1. Introduction
Metamaterials have been addressed in a lot of research in various fields. Applications of metamaterials also include metamaterial antenna, in which metamaterials are utilized to improve their performance. The size of the electromagnetic antenna affects its radiation loss and quality factor. However, a tiny antenna with low cost and high efficiency is preferred for an integrated antenna. The metamaterial can create small antennas with improved bandwidth and gain. It can also help to minimize their electrical size and increase their directivity. Metamaterial antennas can solve the bandwidth limitation of small antennas. Simulation software is employed to estimate the effect of metamaterial on the antenna characteristics, including its gain and bandwidth. During simulation, the metamaterial antenna is adjusted by trial and error to fulfill the expected parameters. However, this process can take much longer than expected. Machine learning (ML) and algorithms can be used to forecast antenna characteristics as an alternative to simulation software. ML is a branch of artificial intelligence extensively used in different engineering applications in making decisions or predictions. This study addresses the challenge of using optimized ML models to forecast the metamaterial antenna’s gain and bandwidth [
1,
2].
Metamaterial antenna has been studied extensively in the literature, as it has unusual properties [
3,
4]. These properties enhance the abilities of the original material and their engagement in the industry [
5]. Metamaterial antennas are derived from a field of science engineering known as computational electromagnetics. Computational electromagnetics is based on optimizing methods and computation for designing antennas. However, traditional design paradigms comprising model designs, parameter sweep, trial-and-error methods, and optimization algorithms are time-consuming and use a large amount of computing resources. Furthermore, if the design requirements change, simulations must be rerun, preventing the scientists from focusing on their actual demands. As a result, we have considered machine learning to fill in the gaps in our search for a quick, efficient, and automated design strategy.
Over the past few years, there has been an increase in research focused on combining machine learning techniques with metaheuristics to solve combinatorial optimization problems. This integration aims to enhance the efficiency, effectiveness, and resilience of metaheuristics during their search process and ultimately improve their performance in terms of solution quality, convergence rate, and robustness. In addition, there are several techniques developed to tackle the different optimization problems [
6,
7,
8,
9]. Optimization problems can be found in almost any field of study [
10]. Some of the most popular areas are medicine [
11], engineering problems [
12,
13,
14], image processing [
15], feature selection [
16], etc. [
17,
18].
Recently, the utilization of ML in computational electromagnetics has attracted the research community’s attention [
19,
20,
21,
22]. The most important benefit of ML-aided electromagnetics lies in the ability to create an underlying relationship between the system input parameters and the desired outcomes; consequently, the computational burden in experimental real-time processing is shifted to the offline training stage [
23]. The application of ML in metamaterial antenna design is a promising approach to deal with its high complexity and computational burden [
24,
25]. In [
26], a joint design for antenna selection was proposed, using two deep learning models to forecast the selected antennas and estimate the hybrid beamformers. Another work utilized KNN and SVM for multiclass classification of the antenna selection in multiple-input, multiple-output (MIMO) systems [
27].
In [
25], ANN was employed to predict the selected antennas having a minimum signal-to-noise ratio (SNR) among the users. The authors of [
24] used SVM and naive Bayes as a hybrid ML model for forecasting a secure-based antenna on the wiretap channel. In [
21], SVM was utilized with several antennas in multiuser communication systems. The authors suggested an antenna allocation system based on the support vector machine. In [
20], the authors built a support vector regression model trained on data collected from a microwave simulator to design the feed in a rectangular patch antenna. In this research, the performance of the ensemble ML approach is investigated in forecasting the bandwidth of the metamaterial antenna. An optimization technique is utilized to estimate the optimal weights of the learning model. Furthermore, a binary version of the proposed algorithm is introduced to select the best features from the input dataset.
There are several ML algorithms, such as k-nearest neighbor (KNN) [
28], artificial neural network (ANN) [
27], decision tree [
29], and support vector machine (SVM). The main concept of these algorithms is building a learning model that can generalize and predict unseen data. For example, ANN is an intelligent learning model that simulates the biological nervous system [
27]. One of the most common architectures of feedforward ANN is called multilayer perceptron (MLP), which comprises an input layer, a set of hidden layers, and an output layer. Ensemble ML is based on combining two or more ML models to improve the performance of the base ML models [
30], including ANN, KNN, and SVM. The main principle of ensemble learning is estimating an output by averaging the output values of the base ML models. In average-based ensemble learning, every base model contributes the same weight to the computation. This may result in an undesired performance of the ensemble methods. An efficient performance can be yielded by using an optimization technique to calculate the weights of the base models.
The proposed system is illustrated in
Figure 1. The system includes three main stages: data preprocessing for inputting the missing values and normalization of the data values; feature selection; and the regression stage through optimized ensemble learning for forecasting the bandwidth of the metamaterial antenna. The proposed framework is applied to publicly available metamaterial forecasting datasets from the Kaggle platform [
31].
In this study, machine learning is incorporated into antenna design. The electromagnetic properties of an antenna that have been established via a series of experimental simulations are used to train a machine learning system. The ML algorithm helps design a metamaterial antenna that delivers the closest results based on the designer’s requirements. The following objectives will be yielded through this study:
Developing an ML model using the ensemble learning approach for forecasting the bandwidth of the metamaterial antenna.
Developing metaheuristic optimization techniques to establish an efficient ensemble ML model.
Developing an optimization algorithm to select the significant features from the input dataset.
Comparing the performance of the proposed model with the state-of-the-art ML models in forecasting bandwidth of the metamaterial antenna.
The following structure can be used for the remaining parts of the paper.
Section 2 presents the related work. In
Section 3, we will go over a general summary of the materials and procedures.
Section 4 explains the mathematical methodology for estimating the bandwidth of metamaterial antennas using the DTACO model in depth. In
Section 5, we will discuss some experimental simulations and various situations for comparison.
Section 6 summarizes the advantages and disadvantages of the suggested method when it is used in real life.
Section 7 of the paper is where the conclusion and future work can be found.
2. Related Work
The frequency selective surface (FSS)-based filtering antenna Filtenna was given computationally efficient optimization recommendations in [
32]. The Filtenna enhances and filters signals at a certain frequency. It is challenging to build Filtenna FSS elements because of the numerous variables and intricate interrelations that affect scattering responses. An accurate model of unit cell behavior is created by the authors using a deep learning method called modified multilayer perceptron (M2LP). Filtenna FSS elements are optimized by the M2LP model. The proposed approach reduces the computational cost of optimization by 90% when compared to direct electromagnetic (EM)-driven design. An experimental Filtenna prototype demonstrates the efficacy of the method. Without incurring additional computing overhead, the unit cell model may generate FSS and Filtenna in many frequency ranges. The authors of [
33] suggested limiting antenna response sensitivity updates to dominant directions in parameter space to hasten antenna tuning. The dominant directions are determined by problem-specific information, or more precisely, how estimated antenna characteristics vary when moving through the one-dimensional affine subspaces encompassed by these directions. The processing costs of full-wave electromagnetic (EM) simulations used in antenna optimization are decreased via local optimization. The results show a 60% speedup over reference approaches without sacrificing quality. The method is evaluated against accelerated versions of trust region algorithms and various antenna topologies.
It is essential to optimize the features of the antenna system. While parametric analyses are common, more exact numerical techniques are required for optimal designs in complex problems with multiple variables, goals, and constraints. The reliability and cost of computation for EM-driven optimization are problematic. Without a solid starting point or multimodal objective function, local numerical algorithms may find it challenging to identify effective designs for EM simulations, which are expensive to run. The reliability of an antenna can be increased by following a recent strategy that suggests matching design objectives (such as center frequencies) with the antenna’s actual operational parameters at each design iteration [
34]. With this modification, a local search is now feasible, and the objectives are gradually being brought closer to the initial targets. Through the use of a specification management system and variable-resolution optimization framework, this research proposes a trustworthy and economical antenna-tuning technique. Depending on the discrepancy between the actual and desired operating conditions and algorithm convergence, the algorithm adaptively modifies EM model fidelity. When compared to a single-fidelity method, starting the search with the lowest-fidelity model and gradually raising it results in computational cost savings of roughly 60%.
The work in [
35] addressed reflectarray (RA) design difficulties, which have advantages over traditional antenna arrays but narrow bandwidths and losses. Inverse surrogate modeling reduces computing costs for the independent adjustment of many unit cells in an alternate RA design technique. A few reference reflection phase-optimized anchor points alter the unit cells. Anchor point optimization uses minimum-volume unit cell regularization for solution uniqueness. The provided method lowers RA design computation to a few dozen cell EM analyses. The method is illustrated and tested. A fully adaptive regression model (FARM) was proposed in [
36] for accurate transistor scattering and noise parameter modeling utilizing artificial neural networks (ANNs), particularly deep learning. Characteristics, designable parameters, biasing conditions, and frequency are complex, making transistor modeling difficult. A tree Parzen estimator automatically determines all network components and processing functions in the FARM technique to match input data and network architecture. Three microwave transistors are used to validate the strategy, which outperforms ANN-based methods in modeling accuracy.
Microwave component design increasingly relies on numerical optimization. Circuit theory techniques can produce good beginning designs, but electromagnetic cross-coupling and radiation losses require fine parameter tweaking. Gradient-based EM-driven design closure processes work well when the initial design is near the optimum. If the starting design is not optimal, the search process may converge to a poor local optimum. Simulation-based optimization is computationally expensive. Research in [
37] proposed a new parameter-tuning method using variable-resolution EM models and a recently published design specification management methodology. The design specification management approach automates design objective modification during the search process, boosting robustness to bad starting points. Algorithm convergence and performance specification disagreement determine simulation model fidelity. Lower-resolution EM simulations in the early optimization phase can save up to 60% computationally compared to a gradient-based search with design specification management and numerical derivatives. Three microstrip circuit tests demonstrate computational speedup without compromising design quality.
Surrogate modeling is preferred for difficult antenna design projects that need expensive full-wave electromagnetic simulations. Traditional metamodeling methodologies cannot handle nonlinear antenna characteristics across a large range of system parameters due to the curse of dimensionality. Performance-driven modeling frameworks that build surrogates from antenna performance numbers rather than geometric factors can overcome this issue [
38]. This method dramatically reduces model setup costs without losing design utility. This study provides a domain confinement-based variable-fidelity electromagnetic simulation modeling framework. The final surrogate is generated using co-kriging, which combines simulation data of diverse fidelities. Three microstrip antennas validate this approach, showing reliable models with much lower CPU costs than conventional and performance-driven modeling methods.
Quantifying fabrication tolerances and uncertainties in antenna design helps antennas resist manufacturing errors and material parameter fluctuations. Industrial settings require this. Geometric parameters can degrade electrical and field properties, causing frequency shifts and impedance matching. Maximizing manufacturing yield requires computationally intensive full-wave electromagnetic analysis to improve antenna performance in the presence of uncertainty. The curse of dimensionality has plagued surrogate modeling methods used to overcome these issues [
39]. This work provides a low-cost antenna yield optimization method. It carefully defines the domain of the statistical analysis metamodel, which consists of a few influential directions controlling antenna responses in the relevant frequency bands. Circuit response variability assessment automates these directions. A small domain volume reduces surrogate model setup cost while improving yield. Three antenna topologies validate the proposed strategy, which outperforms multiple benchmark methods with surrogate models. Electromagnetic-driven Monte Carlo simulations prove the yield optimization’s reliability.
Adaptive algorithms dynamically adjust their search strategies based on problem characteristics or optimization progress. Hybrid algorithms combine multiple optimization techniques to leverage their strengths and compensate for their weaknesses. Considering adaptive or hybrid algorithms can enhance the optimization process by adapting to the specific requirements and challenges of the metamaterial design problem. Metaheuristic algorithms such as dipper-throated optimization and ant colony optimization can effectively handle complex optimization problems such as metamaterial design. These algorithms provide a broader exploration of the design space and can help find global optima.
5. Experimental Results
The entire purpose of this part is to provide a thorough examination of the investigation’s findings. The investigations were carried out in two different contexts. The proposed binary DTACO algorithm’s feature selection capabilities for the dataset under test are covered in the first scenario, and the algorithm’s regression capabilities are demonstrated in the second scenario. The DTACO algorithm was analyzed and compared to other algorithms that are considered to be state-of-the-art, including DTO [
40], ACO [
41], particle swarm optimization (PSO) [
42], the grey wolf optimizer (GWO) [
43], the genetic algorithm (GA) [
43], and the whale optimization algorithm (WOA) [
44]. Both scenarios are described below. A presentation of the DTACO algorithm configuration can be found in
Table 1. This presentation includes all of the experiment’s relevant parameters. It is essential to provide details about the numerous parameters that will be used to determine the behavior and performance of the algorithm. These settings include population size (number of agents), the termination criterion (number of iterations), and other important characteristics for optimization m to select the significant features from the input dataset.
Table 2 presents the comparative algorithms’ setup. To evaluate optimization techniques and parameters fairly, many aspects were considered. First, we considered the search space size, constraints, and objective function. Choosing a problem-specific algorithm can improve performance. Second, parameter choice affects algorithm performance. We considered convergence speed and exploration–exploitation trade-offs while tuning parameters for the issue and method. For fair comparisons, ten runs with varied random seeds were applied, statistical analysis was performed, and an appropriate dataset was tested. A fair comparison of DTO, ACO, GWO, PSO, GA, and WOA optimization algorithms and parameter selection yielded meaningful insights and informed decision making. The computational budget was established based on the number of function calls made during optimization. Each optimizer was run ten times for 80 iterations, and the number of search agents was set to 10. Setting a specific computational budget ensured that all the compared algorithms had an equal opportunity to explore and exploit the search space within the given limitations. This approach allows for a fair and standardized evaluation, facilitating meaningful comparisons between optimization algorithms.
5.1. Dataset
The dataset is freely available and can be utilized in constructing a machine learning model for improved radiation efficiency of an antenna [
31]. The dimensions of a patch antenna, the dimensions of the slots in the patch antenna, the operating frequency, and finally, the matching S11 parameter are all included in this dataset. The HFSS program was utilized in the construction of the antenna as well as the collection of the dataset. Ansys HFSS is a software tool utilized to design and simulate high-frequency electronic devices. This 3D electromagnetic (EM) simulation software is specifically tailored for creating and evaluating various products, including antennas, antenna arrays, filters, connectors, and printed circuit boards. Its primary purpose is to provide accurate modeling and analysis capabilities for the development of these high-frequency electronic systems. The radiation frequency of the tested dataset is maintained at 2.4 GHz, making it compatible with Bluetooth and wireless local area network (WLAN) operations.
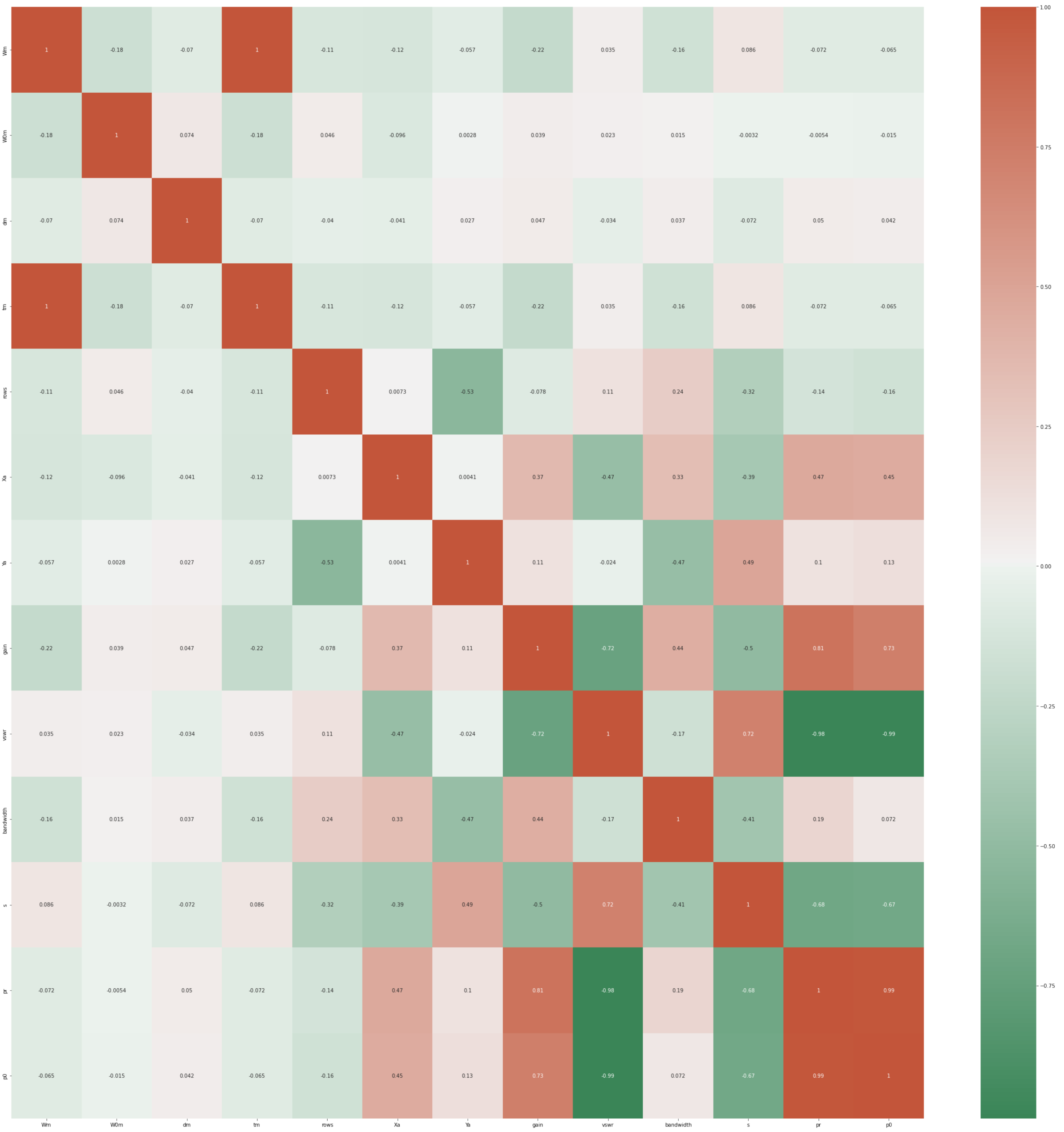
Figure 2 presents a heat map that can be used to gain insight into the manner in which the variables are connected.
5.2. Feature Selection Scenario
When selecting features from the dataset that was put through its paces, the binary implementation of the DTACO method that was proposed is the one that comes into play. In the first scenario, a discussion of the outcomes of the feature selection carried out using the DTACO algorithm described in this paper is included. The binary DTACO (bDTACO) method is analyzed and contrasted with the binary DTO (bDTO), binary ACO (bACO), binary PSO (bPSO), binary GWO (bGWO), and binary GA (bGA).
With the assistance of the objective equation, also known as
, the binary DTACO method is able to determine the level of quality possessed by a given solution. In the equation that follows,
is used as a variable in the expressions for a number of selected features (
v), the total number of features (
V), and a classifier’s error rate (
).
where the significance of the provided feature to the population is indicated by the formula
, and the value of
might fall anywhere in the range [0, 1]. If it is possible to supply a subset of features that are capable of providing a low classification error rate, then the approach can be called acceptable. The k-nearest neighbor technique, also referred to as kNN, is a straightforward classification method that is frequently put into practice. In this method, the employment of the k-nearest neighbor classifier assures that the chosen attributes are of good quality. The only criterion that is used in the process of determining classifiers is the distance that is considered to be the shortest between the query instance and the training instances. This experiment does not make use of any models for the K-nearest neighbor technique in any way.
The effectiveness of the suggested strategy for feature selection is evaluated in accordance with the standards presented in
Table 3. This table also includes a column labeled "M" that contains the total number of iterations performed by both the proposed optimizer and its rivals. The symbol
is used to designate the best solution, and the size of the best solution vector is denoted by the value
. The total number of points for the test set is denoted by the letter
N. The predicted values is denoted by the term
, while the actual values are denoted by the term
.
The results of feature selection using the proposed and compared algorithms are presented in
Table 4. As shown in
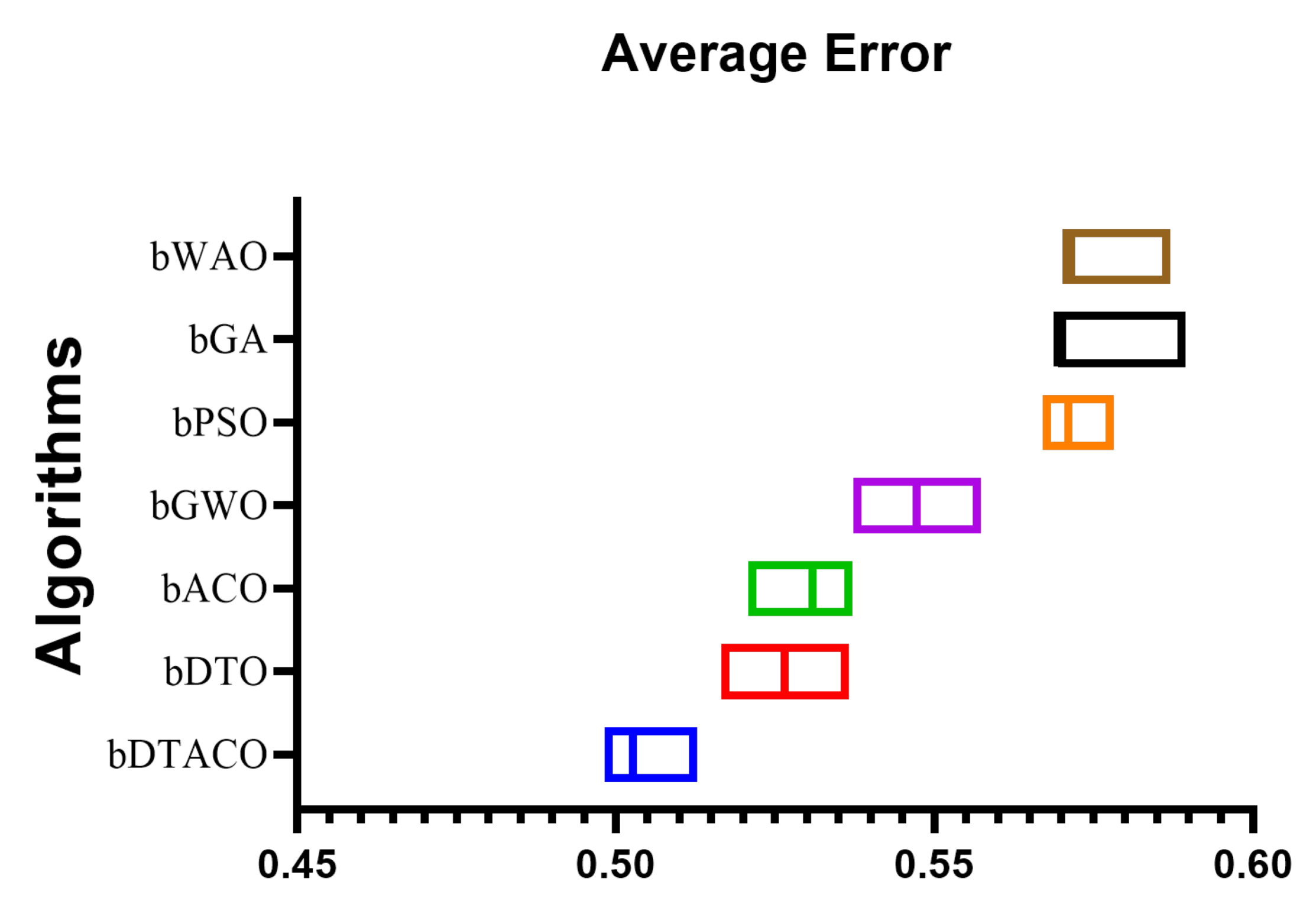
Table 1, these outcomes are based on 80 iterations over 10 runs for 10 agents. With an average error of (0.5027) and a standard deviation of (0.4055), the given bDTACO technique performed as expected. The next best algorithms are bDTO, with a score of (0.5265); bACO, with a score of (0.5308); bGWO, with a score of (0.5472); bGA, with a score of (0.5694); bWOA, with a score of (0.5708); and finally, bPSO, with a score of (0.571), which accomplish the lowest minimal average error in the feature selection process for the data that have been evaluated. When it comes to feature selection, the bPSO algorithm is the weakest one available.
Figure 3 displays the box plot that was generated based on the average error for the bDTACO algorithm, as well as the bDTO algorithm, the bACO algorithm, the bPSO algorithm, the bGWO algorithm, the bGA algorithm, and the bWOA algorithm. The quality of the bDTACO algorithm, as determined by utilizing the objective function described in Equation (
16), is displayed in the figure.
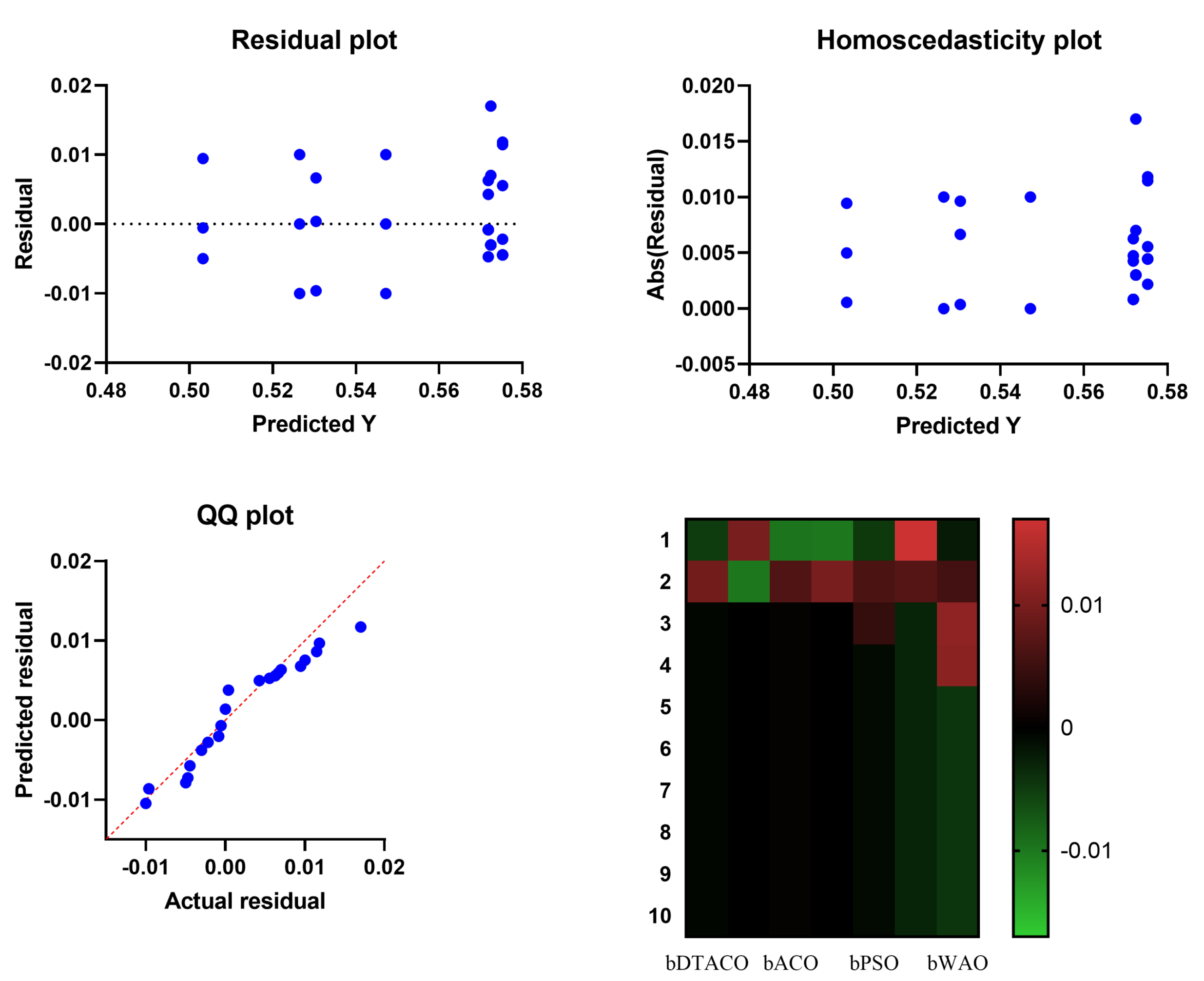
Figure 4 presents the quantile–quantile (QQ) plots, residual plots, and heat map for both the given bDTACO and the methods that were compared for the data that were analyzed. These plots show the relationship between the data and the quantiles and quantile differences.
This statistical analysis uses one-way ANOVA and Wilcoxon signed-rank tests to determine the average error of the suggested binary DTACO algorithm. The Wilcoxon test determines
p-values for comparing the suggested approach to other methods. This statistical test can assess if the suggested algorithm outperforms other algorithms with a
p-value of less than 0.05. The analysis of variance (ANOVA) test was also performed to determine if the suggested algorithm differed significantly from the others.
Table 5 shows the ANOVA test results for the proposed algorithm vs. the methods compared, and
Table 6 shows the Wilcoxon signed-rank test results. The statistical analysis uses ten rounds of each method to achieve reliable comparisons.
5.3. Regression Scenario
In the second scenario, the proposed optimal ensemble DTACO model was compared against basic MLP regressor, SVR, and random forest regressor models over 10 runs and 80 iterations with 10 agents. In order to evaluate the effectiveness of the regression models that were applied in order to anticipate the bandwidth of the metamaterial antenna, additional measurements were used. These metrics include relative root-mean-squared error (RRMSE), Nash–Sutcliffe efficiency (NSE), mean absolute error (MAE), mean bias error (MBE), Pearson’s correlation coefficient (r), coefficient of determination (R2), and determined agreement (WI). the total number of observations in the dataset is represented by the
N parameter. The
nth estimated and observed bandwidth are represented by (
) and (
), and (
) and (
) represents the arithmetic means of the estimated and observed values. The evaluation criteria for predictions are shown in
Table 7.
The findings of the suggested optimizing ensemble DTACO-based model compared to those of the fundamental models are presented in
Table 8. When compared to the RF, which had an RMSE of (0.041033), the given DTACO-based model produced the best results, with an RMSE of (0.003871). MLP, on the other hand, reported an RMSE of (0.045691), which was the poorest possible outcome.
The results of the suggested DTACO-based model’s regression are compared with the results of the DTO, ACO, WOA, GWO, GA, and PSO-based models to demonstrate the effectiveness of the presented algorithm.
Table 9 provides a description of the DTACO-based model that was proposed together with the RMSE results of other models based on ten separate runs. This description includes the minimum, median, maximum, and mean average errors.
Figure 5 displays the box plot calculated using the root-mean-squared error for the proposed DTACO-based model as well as the DTO, ACO, PSO, GWO, GA, and WOA-based models. The quality of the optimized ensemble DTACO-based model, as shown in the figure, was determined with the help of the objective function described in Equation (
16).
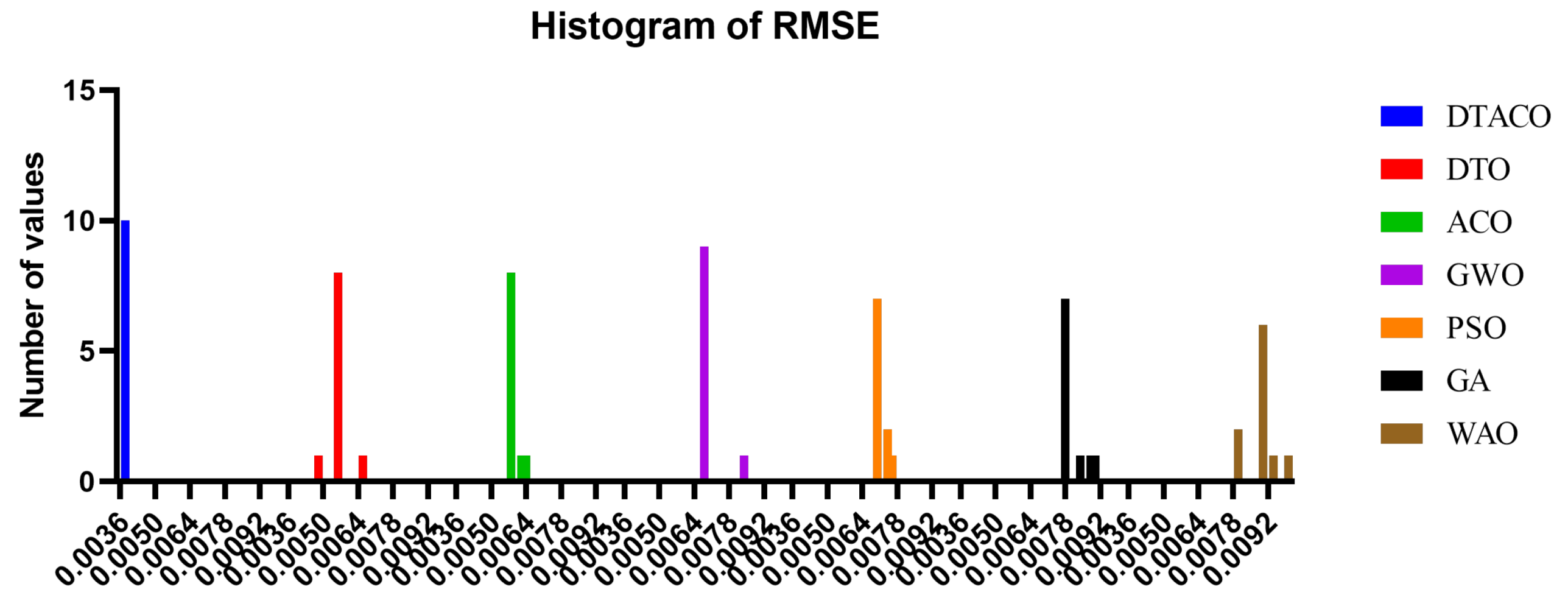
Figure 6 depicts the histogram of the root-mean-squared error (RMSE) for both the DTACO-based model that was presented and the other models.
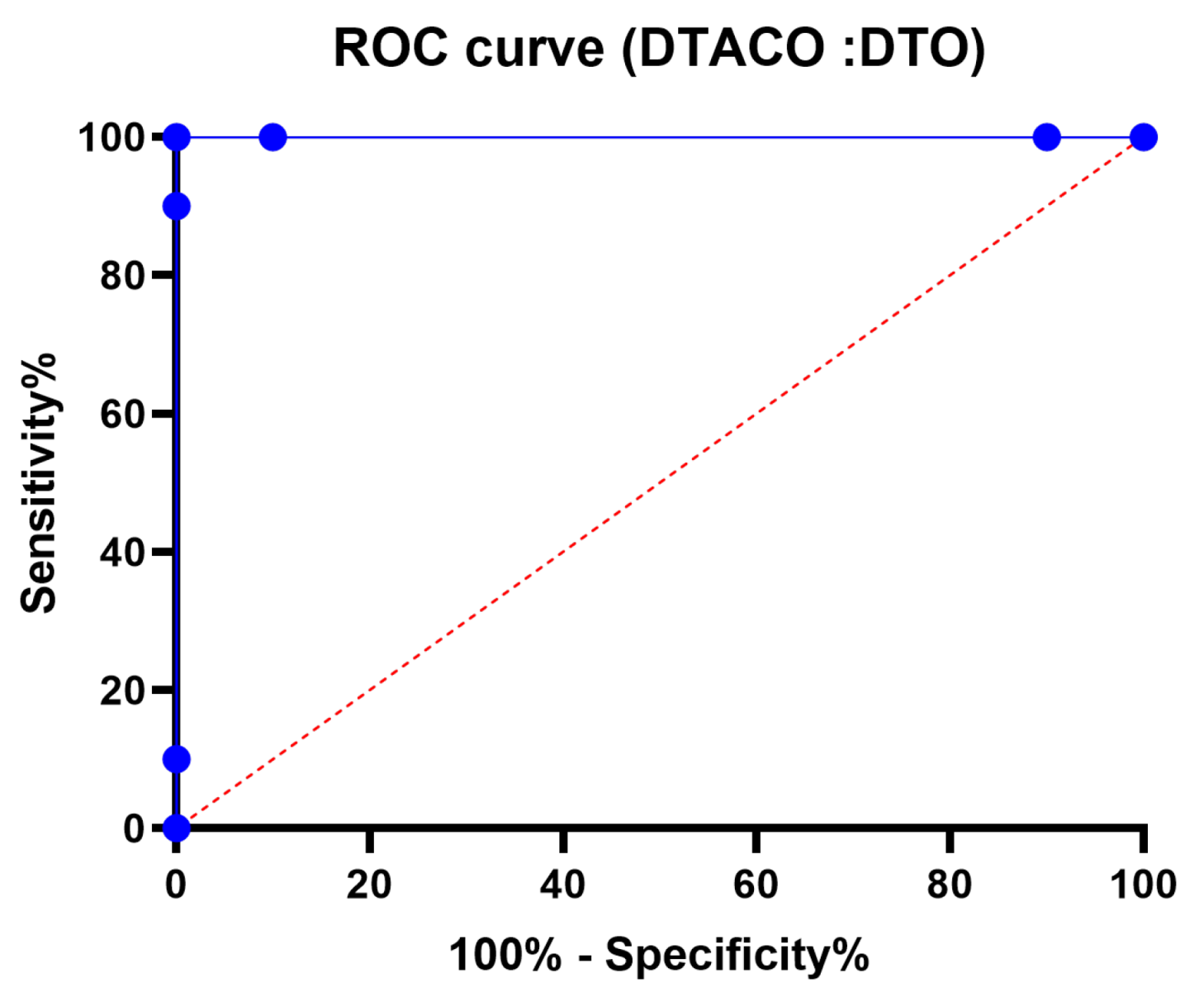
Figure 7 shows the ROC curve of the presented DTACO algorithm versus the DTO algorithm.
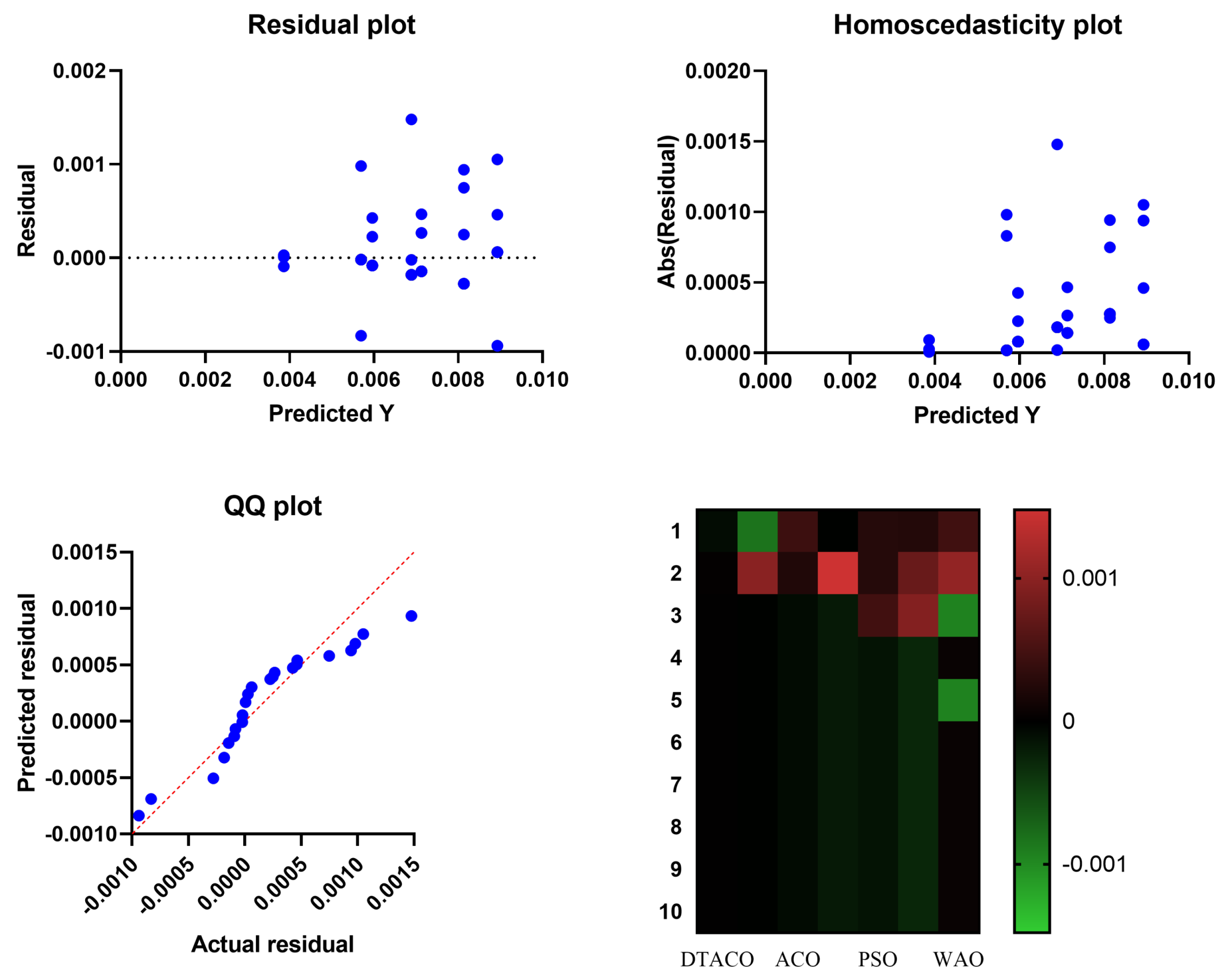
Figure 8 presents the QQ plots, residual plots, and heat map for both the DTACO-based model that was provided and the models that were compared for the data that were investigated. Both sets of plots are based on the analyzed data. These figures demonstrate that the given optimized ensemble DTACO-based model has the potential to outperform the models that were compared.
Table 10 contains the outcomes of the ANOVA test that was performed on the proposed ensemble DTACO and the models that were compared.
Table 11 contains a comparison of the proposed optimized ensemble DTACO and the models that were compared using the Wilcoxon signed-rank test. The statistical analysis was carried out by utilizing ten individual iterations of each of the algorithms that are being presented and evaluated. This ensures that the comparisons are exact and that the results of the study are reliable.
6. Discussion
This section summarizes the advantages and disadvantages of the suggested method when it is used in real life. The suggested method provides a better way to optimize estimating the bandwidth of a metamaterial design. It gives a methodical way to optimize the design factors of metamaterials, which leads to designs that work better and are more efficient. The method is especially useful for figuring out the bandwidth of different metamaterial designs. This is of the utmost importance in engineering applications, where it is important to make sure that developed metamaterials can work within the stated frequency range. When making metamaterials work and perform better, having an exact bandwidth prediction can be very helpful. The fact that the method has been changed to be used in engineering shows that it can be used in real-world situations and is fit for them. It is a useful tool for optimizing metamaterial design because it was made to solve problems and meet the needs of engineering uses. The described method gives designers more options for how to make things because it lets them optimize a number of factors that affect the bandwidth of metamaterials. During the optimization process, it can take into account a number of different design variables and constraints. This lets engineers look into a wide range of choices. The proposed method aims to make the optimization process more productive. By using its newly improved method, it might be possible to reduce the amount of computing time and resources needed to optimize metamaterial design. This would make it easier to use in the real world.
The suggested method focuses on improving the designs of metamaterials and predicting the bandwidth of these designs. Even though this is useful for engineering uses that use metamaterials, it may not be directly applicable to other domains or design problems because of how metamaterials work. The method will only work if accurate models and simulations of the metamaterials are being considered. Wrong or insufficient models may lead to less-than-ideal results or wrong bandwidth estimates. When different design variables and limits are considered, optimizing metamaterial designs can be difficult and time-consuming. The suggested method may still run into problems when dealing with complicated optimization problems, and may not always promise to find the global optimum. One might need the right computer resources, software tools, and experience for the suggested method to work. Engineers and researchers must consider the things mentioned here when applying the method to real-world situations.
7. Conclusions and Future Work
Metamaterials are unusual. They have several constituents and repeating patterns at a smaller wavelength than the phenomena they affect. Metamaterials can control electromagnetic waves by blocking, absorbing, amplifying, or bending them. Metamaterials are used in microwave invisibility cloaks, invisible submarines, revolutionary electronics, microwave components, filters, and negative-refractive-index antennas. This paper improved dipper-throated-based ant colony optimization (DTACO) to predict metamaterial antenna bandwidth. The first case examined the proposed binary DTACO algorithm’s feature selection for the dataset being reviewed, while the second scenario tested its regression. Studying both scenarios’ circumstances, DTACO was compared to the state-of-the-art DTO, ACO, PSO, GWO, and WOA algorithms. The optimal ensemble DTACO-based model was compared to the basic MLP, SVR, and random forest regressor models. The statistical research used Wilcoxon’s rank-sum and ANOVA tests to evaluate the DTACO-based model’s consistency. Because of the versatility of this method, the DTACO-based regression model can be modified and evaluated for a wide variety of datasets in work that will be performed in the future. DTACO will be evaluated with well-known benchmark functions such as CEC17-19, so that DTACO can be compared with other well-known metaheuristic algorithms in future work.

 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}