL’s categorization and its calculated one. Acc is given by [11]:
| Algorithm 2: Genetic Algorithm Pseudo Code |
|
Step 5: Quantum Artificial Bee Colony (QABC) Classifier
| Algorithm 3: K-means clustering |
| Input: K (the number of clusters); K = 2 (malicious or benign) D dataset contains best feature values for each URLi Output: Begin Arbitrary choose K objects from D as the initial cluster centers; Repeat
|
| Algorithm 4: Two-step QABC clustering |
| Input: D dataset contains best feature values for each Fitness Function “Sensitivity” Output: Best solution of final cluster center () j = 1, 2 Begin Initialization phase.
Initialize the food source within the boundary of given dataset in random order; Apply the K-means algorithm Send the employed bees to the food sources; /* Computed centers */ End For Iteration = 0; Do While (the termination condition is not met) For (each employed bee)/* Employed bee’s phase */ For i = 1:SN
For i = 1:SN Compute the probability value associated with each food source. End For For i = 1:SN /* Start the onlooker bees phase*/ If (rand ( ) < Pri) /* Pri the probability associated with ith food source */
i = i + 1; End If End For If (any employed bee becomes scout bee)/* Scout bee’s phase */ Send the scout bee to a randomly produced to food source; End if Memorize the best solution achieved Iteration = iteration + 1 End While Obtain final cluster Center End |
3.2.2. Testing Phase
| Algorithm 5: the Suggested Clustering Model |
| Input: Xi: Passive DNS Dataset GA parameters configuration ABC classifier parameters configuration Output: URL classifier (malicious, benign) Begin
|
4. Results and Discussions
4.1. Experiment 1: (The Significance of Features Selection)
4.2. Experiment 2: (Classifiers Evaluation)
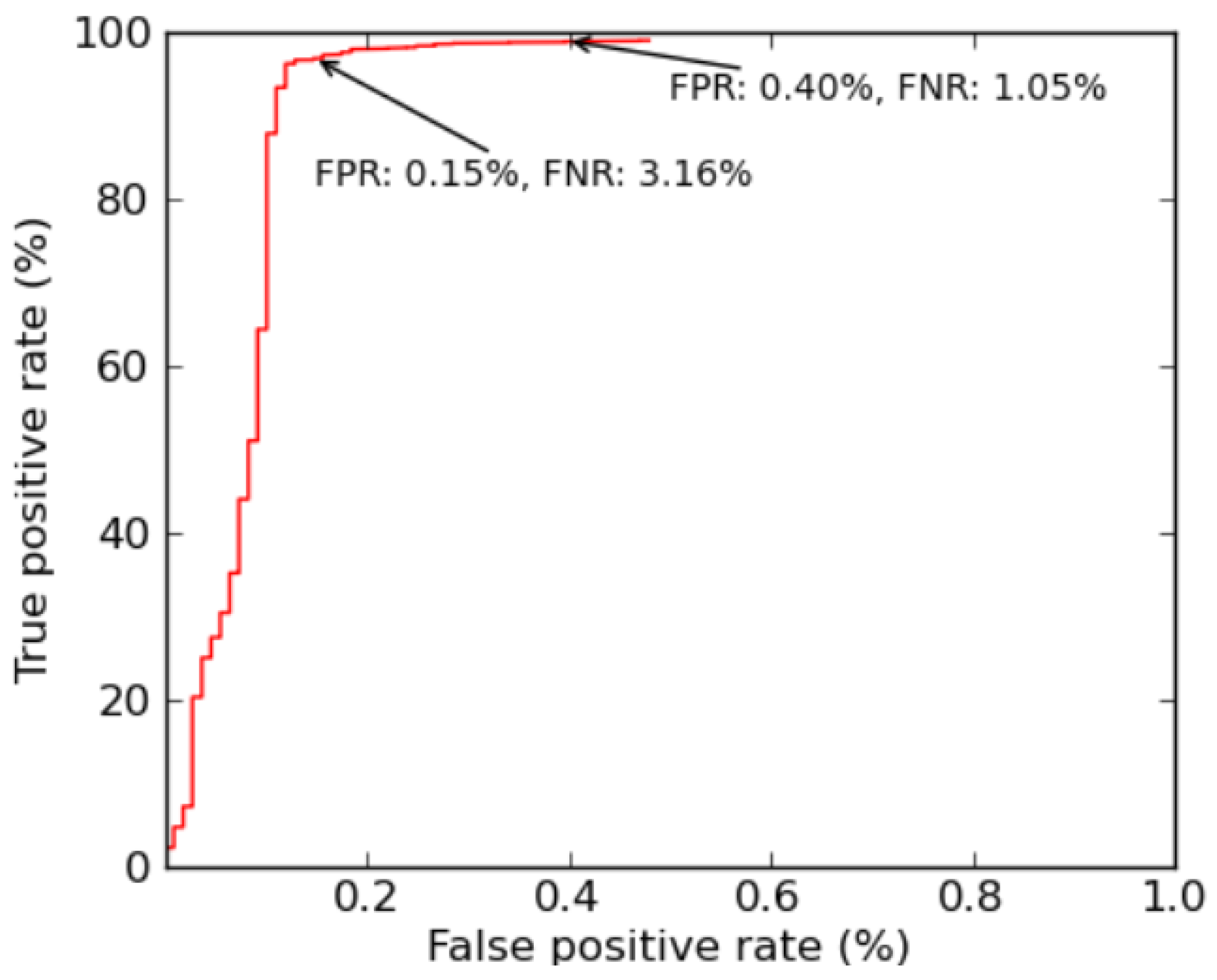
4.3. Experiment 3: (Tuning False Positives and Negatives)
4.4. Experiment 4: (Concept Drift)
4.5. Experiment 5: (Performance of Different Metaheuristics-Based Feature Selection Algorithms)
4.6. Limitation
- -
- Malicious websites are influenced by the selected URL features. They may be altered by several factors. Classification accuracy is the only metric in this work.
- -
- As such, the proposed supervised machine learning model cannot evaluate the harmful potential of any given domain. If a domain isn’t being resolved by any hosts, for instance, it won’t be recorded in the passive DNS database, and hence won’t be considered in the proposed model. A domain will not be included in the domain graph, and the suggested model will not work for it, if it never exchanges IP addresses with any other domains.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Yan, X.; Xu, Y.; Cui, B.; Zhang, S.; Guo, T.; Li, C. Learning URL embedding for malicious website detection. IEEE Trans. Ind. Inform. 2020, 16, 6673–6681. [Google Scholar] [CrossRef]
- Begum, A.; Badugu, S. A study of malicious URL detection using machine learning and heuristic approaches. In Advances in Decision Sciences, Image Processing, Security and Computer Vision; Springer: Cham, Switzerland, 2020; pp. 587–597. [Google Scholar]
- Hong, J.; Kim, T.; Liu, J.; Park, N.; Kim, S. Phishing URL detection with lexical features and blacklisted domains. In Adaptive Autonomous Secure Cyber Systems; Springer: Cham, Switzerland, 2020; pp. 253–267. [Google Scholar]
- Afzaliseresht, N.; Miao, Y.; Michalska, S.; Liu, Q.; Wang, H. From logs to stories: Human-centered data mining for cyber threat intelligence. IEEE Access 2020, 8, 19089–19099. [Google Scholar] [CrossRef]
- Palaniappan, G.; Sangeetha, S.; Rajendran, B.; Goyal, S.; Bindhumadhava, B. Malicious domain detection using machine learning on domain name features, host-based features and web-based features. Procedia Comput. Sci. 2020, 171, 654–661. [Google Scholar] [CrossRef]
- Kim, T.; Reeves, D. A survey of domain name system vulnerabilities and attacks. J. Surveill. Secur. Saf. 2020, 1, 34–60. [Google Scholar] [CrossRef]
- Nabeel, M.; Khalil, I.; Guan, B.; Yu, T. Following passive DNS traces to detect stealthy malicious domains via graph inference. ACM Trans. Priv. Secur. 2020, 23, 1–36. [Google Scholar] [CrossRef]
- Singh, C. Phishing website detection based on machine learning: A survey. In Proceedings of the IEEE International Conference on Advanced Computing and Communication Systems, Coimbatore, India, 6–7 March 2020; pp. 398–404. [Google Scholar]
- Xuan, C.; Nguyen, H.; Tisenko, V. Malicious URL detection based on machine learning. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 148–153. [Google Scholar] [CrossRef] [Green Version]
- Raja, A.; Vinodini, R.; Kavitha, A. Lexical features based malicious URL detection using machine learning techniques. Mater. Today Proc. 2021, 47, 163–166. [Google Scholar] [CrossRef]
- Zhauniarovich, Y.; Khalil, I.; Yu, T.; Dacier, M. A survey on malicious domains detection through DNS data analysis. ACM Comput. Surv. 2018, 51, 1–36. [Google Scholar] [CrossRef] [Green Version]
- Korkmaz, M.; Sahingoz, O.; Diri, B. Feature selections for the classification of webpages to detect phishing attacks: A survey. In Proceedings of the IEEE International Congress on Human-Computer Interaction, Optimization and Robotic Applications, Ankara, Turkey, 26–28 June 2020; pp. 1–9. [Google Scholar]
- Li, S.; Zhang, K.; Chen, Q.; Wang, S.; Zhang, S. Feature selection for high dimensional data using weighted k-nearest neighbors and genetic algorithm. IEEE Access 2020, 8, 139512–139528. [Google Scholar] [CrossRef]
- Ding, Y.; Zhou, K.; Bi, W. Feature selection based on hybridization of genetic algorithm and competitive swarm optimizer. Soft Comput. 2020, 24, 11663–11672. [Google Scholar] [CrossRef]
- Cao, Y.; Ji, S.; Lu, Y. An improved support vector machine classifier based on artificial bee colony algorithm. J. Phys. Conf. Ser. 2020, 1550, 042073. [Google Scholar] [CrossRef]
- Dedeturk, B.; Akay, B. Spam filtering using a logistic regression model trained by an artificial bee colony algorithm. Appl. Soft Comput. 2020, 91, 106229. [Google Scholar] [CrossRef]
- Shiue, Y.; You, G.; Su, C.; Chen, H. Balancing accuracy and diversity in ensemble learning using a two-phase artificial bee colony approach. Appl. Soft Comput. 2021, 105, 107212. [Google Scholar] [CrossRef]
- Jacob, I.; Darney, P. Artificial Bee Colony Optimization Algorithm for Enhancing Routing in Wireless Networks. J. Artif. Intell. 2021, 3, 62–71. [Google Scholar]
- Akay, B.; Karaboga, D.; Gorkemli, B.; Kaya, E. A Survey on the Artificial Bee Colony Algorithm Variants for Binary, Integer and Mixed Integer Programming Problems. Appl. Soft Comput. 2021, 106, 107351. [Google Scholar] [CrossRef]
- Huo, F.; Sun, X.; Ren, W. Multilevel Image Threshold Segmentation Using an Improved Bloch Quantum Artificial Bee Colony Algorithm. Multimed. Tools Appl. 2020, 79, 2447–2471. [Google Scholar] [CrossRef]
- Li, Y.; Zhao, Y.; Zhang, Y. A Spanning Tree Construction Algorithm for Industrial Wireless Sensor Networks Based on Quantum Artificial Bee Colony. EURASIP J. Wirel. Commun. Netw. 2019, 2019, 176. [Google Scholar] [CrossRef]
- Cai, W.; Vosoogh, M.; Reinders, B.; Toshin, D.; Ebadi, A. Application of Quantum Artificial Bee Colony for Energy Management by Considering the Heat and Cooling Storages. Appl. Therm. Eng. 2019, 157, 113742. [Google Scholar] [CrossRef]
- Honar, P.; Rashid, M.; Alam, F.; Demidenko, S. IoT big Data provenance scheme using blockchain on Hadoop ecosystem. J. Big Data 2021, 8, 114. [Google Scholar] [CrossRef]
- Priyanka, E.; Thangavel, S.; Meenakshipriya, B.; Prabu, D.; Sivakumar, N. Big data technologies with computational model computing using Hadoop with scheduling challenges. In Deep Learning and Big Data for Intelligent Transportation; Springer: Cham, Switzerland, 2021; pp. 3–19. [Google Scholar]
- Darwish, S.; Anber, A.; Mesbah, S. Bio-inspired machine learning mechanism for detecting malicious URL through passive DNS in big data platform. In Machine Learning and Big Data Analytics Paradigms: Analysis, Applications and Challenges; Springer: Cham, Switzerland, 2021; pp. 147–161. [Google Scholar]
- Ma, J.; Saul, L.; Savage, S.; Voelker, G. Learning to detect malicious URLs. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Dong, H.; Shang, J.; Yu, D.; Lu, L. Beyond the blacklists: Detecting malicious URL through machine learning. In Proceedings of the BlackHat Asia, Marina Bay Sands, Singapore, 28–31 March 2017; pp. 1–8. [Google Scholar]
- Shi, Y.; Chen, G.; Li, J. Malicious domain name detection based on extreme machine learning. Neural Process. Lett. 2018, 48, 1347–1357. [Google Scholar] [CrossRef]
- Whittaker, C.; Ryner, B.; Nazif, M. Large-scale automatic classification of phishing pages. In Proceedings of the Annual International Conference on Machine Learning, Montreal, QC, Canada, 21–24 June 2010; pp. 1–14. [Google Scholar]
- Benavides, E.; Fuertes, W.; Sanchez, S.; Sanchez, M. Classification of phishing attack solutions by employing deep learning techniques: A systematic literature review. In Developments and Advances in Defense and Security, Smart Innovation, Systems and Technologies; Springer: Singapore, 2020; Volume 152, pp. 51–64. [Google Scholar]
- Jain, A.; Parashar, S.; Katare, P.; Sharma, I. Phishskape: A content based approach to escape phishing attacks. Procedia Comput. Sci. 2020, 171, 1102–1109. [Google Scholar] [CrossRef]
- Alkawaz, M.; Steven, S.; Hajamydeen, A. Detecting phishing website using machine learning. In Proceedings of the IEEE International Colloquium on Signal Processing & Its Applications, Langkawi, Malaysia, 28–29 February 2020; pp. 111–114. [Google Scholar]
- Tupsamudre, H.; Singh, A.; Lodha, S. Everything is in the name—A URL based approach for phishing detection. In Proceedings of the International Symposium on Cyber Security Cryptography and Machine Learning, Be’er Sheva, Israel, 27–28 June 2019; Springer: Cham, Switerland; pp. 231–248. [Google Scholar]
- Guan, D.; Chen, C.; Lin, J. Anomaly based malicious URL detection in instant messaging. In Proceedings of the Joint Workshop on Information Security, Kaohsiung, Taiwan, 6–7 August 2009; Volume 43, pp. 1–14. [Google Scholar]
- Sorio, E.; Bartoli, A.; Medvet, E. Detection of hidden fraudulent URLs within trusted sites using lexical features. In Proceedings of the International Conference on Availability, Reliability and Security, Regensburg, Germany, 2–6 September 2013; pp. 242–247. [Google Scholar]
- Watkins, L.; Beck, S.; Zook, J.; Buczak, A.; Chavis, J.; Robinson, W.; Morales, J.; Mishra, S. Using semi-supervised machine learning to address the big data problem in DNS networks. In Proceedings of the IEEE 7th Annual Computing and Communication Workshop and Conference, Las Vegas, NV, USA, 9–11 January 2017; pp. 1–6. [Google Scholar]
- Bilge, L.; Sen, S.; Balzarotti, D.; Kirda, E.; Kruegel, C. Exposure: A passive DNS analysis service to detect and report malicious domains. ACM Trans. Inf. Syst. Secur. 2014, 16, 1–28. [Google Scholar] [CrossRef]
- Torabi, S.; Boukhtouta, A.; Assi, C.; Debbabi, M. Detecting Internet abuse by analyzing passive DNS traffic: A survey of implemented systems. IEEE Commun. Surv. Tutor. 2018, 20, 3389–3415. [Google Scholar] [CrossRef]
- Da Silva, L.; Silveira, M.; Cansian, A.; Kobayashi, H. Multiclass classification of malicious domains using passive DNS with xgboost. In Proceedings of the IEEE 19th International Symposium on Network Computing and Applications, Cambridge, MA, USA, 24–27 November 2020; pp. 1–3. [Google Scholar]
- Perdisci, R.; Papastergiou, T.; Alrawi, O.; Antonakakis, M. Iotfinder: Efficient large-scale identification of IoT devices via passive DNS traffic analysis. In Proceedings of the IEEE European Symposium on Security and Privacy, Genoa, Italy, 7–11 September 2020; pp. 474–489. [Google Scholar]
- Liang, Z.; Zang, T.; Zeng, Y. Malportrait: Sketch malicious domain portraits based on passive DNS data. In Proceedings of the IEEE Wireless Communications and Networking Conference, Seoul, Republic of Korea, 25–28 May 2020; pp. 1–8. [Google Scholar]
- Sun, Y.; Jee, K.; Sivakorn, S.; Li, Z.; Lumezanu, C.; Korts-Parn, L.; Wu, Z.; Rhee, J.; Kim, C.; Chiang, M.; et al. Detecting malware injection with program-DNS behavior. In Proceedings of the IEEE European Symposium on Security and Privacy, Virtual conference, 7–11 September 2020; IEEE: Genoa, Italy; pp. 552–568. [Google Scholar]
- Guo, X.; Pan, Z.; Chen, Y. Application of passive DNS in cyber security. In Proceedings of the IEEE International Conference on Power, Intelligent Computing and Systems, Shenyang, China, 28–30 July 2020; pp. 257–259. [Google Scholar]
- Silveira, M.; da Silva, L.; Cansian, A.; Kobayashi, H. Detection of newly registered malicious domains through passive DNS. In Proceedings of the IEEE International Conference on Big Data, Orlando, FL, USA, 15–18 December 2021; pp. 3360–3369. [Google Scholar]
- Fernandez, S.; Korczyński, M.; Duda, A. Early detection of spam domains with passive DNS and SPF. In Proceedings of the International Conference on Passive and Active Network Measurement, Virtual Event, 28–30 March 2022; Springer: Cham, Switzerland; pp. 30–49. [Google Scholar]
- Li, K.; Yu, X.; Wang, J. A Review: How to detect malicious domains. In Proceedings of the International Conference on Artificial Intelligence and Security, Dublin, Ireland, 19–23 July 2021; Springer: Cham, Switzerland; pp. 152–162. [Google Scholar]
- Hajaj, C.; Hason, N.; Dvir, A. Less is more: Robust and novel features for malicious domain detection. Electronics 2022, 11, 969. [Google Scholar] [CrossRef]
- Chiew, K.; Tan, C.; Wong, K.; Yong, K.; Tiong, W. A new hybrid ensemble feature selection framework for machine learning-based phishing detection system. Inf. Sci. 2019, 484, 153–166. [Google Scholar] [CrossRef]
- Zuhair, H.; Selamat, A.; Salleh, M. Feature selection for phishing detection: A review of research. Int. J. Intell. Syst. Technol. Appl. 2016, 15, 147–162. [Google Scholar] [CrossRef]
- Zeebaree, S.; Shukur, H.; Haji, L.; Zebari, R.; Jacksi, K.; Abas, S. Characteristics and analysis of Hadoop distributed systems. Technol. Rep. Kansai Univ. 2020, 62, 1555–1564. [Google Scholar]
- Merceedi, K.; Sabry, N. A Comprehensive survey for Hadoop distributed file system. Asian J. Res. Comput. Sci. 2021, 11, 46–57. [Google Scholar] [CrossRef]
- Elkawkagy, M.; Elbeh, H. High performance Hadoop distributed file system. Int. J. Netw. Distrib. Comput. 2020, 8, 119–123. [Google Scholar] [CrossRef]
- Rahul, K.; Banyal, R.; Goswami, P. Analysis and processing aspects of data in big data applications. J. Discret. Math. Sci. Cryptogr. 2020, 23, 385–393. [Google Scholar] [CrossRef]
- Essakimuthu, A.; Karthik, G.; Santhana, K.; Harold, R. Enhanced Hadoop distribution file system for providing solution to big data challenges. In Further Advances in Internet of Things in Biomedical and Cyber Physical Systems; Springer: Cham, Switzerland, 2021; pp. 71–83. [Google Scholar]
- Lappas, P.; Yannacopoulos, A. A machine learning approach combining expert knowledge with genetic algorithms in feature selection for credit risk assessment. Appl. Soft Comput. 2021, 107, 107391. [Google Scholar] [CrossRef]
- Javed, R.; Rahim, M.; Saba, T.; Rehman, A. A comparative study of features selection for skin lesion detection from dermoscopic images. Netw. Model. Anal. Health Inform. Bioinform. 2020, 9, 4. [Google Scholar] [CrossRef]
- Shreem, S.; Turabieh, H.; Al Azwari, S.; Baothman, F. Enhanced binary genetic algorithm as a feature selection to predict student performance. Soft Comput. 2022, 26, 1811–1823. [Google Scholar] [CrossRef]
- Zhou, J.; Hua, Z. A correlation guided genetic algorithm and its application to feature selection. Appl. Soft Comput. 2022, 123, 108964. [Google Scholar] [CrossRef]
- Rostami, M.; Berahmand, K.; Forouzandeh, S. A novel community detection based genetic algorithm for feature selection. J. Big Data 2021, 8, 2. [Google Scholar] [CrossRef]
- Too, J.; Abdullah, A. A new and fast rival genetic algorithm for feature selection. J. Supercomput. 2021, 77, 2844–2874. [Google Scholar] [CrossRef]
- Ibrahim, M.; Nurhakiki, F.; Utama, D.; Rizaki, A. Optimized genetic algorithm crossover and mutation stage for vehicle routing problem pick-up and delivery with time windows. In Proceedings of the IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2021; Volume 1071, p. 012025. [Google Scholar]
- Damia, A.; Esnaashari, M.; Parvizimosaed, M. Adaptive genetic algorithm based on mutation and crossover and selection probabilities. In Proceedings of the 7th IEEE International Conference on Web Research, Tehran, Iran, 19–20 May 2021; pp. 86–90. [Google Scholar]
- Sahoo, G. A two-step artificial bee colony algorithm for clustering. Neural Comput. Appl. 2017, 28, 537–551. [Google Scholar]
- Wäldchen, S.; Macdonald, J.; Hauch, S.; Kutyniok, G. The computational complexity of understanding binary classifier decisions. J. Artif. Intell. Res. 2021, 70, 351–387. [Google Scholar]
- Lang, S.; Bravo-Marquez, F.; Beckham, C.; Hall, M.; Frank, E. Wekadeeplearning4j: A deep learning package for weka based on deeplearning4j. Knowl. Based Syst. 2019, 178, 48–50. [Google Scholar] [CrossRef]
- Gautam, S.; Sharma, C.; Kukreja, V. Handwritten mathematical symbols classification using WEKA. In Applications of Artificial Intelligence and Machine Learning; Springer: Singapore, 2021; pp. 33–41. [Google Scholar]
- Thakkar, A.; Lohiya, R. Attack classification using feature selection techniques: A comparative study. J. Ambient Intell. Humaniz. Comput. 2021, 12, 1249–1266. [Google Scholar] [CrossRef]
- Hassani, H.; Hallaji, E.; Razavi-Far, R.; Saif, M. Unsupervised concrete feature selection based on mutual information for diagnosing faults and cyber-attacks in power systems. Eng. Appl. Artif. Intell. 2021, 100, 104150. [Google Scholar] [CrossRef]
- Bouzoubaa, K.; Taher, Y.; Nsiri, B. Predicting DOS-DDOS attacks: Review and evaluation study of feature selection methods based on wrapper process. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 131–145. [Google Scholar] [CrossRef]
- Garg, S.; Verma, S. A Comparative Study of Evolutionary Methods for Feature Selection in Sentiment Analysis. In Proceedings of the International Joint Conference on Computational Intelligence, Dhaka, Bangladesh, 25–26 October 2019; pp. 131–138. [Google Scholar]
- Di Mauro, M.; Galatro, G.; Fortino, G.; Liotta, A. Supervised feature selection techniques in network intrusion detection: A critical review. Eng. Appl. Artif. Intell. 2021, 101, 104216. [Google Scholar] [CrossRef]
- Yi, Y.; Wang, Y.; Gu, F.; Chen, X. Optimizing uncertain express delivery path planning problems with time window by ant colony optimization. In Proceedings of the International Conference on Computational Intelligence and Security, Chengdu, China, 19–22 November 2021; pp. 420–424. [Google Scholar]
- Deng, C.; Lin, J.; Chen, L. A multi-objective ant colony algorithm for the optimization of path planning problem with time window. In Proceedings of the International Conference on Computational Intelligence and Security, Chengdu, China, 16–18 December 2022; pp. 351–355. [Google Scholar]
- Sui, T.; Mo, Y.; Marelli, D.; Sun, X.; Fu, M. The vulnerability of cyber-physical system under stealthy attacks. IEEE Trans. Autom. Control 2020, 66, 637–650. [Google Scholar] [CrossRef] [Green Version]
- Sui, T.; Sun, X. The vulnerability of distributed state estimator under stealthy attacks. Automatica 2021, 133, 109869. [Google Scholar] [CrossRef]
- Sui, T.; Marelli, D.; Sun, X.; Fu, M. Stealthiness of Attacks and Vulnerability of Stochastic Linear Systems. In Proceedings of the IEEE Asian Control Conference, Kitakyushu, Japan, 9–12 June 2019; pp. 734–739. [Google Scholar]
- Sui, T.; Marelli, D.; Sun, X.; You, K. A networked state estimation approach immune to passive eavesdropper. In Proceedings of the Chinese Control Conference, Guangzhou, China, 27–30 July 2019; pp. 8867–8869. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Feature | Feature Type | Description | Value |
|---|---|---|---|
| pkt.sniff_timestamp | Time | The time used to sniff sending packet by sniffer software | 1466542358.83808 (Microseconds) |
| qry_class | Type 1 | Query class, 1 is most common for Internet | 1 |
| qry_name | Type 3 | Query Name | www.google.com, accessed on 1 May 2022 |
| qry_name_len | Type 3 | Represents the length in bytes of the query name. | 123 |
| qry_type | Type 1 | Type of DNS packet requested | 28 |
| resp_class | Type 1 | This defines the protocol family for the Resource Records record | 1 |
| resp_len | Type 1 | Resource record length | 16 |
| resp_name | Type 1 | Resource record query name | www.google.com, accessed on 1 May 2022 |
| resp_ttl | Type 2 | Resource record time to live in seconds- how long the resource records may be cached | 141 |
| resp_type | Type 1 | Resource record type | 28 |
| Id | 54,323 | ||
| flags_opcode | Type 1 | Type of query (e.g., 0 = standard query) | 0 |
| flags_response | Type 1 | Response code (e.g., 0 = DNS Query completed successfully | 1 |
| Aa | Type 1 | Authoritative answer (0 = This server isn’t an authority for the domain name or from cache) | Null |
| count_queries | Type 1 | Question count | 1 |
| count_auth_rr | Type 1 | Authority resource record count | 0 |
| count_answers | Type 1 | Answer resource record count | 1 |
| TP% | FP% | FN% | TN% | Testing Phase’s Running Time for 1000 URLs (Milliseconds) | |
|---|---|---|---|---|---|
| Utilizing all Features | 96 | 6 | 4 | 94 | 2300 |
| Utilizing optimized Features | 98 | 3 | 2 | 97 | 760 |
| Classifier | Accuracy | TP Rate | TN Rate | Testing Phase’s Running Time for 1000 URLs (Milliseconds) |
|---|---|---|---|---|
| Random Forest | 95 | 96 | 92 | 500 |
| C4.5 | 93 | 92 | 94 | 300 |
| SVM | 87 | 88 | 93 | 560 |
| ABC | 94 | 96 | 91 | 650 |
| Two-step ABC [25] | 96 | 98 | 95 | 690 |
| QABC(Proposed Model) | 98 | 98 | 97 | 760 |
| Batch Number | Error Rate |
|---|---|
| batch 1 | 2.30 |
| batch 2 | 2.25 |
| batch 3 | 2.28 |
| batch 4 | 2.20 |
| batch 5 | 2.10 |
| batch 6 | 2.00 |
| batch 7 | 2.29 |
| batch 8 | 2.05 |
| batch 9 | 2.24 |
| batch 10 | 2.26 |
| Feature Selection Module | Accuracy (%) | Feature Reduction | Testing Phase’s Running Time for 1000 URLs (Milliseconds) |
|---|---|---|---|
| BGW | 78.52 | 17% | 1230 |
| BB | 77.35 | 39% | 940 |
| ACO | 98.00 | 40% | 925 |
| GA (Proposed model) | 97.50 | 50% | 780 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Darwish, S.M.; Farhan, D.A.; Elzoghabi, A.A. Building an Effective Classifier for Phishing Web Pages Detection: A Quantum-Inspired Biomimetic Paradigm Suitable for Big Data Analytics of Cyber Attacks. Biomimetics 2023, 8, 197. https://doi.org/10.3390/biomimetics8020197
Darwish SM, Farhan DA, Elzoghabi AA. Building an Effective Classifier for Phishing Web Pages Detection: A Quantum-Inspired Biomimetic Paradigm Suitable for Big Data Analytics of Cyber Attacks. Biomimetics. 2023; 8(2):197. https://doi.org/10.3390/biomimetics8020197
Chicago/Turabian StyleDarwish, Saad M., Dheyauldeen A. Farhan, and Adel A. Elzoghabi. 2023. "Building an Effective Classifier for Phishing Web Pages Detection: A Quantum-Inspired Biomimetic Paradigm Suitable for Big Data Analytics of Cyber Attacks" Biomimetics 8, no. 2: 197. https://doi.org/10.3390/biomimetics8020197
APA StyleDarwish, S. M., Farhan, D. A., & Elzoghabi, A. A. (2023). Building an Effective Classifier for Phishing Web Pages Detection: A Quantum-Inspired Biomimetic Paradigm Suitable for Big Data Analytics of Cyber Attacks. Biomimetics, 8(2), 197. https://doi.org/10.3390/biomimetics8020197